【Redis学习】Redis中常见的全局命令、数据结构和内部编码
Redis学习笔记:
https://blog.csdn.net/2301_80220607/category_13051025.html?spm=1001.2014.3001.5482
前言:
上一篇我们主要讲了服务端高并发分布式架构的演变,对分布式有了基本的概念,Redis的很多场景都应用了这样的结构,从本篇开始我们就将正式开启Redis的学习,本篇主要讲解一下Redis的常用的全局命令、数据结构和内部编码
注:下面的操作是在Linux系统下进行操作的
目录
1. 预备知识
2. 常见的全局命令
2.1 KEYS
2.2 EXISTS
2.3 DEL
2.4 EXPIRE
2.5 TTL
2.6 TYPE
3. Redis数据类型和内部编码
4. 单线程结构
4.1 引出单线程模型
4.2 为什么单线程还能这么快
1. 预备知识
Redis中的数据都是以键值对的形式存在的,与我们之前所学的键值对不同的是,Redis键值对中的值可以是十种数据中的一种:String(字符串)、Hash(哈希)、List(链表)、Set(集合)、Zset(有序集合)等,这五种是最常用的五种,后面我们也会针对这五种类型分别进行详细的讲解,下面我们会先使用到一个简单的set命令(set key value),这个命令可以帮助我们创建一个String类型的数据
2. 常见的全局命令
2.1 KEYS
返回所有满⾜样式(pattern)的 key。⽀持如下统配样式。
- h?llo 匹配 hello , hallo 和 hxllo
- h*llo 匹配 hllo 和 heeeello
- h[ae]llo 匹配 hello 和 hallo 但不匹配 hillo
- h[^e]llo 匹配 hallo , hbllo , ... 但不匹配 hello
- h[a-b]llo 匹配 hallo 和 hbllo
语法:
KEYS pattern时间复杂度:O(n)
返回值:匹配pattern的所有结果
示例:
127.0.0.1:6379> mset hello 1 hallo 2 hbllo 3 habcllo 4 jhello 5
OK
127.0.0.1:6379> keys *
1) "hbllo"
2) "key1"
3) "habcllo"
4) "hello"
5) "jhello"
6) "hallo"
127.0.0.1:6379> keys h?llo
1) "hbllo"
2) "hello"
3) "hallo"
127.0.0.1:6379> keys h*llo
1) "hbllo"
2) "habcllo"
3) "hello"
4) "hallo"
2.2 EXISTS
判断某个key是否存在
语法:
EXISTS key [key ...]时间复杂度:O(1)
返回值:存在的key的个数
示例:
127.0.0.1:6379> exists hello
(integer) 1
127.0.0.1:6379> exists hhhhh
(integer) 0
127.0.0.1:6379> exists hello hallo
(integer) 2
2.3 DEL
删除指定的key
语法:
DEL key [key ...]时间复杂度:O(1)
返回值:删掉key的个数
示例:
127.0.0.1:6379> del hbllo
(integer) 1
127.0.0.1:6379> del key1 jhello
(integer) 2
2.4 EXPIRE
为指定的key添加过期时间(秒级)
语法:
EXPIRE key seconds时间复杂度:O(1)
返回值:设置成功返回1,设置失败返回0
示例:
127.0.0.1:6379> expire hello 10
(integer) 1
2.5 TTL
获取指定key的过期时间(秒级)
语法:
TTL key时间复杂度:O(1)
返回值:返回剩余的过期时间;-1表示没有关联过期时间,-2表示key不存在
示例:
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 7
127.0.0.1:6379> ttl hello
(integer) 2
127.0.0.1:6379> ttl hello
(integer) -2
2.6 TYPE
返回key对应的数据类型
语法:
TYPE key时间复杂度:O(1)
返回值:key的数据类型,我们上面提到的十种数据类型
示例:(这些数据类型后面都会学到,先看一下这条指令的使用即可)
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> lpush key2 222
(integer) 1
127.0.0.1:6379> sadd key3 333
(integer) 1
127.0.0.1:6379> type key1
string
127.0.0.1:6379> type key2
list
127.0.0.1:6379> type key3
set
3. Redis数据类型和内部编码
type命令返回的是当前键的数据类型,它是Redis对外的数据类型,实际上每种数据类型内部都有多种不同的编码实现,这样方便Redis在处理不同的数据时选择最合适的内部编码
Redis常用数据结构及其内部编码
| 数据结构 | 内部编码 |
|---|---|
| string | raw |
| int | |
| embstr | |
| hash | hashtable |
| ziplist | |
| list | linkedlist |
| set | ziplist |
| hashtable | |
| intset | |
| zset | skiplist |
| ziplist |
可以看到上面的每种数据结构都有两种以上的编码方式,而且有些内部编码可以用来实现多种数据结构,比如ziplist,我们可以通过object encoding命令来查看key的内部编码
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> object encoding key1
"int"
Redis这样设计的好处:
- 可以改进内部编码,而对外的数据结构和命令没有任何影响,这样当我们设计了一种更好的内部编码的时候可以直接去实现数据结构,对用户使用没有影响
- 在不同的场景下数据结构选择不同的内部编码来实现,发挥各自的优势
4. 单线程结构
Redis使用单线程架构来实现高性能的内存数据库服务,下面将通过多个服务端访问Redis服务,Redis服务器的处理上,来解释Redis是如何在单线程模型下保证正确运维和速度
4.1 引出单线程模型
现在同时开启三个redis-cli服务
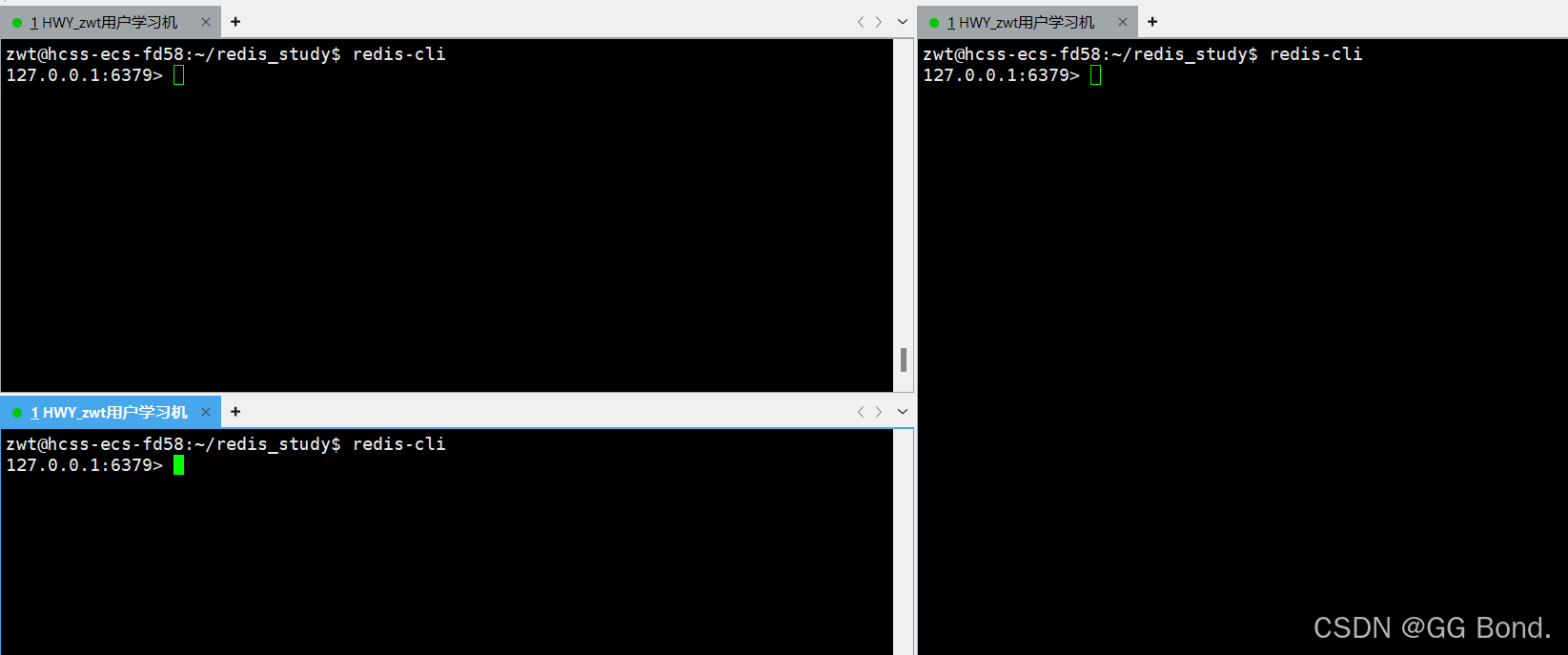
客户端1设置一个字符串键值对:
127.0.0.1:6379> set hello world
客户端2和客户端3都对count做自增操作:
127.0.0.1:6379> incr count
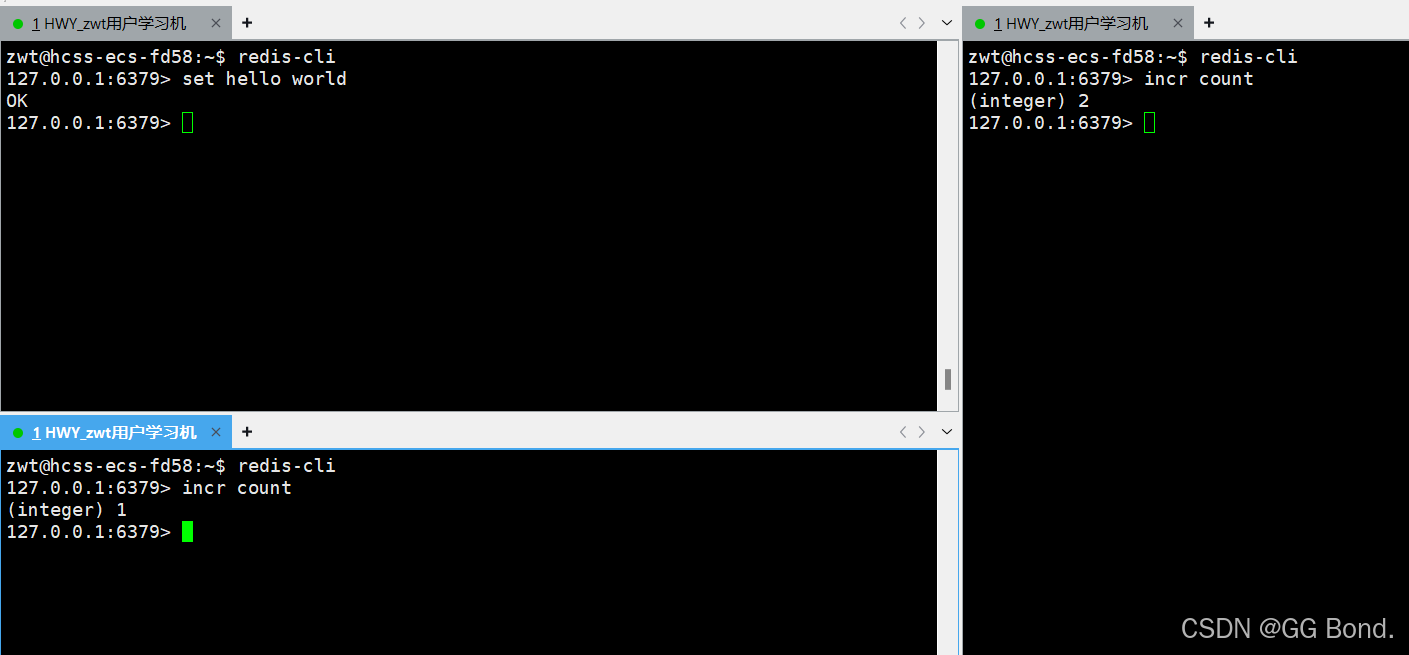
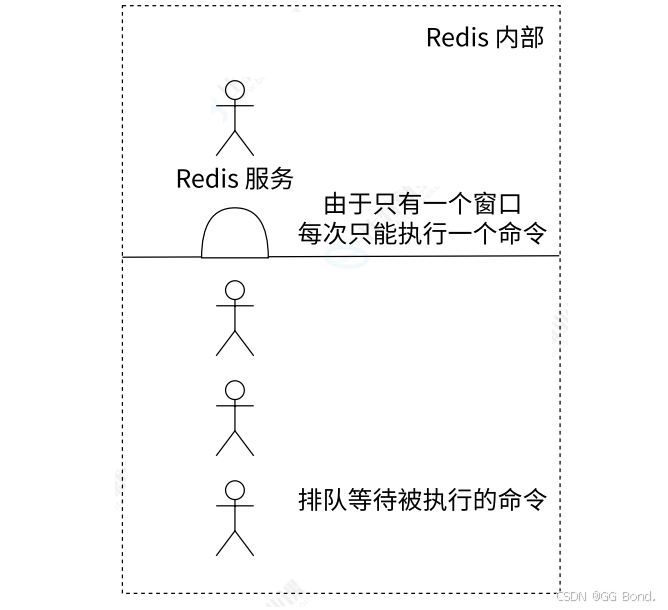
客户端发送的命令要经过:发送命令、执行命令和返回结果三个阶段,虽然我们现在(理论上)同时向Redis服务端发送了三条命令,但它并不会并发执行,而是串行执行的,也就是这三个客户端发出的命令是在服务端排队执行的,这就是Redis的单线程执行模型
4.2 为什么单线程还能这么快
通常来讲,单线程相较于多线程是要慢上很多的,那么Redis服务器在使用单线程架构下是如何保证速率的呢?可以归结为以下三点:
- 纯内存访问,Redis将所有数据放在内存中,内存中响应速度很快
- 非阻塞IO。Redis使用epoll作为I/O多路复用技术的实现,再加上Redis ⾃⾝的事件处理模型 将 epoll 中的连接、读写、关闭都转换为事件,不在⽹络 I/O 上浪费过多的时间(epoll是网络通信中提高速度的一种重要的通信方式)
- 单线程避免了线程切换和竞态产⽣的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;其次多线程避免了在线程竞争同⼀份共享数据时带来的切换和等待消耗。
虽然单线程给Redis带来了许多好处,但还有一个致命的问题:对于单个命令的执行时间都是有要求的。如果某个命令执行时间过长,会导致其它命令都陷入等待队列中,迟迟等不到响应,造成客户端的阻塞,对于Redis这种高性能服务是很致命的,所以Redis是面向快速执行场景的数据库。
感谢各位大佬观看,创作不易,还望各位大佬点赞支持!!!