RocketMQ面试问题与详细回答
第一部分:核心概念与基础
1. 问题: 请先简单介绍一下RocketMQ是什么,它的核心组成部分有哪些?并简要说明每个组件的作用。
考察点: 对RocketMQ整体架构的基本理解。
RocketMQ 是阿里巴巴开源的一款分布式、队列模型的消息中间件,后捐赠给Apache基金会,成为顶级项目。它具有低延迟、高并发、高可用、高可靠的特点。
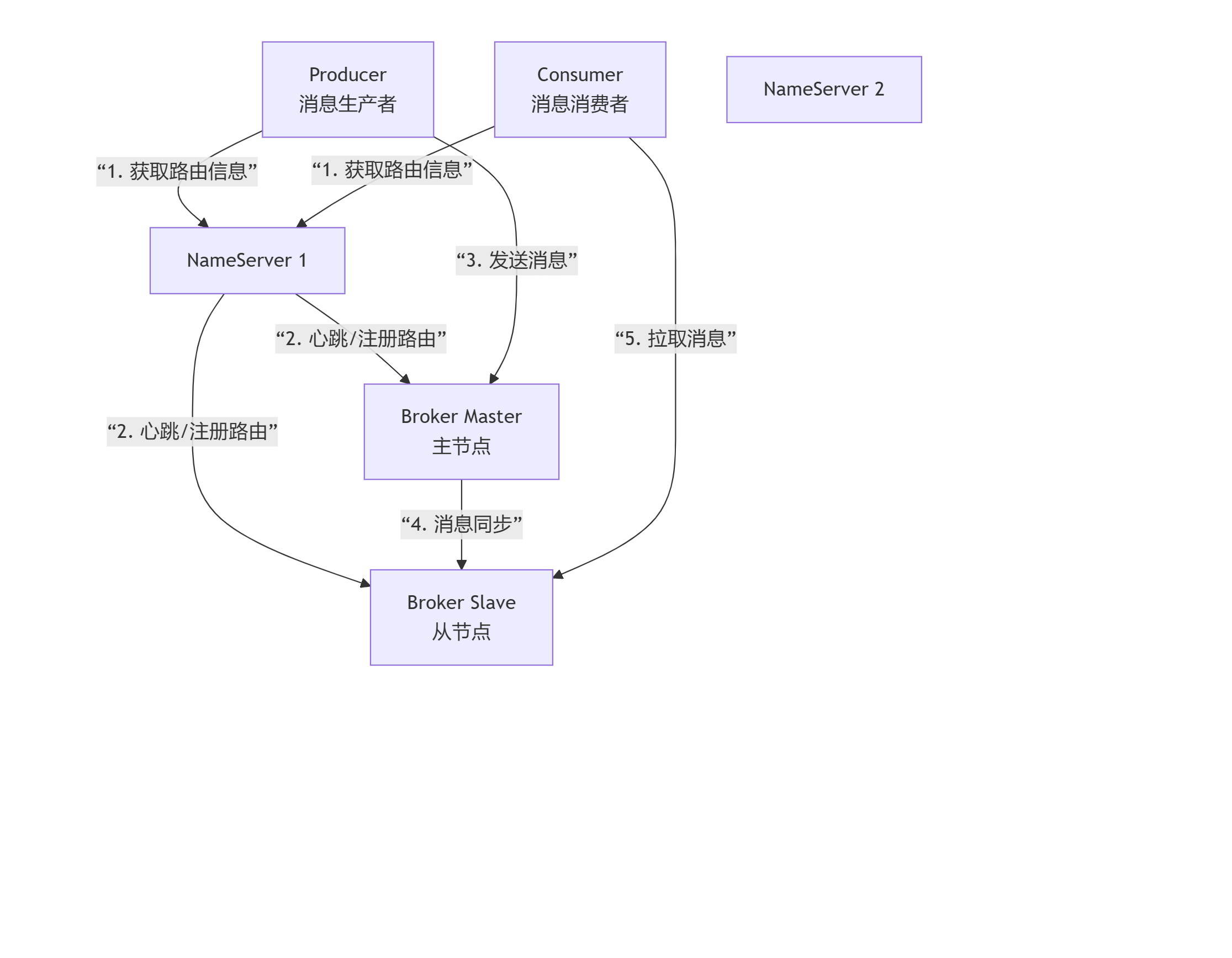
结合上图,我们来详细说明每个组件的作用:
1. NameServer(命名服务器)
角色定位: 消息队列的“指挥中心”或“注册中心”。它本身是无状态的(节点之间不通信)。
核心作用:
服务发现: 接收来自所有Broker节点的注册,并维护整个集群的路由信息(即:哪个Topic存在于哪些Broker上)。
路由管理: 生产者和消费者在启动时,会连接NameServer,获取当前所有Broker的地址和路由信息,从而知道要把消息发送到哪里,从哪里消费消息。
类比理解: 就像电话黄页或DNS服务器。你想联系某个公司(Broker),不需要记住它的具体地址,只需查询黄页(NameServer)即可。
2. Broker(代理服务器)
角色定位: 消息队列的“心脏”或“邮局”,负责消息的存储、投递和查询。
核心作用:
消息存储: 接收生产者发送的消息,并将其持久化到磁盘。
消息投递: 响应消费者的拉取请求,将消息推送给消费者。
高可用保障: 通常以主从架构(Master-Slave)部署。Master负责处理读写请求,Slave则从Master同步数据,作为备份。当Master宕机时,消费者可以从Slave读取消息,保证服务可用性。
类比理解: 就像邮局的分拣中心。它接收寄件人(Producer)的邮件,分门别类地存放(存储),并最终派送给收件人(Consumer)。
3. Producer(消息生产者)
角色定位: 消息的“发起方”或“发布者”。
核心作用:
创建消息: 构建业务消息。
发送消息: 从NameServer获取路由信息,选择相应的Broker Master节点,将消息发送出去。
支持发送模式: 支持同步、异步、单向发送,以满足不同场景下对可靠性和性能的要求。
4. Consumer(消息消费者)
角色定位: 消息的“接收方”或“订阅者”。
核心作用:
订阅消息: 向NameServer获取路由信息,并订阅自己感兴趣的Topic(和Tag)。
消费消息: 连接到Broker,拉取(Pull)消息并进行业务逻辑处理。
消费模式:
集群消费: 同一条消息只能被同一个消费者组内的一个消费者消费。用于负载均衡,是默认模式。
广播消费: 同一条消息会被同一个消费者组内的所有消费者消费。用于所有节点都需要处理同一消息的场景。
数据流总结
结合图表,一次完整的消息收发流程如下:
启动: Broker启动后,向所有NameServer注册自己的路由信息。
寻址: Producer和Consumer启动后,从NameServer拉取路由信息。
发送: Producer根据路由信息,找到对应的Broker Master,将消息发送过去。
存储与同步: Broker Master将消息存储到磁盘,并同步给Slave(如果配置了同步复制)。
消费: Consumer根据路由信息,连接到Broker(可以是Master或Slave),拉取消息进行消费。
2. 问题: 为什么RocketMQ要使用NameServer,而不是像其他一些系统(如Kafka)那样使用ZooKeeper进行服务发现?
考察点: 对RocketMQ设计哲学的理解,以及与其他消息中间件的对比。
优秀回答:
这主要体现了RocketMQ追求简单高效和最终一致性的设计理念。
功能纯粹: NameServer的职责非常单一,就是做路由信息的管理和发现,不参与复杂的Leader选举、强一致性同步等。这使得NameServer本身非常轻量、稳定、性能开销小。
最终一致性: NameServer之间不通信(AP系统),Broker定期向所有NameServer发送心跳来注册路由信息。当某个NameServer下线时,不影响其他节点, Broker会继续向存活的NameServer注册。这种最终一致性模型在消息队列这个场景下是完全足够的,因为短暂的元数据不一致(如新Topic需要一点时间同步)通常不会造成严重问题,系统能快速自我修复。
对比ZooKeeper: ZooKeeper是CP系统,强调强一致性,通过ZAB协议保证数据一致,但牺牲了一定的可用性和性能。对于消息队列的路由发现这种场景,并不需要如此强的一致性保证,NameServer的轻量级设计更为合适。
核心区别:AP 与 CP 的设计选择
首先,要理解一个重要的分布式系统理论:CAP定理。它指出,一个分布式系统无法同时满足一致性(C)、可用性(A)和分区容错性(P)。
ZooKeeper 是 CP 系统:它优先保证强一致性(C) 和分区容错性(P),但在网络分区(比如主节点宕机)时,为了进行选举和恢复一致性,会暂时牺牲可用性(A)。
NameServer 是 AP 系统:它优先保证高可用性(A) 和分区容错性(P),而在数据一致性上采用了最终一致性,即允许在极短时间内,不同节点上的路由信息可能存在细微差别。
基于这个根本区别,我们可以从以下几个维度进行对比:
对比分析表
| 特性 | RocketMQ NameServer | Kafka ZooKeeper | 分析 |
|---|---|---|---|
| 核心职责 | 单一职责:只做路由信息的管理和发现。功能纯粹,像一个轻量级的注册中心。 | 多重职责:不仅负责Broker和Topic的元数据管理,还负责Controller选举、消费偏移量存储(旧版本)、ACL权限控制等。 | NameServer的轻来自于其职责的单一。ZooKeeper的重来自于其作为一个通用协调框架的复杂性。 |
| 数据一致性 | 最终一致性。Broker定期向所有NameServer发送心跳(30秒一次)来注册或更新路由信息。NameServer节点间不进行数据同步。 | 强一致性。使用ZAB协议,所有写请求由Leader处理并同步到多数Follower后才会返回成功,保证所有节点数据视图一致。 | 对于消息路由信息,短暂的不一致(如新Topic需要几秒才能在所有NameServer上可见)是可以接受的,系统能快速自愈。强一致性在此场景下显得“杀鸡用牛刀”,带来了不必要的延迟。 |
| 性能与开销 | 非常高,开销小。无状态,节点间无通信,只是简单的心跳维护和路由查询。 | 相对较低,开销大。每次写操作都需要在集群多数节点间进行磁盘同步和网络通信,延迟更高。 | NameServer的设计极大地提升了路由发现的性能,降低了系统整体延迟。 |
| 可用性 | 非常高。每个NameServer节点都是独立的,任何一个节点宕机,只要还有一个节点存活,生产者和消费者就能通过其他节点获取路由信息(客户端有重试机制)。 | 受选举影响。如果ZooKeeper集群发生Leader选举,在此期间整个Kafka集群的元数据操作(如创建Topic)将不可用,虽然消息的读写可能不受影响(因为生产者消费者有缓存)。 | NameServer的简单性天然带来了更高的可用性。 |
| 扩展性 | 易于水平扩展。只需启动新的NameServer实例,并配置到Broker和客户端即可。 | 扩展性相对复杂。ZooKeeper集群的节点数通常是奇数个(如3、5、7),扩展需要谨慎,因为节点增多可能会影响写性能。 | 消息队列集群的规模变动时,NameServer的扩展更灵活。 |
为什么这种设计更适合RocketMQ?
RocketMQ的设计者认为,消息队列的元数据(路由信息)是变更频率较低、且对强一致性要求不高的数据。
路由信息的特性:Broker的地址、Topic和队列的配置,并不会每秒都在变化。即使NameServer节点间的数据有秒级延迟,也几乎不会影响消息的正确发送和消费。因为生产者客户端有缓存,并且会定期更新路由信息。当某台Broker宕机,NameServer会因其心跳超时而将其剔除,这个变化会在短时间内通知到所有客户端。
追求极致的性能:消息中间件的核心目标是高吞吐、低延迟。将服务发现组件设计得尽可能轻量,有助于实现这一目标。NameServer的AP模型和简单架构完美地服务了这个目标。
故障恢复简单:一个宕机后恢复的NameServer节点,只需要等待Broker的心跳上来,就能快速重建路由表,无需复杂的同步和恢复流程。
总结
RocketMQ选择自研轻量级的NameServer而不是使用ZooKeeper,是一个高度场景化的成功设计。
ZooKeeper 是一个强大的、通用的分布式协调框架,其强一致性保证对于像Kafka的Controller选举、旧版消费位移存储这类需要精确共识的场景是必要的。
NameServer 是一个为消息队列量身定做的专用组件,它牺牲了不必要的强一致性,换来了更简单的架构、更高的性能、更低的延迟和极高的可用性。
这种选择体现了RocketMQ团队“不选最好的,只选最合适的”的设计理念,使得RocketMQ在消息路由这个核心环节上非常高效和稳定。
3. 问题: 解释一下RocketMQ中的Topic、MessageQueue和Tag的概念以及它们之间的关系。
考察点: 对RocketMQ消息模型的理解。
优秀回答:
Topic: 主题,表示一类消息的集合。例如,可以有一个名为
OrderTopic的主题,专门用于处理所有订单相关的消息。它是生产者和消费者进行消息传递的基本单位。MessageQueue: 消息队列。一个Topic在物理上会被分为多个MessageQueue,分布在一个或多个Broker上。MessageQueue是消息存储和水平扩展的实际载体。消息的并行性是由MessageQueue的数量决定的,因为一个Queue只能被一个消费者线程消费(集群模式下)。
Tag: 标签,可以看作是子主题。它用于对同一个Topic下的消息进行更细粒度的分类。消费者可以只订阅其感兴趣的Tag。例如,在
OrderTopic下,我们可以为消息设置不同的Tag,如CreateOrder、PayOrder、CancelOrder。消费者可以只订阅PayOrder这个Tag,从而只处理支付成功的订单消息,过滤掉创建和取消的消息。关系: 一个
Topic包含多个MessageQueue。每条消息必须指定一个Topic,可以选择性地指定一个Tag。MessageQueue是Topic的物理分区,而Tag是Topic下的逻辑过滤。
核心比喻:图书馆与书籍
为了更好地理解,我们可以将一个 Topic 比喻成一家图书馆。
Topic(主题) = 图书馆
它代表一类信息的集合。比如,有一个专门收藏计算机类书籍的图书馆,叫“计算机图书馆”(
ComputerTopic)。
三者的定义与关系
1. Topic(主题) - “图书馆”
定义:消息的主题,它是消息的第一级分类,代表一系列业务逻辑相同的消息集合。
作用:生产者和消费者通过Topic来传递消息。生产者向某个Topic发送消息,消费者订阅某个Topic来接收消息。
比喻:图书馆。例如
OrderTopic(订单图书馆)、UserTopic(用户图书馆)。
2. MessageQueue(消息队列) - “图书馆里的书架”
定义:消息队列。一个Topic在物理上会被分成一个或多个MessageQueue。MessageQueue是消息存储和传输的实际载体。
作用:
实现并行处理/水平扩展:这是MessageQueue最重要的作用。因为一个MessageQueue在同一时刻只能被一个消费者线程消费。所以,如果一个Topic有4个MessageQueue,那么最多就可以有4个消费者线程同时消费这个Topic的消息。MessageQueue的数量决定了消息消费的并发度。
保证顺序性:对于需要顺序处理的消息(如同一个订单的创建、支付、发货),可以将它们发送到同一个MessageQueue中,从而保证它们被顺序消费。
比喻:图书馆里的书架。一个图书馆(Topic)会有很多个书架(MessageQueue)。新书(消息)来的时候,会分布放到不同的书架上。这样,多个读者(消费者)可以同时在不同的书架上找书,提高了效率。
3. Tag(标签) - “书架上书籍的标签(如编程语言、数据库)”
定义:标签,可以看作是子主题。它用于对同一个Topic下的消息进行更细粒度的分类。
作用:消息过滤。消费者可以只订阅其感兴趣的Tag。这样,Broker就只会把带有指定Tag的消息投递给该消费者,其他消息则会被过滤掉,减少了网络传输和消费端的压力。
比喻:书架上的书还可以按更细的类别贴标签,比如“Java区”、“Python区”、“数据库区”。一个读者可以径直走到“Java区”的书架前,只找Java相关的书,而忽略其他标签的书。
关系总结
它们的关系是:一个 Topic 包含多个 MessageQueue。每条消息必须指定一个 Topic,可以选择性地指定一个或多个 Tag。
一个具体的业务例子
场景:一个电商系统的订单流程。
创建Topic:我们创建一个名为
Order_Topic的Topic。设置MessageQueue:为了支持高并发,我们将
Order_Topic设置为4个MessageQueue。定义Tag:我们定义三种Tag:
CreateOrder:订单创建PayOrder:订单支付CancelOrder:订单取消
生产者发送消息:
订单服务在下单成功后,向
Order_Topic发送一条Tag为CreateOrder的消息。支付服务在支付成功后,向
Order_Topic发送一条Tag为PayOrder的消息。注意:生产者通常会使用一种策略(如订单ID取模)来决定将消息发送到4个MessageQueue中的哪一个,以保证同一个订单的消息进入同一个Queue。
消费者订阅消息:
库存服务:只关心订单创建,它订阅
Order_Topic, 并指定Tag为CreateOrder。这样它只会收到创建订单的消息,用于扣减库存。积分服务:只关心订单支付,它订阅
Order_Topic, 并指定Tag为PayOrder。这样它只会收到支付成功的消息,用于增加积分。通知服务:关心所有订单状态变化,它订阅
Order_Topic, 并指定Tag为*(星号代表订阅所有Tag)。
总结
Topic 是逻辑上的消息集合,用于区分不同的业务域。
MessageQueue 是物理上的分区,是并行和扩展的基本单位,也是保证顺序性的关键。
Tag 是过滤手段,用于在同一个业务域内进行细粒度订阅,提升效率。
理解这三者的关系,对于正确使用RocketMQ进行系统设计和性能优化至关重要。
第二部分:消息发送与消费
消息丢失场景及如何解决
消息丢失可能发生在消息从生产到消费的整个链路上。下面这个表格汇总了核心的风险点和应对策略,帮你快速抓住重点。
| 环节 | 主要丢失风险 | 核心解决方案 |
|---|---|---|
| 🚀 消息发送环节 | 网络抖动、Broker响应失败 | 同步发送 + 发送端重试机制 + 事务消息(金融级) |
| 💾 Broker存储环节 | 异步刷盘未落盘时宕机、磁盘损坏 | 同步刷盘 (SYNC_FLUSH) + 主从同步复制 (SYNC_MASTER) |
| 👨💻 消息消费环节 | 消费者返回成功过早,业务逻辑未执行完 | 业务处理完成后再返回CONSUME_SUCCESS,利用重试和死信队列 |
🚀 消息发送阶段
这个阶段的目标是确保消息 reliably 地从生产者到达Broker。
使用同步发送:避免使用单向(Oneway)发送,因为它不关心响应。务必使用
syncSend方法,并同步等待Broker返回发送结果。配置重试机制:生产者应设置合理的重试次数(如
retryTimesWhenSendFailed),在网络抖动等场景下自动重试。事务消息保障:对于资金、交易等不允许丢失的超高可靠性场景,应采用RocketMQ的事务消息机制。其核心流程是:
生产者先向Broker发送一条半消息(Half Message),它对消费者不可见。
半消息发送成功后,生产者执行本地事务。
根据本地事务结果,向Broker提交确认(Commit) 或回滚(Rollback),使消息正式可被消费或丢弃。
如果出现异常,Broker会回查生产者以确认事务状态。
💾 Broker存储阶段
这个阶段的目标是确保消息 reliably 地持久化到磁盘并具备容灾能力。
开启同步刷盘:Broker默认使用异步刷盘以提升性能,消息先写入OS缓存,异步写入磁盘。若此时Broker宕机,内存中的消息会丢失。通过设置
flushDiskType = SYNC_FLUSH,Broker会在消息真正写入磁盘后再向生产者返回成功,保证持久化。配置主从同步复制:即使消息已刷盘,若单机磁盘损坏,消息仍会丢失。采用主从架构(Master-Slave)并将主节点的角色设置为
brokerRole = SYNC_MASTER,这样一条消息只有在被主节点和从节点都成功持久化后,才被认为发送成功。这通常与同步刷盘结合,构成最可靠的配置。
👨💻 消息消费阶段
这个阶段的目标是确保消息 reliably 地被消费者处理完毕。
正确的消费确认:消费者应在业务逻辑完全执行成功后,再返回
ConsumeConcurrentlyStatus.CONSUME_SUCCESS。RocketMQ默认采用 at least once 的投递语义,只要未返回成功,Broker会认为消息消费失败,并按延迟级别进行重投。避免异步消费陷阱:切勿在监听器中开启新线程异步处理消息,却立即返回
CONSUME_SUCCESS。这会导致消息看似消费成功,实际业务逻辑可能失败。利用重试和死信队列:如果消费失败返回
RECONSUME_LATER,消息会进入重试队列。超过最大重试次数(默认16次)后,消息会转入死信队列(Dead-Letter Queue),供后续人工处理或系统补偿,为消息提供了最后的保障。
🛠️ 额外保障与监控
服务降级方案:当整个RocketMQ集群完全不可用时,应有降级策略。例如,将消息临时存储到数据库、Redis或本地文件中,待MQ恢复后再重新发送。
开启消息轨迹:通过配置
traceTopicEnable=true来开启消息轨迹追踪功能,可以清晰地了解每条消息的生命周期,便于排查问题。
⚖️ 可靠性与性能的权衡
至关重要的一点是,更高的可靠性通常意味着性能的牺牲。同步刷盘和同步复制的吞吐量会低于其异步模式。你需要根据业务场景(例如,是日志处理还是支付交易)在对消息零丢失的要求和系统吞吐量之间做出权衡。
4. 问题: RocketMQ支持哪几种消息发送方式?请分别说明它们的适用场景。
考察点: 对消息可靠性级别的掌握。
优秀回答:
主要支持三种方式:
同步发送: 生产者发送消息后,会阻塞等待Broker返回发送结果。这种方式可靠性最高,但吞吐量最低。适用于重要通知、短信发送等不允许丢失的场景。
异步发送: 生产者发送消息后,不阻塞等待,而是通过回调函数接收Broker的返回结果。这种方式在保证可靠性的同时,具有较高的吞吐量。适用于链路耗时较长、对RT响应敏感的业务场景。
单向发送: 生产者只负责发送消息,不等待也不关心发送结果。可靠性最低,但吞吐量最高。适用于日志收集等允许少量丢失的非核心业务。
三种消息发送方式总览
| 发送方式 | 可靠性 | 吞吐量 | 响应时间(RT) | 核心过程 |
|---|---|---|---|---|
| 同步发送 | 最高 | 最低 | 最长 | 发送 → 等待Broker响应 → 收到ACK后继续 |
| 异步发送 | 高 | 高 | 短 | 发送 → 立即继续 → Broker响应后执行回调 |
| 单向发送 | 低 | 最高 | 最短 | 发送 → 立即继续(不关心结果) |
下面我们详细解释每一种方式及其适用场景。
1. 同步发送
工作流程:
生产者发送一条消息到Broker。
生产者线程会阻塞等待,直到收到Broker返回的发送结果(SendResult)。
根据结果判断成功与否,如果失败或超时,会根据配置的重试次数进行重试。
代码示例感观:
SendResult sendResult = producer.send(message); // 执行到这里时,消息已经成功发送到Broker了(或重试后失败) System.out.println("消息ID: " + sendResult.getMsgId());适用场景:
重要通知场景:如短信验证码发送、订单创建成功通知。这类场景要求消息绝对不能丢失,需要立即知道发送结果,如果失败可以快速重试或告警。
强依赖流程:后续业务逻辑必须依赖于消息发送成功后才能执行。例如,下单后需要先成功发出“订单创建”消息,然后才能给用户返回成功响应。
优点:可靠性最高,能够确保消息成功送达Broker。
缺点:性能较差,吞吐量低,因为每次发送都有网络往返的延迟(RTT)。
2. 异步发送
工作流程:
生产者发送一条消息到Broker。
发送后,线程不会阻塞等待,而是立即返回,继续执行后续代码。
当Broker将结果(成功或失败)返回给生产者时,会异步地触发一个回调函数,在回调函数中处理发送结果。
代码示例感观:
producer.send(message, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {// 消息发送成功后的处理逻辑System.out.println("异步发送成功: " + sendResult.getMsgId());}@Overridepublic void onException(Throwable e) {// 消息发送失败后的处理逻辑,如记录日志、告警、重试等System.err.println("异步发送失败: " + e.getMessage());} }); // 这行代码会立即执行,不会等待消息发送完成 System.out.println("主线程继续执行...");适用场景:
高并发、链路耗时的场景:如用户行为追踪数据上报、日志记录。业务对实时响应要求高,但消息发送本身可以稍有延迟。
削峰填谷的入口:在秒杀等瞬时高并发场景中,使用异步发送可以快速地将请求接入系统,避免同步等待造成的线程阻塞,从而极大地提升系统的吞吐能力和响应速度。
优点:在保证可靠性的前提下(通过回调处理失败),拥有很高的吞吐量。
缺点:编程模型比同步发送复杂,需要处理好回调逻辑。
3. 单向发送
工作流程:
生产者发送一条消息到Broker。
发送后,不等待Broker的响应,也不提供回调函数。就像“发射后不管”。
它只管发送,完全不关心消息是否成功到达Broker。
代码示例感观:
producer.sendOneway(message); // 这行代码会立即执行,完全不知道消息发送结果 System.out.println("单向发送调用完成。");适用场景:
日志收集:收集应用运行日志,允许有少量消息丢失,但要求极致的性能。
监控数据上报:上报系统的CPU、内存等指标,丢失个别数据点对整体监控趋势影响不大。
非核心业务:一些非常不重要的消息,比如操作日志记录,即使丢失也无关紧要。
优点:性能极致,吞吐量最高。
缺点:可靠性最低,无法保证消息不丢失。
总结与选择建议
| 场景特征 | 推荐方式 |
|---|---|
| 必须确保消息成功,且愿意等待结果 | 同步发送 |
| 希望高吞吐,但又不能接受大量消息丢失 | 异步发送 |
| 追求极致性能,可容忍少量消息丢失 | 单向发送 |
简单决策树:
这个消息必须成功吗?
是 -> 进入第2步。
否 -> 使用单向发送。
发送消息的等待时间会影响主业务流程的响应速度吗?
会(或对吞吐量要求高)-> 使用异步发送。
不会 -> 使用同步发送。
在实际项目中,异步发送是用得最多的一种方式,因为它很好地平衡了可靠性和性能。
下表总结了三种发送方式的失败处理特点:
| 发送方式 | 重试机制 | 重试对象 | 可靠性 | 适用场景 |
|---|---|---|---|---|
| 同步发送 | 自动重试(默认3次),跨Broker重试,支持存储失败后重试 | 优先选择不同的Broker | 最高 | 重要通知、订单创建等要求高可靠性的场景 |
| 异步发送 | 自动重试(默认同一Broker),在回调中触发 | 默认同一Broker | 高 | 高吞吐场景,如日志收集、用户行为跟踪 |
| 单向发送 | 无重试 | 不适用 | 最低 | 极高性能要求,可容忍少量消息丢失的场景,如日志上报 |
⚠️ 重要提示
重试可能导致消息重复:任何重试机制都可能带来消息重复的风险。例如,网络超时后生产者发起重试,但之前发送的消息可能已被Broker成功处理。因此,消费者端必须实现消息的幂等性处理。
业务层兜底必不可少:即使同步发送重试多次后仍然失败,客户端会抛出异常。对于绝对不允许丢失的消息,业务方应在捕获异常后,有自己的兜底方案,例如将消息持久化到数据库,然后由定时任务扫描并进行补偿发送。
5. 问题: 解释一下RocketMQ的消费者是如何工作的?Push模式和Pull模式有什么区别?
考察点: 对消费模型底层机制的理解。
优秀回答:
RocketMQ的消费者在底层是基于长轮询的Pull模式。
Pull模式: 由消费者主动向Broker发起拉取请求。优点是主动权在消费者,可以根据自己的消费能力控制速率;缺点是间隔时间不好控制,太短可能造成忙等,太长可能导致消息延迟。
Push模式: RocketMQ的Push模式是一种伪Push,它封装了Pull模式,在消费者端有一个后台线程
PullMessageService不断地进行长轮询。当有新消息到达或等待超时后,它会立即再次发起拉取请求,从而在用户感知上实现了类似“推送”的效果。它结合了Pull的优点和Push的实时性。所以,简单来说,RocketMQ的消费方式是基于长轮询的Pull模型,其提供的Push API是对这个模型的封装,以简化使用并保证实时性。
核心结论:一个常见的误解
首先,必须澄清一个关键点:RocketMQ的消费者在底层是基于Pull(拉取)模式的。其提供的Push API是一种“伪Push”,是对Pull模式的封装和优化,以实现类似Push的实时性。
下面我们通过分析源码的工作流程来深入理解。
🔍 RocketMQ消费者是如何工作的?(源码流程分析)
消费者的工作核心由一个后台线程服务 PullMessageService 驱动。其工作流程如下图所示,它完美地展示了“长轮询”机制如何将基础的Pull模式优化为实时的“Push”效果:
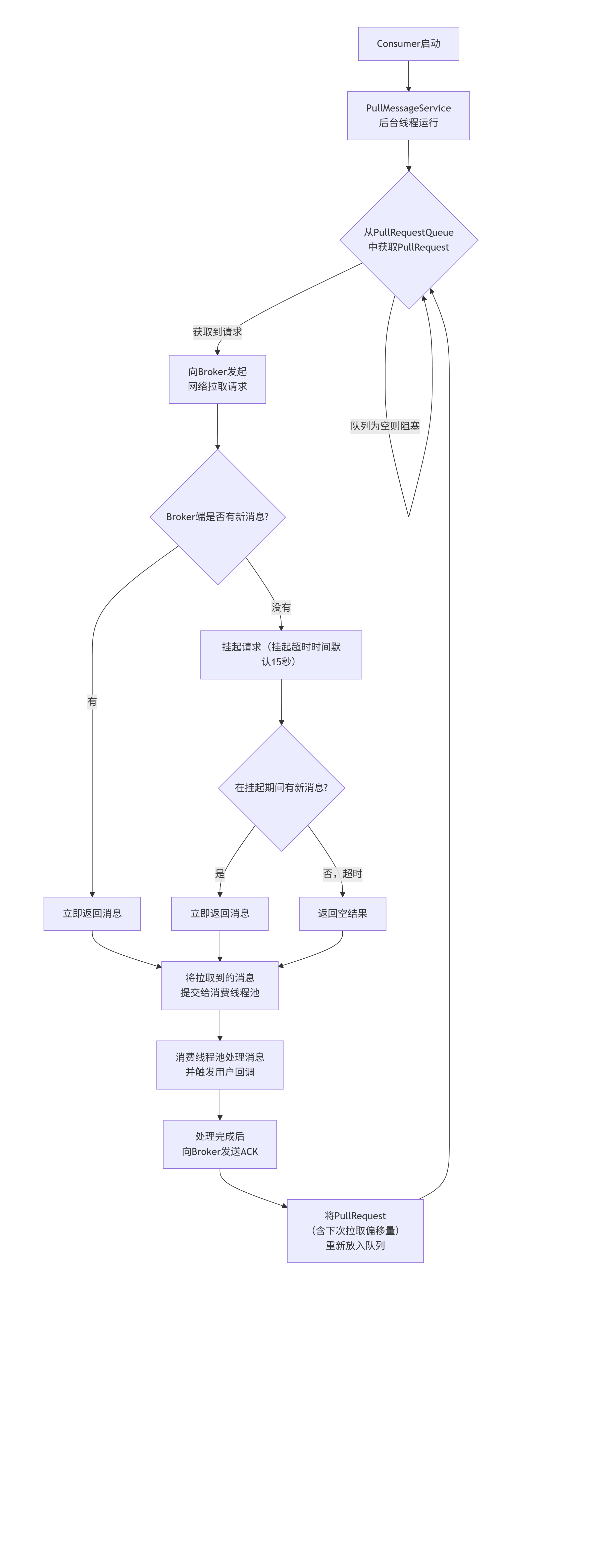
下面我们来分解图中的关键步骤:
初始化与订阅:
消费者启动时,会为每个分配到的
MessageQueue创建一个PullRequest对象。这个对象包含了下次要从哪个位置(offset)开始拉取消息。这些
PullRequest会被放入一个阻塞队列PullRequestQueue中。
核心拉取循环:
PullMessageService是一个独立的后台线程,它的run()方法会不停地从PullRequestQueue中取出PullRequest。如果队列为空,线程就会阻塞,避免空转消耗CPU。
与Broker的交互 - “长轮询”:
拿到
PullRequest后,服务会通过网络向对应的Broker发起拉取请求。这里就是“伪Push”的魔法所在: Broker端如果发现有新消息,会立即返回。但如果当时没有新消息,Broker不会立即返回空结果,而是会将这个请求挂起一段时间(默认15秒,由
brokerSuspendMaxTimeMillis参数控制)。在这段挂起时间内,只要有任何新消息到达该队列,Broker会立即唤醒挂起的请求并返回消息。
如果挂起超时后依然没有新消息,Broker才返回一个空结果。
回调与流控:
拉取到消息(无论是立即返回还是挂起后返回)后,
PullMessageService并不会直接处理消息,而是将消息提交给一个消费线程池。消费线程池中的线程会执行
MessageListener(消息监听器)中用户编写的业务代码,从而完成消费逻辑。这里有一个重要的流控保护:消费线程池有一个队列(
ConsumeMessageQueue),如果线程池已满(说明消费者消费能力跟不上),PullMessageService会暂停拉取消息(默认延迟1毫秒再将PullRequest放回队列),防止消息在客户端过度堆积。
偏移量管理与下一次拉取:
无论消费成功与否,在处理完一批消息后,系统都会生成一个新的
PullRequest(其中包含更新了的拉取偏移量nextBeginOffset)并放回PullRequestQueue中,等待PullMessageService下一次拉取,从而形成一个循环。
⚖️ Push模式 vs. Pull模式(本质区别)
现在,我们可以清晰地对比这两种模式了。这里的“Pull模式”指的是用户自己控制循环的原始Pull,而“Push模式”指的是RocketMQ封装后的“伪Push”API。
| 特性 | 原始Pull模式 | RocketMQ的“Push”模式 |
|---|---|---|
| 控制权 | 消费者主动控制。消费者需要自己实现一个循环,定时向Broker拉取消息。 | RocketMQ客户端SDK控制。SDK内部封装了拉取循环,对用户透明。 |
| 实时性 | 差。取决于拉取间隔。间隔太短会导致大量无效请求(忙等);间隔太长会导致消息消费延迟。 | 高。基于长轮询,消息到达后能立即被推送(实际上是立即返回给拉取请求),延迟极低。 |
| 复杂度 | 高。用户需要自己管理拉取间隔、异常处理、负载均衡等,非常复杂。 | 低。用户只需注册一个监听器(Listener)处理业务逻辑即可,简单易用。 |
| 负载适应性 | 灵活但需手动调整。消费者可以根据自身处理能力动态调整拉取频率。 | 自动流控。当消费线程池打满时,会自动暂停拉取,起到背压(Backpressure)作用,保护消费者。 |
| RocketMQ中的体现 | 提供 pull() API,但一般不建议直接使用。 | 提供 registerMessageListener() API,是最常用、推荐的方式。 |
💎 总结
工作方式:RocketMQ消费者通过一个后台的
PullMessageService线程,不断地从Broker拉取(Pull) 消息,并交给消费线程池处理,形成一个自动化循环。“Push”的本质:RocketMQ的Push模式是基于长轮询机制的、对用户友好的高级API封装。它通过Broker端挂起请求的方式,结合了Pull模式的可靠性与Push模式的实时性,避免了各自的缺点。
如何选择:在99%的场景下,你都应该使用RocketMQ提供的 “Push”模式,因为它既简单又高效。只有在需要极其特殊的、自定义拉取策略时,才考虑使用底层的Pull API。
所以,当被问到RocketMQ的消费模式时,一个精彩的回答是:“它底层是Pull模式,但通过长轮询优化后,对外提供了表现如同Push模式的API,兼顾了实时性和可靠性。”
6. 问题: 什么是顺序消息?RocketMQ如何保证消息的顺序性?
考察点: 对顺序消息实现原理的理解。
优秀回答:
顺序消息 指的是消费者按照消息发送的顺序进行消费。例如,一个订单的创建、付款、发货这三个消息必须按顺序处理。
保证机制:
全局顺序: 要求一个Topic下所有消息严格有序。这种场景下,需要将Topic的MessageQueue数量设置为1,这样所有消息都进入一个队列,由一个消费者单线程处理。这会严重牺牲性能,一般很少使用。
分区顺序: 更常用的方式。保证同一组关键消息(如同一个订单ID)按顺序消费。实现方法是:生产者使用MessageQueueSelector,将同一组消息(如同一个订单ID)总是发送到同一个MessageQueue中;消费者则通过“顺序消费”模式(
MessageListenerOrderly)来消费这个Queue,这个监听器会锁定当前队列,保证同一时刻只有一个线程消费该队列,从而保证了顺序。
RocketMQ保证顺序性的核心原理是:将需要保证顺序的一组消息,通过特定的策略,总是发送到同一个消息队列中,然后由单个消费者线程串行地消费这个队列。
下面我们通过图解和源码层面的分析来详细说明这一过程。
核心原理图解
整个顺序消息的保证机制涉及生产者和消费者的协同工作,其流程如下图所示:
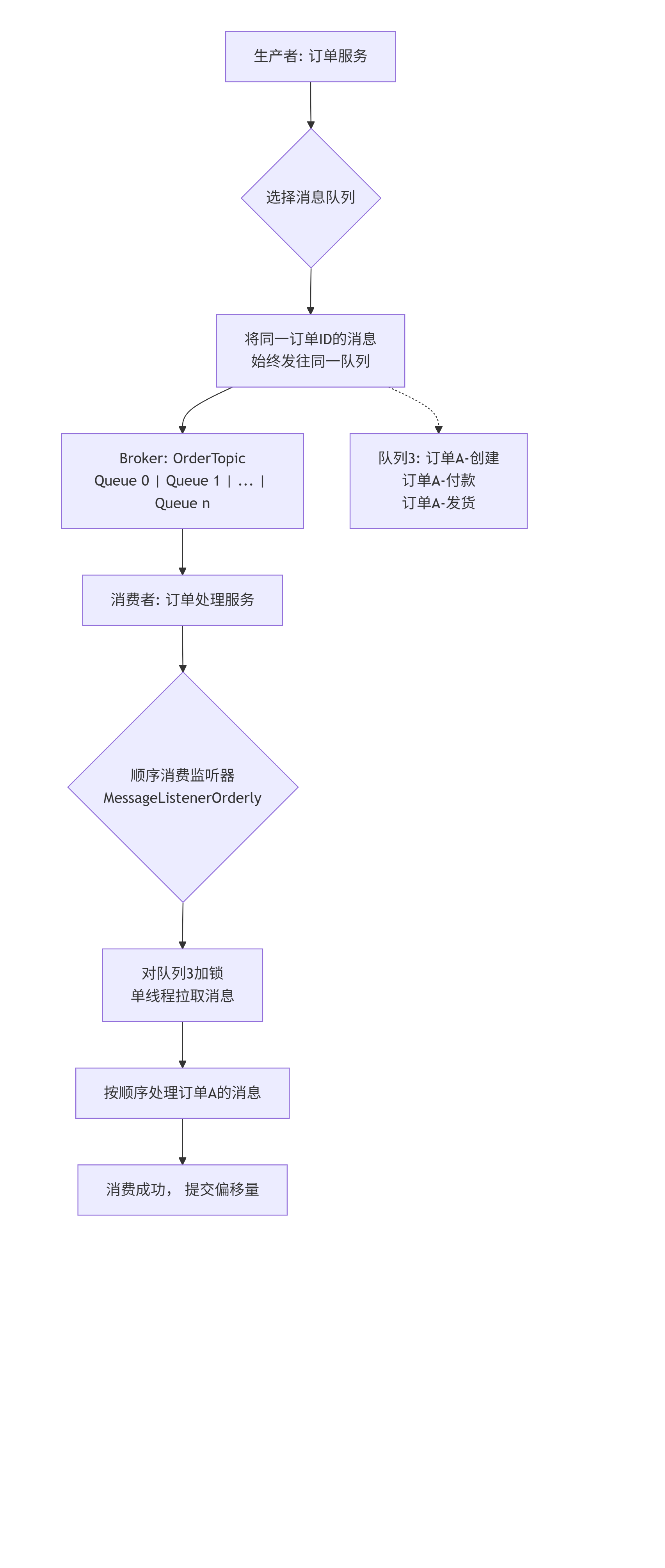
1. 生产者端:保证局部有序发送
顺序消息的前提是,需要保证顺序的一组消息必须被发送到同一个MessageQueue中。因为RocketMQ只保证在一个队列内部消息是先进先出的。
如何实现?
生产者发送消息时,不能使用默认的轮询策略,而必须使用一个自定义的MessageQueueSelector来选择队列。源码示例与分析:
// 关键代码:使用MessageQueueSelector确保同一业务ID的消息进入同一队列 SendResult sendResult = producer.send(message, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {// arg 就是用于区分消息组的标识,比如订单IDString orderId = (String) arg;// 使用订单ID的哈希值对队列列表大小取模,确定目标队列int index = Math.abs(orderId.hashCode()) % mqs.size();// 返回选中的队列。只要orderId相同,计算出的index就相同,从而选中同一个队列。return mqs.get(index);} }, orderId); // 将订单ID作为参数传入原理:通过一个固定的算法(如对订单ID取哈希再取模),使得同一个订单ID的消息总是被计算到同一个队列索引上。这样就保证了“同一订单”的消息在Broker端被存储在同一个队列里,天然有序。
2. 消费者端:保证顺序消费
即使消息在Broker端是有序的,如果消费者端并行消费,多个线程同时处理一个队列的消息,顺序依然会乱。因此,消费者端必须串行消费。
如何实现?
消费者不能使用并发监听器MessageListenerConcurrently,而必须注册顺序监听器MessageListenerOrderly。源码机制分析:
MessageListenerOrderly的核心工作原理如下:队列加锁:在消费开始时,RocketMQ客户端会尝试对当前要消费的
MessageQueue进行加锁(通过向Broker发送请求)。这可以防止在集群模式下,同一个消费者组内的其他消费者实例同时消费这个队列。串行拉取:对于同一个队列,
Orderly监听器会确保在前一批消息消费完成(即监听器方法返回)后,才去拉取下一批消息。它通过一个ProcessQueue对象来维护每个队列的消费状态。自动提交偏移量:顺序消费模式下,消息消费成功的偏移量不是每条提交,而是在一批消息处理成功后统一提交。这保证了如果中间某条消息消费失败,整个批次会重试。
同步处理:在
ConsumeMessageOrderlyService中,每个MessageQueue都有一个专用的线程,它通过一个while循环不断地、串行地处理该队列的消息。
consumer.registerMessageListener(new MessageListenerOrderly() {@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {// 这个方法是串行调用的,对于同一个队列,前一条消息处理完才会处理下一条。for (MessageExt msg : msgs) {String orderId = msg.getKeys(); // 获取订单ID// 处理业务逻辑...}// 返回成功,然后才会处理下一批消息return ConsumeOrderlyStatus.SUCCESS;} });
3. 消费失败的重试机制
对于顺序消息,消费失败时的重试行为非常关键:
MessageListenerOrderly的重试:当消费失败时,它不会立即将消息发送到重试主题,而是暂停当前队列的消费,并在后台进行本地重试(默认重试次数为Integer.MAX_VALUE)。为什么会暂停? 因为要保证顺序。如果第N条消息失败,而第N+1条消息被成功消费了,那么顺序就破坏了。因此,顺序消费在遇到失败时会“阻塞”在该消息上,直到:
消费成功。
或者人工干预(如停止消费者)。
💡 全局顺序消息
除了上述常用的分区顺序,RocketMQ还支持全局顺序,即整个Topic下的所有消息严格有序。
实现方式:将Topic的MessageQueue数量设置为1。这样所有消息都进入一个队列,生产者和消费者都单线程操作。
缺点:严重牺牲了扩展性和性能, parallelism(并行度)为1。除非极端场景,否则不推荐使用。
💎 总结与最佳实践
| 特性 | 分区顺序消息 | 全局顺序消息 |
|---|---|---|
| 实现方式 | 1. 生产者用 MessageQueueSelector 将同一组消息发往同一队列。2. 消费者用 MessageListenerOrderly 串行消费该队列。 | 1. Topic只设置1个MessageQueue。 2. 生产消费均为单线程。 |
| 性能 | 高,充分利用了多个队列的并行能力。 | 极低,无并行度。 |
| 适用场景 | 绝大部分需要顺序的场景,如:同一订单、同一会话、同一用户等。 | 性能要求不高,但全局顺序性至关重要的场景,如:数据库Binlog同步。 |
最佳实践:
关键:确保顺序的业务ID(如订单ID)选择正确,并且生产者的选择算法分布均匀,避免数据倾斜导致某些队列压力过大。
消费逻辑:顺序消费的业务逻辑要尽可能高效,避免长时间阻塞,因为会直接影响该队列的吞吐量。
监控:密切监控顺序消息Topic的堆积情况,因为一旦某个队列的消息消费被阻塞(如某条消息一直处理失败),整个队列的消费都会停滞。
理解顺序消息的实现机制,对于设计依赖消息顺序的分布式系统至关重要。
7. 问题: 什么是事务消息?描述一下RocketMQ事务消息的半消息流程。
考察点: 对分布式事务解决方案的理解。
优秀回答:
事务消息 用于解决分布式事务问题,保证本地事务执行和消息发送的原子性。
半消息流程:
发送半消息: 生产者向Broker发送一条“半消息”,这条消息对消费者是不可见的。
执行本地事务: 生产者执行本地数据库事务。
提交/回滚:
如果本地事务成功,生产者向Broker发送
commit指令,半消息变为正式消息,对消费者可见。如果本地事务失败,生产者发送
rollback指令,Broker会丢弃这条半消息。
回查机制: 如果生产者执行完本地事务后,由于网络闪断、应用重启等原因,没有向Broker发送commit或rollback指令,Broker会定时向生产者发起事务状态回查。生产者根据回查结果决定提交或回滚消息。这是保证数据最终一致性的关键。
什么是事务消息?
事务消息 是一种特殊的消息类型,用于确保本地事务执行与消息发送这两个分布式操作的原子性。换句话说,它要保证:本地事务成功完成时,消息一定能被消费;本地事务失败时,消息一定不会被消费。
经典业务场景: 银行转账
A账户扣款100元(本地数据库事务)
发送一条"B账户应加款100元"的消息到消息队列
如果没有事务消息,可能会出现:
先扣款成功,但消息发送失败 → A的钱扣了,B没收到,数据不一致
先发送消息成功,但扣款失败 → B的钱加了,A没扣款,数据不一致
事务消息就是为了解决这类问题而设计的。
RocketMQ事务消息的"半消息"流程
RocketMQ通过"两阶段提交"和"事务状态回查"机制来实现事务消息。其核心流程如下图所示,它清晰地展示了事务消息的完整生命周期:
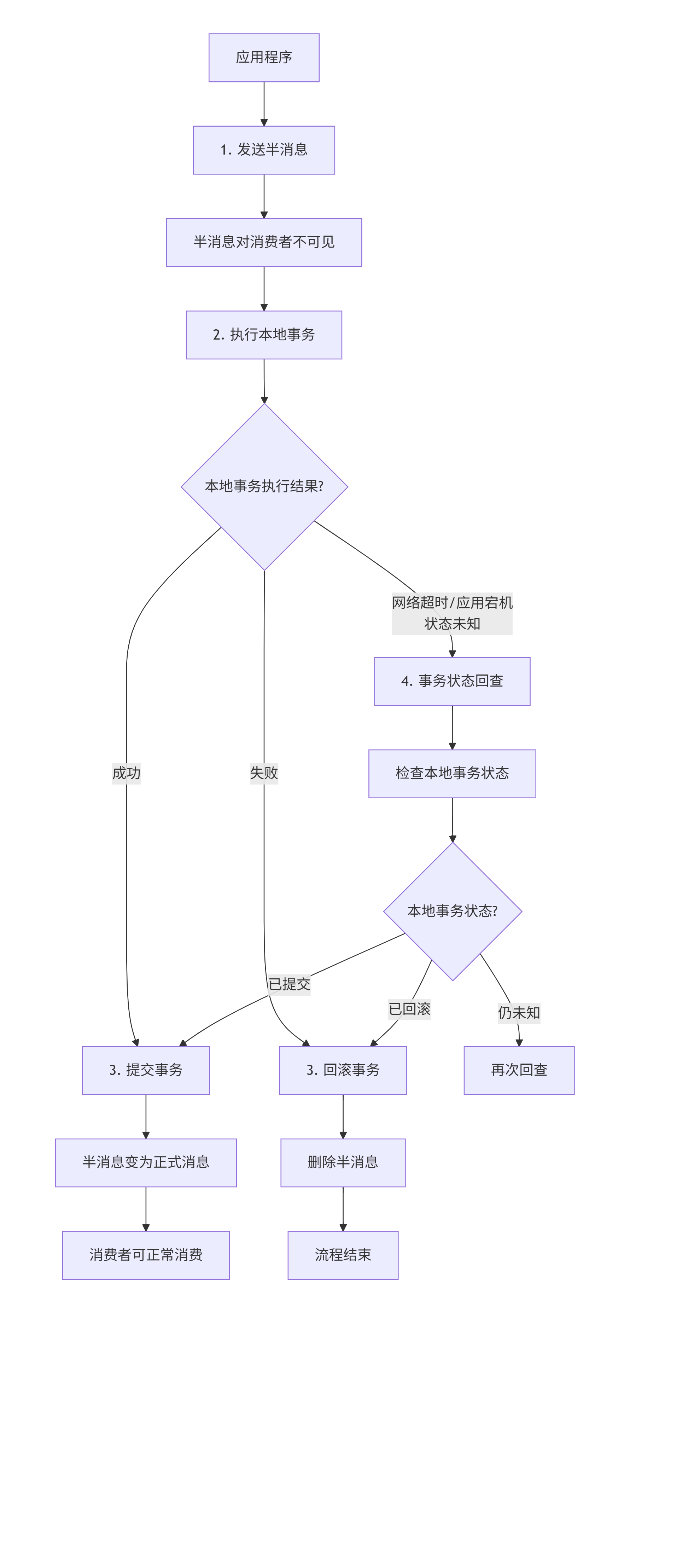
下面我们来详细解析图中的每一个步骤:
第1阶段:发送半消息(Prepare Message)
发送半消息:应用程序(生产者)首先向RocketMQ Broker发送一条半消息(Half Message),也称作"预处理消息"。
特殊属性:这条半消息与普通消息的唯一区别是:它对消费者是不可见的。消费者无法拉取到这条消息。这样设计的目的是:在本地事务执行结果明确之前,防止消息被错误地消费。
第2阶段:执行本地事务
执行本地事务:半消息发送成功后,生产者开始执行本地事务(例如:扣减A账户的余额)。
提交或回滚:根据本地事务的执行结果,生产者向Broker发送二次确认(Commit或Rollback):
本地事务成功 → 发送 Commit 指令。
本地事务失败 → 发送 Rollback 指令。
第3阶段:Broker处理二次确认
Broker处理确认:
收到 Commit:Broker会将半消息标记为"可投递"状态(Deferred),这条消息立刻对消费者可见。
收到 Rollback:Broker会直接删除半消息,流程结束。
🔁 核心保障机制:事务状态回查
上面描述的流程在理想情况下能正常工作。但在分布式环境中,网络闪断、生产者应用重启等故障随时可能发生。考虑这个场景:
生产者执行完本地事务后,在发送Commit/Rollback指令之前突然宕机了。此时,Broker上有一条"悬而未决"的半消息,不知道该如何处理。
为了解决这个问题,RocketMQ引入了事务状态回查机制。
定时回查:Broker会定时扫描处于"半消息"状态已久(默认1分钟)的消息。
发起回查:对于这些消息,Broker会回调生产者提供一个检查本地事务状态的接口。
决定消息命运:生产者收到回查请求后,需要检查本地事务(如查询数据库)的最终状态,并返回Commit或Rollback指令。
回查机制是保证数据最终一致性的关键,它确保了即使生产者出现故障,事务消息也能得到正确的处理。
💻 代码实现概览
要实现事务消息,生产者需要实现 TransactionListener 接口:
// 创建事务生产者
TransactionMQProducer producer = new TransactionMQProducer("transaction_producer_group");// 设置事务监听器
producer.setTransactionListener(new TransactionListener() {/*** 执行本地事务* @param msg 发送的半消息* @param arg 自定义参数* @return 本地事务状态*/@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {// 1. 执行本地事务(如数据库操作)try {boolean success = doLocalTransaction(arg); // 你的业务逻辑if (success) {return LocalTransactionState.COMMIT_MESSAGE; // 本地事务成功,提交消息} else {return LocalTransactionState.ROLLBACK_MESSAGE; // 本地事务失败,回滚消息}} catch (Exception e) {// 返回UNKNOW,触发后续的事务状态回查return LocalTransactionState.UNKNOW;}}/*** 事务状态回查* @param msg 需要回查的半消息* @return 本地事务状态*/@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {// 根据消息内容(如订单ID)去检查本地事务的真实状态String orderId = msg.getKeys();// 查询数据库,判断该订单的本地事务是否已成功boolean isSuccess = checkTransactionStatus(orderId);if (isSuccess) {return LocalTransactionState.COMMIT_MESSAGE;} else {return LocalTransactionState.ROLLBACK_MESSAGE;}}
});// 发送事务消息
SendResult sendResult = producer.sendMessageInTransaction(message, null);💎 总结与关键点
| 环节 | 关键动作 | 目的 |
|---|---|---|
| 第一阶段发送 | 发送半消息(对消费者不可见) | 探路,确保Broker可用,同时避免消息提前暴露。 |
| 第二阶段执行 | 执行本地事务并返回状态 | 完成核心业务操作。 |
| 第二阶段确认 | 根据本地事务结果发送Commit/Rollback | 让Broker决定消息的最终命运。 |
| 兜底机制 | 事务状态回查 | 解决因网络、宕机导致的"悬而未决"的消息状态,保证最终一致性。 |
重要提示:
幂等性:消费者端必须实现幂等消费。因为网络超时等原因,生产者可能重试发送Commit指令,导致消息被多次投递。
回查逻辑:
checkLocalTransaction方法的实现必须非常可靠,通常需要根据消息中的关键业务ID(如订单号)查询数据库来确定事务的最终状态。
事务消息是RocketMQ提供的一个非常强大的功能,它虽然不是强一致的(属于最终一致性),但在大多数业务场景下,能够以较低的复杂度较好地解决分布式事务问题。
第三部分:高可用与可靠性
8. 问题: RocketMQ的Broker是如何保证高可用的?请解释主从复制模式。
考察点: 对消息存储高可用架构的理解。
优秀回答:
RocketMQ通过主从架构 来保证高可用。一个Broker角色可以是Master或Slave。
主从复制:
异步复制: Master收到消息后,先写入本地,然后异步地将数据复制给Slave。性能好,但极端情况下(Master磁盘损坏)可能会有少量消息丢失。
同步双写: Master收到消息后,必须等待Slave也写入成功后才返回成功给生产者。数据可靠性极高,但性能会有下降。
故障转移:
当Master宕机后,消费者可以从Slave节点读取消息(因为Slave有消息备份),保证了服务的可用性。但Slave默认不允许写入,所以生产者无法向该组Broker发送消息,直到有新的Master被选举出来(需要Dledger等工具支持自动选主)。
核心高可用架构:主从模式
RocketMQ的Broker采用经典的"一主多从"架构。一个Broker组(Broker Group)包含一个Master节点和至少一个Slave节点。
Master(主节点):负责处理所有的写请求(生产者发送消息)和读请求(消费者拉取消息)。它是消息流的首要入口。
Slave(从节点):作为Master的热备份,其核心职责是从Master同步消息数据。平时主要分担读请求(消费者拉取消息),在某些配置下也可以处理写请求。
这种架构的高可用性体现在以下两个核心机制中,其协同工作原理如下图所示:
机制一:数据同步(复制模式)
这是保证数据可靠性的核心。Slave节点需要实时或近实时地从Master节点复制数据。RocketMQ提供了两种复制策略:
1. 异步复制
工作流程:
Master收到生产者发送的消息后,将其写入本地存储(CommitLog)。
写入成功后,立即返回"发送成功"的ACK信号给生产者。
之后,Master再异步地将消息数据复制给Slave节点。
优点:
性能极高,延迟低。因为生产者不需要等待跨节点的网络同步。
缺点:
有极小的数据丢失风险。如果Master在返回成功ACK后、但数据尚未复制到Slave时发生宕机且磁盘损坏,这条消息就会永久丢失。
适用场景:追求高性能,能够容忍在极端情况下毫秒级数据丢失的业务,如日志收集、监控数据上报等。
2. 同步复制
工作流程:
Master收到生产者发送的消息后,将其写入本地存储。
写入成功后,Master立即将消息同步给Slave节点。
必须等待Slave也成功写入并返回确认后,Master才向生产者返回"发送成功"的ACK信号。
优点:
数据可靠性极高。只要有一个Slave存活,数据就不会丢失,因为数据在多个节点上都存在。
缺点:
性能较低,延迟更高。因为每次写入都增加了跨节点网络的往返时间(RTT)。
适用场景:对数据可靠性要求极高的金融、交易等核心业务场景。
配置建议:通常在生产环境中,Master会配置为同步刷盘+同步复制,以达到最高的数据可靠性(即使机器掉电、宕机,消息也不会丢失)。而Slave则配置为异步刷盘,以平衡性能。
机制二:故障转移
这是保证服务可用性的核心。当Master节点宕机后,系统需要一种机制来保证服务可以继续。
1. 消费者的故障转移
默认行为:在Master正常时,消费者默认从Master拉取消息。
故障发生:当NameServer检测到Master宕机(心跳超时)后,会将最新的路由信息通知给消费者。
自动切换:消费者收到路由更新后,会自动切换到对应的Slave节点进行消息拉取。
重要限制:Slave节点默认只提供读服务。消费者可以从Slave正常消费已同步的消息,保证了业务的连续性。
2. 生产者的故障转移
故障发生:当生产者尝试向已宕机的Master发送消息时,会收到失败响应。
自动重试:生产者客户端内置了重试机制。在发送失败后,它会从NameServer重新拉取路由信息,发现Master宕机后,会自动尝试向该Broker组下的另一个Broker(通常是Slave)发送消息。
关键点:Slave能否接收写请求,取决于Broker的配置。早期版本Slave不能写,但在一些较新的版本或通过Dledger模式,可以实现自动选主,让Slave升级为新的Master来接收写请求。
进阶高可用方案:Dledger模式
上述传统主从模式有一个短板:当Master宕机后,需要人工干预将Slave升级为新的Master,无法实现自动故障转移,会有一段不可写的时间。
为了解决这个问题,RocketMQ引入了基于Raft协议的 Dledger 技术。
工作原理:
一个Dledger组由多个节点(通常为3个)组成,它们之间通过Raft协议进行选举和数据同步。
只有一个节点是Leader(即Master),其他节点是Follower(即Slave)。
所有写请求都必须发给Leader,Leader会同步数据给超过半数的Follower后才确认成功。
当Leader宕机后,剩余的Follower节点会自动触发选举,在秒级内选出新的Leader,并通知NameServer更新路由。
核心优势:
强一致性:数据在多数节点上成功才算成功,可靠性极高。
自动故障转移:Master宕机后无需人工干预,自动选举新Master,同时支持读写,真正实现高可用。
💎 总结
| 特性 | 传统主从模式 | Dledger模式(推荐) |
|---|---|---|
| 数据同步 | 异步复制(性能好) / 同步复制(可靠性高) | 基于Raft的强一致性同步 |
| Master故障后 | 消费者:可自动切换到Slave读。 生产者:无法向该组写消息,除非人工干预。 | 自动选举新Master,生产者和消费者均可快速切换到新Master,读写不受影响。 |
| 优点 | 架构简单,易于理解。异步复制模式下性能出色。 | 真正的全自动高可用,同时保证了数据强一致性和服务连续性。 |
| 缺点 | 故障转移需要人工介入,无法实现"故障自愈"。 | 性能有一定损耗(因Raft协议),部署至少需要3个节点。 |
结论:RocketMQ Broker通过主从复制保障数据可靠性,通过客户端路由切换保障服务可用性。对于要求完全自动化的高可用场景,推荐使用Dledger模式,它解决了传统主从模式需要人工干预的痛点,是生产环境搭建高可用RocketMQ集群的首选方案。
9. 问题: 消息存储在RocketMQ中是如何实现的?说说CommitLog和ConsumeQueue的作用。
考察点: 对消息存储核心机制的深入理解。
优秀回答:
RocketMQ使用了单一、顺序写的CommitLog文件来存储所有消息,这是一种非常高效的磁盘IO方式。
CommitLog: 是所有消息内容的实体存储文件。所有Topic的消息都按照到达的顺序追加写入到同一个CommitLog文件中。这种设计最大限度地利用了磁盘的顺序写性能。
ConsumeQueue: 是消息的逻辑队列索引文件。每个Topic下的每个MessageQueue都对应一个ConsumeQueue文件。它不存储消息内容,只存储消息在CommitLog中的偏移量(offset)、大小(size)和消息Tag的哈希码。消费者实际上是先读取ConsumeQueue找到消息的索引,然后再根据索引去CommitLog中获取完整的消息内容。
这种设计的好处是: 将物理存储(CommitLog)和逻辑消费(ConsumeQueue)分离,既保证了写入的高性能,又方便了不同Queue的消费和查找。
10. 问题: 消息刷盘有哪两种方式?它们各自的优缺点是什么?
考察点: 对消息持久化可靠性和性能权衡的理解。
优秀回答:
同步刷盘: Broker收到消息后,必须将消息写入磁盘后才返回成功ACK给生产者。可靠性最高,即使机器掉电,消息也不会丢失。缺点是性能较低,因为受限于磁盘IO速度。
异步刷盘: Broker收到消息后,先写入OS的Page Cache就返回成功,然后由一个后台线程定期将Page Cache中的数据刷入磁盘。性能很高,接近内存写速度。缺点是如果机器掉电,Page Cache中未刷盘的数据会丢失。
选择: 同步刷盘保证数据不丢失,适用于金融等对数据可靠性要求极高的场景;异步刷盘性能好,适用于业务量巨大、允许毫秒级数据丢失的场景。通常Master配置为同步刷盘+主从同步,Slave配置为异步刷盘。
第四部分:核心场景应用
11. 问题: 请结合一个具体例子,详细说明RocketMQ是如何实现“应用解耦”的。
考察点: 对消息队列核心价值之一的理解和应用能力。
优秀回答:
场景: 用户在下单成功后,需要执行一系列后续操作:更新库存、发放积分、发送通知短信。
无MQ的耦合架构: 订单服务需要依次调用库存服务、积分服务、短信服务的接口。这些服务是强耦合的,任何一个下游服务故障或延迟,都会导致订单成功流程失败或卡住,用户体验差。系统扩展性也差,增加一个新的下游服务(如推荐服务)需要修改订单服务的代码。
使用RocketMQ解耦:
订单服务完成核心下单逻辑(如写数据库)后,向RocketMQ发送一条“订单创建成功”的消息,然后立即返回给用户。
库存服务、积分服务、短信服务都作为独立的消费者,订阅这个Topic。
它们各自从MQ中获取消息,并独立、异步地执行自己的业务逻辑。
解耦效果:
功能解耦: 订单服务不关心谁来处理后续逻辑,也不关心它们如何处理。下游服务的任何变更、扩容、故障,都不会影响主下单流程。
故障隔离: 即使短信服务暂时宕机,也不会影响库存和积分的处理,消息会在MQ中堆积,等服务恢复后继续消费。
12. 问题: 同样,请结合具体例子说明RocketMQ是如何实现“异步削峰”的。
考察点: 对消息队列另一个核心价值的理解和应用能力。
优秀回答:
场景: 秒杀活动开始瞬间,会有海量的请求涌向系统,远远超过数据库和处理服务的正常承载能力。
无MQ的同步架构: 所有请求直接打到后端服务,服务和处理数据库会因瞬时高并发而崩溃,导致整个系统不可用。
使用RocketMQ削峰填谷:
将秒杀请求的业务逻辑拆解。前端请求到达后,只进行简单的参数校验,然后将有效的秒杀请求作为消息发送到RocketMQ,并立即返回“请求正在处理中”的状态给用户。
RocketMQ作为缓冲区,将这些海量的瞬时请求平滑地接收并存储起来,避免了后端系统被冲垮。
后端的秒杀处理服务按照自己最大的处理能力,稳定、匀速地从MQ中消费消息,进行库存扣减、订单创建等核心操作。
处理完成后,再通过其他方式(如WebSocket)通知用户最终结果。
效果: 将瞬间的流量洪峰(波峰)削平,变成后端系统可以承受的平稳流量(填谷),保护了后端系统,保证了服务的可用性。
13. 问题: 在“削峰”场景下,如果消息在Broker中大量堆积,可能的原因是什么?作为开发者或运维人员,你会如何排查和解决?
考察点: 对线上问题的排查和解决能力。
优秀回答:
可能原因:
消费能力不足: 消费者服务实例太少,或消费逻辑太慢(如复杂的数据库操作、调用外部API慢)。
消息量远超预期: 流量洪峰确实太大,超过了系统设计容量。
消费端故障: 消费者服务出现Bug、宕机或网络问题,导致无法消费。
排查与解决:
监控: 首先通过RocketMQ控制台查看堆积的Topic、Queue,以及消费者组的状态和连接情况。
分析消费端: 检查消费者服务的CPU、内存、GC情况。查看业务日志是否有大量错误(如数据库连接超时、空指针等)。
解决方案:
紧急扩容: 快速增加消费者服务实例数量,提升整体消费能力。
优化消费逻辑: 检查消费代码,优化慢SQL,考虑批量处理,避免在消费循环中进行远程调用。
限流降级: 如果消费能力已达上限,可对非核心消息进行限流或暂时降级,优先保障核心业务。
长远规划: 事后需要根据峰值重新评估系统容量,设计更具弹性的架构。
第五部分:高级特性与最佳实践
14. 问题: 什么是消息重试机制?RocketMQ是如何处理消费失败的?
考察点: 对消息可靠投递机制的理解。
优秀回答:
当消费者消费某条消息失败时,RocketMQ会提供重试机制,确保消息最终能被成功消费。
集群模式:
消费失败后,消息不会立即被投递,而是会在Broker端延迟一段时间后再次投递。
重试间隔会逐渐变长,默认最多重试16次。如果16次后仍然失败,该消息会被投递到死信队列。
广播模式: 没有重试机制,消费失败后只会记录日志,需要应用自己保证消费成功。
15. 问题: 什么是死信队列?它有什么作用?
考察点: 对最终处理失败消息的兜底方案的理解。
优秀回答:
当一条消息经过最大重试次数后仍然消费失败,RocketMQ会将其放入一个特殊的队列,这个队列就是死信队列。
命名规则:
%DLQ% + 消费者组名。作用:
隔离异常消息: 防止因个别“毒药消息”无限次重试,占用系统资源,影响正常消息的消费。
人工干预: 死信队列中的消息不会被自动消费,需要开发或运维人员人工查看消息内容,分析失败原因(是代码Bug还是数据问题),修复后手动将消息重新发送回正常的Topic进行消费。这是一个重要的兜底和排查手段。
16. 问题: 如何保证消息不被重复消费?(幂等性)
考察点: 对消息队列常见问题(消息重复)的解决方案的理解。
优秀回答:
由于网络重传、消费者重启等原因,RocketMQ无法保证“Exactly-Once”,而是“At-Least-Once”,即消息可能会被重复投递。因此,消费的幂等性必须由消费者业务逻辑来保证。
实现幂等性的常用方法:
数据库唯一键: 利用数据库主键或唯一约束。例如,消息中包含一个唯一业务ID(如订单ID),在消费时尝试插入数据库,如果重复则会失败。
状态机: 使业务逻辑具有状态。例如,订单状态从“未支付”到“已支付”只能变更一次,如果收到重复的支付成功消息,检查当前状态已经是“已支付”,则直接忽略。
分布式锁/去重表: 在消费前,先拿消息的唯一ID去一个Redis或数据库中去重表里查询是否已处理过。
核心思想是:在业务逻辑中,判断“这笔业务我是否已经做过了”。
17. 问题: 消息过滤有哪几种方式?Tag过滤和SQL92过滤有什么区别?
考察点: 对消息路由和过滤能力的了解。
优秀回答:
RocketMQ支持两种主要的过滤方式:
Tag过滤: 在订阅时指定Tag,Broker会为消费者建立基于Tag的HashCode的索引,过滤在Broker端完成,效率非常高。但Tag是单个字符串,表达能力有限。
SQL92过滤: 消费者可以通过SQL92表达式(如
a > 5 AND b = ‘hello’)来过滤消息。这要求生产者在发送消息时,为消息设置一些属性(Properties)。SQL过滤方式更灵活,功能更强大,但需要Broker做更多的计算,性能开销比Tag过滤大。
18. 问题: 在消息发送和消费过程中,如何保证消息的零丢失?
考察点: 对消息全链路可靠性保障的综合理解。
优秀回答:
保证零丢失需要在生产、存储、消费三个环节都做好配置:
生产端:
使用同步发送。
合理设置重试次数。
处理发送失败的回调,进行日志记录或告警。
Broker端:
采用同步刷盘机制(
flushDiskType = SYNC_FLUSH)。采用同步主从复制机制(
brokerRole = SYNC_MASTER)。这样即使Master磁盘损坏,Slave上也有完整备份。
消费端:
使用集群模式,并在业务逻辑处理成功后再返回
CONSUME_SUCCESS状态。如果处理失败,则返回RECONSUME_LATER,利用重试机制。确保消费逻辑的幂等性,以应对重试带来的重复消息。
19. 问题: 如何监控RocketMQ集群的健康状态?你会关注哪些关键指标?
考察点: 运维和监控意识。
优秀回答:
可以使用RocketMQ自带的控制台(
rocketmq-console)或与Prometheus、Grafana等监控系统集成。关键指标包括:
生产/消费TPS: 消息流入流出速率。
消息堆积量: 每个Topic/消费者组的未消费消息数量,这是最重要的告警指标之一。
Broker存储信息: 磁盘使用率。
NameServer/Broker的CPU、内存、IO: 系统资源使用情况。
发送/消费延迟: 消息从生产到消费的时间。
失败次数: 发送失败和消费失败的次数。
20. 问题: 在设计系统时,如何决定一个Topic应该设置多少个MessageQueue?
考察点: 对性能调优和容量规划的理解。
优秀回答:
MessageQueue的数量是RocketMQ并行能力的上限,因为一个Queue在同一时刻只能被一个消费者线程消费。
决定因素:
预期的吞吐量: 需要评估该Topic下消息的生产和消费峰值TPS。
消费者数量与能力: 评估一个消费者实例能处理多少个Queue。理想情况下,消费者实例的总数应该等于Queue的总数,这样每个实例都能分配到均匀的Queue,达到负载均衡和最大并行度。如果消费者实例少于Queue数,有些实例会承担更多负载;如果多于Queue数,多出来的实例将分配不到Queue,无法消费。
建议: 在系统初期可以设置多一些(如16或32个),因为Topic创建后Queue数只能增加不能减少。这样可以预留扩展空间,未来通过增加消费者实例就能线性提升消费能力。