AI行业应用深度解析:从理论到实践
引言:AI为何能重塑千行百业
人工智能(AI)已不再是科幻概念,而是推动全球产业变革的核心驱动力。其价值在于通过机器学习(ML)、深度学习(DL)、自然语言处理(NLP)、计算机视觉(CV)等技术,实现对海量数据的智能处理、模式识别和预测优化,从而提升效率、降低成本、创造新价值。本文将深入金融、医疗、教育、制造四大关键领域,通过具体的落地案例、技术代码、流程图表和交互提示,全景式展现AI的应用现状与未来潜力。
第一章:AI在金融领域的应用 - 以“智能风控与反欺诈”为例
金融是数据密度最高、AI应用最成熟的领域之一。核心应用包括智能投顾、算法交易、信用评估、智能客服等。我们选取与每个人息息相关的“智能风控与反欺诈”作为深度案例。
1.1 业务背景与痛点
痛点:传统的风控规则引擎(如“单笔交易金额大于5000元即预警”)僵硬、滞后,难以应对不断演变的欺诈手段(如盗刷、套现、电信诈骗)。误报率高,影响正常用户体验;漏报则直接导致资金损失。
AI解决方案:利用机器学习模型,综合分析用户历史交易行为、设备信息、位置信息、交易上下文等上百个特征,实时判断单笔交易的风险概率,实现动态、精准、主动的防御。
1.2 技术架构与流程
下图展示了智能风控系统的核心工作流程:
flowchart TDA[交易请求发起] --> B[实时特征工程]subgraph B [实时特征工程]B1[用户历史行为特征<br>(如日均交易额)]B2[本次交易特征<br>(如金额、商户)]B3[设备与环境特征<br>(如IP、GPS)]endB --> C{输入预训练模型}subgraph D [模型服务]C --> E[模型推理<br>(如LightGBM, XGBoost)]E --> F[输出风险分数<br>(0-1)]endF --> G{风险决策引擎}G -- 分数 < 0.05 --> H[正常交易<br>直接通过]G -- 0.05 ≤ 分数 < 0.3 --> I[低风险交易<br>发送短信验证]G -- 0.3 ≤ 分数 < 0.7 --> J[中高风险交易<br>人工审核]G -- 分数 ≥ 0.7 --> K[高风险交易<br>直接拒绝]I --> L[验证通过?]L -- 是 --> M[交易通过]L -- 否 --> N[交易中止]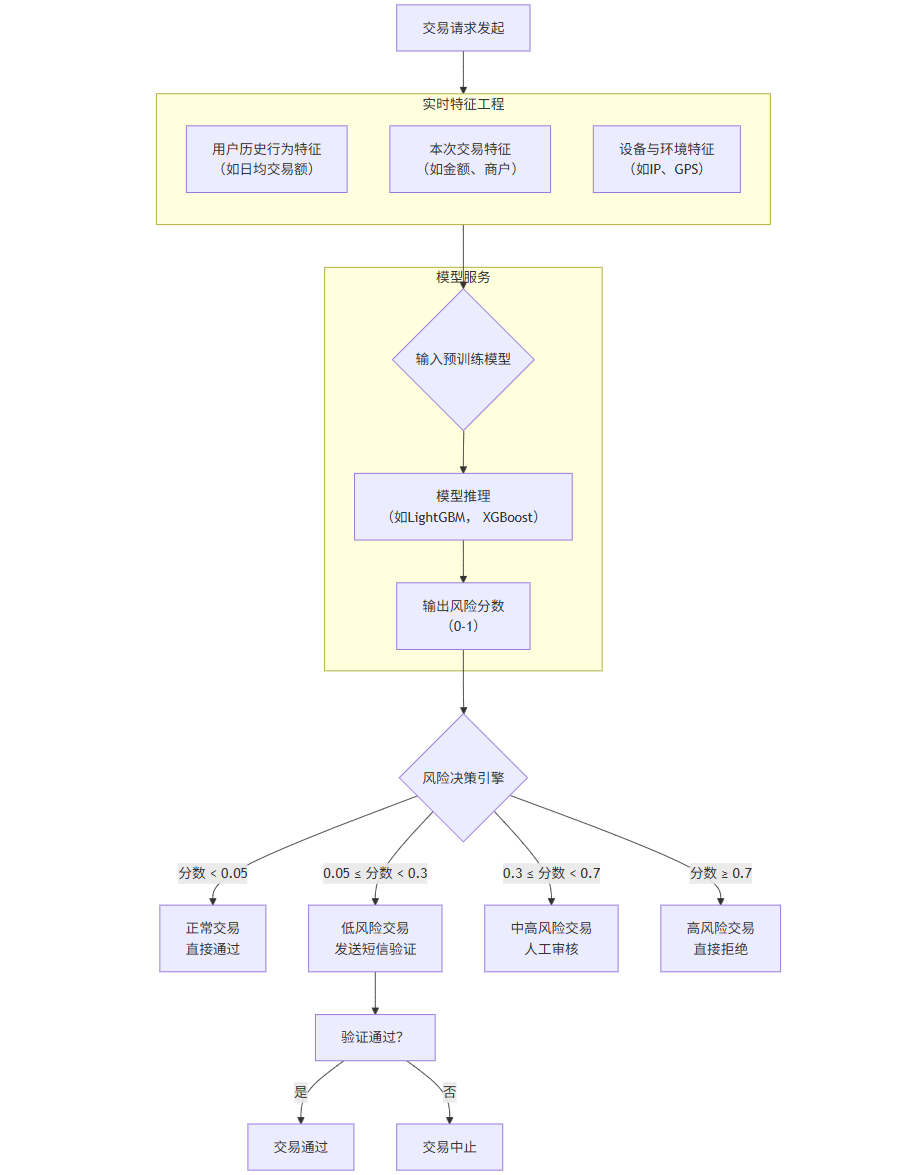
流程解读:
特征工程:从各类数据源实时提取特征。例如:
user_avg_amount_30d: 用户过去30天平均交易金额。transaction_amount: 本次交易金额。is_night: 是否在深夜交易。distance_from_home: 交易地点与常用地址的距离。
模型推理:将特征向量输入已训练好的模型(如梯度提升树模型LightGBM),模型输出一个0到1之间的风险分数。
决策引擎:根据风险分数和预设阈值,执行相应的风控策略,实现差异化处理。
1.3 代码示例:使用LightGBM构建反欺诈模型
以下是一个简化的模型训练代码示例,使用Python和LightGBM库。
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score, classification_report
import lightgbm as lgb# 1. 模拟生成一些训练数据(现实中来自数据仓库)
# 假设有10万条交易记录,100个特征,1个标签(0=正常,1=欺诈)
np.random.seed(42)
n_samples = 100000
n_features = 100# 生成特征数据
X = np.random.randn(n_samples, n_features)
# 生成标签:假设欺诈率约为1%
y = np.random.choice([0, 1], size=n_samples, p=[0.99, 0.01])
# 为了让一些特征与标签相关,我们手动制造一些关联
X[:, 0] += y * 2 # 特征0与欺诈正相关
X[:, 1] -= y * 1.5 # 特征1与欺诈负相关# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 3. 创建LightGBM数据集
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)# 4. 设置模型参数(针对高度不平衡数据)
params = {'objective': 'binary','metric': 'auc','boosting_type': 'gbdt','learning_rate': 0.05,'num_leaves': 31,'max_depth': -1,'min_data_in_leaf': 20,'feature_fraction': 0.8,'bagging_fraction': 0.8,'is_unbalance': True, # 处理类别不平衡'verbose': -1
}# 5. 训练模型
gbm = lgb.train(params,train_data,num_boost_round=1000,valid_sets=[test_data],callbacks=[lgb.early_stopping(stopping_rounds=50), lgb.log_evaluation(50)])# 6. 模型预测与评估
y_pred_proba = gbm.predict(X_test, num_iteration=gbm.best_iteration) # 预测概率值
y_pred = (y_pred_proba > 0.5).astype(int) # 根据阈值(0.5)转换为二分类结果print(f"测试集 AUC: {roc_auc_score(y_test, y_pred_proba):.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))# 7. 保存模型,用于线上推理
gbm.save_model('transaction_fraud_model.txt')1.4 Prompt示例:针对风控模型的解释性分析
在实际业务中,模型的可解释性至关重要。我们可以使用SHAP等工具来理解模型为何做出某个决策。
Prompt给数据分析师的指令:
“我已经训练好了一个反欺诈的LightGBM模型(文件:
fraud_model.pkl)和一条需要分析的交易数据(特征向量:transaction_vector.csv)。请生成一个Python脚本,使用SHAP库完成以下任务:
计算该条交易预测结果的特征贡献度(SHAP值)。
绘制一个力力图(force plot),直观展示哪些特征将预测推向‘欺诈’或‘正常’。
输出贡献度最高的前5个特征及其SHAP值,并给出业务解释。”
1.5 图表:模型性能评估
在实际应用中,我们不仅看AUC,还会关注不同阈值下的精确率(Precision)和召回率(Recall),通过P-R曲线来找到业务最佳平衡点。
(此处应有一张P-R曲线图)
X轴: 召回率(Recall)- 我们找出了多少真正的欺诈交易?
Y轴: 精确率(Precision)- 我们报警的交易中,有多少是真的欺诈?
业务意义:金融风控中,通常愿意牺牲一定的召回率来保证极高的精确率,因为误报(骚扰正常用户)的成本也很高。通过曲线可以选择一个阈值,使得精确率在99%以上时,召回率尽可能高。
第二章:AI在医疗领域的应用 - 以“医学影像辅助诊断”为例
AI在医疗领域的应用正在挽救生命。医学影像分析是其中发展最快的方向,用于辅助医生进行病灶检测、分割和分类。
2.1 业务背景与痛点
痛点:放射科、病理科医生工作量大,长时间阅片容易产生视觉疲劳,导致误诊或漏诊。不同医生之间存在诊断差异。对于罕见病,经验不足的医生难以识别。
AI解决方案:利用卷积神经网络(CNN)等深度学习模型,对X光、CT、MRI、病理切片等影像进行自动分析,快速、准确地定位可疑区域(如肺结节、肿瘤),并提供辅助诊断意见。
2.2 技术架构与流程:以肺结节检测为例
flowchart TDA[DICOM格式CT影像] --> B[影像预处理]B --> C[肺部区域分割<br>(语义分割模型如U-Net)]C --> D[候选结节检测<br>(目标检测模型如Faster R-CNN)]D --> E[假阳性削减<br>(分类模型如ResNet)]E --> F[生成诊断报告<br>(结节位置、大小、恶性概率)]F --> G[医生最终审核]
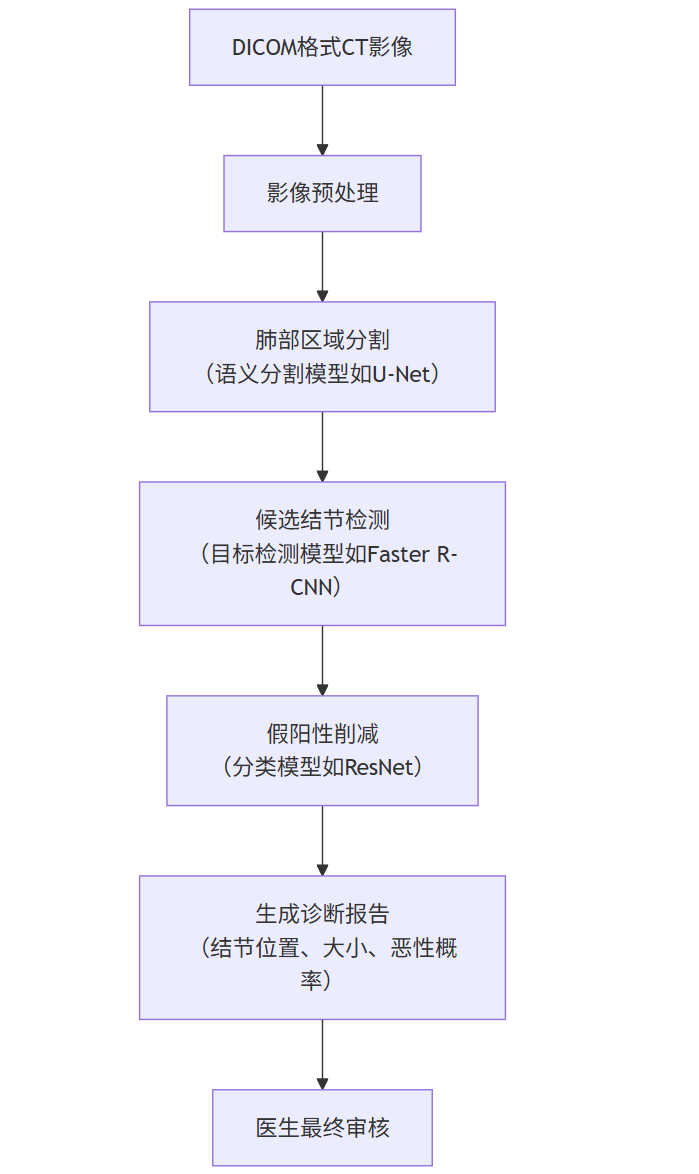
流程解读:
预处理:标准化CT图像的窗宽窗位、分辨率,并进行去噪。
肺部区域分割:首先将肺部组织从胸腔CT中分割出来,减少后续分析的范围。
候选结节检测:在肺部区域内,检测所有可能是结节的区域(候选框)。这一步灵敏度很高,但会产生大量假阳性(不是结节的正常组织被误检)。
假阳性削减:对每一个候选区域,用一个更精细的分类模型判断它到底是真结节还是假阳性。这是提升模型精度的关键步骤。
报告生成:系统汇总真结节的信息,如3D坐标、直径、密度等,并基于大量数据训练的风险预测模型计算恶性概率,生成结构化报告供医生参考。
2.3 代码示例:使用TensorFlow构建一个简单的CNN进行X光肺炎分类
本例使用著名的ChestX-Ray数据集(肺炎X光片),构建一个二分类模型(正常 vs 肺炎)。
python
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt# 1. 设置数据路径和参数
IMG_HEIGHT = 224
IMG_WIDTH = 224
BATCH_SIZE = 32
EPOCHS = 10train_dir = 'path/to/chest_xray/train'
val_dir = 'path/to/chest_xray/val'# 2. 使用ImageDataGenerator进行数据增强和加载
# 注意:医疗影像数据稀缺,数据增强至关重要。
train_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255,rotation_range=20,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest'
)val_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(IMG_HEIGHT, IMG_WIDTH),batch_size=BATCH_SIZE,class_mode='binary' # 二分类
)val_generator = val_datagen.flow_from_directory(val_dir,target_size=(IMG_HEIGHT, IMG_WIDTH),batch_size=BATCH_SIZE,class_mode='binary'
)# 3. 构建CNN模型(使用预训练的权重进行迁移学习)
base_model = keras.applications.DenseNet121(weights='imagenet',include_top=False,input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)
)
base_model.trainable = False # 冻结基础模型,先只训练顶层model = keras.Sequential([base_model,layers.GlobalAveragePooling2D(),layers.Dropout(0.2),layers.Dense(1, activation='sigmoid') # 二分类输出层
])# 4. 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy', tf.keras.metrics.Precision(name='prec'), tf.keras.metrics.Recall(name='rec')]
)# 5. 训练模型
history = model.fit(train_generator,epochs=EPOCHS,validation_data=val_generator
)# 6. 微调:解冻基础模型的部分层进行进一步训练
base_model.trainable = True
# 微调后20层
fine_tune_at = len(base_model.layers) - 20
for layer in base_model.layers[:fine_tune_at]:layer.trainable = Falsemodel.compile(optimizer=keras.optimizers.Adam(learning_rate=0.0001/10), # 使用更小的学习率loss='binary_crossentropy',metrics=['accuracy']
)# 继续训练
history_fine = model.fit(train_generator,epochs=EPOCHS + 5,initial_epoch=history.epoch[-1],validation_data=val_generator
)# 7. 保存模型
model.save('pneumonia_detection_model.h5')# 8. 可视化训练过程(准确率和损失曲线)
acc = history.history['accuracy'] + history_fine.history['accuracy']
val_acc = history.history['val_accuracy'] + history_fine.history['val_accuracy']
loss = history.history['loss'] + history_fine.history['loss']
val_loss = history.history['val_loss'] + history_fine.history['val_loss']plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend()
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()2.4 Prompt示例:针对医学影像模型的Grad-CAM可视化
为了增加医生对AI结果的信任,需要让AI“看得见”,即展示模型是关注图像的哪些区域做出决策的。
Prompt给AI工程师的指令:
“我们有一个训练好的肺炎分类模型
model.h5和一张待分析的胸部X光片patient_xray.png。请编写一个Python函数,实现Grad-CAM(梯度加权类激活映射)可视化。
加载模型和图像,并进行与前训练时相同的预处理。
使用Grad-CAM算法生成一张热力图,叠加在原图上。
热力图应高亮显示模型认为最可能属于‘肺炎’特征的图像区域。
将结果保存为
gradcam_output.png,并在屏幕上显示。”
2.5 图片:Grad-CAM可视化效果示意
(此处应有一张Grad-CAM效果图)
左图:原始胸部X光片。
右图:Grad-CAM热力图叠加效果。红色区域表示模型决策时关注的重点,这些区域与医生关注的肺叶感染区域高度吻合,极大地增强了诊断结果的可信度。
第三章:AI在教育领域的应用 - 以“自适应学习系统”为例
教育正从“一刀切”走向个性化。自适应学习系统是AI赋能教育的典型代表。
3.1 业务背景与痛点
痛点:传统课堂无法兼顾每个学生的认知水平和学习速度。学得快的学生“吃不饱”,学得慢的学生“跟不上”。
AI解决方案:通过分析学生的答题记录、学习行为、停留时间等数据,为每个学生构建知识状态模型(Knowledge Tracing),动态推荐最适合其当前能力的练习题和学习路径,实现“因材施教”。
3.2 技术核心:知识追踪(Knowledge Tracing)模型
知识追踪的核心是预测学生答对下一道题的概率。经典模型有BKT(贝叶斯知识追踪)和基于深度学习的DKT(深度知识追踪)。
下图展示了自适应学习系统如何利用DKT模型进行个性化推荐:
flowchart LRA[学生答题序列] --> B[DKT模型]B -- 更新 --> C[隐藏状态<br>(表征学生知识掌握程度)]C --> D[预测下一题正确概率]D --> E{推荐引擎决策}E -- 概率高 (>0.8) --> F[推荐更难的题目<br>(巩固与挑战)]E -- 概率中 (0.5-0.8) --> G[推荐相似难度题目<br>(强化练习)]E -- 概率低 (<0.5) --> H[推荐更基础题目<br>(弥补知识漏洞)]F & G & H --> I[学生作答]I --> A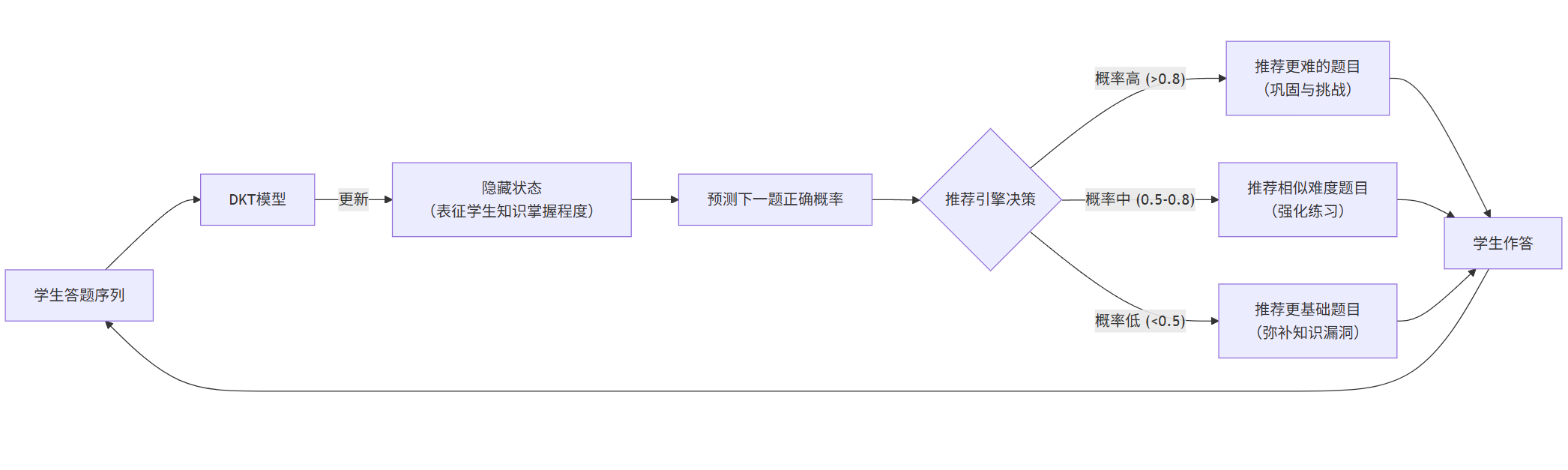
流程解读:
DKT模型将学生的学习历史(如
[q1: 对, q2: 错, q3: 对...])作为一个时间序列。模型(通常使用RNN或LSTM)会维护一个“隐藏状态”,这个状态编码了学生当前对各知识点的掌握情况。
基于这个隐藏状态,模型可以预测学生答对下一道题(如
q4)的概率。推荐系统根据这个预测概率,决定下一步的学习内容。如果预测概率很高,说明学生已掌握该知识点,可以学习新内容或挑战更高难度;如果概率很低,则推荐复习材料。
3.3 代码示例:使用PyTorch实现一个简单的DKT模型
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 假设我们有一个模拟数据集
# 每个学生是一个序列,每个元素是(题目ID, 答题结果:1对0错)的元组
# 为了简化,我们将(题目ID, 结果)编码成一个唯一的整数特征
def create_sequence_data(num_students, seq_length, num_questions):data = []for _ in range(num_students):seq = []for _ in range(seq_length):q_id = np.random.randint(0, num_questions)correct = np.random.choice([0, 1])# 一种常见的编码方式:feature_id = q_id * 2 + correctfeature_id = q_id * 2 + correctseq.append(feature_id)data.append(seq)return torch.tensor(data, dtype=torch.long)# 超参数
num_questions = 50 # 题目数量
input_size = num_questions * 2 # 输入维度:one-hot编码后的大小
hidden_size = 100 # LSTM隐藏层维度
output_size = num_questions # 输出维度:预测每道题的正确概率
num_layers = 1
batch_size = 32
seq_len = 50# 生成模拟数据
train_data = create_sequence_data(1000, seq_len, num_questions)# 定义DKT模型
class DKTModel(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers):super(DKTModel, self).__init__()self.embedding = nn.Embedding(input_size, input_size) # 可选的嵌入层self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)self.sigmoid = nn.Sigmoid()def forward(self, x):# x shape: (batch_size, sequence_length)x = self.embedding(x) # shape: (batch_size, seq_len, input_size)lstm_out, (hn, cn) = self.lstm(x) # lstm_out shape: (batch_size, seq_len, hidden_size)output = self.fc(lstm_out) # shape: (batch_size, seq_len, output_size)output = self.sigmoid(output)return output# 初始化模型、损失函数、优化器
model = DKTModel(input_size, hidden_size, output_size, num_layers)
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环(简化版)
for epoch in range(10):model.train()total_loss = 0# 模拟一个数据加载器for i in range(0, len(train_data), batch_size):batch = train_data[i:i+batch_size]# 输入是序列的前n-1步inputs = batch[:, :-1]# 目标是序列的后n-1步,需要转换为每个时间步对应题目的答题结果# 这是一个简化的目标构建,实际更复杂targets = batch[:, 1:].float() # 这里需要更精细的处理,将feature_id映射回题目ID和正确性optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets) # 需要调整outputs和targets的shape以匹配loss.backward()optimizer.step()total_loss += loss.item()print(f'Epoch [{epoch+1}/10], Loss: {total_loss:.4f}')# 使用模型进行预测
model.eval()
with torch.no_grad():# 假设有一个新学生的部分学习序列test_student = train_data[0:1, :10] # 取第一个学生的前10个步骤prediction = model(test_student) # 预测第11步的答题情况# prediction shape: (1, 10, 50) -> [batch, seq, question_probs]next_step_probs = prediction[0, -1, :] # 取最后一个时间步的预测,表示对50道题答对的概率print("预测下一题答对概率(部分):", next_step_probs[:5])3.4 Prompt示例:为自适应学习系统生成练习题
系统可以根据学生薄弱知识点,动态生成题目。这里展示如何利用大语言模型(LLM)进行题目生成。
Prompt给LLM的指令:
“你是一个自适应学习系统的AI助教。请根据以下学生信息,生成一道适合他当前水平的数学练习题。
学生信息:
年级:初中二年级
薄弱知识点:一元一次方程的应用题,特别是涉及‘行程问题’的类型。
当前难度级别:中等(已掌握基本解法,但需要巩固)
要求:
题目背景贴近生活,是关于‘行程问题’的。
难度适中,不能太简单也不要超纲。
只生成题目本身,不需要解答。
输出格式为JSON,包含
question(题目内容)、knowledge_point(知识点)和difficulty(难度)三个字段。”
预期的LLM输出:
json
{"question": "小明骑自行车从家到学校,如果以每分钟200米的速度行驶,则会迟到5分钟;如果以每分钟250米的速度行驶,则会提前3分钟到达。请问小明家到学校的距离是多少米?","knowledge_point": "一元一次方程的应用-行程问题","difficulty": "medium"
}第四章:AI在制造业的应用 - 以“工业质检与预测性维护”为例
智能制造是工业4.0的核心。AI在制造业的应用主要体现在提升质量(质检)和保障设备运行(维护)两方面。
4.1 业务背景与痛点
痛点1(质检):传统人工质检效率低、成本高、易疲劳,标准不统一。精密部件(如电路板)的微小缺陷人眼难以发现。
痛点2(维护):传统维护模式是事后维修(坏了再修)或定期维修(不管好坏到点就修),前者导致停产损失,后者造成资源浪费且可能过度维修。
AI解决方案1:基于计算机视觉的自动光学检测(AOI),7x24小时无休,检测精度和效率远超人工。
AI解决方案2:预测性维护,通过分析设备传感器数据(温度、振动、噪声等),提前预测设备故障,在最佳时间点进行维修。
4.2 技术架构与流程:基于CV的缺陷检测
flowchart TDA[工业相机采集产品图像] --> B[图像预处理<br>(增强对比度/去噪)]B --> C[缺陷检测模型推理<br>(目标检测模型如YOLO)]C --> D[缺陷分类与定位]D --> E{缺陷判断}E -- 有缺陷 --> F[记录缺陷信息<br>并触发报警/分拣]E -- 无缺陷 --> G[产品流入下一环节]F --> H[缺陷数据回流至模型训练集]H --> I[模型持续优化]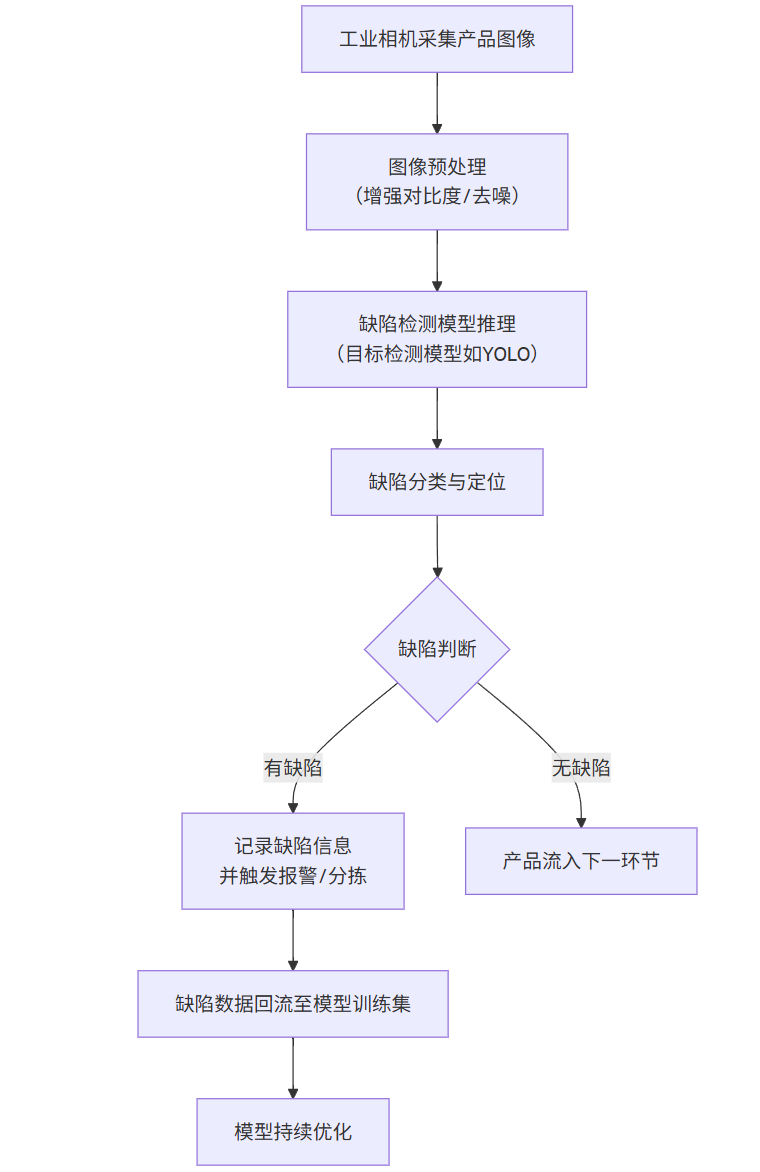
4.3 代码示例:使用PyTorch和Faster R-CNN进行零件缺陷检测
假设我们有一个包含缺陷的零件数据集,标注了缺陷的边界框(Bounding Box)和类别(如划痕、凹陷)。
python
import torch
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torchvision import transforms as T
import numpy as np
from PIL import Image
import cv2# 1. 准备数据集 - 这里需要自定义Dataset类(略)
# 假设我们已经有一个返回(image, target)的数据集
# target是字典,包含'boxes'和'labels'# 2. 加载预训练模型并修改头部,以适应我们的缺陷类别数
def get_model(num_classes):# 加载在COCO上预训练的骨干网络backbone = torchvision.models.mobilenet_v3_large(pretrained=True).featuresbackbone.out_channels = 960 # MobilenetV3-Large的输出通道数# 定义RPN的锚点生成器anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),aspect_ratios=((0.5, 1.0, 2.0),))# 定义ROI池化层roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 从哪个特征图提取output_size=7,sampling_ratio=2)# 组装Faster R-CNN模型model = FasterRCNN(backbone,num_classes=num_classes,rpn_anchor_generator=anchor_generator,box_roi_pool=roi_pooler)return model# 假设我们有2类:背景(0)和缺陷(1)
model = get_model(num_classes=2)# 3. 训练代码框架
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)# 假设dataloaders是一个包含‘train’和‘val’的数据加载器字典
num_epochs = 10for epoch in range(num_epochs):model.train()for images, targets in dataloaders['train']:images = list(image.to(device) for image in images)targets = [{k: v.to(device) for k, v in t.items()} for t in targets]loss_dict = model(images, targets)losses = sum(loss for loss in loss_dict.values())optimizer.zero_grad()losses.backward()optimizer.step()lr_scheduler.step()# 在验证集上评估...# 4. 模型推理(在线检测)
def predict_defect(image_path, model, device, confidence_threshold=0.7):model.eval()image = Image.open(image_path).convert("RGB")transform = T.Compose([T.ToTensor()])image_tensor = transform(image).to(device)with torch.no_grad():prediction = model([image_tensor])# 解析预测结果boxes = prediction[0]['boxes'].cpu().numpy()labels = prediction[0]['labels'].cpu().numpy()scores = prediction[0]['scores'].cpu().numpy()# 根据置信度阈值过滤结果keep = scores >= confidence_thresholdboxes = boxes[keep]labels = labels[keep]scores = scores[keep]# 可视化结果(使用OpenCV)image_cv = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)for box, score in zip(boxes, scores):x1, y1, x2, y2 = box.astype(int)cv2.rectangle(image_cv, (x1, y1), (x2, y2), (0, 255, 0), 2)cv2.putText(image_cv, f'Defect: {score:.2f}', (x1, y1-10),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)cv2.imwrite('detection_result.jpg', image_cv)return boxes, scores# 使用训练好的模型进行预测
boxes, scores = predict_defect('test_product.jpg', model, device)4.4 图表:预测性维护中的振动信号分析
在预测性维护中,设备振动频谱是判断健康状态的关键指标。
(此处应有一张振动频谱对比图)
上图:正常设备的振动频谱。能量主要集中在基频(运行频率)上,谐波分量很小。
下图:出现早期故障(如轴承磨损)设备的振动频谱。在基频的倍频处出现了明显的高能量峰值(谐波),这是故障的典型特征。
AI模型:可以通过学习正常和异常频谱的模式,自动识别出这些早期故障特征,并预警。
总结与展望
通过以上四个领域的深度案例剖析,我们可以看到AI已经从实验室走向了产业应用的方方面面。其核心价值在于:
提升效率与精度:在金融、制造领域,AI处理海量数据的速度和准确性远超人类。
实现个性化:在教育、医疗领域,AI能够提供量身定制的解决方案。
赋能人类专家:AI并非取代医生、教师或工程师,而是作为强大的辅助工具,帮助他们做出更优决策。
未来趋势:
多模态融合:结合视觉、语音、文本等多种信息进行综合决策(如结合医学影像和电子病历进行诊断)。
生成式AI的深入应用:用于生成合成训练数据、进行产品设计、创建模拟环境等。
可解释性与可信AI:让AI的决策过程更加透明,赢得用户的信任,尤其是在医疗、金融等高风险领域。
边缘计算与AIoT:将AI模型部署到设备端(如摄像头、传感器),实现实时响应和数据隐私保护。
AI的行业落地是一场深刻的变革,它需要技术专家与行业专家的紧密合作,共同挖掘数据价值,解决实际业务痛点,最终推动整个社会的智能化升级。