ShardingSphere 分布式数据库中间件生态

shard 碎片
sphere 生态圈
- ShardingSphere-JDBC
轻量级Java框架,在Java的JDBC层提供额外服务。 - ShardingSphere-Proxy
数据库代理,对异构语言的支持
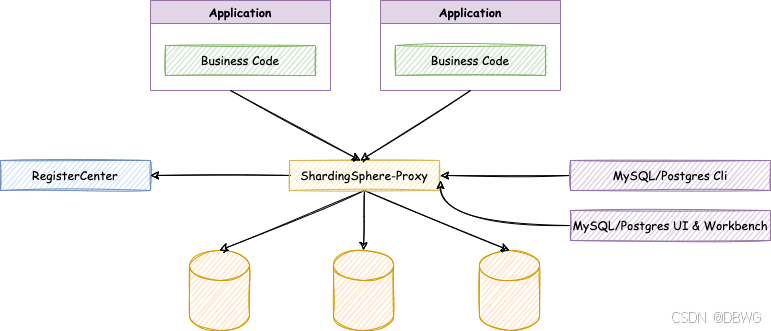
- ShardingSphere-Sidecar
Kubernetes的云原生数据库代理
文章目录
- ShardingSphere
- 三层可插拔架构
- 集群管控
- 读写分离
- 数据分片
- 弹性伸缩
- 影子库压测
- Hint 影子算法
- 分布式事务
- 两阶段提交(2PC)
- 柔性事务(BASE)
ShardingSphere
Apache ShardingSphere 是一个开源的 分布式数据库中间件生态
集群环境需要通过独立部署的注册中心(Zookeeper或Etcd)来存储元数据和协调节点状态。
三层可插拔架构
ShardingSphere 5.x版本开始致力于可插拔架构,项目的功能组件能够灵活地以可插拔的方式进行扩展。
-
L1内核层是数据库基本能力的抽象,主要包括查询优化器、分布式事务引擎、分布式执行引擎、权限引擎和调度引擎等组件。所有组件都必须存在,但具体实现可通过可插拔的方式更换。
-
L2功能层用于提供增量能力,主要包括数据分片、读写分离、数据库高可用、数据加密、影子库等组件。所有组件均是可选的,可以包含零至多个组件。组件之间完全隔离,互无感知,多组件可通过叠加的方式相互配合使用。用户自定义功能可完全面向ShardingSphere定义的顶层接口进行定制化扩展,而无需改动内核代码。
-
L3生态层用于对接和融入现有数据库生态,包括数据库协议、SQL解析器和存储适配器,分别对应于ShardingSphere以数据库协议提供服务的方式、SQL方言操作数据的方式以及对接存储节点的数据库类型。
集群管控
-
面对超负荷流量,针对某一节点进行熔断(阻断ShardingSphere和数据库的连接)和限流,以保证整个数据库集群得以继续运行
-
分布式主键
ShardingSphere不仅提供了内置的分布式主键生成器,例如UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户实现自定义的自增主键生成器。
读写分离
把写请求发到主库,读请求发到从库,自动管理路由和连接,减少应用端逻辑。
传统做法是应用端自己判断走主库或从库,代码复杂且容易出错。
数据分片
ShardingSphere 重点做水平分片。
- 水平分片:同一个表按照某个分片键(如 user_id、order_id)拆到多个物理表或库。
- 垂直分片:按业务模块拆分到不同库,例如用户、订单、支付表放到不同库。
过程:
1.SQL解析
2.路由计算
根据分片规则决定应该访问哪些库、哪些表。
3.改写SQL:
SELECT * FROM t_order WHERE order_id = 123;
改写为
SELECT * FROM ds_1.t_order_3 WHERE order_id = 123;
(如果是多表分片,可能生成多个子 SQL 并行发出。)
4.结果归并
弹性伸缩
数据库直扩很麻烦,手动迁移容易出错且需要停机;希望对应用透明。
ShardingSphere 提供统一的伸缩工具和规则,让迁移自动化、可观测、不中断。
ShardingSphere-Scaling 弹性伸缩过程:
- 捕获增量数据
用数据订阅(如 MySQL Binlog、PostgreSQL WAL)实时获取迁移过程中的新增/更新/删除。 - 迁移全量数据
先把老分片的存量数据同步到新分片。 - 切换路由配置
全量+增量同步完成后,更新 ShardingSphere 的分片规则,应用自动路由到新分库/分表。
过程对应用透明,应用只用一个逻辑库表名,不关心底层库表变化。
影子库压测
在生产环境做压测时,业务代码走的是真实链路,但 数据必须不要污染生产库。
ShardingSphere 做了一个“影子库路由”:
- 如果是压测流量 → SQL 自动路由到影子库(Shadow DB)。
- 如果是正常流量 → 继续走生产库。
关键是要识别哪些 SQL 是压测流量,所以就有了 影子算法。
Hint 影子算法
Hint 在数据库里指的是 SQL 里的 注释式指令,例如 /*+ something */,可以携带一些控制信息。
ShardingSphere 借助这种能力,让应用在 SQL 或上下文中插入标记,来告诉路由逻辑:“这是压测流量”。
/* shadow:true */
INSERT INTO t_order (id, user_id, status) VALUES (1, 123, 'init');
分布式事务
CAP 定理
- Consistency 一致性
- Availability 可用性
- Partition tolerance 分区容错
分布式系统必须在 C 与 A 之间权衡,P 是必须要支持的。
两阶段提交(2PC)
Two-Phase Commit
-
Prepare:协调者(Transaction Manager)向各参与者发送准备命令,每个参与者写入预提交日志并返回“可以提交/不可以提交”。
-
Commit/Rollback:如果全部准备成功,协调者发 commit,否则 rollback。
优点:实现简单,强一致性。
缺点:同步阻塞;协调者单点故障,性能差。
应用:XA 协议(eXtended Architecture接口标准。MySQL InnoDB、Oracle 都支持 XA)。
场景:
核心金融、支付、账户转账等需要强一致性的小型高价值事务。
数据量不大,但对一致性要求极高的系统。
柔性事务(BASE)
Basically Available(基本可用)
Soft state(软状态)
Eventually consistent(最终一致)
工业界很多系统都不是强一致,而是最终一致。
全局提交时先写日志再异步执行提交,如果部分失败可以根据日志进行恢复或补偿。
特点:
✅性能好:不会长时间持锁,不强制同步阻塞。
✅高可用:即使协调者或网络临时异常,也能恢复。
❌ 只保证最终一致,提交后短时间内各库状态可能不一致。
场景:
电商下单、库存更新、用户积分、日志类数据。
对实时强一致要求不高,但必须保证数据最终收敛一致。
参考:
https://cloud.tencent.com/developer/article/2010830