【知识图谱:实战篇】--搭建医药知识图谱问答系统
从无到有搭建一个以疾病为中心的一定规模医药领域知识图谱,并以该知识图谱完成自动问答与分析服务。
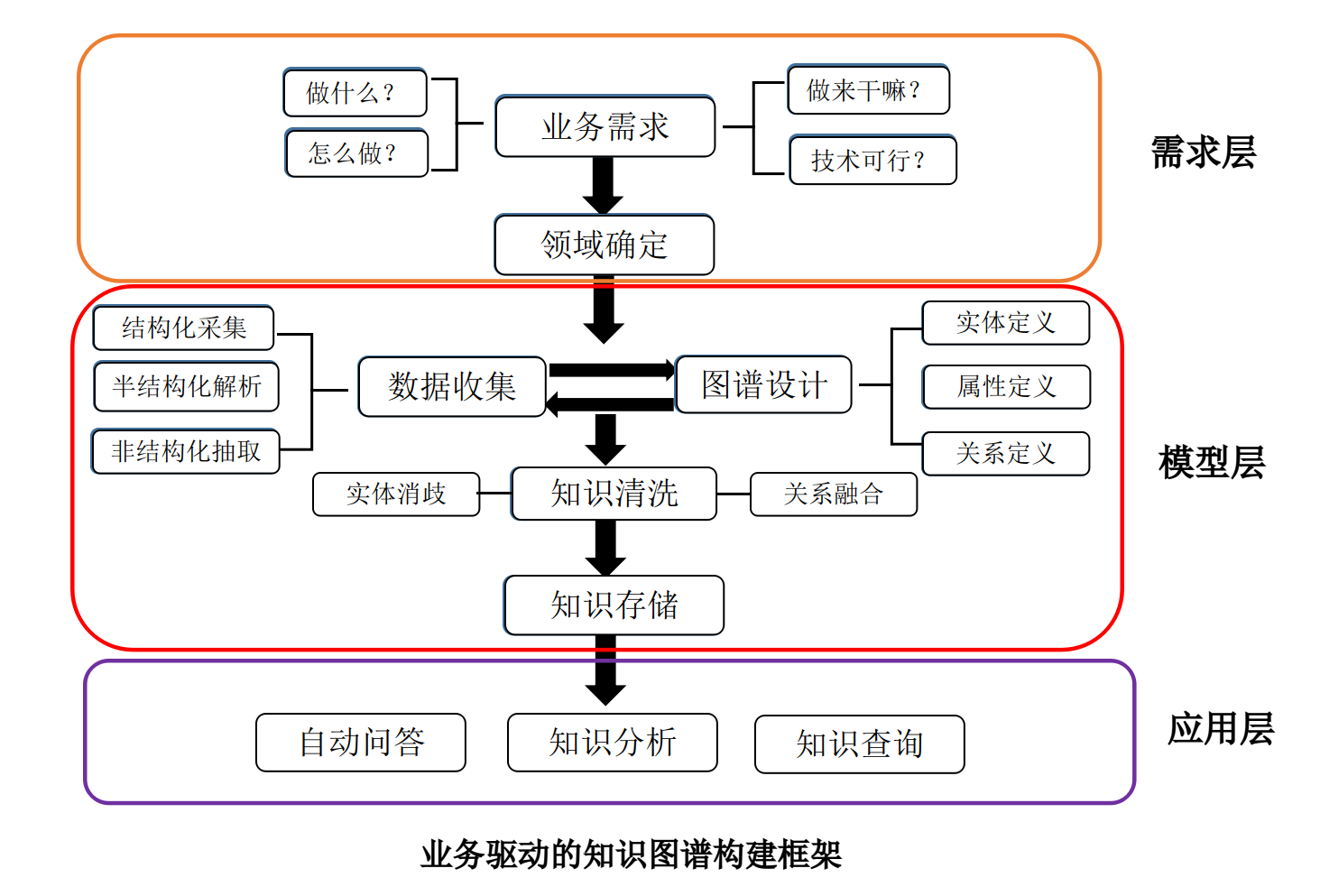
关于知识图谱概念性的介绍就不在此赘述。目前知识图谱在各个领域全面开花,如教育、医疗、司法、金融等。本项目立足医药领域,以垂直型医药网站为数据来源,以疾病为核心,构建起一个包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。 本项目将包括以下两部分的内容:
- 基于垂直网站数据的医药知识图谱构建
- 基于医药知识图谱的自动问答
效果展示:
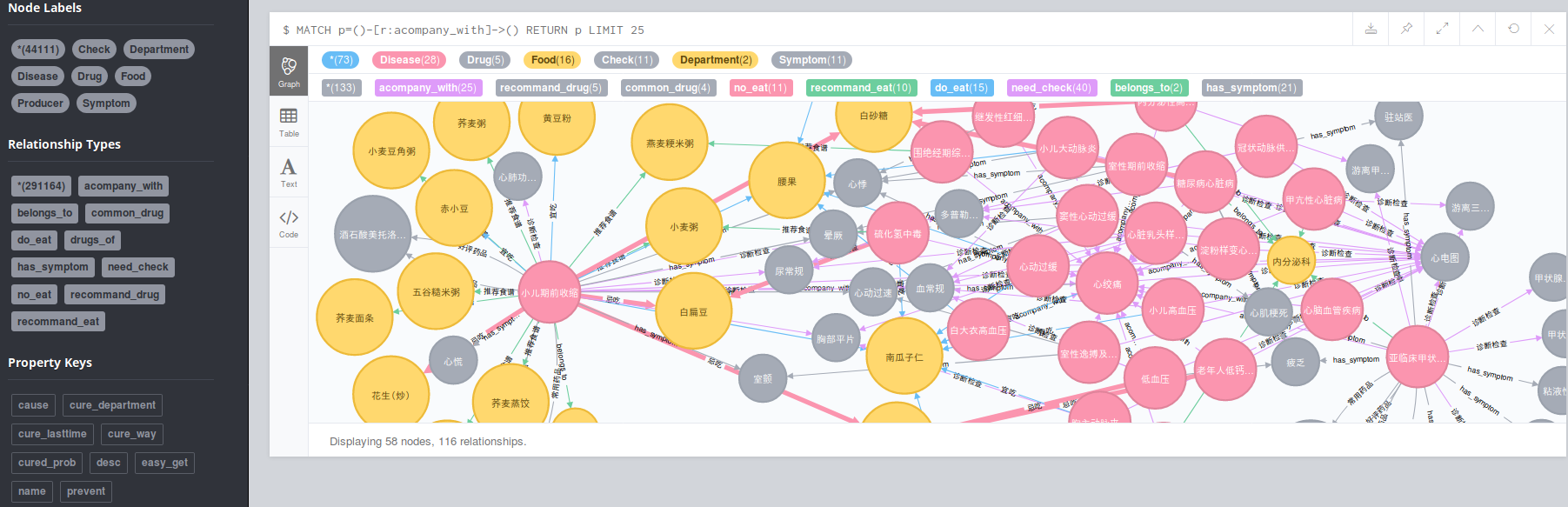
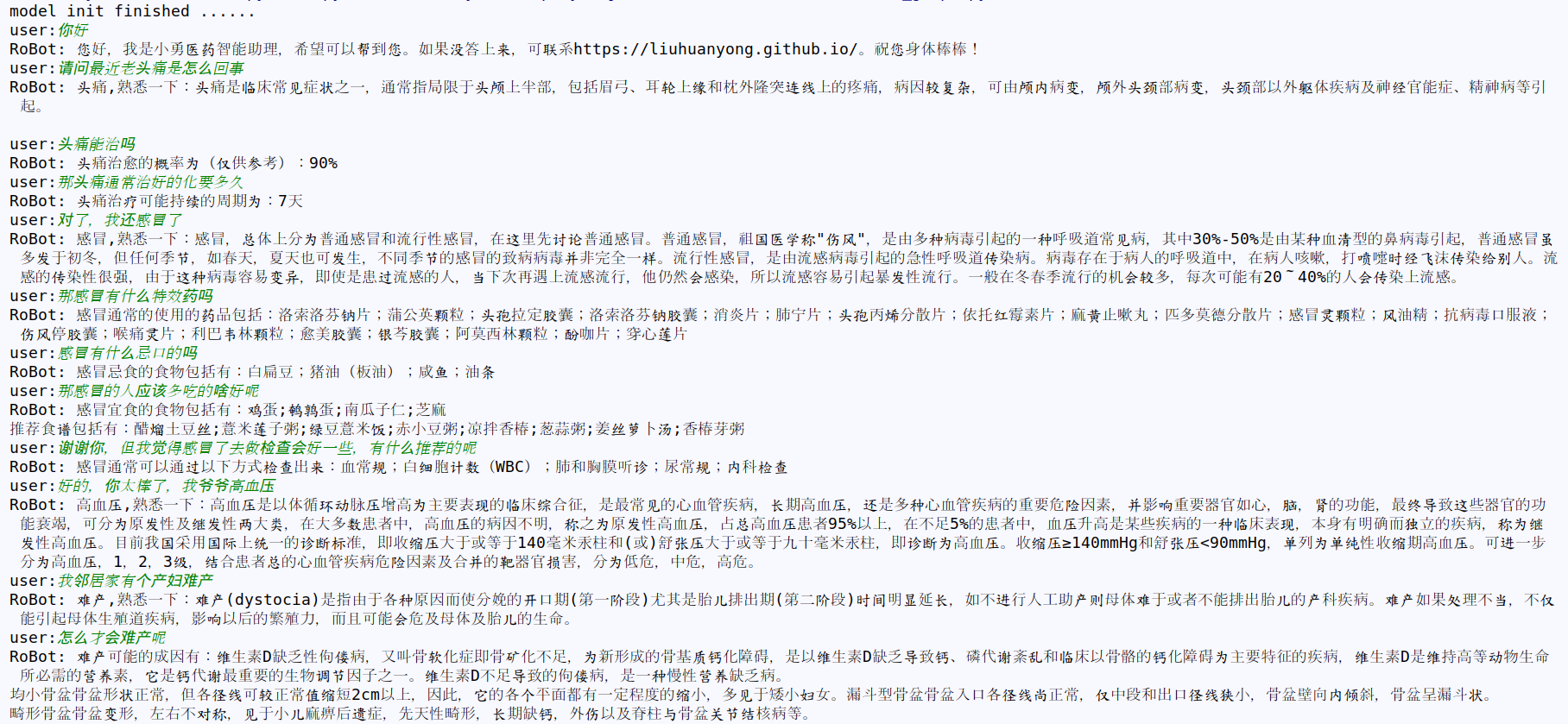
所有源码:https://github.com/gyplove/Medical_Knowledge_Graph.git
目录
1.数据获取模块
1.1.爬取数据
1.2.处理数据
2.构建实体、关系、属性三维列表
2.1.知识图谱实体类型
2.2.知识图谱实体关系
2.3.知识图谱属性类型
2.4.创建实体节点、关系、属性
3.基于知识图谱的问答构建
3.1.问题分类
3.2.生成查询
3.3.执行查询
1.数据获取模块
数据全部来自网站:
http://jib.xywy.com/il_sii/gaishu/1.htm
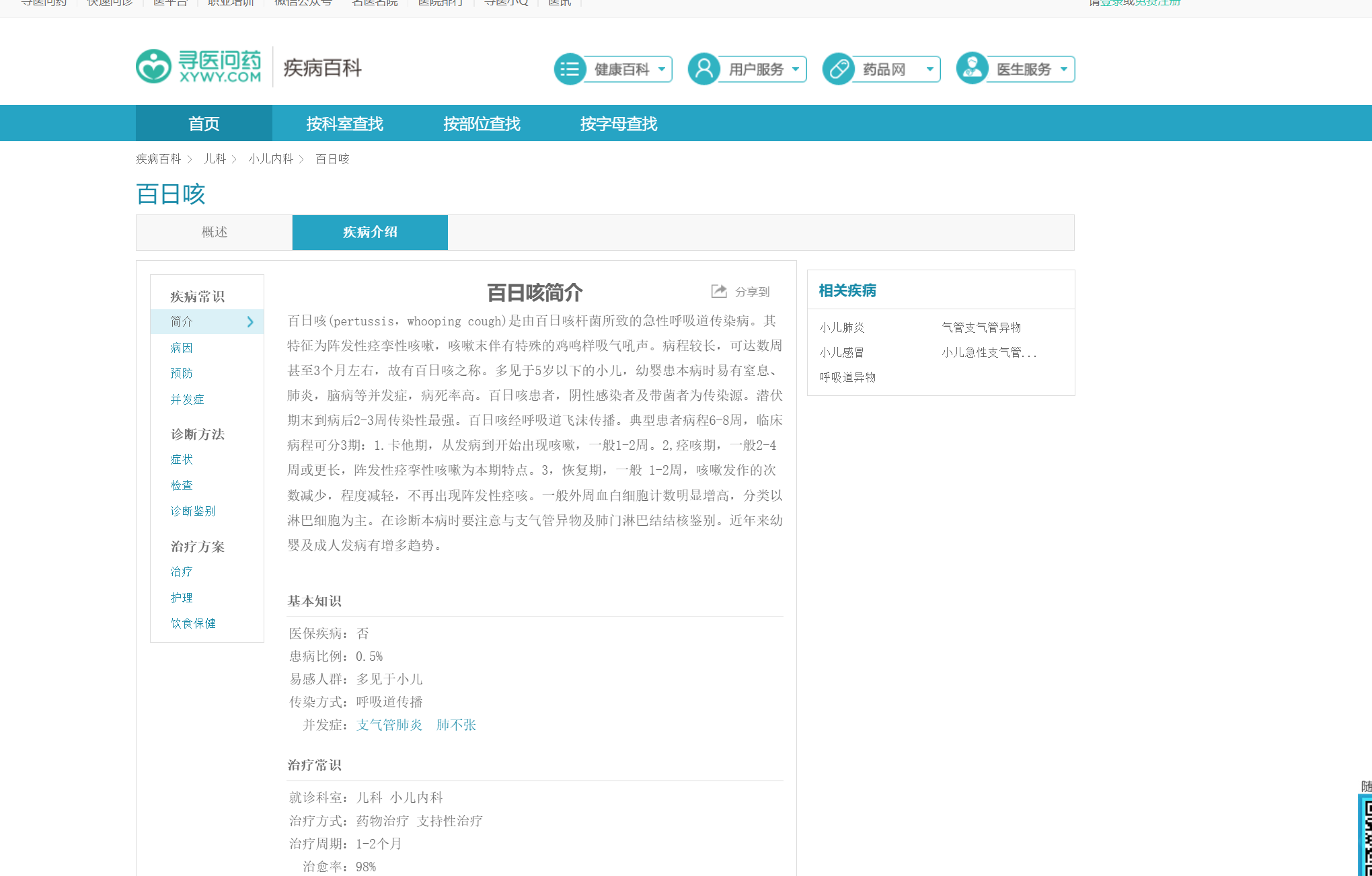
1.1.爬取数据
这里写一个简单的爬虫类获取数据为json格式
get_data.py:
import urllib.request
import urllib.parse
from lxml import etree
import json
import time
import os'''
疾病信息爬虫(无数据库版)
功能:采集疾病详情并保存为 JSON 文件
'''class DiseaseSpider:def __init__(self):# 保存文件路径self.disease_file = 'diseases.json'self.inspect_file = 'inspects.json''''根据 URL 获取 HTML 内容'''def get_html(self, url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ''(KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36'}req = urllib.request.Request(url=url, headers=headers)try:res = urllib.request.urlopen(req, timeout=10)html = res.read()# 尝试用 utf-8 解码,失败则用 gbktry:return html.decode('utf-8')except UnicodeDecodeError:return html.decode('gbk')except Exception as e:print(f"获取页面失败: {url}, 错误: {e}")return '''''主函数:爬取疾病数据并保存为 JSON'''def spider_main(self, start_page=1, end_page=100):print(f"开始爬取疾病数据({start_page} ~ {end_page})...")all_data = []# 如果文件已存在,加载已有数据(实现增量采集)if os.path.exists(self.disease_file):with open(self.disease_file, 'r', encoding='utf-8') as f:all_data = json.load(f)print(f"已加载 {len(all_data)} 条历史数据")existing_ids = {item['page_id'] for item in all_data} # 避免重复采集for page in range(start_page, end_page + 1):if page in existing_ids:print(f"[跳过] 第 {page} 页已存在")continuetry:basic_url = f'http://jib.xywy.com/il_sii/gaishu/{page}.htm'cause_url = f'http://jib.xywy.com/il_sii/cause/{page}.htm'prevent_url = f'http://jib.xywy.com/il_sii/prevent/{page}.htm'symptom_url = f'http://jib.xywy.com/il_sii/symptom/{page}.htm'inspect_url = f'http://jib.xywy.com/il_sii/inspect/{page}.htm'treat_url = f'http://jib.xywy.com/il_sii/treat/{page}.htm'food_url = f'http://jib.xywy.com/il_sii/food/{page}.htm'drug_url = f'http://jib.xywy.com/il_sii/drug/{page}.htm'data = {'page_id': page,'url': basic_url,'basic_info': self.basicinfo_spider(basic_url),'cause_info': self.common_spider(cause_url),'prevent_info': self.common_spider(prevent_url),'symptom_info': self.symptom_spider(symptom_url),'inspect_info': self.inspect_spider(inspect_url),'treat_info': self.treat_spider(treat_url),'food_info': self.food_spider(food_url),'drug_info': self.drug_spider(drug_url)}# 只有成功采集才添加if data['basic_info']: # 基本信息存在说明页面有效all_data.append(data)print(f"[成功] 爬取第 {page} 页: {data['basic_info']['name']}")else:print(f"[空页] 第 {page} 页无数据,跳过")except Exception as e:print(f"[失败] 爬取第 {page} 页失败: {e}")# 防封:每爬一页暂停 1 秒time.sleep(1)# 保存到 JSON 文件with open(self.disease_file, 'w', encoding='utf-8') as f:json.dump(all_data, f, ensure_ascii=False, indent=2)print(f"✅ 疾病数据已保存到 {self.disease_file},共 {len(all_data)} 条")'''基本信息解析'''def basicinfo_spider(self, url):html = self.get_html(url)if not html:return {}selector = etree.HTML(html)try:title = selector.xpath('//title/text()')[0]category = selector.xpath('//div[@class="wrap mt10 nav-bar"]/a/text()')desc_list = selector.xpath('//div[@class="jib-articl-con jib-lh-articl"]/p/text()')ps = selector.xpath('//div[@class="mt20 articl-know"]/p')infobox = []for p in ps:info = p.xpath('string(.)').replace('\r', '').replace('\n', '').replace('\xa0', '').replace(' ', '').replace('\t', '')if info.strip():infobox.append(info.strip())return {'category': [cat.strip() for cat in category],'name': title.replace('的简介', '').strip(),'desc': ''.join(desc_list).strip(),'attributes': infobox}except Exception as e:print(f"解析 basic_info 失败 {url}: {e}")return {}'''治疗信息解析'''def treat_spider(self, url):html = self.get_html(url)if not html:return []selector = etree.HTML(html)ps = selector.xpath('//div[starts-with(@class,"mt20 articl-know")]/p')infobox = []for p in ps:info = p.xpath('string(.)').replace('\r', '').replace('\n', '').replace('\xa0', '').replace(' ', '').replace('\t', '')if info.strip():infobox.append(info.strip())return infobox'''药品推荐解析'''def drug_spider(self, url):html = self.get_html(url)if not html:return []selector = etree.HTML(html)drugs = [name.replace('\n', '').replace('\t', '').replace(' ', '')for name in selector.xpath('//div[@class="fl drug-pic-rec mr30"]/p/a/text()')]return drugs'''饮食建议解析'''def food_spider(self, url):html = self.get_html(url)if not html:return {}selector = etree.HTML(html)divs = selector.xpath('//div[@class="diet-img clearfix mt20"]')try:good = [food.strip() for food in divs[0].xpath('./div/p/text()')]bad = [food.strip() for food in divs[1].xpath('./div/p/text()')]recommand = [food.strip() for food in divs[2].xpath('./div/p/text()')]return {'good': good, 'bad': bad, 'recommand': recommand}except:return {}'''症状信息解析'''def symptom_spider(self, url):html = self.get_html(url)if not html:return {'symptoms': [], 'symptoms_detail': []}selector = etree.HTML(html)symptoms = selector.xpath('//a[@class="gre"]/text()')ps = selector.xpath('//p')detail = []for p in ps:info = p.xpath('string(.)').replace('\r', '').replace('\n', '').replace('\xa0', '').replace(' ', '').replace('\t', '')if info.strip():detail.append(info.strip())return {'symptoms': symptoms, 'symptoms_detail': detail}'''检查项目解析'''def inspect_spider(self, url):html = self.get_html(url)if not html:return []selector = etree.HTML(html)inspects = selector.xpath('//li[@class="check-item"]/a/@href')return inspects'''通用文本解析模块'''def common_spider(self, url):html = self.get_html(url)if not html:return ''selector = etree.HTML(html)ps = selector.xpath('//p')texts = []for p in ps:info = p.xpath('string(.)').replace('\r', '').replace('\n', '').replace('\xa0', '').replace(' ', '').replace('\t', '')if info.strip():texts.append(info.strip())return '\n'.join(texts)'''检查项页面 HTML 抓取(保存为 JSON)'''def inspect_crawl(self, start_page=1, end_page=3684):print(f"开始爬取检查项页面 HTML({start_page} ~ {end_page})...")all_inspects = []if os.path.exists(self.inspect_file):with open(self.inspect_file, 'r', encoding='utf-8') as f:all_inspects = json.load(f)print(f"已加载 {len(all_inspects)} 条检查项数据")existing_ids = {item['page_id'] for item in all_inspects}for page in range(start_page, end_page + 1):if page in existing_ids:print(f"[跳过] 检查项第 {page} 页已存在")continuetry:url = f'http://jck.xywy.com/jc_{page}.html'html = self.get_html(url)if html:data = {'page_id': page,'url': url,'html': html # 可改为只存关键部分以节省空间}all_inspects.append(data)print(f"[成功] 爬取检查项第 {page} 页")else:print(f"[失败] 获取检查项第 {page} 页失败")except Exception as e:print(f"[异常] 检查项第 {page} 页: {e}")time.sleep(1) # 防封# 保存with open(self.inspect_file, 'w', encoding='utf-8') as f:json.dump(all_inspects, f, ensure_ascii=False, indent=2)print(f"✅ 检查项数据已保存到 {self.inspect_file}")# ========================
# 🚀 运行爬虫
# ========================
if __name__ == '__main__':spider = DiseaseSpider()# 选择运行一个任务:# 1. 爬疾病数据(建议先试 1-10)spider.spider_main(start_page=1, end_page=11000)# 2. 爬检查项 HTML(可选)# spider.inspect_crawl(start_page=1, end_page=10)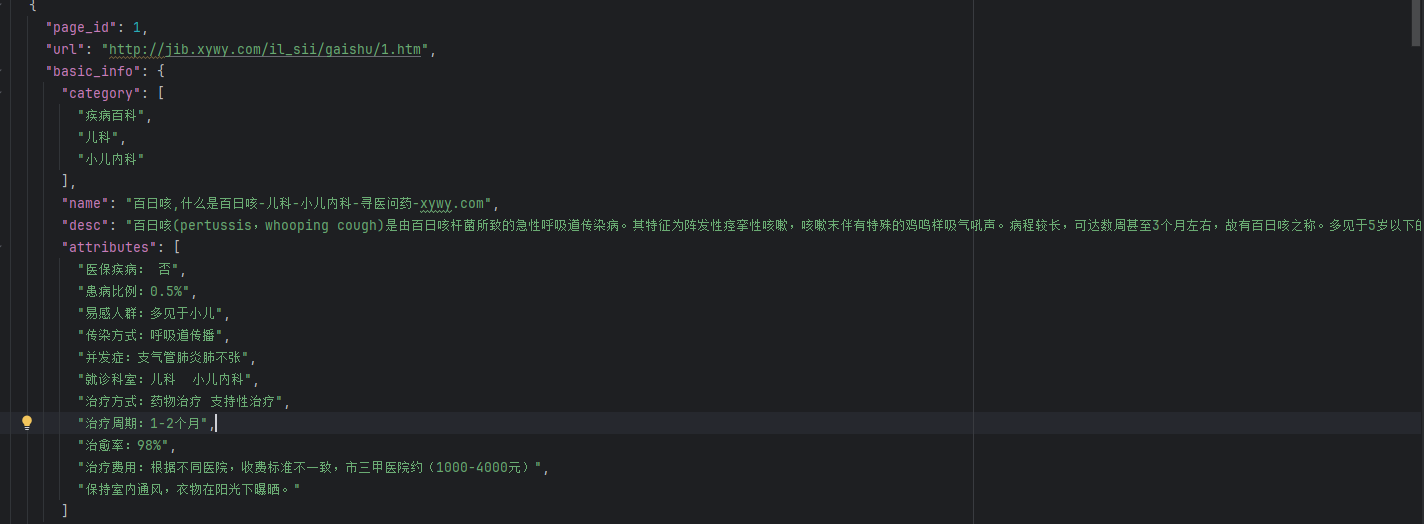
1.2.处理数据
build_data.py:
这段代码实现了一个医疗知识图谱的数据处理类 MedicalGraph,其主要功能是从本地的 diseases.json 文件中加载疾病数据(替代了原本的 MongoDB 数据源),对数据进行清洗、结构化和字段映射。它通过定义停用词和字段关键词字典,提取疾病名称、简介、症状、检查项目、并发症、治疗方式、药品、饮食建议等信息,并利用自定义的分词工具(max_cut)对并发症等文本进行中文分词处理。同时,代码还支持从 jc_data.json 文件中读取并清洗医学检查项目的网页数据,提取标题和描述。最终,清洗后的结构化数据被插入到 MongoDB 中,用于构建医疗知识图谱。整个流程实现了从原始 JSON 数据到标准化知识库记录的转换。
import pymongo
from lxml import etree
import os
import json # 新增:用于读取 JSON 文件
from max_cut import *class MedicalGraph:def __init__(self):# self.conn = pymongo.MongoClient() # 注释掉 MongoDB 连接# self.db = self.conn['medical']# self.col = self.db['data']cur_dir = os.path.dirname(os.path.abspath(__file__))print(cur_dir)# 从 JSON 文件加载数据json_path = os.path.join(cur_dir, 'diseases.json') # 可自定义文件名if not os.path.exists(json_path):raise FileNotFoundError(f"找不到数据文件: {json_path}")with open(json_path, 'r', encoding='utf-8') as f:self.data_list = json.load(f) # 加载整个数据列表# 其他初始化不变first_words = ['', # 空字符串,防止索引越界'我','你','他','她','它','我们','你们','他们','这','那','哪','谁','怎','如何','为什么','是否','请','建议','可能','常见','出现','患有','导致','引起','属于','一种','症状','疾病','病人','患者','临床','表现','包括','伴有','并发','和','或','与','及','等']alphabets = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y', 'z']nums = ['1','2','3','4','5','6','7','8','9','0']self.stop_words = first_words + alphabets + numsself.key_dict = {'医保疾病' : 'yibao_status',"患病比例" : "get_prob","易感人群" : "easy_get","传染方式" : "get_way","就诊科室" : "cure_department","治疗方式" : "cure_way","治疗周期" : "cure_lasttime","治愈率" : "cured_prob",'药品明细': 'drug_detail','药品推荐': 'recommand_drug','推荐': 'recommand_eat','忌食': 'not_eat','宜食': 'do_eat','症状': 'symptom','检查': 'check','成因': 'cause','预防措施': 'prevent','所属类别': 'category','简介': 'desc','名称': 'name','常用药品' : 'common_drug','治疗费用': 'cost_money','并发症': 'acompany'}self.cuter = CutWords()def collect_medical(self):cates = []inspects = []count = 0# === 修改点:遍历 self.data_list 而不是 MongoDB 的 cursor ===for item in self.data_list: # 直接遍历 JSON 数据data = {}basic_info = item['basic_info']name = basic_info.get('name')if not name:continue# 基本信息data['名称'] = namedesc = basic_info.get('desc', [])data['简介'] = '\n'.join(desc).replace('\r\n\t', '').replace('\r\n\n\n','').replace(' ','').replace('\r\n','\n')category = basic_info.get('category', [])data['所属类别'] = categorycates += categoryinspect = item.get('inspect_info', [])inspects += inspectattributes = basic_info.get('attributes', [])# 成因及预防data['预防措施'] = item.get('prevent_info', '')data['成因'] = item.get('cause_info', '')# 症状symptom_list = item.get("symptom_info", [[]])[0]data['症状'] = list(set([i for i in symptom_list if i and i[0] not in self.stop_words]))# 属性对for attr in attributes:attr_pair = attr.split(':', 1) # 最多分割一次if len(attr_pair) == 2:key = attr_pair[0].strip()value = attr_pair[1].strip()data[key] = value# 检查项目inspects = item.get('inspect_info', [])jcs = []for inspect in inspects:jc_name = self.get_inspect(inspect)if jc_name:jcs.append(jc_name)data['检查'] = jcs# 食物food_info = item.get('food_info', {})if food_info:data['宜食'] = food_info.get('good', [])data['忌食'] = food_info.get('bad', [])data['推荐'] = food_info.get('recommand', [])else:data['宜食'] = []data['忌食'] = []data['推荐'] = []# 药品drug_info = item.get('drug_info', [])data['药品推荐'] = list(set([i.split('(')[-1].replace(')', '') for i in drug_info if '(' in i]))data['药品明细'] = drug_info# 转换为英文字段并清洗data_modify = {}for attr, value in data.items():attr_en = self.key_dict.get(attr)if not attr_en:continue # 忽略没有映射的字段# 特殊字段清洗if attr_en in ['yibao_status', 'get_prob', 'easy_get', 'get_way', "cure_lasttime", "cured_prob"]:data_modify[attr_en] = str(value).replace(' ', '').replace('\t', '')elif attr_en in ['cure_department', 'cure_way', 'common_drug']:if isinstance(value, str):data_modify[attr_en] = [i for i in value.split(' ') if i]else:data_modify[attr_en] = value if isinstance(value, list) else []elif attr_en == 'acompany':# 使用最大双向分词处理并发症raw = value if isinstance(value, str) else ''.join(value)acompany = [i for i in self.cuter.max_biward_cut(raw) if len(i) > 1]data_modify[attr_en] = acompanyelse:data_modify[attr_en] = value# 存入 MongoDB(保留存储逻辑)try:# 注意:这里仍然使用 MongoDB 存结果,如果你也不想存 MongoDB,请改成写入 JSON 或其他方式pymongo.MongoClient()['medical']['medical'].insert_one(data_modify)count += 1print(count)except Exception as e:print(f"插入失败: {e}")print(f"共处理 {count} 条记录")returndef get_inspect(self, url):"""这个函数原来查 MongoDB 的 jc 集合如果你也想从文件读取 jc 数据,可以也改成 JSON 加载"""# 示例:从另一个 JSON 文件加载检查项try:cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])jc_path = os.path.join(cur_dir, 'jc_data.json')with open(jc_path, 'r', encoding='utf-8') as f:jc_data = json.load(f)# 假设 jc_data 是列表,每个元素有 'url' 和 'name'for item in jc_data:if item['url'] == url:return item['name']return ''except:return ''def modify_jc(self):"""如果你还想更新 jc 数据,也可以从 JSON 文件读取并处理但 MongoDB 的 update 操作需要调整或移除"""cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])jc_path = os.path.join(cur_dir, 'jc_data.json')output = []with open(jc_path, 'r', encoding='utf-8') as f:jc_data = json.load(f)for item in jc_data:url = item['url']content = item['html']selector = etree.HTML(content)try:name = selector.xpath('//title/text()')[0].split('结果分析')[0]except:name = item.get('name', url)try:desc = selector.xpath('//meta[@name="description"]/@content')[0].replace('\r\n\t','')except:desc = ''# 更新内存中的数据item['name'] = nameitem['desc'] = descoutput.append(item)# 写回文件(可选)with open(os.path.join(cur_dir, 'jc_data_cleaned.json'), 'w', encoding='utf-8') as f:json.dump(output, f, ensure_ascii=False, indent=2)print("检查项数据清洗完成,已保存到 jc_data_cleaned.json")if __name__ == '__main__':handler = MedicalGraph()handler.collect_medical() # 开始处理max_cut.py
import os
class CutWords:def __init__(self):dict_path = os.path.dirname(os.path.abspath(__file__))# 从 JSON 文件加载数据dict_path = os.path.join(dict_path, 'diseases.json') # 可自定义文件名self.word_dict, self.max_wordlen = self.load_words(dict_path)# 加载词典def load_words(self, dict_path):words = list()max_len = 0for line in open(dict_path, encoding='utf-8'):wd = line.strip()if not wd:continueif len(wd) > max_len:max_len = len(wd)words.append(wd)return words, max_len# 最大向前匹配def max_forward_cut(self, sent):# 1.从左向右取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。# 2.查找大机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。cutlist = []index = 0while index < len(sent):matched = Falsefor i in range(self.max_wordlen, 0, -1):cand_word = sent[index: index + i]if cand_word in self.word_dict:cutlist.append(cand_word)matched = Truebreak# 如果没有匹配上,则按字符切分if not matched:i = 1cutlist.append(sent[index])index += ireturn cutlist# 最大向后匹配def max_backward_cut(self, sent):# 1.从右向左取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。# 2.查找大机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。cutlist = []index = len(sent)max_wordlen = 5while index > 0:matched = Falsefor i in range(self.max_wordlen, 0, -1):tmp = (i + 1)cand_word = sent[index - tmp: index]# 如果匹配上,则将字典中的字符加入到切分字符中if cand_word in self.word_dict:cutlist.append(cand_word)matched = Truebreak# 如果没有匹配上,则按字符切分if not matched:tmp = 1cutlist.append(sent[index - 1])index -= tmpreturn cutlist[::-1]# 双向最大向前匹配def max_biward_cut(self, sent):# 双向最大匹配法是将正向最大匹配法得到的分词结果和逆向最大匹配法的到的结果进行比较,从而决定正确的分词方法。# 启发式规则:# 1.如果正反向分词结果词数不同,则取分词数量较少的那个。# 2.如果分词结果词数相同 a.分词结果相同,就说明没有歧义,可返回任意一个。 b.分词结果不同,返回其中单字较少的那个。forward_cutlist = self.max_forward_cut(sent)backward_cutlist = self.max_backward_cut(sent)count_forward = len(forward_cutlist)count_backward = len(backward_cutlist)def compute_single(word_list):num = 0for word in word_list:if len(word) == 1:num += 1return numif count_forward == count_backward:if compute_single(forward_cutlist) > compute_single(backward_cutlist):return backward_cutlistelse:return forward_cutlistelif count_backward > count_forward:return forward_cutlistelse:return backward_cutlist这段代码实现了一个基于词典的中文分词类 CutWords,采用双向最大匹配算法进行分词。其核心逻辑是:首先从 diseases.json 文件中加载词汇构建词典,并记录词典中最长词的长度;然后分别实现最大正向匹配(从左到右)和最大反向匹配(从右到左)两种分词方法;最后通过 max_biward_cut 方法对两种结果进行比较,采用启发式规则选择最优分词结果——即优先选择分词数量更少的一方,若数量相同则选择单字词更少的一方。该方法能有效处理中文分词中的歧义问题,适用于医疗领域文本的分词任务。
当然我在文件里面放好了构建的数据:也可以直接使用,不需要执行上面的代码

2.构建实体、关系、属性三维列表
def read_nodes(self):"""从 JSON 数据文件中读取疾病数据,提取节点(实体)和关系,用于构建医疗知识图谱。返回所有去重后的节点集合及各类关系列表。"""# ================== 初始化各类节点列表(实体) ==================drugs = [] # 存储药品名称foods = [] # 存储食物名称(宜吃、忌吃、推荐吃)checks = [] # 存储检查项目名称departments = [] # 存储科室名称(如内科、呼吸内科)producers = [] # 存储药品生产厂家diseases = [] # 存储疾病名称symptoms = [] # 存储症状名称disease_infos = [] # 存储每个疾病的详细信息字典# ================== 初始化实体间的关系列表 ==================rels_department = [] # 科室-上级科室关系(如:呼吸内科 -> 内科)rels_noteat = [] # 疾病-忌吃食物关系rels_doeat = [] # 疾病-宜吃食物关系rels_recommandeat = [] # 疾病-推荐吃食物关系rels_commonddrug = [] # 疾病-常用药品关系rels_recommanddrug = [] # 疾病-推荐药品关系rels_check = [] # 疾病-所需检查项目关系rels_drug_producer = [] # 药品-生产厂家关系rels_symptom = [] # 疾病-症状关系rels_acompany = [] # 疾病-并发疾病关系(并发症)rels_category = [] # 疾病-所属科室关系count = 0print("开始构建知识图谱...")'''这是第一条数据 data[0]{"_id": {"$oid": "5bb578b6831b973a137e3ee6"},"name": "肺泡蛋白质沉积症","desc": "肺泡蛋白质沉积症(简称PAP),又称Rosen-Castleman-Liebow综合征,是一种罕见疾病。该病以肺泡和细支气管腔内充满PAS染色阳性,来自肺的富磷脂蛋白质物质为其特征,好发于青中年,男性发病约3倍于女性。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、避免感染分支杆菌病,卡氏肺囊肿肺炎,巨细胞病毒等。2、注意锻炼身体,提高免疫力。","cause": "病因未明,推测与几方面因素有关:如大量粉尘吸入(铝,二氧化硅等),机体免疫功能下降(尤其婴幼儿),遗传因素,酗酒,微生物感染等。对于感染,有时很难确认是原发致病因素还是继发于肺泡蛋白沉着症,例如巨细胞病毒、卡氏肺孢子虫、组织胞浆菌感染等均发现有肺泡内高蛋白沉着。虽然启动因素尚不明确,但基本上同意发病过程为脂质代谢障碍所致,即由于机体内、外因素作用引起肺泡表面活性物质的代谢异常。目前研究较多的是肺泡巨噬细胞活力。动物实验证明巨噬细胞吞噬粉尘后其活力明显下降,而患者灌洗液中的巨噬细胞内颗粒可使正常细胞活力下降。经支气管肺泡灌洗治疗后,其肺泡巨噬细胞活力可上升。研究未发现Ⅱ型肺泡上皮细胞生成蛋白增加,全身脂代谢也无异常。因此目前一般认为本病与清除能力下降有关。","symptom": ["紫绀", "胸痛", "呼吸困难", "乏力", "咳嗽"],"yibao_status": "否","get_prob": "0.00002%","get_way": "无传染性","acompany": ["多重肺部感染"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["支气管肺泡灌洗"],"cure_lasttime": "约3个月","cured_prob": "约40%","cost_money": "根据不同医院,收费标准不一致,省市三甲医院约(8000——15000元)","check": ["胸部CT检查", "肺活检", "支气管镜检查"],"recommand_drug": [],"drug_detail": []}'''# ================== 遍历数据文件中的每一行(每条疾病数据) ==================for data in open(self.data_path, 'r', encoding='utf-8'):disease_dict = {} # 当前疾病的详细信息字典count += 1print(count)data_json = json.loads(data) # 将 JSON 字符串解析为 Python 字典disease = data_json['name']disease_dict['name'] = disease # 记录疾病名称diseases.append(disease)# 初始化疾病详细信息字段,也就是实体的属性信息disease_dict['desc'] = ''disease_dict['prevent'] = ''disease_dict['cause'] = ''disease_dict['easy_get'] = ''disease_dict['cure_department'] = ''disease_dict['cure_way'] = ''disease_dict['cure_lasttime'] = ''disease_dict['symptom'] = ''disease_dict['cured_prob'] = ''# -------------------- 模块1: 处理症状关系 --------------------if 'symptom' in data_json:# 将当前疾病的所有症状加入全局症状列表symptoms += data_json['symptom']# 构建“疾病-症状”关系对for symptom in data_json['symptom']:rels_symptom.append([disease, symptom])# -------------------- 模块2: 处理并发症关系 --------------------if 'acompany' in data_json:# 构建“疾病-并发疾病”关系对for acompany in data_json['acompany']:rels_acompany.append([disease, acompany])# -------------------- 模块3: 处理疾病描述 --------------------if 'desc' in data_json:disease_dict['desc'] = data_json['desc']# -------------------- 模块4: 处理预防措施 --------------------if 'prevent' in data_json:disease_dict['prevent'] = data_json['prevent']# -------------------- 模块5: 处理病因 --------------------if 'cause' in data_json:disease_dict['cause'] = data_json['cause']# -------------------- 模块6: 处理发病率 --------------------if 'get_prob' in data_json:disease_dict['get_prob'] = data_json['get_prob']# -------------------- 模块7: 处理易感人群(注意:字段名可能应为 easy_get,但数据中可能未使用) --------------------if 'easy_get' in data_json:disease_dict['easy_get'] = data_json['easy_get']# -------------------- 模块8: 处理就诊科室 --------------------if 'cure_department' in data_json:cure_department = data_json['cure_department']disease_dict['cure_department'] = cure_departmentdepartments += cure_department # 添加到全局科室列表# 根据科室层级构建关系if len(cure_department) == 1:# 只有一个科室:直接建立疾病与科室的关系rels_category.append([disease, cure_department[0]])elif len(cure_department) == 2:# 有两个科室:认为第二个是子科室,第一个是父科室big = cure_department[0] # 父科室(如:内科)small = cure_department[1] # 子科室(如:呼吸内科)rels_department.append([small, big]) # 子科室 → 父科室rels_category.append([disease, small]) # 疾病 → 子科室# -------------------- 模块9: 处理治疗方式 --------------------if 'cure_way' in data_json:disease_dict['cure_way'] = data_json['cure_way']# -------------------- 模块10: 处理治疗周期 --------------------if 'cure_lasttime' in data_json:disease_dict['cure_lasttime'] = data_json['cure_lasttime']# -------------------- 模块11: 处理治愈概率 --------------------if 'cured_prob' in data_json:disease_dict['cured_prob'] = data_json['cured_prob']# -------------------- 模块12: 处理常用药品 --------------------if 'common_drug' in data_json:common_drug = data_json['common_drug']drugs += common_drug # 添加到全局药品列表# 构建“疾病-常用药品”关系for drug in common_drug:rels_commonddrug.append([disease, drug])# -------------------- 模块13: 处理推荐药品 --------------------if 'recommand_drug' in data_json:recommand_drug = data_json['recommand_drug']drugs += recommand_drug # 添加到全局药品列表# 构建“疾病-推荐药品”关系for drug in recommand_drug:rels_recommanddrug.append([disease, drug])# -------------------- 模块14: 处理饮食禁忌与推荐 --------------------if 'not_eat' in data_json:not_eat = data_json['not_eat']do_eat = data_json['do_eat']recommand_eat = data_json['recommand_eat']# 构建“疾病-忌吃食物”关系for _not in not_eat:rels_noteat.append([disease, _not])foods += not_eat# 构建“疾病-宜吃食物”关系for _do in do_eat:rels_doeat.append([disease, _do])foods += do_eat# 构建“疾病-推荐吃食物”关系for _recommand in recommand_eat:rels_recommandeat.append([disease, _recommand])foods += recommand_eat# -------------------- 模块15: 处理所需检查 --------------------if 'check' in data_json:check = data_json['check']checks += check # 添加到全局检查项目列表# 构建“疾病-检查项目”关系for _check in check:rels_check.append([disease, _check])# -------------------- 模块16: 处理药品详情(含厂家) --------------------if 'drug_detail' in data_json:drug_detail = data_json['drug_detail']# 提取药品名称(括号前部分)producer = [i.split('(')[0] for i in drug_detail]# 提取“药品-厂家”关系对rels_drug_producer += [[i.split('(')[0], i.split('(')[-1].replace(')', '')] for i in drug_detail]producers += producer # 添加到全局厂家列表drugs += producer # 药品名称也加入药品列表# -------------------- 汇总当前疾病信息 --------------------disease_infos.append(disease_dict)# ================== 返回所有去重后的节点和关系列表 ==================return (set(drugs), # 去重药品set(foods), # 去重食物set(checks), # 去重检查set(departments), # 去重科室set(producers), # 去重药厂set(symptoms), # 去重症状set(diseases), # 去重疾病disease_infos, # 疾病详细信息列表# 关系列表rels_check,rels_recommandeat,rels_noteat,rels_doeat,rels_department,rels_commonddrug,rels_drug_producer,rels_recommanddrug,rels_symptom,rels_acompany,rels_category)2.1.知识图谱实体类型
| 实体类型 | 中文含义 | 实体数量 | 举例 |
|---|---|---|---|
| Check | 诊断检查项目 | 3,353 | 支气管造影;关节镜检查 |
| Department | 医疗科目 | 54 | 整形美容科;烧伤科 |
| Disease | 疾病 | 8,807 | 血栓闭塞性脉管炎;胸降主动脉动脉瘤 |
| Drug | 药品 | 3,828 | 京万红痔疮膏;布林佐胺滴眼液 |
| Food | 食物 | 4,870 | 番茄冲菜牛肉丸汤;竹笋炖羊肉 |
| Producer | 在售药品 | 17,201 | 通药制药青霉素V钾片;青阳醋酸地塞米松片 |
| Symptom | 疾病症状 | 5,998 | 乳腺组织肥厚;脑实质深部出血 |
| Total | 总计 | 44,111 | 约4.4万实体量级 |
2.2.知识图谱实体关系
| 实体关系类型 | 中文含义 | 关系数量 | 举例 |
|---|---|---|---|
| belongs_to | 属于 | 8,844 | <妇科,属于,妇产科> |
| common_drug | 疾病常用药品 | 14,649 | <阳强,常用,甲磺酸酚妥拉明分散片> |
| do_eat | 疾病宜吃食物 | 22,238 | <胸椎骨折,宜吃,黑鱼> |
| drugs_of | 药品在售药品 | 17,315 | <青霉素V钾片,在售,通药制药青霉素V钾片> |
| need_check | 疾病所需检查 | 39,422 | <单侧肺气肿,所需检查,支气管造影> |
| no_eat | 疾病忌吃食物 | 22,247 | <唇病,忌吃,杏仁> |
| recommand_drug | 疾病推荐药品 | 59,467 | <混合痔,推荐用药,京万红痔疮膏> |
| recommand_eat | 疾病推荐食谱 | 40,221 | <鞘膜积液,推荐食谱,番茄冲菜牛肉丸汤> |
| has_symptom | 疾病症状 | 5,998 | <早期乳腺癌,疾病症状,乳腺组织肥厚> |
| acompany_with | 疾病并发疾病 | 12,029 | <下肢交通静脉瓣膜关闭不全,并发疾病,血栓闭塞性脉管炎> |
| Total | 总计 | 294,149 | 约30万关系量级 |
2.3.知识图谱属性类型
| 属性类型 | 中文含义 | 举例 |
|---|---|---|
| name | 疾病名称 | 喘息样支气管炎 |
| desc | 疾病简介 | 又称哮喘性支气管炎... |
| cause | 疾病病因 | 常见的有合胞病毒等... |
| prevent | 预防措施 | 注意家族与患儿自身过敏史... |
| cure_lasttime | 治疗周期 | 6-12个月 |
| cure_way | 治疗方式 | "药物治疗","支持性治疗" |
| cured_prob | 治愈概率 | 95% |
| easy_get | 疾病易感人群 | 无特定的人群 |
2.4.创建实体节点、关系、属性
'''建立节点'''def create_node(self, label, nodes):count = 0for node_name in nodes:node = Node(label, name=node_name)self.g.create(node)count += 1print(count, len(nodes))return'''创建知识图谱中心疾病的节点,添加属性'''def create_diseases_nodes(self, disease_infos):count = 0for disease_dict in disease_infos:node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],prevent=disease_dict['prevent'] ,cause=disease_dict['cause'],easy_get=disease_dict['easy_get'],cure_lasttime=disease_dict['cure_lasttime'],cure_department=disease_dict['cure_department'],cure_way=disease_dict['cure_way'] , cured_prob=disease_dict['cured_prob'])self.g.create(node)count += 1print(count)return'''创建知识图谱实体节点类型schema'''def create_graphnodes(self):(Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos,rels_check,rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug,rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category) = self.read_nodes()self.create_diseases_nodes(disease_infos)self.create_node('Drug', Drugs)print(len(Drugs))self.create_node('Food', Foods)print(len(Foods))self.create_node('Check', Checks)print(len(Checks))self.create_node('Department', Departments)print(len(Departments))self.create_node('Producer', Producers)print(len(Producers))self.create_node('Symptom', Symptoms)return'''创建实体关系边'''def create_graphrels(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')'''创建实体关联边'''def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):count = 0# 去重处理set_edges = []for edge in edges:set_edges.append('###'.join(edge))all = len(set(set_edges))for edge in set(set_edges):edge = edge.split('###')p = edge[0]q = edge[1]query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (start_node, end_node, p, q, rel_type, rel_name)try:self.g.run(query)count += 1print(rel_type, count, all)except Exception as e:print(e)return
完整代码:
import os
import json
from py2neo import Graph,Nodeclass MedicalGraph:def __init__(self):cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])self.data_path = os.path.join(cur_dir, 'data/medical.json')self.g = Graph(host="127.0.0.1", # neo4j 搭载服务器的ip地址,ifconfig可获取到# http_port=7474, # neo4j 服务器监听的端口号user="neo4j", # 数据库user name,如果没有更改过,应该是neo4jpassword="gyp123456789")print("知识图谱连接成功!")'''读取文件'''def read_nodes(self):"""从 JSON 数据文件中读取疾病数据,提取节点(实体)和关系,用于构建医疗知识图谱。返回所有去重后的节点集合及各类关系列表。"""# ================== 初始化各类节点列表(实体) ==================drugs = [] # 存储药品名称foods = [] # 存储食物名称(宜吃、忌吃、推荐吃)checks = [] # 存储检查项目名称departments = [] # 存储科室名称(如内科、呼吸内科)producers = [] # 存储药品生产厂家diseases = [] # 存储疾病名称symptoms = [] # 存储症状名称disease_infos = [] # 存储每个疾病的详细信息字典# ================== 初始化实体间的关系列表 ==================rels_department = [] # 科室-上级科室关系(如:呼吸内科 -> 内科)rels_noteat = [] # 疾病-忌吃食物关系rels_doeat = [] # 疾病-宜吃食物关系rels_recommandeat = [] # 疾病-推荐吃食物关系rels_commonddrug = [] # 疾病-常用药品关系rels_recommanddrug = [] # 疾病-推荐药品关系rels_check = [] # 疾病-所需检查项目关系rels_drug_producer = [] # 药品-生产厂家关系rels_symptom = [] # 疾病-症状关系rels_acompany = [] # 疾病-并发疾病关系(并发症)rels_category = [] # 疾病-所属科室关系count = 0print("开始构建知识图谱...")'''这是第一条数据 data[0]{"_id": {"$oid": "5bb578b6831b973a137e3ee6"},"name": "肺泡蛋白质沉积症","desc": "肺泡蛋白质沉积症(简称PAP),又称Rosen-Castleman-Liebow综合征,是一种罕见疾病。该病以肺泡和细支气管腔内充满PAS染色阳性,来自肺的富磷脂蛋白质物质为其特征,好发于青中年,男性发病约3倍于女性。","category": ["疾病百科", "内科", "呼吸内科"],"prevent": "1、避免感染分支杆菌病,卡氏肺囊肿肺炎,巨细胞病毒等。2、注意锻炼身体,提高免疫力。","cause": "病因未明,推测与几方面因素有关:如大量粉尘吸入(铝,二氧化硅等),机体免疫功能下降(尤其婴幼儿),遗传因素,酗酒,微生物感染等。对于感染,有时很难确认是原发致病因素还是继发于肺泡蛋白沉着症,例如巨细胞病毒、卡氏肺孢子虫、组织胞浆菌感染等均发现有肺泡内高蛋白沉着。虽然启动因素尚不明确,但基本上同意发病过程为脂质代谢障碍所致,即由于机体内、外因素作用引起肺泡表面活性物质的代谢异常。目前研究较多的是肺泡巨噬细胞活力。动物实验证明巨噬细胞吞噬粉尘后其活力明显下降,而患者灌洗液中的巨噬细胞内颗粒可使正常细胞活力下降。经支气管肺泡灌洗治疗后,其肺泡巨噬细胞活力可上升。研究未发现Ⅱ型肺泡上皮细胞生成蛋白增加,全身脂代谢也无异常。因此目前一般认为本病与清除能力下降有关。","symptom": ["紫绀", "胸痛", "呼吸困难", "乏力", "咳嗽"],"yibao_status": "否","get_prob": "0.00002%","get_way": "无传染性","acompany": ["多重肺部感染"],"cure_department": ["内科", "呼吸内科"],"cure_way": ["支气管肺泡灌洗"],"cure_lasttime": "约3个月","cured_prob": "约40%","cost_money": "根据不同医院,收费标准不一致,省市三甲医院约(8000——15000元)","check": ["胸部CT检查", "肺活检", "支气管镜检查"],"recommand_drug": [],"drug_detail": []}'''# ================== 遍历数据文件中的每一行(每条疾病数据) ==================for data in open(self.data_path, 'r', encoding='utf-8'):disease_dict = {} # 当前疾病的详细信息字典count += 1print(count)data_json = json.loads(data) # 将 JSON 字符串解析为 Python 字典disease = data_json['name']disease_dict['name'] = disease # 记录疾病名称diseases.append(disease)# 初始化疾病详细信息字段disease_dict['desc'] = ''disease_dict['prevent'] = ''disease_dict['cause'] = ''disease_dict['easy_get'] = ''disease_dict['cure_department'] = ''disease_dict['cure_way'] = ''disease_dict['cure_lasttime'] = ''disease_dict['symptom'] = ''disease_dict['cured_prob'] = ''# -------------------- 模块1: 处理症状关系 --------------------if 'symptom' in data_json:# 将当前疾病的所有症状加入全局症状列表symptoms += data_json['symptom']# 构建“疾病-症状”关系对for symptom in data_json['symptom']:rels_symptom.append([disease, symptom])# -------------------- 模块2: 处理并发症关系 --------------------if 'acompany' in data_json:# 构建“疾病-并发疾病”关系对for acompany in data_json['acompany']:rels_acompany.append([disease, acompany])# -------------------- 模块3: 处理疾病描述 --------------------if 'desc' in data_json:disease_dict['desc'] = data_json['desc']# -------------------- 模块4: 处理预防措施 --------------------if 'prevent' in data_json:disease_dict['prevent'] = data_json['prevent']# -------------------- 模块5: 处理病因 --------------------if 'cause' in data_json:disease_dict['cause'] = data_json['cause']# -------------------- 模块6: 处理发病率 --------------------if 'get_prob' in data_json:disease_dict['get_prob'] = data_json['get_prob']# -------------------- 模块7: 处理易感人群(注意:字段名可能应为 easy_get,但数据中可能未使用) --------------------if 'easy_get' in data_json:disease_dict['easy_get'] = data_json['easy_get']# -------------------- 模块8: 处理就诊科室 --------------------if 'cure_department' in data_json:cure_department = data_json['cure_department']disease_dict['cure_department'] = cure_departmentdepartments += cure_department # 添加到全局科室列表# 根据科室层级构建关系if len(cure_department) == 1:# 只有一个科室:直接建立疾病与科室的关系rels_category.append([disease, cure_department[0]])elif len(cure_department) == 2:# 有两个科室:认为第二个是子科室,第一个是父科室big = cure_department[0] # 父科室(如:内科)small = cure_department[1] # 子科室(如:呼吸内科)rels_department.append([small, big]) # 子科室 → 父科室rels_category.append([disease, small]) # 疾病 → 子科室# -------------------- 模块9: 处理治疗方式 --------------------if 'cure_way' in data_json:disease_dict['cure_way'] = data_json['cure_way']# -------------------- 模块10: 处理治疗周期 --------------------if 'cure_lasttime' in data_json:disease_dict['cure_lasttime'] = data_json['cure_lasttime']# -------------------- 模块11: 处理治愈概率 --------------------if 'cured_prob' in data_json:disease_dict['cured_prob'] = data_json['cured_prob']# -------------------- 模块12: 处理常用药品 --------------------if 'common_drug' in data_json:common_drug = data_json['common_drug']drugs += common_drug # 添加到全局药品列表# 构建“疾病-常用药品”关系for drug in common_drug:rels_commonddrug.append([disease, drug])# -------------------- 模块13: 处理推荐药品 --------------------if 'recommand_drug' in data_json:recommand_drug = data_json['recommand_drug']drugs += recommand_drug # 添加到全局药品列表# 构建“疾病-推荐药品”关系for drug in recommand_drug:rels_recommanddrug.append([disease, drug])# -------------------- 模块14: 处理饮食禁忌与推荐 --------------------if 'not_eat' in data_json:not_eat = data_json['not_eat']do_eat = data_json['do_eat']recommand_eat = data_json['recommand_eat']# 构建“疾病-忌吃食物”关系for _not in not_eat:rels_noteat.append([disease, _not])foods += not_eat# 构建“疾病-宜吃食物”关系for _do in do_eat:rels_doeat.append([disease, _do])foods += do_eat# 构建“疾病-推荐吃食物”关系for _recommand in recommand_eat:rels_recommandeat.append([disease, _recommand])foods += recommand_eat# -------------------- 模块15: 处理所需检查 --------------------if 'check' in data_json:check = data_json['check']checks += check # 添加到全局检查项目列表# 构建“疾病-检查项目”关系for _check in check:rels_check.append([disease, _check])# -------------------- 模块16: 处理药品详情(含厂家) --------------------if 'drug_detail' in data_json:drug_detail = data_json['drug_detail']# 提取药品名称(括号前部分)producer = [i.split('(')[0] for i in drug_detail]# 提取“药品-厂家”关系对rels_drug_producer += [[i.split('(')[0], i.split('(')[-1].replace(')', '')] for i in drug_detail]producers += producer # 添加到全局厂家列表drugs += producer # 药品名称也加入药品列表# -------------------- 汇总当前疾病信息 --------------------disease_infos.append(disease_dict)# ================== 返回所有去重后的节点和关系列表 ==================return (set(drugs), # 去重药品set(foods), # 去重食物set(checks), # 去重检查set(departments), # 去重科室set(producers), # 去重药厂set(symptoms), # 去重症状set(diseases), # 去重疾病disease_infos, # 疾病详细信息列表# 关系列表rels_check,rels_recommandeat,rels_noteat,rels_doeat,rels_department,rels_commonddrug,rels_drug_producer,rels_recommanddrug,rels_symptom,rels_acompany,rels_category)'''建立节点'''def create_node(self, label, nodes):count = 0for node_name in nodes:node = Node(label, name=node_name)self.g.create(node)count += 1print(count, len(nodes))return'''创建知识图谱中心疾病的节点,添加属性'''def create_diseases_nodes(self, disease_infos):count = 0for disease_dict in disease_infos:node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],prevent=disease_dict['prevent'] ,cause=disease_dict['cause'],easy_get=disease_dict['easy_get'],cure_lasttime=disease_dict['cure_lasttime'],cure_department=disease_dict['cure_department'],cure_way=disease_dict['cure_way'] , cured_prob=disease_dict['cured_prob'])self.g.create(node)count += 1print(count)return'''创建知识图谱实体节点类型schema'''def create_graphnodes(self):(Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos,rels_check,rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug,rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category) = self.read_nodes()self.create_diseases_nodes(disease_infos)self.create_node('Drug', Drugs)print(len(Drugs))self.create_node('Food', Foods)print(len(Foods))self.create_node('Check', Checks)print(len(Checks))self.create_node('Department', Departments)print(len(Departments))self.create_node('Producer', Producers)print(len(Producers))self.create_node('Symptom', Symptoms)return'''创建实体关系边'''def create_graphrels(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')'''创建实体关联边'''def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):count = 0# 去重处理set_edges = []for edge in edges:set_edges.append('###'.join(edge))all = len(set(set_edges))for edge in set(set_edges):edge = edge.split('###')p = edge[0]q = edge[1]query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (start_node, end_node, p, q, rel_type, rel_name)try:self.g.run(query)count += 1print(rel_type, count, all)except Exception as e:print(e)return'''导出数据'''def export_data(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug, rels_symptom, rels_acompany, rels_category = self.read_nodes()f_drug = open('drug.txt', 'w+', encoding='utf-8')f_food = open('food.txt', 'w+', encoding='utf-8')f_check = open('check.txt', 'w+', encoding='utf-8')f_department = open('department.txt', 'w+', encoding='utf-8')f_producer = open('producer.txt', 'w+',encoding='utf-8')f_symptom = open('symptoms.txt', 'w+',encoding='utf-8')f_disease = open('disease.txt', 'w+',encoding='utf-8')f_drug.write('\n'.join(list(Drugs)))f_food.write('\n'.join(list(Foods)))f_check.write('\n'.join(list(Checks)))f_department.write('\n'.join(list(Departments)))f_producer.write('\n'.join(list(Producers)))f_symptom.write('\n'.join(list(Symptoms)))f_disease.write('\n'.join(list(Diseases)))f_drug.close()f_food.close()f_check.close()f_department.close()f_producer.close()f_symptom.close()f_disease.close()returnif __name__ == '__main__':handler = MedicalGraph()print("step1:导入图谱节点中")handler.create_graphnodes()print("step2:导入图谱边中")handler.create_graphrels()print("构建知识图谱完成,可以直接使用Neo4j可视化工具进行可视化展示")导入的数据较多,估计需要一个多小时。
看一下效果:
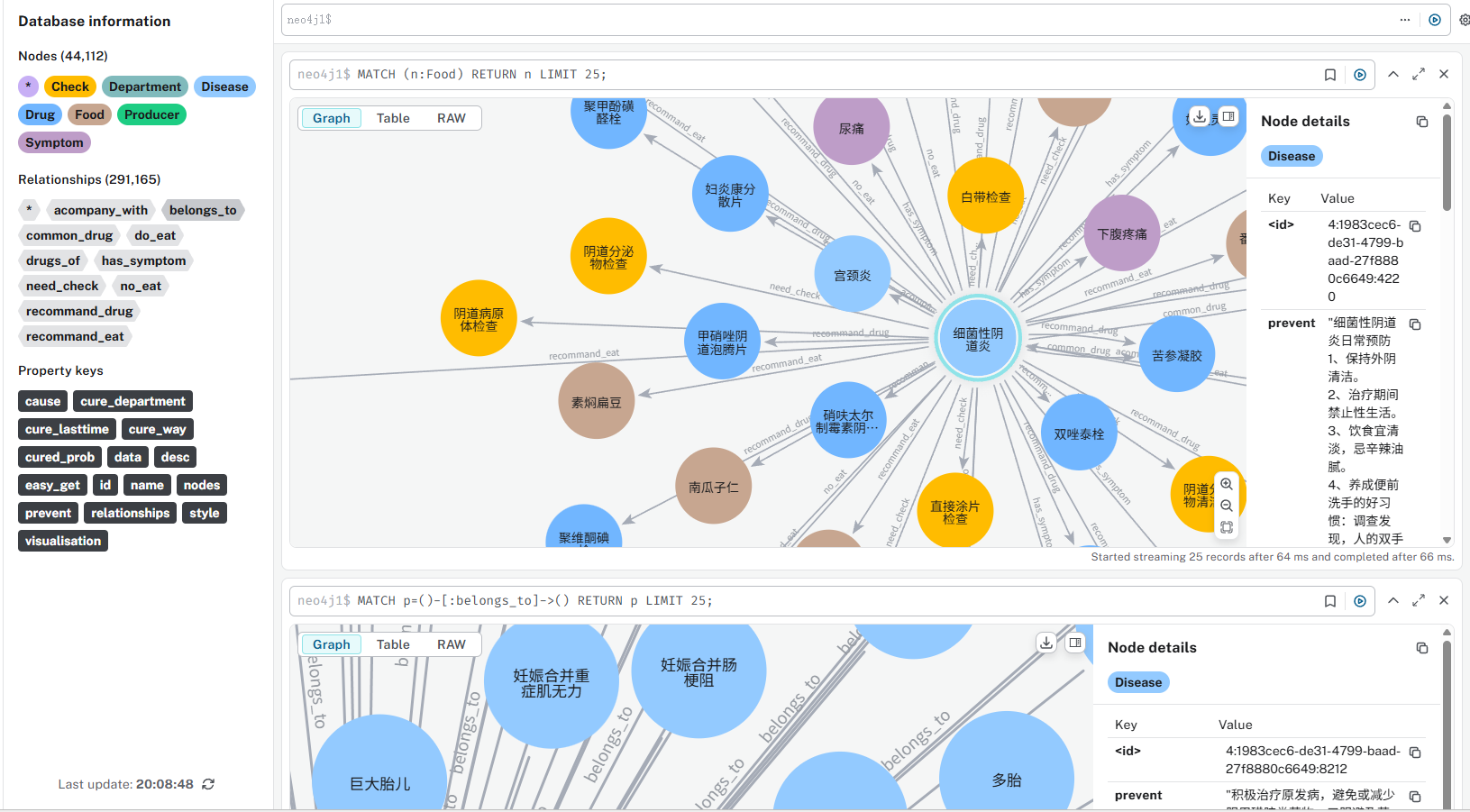
3.基于知识图谱的问答构建
注意:这里只有单纯的知识图谱查询回答,没有结合大模型,这个GraphRAG后面项目再补充
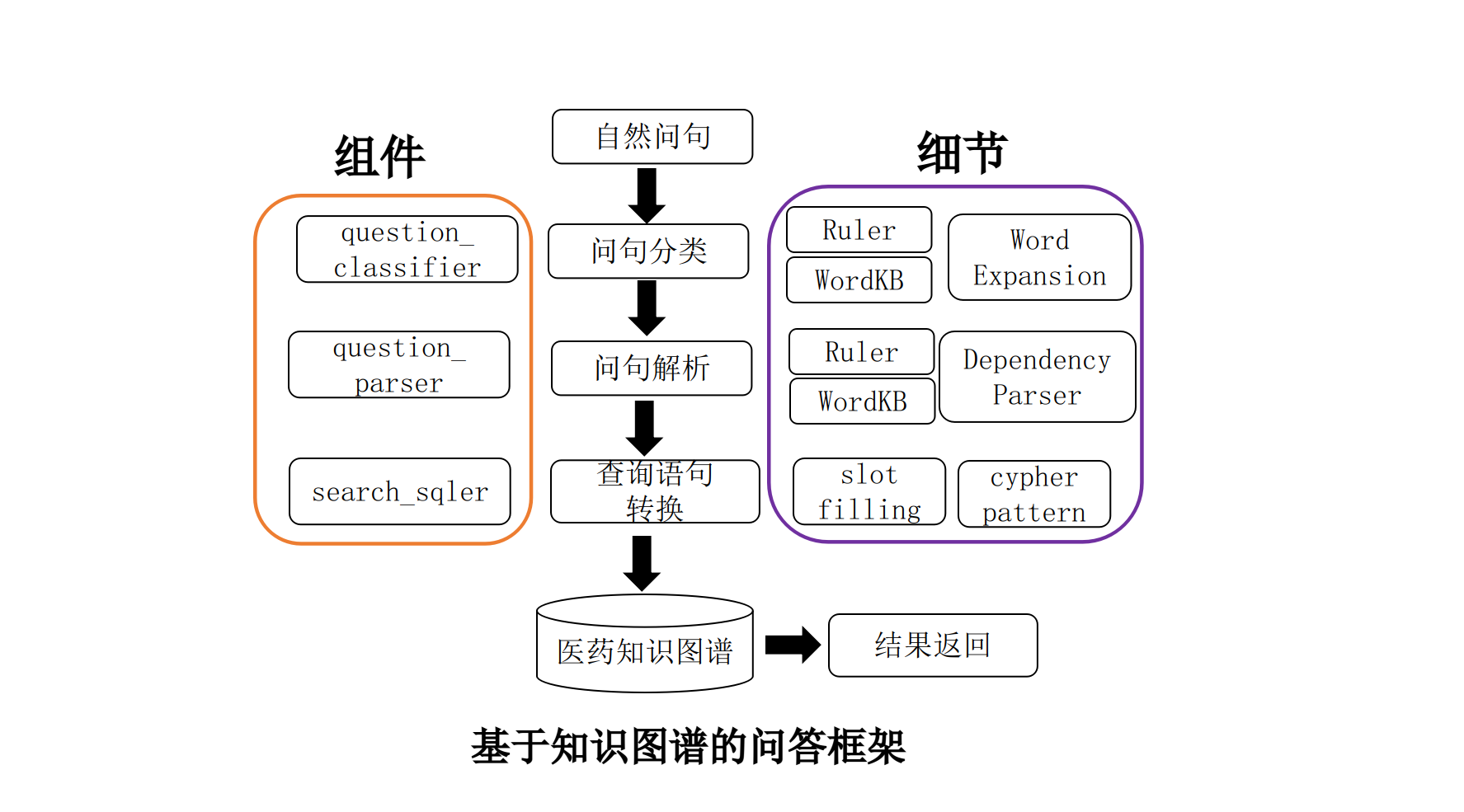
支持问答类型
| 问句类型 | 中文含义 | 问句举例 |
|---|---|---|
| disease_symptom | 疾病症状 | 乳腺癌的症状有哪些? |
| symptom_disease | 已知症状找可能疾病 | 最近老流鼻涕怎么办? |
| disease_cause | 疾病病因 | 为什么有的人会失眠? |
| disease_acompany | 疾病的并发症 | 失眠有哪些并发症? |
| disease_not_food | 疾病需要忌口的食物 | 失眠的人不要吃啥? |
| disease_do_food | 疾病建议吃什么食物 | 耳鸣了吃点啥? |
| food_not_disease | 什么病最好不要吃某事物 | 哪些人最好不好吃蜂蜜? |
| food_do_disease | 食物对什么病有好处 | 鹅肉有什么好处? |
| disease_drug | 啥病要吃啥药 | 肝病要吃啥药? |
| drug_disease | 药品能治啥病 | 板蓝根颗粒能治啥病? |
| disease_check | 疾病需要做什么检查 | 脑膜炎怎么才能查出来? |
| check_disease | 检查能查什么病 | 全血细胞计数能查出啥来? |
| disease_prevent | 预防措施 | 怎样才能预防肾虚? |
| disease_lasttime | 治疗周期 | 感冒要多久才能好? |
| disease_cureway | 治疗方式 | 高血压要怎么治? |
| disease_cureprob | 治愈概率 | 白血病能治好吗? |
| disease_easyget | 疾病易感人群 | 什么人容易得高血压? |
| disease_desc | 疾病描述 | 糖尿病 |
3.1.问题分类
| 模块 | 功能 |
|---|---|
__init__ | 加载各类医学词典(疾病、症状、药品、食物等),构建 AC 自动机和词-类型映射字典 |
build_actree | 使用 ahocorasick 库构建多模式字符串匹配自动机,提升实体识别效率 |
check_medical | 利用 AC 自动机从问题中提取所有医学实体,并去重、去除子串(例如保留“病毒性肺炎”而非“肺炎”) |
classify | 主分类逻辑:根据关键词 + 实体类型组合判断用户意图(问题类型) |
check_words | 判断一句话是否包含某个关键词列表中的任意词 |
import os
import ahocorasick # 用于高效多模式字符串匹配(AC自动机)class QuestionClassifier:"""问题分类器:根据用户输入的问题,识别其中的医学实体(如疾病、症状、药品等),并结合关键词判断问题类型,用于后续的知识图谱查询。"""def __init__(self):"""初始化分类器,加载词典、构建AC自动机、定义问题关键词等。"""# 获取当前文件所在目录路径(用于相对路径加载词典)cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])# ------------------- 定义各类医学实体词典文件路径 -------------------self.disease_path = os.path.join(cur_dir, 'dict/disease.txt') # 疾病词典self.department_path = os.path.join(cur_dir, 'dict/department.txt') # 科室词典self.check_path = os.path.join(cur_dir, 'dict/check.txt') # 检查项目词典self.drug_path = os.path.join(cur_dir, 'dict/drug.txt') # 药品词典self.food_path = os.path.join(cur_dir, 'dict/food.txt') # 食物词典self.producer_path = os.path.join(cur_dir, 'dict/producer.txt') # 药品厂商词典self.symptom_path = os.path.join(cur_dir, 'dict/symptom.txt') # 症状词典self.deny_path = os.path.join(cur_dir, 'dict/deny.txt') # 否定词词典(如“不”、“忌”)# ------------------- 加载各类特征词 -------------------# 每个词表读取为列表,去除空行和首尾空格self.disease_wds = [i.strip() for i in open(self.disease_path, encoding='utf-8') if i.strip()]self.department_wds = [i.strip() for i in open(self.department_path, encoding='utf-8') if i.strip()]self.check_wds = [i.strip() for i in open(self.check_path, encoding='utf-8') if i.strip()]self.drug_wds = [i.strip() for i in open(self.drug_path, encoding='utf-8') if i.strip()]self.food_wds = [i.strip() for i in open(self.food_path, encoding='utf-8') if i.strip()]self.producer_wds = [i.strip() for i in open(self.producer_path, encoding='utf-8') if i.strip()]self.symptom_wds = [i.strip() for i in open(self.symptom_path, encoding='utf-8') if i.strip()]self.deny_words = [i.strip() for i in open(self.deny_path, encoding='utf-8') if i.strip()]# 所有医学相关词汇的并集(用于实体识别)self.region_words = set(self.disease_wds + self.department_wds + self.check_wds +self.drug_wds + self.food_wds + self.producer_wds + self.symptom_wds)# ------------------- 构建AC自动机(用于快速实体识别) -------------------# AC自动机可高效匹配文本中所有出现的医学词汇self.region_tree = self.build_actree(list(self.region_words))# ------------------- 构建词 -> 类型映射字典 -------------------# 例如:{'感冒': ['disease'], '头痛': ['symptom'], '阿司匹林': ['drug']}self.wdtype_dict = self.build_wdtype_dict()# ------------------- 定义各类问题的疑问词(关键词) -------------------# 根据这些关键词判断用户想问什么类型的问题# 症状类问题关键词self.symptom_qwds = ['症状', '表征', '现象', '症候', '表现']# 病因类问题关键词self.cause_qwds = ['原因','成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何','如何才会', '怎么才会', '会导致', '会造成']# 并发症类问题关键词self.acompany_qwds = ['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现','伴随发生', '伴随', '共现']# 饮食类问题关键词self.food_qwds = ['饮食', '饮用', '吃', '食', '伙食', '膳食', '喝', '菜', '忌口', '补品', '保健品', '食谱','菜谱', '食用', '食物', '补品']# 药品类问题关键词self.drug_qwds = ['药', '药品', '用药', '胶囊', '口服液', '炎片']# 预防类问题关键词self.prevent_qwds = ['预防', '防范', '抵制', '抵御', '防止','躲避','逃避','避开','免得','逃开','避开','避掉','躲开','躲掉','绕开','怎样才能不', '怎么才能不', '咋样才能不','咋才能不', '如何才能不','怎样才不', '怎么才不', '咋样才不','咋才不', '如何才不','怎样才可以不', '怎么才可以不', '咋样才可以不', '咋才可以不', '如何可以不','怎样才可不', '怎么才可不', '咋样才可不', '咋才可不', '如何可不']# 治疗周期类问题关键词self.lasttime_qwds = ['周期', '多久', '多长时间', '多少时间', '几天', '几年', '多少天', '多少小时','几个小时', '多少年']# 治疗方式类问题关键词self.cureway_qwds = ['怎么治疗', '如何医治', '怎么医治', '怎么治', '怎么医', '如何治', '医治方式', '疗法','咋治', '怎么办', '咋办', '咋治']# 治愈概率类问题关键词self.cureprob_qwds = ['多大概率能治好', '多大几率能治好', '治好希望大么', '几率', '几成', '比例', '可能性','能治', '可治', '可以治', '可以医']# 易感人群类问题关键词self.easyget_qwds = ['易感人群', '容易感染', '易发人群', '什么人', '哪些人', '感染', '染上', '得上']# 检查类问题关键词self.check_qwds = ['检查', '检查项目', '查出', '检查', '测出', '试出']# 科室归属类问题关键词self.belong_qwds = ['属于什么科', '属于', '什么科', '科室']# “能治什么病”类问题关键词(用于药品/检查反向查询)self.cure_qwds = ['治疗什么', '治啥', '治疗啥', '医治啥', '治愈啥', '主治啥', '主治什么', '有什么用', '有何用','用处', '用途', '有什么好处', '有什么益处', '有何益处', '用来', '用来做啥', '用来作甚','需要', '要']print('model init finished ......')def classify(self, question):"""主分类函数:接收用户问题,识别实体并分类问题类型。Args:question (str): 用户输入的问题文本Returns:dict: 包含识别出的实体和问题类型的字典,格式如下:{'args': {'感冒': ['disease'], '头痛': ['symptom']},'question_types': ['disease_symptom']}"""data = {}# 第一步:识别问题中出现的医学实体medical_dict = self.check_medical(question)# 如果没有识别出任何医学实体,返回空结果if not medical_dict:return {}data['args'] = medical_dict # 存储识别出的实体及其类型# 收集所有识别出的实体类型(如 disease, symptom 等)types = []for type_list in medical_dict.values():types.extend(type_list)types = list(set(types)) # 去重question_types = [] # 存储所有可能的问题类型# -------------------- 分类逻辑:根据关键词+实体类型判断问题意图 --------------------# 1. 疾病相关症状if self.check_words(self.symptom_qwds, question) and ('disease' in types):question_types.append('disease_symptom')# 2. 症状对应哪些疾病if self.check_words(self.symptom_qwds, question) and ('symptom' in types):question_types.append('symptom_disease')# 3. 疾病的病因if self.check_words(self.cause_qwds, question) and ('disease' in types):question_types.append('disease_cause')# 4. 疾病的并发症if self.check_words(self.acompany_qwds, question) and ('disease' in types):question_types.append('disease_acompany')# 5. 疾病宜吃/忌吃食物(需结合否定词判断)if self.check_words(self.food_qwds, question) and ('disease' in types):deny_status = self.check_words(self.deny_words, question)question_type = 'disease_not_food' if deny_status else 'disease_do_food'question_types.append(question_type)# 6. 食物对应哪些疾病(推荐/禁忌)if self.check_words(self.food_qwds + self.cure_qwds, question) and ('food' in types):deny_status = self.check_words(self.deny_words, question)question_type = 'food_not_disease' if deny_status else 'food_do_disease'question_types.append(question_type)# 7. 疾病推荐药品if self.check_words(self.drug_qwds, question) and ('disease' in types):question_types.append('disease_drug')# 8. 药品能治什么病if self.check_words(self.cure_qwds, question) and ('drug' in types):question_types.append('drug_disease')# 9. 疾病需要做哪些检查if self.check_words(self.check_qwds, question) and ('disease' in types):question_types.append('disease_check')# 10. 检查项目用于诊断哪些疾病if self.check_words(self.check_qwds + self.cure_qwds, question) and ('check' in types):question_types.append('check_disease')# 11. 疾病如何预防if self.check_words(self.prevent_qwds, question) and ('disease' in types):question_types.append('disease_prevent')# 12. 疾病治疗周期if self.check_words(self.lasttime_qwds, question) and ('disease' in types):question_types.append('disease_lasttime')# 13. 疾病治疗方式if self.check_words(self.cureway_qwds, question) and ('disease' in types):question_types.append('disease_cureway')# 14. 疾病治愈概率if self.check_words(self.cureprob_qwds, question) and ('disease' in types):question_types.append('disease_cureprob')# 15. 疾病易感人群if self.check_words(self.easyget_qwds, question) and ('disease' in types):question_types.append('disease_easyget')# 16. 默认返回疾病描述(未匹配具体问题类型但包含疾病)if not question_types and 'disease' in types:question_types = ['disease_desc']# 17. 默认返回症状相关疾病(仅提到症状)if not question_types and 'symptom' in types:question_types = ['symptom_disease']# ------------------- 返回最终分类结果 -------------------data['question_types'] = question_typesprint("分类结果:", data)return datadef build_wdtype_dict(self):"""构建词汇到类型的映射字典。一个词可能属于多个类型(如“感冒药”既是药也是症状相关词,但此处按精确匹配)。Returns:dict: 如 {'感冒': ['disease'], '头痛': ['symptom'], '阿司匹林': ['drug']}"""wd_dict = {}for wd in self.region_words:wd_dict[wd] = []if wd in self.disease_wds:wd_dict[wd].append('disease')if wd in self.department_wds:wd_dict[wd].append('department')if wd in self.check_wds:wd_dict[wd].append('check')if wd in self.drug_wds:wd_dict[wd].append('drug')if wd in self.food_wds:wd_dict[wd].append('food')if wd in self.symptom_wds:wd_dict[wd].append('symptom')if wd in self.producer_wds:wd_dict[wd].append('producer')return wd_dictdef build_actree(self, wordlist):"""使用 ahocorasick 构建AC自动机,实现高效多关键词匹配。Args:wordlist (list): 词汇列表Returns:ahocorasick.Automaton: 构建好的AC自动机对象"""actree = ahocorasick.Automaton()for index, word in enumerate(wordlist):actree.add_word(word, (index, word)) # (word, value) 存储索引和词本身actree.make_automaton() # 构建失败指针,完成自动机构建return actreedef check_medical(self, question):"""使用AC自动机从问题中提取所有医学实体,并去除包含关系中的子串(如“肺炎”和“病毒性肺炎”共现时保留长的)。Args:question (str): 用户问题Returns:dict: 识别出的实体及其类型,如 {'肺炎': ['disease'], '头痛': ['symptom']}"""region_wds = [] # 存储所有匹配到的词for match in self.region_tree.iter(question): # AC自动机匹配word = match[1][1] # 提取匹配到的词region_wds.append(word)# 去除包含关系中的短词(避免“肺炎”和“病毒性肺炎”同时出现)stop_wds = []for wd1 in region_wds:for wd2 in region_wds:if wd1 in wd2 and wd1 != wd2: # wd1 被 wd2 包含stop_wds.append(wd1)final_wds = [wd for wd in region_wds if wd not in stop_wds] # 过滤后保留长词# 构建最终实体 -> 类型字典final_dict = {wd: self.wdtype_dict.get(wd, []) for wd in final_wds}return final_dictdef check_words(self, wds, sent):"""判断句子中是否包含任一关键词。Args:wds (list): 关键词列表sent (str): 句子Returns:bool: 是否包含"""for wd in wds:if wd in sent:return Truereturn False# ==================== 主程序入口 ====================
if __name__ == '__main__':"""测试用例:启动一个交互式命令行,输入问题并输出分类结果。"""handler = QuestionClassifier()while True:question = input('请输入问题')data = handler.classify(question)print("分类结果:", data)3.2.生成查询
class QuestionPaser:'''构建实体字典:将分类器识别出的实体按类型分组'''def build_entitydict(self, args):"""将输入的实体及其类型转换为按类型组织的字典。Args:args (dict): 例如 {'感冒': ['disease'], '头痛': ['symptom']}Returns:dict: 按类型分组的实体字典,例如 {'disease': ['感冒'], 'symptom': ['头痛']}"""entity_dict = {}for arg, types in args.items():for type in types:if type not in entity_dict:# 如果该类型还未在字典中,创建一个新列表entity_dict[type] = [arg]else:# 否则追加到已有列表中entity_dict[type].append(arg)return entity_dict'''解析主函数:根据问题类型生成对应的数据库查询语句'''def parser_main(self, res_classify):"""主要解析函数,接收分类结果并生成相应的 Cypher 查询语句。Args:res_classify (dict): 分类器输出的结果,包含 args 和 question_typesReturns:list: 包含多个查询结构的列表,每个元素是 {'question_type': str, 'sql': list}"""# 提取识别出的实体args = res_classify['args']# 构建按类型分组的实体字典entity_dict = self.build_entitydict(args)# 获取问题类型列表(如 ['disease_symptom'])question_types = res_classify['question_types']# 存储最终生成的所有 SQL(Cypher)语句sqls = []# 遍历每一种问题类型for question_type in question_types:# 初始化当前查询结构sql_ = {}sql_['question_type'] = question_typesql = [] # 当前类型的查询语句列表# 根据不同的问题类型调用 sql_transfer 方法生成查询语句if question_type == 'disease_symptom':# 疾病 → 症状sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'symptom_disease':# 症状 → 可能的疾病sql = self.sql_transfer(question_type, entity_dict.get('symptom'))elif question_type == 'disease_cause':# 疾病 → 原因sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_acompany':# 疾病 → 并发症sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_not_food':# 疾病 → 忌吃食物sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_do_food':# 疾病 → 宜吃/推荐食物sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'food_not_disease':# 食物 → 哪些疾病不能吃它sql = self.sql_transfer(question_type, entity_dict.get('food'))elif question_type == 'food_do_disease':# 食物 → 哪些疾病推荐吃它sql = self.sql_transfer(question_type, entity_dict.get('food'))elif question_type == 'disease_drug':# 疾病 → 推荐药品sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'drug_disease':# 药品 → 可治疗的疾病sql = self.sql_transfer(question_type, entity_dict.get('drug'))elif question_type == 'disease_check':# 疾病 → 需要做哪些检查sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'check_disease':# 检查项目 → 可能用于诊断哪些疾病sql = self.sql_transfer(question_type, entity_dict.get('check'))elif question_type == 'disease_prevent':# 疾病 → 如何预防sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_lasttime':# 疾病 → 治疗周期/持续时间sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_cureway':# 疾病 → 治疗方式sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_cureprob':# 疾病 → 治愈概率sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_easyget':# 疾病 → 易感人群sql = self.sql_transfer(question_type, entity_dict.get('disease'))elif question_type == 'disease_desc':# 疾病 → 基本介绍/描述sql = self.sql_transfer(question_type, entity_dict.get('disease'))# 如果成功生成了查询语句,则加入最终结果if sql:sql_['sql'] = sqlsqls.append(sql_)return sqls'''根据问题类型和实体生成具体的 Cypher 查询语句'''def sql_transfer(self, question_type, entities):"""核心方法:根据问题类型和相关实体生成 Neo4j 图数据库的查询语句(Cypher)Args:question_type (str): 问题类型,如 'disease_symptom'entities (list or None): 实体名称列表,如 ['感冒', '糖尿病']Returns:list: 生成的 Cypher 查询语句字符串列表"""# 如果没有提取到有效实体,返回空列表if not entities:return []# 存储生成的查询语句sql = []# ================== 单向属性查询(节点自身属性)==================# 查询疾病的原因if question_type == 'disease_cause':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.cause".format(i)for i in entities]# 查询疾病的预防措施elif question_type == 'disease_prevent':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.prevent".format(i)for i in entities]# 查询疾病的持续时间(治疗周期)elif question_type == 'disease_lasttime':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.cure_lasttime".format(i)for i in entities]# 查询疾病的治愈概率elif question_type == 'disease_cureprob':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.cured_prob".format(i)for i in entities]# 查询疾病的治疗方式elif question_type == 'disease_cureway':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.cure_way".format(i)for i in entities]# 查询疾病的易感人群elif question_type == 'disease_easyget':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.easy_get".format(i)for i in entities]# 查询疾病的基本描述elif question_type == 'disease_desc':sql = ["MATCH (m:Disease) WHERE m.name = '{0}' RETURN m.name, m.desc".format(i)for i in entities]# ================== 关系型查询(通过边查询其他节点)==================# 查询疾病有哪些症状elif question_type == 'disease_symptom':sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]# 查询某个症状可能对应哪些疾病(逆向关系)elif question_type == 'symptom_disease':sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]# 查询疾病的并发症(双向:该病引发的 + 会引发该病的)elif question_type == 'disease_acompany':# 1. 该病会并发哪些其他疾病sql1 = ["MATCH (m:Disease)-[r:acompany_with]->(n:Disease) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]# 2. 哪些疾病会并发此病(即它是别人的并发症)sql2 = ["MATCH (m:Disease)-[r:acompany_with]->(n:Disease) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql = sql1 + sql2 # 合并两个方向的查询# 查询疾病忌吃的食物elif question_type == 'disease_not_food':sql = ["MATCH (m:Disease)-[r:no_eat]->(n:Food) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]# 查询疾病宜吃或推荐的食物(两种关系合并)elif question_type == 'disease_do_food':sql1 = ["MATCH (m:Disease)-[r:do_eat]->(n:Food) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql2 = ["MATCH (m:Disease)-[r:recommand_eat]->(n:Food) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql = sql1 + sql2# 已知某种食物不能吃,反查哪些疾病需要忌口elif question_type == 'food_not_disease':sql = ["MATCH (m:Disease)-[r:no_eat]->(n:Food) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]# 已知某种食物推荐吃,反查对应哪些疾病elif question_type == 'food_do_disease':sql1 = ["MATCH (m:Disease)-[r:do_eat]->(n:Food) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql2 = ["MATCH (m:Disease)-[r:recommand_eat]->(n:Food) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql = sql1 + sql2# 查询疾病常用或推荐的药物elif question_type == 'disease_drug':sql1 = ["MATCH (m:Disease)-[r:common_drug]->(n:Drug) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql2 = ["MATCH (m:Disease)-[r:recommand_drug]->(n:Drug) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql = sql1 + sql2# 已知药品,查询其可治疗的疾病elif question_type == 'drug_disease':sql1 = ["MATCH (m:Disease)-[r:common_drug]->(n:Drug) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql2 = ["MATCH (m:Disease)-[r:recommand_drug]->(n:Drug) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]sql = sql1 + sql2# 查询疾病需要做哪些检查elif question_type == 'disease_check':sql = ["MATCH (m:Disease)-[r:need_check]->(n:Check) WHERE m.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]# 已知检查项目,查询可用于诊断哪些疾病elif question_type == 'check_disease':sql = ["MATCH (m:Disease)-[r:need_check]->(n:Check) WHERE n.name = '{0}' ""RETURN m.name, r.name, n.name".format(i)for i in entities]print("neo4j查询语句:", sql)return sql# ================== 测试入口 ==================
if __name__ == '__main__':# 创建 QuestionPaser 实例handler = QuestionPaser()# 示例:模拟一个分类器输出结果res_classify_example = {'args': {'感冒': ['disease'],'头痛': ['symptom']},'question_types': ['disease_symptom', 'disease_cause']}# 调用主解析函数result = handler.parser_main(res_classify_example)# 打印生成的查询语句for item in result:print(f"问题类型: {item['question_type']}")for s in item['sql']:print(f" 查询语句: {s}")3.3.执行查询
from py2neo import Graphclass AnswerSearcher:def __init__(self):self.g = Graph(host="127.0.0.1",# http_port=7474,user="neo4j",password="gyp123456789")self.num_limit = 20'''执行cypher查询,并返回相应结果'''def search_main(self, sqls):final_answers = []for sql_ in sqls:question_type = sql_['question_type']queries = sql_['sql']answers = []for query in queries:ress = self.g.run(query).data()print("查询结果:", ress)answers += ressfinal_answer = self.answer_prettify(question_type, answers)if final_answer:final_answers.append(final_answer)return final_answers'''根据对应的qustion_type,调用相应的回复模板'''def answer_prettify(self, question_type, answers):final_answer = []if not answers:return ''if question_type == 'disease_symptom':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'symptom_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '症状{0}可能染上的疾病有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_cause':desc = [i['m.cause'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}可能的成因有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_prevent':desc = [i['m.prevent'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}的预防措施包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_lasttime':desc = [i['m.cure_lasttime'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}治疗可能持续的周期为:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_cureway':desc = [';'.join(i['m.cure_way']) for i in answers]subject = answers[0]['m.name']final_answer = '{0}可以尝试如下治疗:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_cureprob':desc = [i['m.cured_prob'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}治愈的概率为(仅供参考):{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_easyget':desc = [i['m.easy_get'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}的易感人群包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_desc':desc = [i['m.desc'] for i in answers]subject = answers[0]['m.name']final_answer = '{0},熟悉一下:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_acompany':desc1 = [i['n.name'] for i in answers]desc2 = [i['m.name'] for i in answers]subject = answers[0]['m.name']desc = [i for i in desc1 + desc2 if i != subject]final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_not_food':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}忌食的食物包括有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_do_food':do_desc = [i['n.name'] for i in answers if i['r.name'] == '宜吃']recommand_desc = [i['n.name'] for i in answers if i['r.name'] == '推荐食谱']subject = answers[0]['m.name']final_answer = '{0}宜食的食物包括有:{1}\n推荐食谱包括有:{2}'.format(subject, ';'.join(list(set(do_desc))[:self.num_limit]), ';'.join(list(set(recommand_desc))[:self.num_limit]))elif question_type == 'food_not_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '患有{0}的人最好不要吃{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)elif question_type == 'food_do_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '患有{0}的人建议多试试{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)elif question_type == 'disease_drug':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}通常的使用的药品包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'drug_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '{0}主治的疾病有{1},可以试试'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_check':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}通常可以通过以下方式检查出来:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'check_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '通常可以通过{0}检查出来的疾病有{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))return final_answerif __name__ == '__main__':searcher = AnswerSearcher()查看结果:
