PyTorch 数据处理与可视化全攻略
在深度学习项目中,数据处理的效率和可视化的清晰度直接影响开发进度与模型调优效果。PyTorch 作为主流深度学习框架,提供了一套完整的数据处理工具箱与可视化方案。本文将从utils.data数据加载、torchvision图像处理到TensorBoard可视化,手把手带你掌握 PyTorch 生态中核心的数据处理与分析能力,附带完整代码示例与效果演示,让你少走弯路!
一、数据处理基石:utils.data 工具箱
utils.data是 PyTorch 数据加载的核心模块,解决了 "如何高效读取数据" 的核心问题,主要包含Dataset(数据集定义)和DataLoader(批量加载)两大组件,二者配合使用可实现灵活、高效的数据读取。
1.1 Dataset:自定义数据集的 "模板"
Dataset是抽象类,用于定义数据集的数据来源与索引映射规则。我们只需继承它并实现 3 个核心方法,即可构建自定义数据集:
__init__:初始化数据(如加载文件路径、读取标签)
__getitem__:根据索引返回单个样本(必须实现,支持按[index]取值)
__len__:返回数据集总样本数
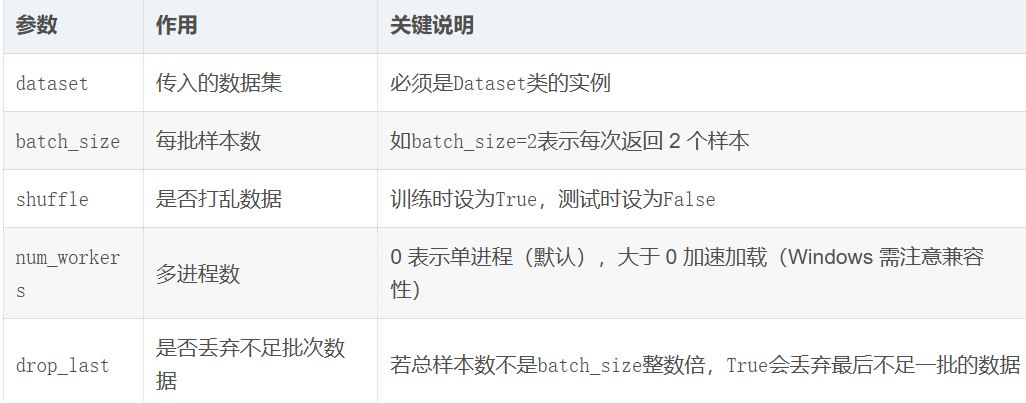
1.2 DataLoader:批量加载的 "加速器"
Dataset每次只能返回单个样本,而DataLoader可将其包装为批量数据迭代器,支持打乱、多进程加载、丢弃不足批次数据等功能,大幅提升训练效率。
核心参数解析
二、图像处理利器:torchvision 工具链
当处理图像数据时,torchvision是 PyTorch 官方提供的 "一站式解决方案",包含datasets(图像数据集)、transforms(图像预处理)、utils(图像工具)三大模块,尤其擅长处理多目录图像数据集。
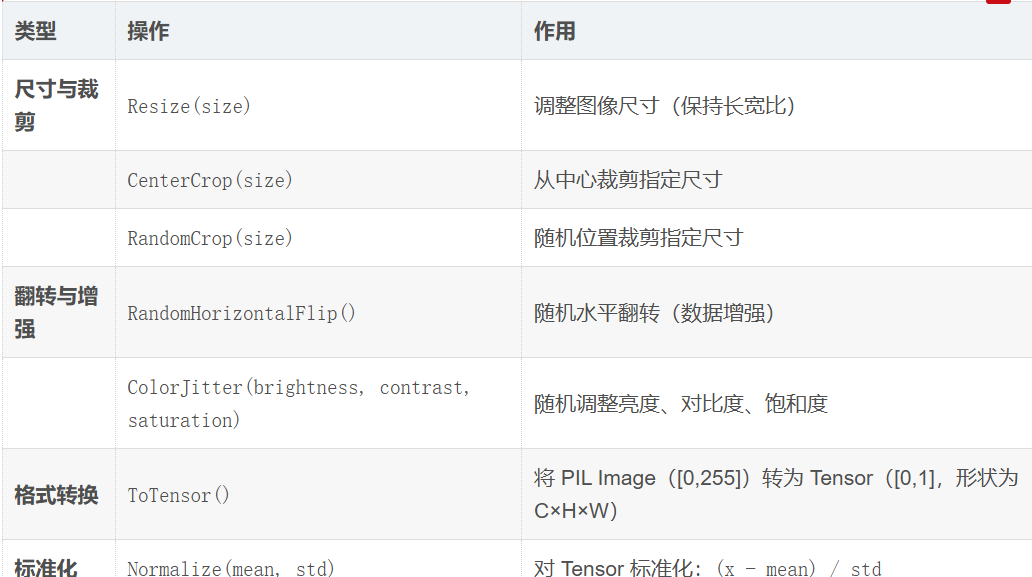
2.1 transforms:图像预处理的 "流水线"
transforms提供了对 PIL Image 和 Tensor 的常用操作,支持通过Compose将多个操作串联成 "流水线",避免重复代码。
常用操作分类
2.2 ImageFolder:多目录图像的 "读取器"
实际项目中,图像常按类别存放在不同目录(如cat/001.jpg、dog/001.jpg),ImageFolder可自动读取这种目录结构,无需手动处理标签,极大简化代码。
三、可视化神器:TensorBoard 全方位分析
训练过程中,仅靠打印日志难以直观观察模型状态,TensorBoard是 PyTorch 集成的可视化工具,支持损失值、神经网络结构、特征图等多种维度的可视化,帮你快速定位问题。
3.1 TensorBoard 使用步骤
- 导入并初始化 SummaryWriter:指定日志保存路径
- 调用 add_xxx API:记录需要可视化的数据
- 启动 TensorBoard 服务:在命令行启动
- 浏览器访问:查看可视化结果
浏览器访问:
在浏览器输入http://localhost:6006(本地)或http://服务器IP:6006(远程),即可进入 TensorBoard 界面。
四、总结与实战建议
PyTorch 的数据处理与可视化工具链形成了完整的 "数据加载→预处理→训练→可视化" 闭环,掌握这些工具能大幅提升深度学习开发效率:
- 数据加载:用
Dataset定义自定义数据,DataLoader实现批量加载,多进程num_workers加速读取。 - 图像处理:
transforms构建预处理流水线,ImageFolder处理多目录图像,减少重复代码。 - 可视化:
TensorBoard跟踪损失值、查看模型结构、分析特征图,帮你快速调优模型。
实战建议:
训练时开启shuffle=True和num_workers>0,提升数据多样性与加载速度。
图像预处理推荐使用Normalize(用 ImageNet 参数或自定义数据集统计值),加速模型收敛。
TensorBoard 日志按功能分目录(如logs/loss、logs/graph),避免混乱。
掌握这些工具后,你可以轻松应对大部分深度学习数据处理场景,快去动手实践吧!