从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力机制听起来很玄乎,但我们可以把它看作一个软k-NN算法。查询向量问:“谁跟我最像?”,softmax投票,相似的邻居们返回一个加权平均值。这就是注意力头的另外一种解释: 一个可微分的软k-NN:计算相似度 → softmax转换为权重 → 对邻居值求加权平均。
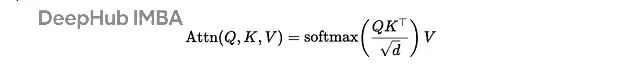
通过
1/sqrt(d)
缩放防止softmax在高维时饱和,掩码决定哪些位置可以互相"看见"(处理因果关系、填充等问题)。
想象有个查询向量 𝐪 在问:“哪些token跟我相似?”
接下来就是三步走:
- 把 𝐪 跟每个键 𝒌 ᵢ 做比较,算出相似度分数
- Softmax把这些分数归一化成概率分布(分数越高权重越大)
- 用这些权重对值向量 𝐯ᵢ 做加权平均
这就是注意力的另外一种解释:考虑序列顺序的软邻居平均算法。
数学推导
单注意力头,键/查询维度是 𝒅,值维度是 𝒅 ᵥ:
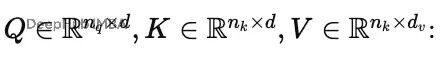
相似度计算用缩放点积:
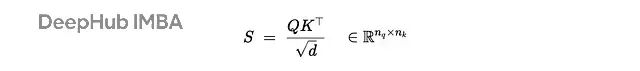
可选的掩码操作:

按行做softmax得到权重:
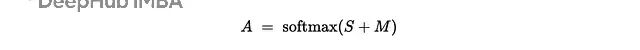
最后计算值的加权平均:
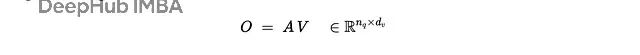
为什么要除以 sqrt(d)?
随机d维向量的点积会按 O(sqrt(d)) 增长。不做缩放的话,softmax就变成了胜者通吃(一个权重接近1,其他都接近0),梯度直接就消失了,所以除以sqrt(d)能让分数方差保持在合理范围,这样softmax的熵也就稳定了。
掩码的作用
掩码 𝐌 在softmax之前加入:
因果掩码用于语言建模,阻止位置 t 看到 j > t 的未来信息。填充掩码则屏蔽那些占位符token。数学上就是 A=softmax(S+M),其中 Mᵢⱼ=0 表示允许,-∞ 表示阻塞。
软k-NN的不同变体
换个相似度函数就是换个归纳偏置:
点积考虑方向和幅度:
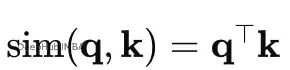
余弦相似度只看角度,忽略长度:
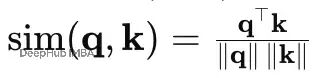
负距离(RBF风格)专注欧几里得邻域:
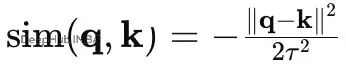
之后都是 softmax → 权重 → 加权平均。温度参数τ控制软硬程度:τ越小越尖锐,越像argmax。
NumPy最小实现
目标很简单:清晰胜过速度。
import numpy as np def softmax(x, axis=-1): x = x - np.max(x, axis=axis, keepdims=True) # numerical stability ex = np.exp(x) return ex / np.sum(ex, axis=axis, keepdims=True) def attention(Q, K, V, mask=None): """ Q: (n_q, d), K: (n_k, d), V: (n_k, d_v) mask: (n_q, n_k) with 0=keep, -inf=block (or None) Returns: (n_q, d_v), (n_q, n_k) """ d = Q.shape[-1] scores = (Q @ K.T) / np.sqrt(d) # (n_q, n_k) if mask is not None: scores = scores + mask weights = softmax(scores, axis=-1) # (n_q, n_k) return weights @ V, weights
简单实验:6个二维token
创建6个token embedding和一个查询,看看权重分配:
# toy data
np.random.seed(7)
n_tokens, d, d_v = 6, 2, 2 K = np.array([[ 1.0, 0.2], [ 0.9, 0.1], [ 0.2, 1.0], [-0.2, 0.9], [ 0.0, -1.0], [-1.0, -0.6]]) # Values as a simple linear map of keys (for intuition)
Wv = np.array([[0.7, 0.1], [0.2, 0.9]])
V = K @ Wv # Query near the first cluster
Q = np.array([[0.8, 0.15]]) # (1, d) out, W = attention(Q, K, V)
print("Attention weights:", np.round(W, 3))
print("Output vector:", np.round(out, 3))
# -> weights ~ heavier on the first two neighbors
Attention weights: [[0.252 0.236 0.174 0.138 0.126 0.075]] Output vector: [[0.318 0.221]]
权重可视化:
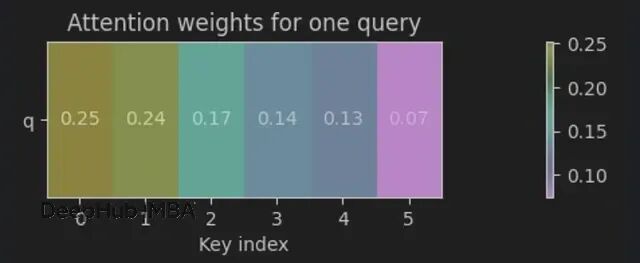
查询通过缩放点积+softmax给键分配概率(权重和为1),大部分权重落在最近的邻居上(0≈0.25,1≈0.24),输出就是这些值的加权平均。所以可以说注意力就是软k-NN。
使用几何视角更直观:
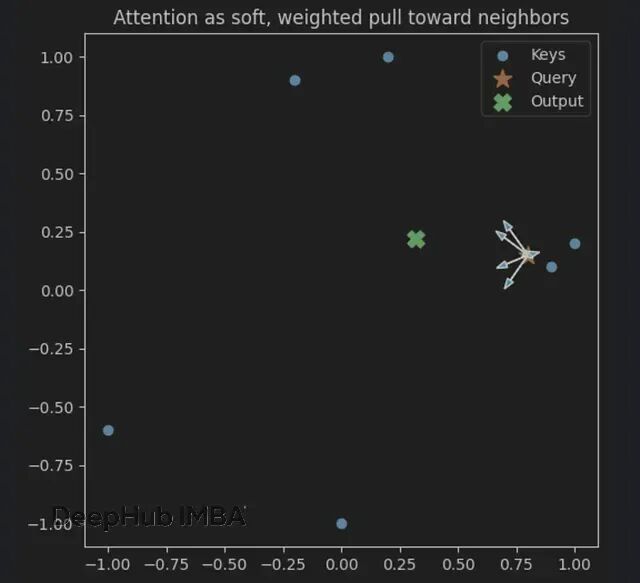
查询(★)感受到来自附近键(●)的加权拉力,箭头长度正比于注意力权重。输出(✖)就是邻居们的加权重心。
三种相似度的对比
试试不同的相似度函数:
def attention_with_sim(Q, K, V, sim="dot", tau=1.0, eps=1e-9): if sim == "dot": scores = (Q @ K.T) / np.sqrt(K.shape[-1]) elif sim == "cos": Qn = Q / (np.linalg.norm(Q, axis=-1, keepdims=True) + eps) Kn = K / (np.linalg.norm(K, axis=-1, keepdims=True) + eps) scores = (Qn @ Kn.T) / tau elif sim == "rbf": # scores = -||q-k||^2 / (2*tau^2) q2 = np.sum(Q**2, axis=-1, keepdims=True) # (n_q, 1) k2 = np.sum(K**2, axis=-1, keepdims=True).T # (1, n_k) qk = Q @ K.T # (n_q, n_k) d2 = q2 + k2 - 2*qk scores = -d2 / (2 * tau**2) else: raise ValueError("sim in {dot, cos, rbf}") W = softmax(scores, axis=-1) return W @ V, W, scores for sim in ["dot", "cos", "rbf"]: out_s, W_s, _ = attention_with_sim(Q, K, V, sim=sim, tau=0.5) print(sim, "weights:", np.round(W_s, 3), "out:", np.round(out_s, 3))[#结果](#结果)
dot weights: [[0.252 0.236 0.174 0.138 0.126 0.075]] out: [[0.318 0.221]]
cos weights: [[0.397 0.394 0.113 0.05 0.037 0.008]] out: [[0.576 0.287]] rbf weights: [[0.443 0.471 0.055 0.021 0.01 0. ]] out: [[0.651 0.268]]
相似度选择就是归纳偏置选择。余弦看角度,RBF看距离,点积两者兼顾。
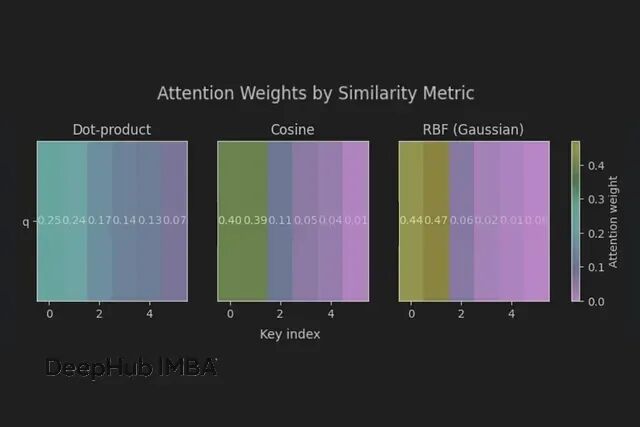
同一个查询,三种视角。余弦和RBF在最近键上更加聚焦,点积分布相对均匀。
因果掩码和填充掩码
语言建模里经常用到:
因果掩码防止模型偷看未来,位置 t 不能看到 > t 的内容。填充掩码忽略那些没有实际内容的占位符。
# Causal mask for sequence length n (upper-triangular blocked)
n = 6
mask = np.triu(np.ones((n, n)) * -1e9, k=1) # Visualize structure by setting Q=K=V (toy embeddings)
X = K
out_seq, A = attention(X, X, X, mask=mask) # Row sums stay 1.0 (softmax is row-wise):
print(np.allclose(np.sum(A, axis=1), 1.0))[#True](#True)
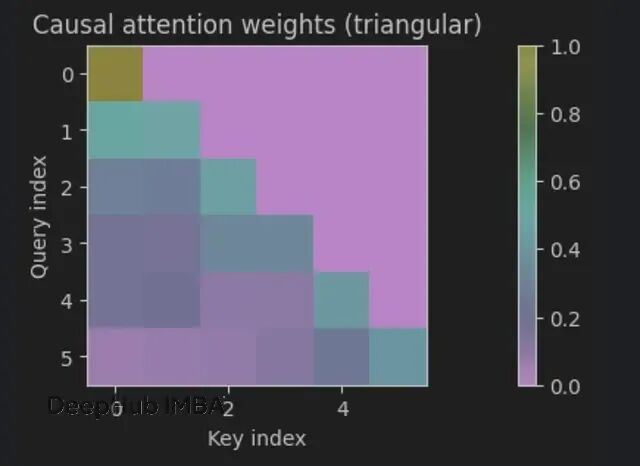
严格的下三角结构 —— 每个位置只能看到自己和过去的信息。
填充掩码就简单了:构建布尔掩码,填充位置设为-∞,复用同一个attention函数即可。
缩放为什么有效?
用随机高维向量实验一下:
def entropy(p, axis=-1, eps=1e-12): p = np.clip(p, eps, 1.0) return -np.sum(p * np.log(p), axis=axis) nq = nk = 64
dims = [256*(2**i) for i in range(7)] # 256..16,384
trials = 5
H_max = np.log(nk) for dim in dims: H_u = [] H_s = [] for _ in range(trials): Q = np.random.randn(nq, dim) K = np.random.randn(nk, dim) S_unscaled = Q @ K.T S_scaled = S_unscaled / np.sqrt(dim) H_u.append(entropy(softmax(S_unscaled, axis=-1), axis=-1).mean()) H_s.append(entropy(softmax(S_scaled, axis=-1), axis=-1).mean()) print(f"{dim:>6} | unscaled: {np.mean(H_u):.3f} scaled: {np.mean(H_s):.3f} (max={H_max:.3f})")[#结果](#结果)
256 | unscaled: 0.280 scaled: 3.686 (max=4.159)
512 | unscaled: 0.165 scaled: 3.672 (max=4.159)
1024 | unscaled: 0.124 scaled: 3.682 (max=4.159)
2048 | unscaled: 0.078 scaled: 3.669 (max=4.159)
4096 | unscaled: 0.063 scaled: 3.689 (max=4.159)
8192 | unscaled: 0.041 scaled: 3.685 (max=4.159) 16384 | unscaled: 0.024 scaled: 3.694 (max=4.159)
可以看到,缩放让softmax更加可靠。
数据很明显:未缩放时熵只有0.07-0.28,缩放后保持在3.68附近。64个键的最大熵是ln(64)≈4.16。
不缩放→接近独热分布:一个键可以霸占所有权重,梯度消失。
缩放后→高熵,权重分散:多个邻居都有贡献,梯度健康。
原理很简单:独立同分布随机向量的点积方差∝d。维度增长时logits变大,softmax饱和。除以sqrt(d)把logit方差归一化到O(1),保持softmax"温度"恒定。
1/sqrt(d)维护了可训练性和稳定性 —— 注意力保持软k-NN特性,不会退化成硬argmax。
一些常见问题
相似度太平→输出模糊。降低温度/提高缩放;训练投影矩阵W_Q、W_K分离token。
某个token占主导→过于自信,系统脆弱。调节温度、加attention dropout、增加多头多样性。
选错度量→关注错了重点。角度问题用余弦;距离问题用RBF;需要考虑幅度用点积。
从基础到Transformer
加上可学习的投影矩阵:
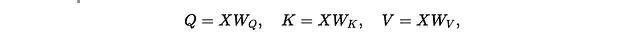
复制h个头,拼接输出再用W_O混合 ,所以还是软邻居平均,只是这是在多个学习子空间里并行。
总结
注意力机制没那么神秘,可以把它想象成带可学习投影的软k-NN。查询问"谁像我",softmax把相似度转成分布,输出就是加权平均。
只不过它多了两个关键调节器:
1/sqrt(d)缩放保持logits在O(1)范围,维持熵的稳定性。实验证明没有它会饱和(近似argmax),有它就能保持健康的软性。
掩码控制信息流:因果掩码防止偷看未来,填充掩码忽略无效内容。
相似度选择就是归纳偏置选择:点积(幅度+方向)、余弦(角度)、RBF(欧氏距离)。多头就是在并行子空间里跑这套逻辑然后混合结果。
所以如果你还不理解注意力,可以直接把它,注意力就是一个带温控的概率邻居平均算法。温度设对了(1/sqrt(d)),邻域选对了(相似度+掩码),剩下的就是工程实现了。
https://avoid.overfit.cn/post/036fe92cd30245fbb4d7ff97f5301c36
作者:Joseph Robinson, Ph.D.