qwen2.5-vl多模态大模型详解
本文已经发表在知乎,辛苦移步~ 《qwen2.5-vl多模态大模型详解》
最近详细的学习了一下qwen2.5-vl国产多模态大模型,笔记如下。
在本文中主要关注数据层面是如何一步一步处理的,也会把一些关键的数据tensor列出来。至于原理层面的介绍,可以参考:万字长文图解Qwen2.5-VL实现细节,【多模态大模型】Qwen2.5-VL解剖 这两篇文章。
环境安装
官方readme中关于环境安装方面的信息不多,可参考:Qwen2.5-VL部署详细记录-CSDN博客,里面遇到的问题确实都会遇到。本文使用的是Qwen2.5-VL-7B-Instruct模型。
另外,建议安装flash-attn,因为我这边3090显卡24G显存在不安装flash-attn时,会话过长时会出现out of memory的错误,且速度很慢,一秒也就能输出大概几个词。开启后速度就很快,也节省显存。
效果测试
前一段时间在搞目标检测相关的小模型,所以就顺手拿了几张图片看看qwen识别的怎么样,过程如下:
问题:
请把这张图片里所有“车辆”用一个列表返回,格式统一为[{“bbox”: [x1,y1,x2,y2], “category”: “vehicle/bus/van/truck”}, …]坐标必须是整数像素,不要有任何解释,只要 JSON 列表。
qwen2.5-vl效果:
如下图,我把识别结果渲染在了图片中,可以看到图片中共有5辆车,识别出了2辆,且bbox的准确性还是可以的。5辆车中有2辆在远方,确实有些难度。

问题:
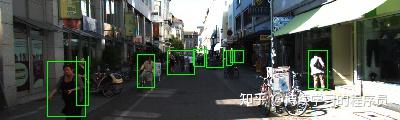
请把这张图片里所有“行人”用一个列表返回,格式统一为[{“bbox”: [x1,y1,x2,y2], “category”: “pedestrain”}, …]坐标必须是整数像素,不要有任何解释,只要 JSON 列表。
qwen2.5-vl效果: