制冷剂中表压对应温度值的获取(Selenium)
本文可做爬虫的练手的一个小项目,难度不大,数据是公开数据,仅供学习参考!
目录
一、前言
二、思路分析
三、数据获取
四、完整代码
五、结语
一、前言
Danfoss 是一家全球知名企业,专注于能源效率、气候解决方案、制冷、供热、动力系统等领域。Ref Tools 是其为用户提供的一系列参考工具(referencing tools),用于支持工程师、技术人员或爱好者进行制冷剂、压缩机、系统参数等方面的查阅与计算。
网站链接:https://reftools.danfoss.com/spa/tools/ref-slider#/
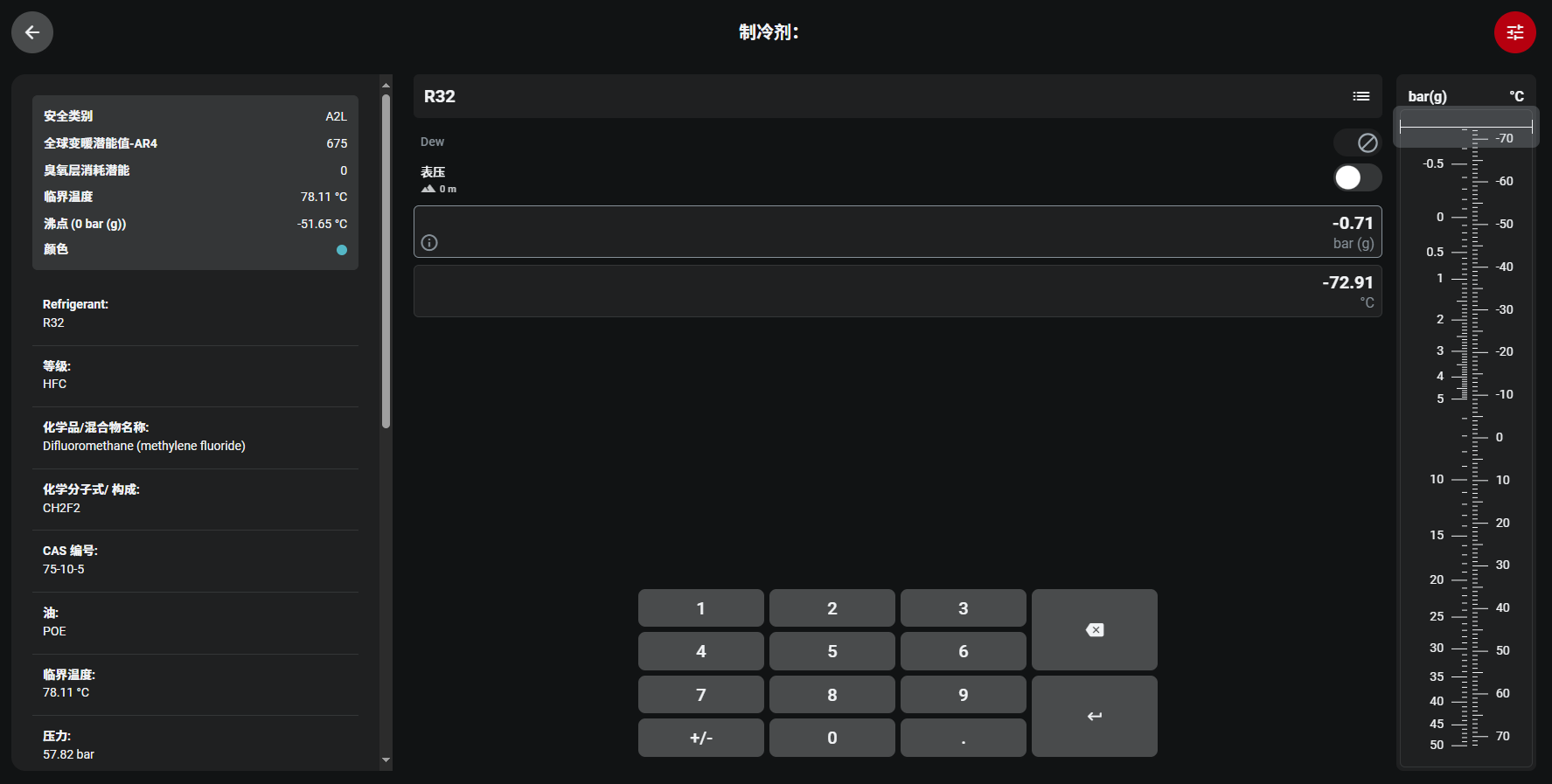
网站打开后,只需输入对应的表压值,就能生成匹配的温度值,这种实时计算功能确实为单条数据查询提供了便利。但实际场景中若面临大量表压数据(比如成百上千条),逐一手动输入不仅耗时费力,效率极低;更关键的是,由于不清楚背后的计算逻辑(如是否基于特定制冷剂的物理特性公式、是否包含丹佛斯专属算法修正),也无法通过公式批量换算。
因此,能否通过 Python 爬虫获取该工具内部的完整数据映射关系(即表压与温度的对应数据集)?若能实现,后续再处理大量表压数据时,就能直接用 Excel 的 VLOOKUP 函数或其他工具快速匹配出对应的温度值,彻底解决批量数据处理的难题。
二、思路分析
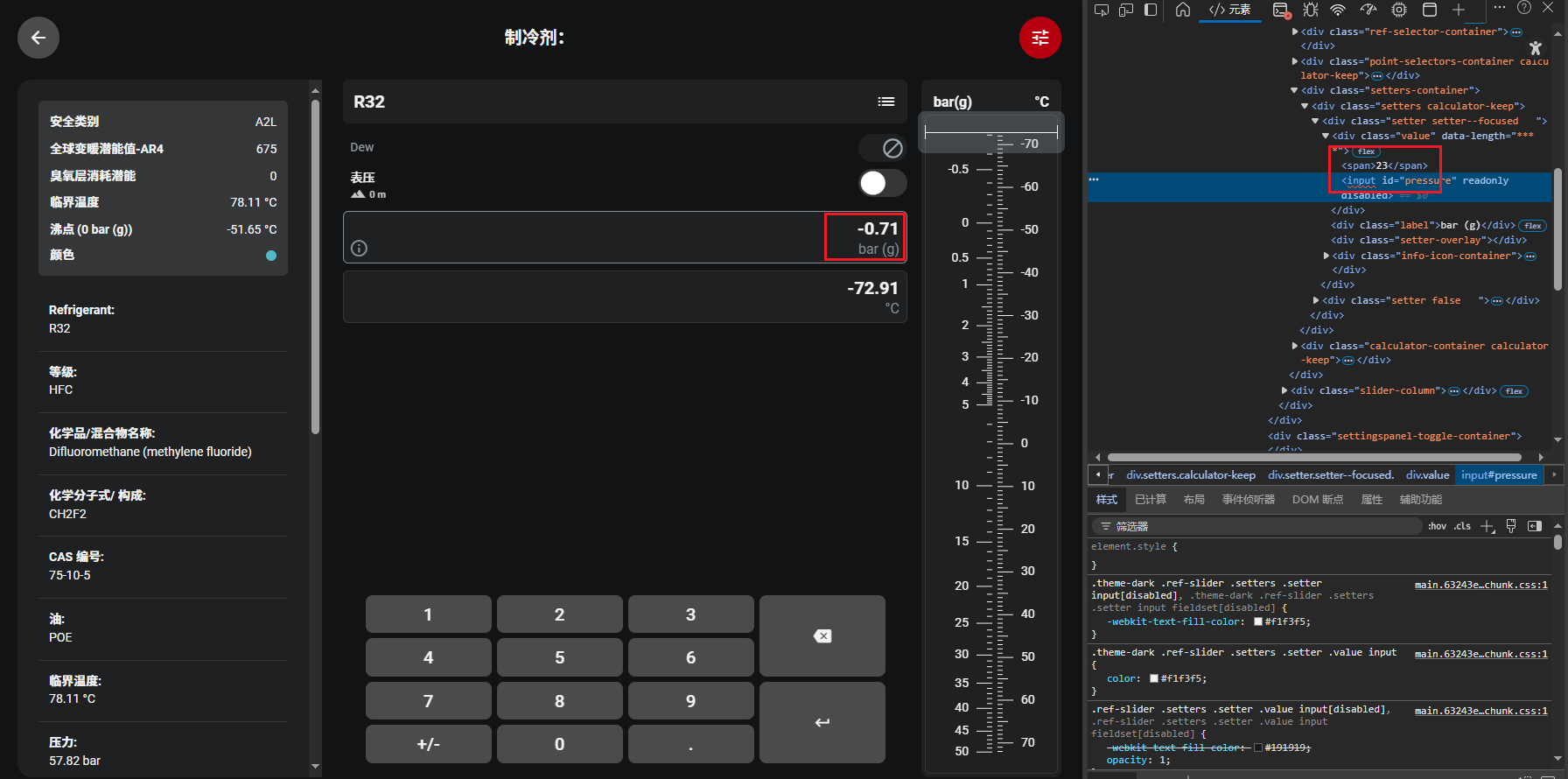
我原本的思路是,既然需要自动输入表压值来获取对应温度值,或许可以直接修改页面 HTML 中表压输入框的内容,以此让页面识别到数值变化并触发温度计算。但实际操作后发现,这种方式完全没有效果 (如下图)—— 即便手动修改了 HTML 代码里输入框对应的数值,页面上的输入框显示、以及后续的温度值输出都没有任何变动,显然这种直接修改 HTML 的方法无法实现表压值的有效输入,也就没办法推进后续的数据获取流程。
既然直接修改 HTML 的方法行不通,我便将注意力转向了页面下方的按钮选项 —— 这些按钮不仅功能明确,且在页面中的位置固定,不会随交互动态变化。由此产生了新的思路:能否通过模拟点击这些按钮,间接实现向表压输入框填入对应数值的效果,进而触发温度值计算?经过实际测试验证,这种通过按钮点击(click)来传递表压值、获取对应温度值的方法,最终是可行的。
OK,既然按钮点击的方法已验证可行,那整体的初步爬取思路就清晰了。具体方案如下:通过 Selenium 模拟浏览器操作来爬取该页面,核心是针对 R32 制冷剂(本次仅作演示),通过程序自动遍历并点击页面下方的数字按钮表格,每点击一次按钮,即可向表压输入框填入对应数值,待页面生成并加载出匹配的温度值后,同步获取该组 “表压 - 温度” 数据;重复这一 “点击 - 获取” 的循环操作,遍历所有按钮对应的表压值,最终将收集到的全部 R32 冷媒表压与温度的对应数据整理输出,形成结构化数据库。
三、数据获取
第一步自然是导入所需的Python库。虽说目前的爬取需求未必会用到下面列出的所有库,但出于个人使用习惯,还是先一并导入——这样后续若需扩展功能(比如数据清洗、多格式导出等),就不用临时补导,能更顺畅地推进开发,避免中途因库缺失打乱节奏。
import os
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rowsplt.rcParams['font.sans-serif']='SimHei' # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置公式符号
warnings.filterwarnings('ignore') # 设置忽略警告import requests # requests请求
from lxml import etree # xpath解析
import re # 正则表达式解析
from selenium import webdriver # selenium爬取
from selenium.webdriver.common.by import By # selenium库中定位元素By
import time # 时间库包
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException, TimeoutException 若尚未安装所需的 Python 库,可通过命令行执行 pip install 库名 的方式完成安装。需要说明的是,在本文的爬取方案中,核心依赖的库仅有两个,分别是用于数据整理与存储的 Pandas,以及用于模拟浏览器操作(如点击按钮、获取页面数据)的 Selenium,优先确保这两个库安装成功即可满足基本需求
# 构建网站
driver = webdriver.Edge()
# 网站跳转
url = 'https://reftools.danfoss.com/spa/tools/ref-slider#/'
driver.get(url) 这里需要特别说明一点:如果是首次使用 Selenium 库,后续运行代码时可能会出现网站无法打开或报错的情况,核心原因是 Selenium 需要对应浏览器的驱动程序(如 Edge 浏览器需匹配msedgedriver)才能实现自动化操作。如果你不是第一次使用selenium,那下面步骤可以跳过。
本文将以Edge 浏览器(简称 “Edge”) 为例演示驱动的下载与配置步骤 —— 需将下载好的msedgedriver程序放到当前 Python 运行程序所在的文件路径下,确保驱动与浏览器版本匹配,才能避免因驱动缺失或版本不兼容导致的运行故障。
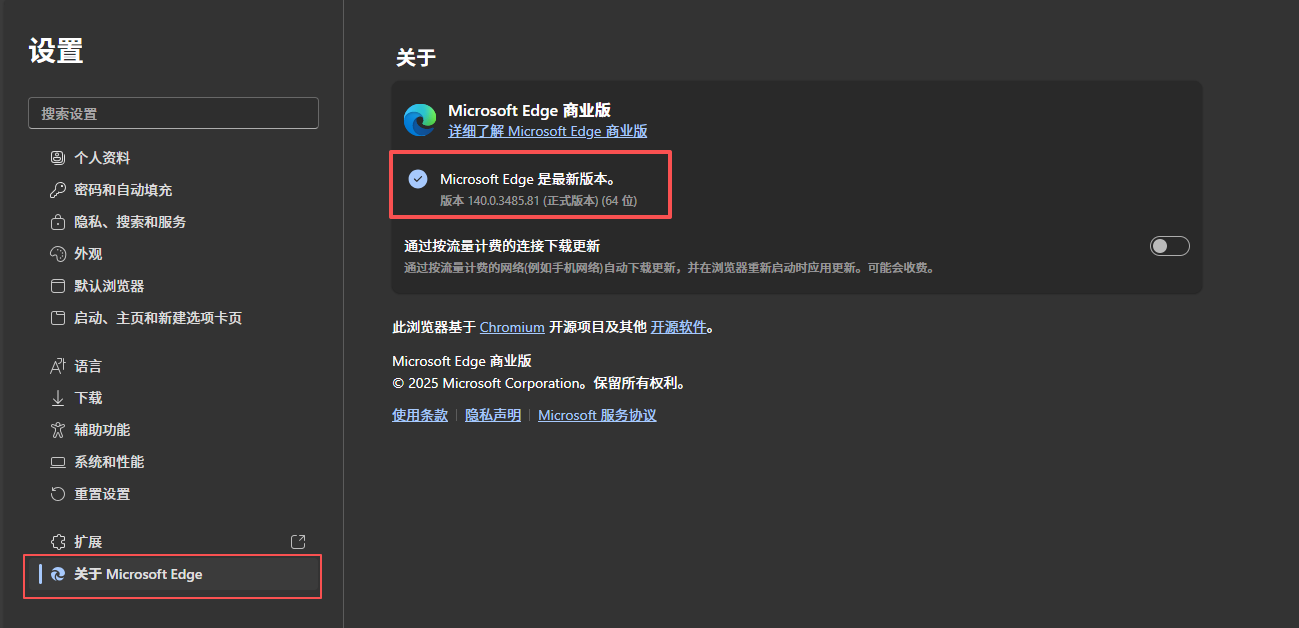
① 先打开edge浏览器,去设置那查找当前edge浏览器的版本,可以看到我这的版本是140.0.3485.81
② 打开下面的网页,查找到和刚刚版本一样的版本,然后点击下载
https://developer.microsoft.com/zh-cn/microsoft-edge/tools/webdriver/?form=MA13LH

③ 下载后将下面这个exe后缀的程序移动到你当前代码程序运行的文件路径下,完成操作!
![]()
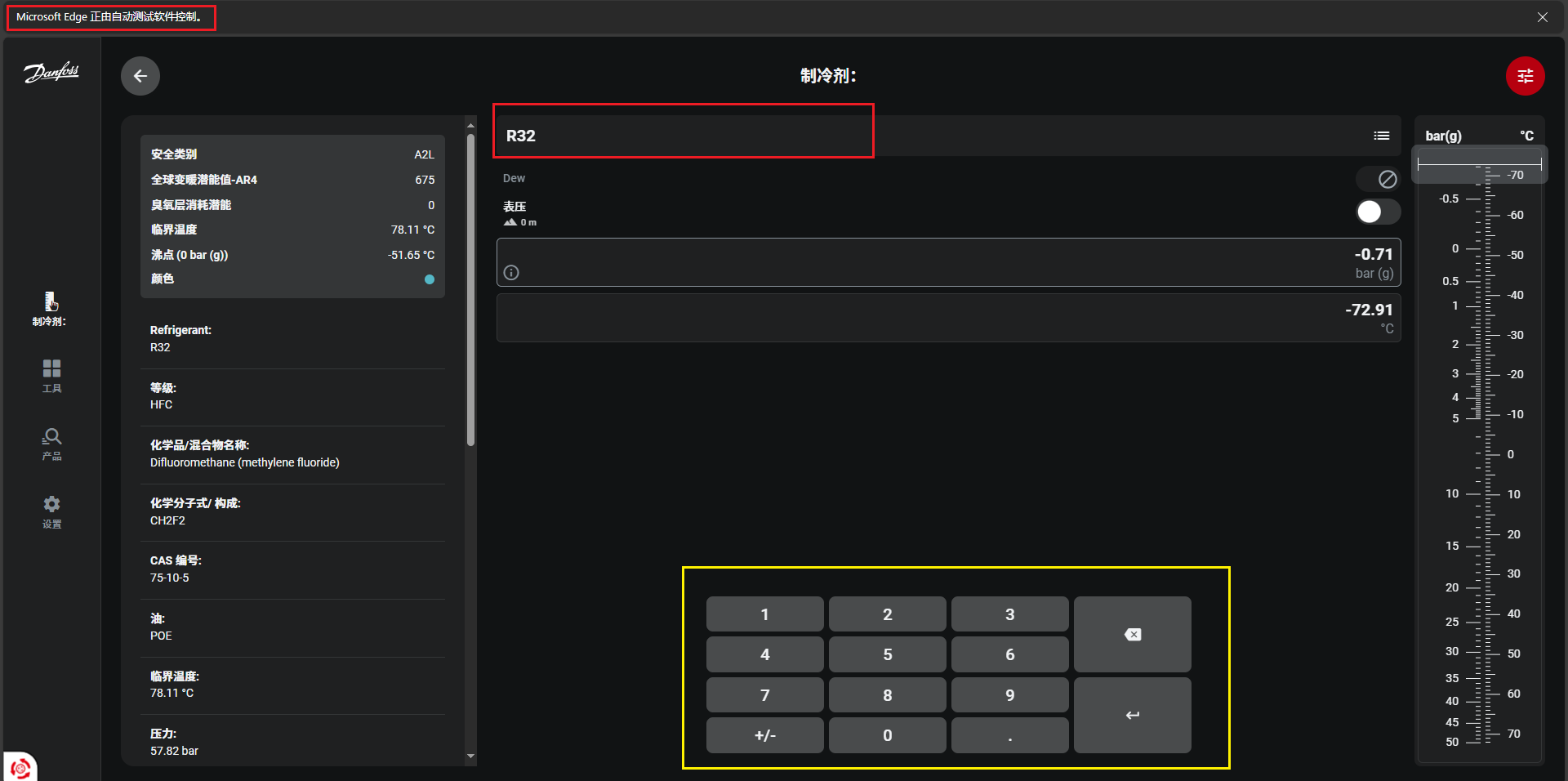
回归正题,当执行 driver.get(url) 代码并运行成功后,程序会自动打开一个 Edge 浏览器窗口并跳转到目标网页。接下来,我们需要在页面中手动完成两项关键操作:一是从列表中选定目标冷媒(本文演示用的 R32)及其对应的状态;二是调整好其他必要的基础配置。(效果如下图)
接下来,我们需要定位页面下方数字按钮区域中黄色框标记的那些按钮(即用于输入表压值的交互按钮)。为了便于后续通过代码精准操控这些按钮,我们需要为它们逐一命名,分别记为 a_1、a_2、a_3、a_4、a_5、a_6、a_7、a_8、a_9、a_Y、a_0、a_D、a_X(命名规则可根据按钮实际功能对应,例如 a_1 对应数字 “1” 按钮,a_Y 对应正负符合按钮,a_X对应清除按钮,a_D对应小数点按钮,a_DJ对应回车按钮)。这样,在后续的自动化点击操作中,就能通过这些命名直接调用对应的按钮元素,并搞成字典。
a_1 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[1]'
a_2 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[2]'
a_3 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[3]'
a_4 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[2]/td[1]'
a_5 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[2]/td[2]'
a_6 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[2]/td[3]'
a_7 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[1]'
a_8 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[2]'
a_9 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[3]'
a_Y = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[4]/td[1]'
a_0 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[4]/td[2]'
a_D = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[4]/td[3]'
a_X = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[4]'
dic = {a_1:1,a_2:2,a_3:3,a_4:4,a_5:5,a_6:6,a_7:7,a_8:8,a_9:9,a_Y:"-",a_0:0,a_D:".",a_X:"x"}
a_DJ = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[4]'在每次输入新数值前,必须先将输入框中已有的内容清空,避免新旧数值混杂导致输入错误。由于需要输入的表压值有正有负,因此在模拟输入时需要分情况处理:
- 若为负数,需先点击负号按钮(a_Y),再取数值的绝对值,依次点击对应数字按钮;
- 若为正数,则直接点击数值对应的数字按钮即可。
不过,我们需要判断通过按钮输入的值是否与目标值一致,只有确认一致后,才能去获取对应的温度值。这就带来一个问题:如果用range(-10, 10, 0.1)这类方法生成数值,无法精准得到我们需要的目标值(因为range不支持浮点数步长,且浮点数计算易产生精度误差)
start = -10.0
end = 10.0
step = 0.01current = start
while current <= end:current = round(current, 2) # 保留两位小数,确保数值精度print(current)current += step 这样既能按设定步长(如 0.01)生成从 - 10.0 到 10.0 的所有目标值,又能通过round函数控制精度,避免因浮点数误差导致按钮输入值与目标值不匹配的问题。
OK,以上问题都解决了,那么就基本上可以写出一个简单的代码程序了,如下
df = pd.DataFrame()
# 数字循环生成
start = 0
end = 1
step = 0.1current = start
while current <= end:# 小数点保留current = round(current,4)for j in [a_1,a_2,a_3,a_4,a_5,a_6,a_7,a_8,a_9,a_Y,a_0,a_D,a_X]:# 映射对应的值i = dic[j]# 内容清除for i in range(20):driver.find_element(By.XPATH, a_X).click()# 处理负数if current < 0:# 先添加负号driver.find_element(By.XPATH, a_Y).click()# 处理数字部分(取绝对值)num_str = str(abs(current))else:num_str = str(current)# 为每个数字字符添加对应的键for char in num_str:if char == '0':driver.find_element(By.XPATH, a_0).click()elif char == '1':driver.find_element(By.XPATH, a_1).click()elif char == '2':driver.find_element(By.XPATH, a_2).click()elif char == '3':driver.find_element(By.XPATH, a_3).click()elif char == '4':driver.find_element(By.XPATH, a_4).click()elif char == '5':driver.find_element(By.XPATH, a_5).click()elif char == '6':driver.find_element(By.XPATH, a_6).click()elif char == '7':driver.find_element(By.XPATH, a_7).click()elif char == '8':driver.find_element(By.XPATH, a_8).click()elif char == '9':driver.find_element(By.XPATH, a_9).click()elif char == '.':driver.find_element(By.XPATH, a_D).click()time.sleep(1)# 判断值是否正确if str(current) == driver.find_element(By.XPATH, '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[3]/div/div[1]/div[1]/span').text:# 回车确定driver.find_element(By.XPATH, a_DJ).click()time.sleep(2)# 下一次循环current += stepbreak目前代码已经能够实现自动点击按钮的功能,但尚未涉及数据获取的部分。这部分功能需要在完成数值输入并按下回车确认后触发 —— 当程序判断通过按钮输入的数值与目标值完全一致时,便会自动执行数据获取操作,将对应的温度值提取出来并存储到预设的容器中(如列表或 DataFrame),从而完成 “输入 - 验证 - 获取 - 存储” 的完整闭环。
本文核心的技术验证工作(即通过 Selenium 模拟按钮点击实现表压值精准输入、并确认输入值与目标值匹配的可行性)已全部完成。至于后续的数据获取(如提取回车确认后生成的温度值)与存储(如将 “表压 - 温度” 数据写入表格或数据库),操作逻辑相对基础、流程也更简单,因此不再展开详细说明。直接上代码如下:
df = pd.DataFrame()
# 数字循环生成
start = 0
end = 1
step = 0.1current = start
while current <= end:dic1={}# 小数点保留current = round(current,4)for j in [a_1,a_2,a_3,a_4,a_5,a_6,a_7,a_8,a_9,a_Y,a_0,a_D,a_X]:# 映射对应的值i = dic[j]# 内容清除for i in range(20):driver.find_element(By.XPATH, a_X).click()# 处理负数if current < 0:# 先添加负号driver.find_element(By.XPATH, a_Y).click()# 处理数字部分(取绝对值)num_str = str(abs(current))else:num_str = str(current)# 为每个数字字符添加对应的键for char in num_str:if char == '0':driver.find_element(By.XPATH, a_0).click()elif char == '1':driver.find_element(By.XPATH, a_1).click()elif char == '2':driver.find_element(By.XPATH, a_2).click()elif char == '3':driver.find_element(By.XPATH, a_3).click()elif char == '4':driver.find_element(By.XPATH, a_4).click()elif char == '5':driver.find_element(By.XPATH, a_5).click()elif char == '6':driver.find_element(By.XPATH, a_6).click()elif char == '7':driver.find_element(By.XPATH, a_7).click()elif char == '8':driver.find_element(By.XPATH, a_8).click()elif char == '9':driver.find_element(By.XPATH, a_9).click()elif char == '.':driver.find_element(By.XPATH, a_D).click()time.sleep(1)# 判断值是否正确if str(current) == driver.find_element(By.XPATH, '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[3]/div/div[1]/div[1]/span').text:# 回车确定driver.find_element(By.XPATH, a_DJ).click()time.sleep(2)# 获取对应的温度值temp = driver.find_element(By.XPATH, '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[3]/div/div[2]/div[1]/span').text# 字典dic1[current] = tempprint(dic1)dict_items = list(dic1.items())df1 = pd.DataFrame(dict_items, columns=['Key', 'Value'])df = pd.concat([df, df1])# 下一次循环current += stepbreak
df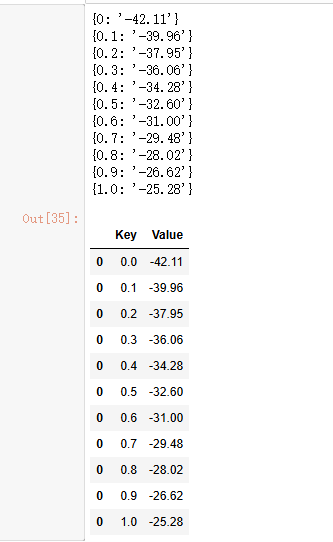
以上是本次爬取的运行结果(示例中仅选取了从 0 到 1.0、步长 0.1 的表压值范围)。实际操作时,你完全可以根据需求扩展数据范围,只需调整代码中start(起始值)、end(终止值)、step(步长)这三个参数,即可覆盖全部所需的表压数据。需要注意的是,数据量越大,程序遍历点击、等待页面响应的总耗时会相应增加。
另外,代码中加入time.sleep(1)这一行,是因为页面在接收输入并生成温度值时,偶尔会出现响应延迟;若不设置这段等待时间,程序可能会因页面数据未加载完成而无法获取到有效温度值,导致数据缺失或爬取错误。
四、完整代码
import os
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rowsplt.rcParams['font.sans-serif']='SimHei' # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置公式符号
warnings.filterwarnings('ignore') # 设置忽略警告import requests # requests请求
from lxml import etree # xpath解析
import re # 正则表达式解析
from selenium import webdriver # selenium爬取
from selenium.webdriver.common.by import By # selenium库中定位元素By
import time # 时间库包
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException, TimeoutException# 构建网站
driver = webdriver.Edge()
# 网站跳转
url = 'https://reftools.danfoss.com/spa/tools/ref-slider#/'
driver.get(url)
以上运行好后,需要等待页面弹出来后简单处理页面后再运行下面的代码
a_1 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[1]'
a_2 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[2]'
a_3 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[3]'
a_4 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[2]/td[1]'
a_5 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[2]/td[2]'
a_6 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[2]/td[3]'
a_7 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[1]'
a_8 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[2]'
a_9 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[3]'
a_Y = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[4]/td[1]'
a_0 = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[4]/td[2]'
a_D = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[4]/td[3]'
a_X = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[4]'
dic = {a_1:1,a_2:2,a_3:3,a_4:4,a_5:5,a_6:6,a_7:7,a_8:8,a_9:9,a_Y:"-",a_0:0,a_D:".",a_X:"x"}
a_DJ = '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[4]/div/table/tbody/tr[3]/td[4]'df = pd.DataFrame()
# 数字循环生成
start = 0
end = 1
step = 0.1current = start
while current <= end:dic1={}# 小数点保留current = round(current,4)for j in [a_1,a_2,a_3,a_4,a_5,a_6,a_7,a_8,a_9,a_Y,a_0,a_D,a_X]:# 映射对应的值i = dic[j]# 内容清除for i in range(20):driver.find_element(By.XPATH, a_X).click()# 处理负数if current < 0:# 先添加负号driver.find_element(By.XPATH, a_Y).click()# 处理数字部分(取绝对值)num_str = str(abs(current))else:num_str = str(current)# 为每个数字字符添加对应的键for char in num_str:if char == '0':driver.find_element(By.XPATH, a_0).click()elif char == '1':driver.find_element(By.XPATH, a_1).click()elif char == '2':driver.find_element(By.XPATH, a_2).click()elif char == '3':driver.find_element(By.XPATH, a_3).click()elif char == '4':driver.find_element(By.XPATH, a_4).click()elif char == '5':driver.find_element(By.XPATH, a_5).click()elif char == '6':driver.find_element(By.XPATH, a_6).click()elif char == '7':driver.find_element(By.XPATH, a_7).click()elif char == '8':driver.find_element(By.XPATH, a_8).click()elif char == '9':driver.find_element(By.XPATH, a_9).click()elif char == '.':driver.find_element(By.XPATH, a_D).click()time.sleep(1)# 判断值是否正确if str(current) == driver.find_element(By.XPATH, '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[3]/div/div[1]/div[1]/span').text:# 回车确定driver.find_element(By.XPATH, a_DJ).click()time.sleep(2)# 获取对应的温度值temp = driver.find_element(By.XPATH, '//*[@id="sections-container"]/div/div/div/div[2]/div/div[2]/div/div[1]/div/div[1]/div[3]/div/div[2]/div[1]/span').text# 字典dic1[current] = tempprint(dic1)dict_items = list(dic1.items())df1 = pd.DataFrame(dict_items, columns=['Key', 'Value'])df = pd.concat([df, df1])# 下一次循环current += stepbreak
df五、结语
本文主要供各位的一个学习小项目,可以适当的练练手。另外我可能在内容上存在一些不足或错误之处。如果有任何资深人士发现这些问题,请不吝指出并给予指导,我会及时修改,以帮助大家采用更准确的方法进行学习和实践。
若对这篇文章能对您的学习和工作有所帮助,请动动你的宝贵的小手指,点赞+收藏+关注!后续还会更新我自己写的项目或笔记哦~