Universal bovine identification via depth data and deep metric learning 阅读笔记
目录
- Title
- Abstract
- Conclusion
- Introduction
- 1.1 Motivation
- 1.2. Open-set identification via deep metric-learning
- Related Work
- 2.1. Biometrics for bovine identification
- 2.2. Coat patterns and metric learning
- 2.3. Capturing depth data and related analysis:
- 3. Methodology
- 3.1. Dataset preparation
- 3.2. Model architectures
- 3.3. Training setup
- Results
Title
标题:
Universal bovine identification via depth data and deep metric learning
通过深度数据和深度度量学习进行通用牛识别
发布:Computers and Electronics in Agriculture
作者:
Asheesh Sharma
Abstract
背景:
随着牛群规模扩大,农场中牛与人比例失衡使得个体人工监测更具挑战性。因此,实时牛只识别对农场至关重要,也是迈向精准畜牧业的关键一步
方法:
深度度量学习方法,利用现成3D摄像头获取的深度数据作为新型生物特征进行牛只识别
结果:
深度作为生物特征可能将我们方法的实际应用范围扩展到英国其余68%缺乏独特被毛图案的牛品种。
本方法的概述: 依托卷积神经网络CNN和多层感知机MLP为主干网络,通过提取泛化能力强的嵌入空间来区分个体。网络嵌入通过k-邻近 KNN 等算法通过简单的聚类实现高精度的识别
做了什么: 评估了两种主干架构:通过RGB图像识别荷斯坦牛的残差神经网络ResNet,以及专为处理3D点云设计的PointNet。发布了Cow2023数据集用于评估主干网络,分别处理了深度图点云的ResNet和PointNet框架都达到了与基于毛皮花纹的骨干相当的水平,还解决了全黑和全白品种问题。
结论:
ResNet彩色主干网络实现了99.97%的 k-NN 识别准确率,PointNet准确率为99.36%。PointNet架构对噪声和缺失数据具有鲁棒性。
嵌入空间
嵌入空间指的是通过卷积神经网络(CNN)和多层感知机(MLP)等模型所学习到的、能够有效区分个体的空间。在这个空间中,相似的动物(如外形相似的牛)会被映射到彼此较近的位置,而不同的动物(即具有不同特征的牛)则会被映射到较远的地方。
Conclusion
主要拓展基于RGB图像的奶牛的研究,开发了通过深度图识别牛的深度神经网络DNNs和多层感知机MLPs,通过梯度加权类激活映射(Grad-CAM)和 点云显著性映射(PC-SM)可视化ResNet与PointNet架构的梯度,定性评 估了深度图和点云在牛只识别中的有效性。
比较了ResNet和PointNet的性能,该研究通过深度度量学习利用深度数据实现高效牛只识别
Introduction
- 第一段:检测的重要性:检测每头奶牛对农场生产力很重要,个体识别是前提条件,对个体进行连续识别对于通过接触追踪 和社交互动研究疾病传播也至关重要。
- 第二段:建立一种普适性的检测方法:该方法采用深度相机远距离(非接触式)拍摄动物,旨在突破品种特异性毛皮纹路的限制,我们的主要目标是通过探索深度作为生物特征模 态,建立一种普适性牛只识别方法。
1.1 Motivation
- 第一段:深度数据的局限性:(1) 系统通常需要 大量重新校准才能登记新动物,(2) 依赖RGB与深度数据的结合,可能限 制其在具有明显毛皮图案的牛群中的应用,(3) 由于依赖步态等次要信息 的精确估计,在非结构化农场环境中表现可能不稳定。
- 第二段:指出射频识别标签(RFID)的缺点
- 第三段:指出传统方式的局限性
- 第四段:机器学习方法加摄像头系统能够克服这些困难。
- 第五段:指出了口鼻特征和虹膜虽然取得了显著的成效,但是图像获取困难,仍然存在局限性。
1.2. Open-set identification via deep metric-learning
- 第一段:通过之前的研究引出本次研究:之前通过背面视角的RGB图像识别了荷斯坦弗里斯牛,存在的局限性是识别缺乏毛皮花纹的全黑牛。本次讨论了否可以仅通过背面视角的3D图像中可见的体形特征如脊柱和钩臀区域来识别牛,而不通过毛皮花纹。
- 第二段:为了说明本框架的适用性,指出了封闭集的缺点:虽然可以在封闭结合中取得不错的效果,但是对于牛只随时变化的农场存在不适用性。
- 第三段:开放数据集的特点:测试集与训练集和验证集不相交,必须识别未知的个体,模拟了更加贴合现实情况的表现。
- 第四段:开放数据集与封闭数据集的区别:在封闭集上训练的分类模型具有固定数量的输出,用于预测输入的 标签。开放集中的标签数量是动态的,我们无法将训练过程表述为传统的分类 任务。卷积网络应用于视频时会产生闪烁现象。
- 第五段: 提出的新系统:将深度数据特征中的微小差异转化为一个丰富的多维空间,在这个空间中,来自相似输入的数据点被排列得更接近。任何已知或未知的个体都可以通过这个多维空间进行转换,生成一个独特的度量或嵌入,该嵌入在模型中是潜在的。使用这个潜在空间生成的嵌入可以通过鲁棒的算法(如k最近邻(k-NN))进行聚类,从而分配识别标签。
Related Work
2.1. Biometrics for bovine identification
讨论眼睛、鼻子等局部特征到面部特征的局限性,最后与我们方法比较
- 面部识别、眼部识别和鼻部特征识别都取得了不错的成果,但仍然存在不小的局限性。如图像难以获取,对图像质量要求高,容易出现遮挡,运动导致的模糊。
- 我们提出了非接触式获取深度图像,遮挡或质量损失可能性较低,
2.2. Coat patterns and metric learning
讨论度量学习
- 学习一组代表图像特征图案的特征。这些特征或潜在空间随后可通过简单算法(如 k-NN)聚类为外观相似的图像,从而无需重新训练。学习潜在空间的方法被称为度量学习。这种方法在识别牛方面具有鲁棒性
- 引用其它论文,一种用于牛只识别的自监督度量学习新型标注框架,仅需几分钟人工标注即可实现92.4%的测试准确率
2.3. Capturing depth data and related analysis:
深度数据在评估动物健康方面已受到关注,但其在身份识别方面的全部潜力尚未得到充分探索,利用轮廓检测和分割算法捕获奶牛的背侧深度图像,
3. Methodology
3.1. Dataset preparation
- 第一段:数据集获取:使用Kinect V2相机记录了16位深度和8位RGB图像流,并记录了帧级设备时间戳,该相机通过反射在物体上的红外光模式进行工作,设备时间戳随后用于将深度图和RGB图像帧进行关联,即时间同步。数据集包含99头荷斯坦弗里斯牛的21,490张图像
- 第二段:划分数据集:为了减少时间相邻样本间微小差异对测试准确率的影响,剔除每个测试目标两侧n张图片。降低测试样本在训练集中存在已学习过的时间相似图像的可能性。
- 第三段:消除时间偏差的后果:移除了相邻图片,总数据集图片会减少,会导致某些牛的图像很少或者归零,这些牛会当做未知类别的一部分,模拟真实场景。
3.2. Model architectures
- 第一段:3D信息处理的困难:3D深度信息在用于各种3D识别任务之前,需要经过一些转换,转化为稀疏的、有意义的特征
- 第二段:ResNet架构可以处理深度图:专注于深度图,深度图容易获取,并且可以于ResNet有更好的契合,ResNet架构可以通过残差跳跃连接缓解了梯度消失问题。
- 第三段:本文采用ResNet-50变体:ResNet-50包含四个以瓶颈结构排列的卷积块,最后接一 个全连接(或密集)层,输出维度为(1 × 2048)。四个卷积块的尺寸各 不相同,如图所示。总计有49个卷积层。网络将ResNet-50的密集层 (1 × 2048)输出馈送至空间上下文模块(SCM),随后通过最终层生成 (1 × 128)嵌入。
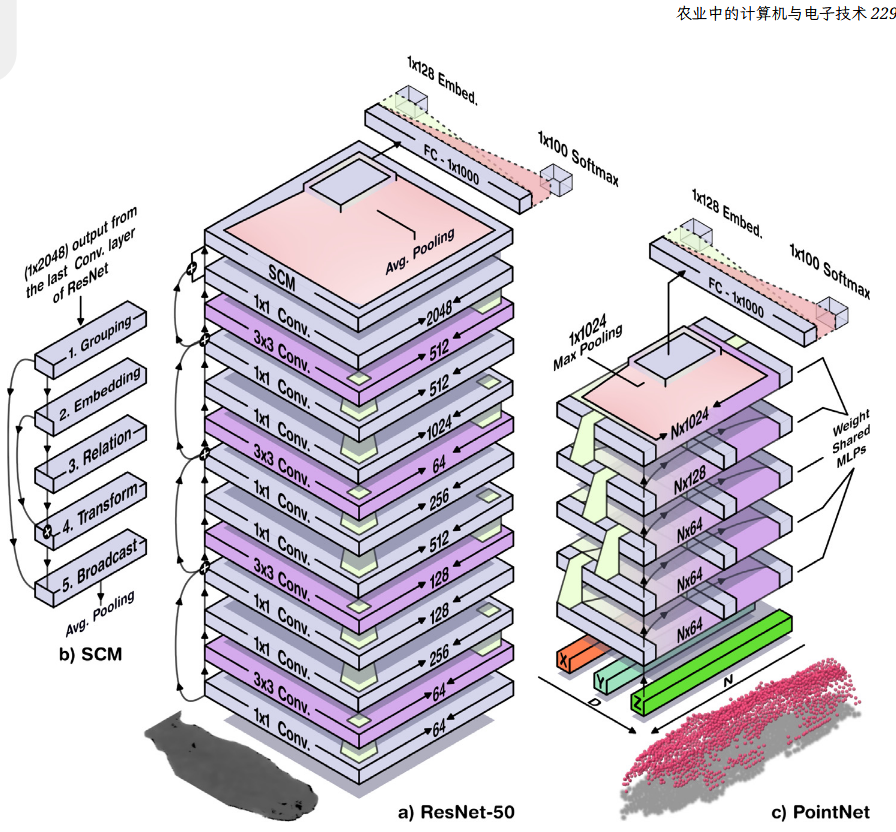
- 第四段:空间上下文模块(SCM):通过权衡每个区域在识别过程中的重要性, 使网络能够聚焦于图像中最相关的区域。空间上下文模块(SCM)通过 分组最后一个ResNet卷积块的(1 × 2048)输出来构建嵌入向量。该嵌 入向量存储了一个标准化权重值,对应于ResNet输出的(1 × 2048)中 第 i个与第 j个位置之间的关系。计算特征图后,通过矩阵乘法将其应用 于ResNet的(1 × 2048)输出,以突出最关键的区域。
- 第五段:PointNet架构:为了解决深度图固有的二维特性,ResNet架构可能会无意中学习与视角相关的线索,尤其是在模式识别的过程中。我们研究了通过使用深度相机的内参,将深度数据从摄像机平面(u, v, 距离)重新投影到物理单位(x, y, 距离)的点云。
- PointNet包含四层MLP,每一层具有不同数量的输出通道。每个MLP都会考虑点云中的每个点,生成一个N × 3的输出,其中N是点的数量。最后,在第四层之后,最大池化(max pooling)操作生成一个全局特征向量(1 × 1024)。为了生成256维的嵌入,最大池化输出将通过额外的全连接层,这些层的结构与之前描述的ResNet架构类似。
3.3. Training setup
-
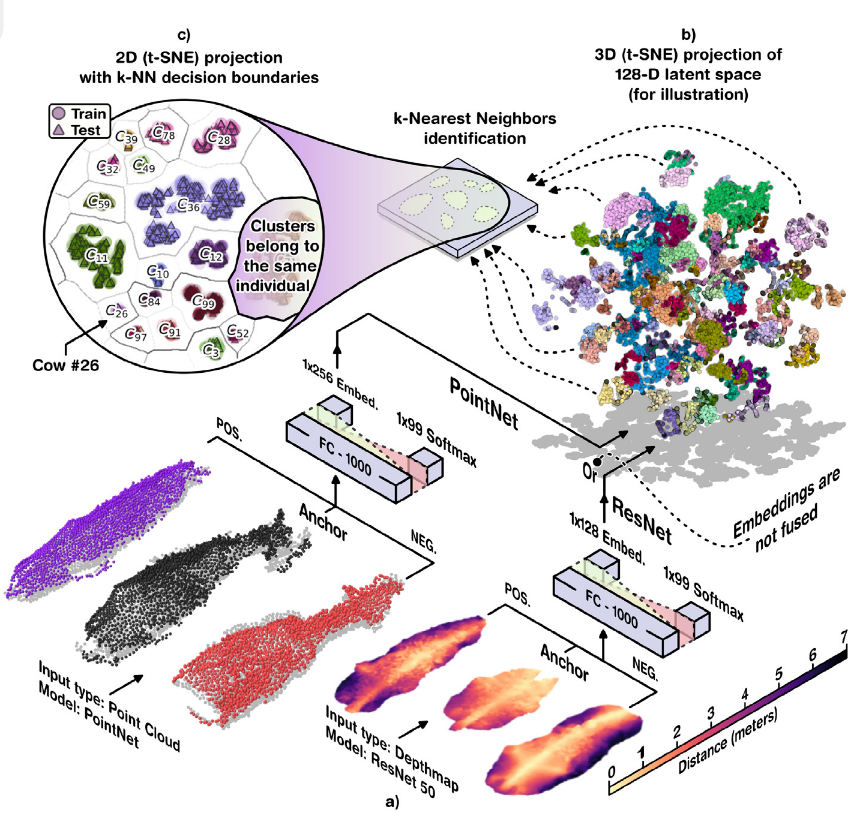
第一段:如何训练:最大化两只不同动物之间的嵌入距离,最小化两只相同动物的深度图或点云之间距离。两个模型均接收三个输入,即锚点、正样本和负样 本。经过前向传播后,模型会生成三个128维向量(或称嵌入),分别 对应这三个输入。
-
信息充分的潜在空间中,锚点嵌入应在几何上非常 接近正样本嵌入,因为它们属于同一只动物。相反,负样本嵌入则会相 距较远,从而形成更紧密的聚类如图b
-
第二段:相同动物近一点,不同动物远一点:锚点代表特定奶牛,最小化锚点与正样本之间距离,最大化锚点与负样本之间距离。
-
第三段:损失函数:倒数三元损失函数与softmax结合损失结合使用,具体表达式


-
第四段:数据增强:通过旋转、 缩放等图像变换手段来增加训练数据的多样性。对原图进行数据增强,使用Augmentor包通过随机的裁剪、平移和旋转为每头牛获取60张新图像。在引入不同的高斯噪声又额外获取了30张图片。对于点云数据提取相同的增强方法。
-
第五段:设备和超参数:部署的机器
Results
对封闭集评估,在有时间偏差的情况下,比较了ResNet和PointNet在输入类型上的性能,数据集按照7:3比例划分5次,确保所有奶牛都在训练集和测试集中。
实验目的:
- 为保留时间偏差的两种模型建立基准
- 对比ResNet的性能,将平均池化层输出直接前馈至嵌入层
- 通过控制输入点数量,评估PointNet对深度差异的鲁棒性
- 确定最佳性能PointNet变体所需的3D点最优数量
ResNet和PointNet模型分别在深度图和点云数据 上表现出良好的泛化能力,其性能与使用被毛图案RGB图像的模型相当。
研究不同点云分辨率对PointNet模型准确率的影响时,我们观察 到其准确率随分辨率降低而逐渐下降
失败案例: 当输入图像缺乏显著毛皮图案(如纯黑 或纯白奶牛)时,带或不带空间上下文模块的ResNet-50(彩色)模型 均会失败。当彩色模型因缺乏被毛图案而失败时, ResNet-50(深度)和PointNet模型却能成功识别
开放集评估: 封闭集与开放集训练的区别 有两点:(1) 我们仅在已知动物上训练模型,(2) 评估时首先生成所有已 知和未知类别的嵌入,并用训练集中对应标签拟合 k-NN分类器
影响PointNet性能的原因有两个:(1) 准确率取决于输入点云的密度——事实上,当我们将输入点数量增至 8192并针对n = 10重新训练PointNet模型时,最低准确率从86.1%提 升至89.72%;(2) 对于所有ResNet实验,我们遵循了使用公开可用权重 的标准实践,这些权重是针对ImageNet数据集的千个类别训练的。