一致性Hash算法:解决扩容缩容时数据迁移问题
目录
1、问题背景
2、一致性Hash算法的原理
2.1 基本思想:Hash环
2.2 容错性与可扩展性(核心优势)
2.3 虚拟节点:解决数据倾斜问题
3、实现与使用
3.1 代码实现
3.2 选择Hash函数
3.3 实际应用中的工具和框架
1、问题背景
传统Hash(取模)的问题:
假设我们有3台缓存服务器(节点),我们用 hash(key) % 3 来决定数据存储在哪个节点上。
-
问题1:节点扩容或缩容时,缓存会大量失效。 如果增加一台服务器(变成4台),公式变为
hash(key) % 4。这会导致绝大多数数据的计算结果发生变化,从而需要重新迁移数据。这被称为缓存雪崩,对后端数据库会造成巨大压力。 -
问题2:不容易实现平滑的负载均衡。 节点宕机时,所有流量会重新分布,可能造成存活节点压力不均。
一致性Hash的目标:在分布式缓存环境中,当节点数量发生变化时,尽可能少地影响已有的数据映射关系,避免大规模的数据迁移。
2、一致性Hash算法的原理
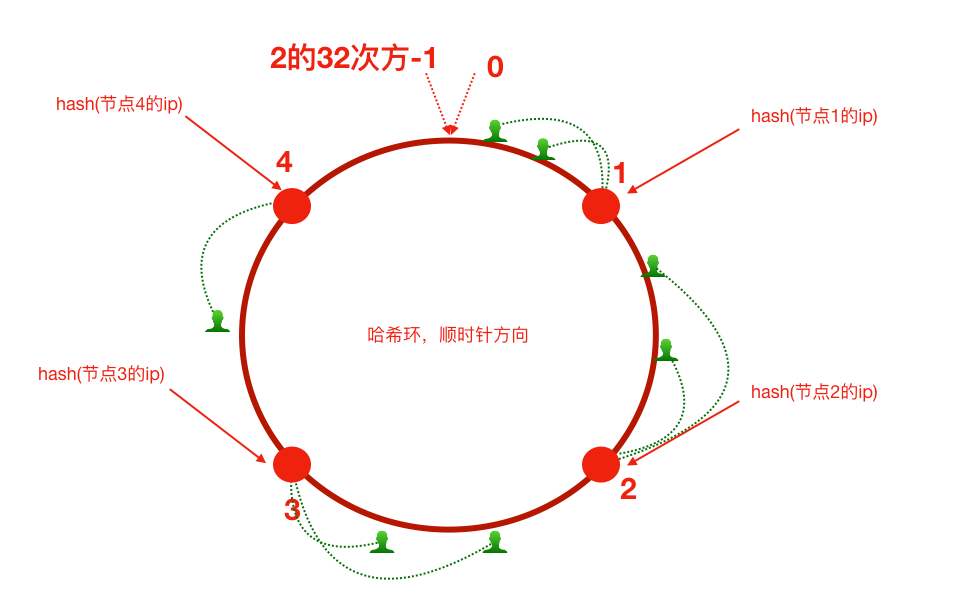
2.1 基本思想:Hash环
-
首先由一条直线,直线开头和结尾分别定为0和2^32 - 1,将这一条线弯过来构成一个圆形的闭环,这样的一个圆环称为Hash环。
-
对缓存节点(可以用IP或名称)进行Hash计算,确定其在环上的位置。
-
对数据Key进行同样的Hash计算,也映射到环上。
-
数据存储规则:从数据Key在环上的位置开始,顺时针查找,找到的第一个节点,就是该数据所属的节点。
2.2 容错性与可扩展性(核心优势)
-
增加节点:假设在Node2和Node3之间加入Node4。那么只会影响原本从Node2顺时针到Node4之间的数据(这部分数据原本属于Node3,现在要迁移到Node4)。其他大部分数据不受影响。
-
移除节点:假设Node1宕机。那么原本属于Node1的数据会顺时针找到下一个节点Node2。只有Node1到Node2之间的数据受影响,需要迁移到Node2上。
这极大地减少了节点变动带来的数据迁移量。
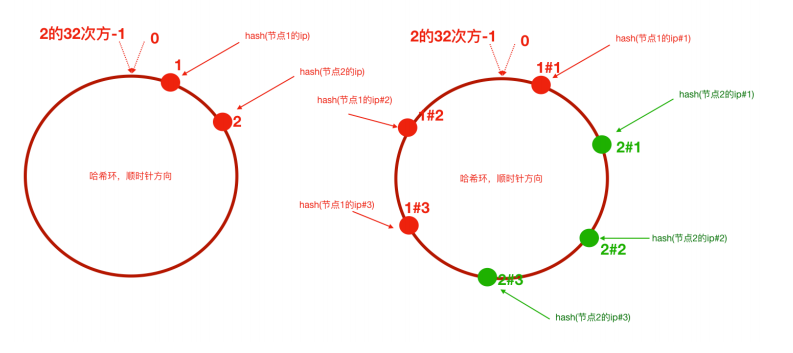
2.3 虚拟节点:解决数据倾斜问题
新问题:数据倾斜与负载不均
-
如果节点数量很少,或者节点的Hash值在环上分布不均匀,会导致某些节点负责的环段很长,存储的数据过多,而其他节点负责的环段很短。这就是数据倾斜。
-
极端情况下,大部分数据可能都落在一个节点上。
解决方案:虚拟节点
-
为每个物理节点计算多个Hash值(即创建多个虚拟节点),让这些虚拟节点均匀分布在环上。
-
数据先映射到虚拟节点,再由虚拟节点决定其所属的物理节点。
-
优点:
-
负载均衡:即使物理节点很少,大量的虚拟节点也能使数据在环上分布得更均匀。
-
物理节点负载均衡:当某个物理节点性能较好时,可以为其分配更多的虚拟节点,让它承担更多的数据。
-
这是实际应用中必不可少的一步! 不引入虚拟节点的简单一致性Hash实现基本没有实用价值。
3、实现与使用
3.1 代码实现
一致性Hash的核心是在环上快速查找。Java中最适合的数据结构是 TreeMap,因为它提供了 tailMap(key) 方法,可以高效地找到大于等于指定key的第一个元素(即顺时针查找)。
一个简单的代码框架:
import java.util.SortedMap;
import java.util.TreeMap;public class ConsistentHash<T> {// 使用TreeMap表示Hash环,key为节点的hash值,value为节点本身private final SortedMap<Integer, T> circle = new TreeMap<>();// 每个物理节点对应的虚拟节点数量private final int numberOfReplicas;// Hash函数private final HashFunction hashFunction;public ConsistentHash(int numberOfReplicas, Collection<T> nodes) {this.numberOfReplicas = numberOfReplicas;this.hashFunction = new MD5Hash(); // 可以使用其他Hash函数,如FNV1_32_HASH// 初始化,将所有节点加入环中for (T node : nodes) {add(node);}}// 添加节点(物理节点+虚拟节点)public void add(T node) {for (int i = 0; i < numberOfReplicas; i++) {// 为节点生成虚拟节点的key,例如:"192.168.1.1#0", "192.168.1.1#1"...int hash = hashFunction.hash(node.toString() + "#" + i);circle.put(hash, node);}}// 移除节点public void remove(T node) {for (int i = 0; i < numberOfReplicas; i++) {int hash = hashFunction.hash(node.toString() + "#" + i);circle.remove(hash);}}// 根据数据key获取节点public T get(Object key) {if (circle.isEmpty()) {return null;}int hash = hashFunction.hash(key);// 如果该hash值正好映射到一个节点,直接返回if (!circle.containsKey(hash)) {// 获取大于等于该hash值的子映射SortedMap<Integer, T> tailMap = circle.tailMap(hash);// 如果tailMap为空,说明到了环的尾部,返回环的第一个节点(顺时针查找)hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();}return circle.get(hash);}
}3.2 选择Hash函数
-
要求:散列性要好,尽可能均匀。
-
选择:
MD5、CRC32、MurmurHash等。在Java中,可以使用Guava库的Hashing工具类,它提供了高质量且性能好的Hash函数(如murmur3_32)。
3.3 实际应用中的工具和框架
通常不需要自己从头实现,有成熟的工具在用:
-
Redis Cluster: 其数据分片(Sharding)的核心思想就是一致性Hash的变种(引入了Hash Slot的概念)。
-
Memcached: 客户端分布式策略通常包含一致性Hash。
-
Dubbo: 负载均衡策略中有“一致性Hash”选项。
-
Nginx:
upstream模块的hash指令可以实现一致性Hash负载均衡。 -
Java库: 比如 Google Guava 的
Hashing.consistentHash()方法提供了一个简单实现。但生产环境建议使用更完善的客户端或库。