AI浏览器概述:Browser Use、Computer Use、Fellou
概述
Browser Use
官网,GitHub,70.2K Star,8.2K Fork。基于Python+Playwright+LangChain+LLM,能够让智能体发起网页访问、操作页面元素、收集信息、执行脚本等,扩展AI应用的落地场景。
功能列表:
- 浏览器自动化:支持网页导航、表单填写、数据抓取等操作,基于Playwright实现高效的浏览器控制
- AI决策能力:通过LangChain框架兼容多种LLM,利用模型生成操作指令并处理复杂逻辑
- 多标签页管理:自动切换和管理多个浏览器标签页,提升多任务处理效率
- 自我纠正机制:在操作遇到错误时自动调整策略或重试,提高任务成功率
- WebUI界面:基于Gradio提供图形化操作界面,支持实时查看浏览器交互和屏幕录制功能
- 跨平台与自定义:支持本地或Docker部署,支持使用个人浏览器,保留登录状态和历史记录
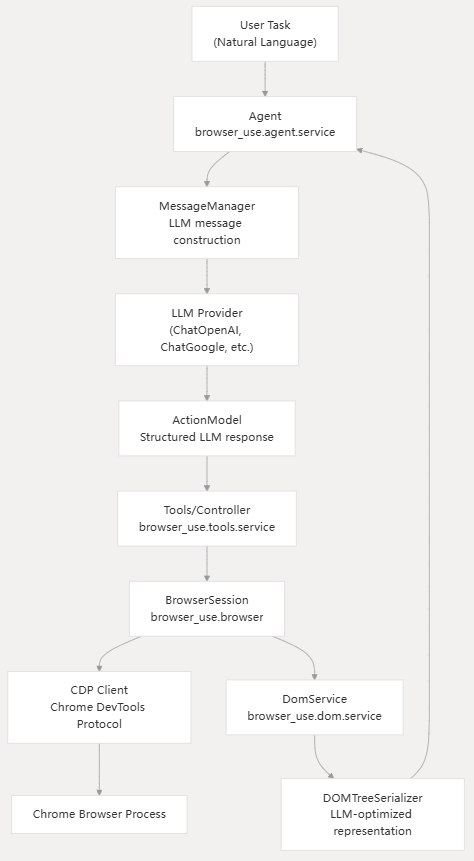
架构
流程示意图
目录结构
再看看browser-use目录
核心模块:
- Actor:
- Agent:核心协调者,负责协调所有组件的工作,是整个流程的中心
- Controller: 动作执行者,负责执行各种浏览器操作,衔接Agent和Browser
- Browser:操作对象,负责实际的浏览器操作,与网页进行交互
- Dom:DOM处理者,负责提取和处理DOM元素,为Browser提供支持
- LLM:对接各大主流LLM对话
- MCP:衔接MCP Server和Client
- Telemetry:可观测性支持,负责记录各种事件
实战
安装:
pip install browser-use
npm init playwright@latest
示例
import asyncio
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from browser_use import Agentload_dotenv()
llm = ChatOpenAI(model="gpt-4o")
async def main():agent = Agent(task="打开https://www.google.com,获取页面里所有h1标签文本",llm=llm,)result = await agent.run()print('result:', result)if __name__ == "__main__":asyncio.run(main())
Web UI
除Python SDK外,官方还提供开源(GitHub,14.9K Star,2.6K Fork)Web UI,启动命令:
git clone https://github.com/browser-use/web-ui.git
cd web-ui/
python webui.py
浏览器打开,
可直接在浏览器中直接配置任务,不需写Agent代码。
Playwright
官网,微软开源(GitHub,77.3K Star,4.6K Fork),用于Web自动化和端到端(End-to-End,E2E)测试的开源框架。支持多种浏览器(Chromium、Firefox和WebKit)和多种编程语言(JS/TS、Python、Java和.NET),对单页应用(SPA)、动态加载、iframe、多标签页都能稳定处理,旨在提供可靠、快速且功能丰富的自动化测试解决方案。
应用场景:
- E2E测试:可模拟真实用户的使用场景,测试网站从头到尾的整个流程是否正常工作;
- Web爬虫和数据抓取:从网页上自动化地获取数据,可渲染JS动态加载内容,比传统爬虫工具更强大;
- 网页自动化:任何重复性网页操作,如自动签到、批量下载文件、填写报告等,都可以用Playwright来自动化;
- 生成截图和PDF:网页截图、网页内容保存为PDF文件。
官方提供VS Code插件。
三个核心概念/对象:
- Browser:浏览器,自动化过程起点。启动Browser示例,在其内部创建多个独立会话;
- BrowserContext:浏览器上下文,独立的浏览器会话。完全隔离页面、本地存储、cookies等数据;
- Page:页面,代表浏览器上下文中的标签页或窗口。所有操作,如点击、输入、导航、截图等,都是在Page对象上执行的。
一个Browser可包含多个BrowserContext,一个BrowserContext可包含多个Page;通常只需一个Browser和一个BrowserContext。多BrowserContext实例用于数据隔离场景,同时运行多个互不影响的任务,类似隐身模式。
| 对比项 | Selenium | Playwright |
|---|---|---|
| 开源时间 | 2004年,历史悠久 | 2020年,后起之秀 |
| 浏览器支持 | Chrome、IE等 | Chromium,Firefox,WebKit(现代浏览器全覆盖) |
| API设计 | 早期接口多,稍显复杂 | API简洁现代,学习成本低 |
| 执行速度 | 较慢,常遇到等待问题 | 更快,更少超时 |
| 特殊功能 | 较强大,生态成熟 | 原生支持截图、录制视频、Mock网络请求 |
安装:npm init playwright@latest
常用命令行:
npx playwright test # 运行全部测试
npx playwright test login.spec.js # 测试指定文件
npx playwright codegen # 启动录制工具,自动生成脚本
npx playwright show-report # 打开测试报告
示例
await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
await page.reload({ waitUntil: 'networkidle' });
await page.goBack();
await page.goForward();
await page.waitForLoadState('load'); // 页面和资源全部加载完
await page.waitForSelector('#main-content'); // 等待元素出现
// 文件上传
await page.setInputFiles('input[type="file"]', 'avatar.png');
const upload = page.locator('input[type=file]');
await upload.setInputFiles(['1.png', '2.png']);
// 下载文件
await page.goto('https://the-internet.herokuapp.com/download');
const [download] = await Promise.all([page.waitForEvent('download'),page.click('a[href="some-file.txt"]'),
]);
await download.saveAs('downloads/some-file.txt');
console.log('下载完成:', await download.suggestedFilename());await page.screenshot({ path: 'home.png', fullPage: true });
await page.video()?.saveAs('test.mp4'); // 需开启video记录才可用
Computer Use
2024年10月,Anthropic发布Claude 3.5 Sonnet,首次将Computer Use能力推向公众视野。愿景:开发人员可通过API指导Claude像人类一样使用计算机——查看屏幕、移动光标、点击按钮、输入文本。开源仍处于体验阶段的demo代码。
2025年1月,OpenAI推出Operator及其核心模型Computer-Using Agent(CUA)。官方文档。
CUA依赖视觉模型和高级推理模型,过程可分为三个步骤:
- 感知:截取计算机屏幕的屏幕截图,以将数字环境的内容置于上下文中。视觉输入构成决策的基础;
- 推理:利用思维链推理,评估其观察结果并跟踪中间步骤的进度。通过分析过去和当前的屏幕截图,可动态地适应新的挑战和不可预见的变化;
- 行动:使用虚拟鼠标和键盘执行键入、单击和滚动等任务。对于敏感任务,例如处理登录凭证或解决CAPTCHA质询,系统会寻求用户确认以确保安全性。
基准测试
包括:
- OSWorld:一般计算机使用任务
- WebArena:模拟电子商务和内容管理中的实际任务
- WebVoyager:测试实时网站交互
产品
除去Claude和OpenAI外,其他闭源产品:
- Manus:默认大家都用过至少听过;
- Project Mariner:Google DeepMind推出,基于Google的Gemini 2模型;
- Flowith:类似Manus,旨在通过其独特的节点式交互方式,为用户提供高效多线程的AI交互体验。提供知识管理、内容创作、自动化任务执行等功能,适合内容创作者、研究人员、企业员工等多类用户。
- Google AI Studio:集成多种AI功能且易于使用的AI开发平台,专注于简化AI模型的创建、优化和部署流程。支持通过文字或语音让Google AI Studio借助于浏览器或电脑做一些自动化的操作。
- GLM-PC:智谱推出,基于CogAgent视觉语言大模型的电脑智能体。内测中,支持深度思考模式、Windows和Mac系统。
项目
开源项目,参考awesome-computer-use:
- open-computer-use:E2B开源(GitHub,1.6K Star,209 Fork)。E2B,Environment to Build缩写,一个专为AI应用和AI代理设计的开源云端沙盒环境,旨在为AI提供一个长期稳定的运行平台。
- OpenInterpreter:GitHub,60.5K Star,5.2K Fork。自然语言接口工具,允许LLM在本地运行代码,支持Python、JS等多种语言。用户可通过类似ChatGPT的界面与计算机互动,执行文件编辑、浏览器控制和数据分析等任务。
- Midscene.js:Web自动化开源(GitHub,10.3K Star,736 Fork)项目,旨在让AI成为浏览器操作员。用户只需用自然语言描述需求,AI就能操作网页、验证内容和提取数据。支持多种模型,包括UI-TARS和Qwen2.5-VL等开源模型,适用于UI自动化场景。Midscene Chrome扩展还支持一种桥接模式,允许用户使用本地脚本来控制Chrome的桌面版本。
- OmniParser:微软开源(GitHub,23.6K Star,2K Fork),能将LLM转化为具备计算机操作能力的智能Agent。通过视觉解析技术,将用户界面的屏幕截图转换为结构化数据,使LLM能够理解和操作GUI,从而实现跨平台自动化任务。
- OpenInterface:开源(GitHub,2.4K Star,250 Fork),提供简洁的API接口,支持多种编程语言和框架,帮助开发者快速实现功能集成和自动化任务。
Mobile Use
论文,开源(GitHub,1.6K Star,111 Fork)的AI代理工具。可通过自然语言控制Android和iOS设备。理解自然语言指令,自动操作UI界面,完成任务。支持多种LLM,可快速部署使用,可提高手机端操作效率。
功能
- 自然语言输入:支持通过自然语言给手机发送指令,就像是跟好朋友聊天一样,把你想要做的事,跟他说出来,他就会帮助你完成。成为你工作中的得力小帮手
- 支持操作多应用:不仅支持单个APP的操作,还支持多APP的操作,可以理解和解析屏幕上的UI元素,而不是依赖坐标定位,让你可以更智能地浏览不同的应用界面
- 支持数据抓取:支持从任何应用中提取数据,并且可以通过自然语言描述将其转化为我们所需要的结构化格式
- 支持多种AI模型:支持配置多种不同的LLM模型,如Qwen等,方便快捷配置
实战
对于Android手机,打开开发者模式和USB调试模式,通过USB连接到电脑上。
git clone https://github.com/minitap-ai/mobile-use.git
cd mobile-use
cp .env.example .env
# 配置.env文件
OPENAI_BASE_URL=
OPENAI_API_KEY=api-key
chmod +x mobile-use.sh
bash ./mobile-use.sh \"Open Gmail, find first 3 unread emails, and list their sender and subject line" \--output-description "A JSON list of objects, each with 'sender' and 'subject' keys"
Fellou
官网,全球首个Agent化浏览器,基于Browser+Workflow+Agent架构。
2.0的升级概要:
- 更快:减少等待,多任务并行,交付更多;
- 更惊人:多样任务交付,7*24全天候执行;
- 更可靠:生产级多样化场景覆盖,成功率大幅提升,Online-mind2web榜单从31%到80%。
基于Eko 2.0,目前需要在提示词前加上Use Workflow,才能开启新版能力。
Code Agent现场撸代码,生成一份网页报告,信息丰富,样式精美,表格图表俱全。
从社交媒体监控到数据聚合,自动化执行可以跨越50多个平台。
Eko
官网,GitHub,4.6K Star,394 Fork,定位:Browseruse和Computeruse框架。Eko 2.0中,提供Multi Agent,DOM状态变化监听、Loop Tasks管理、Workflow规划等多项必须的基建能力。
Dia
官网,内测中。
Nanobrowser
官网,一款运行于浏览器中的开源(GitHub,9.6K Star,960 Fork)Web自动化AI工具,安装使用简单,无需代码基础。通过简单的自然语言描述,将指令传入给智能体,进行计划、执行、校验最终给出答案,整个过程无需人工干预。
功能
- 多智能体协同:内置多个智能体共同协同,包括计划模块、执行模块、校验模块,共同来完成一个复杂的任务
- 交互式侧面板:采用侧边栏进行交互,方便打开和关闭。可以实时查看每一步任务,节点更新的状态
- 自动执行任务:通过自然语言描述,将指令传递给智能体,它会自动进行计划、执行、校验结果,最终给出一个答案
- 已完成任务继续执行:支持已完成的任务,继续对话,更深入的执行任务,进行解答
- 存档历史记录:支持已经完成的任务,会进行存档,方便后续查找
- 支持多种大模型:支持OpenAI、Ollama等
应用场景:
- 重复表单:
- 数据采集:日常重复搜索关键词,采集数据
- 自动化流程:日常重复的工作流
安装:
- Chrome App市场搜索
- GitHub Release页面下载压缩包
如果安装失败:
切换代理区域解决。

打开设置
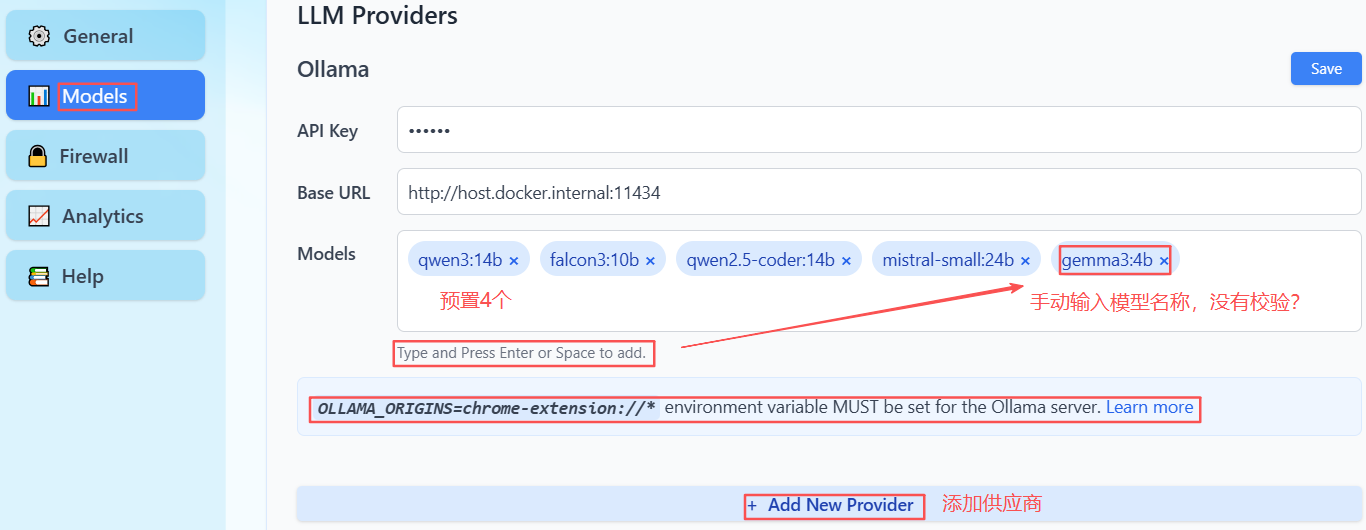
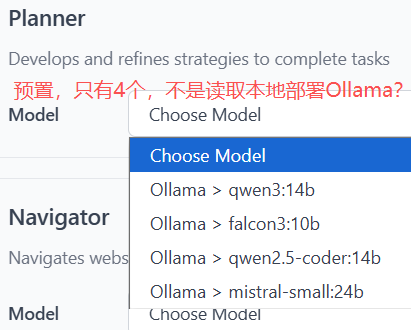
模型配置,主要是3个:
- 规划:MAS多智能体架构核心角色
- 网页浏览:浏览器核心操作
- ASR:语音识别
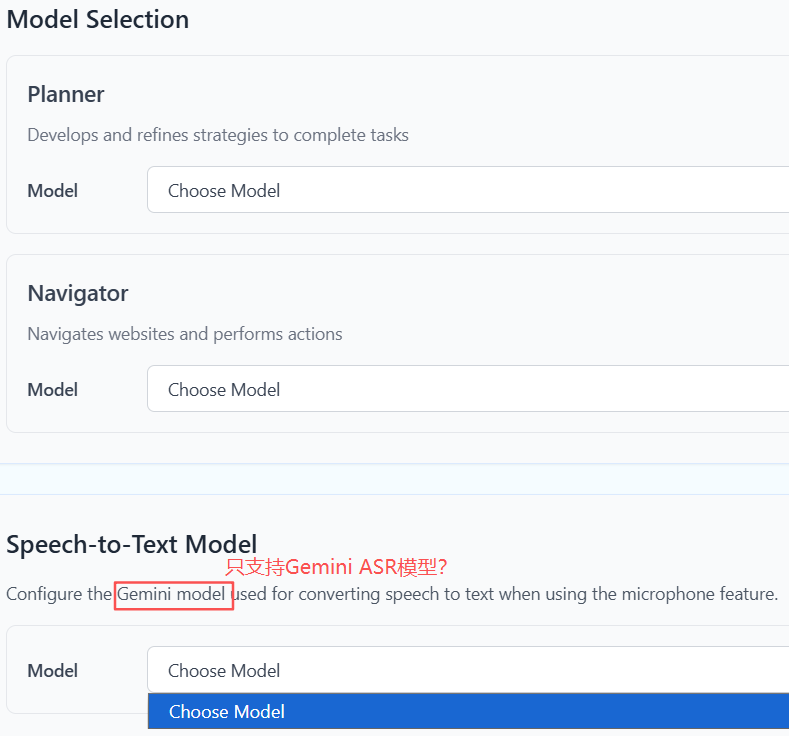
配置Gemini API Key之后,ASR模型下拉框
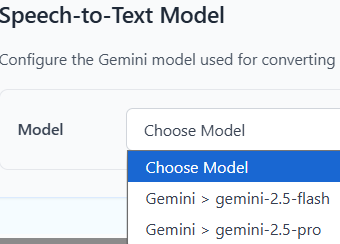
遇到的问题:配置好gemma3:4b模型,无法完成对话
防火墙
BrowserOS
官网,开源(GitHub,4.2K Star,336 Fork)智能体浏览器,核心宗旨,所有数据都保留在本地,保护隐私。支持配置AI模型密钥或使用本地Ollama模型,通过自然语言描述,自动完成任务,即将推出MCP和AI广告拦截功能。
重构Chrome浏览器内核,数据都存在本地。
功能
- AI Agent的应用:对于通用Agent的功能,它都具备。当你给出一条指令后,它会自动打开浏览器访问网站,执行动作,达到最终目标
- 本地AI对话:可以选择浏览器中的标签,与AI对话,让AI帮助总结内容
- 提高效率:可以通过与AI的对话,帮助我们创建不同的标签分组,来提升我们使用的效率
- 界面交互迁移无感知:界面风格和交互,与Chrome保持一致,并且支持把Chrome的所有扩展数据导出到BrowserOS中,让你无缝对接
部署
对比
BrwoserOS:改造Chrome内核,将所有数据都放到本地,号称本地Manus;
OpenManus:通过多个智能体协作,来编排任务模块完成任务;
Browser Use:基于Playwright操控浏览器元素,最终完成指令;
Magentic-UI:采用人机协同模式,实时审批每一步操作,人工干预,执行计划。
Comet
Perplexity推出的Comet,定位是个人AI助手,能够自动化任务、网络研究、整理邮件等。
架构
AI浏览器本质上是一个任务执行引擎,相比传统的页面渲染器,其核心差异在于:
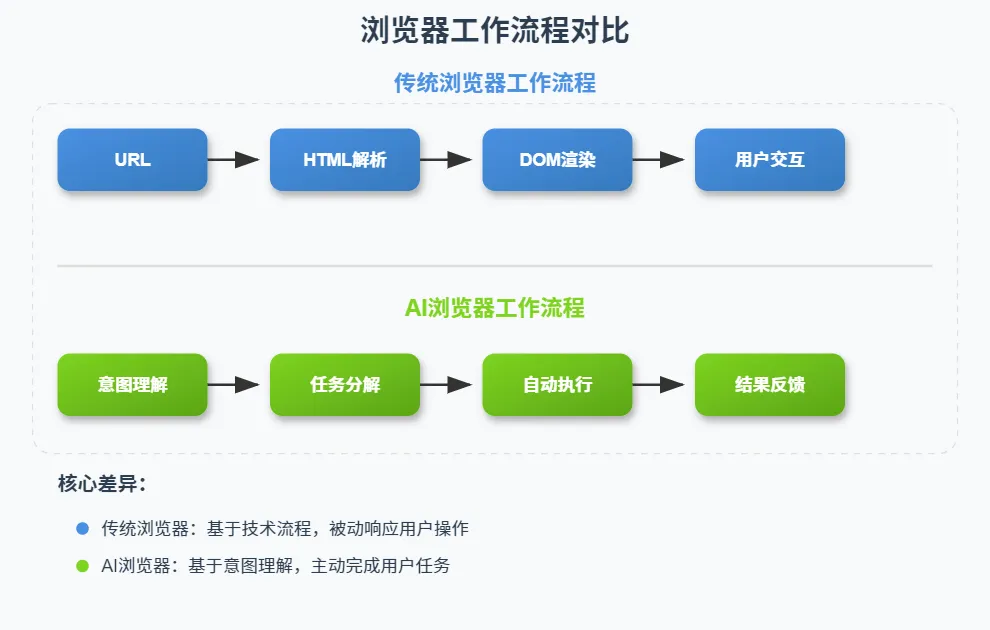
三个关键能力建设:
- 意图解析:将自然语言转换为可执行的操作序列
- 状态管理:维护跨页面、跨会话的上下文信息
- 动作执行:模拟人类的点击、输入、导航行为
技术亮点:
- 混合推理架构
- 多层次推理系统
- Web感知的双重机制
- CDP协议的直接集成
Comet采用分层推理策略解决成本与性能的平衡问题:
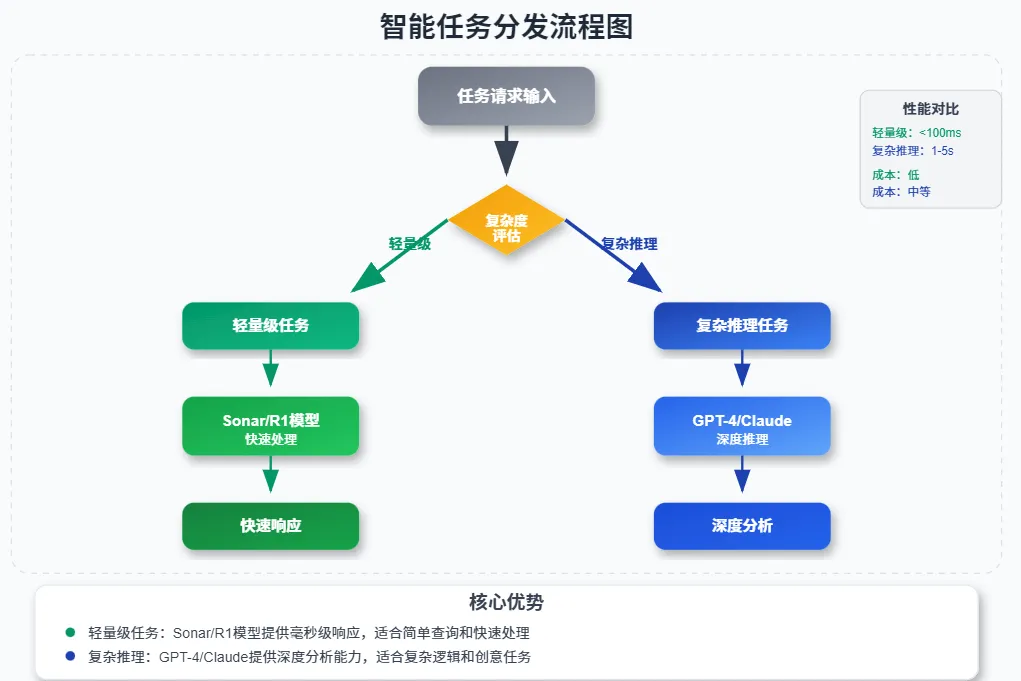
这种设计避免LLM的过度调用,将推理成本控制在可接受范围内。实际测试中,80%的常规任务可由轻量模型完成,仅在需要复杂逻辑推理时才调用重型模型。
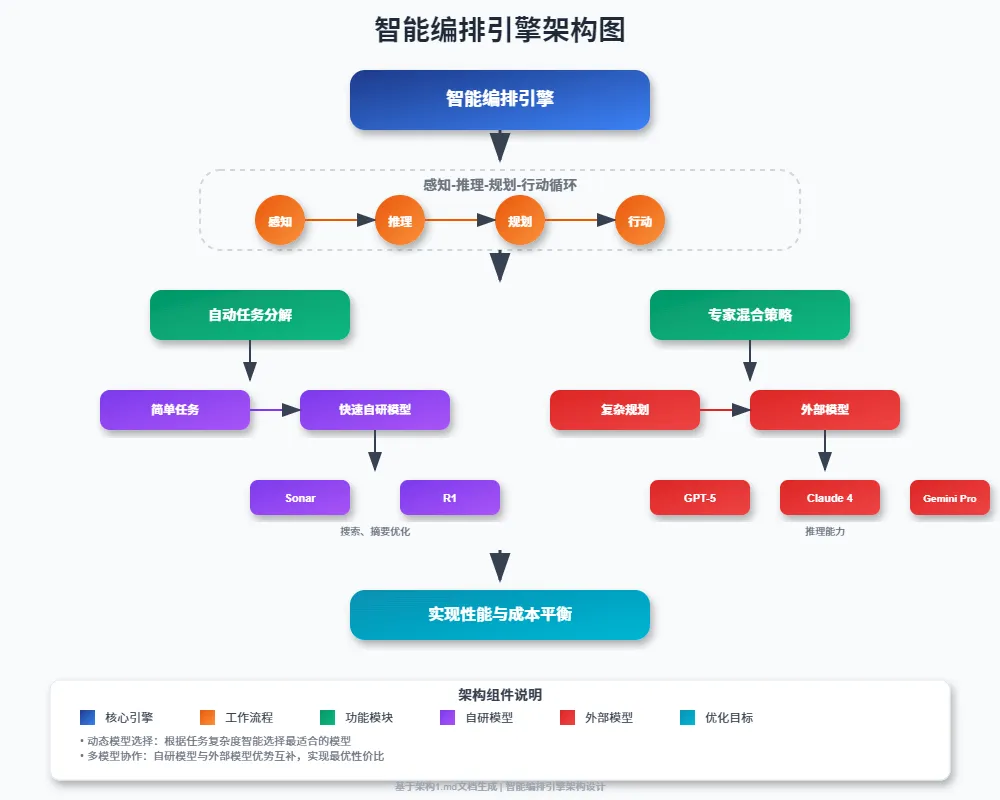
多层次推理系统,可通过智能调度不同能力的模型来平衡性能与成本:
- 执行循环:感知页面状态→理解用户意图→制定执行计划→自动化操作
- 模型调度:轻量任务优先使用自研模型,复杂推理场景调用外部大模型
- 成本控制:通过任务复杂度评估,实现80%常规操作低成本处理,仅在必要时使用重型模型
DOM解析+视觉理解的组合方案解决现代Web应用的复杂性:
- DOM解析:处理语义化HTML,效率高但覆盖有限
- 视觉理解:通过计算机视觉识别页面元素,适应性强但计算开销大
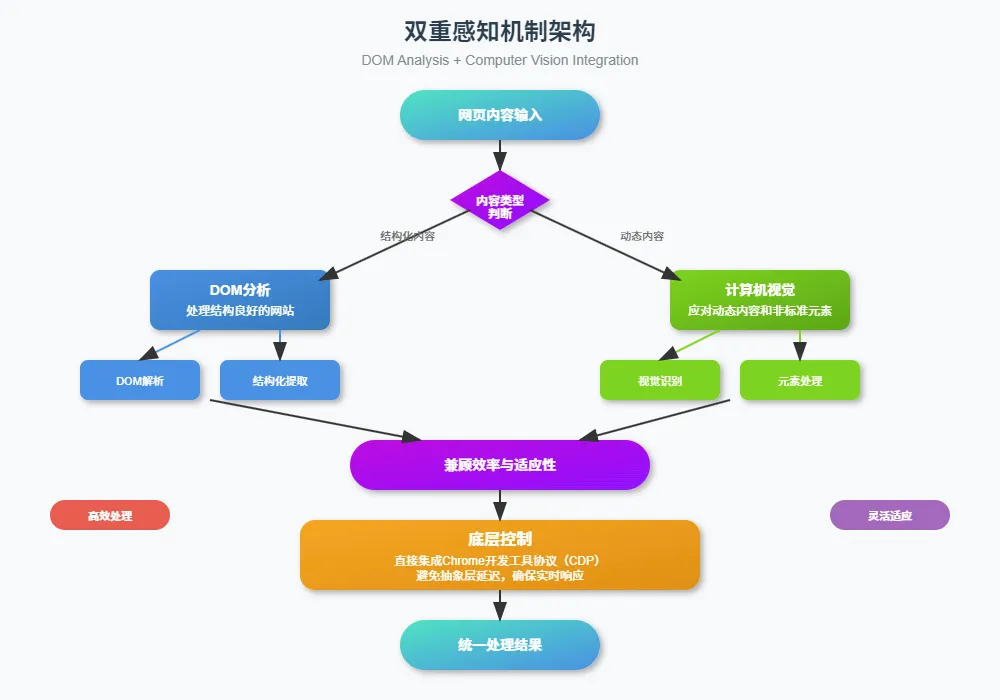
混合方案的优势:对于结构良好的网站(如GitHub、文档站点),优先使用DOM解析获得精确的元素定位;对于重度依赖JS的SPA应用,则启用视觉识别确保兼容性。
Comet绕过Selenium等中间层,直接使用Chrome DevTools Protocol,消除抽象层带来的延迟,使得页面操作的响应时间从秒级降低到毫秒级。直接的协议控制也提供更精细的页面状态管理能力。
duckduckgo
官网,注重隐私安全的搜索引擎,提供Windows等系统应用程序。
brave
官网,同duckduckgo类似,安全浏览器,提供安装程序。
参考
- E2B介绍
- browser-use