embedding多模态模型
向量嵌入embedding
将文本,图像或者文本图像对送入一个嵌入模型,他会对这些对象在一个高维空间中重新定位编码一个坐标,这些坐标之间的距离可以代表他们之间的距离。距离越近,则这些对象越相似。
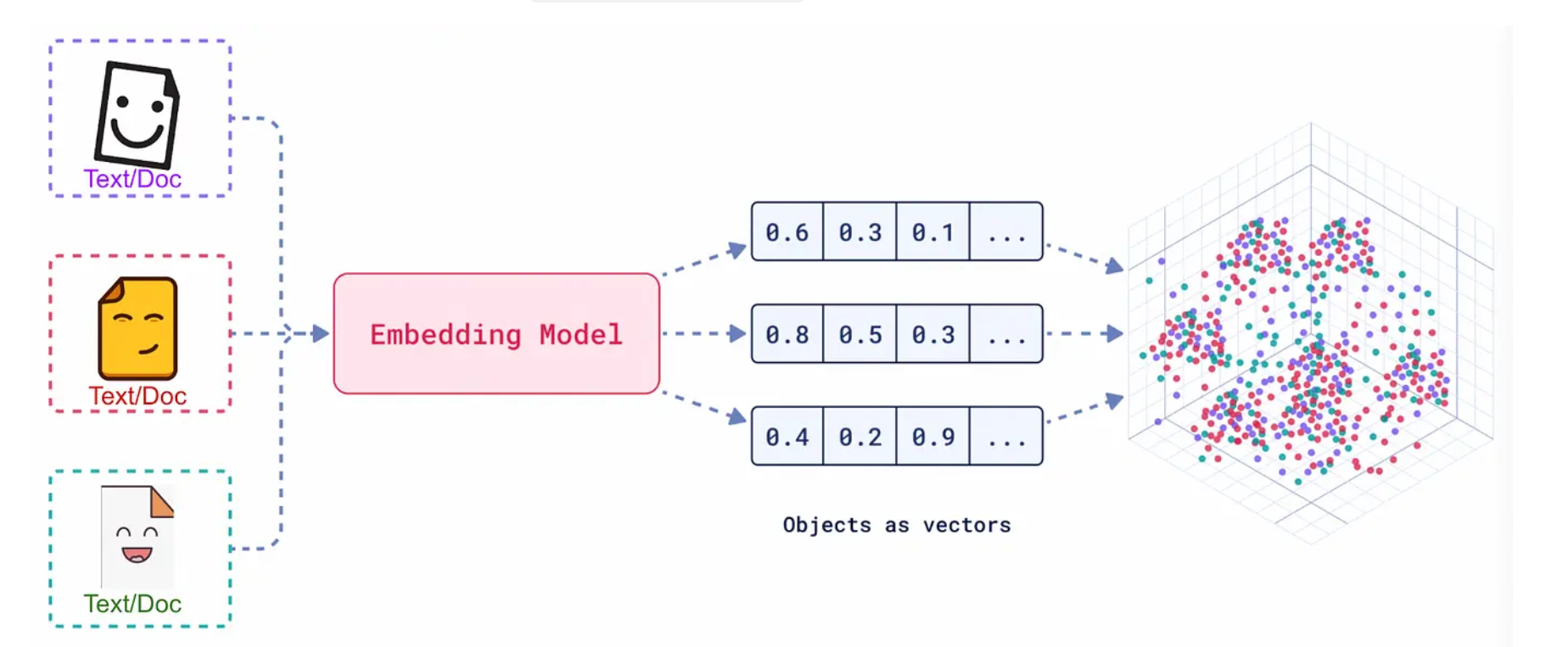
向量的点积代表他们的相似度。
Embedding 的真正意义在于,它产生的向量不是随机数值的堆砌,而是对数据语义的数学编码。
- 核心原则:在 Embedding 构建的向量空间中,语义上相似的对象,其对应的向量在空间中的距离会更近;而语义上不相关的对象,它们的向量距离会更远。
- 关键度量:我们通常使用以下数学方法来衡量向量间的“距离”或“相似度”:
- 余弦相似度 (Cosine Similarity) :计算两个向量夹角的余弦值。值越接近 1,代表方向越一致,语义越相似。这是最常用的度量方式。
- 点积 (Dot Product) :计算两个向量的乘积和。在向量归一化后,点积等价于余弦相似度。
- 欧氏距离 (Euclidean Distance) :计算两个向量在空间中的直线距离。距离越小,语义越相似。
多模态嵌入
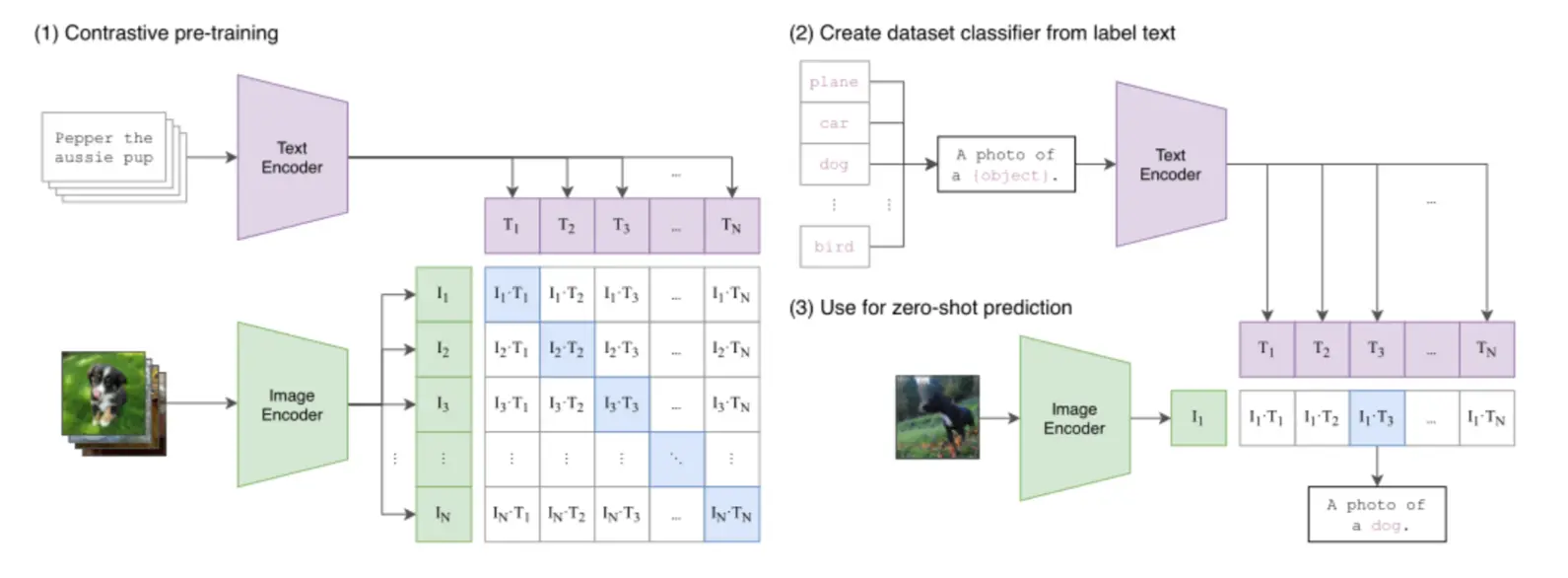
多模态嵌入 (Multimodal Embedding) 的目标正是为了打破这堵墙。其目的是将不同类型的数据(如图像和文本)映射到同一个共享的向量空间。在这个统一的空间里,一段描述“一只奔跑的狗”的文字,其向量会非常接近一张真实小狗奔跑的图片向量。
实现这一目标的关键,在于解决 跨模态对齐 (Cross-modal Alignment) 的挑战。以对比学习、视觉 Transformer (ViT) 等技术为代表的突破,让模型能够学习到不同模态数据之间的语义关联,最终催生了像 CLIP 这样的模型。
嵌入模型的选择需要综合考虑算力,推理速度,语言等因素
在众多优秀的模型中,由北京智源人工智能研究院(BAAI)开发的 BGE-M3 是一个很有代表性的现代多模态嵌入模型。它在多语言、多功能和多粒度处理上都表现出色,体现了当前技术向“更统一、更全面”发展的趋势。
BGE-M3 的核心特性可以概括为“M3”:
- 多语言性 (Multi-Linguality):原生支持超过 100 种语言的文本与图像处理,能够轻松实现跨语言的图文检索。
- 多功能性 (Multi-Functionality):在单一模型内同时支持密集检索(Dense Retrieval)、多向量检索(Multi-Vector Retrieval)和稀疏检索(Sparse Retrieval),为不同应用场景提供了灵活的检索策略。
- 多粒度性 (Multi-Granularity):能够有效处理从短句到长达 8192 个 token 的长文档,覆盖了更广泛的应用需求。
在技术架构上,BGE-M3 采用了基于 XLM-RoBERTa 优化的联合编码器,并对视觉处理机制进行了创新。它不同于 CLIP 对整张图进行编码的方式,而是采用网格嵌入 (Grid-Based Embeddings),将图像分割为多个网格单元并独立编码。这种设计显著提升了模型对图像局部细节的捕捉能力,在处理多物体重叠等复杂场景时更具优势。
代码逻辑
导入嵌入模型,对文本,图像和文本图像对进行编码,然后测试他们之间的相似性。
import torch
from visual_bge.visual_bge.modeling import Visualized_BGEmodel = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5",model_weight="../../models/bge/Visualized_base_en_v1.5.pth")
model.eval()with torch.no_grad():text_emb = model.encode(text="datawhale开源组织的logo")img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")multi_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="datawhale开源组织的logo")img_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png")multi_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="datawhale开源组织的logo")text_emb_3 = model.encode(text="一条龙")img_emb_3 = model.encode(image="../../data/C3/dragon/dragon02.png")multi_emb_3 = model.encode(image="../../data/C3/dragon/dragon02.png", text="一条龙")text_emb_4 = model.encode(text="一只蓝鲸")img_emb_4 = model.encode(image="../../data/C3/blue_whale/blue_whale02.png")multi_emb_4 = model.encode(image="../../data/C3/blue_whale/blue_whale02.png", text="一只蓝鲸")text_emb_5 = model.encode(text="bluewhale")img_emb_5 = model.encode(image="../../data/C3/imgs/datawhale01.png")multi_emb_5 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="bluewhale")img_emb_6 = model.encode(image="../../data/C3/imgs/datawhale02.png")multi_emb_6 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="bluewhale")# 计算datawhale相似度
sim_1 = img_emb_1 @ img_emb_2.T
sim_2 = img_emb_1 @ multi_emb_1.T
sim_3 = text_emb @ multi_emb_1.T
sim_4 = multi_emb_1 @ multi_emb_2.T# 计算龙与datawhale相似度
sim_5 = img_emb_3 @ img_emb_2.T
sim_6 = text_emb_3 @ text_emb.T
sim_7 = multi_emb_1 @ multi_emb_3.T# 计算蓝鲸与datawhale相似度
sim_8 = img_emb_4 @ img_emb_2.T
sim_9 = text_emb_4 @ text_emb.T
sim_10 = img_emb_4 @ multi_emb_4.T
sim_11 = text_emb_4 @ multi_emb_4.T
sim_12 = multi_emb_4 @ multi_emb_2.Tsim_13 = img_emb_4 @ multi_emb_1.T# 计算datawhale相似度(文本替换为bluewhale)
sim_14 = img_emb_5 @ img_emb_6.T
sim_15 = img_emb_5 @ multi_emb_5.T
sim_16 = text_emb_5 @ multi_emb_5.T
sim_17 = multi_emb_5 @ multi_emb_6.T
print("=== Datawhale相似度计算结果 ===")
print(f"纯图像 vs 纯图像: {sim_1}")
print(f"图文结合1 vs 纯图像: {sim_2}")
print(f"图文结合1 vs 纯文本: {sim_3}")
print(f"图文结合1 vs 图文结合2: {sim_4}")print("=== 龙与datawhale相似度计算结果 ===")
print(f"龙 vs 纯图像: {sim_5}")
print(f"龙 vs 纯文本: {sim_6}")
print(f"龙 vs 图文结合1: {sim_7}")print("=== 蓝鲸与datawhale相似度计算结果 ===")
print(f"蓝鲸 vs 纯图像datawhale: {sim_8}")
print(f"蓝鲸 vs 纯文本datawhale: {sim_9}")
print(f"图像蓝鲸 vs 图文结合蓝鲸: {sim_10}")
print(f"文本蓝鲸 vs 图文结合蓝鲸: {sim_11}")
print(f"图文结合蓝鲸 vs 图文结合datawhale: {sim_12}")
print(f"图像蓝鲸 vs 图文结合datawhale: {sim_13}")print("=== datawhale相似度计算结果(文本替换为bluewhale) ===")
print(f"纯图像 vs 纯图像: {sim_14}")
print(f"图文结合1 vs 纯图像: {sim_15}")
print(f"图文结合1 vs 纯文本: {sim_16}")
print(f"图文结合1 vs 图文结合2: {sim_17}")# 向量信息分析
print("\n=== 嵌入向量信息 ===")
print(f"多模态向量维度: {multi_emb_1.shape}")
print(f"图像向量维度: {img_emb_1.shape}")
print(f"多模态向量示例 (前10个元素): {multi_emb_1[0][:10]}")
print(f"图像向量示例 (前10个元素): {img_emb_1[0][:10]}")
分析结果发现:
两个相似图像的相似度很高,文本和图像与图文结合的相似度也很高。(0.7-0.9)
不同图像的相似度比较低,不同文本的相似度和图文的相似度也很低。(0.3-0.6)
图像替换为更真实的蓝鲸后,发现对于之前的相似度反而是下降的,说明模型对于Logo的基本识别能力是存在的。
一模一样的数据,datawhale的两个图片Logo对应文本在被改成了blue whale后,文本相关的相似度发生了一点点下降。图像相关的发生了一些上升。
