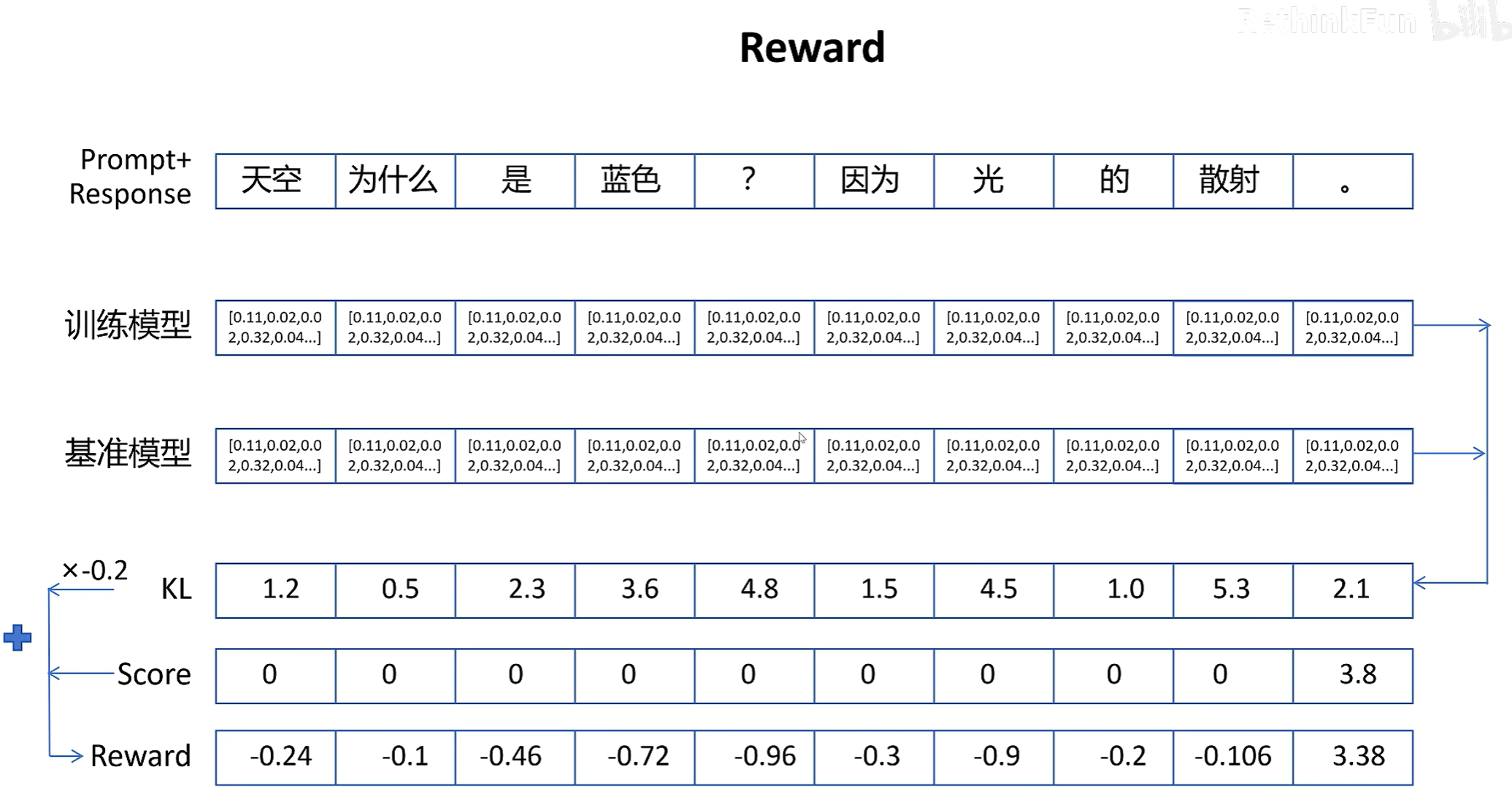
大模型强化学习-PPO应用

如何训练reward模型:
训练数据采用偏好数据:
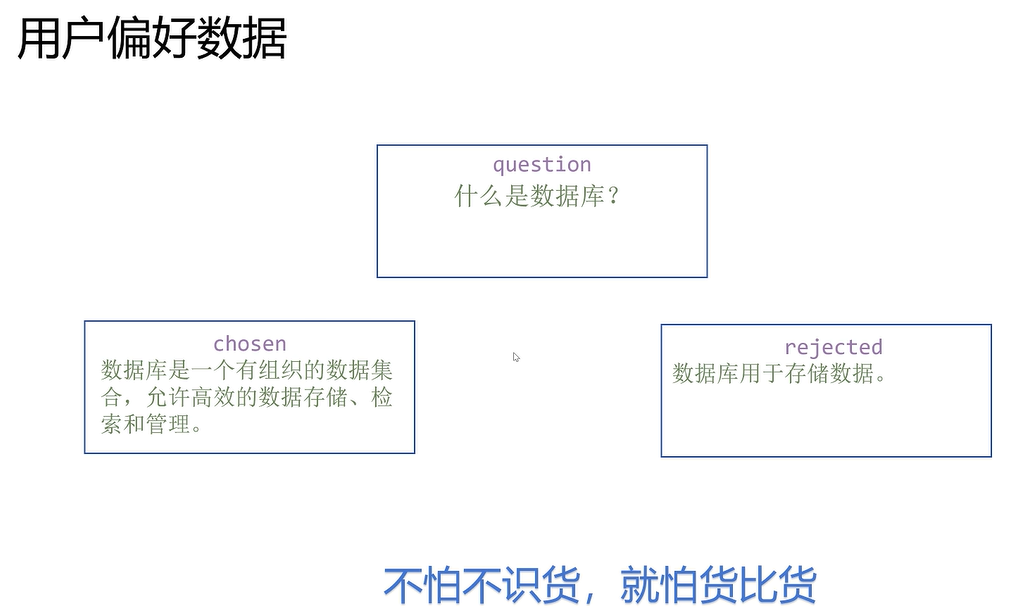
一般都采用和当前大模型能力差不多或者更优的大模型来训练reward模型:
评价一个回答的好坏,总是比生成一个好的回答容易。
那如何利用大模型,针对一个问答对,给出得分呢?
首先把问答拼接在一起,作为输入。只对序列的最后一维调用score head,因为只有最后的序列可以看到前面完整的。
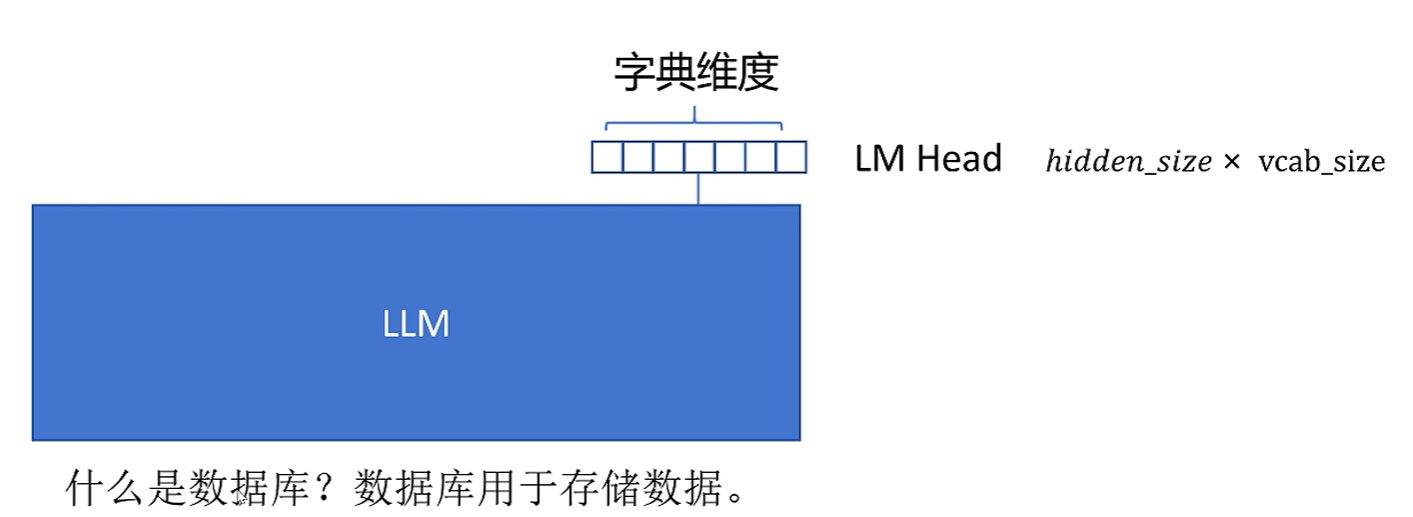

reward模型的loss:

需要调用两次reward模型,分别得到模型对chosen和rejected的得分。然后按照下面的函数:
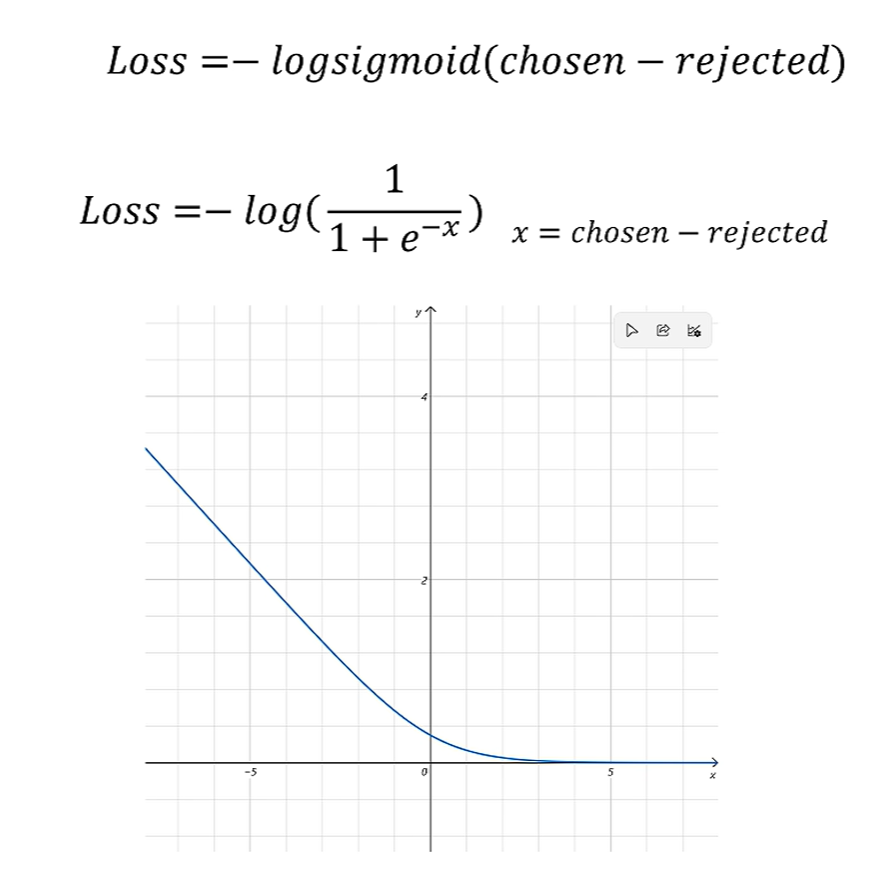
可以看到,如果chosen得分小于rejected得分时,loss呈现指数级增长;反之loss趋近0
数据集样式:

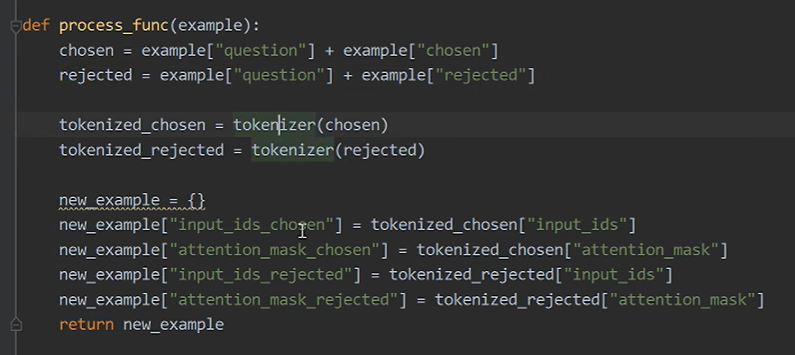
将问题与chosen和rejected回答分别都拼接起来,然后分词。生成一个新数据样本,包含以下四项:
PPO训练:

一般来说需要四个模型:
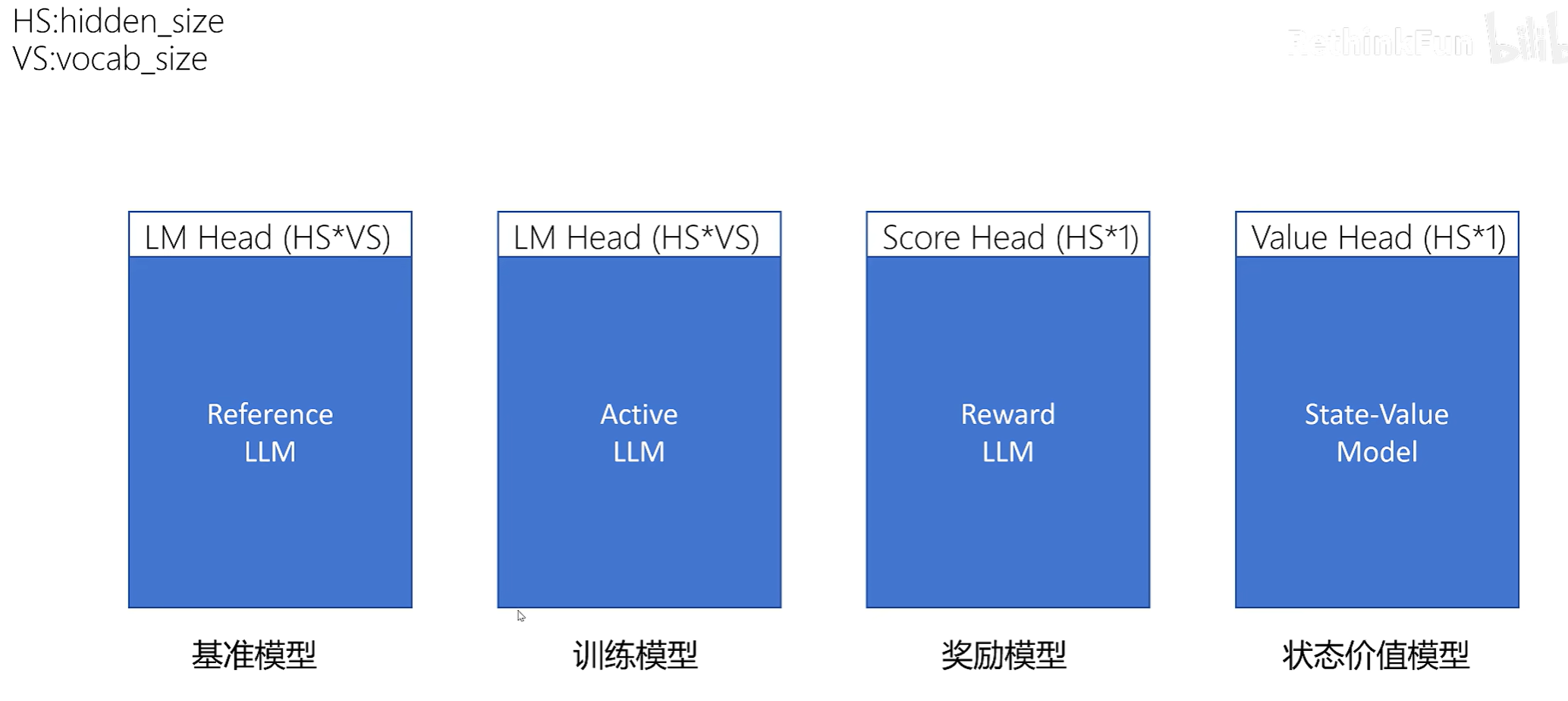
基准模型:一般是SFT之后的大模型。新训练后的模型输出的概率分布不能和基准模型相差太大。
训练模型:它的结构和基准模型的完全一致的,PPO训练的目标就是优化训练模型。它输出的概率分布不能和基准模型相差太大。
奖励模型:它对一个问答序列进行评分。问答对最后一个token序列的输出通过socre_head计算后,就是这个问答序列的得分了。
状态价值模型:对每个状态评估价值。需要对每个token都输出,截止到当前的toekn,期望回报是多少。每个输出的token都共享权重。
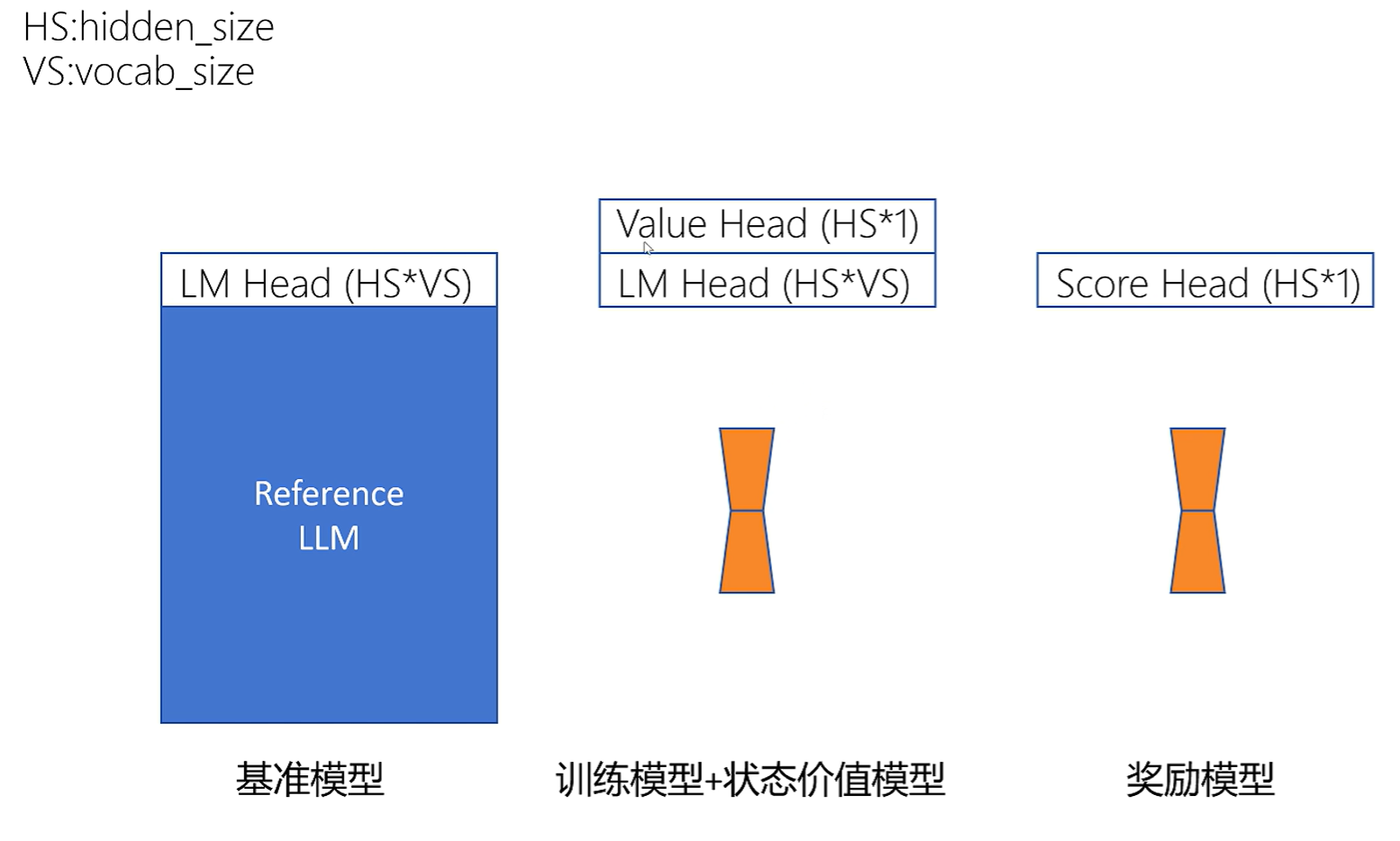
训练时,如果加载四个大模型,参数量太大了。
那么我们可以通过Lora的思想,只加载一个大模型,加载多个Adapter:
对于大模型输出的每一步而言,它的state就是截止到当前输出的token序列,action就是下一个输出的token,大模型就是策略函数。