分库分表后ID冲突怎么解决?分布式ID生成方案。保证ID全局唯一性。
在分库分表场景中,由于数据库的数据被拆分到独立数据库或者独立的表,原本单库单表的自增ID(MySQL 的自增字段 AUTO_INCREMENT) 会因为多个表独立而导致ID全局唯一性冲突。解决这一问题的核心是实现全局唯一性和一些其他特性(有序性,可追溯性)的分布式ID。

一、分布式ID核心要求
全局唯一性:无论在哪个库/表生成, 都要保证唯一ID
高性能:生成ID过程不能成为性能瓶颈(低延迟,高吞吐)
高可用:生成ID的服务不能单点故障
有序性:保证有序,便于(索引,排序,分页操作)
安全性:避免ID泄露业务数据量,(如连续ID可被猜测总量)
二、常见的分布式ID生成方案
1.UUID/GUID
根据MAC地址,时间戳,随机数等128位(36字符)的唯一标识(如550e8400-e29b-41d4-a716-446655440000))
优点:
- 实现简单(几乎所有语言都支持),无序中心化服务
- 无网络依赖,性能极高。
缺点:
- 无序(字符串乱序),不适合做数据库主键(索引效率低)。
- 过长(36字符),存储和运输成本高
- 存在极小概率重复(基于MAC地址的版本可能泄露设备信息)
场景:适用于不要求ID有序,追求极简实现的场景(如日志ID,临时标记)
2. 数据库自增 ID 改进(分段自增)
原理:为每个分库 / 分表分配独立的自增 ID 范围,避免重叠。
- 例如分 3 个库,设置自增步长为 3:
- 库 1:ID 从 1 开始,自增 3(1,4,7,10...)
- 库 2:ID 从 2 开始,自增 3(2,5,8,11...)
- 库 3:ID 从 3 开始,自增 3(3,6,9,12...)
优点:
- 实现简单,复用数据库自增特性,ID 有序。
- 对代码侵入性低。
缺点:
- 扩展性差:新增分库 / 分表时需重新调整步长和起始值,易引发冲突。
- ID 分布不均:若某库数据量激增,可能提前用尽分配的 ID 范围。
适用场景:分库分表数量固定、数据增长可预测的小规模场景。
3.号段模式(批量分配)
原理:从中心数据库申请一段连续的 ID(号段),本地缓存使用,用完后再申请下一段。
- 例如:服务 A 从数据库申请
1-1000的号段,本地按顺序生成 1~1000;用完后申请1001-2000。
实现:
- 中心数据库维护一张号段表(如
id_generator),包含biz_type(业务类型)、max_id(当前最大 ID)、step(号段长度)。 - 服务申请号段时,通过
UPDATE id_generator SET max_id = max_id + step WHERE biz_type = 'xxx'原子操作获取新号段。
优点:
- 减少数据库访问(一次申请一段),性能高。
- 支持动态扩容,新增业务类型只需新增记录。
- ID 有序,适合作为主键。
缺点:
- 服务宕机可能导致未使用的号段浪费(可接受,ID 无需连续)。
- 依赖中心数据库,需保证其高可用(可做主从架构)。
适用场景:中高并发场景,对 ID 有序性和性能有要求(如电商订单 ID)。
4. 雪花算法(Snowflake)
原理:Twitter 开源的分布式 ID 生成算法,生成 64 位长整型 ID,结构如下:
- 符号位:0(保证 ID 为正数)。
- 时间戳:当前时间与基准时间(如 2020-01-01)的差值(毫秒级),可支持约 69 年。
- 机器 ID:标识不同服务节点(最多支持 1024 个节点)。
- 序列号:同一毫秒内的自增序号(最多支持 4096 个 ID / 毫秒)
优点:
- 高性能(本地生成,无网络开销),单机 TPS 可达百万级。
- ID 有序(按时间递增),适合作为数据库主键。
- 可追溯(通过 ID 反推生成时间和机器)。
缺点:
- 依赖系统时钟:若时钟回拨(如 NTP 同步),可能生成重复 ID。
- 机器 ID 需提前分配(需手动配置或通过服务注册中心获取)。
雪花算法回拨问题:
雪花算法(Snowflake)靠 “时间戳 + 机器 ID + 序列号” 生成唯一 ID,且 ID 按时间递增。“回拨问题” 本质是:生成 ID 时用的时间戳,比实际当前时间小(比如服务器时间被手动调回、NTP 同步时时间跳回)。这会导致两个严重问题:
- 生成的 ID 可能和之前已生成的 ID 重复;
- ID 不再按时间递增,破坏雪花算法的核心特性。
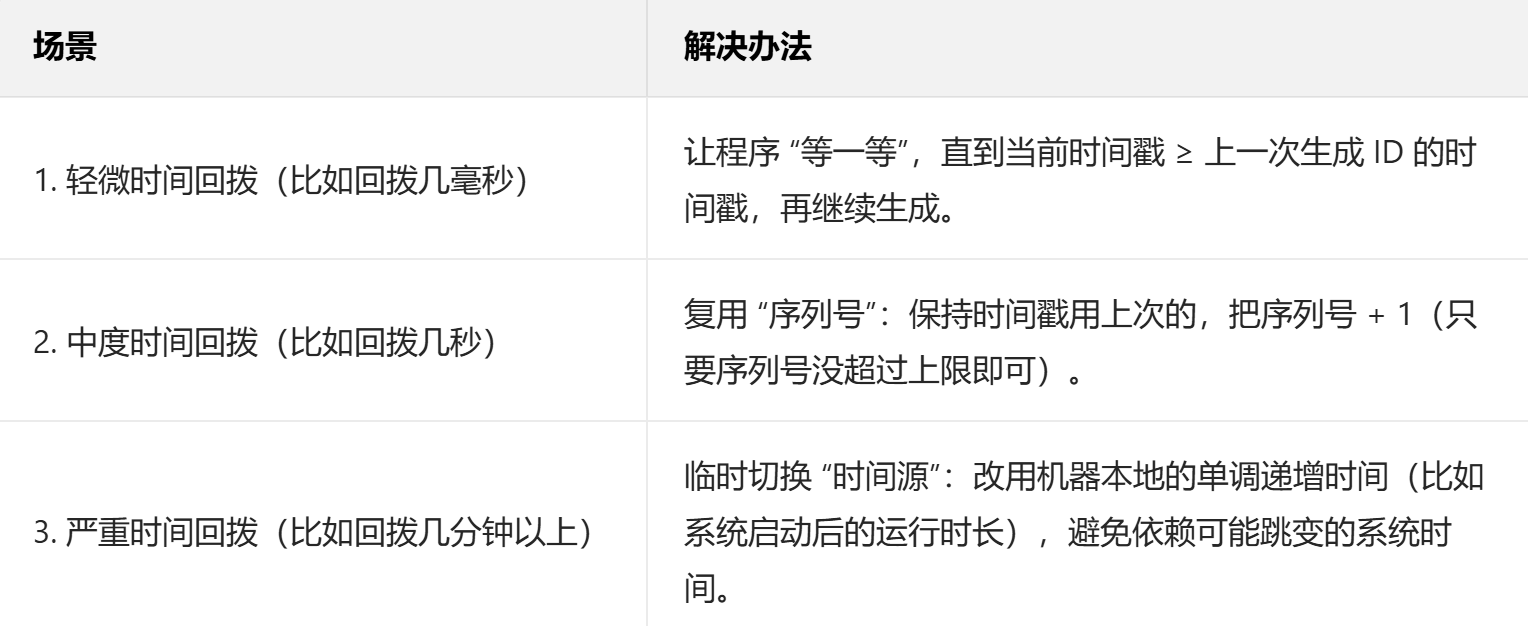
解决方案:核心思路:确保生成 ID 时用的时间戳,永远不小于上一次生成 ID 的时间戳,分 3 类场景处理:
此外,从源头减少回拨:
- 服务器时间用 NTP 服务同步时,配置 “平滑调整”(避免时间跳变,改为缓慢趋近正确时间);
- 严格限制手动修改服务器时间。
优化方案:
- 时钟回拨处理:记录最后一次生成 ID 的时间戳,若发生回拨则等待时钟追上或报错。
- 扩展位:根据需求调整各段位数(如增加机器 ID 位数支持更多节点)。
适用场景:高并发分布式系统(如秒杀、社交平台),对性能和有序性要求高。
5. Redis 自增 ID
原理:利用 Redis 的INCR/INCRBY命令(原子性)生成自增 ID。
- 例如:
INCR order_id每次调用返回全局唯一的递增 ID。
优点:
- 性能极高(Redis 单节点 TPS 可达 10 万 +,支持集群扩容)。
- 实现简单,ID 有序。
缺点:
- 依赖 Redis 可用性:Redis 宕机将导致 ID 生成失败(需做主从 + 哨兵保证高可用)。
- 数据持久化风险:若 Redis 未持久化,重启后可能重复生成已使用的 ID(需开启 AOF+RDB 持久化)。
适用场景:已有 Redis 集群、对 ID 生成性能要求高的场景(如游戏道具 ID)。
6. 其他方案
- MongoDB ObjectId:12 字节 ID,包含时间戳(4 字节)、机器 ID(3 字节)、进程 ID(2 字节)、计数器(3 字节),类似简化版雪花算法。
- ZooKeeper 生成 ID:利用 ZNode 的版本号(
version)自增特性,通过创建临时节点生成 ID,但性能较低(不适合高并发)。
三、方案选择建议
- 追求极简实现 → UUID(不要求有序时)。
- 小规模分库分表 → 数据库分段自增。
- 中高并发 + 有序性 → 号段模式 或 Redis 自增。
- 高并发 + 高性能 + 可追溯 → 雪花算法(需处理时钟问题)。
实际场景中,需结合业务对 ID 的有序性、性能、可用性要求综合选择,必要时可混合使用(如核心业务用雪花算法,非核心用 UUID)。