JUC(8)线程安全集合类
1. 概述


2. ConcurrentHashMap
1. 使用
- ConcurrentHashMap单个方法是线程安全的,但是对同一个集合的两个方法组合并不是原子的。所以需要注意线程安全
- 比如: 对get()和put()方法的原子性:
- 提供了一个computeIfAbsent()这个API来保证两个方法的原子性..
注:当key不存在的时候,mappingFunction方法的结果会作为值直接插入到map中,无需在mappingFunction中再执行put
线程安全版:

2. 原理

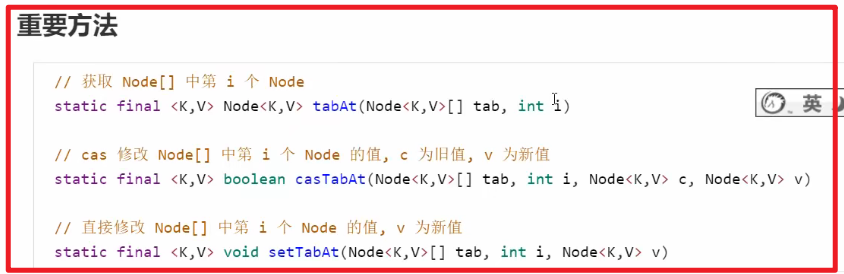
3. 源码分析
1. 构造器分析

2. get()流程
全程是没有加锁的,典型的弱一致性的体现
get()方法中所有的涉及的共享变量都定义成volatile类型,保证读取的都是最新值。根据Java内存模型提供的happends-before规则,规定对volatile变量的读一定发生在写之后,且写的最新数据对读是可见的,这是volatile替换锁的经典场景
扩: cas + volatile的应用
- 原子整数
- 原子引用
- 原子数组
- 原子累加器
- ConcurrentHashMap的get()
3. put()流程
以下数组简称(table),链表简称(bin)
while(ture){
if(当前还未初始化)[CAS]初始化哈希表时使用了cas的方式,保证只会初始化一次.无需synchronized
if(当前数组下标元素为空)[CAS]添加链表头结点时使用了cas,无需synchronized
if(有别的线程正在进行扩容.)[CAS]扩容过程中如果同时put()是会出问题的,在扩容过程中完成了链表的转移后会将链表的头结点设置为forwardNode,且hash值为负数..作为标记. 注意:扩容时以链表为单位,所以协助扩容的时候锁住一个未被转移的链表,就能保证线程安全!eg: 线程1正在进行扩容,将扩容完成的链表头部标志为forwardNode作为标识,线程2正在put()时发现了forwardNode说明此时有线程正在进行扩容,线程2会帮助扩容.锁住一条链表,帮助扩容...以上判断条件解决线程安全都是通过cas的方式,并没有加锁.只有当桶下标冲突的时候,才采用synchronized来加锁..(如下)
if(当前数组下标有元素,桶下标发生了冲突)[synchronized]锁住链表的头结点然后进行链表的遍历来put.当释放锁之后,会对链表做一些优化,决定树化(8 64) / 扩容(阈值)..
4. size计数

其实就是使用了LongAdder的思想。
ConcurrentHashMap因为多线程下,所以计数不会完全准确,这也体现了其缺点"弱一致性"
5. 扩容
以链表为单位,一个链表一个链表来迁移
- 如果链表为空,说明处理完了,将其处理为forwardingNode
- 如果已经是fwd了,说明当前的链表已经转移结束,处理下一个链表
- 走到这里说明 链表有元素,则进行对哈希桶的上锁(synchronized)操作来锁住链表保证线程安全 ,里面还会判断是普通节点还是树节点(hashcode>0 是普通,hashcode<0 是树)
6. ConcurrentHashMap1.7和1.8的区别
JDK1.7 中的 ConcurrentHashMap
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
如下图所示,首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据时,其他段的数据也能被其他线程访问,实现了真正的并发访问。
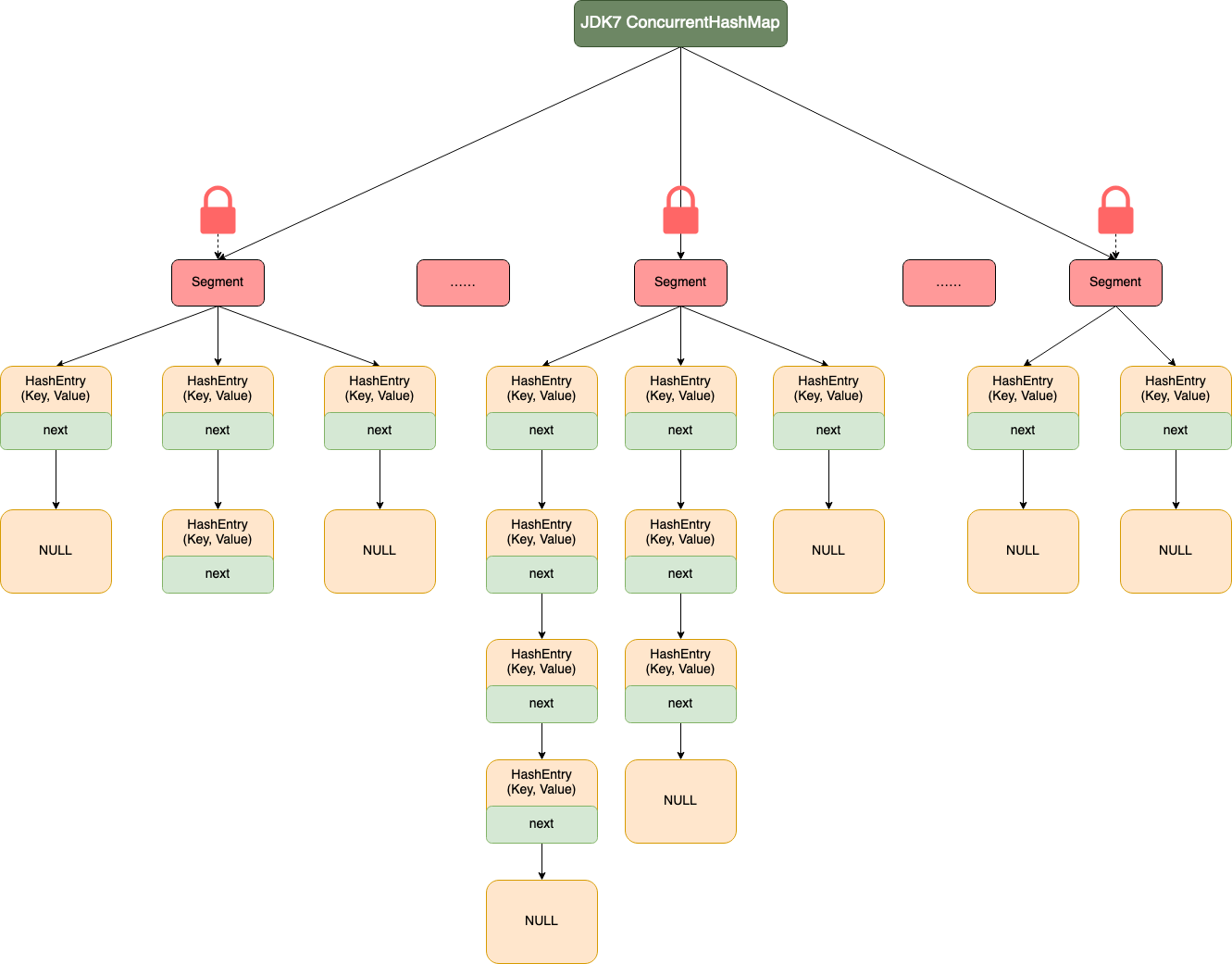
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。
简单来说就是,ConcurrentHashMap 是一个 Segment数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
Segment
Segment 本身就相当于一个 HashMap 对象。
同 HashMap 一样,Segment 包含一个 HashEntry 数组,数组中的每一个 HashEntry 既是一个键值对,也是一个链表的头节点。
单一的 Segment 结构如下: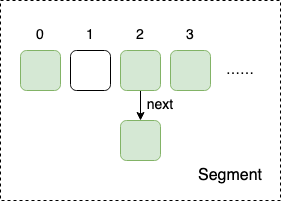
concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16,也就是说默认情况下 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。最大不超过 MAX_SEGMENTS 也就是2^16。
默认是 16 个,共同保存在一个名为 segments 的数组当中。 因此整个ConcurrentHashMap 的结构如下: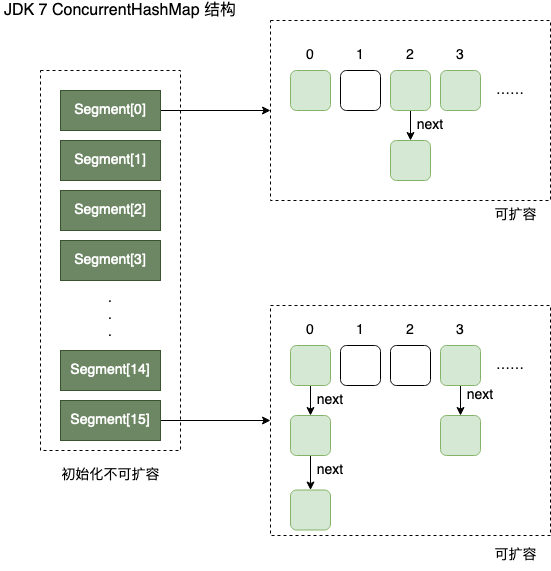
可以说,ConcurrentHashMap 是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
这样的二级结构,和数据库的水平拆分有些相似。
JDK1.8 中的 ConcurrentHashMap
虽然 JDK1.7 中的 ConcurrentHashMap 解决了 HashMap 并发的安全性,但是当冲突的链表过长时,在查询遍历的时候依然很慢
在 JDK1.8 中,HashMap 引入了红黑二叉树设计,当冲突的链表长度大于 8时,会将链表转化成红黑二叉树结构,红黑二叉树又被称为平衡二叉树,在查询效率方面,又大大的提高了不少。
在数据结构上, JDK1.8 中的 ConcurrentHashMap 选择了与 HashMap 相同的数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用 CAS + synchronized 实现更加细粒度的锁。
将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点或者红黑树的根节点,就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。
我们再来看看 JDK1.8 中 ConcurrentHashMap 的整体结构,内容如下: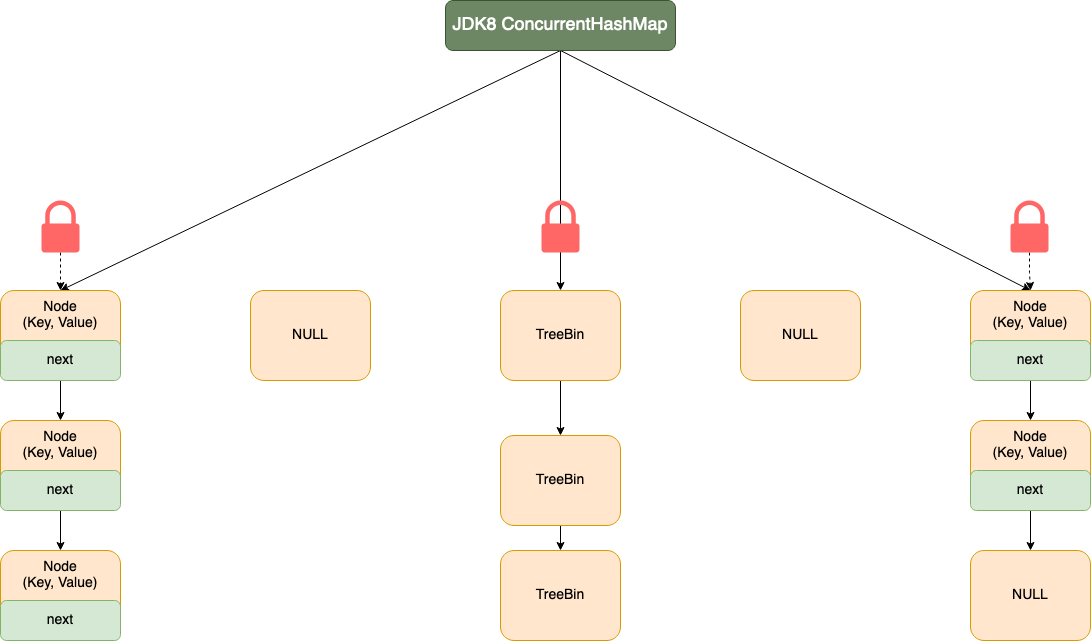
并发度:
- 1.7 维护了一个segment数组,数组默认容量为16.
- 这个容量初始化指定后就不能改变了,并且不是懒惰初始化
- segment数组中每个segment节点都维护了一个哈希表(数组+链表)
- 1.8 因为锁的是哈希桶,所以并发度随着扩容而一起增大
总结:
虽然 HashMap 在多线程环境下操作不安全,但是在 java.util.concurrent 包下,java 为我们提供了 ConcurrentHashMap 类,保证在多线程下 HashMap 操作安全!
在 JDK1.7 中,ConcurrentHashMap 采用了分段锁策略,将一个 HashMap 切割成 Segment 数组,其中 Segment 可以看成一个 HashMap, 不同点是 Segment 继承自 ReentrantLock,在操作的时候给 Segment 赋予了一个对象锁,从而保证多线程环境下并发操作安全。
但是 JDK1.7 中,HashMap 容易因为冲突链表过长,造成查询效率低,所以在 JDK1.8 中,HashMap 引入了红黑树特性,当冲突链表长度大于8时,会将链表转化成红黑二叉树结构。
在 JDK1.8 中,与此对应的 ConcurrentHashMap 也是采用了与 HashMap 类似的存储结构,但是 JDK1.8 中 ConcurrentHashMap 并没有采用分段锁的策略,而是在元素的节点上采用 CAS + synchronized 操作来保证并发的安全性,源码的实现比 JDK1.7 要复杂的多。
3. LinkedBlockingQueue
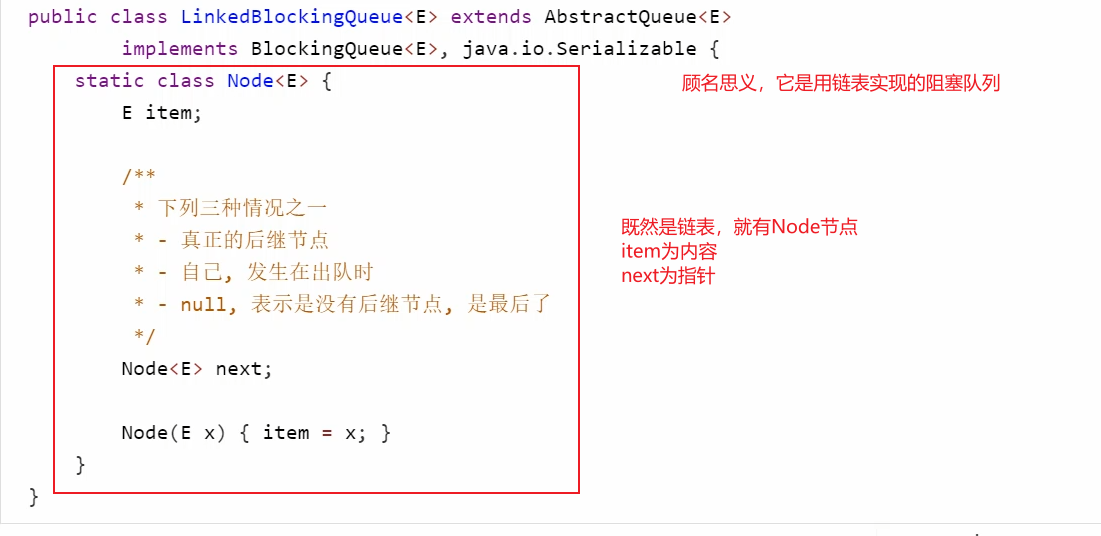
初始化链表的时候:
head last dummy哨兵节点。注意: head last并不是真实存在的节点,而是头结点 和 尾节点的引用
加一个元素:
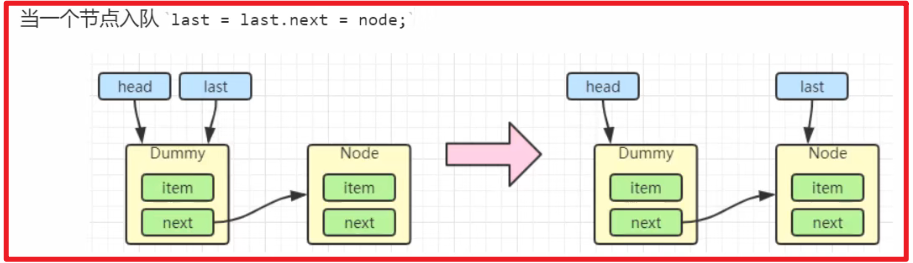
出队的时候,会将自己指向自己,帮助GC安全的来回收
加锁分析:
LinkedBlockingQueue采用了两把锁 和 dummy哨兵节点提高效率

哨兵节点的体现:
- 当不存在哨兵节点的 时候,如果只有一个正常节点,那么两把锁锁的也就是同一个对象
- 如果有哨兵节点+1个正常节点,也就是正常的两把锁锁住的是两个对象

put()分析(生产者)
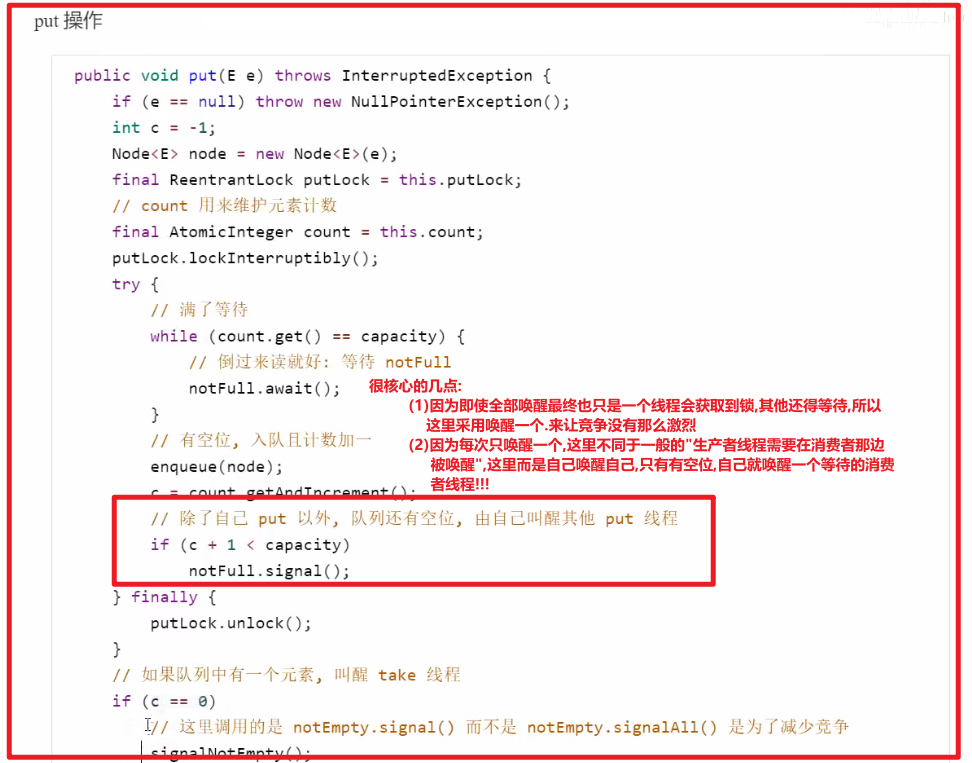
take()类似(消费者)

和ArrayBlockingQueue的比较

因为Array底层是数组,不能像链表一个,单独在头和尾设置两把锁,只能设置一把锁,所以性能上
是地狱Linked的,生产者和消费者不能同时并行执行
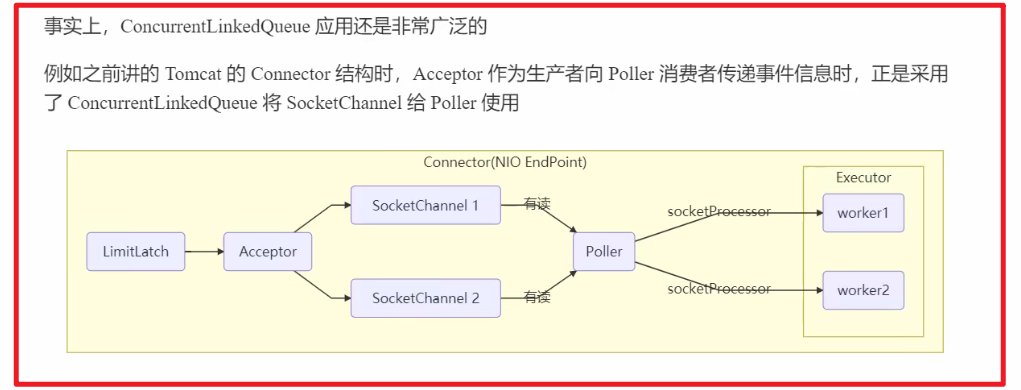
4. ConcurrentLinkedQueue

生产者向队尾添加元素的操作 和 消费者向对头删除元素的操作,都是通过CAS的方式来实现线程安全
5. CopyOnWriteArrayList
特点:
- 读写并发
- 读读并发
- 写写互斥
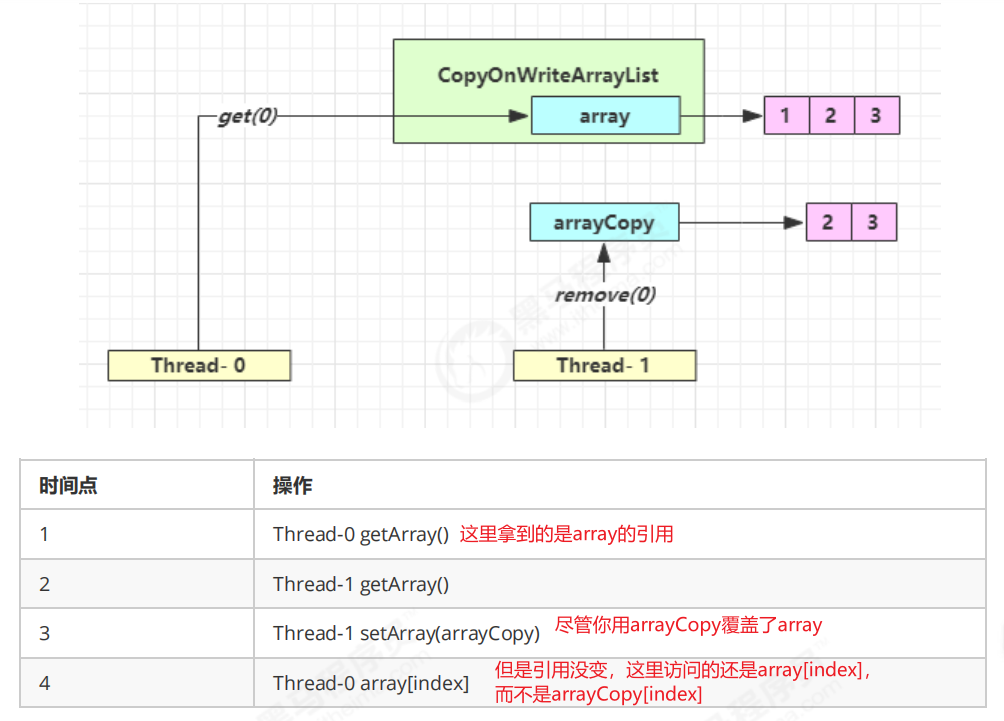
底层实现采用了 写时复制技术(CopyOnWrite) 的思想,增删改会将原先数组进行拷贝,增删改的操作是在新的数组上操作,而读取操作都是在原先数组上,写操作完成后覆盖掉旧数组.所以读写分离,读写并发
add():
会对写的操作使用synchronized进行互斥,但是不阻塞读的操作

所有的读操作,是没有加锁的
适合于: [读多写少]的场景!典型用空间换取的线程安全
问题:
1. get弱一致性问题.(带Concurrent开头的都存在该问题)
2. 迭代器弱一致性问题
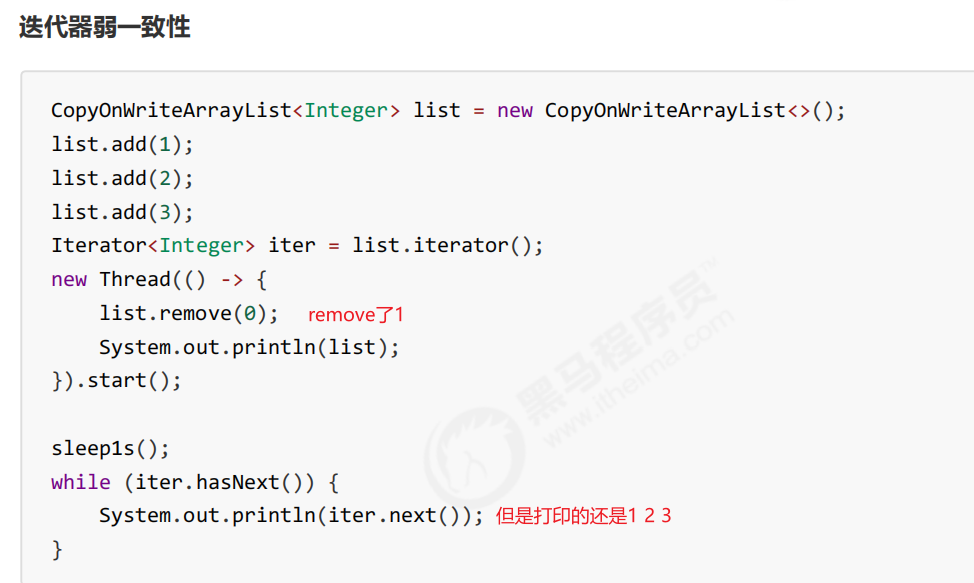
不要觉得弱一致性就不好,其实很好,它不仅做到了读读的并发,还做到了读写的并发,MVCC也是弱一致性的表现。并发高 和 一致性是矛盾的,需要权衡
后续内容:disrupt、guava、异步编程、非共享模型、并行编程