UniScene 统一驾驶场景 | 生成语义占据 | 生成多视角视频 | 生成激光点云 CVPR2025
UniScene 是一个面向自动驾驶场景的统一生成框架,来自CVPR2025。
可同时生成语义占据、多视角视频、LiDAR 点云三种核心数据,打破了现有方法 “单一数据形式生成” 的局限。
通过 “以占据为中心的分层生成 + 跨域转换创新策略”,为自动驾驶提供了高质量、多模态、可控的合成数据生成范式。
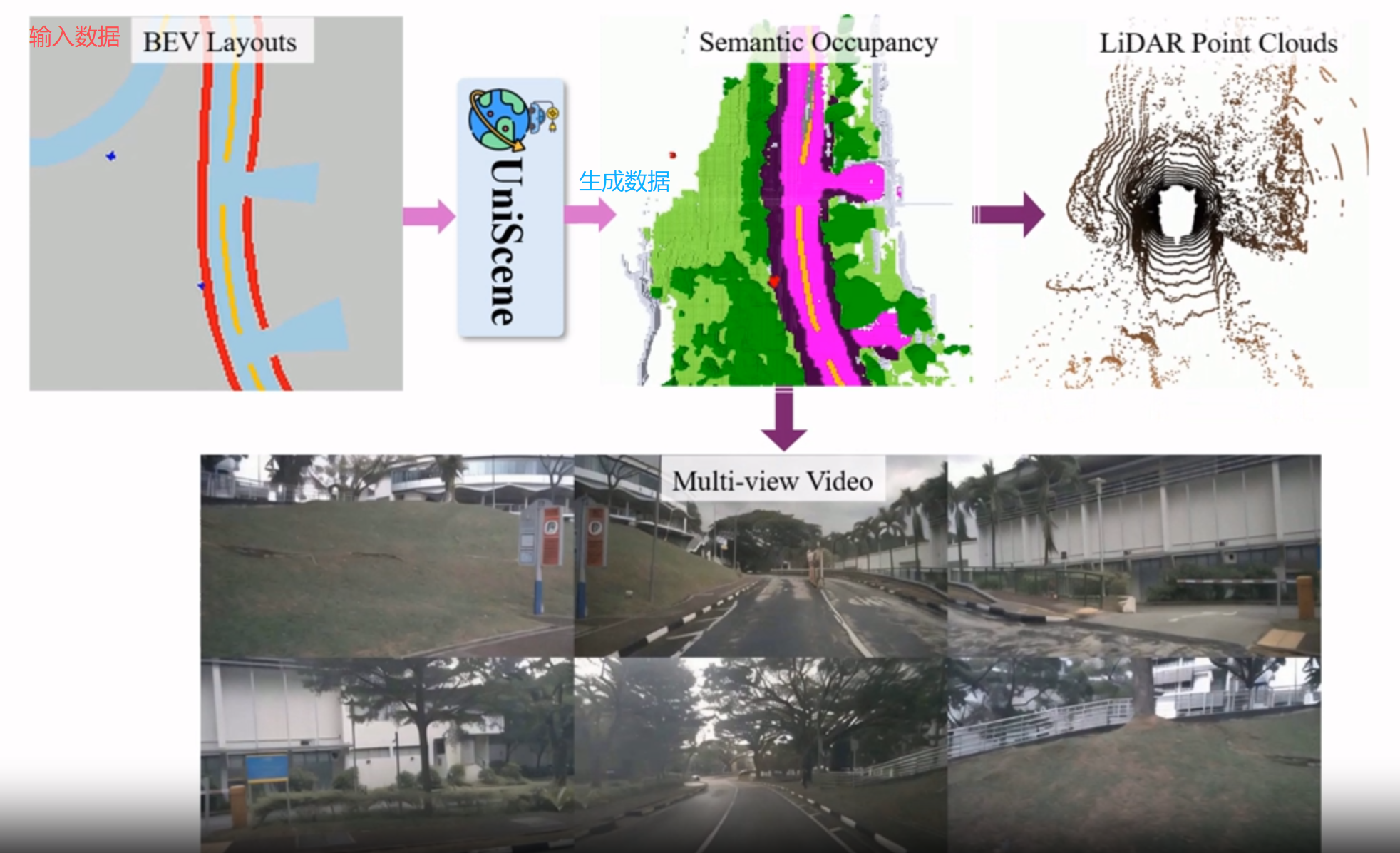
论文地址:UniScene: Unified Occupancy-centric Driving Scene Generation
代码地址:https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation
项目地址:https://arlo0o.github.io/uniscene/
一、模型框架
UniScene的模型框架如下图所示,“BEV→语义占据→视频 / LiDAR” 的分层流程。
核心是 “首先生成语义占据(中间表示),再基于占据生成 视频 与 LiDAR点云”
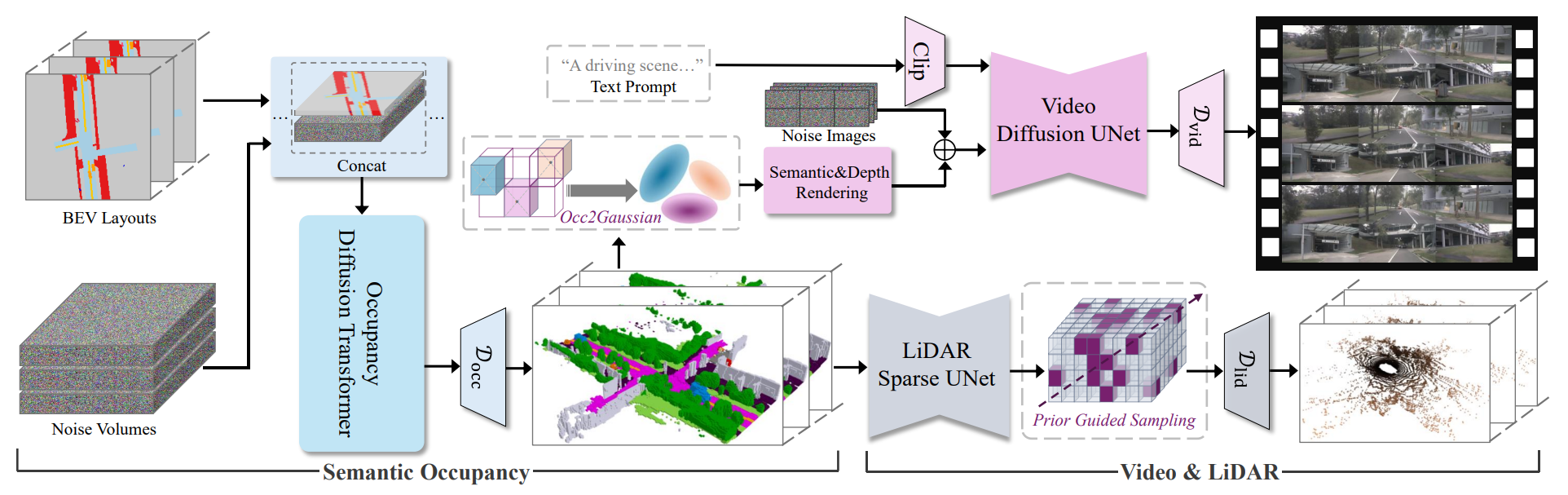
整体分为 “语义占据生成”和“多模态数据(视频、LiDAR)生成”两大阶段,各模块逻辑与数据流转如下:
1.1、第一阶段:语义占据生成(左半部分)
目标是从 可控输入(BEV 布局)、随机性(噪声体)中,生成富含语义与几何信息的 3D 语义占据。
- 输入:
BEV Layouts:BEV 视角的场景布局(如车辆、道路的 2D 轮廓),是 “可控生成” 的核心条件(用户可编辑布局来定制场景);Noise Volumes:噪声体(采样自正态分布),为生成引入随机性,保证结果多样性。
- 核心模块:
Occupancy Diffusion Transformer(占据扩散 Transformer)- 作用:以 “BEV 布局 + 噪声体” 为输入,通过扩散模型的去噪过程,生成时空一致、语义精准的 3D 语义占据(每个体素标注 “是否占据” 及 “语义类别”,如 “车”“路”);
- 辅助:
D_occ(占据生成的判别 / 处理模块),确保生成的占据质量(如精度、一致性)。
2.2、第二阶段:多模态数据生成(右半部分)
以 “语义占据” 为中间表示,分别生成多视角视频和LiDAR 点云,利用占据的 “语义 + 几何” 信息约束跨模态生成的一致性。
(1)视频生成支路(上半部分)
目标:生成与语义占据 “几何匹配、语义一致” 的多视角视频。
- 核心步骤:
Occ2Gaussian(占据转高斯):将 3D 语义占据转换为3D 高斯基元(每个高斯基元编码 “位置、语义、透明度、形状(协方差)” 等信息);Semantic&Depth Rendering(语义 + 深度渲染):从相机视角,将 3D 高斯基元 “投影” 为 2D 的语义图(每个像素的语义类别)和深度图(每个像素到相机的距离),为视频生成提供 “几何透视 + 语义标签” 的细粒度引导;Text Prompt + Clip:文本提示(如 “A driving scene...”)通过 Clip 模型转换为 “高层语义特征”(注入场景属性,如 “雨天”“夜晚”);Noise Images:扩散模型的初始噪声输入;Video Diffusion UNet:融合 “语义 / 深度引导、文本特征、噪声”,通过扩散去噪过程生成多视角连贯视频;D_vid:视频生成的判别 / 处理模块,保证视频真实感(如帧间一致性、纹理细节)。
(2)LiDAR 生成支路(下半部分)
目标:生成与语义占据 “物理匹配、稀疏性一致” 的 LiDAR 点云。
- 核心步骤:
LiDAR Sparse UNet:处理 3D 语义占据,仅关注 “被占据的体素”(跳过空体素,大幅节省计算量),提取稀疏体素特征;Prior Guided Sampling(先验引导采样):模拟真实 LiDAR 的 “射线发射 - 反射” 物理过程 —— 沿 LiDAR 射线均匀采样,结合语义占据的 “占据先验”(仅在有物体的体素区域保留采样点),生成符合真实 LiDAR“稀疏性、遮挡特性” 的点云;D_lid:LiDAR 生成的判别 / 处理模块,保证点云真实感(如反射强度、噪声分布)。
二、技术核心点:可控语义占据生成
生成 时空一致、语义精准且可通过 BEV 布局 “定制”的 3D 语义占据(semantic occupancy)
作为后续视频、LiDAR 生成的 “中间载体”,既承载场景的语义与几何信息,又支持用户通过编辑 BEV 布局来控制生成结果。
通过 “Occupancy VAE(高效表示)+ Occupancy DiT(可控生成)”实现的,最终生成语义占据。
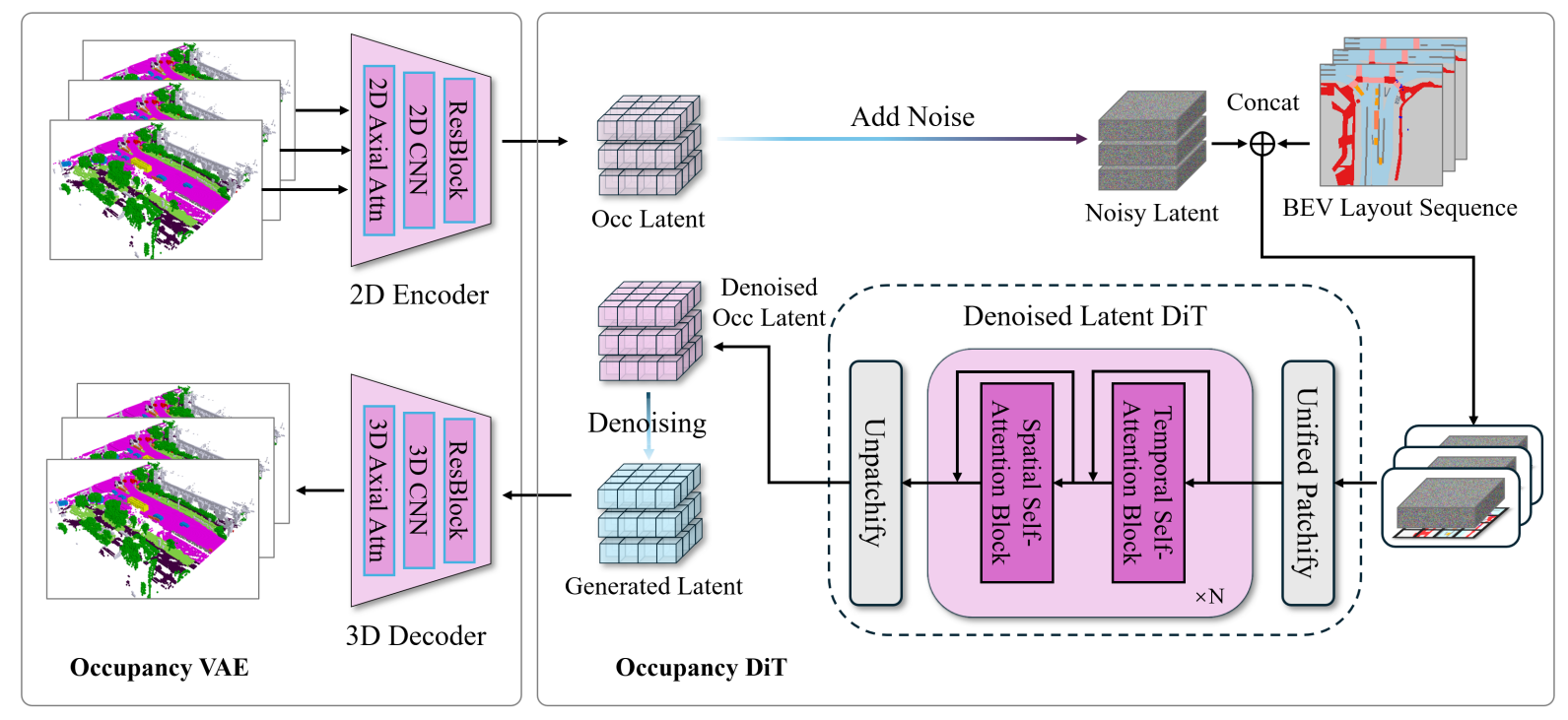
关键模块1:Occupancy VAE(变分自编码器)
语义占据是高维 3D 体素数据,直接处理成本高。Occupancy VAE 的作用是将 3D 语义占据压缩为低维连续潜在表示(latent),同时保证重建细节。
-
创新点:连续潜在空间(对比传统 VQVAE),传统方法(如 OccLLama、OccWorld)用VQVAE(矢量量化 VAE),将潜在空间拆分为 “离散 token”(类似拼图块),高压缩比下易丢失细节(如车辆边缘模糊)。
-
UniScene 采用连续潜在空间(无离散拼接缝隙),即使压缩比达 512 倍,重建语义占据的mIoU(平均交并比)仍达 72.9%,远超 VQVAE 方法(如 OccSora 仅 27.4%)。
-
流程:Encoder 压缩 → Decoder 重建
- Encoder(编码器):输入:单帧 3D 语义占据步骤:
- 语义嵌入:为每个语义类别(如 “车”“路”)分配可学习的类别嵌入向量(如 8 维向量),将 3D 占据转换为 BEV 视角表示。
- 特征提取:通过 * 2D 卷积层 + 2D 轴向注意力(Axial Attention)* 提取特征 ——2D 卷积缩小尺寸(节省算力),轴向注意力仅在 “高度、宽度” 维度计算关联(如道路的横向连续性),最终得到下采样后的连续潜在特征。
- Decoder(解码器):输入:多帧潜在特征序列。步骤:
- 维度恢复:通过3D 卷积层 + 3D 轴向注意力恢复 3D 维度 ——3D 卷积将 2D 特征升为 3D,3D 轴向注意力同时捕捉 “高度、宽度、时间” 维度的关联(如车辆在连续帧中的运动轨迹)。
- 语义重建:将恢复的 BEV 表示转换为 “每个体素的语义概率分布”,取概率最大的类别作为最终重建的语义占据序列。
- Encoder(编码器):输入:单帧 3D 语义占据步骤:
关键模块 2:Occupancy DiT(扩散 Transformer)
Occupancy VAE 负责 “压缩重建”,而 Occupancy DiT 的作用是基于 BEV 布局,生成 “可控、时空一致” 的语义占据潜在特征
类似 “根据 BEV 蓝图,用扩散过程画出生动的 3D 占据”。
-
核心逻辑:BEV 布局作为 “控制信号”输入:
- BEV 布局特征;
- 带噪声的潜在特征(初始为纯噪声,模拟扩散的 “起始状态”)。操作:
- BEV 布局下采样:将 BEV 布局下采样到与潜在特征相同的尺寸。
- 特征拼接:将 “带噪声的潜在特征” 与 “下采样后的 BEV 布局” 拼接,通过 统一分块转换为 Transformer 可处理的 token 序列。
- 时空注意力建模:堆叠空间自注意力块 + 时间自注意力块:
- 空间自注意力:捕捉单帧内的空间关联(如 BEV 中 “车” 的位置对应 3D 占据中 “车” 的体素位置);
- 时间自注意力:捕捉多帧间的时序关联(如车辆在第 1 帧在左侧,第 2 帧向右侧移动的连贯性)。
三、技术核心点:视频生成
使用语义占据(3D 体素级的语义 + 几何表示)作为 “底层约束”,生成与 3D 场景语义 / 几何一致、时序连贯且属性可控的多视角视频。
下图展示了核心流程,通过 “语义占据引导 + 文本可控 + 扩散去噪” 的协同:
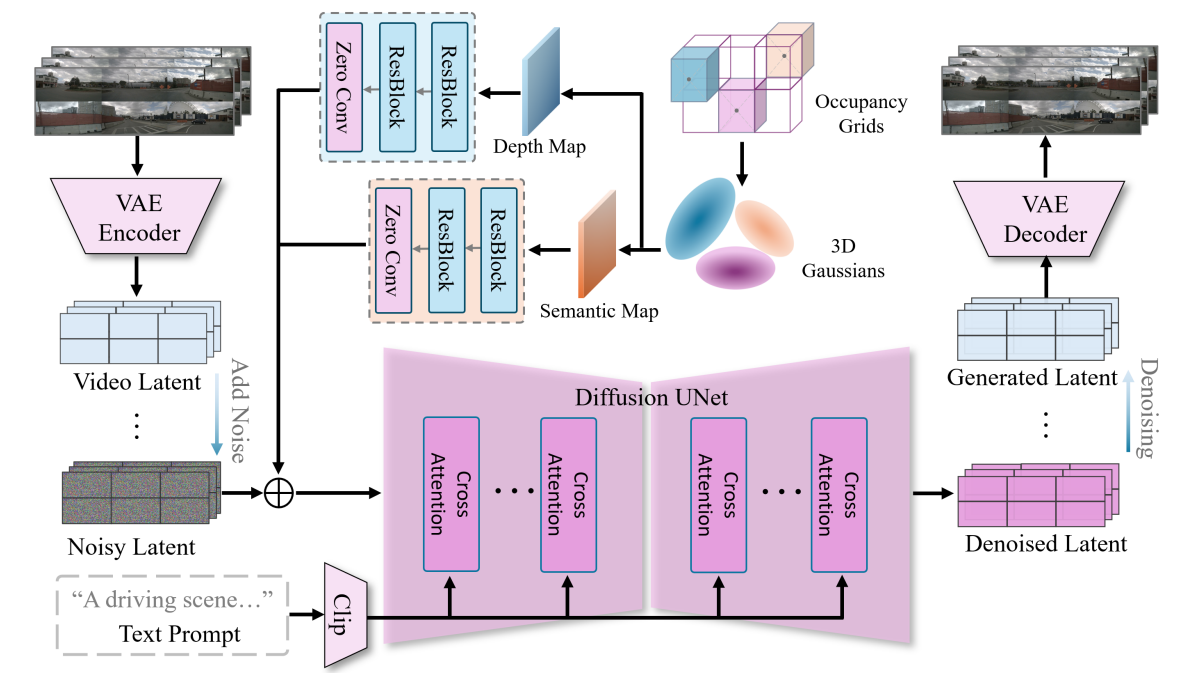
核心思路:用 3D 语义占据生成 “精准的 2D语义 / 深度图”,再结合文本提示,通过扩散模型 “从噪声画到真实视频”,同时保证帧间连贯。
A. 3D占据 → 2D引导图:高斯联合渲染
语义占据是3D 离散体素数据(每个体素标注 “是否占据” 及 “语义类别”,如 “车”\“路”),而视频是2D 连续图像。
为了让 “3D 结构” 指导 “2D 生成”,需要将 3D占据转换为2D 语义图(Semantic Map)和深度图(Depth Map),作为视频生成的 “描边 + 透视指南”。
-
Occ2Gaussian:3D 占据转高斯基元将 3D 语义占据中 “被占据的体素” 转换为3D 高斯基元
-
3D Gaussians)—— 每个高斯基元编码:
- 位置 (体素中心坐标);
- 语义标签 (如 “车” 的 one-hot 编码);
- 透明度(体素可见性,模拟遮挡);
- 形状协方差(体素的 “胖瘦”,模拟物体形态)。
这样,离散的 3D体素被转化为连续、带语义 + 几何信息的高斯表示,为后续渲染提供基础。
B. 语义渲染、深度渲染
-
从高斯到 2D图从相机视角出发,将 3D 高斯基元 “投影” 到 2D 平面,计算每个像素的语义与深度:
深度图D:(从近到远遍历高斯基元,每个高斯的深度 d_i乘以 “自身透明度 a_i' 和 “前面未遮挡的概率 ,最终累加得到像素深度。
近物贡献大,远物被遮挡则贡献小。
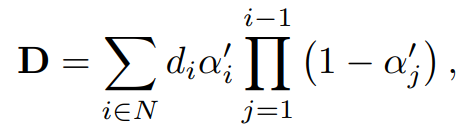
语义图 S:类似深度图,累加各高斯的语义编码,取总贡献最大的语义作为像素类别。
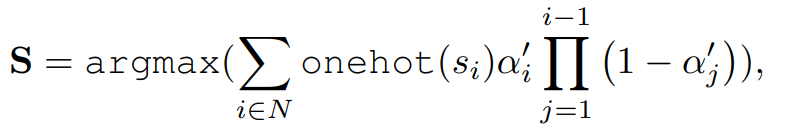
C. 文本属性可控:Clip 模型注入高层语义
除了 3D结构约束,还可通过文本提示(Text Prompt,如 “A rainy driving scene”)控制视频属性(如天气、时间)。
利用Clip 模型,将自然语言转换为语义特征向量,使生成的视频同时满足 “3D 结构” 和 “文本描述的属性”(如雨天的路面反光、灯光效果)。
D. 视频扩散生成:Video Diffusion UNet + 多条件融合
视频生成基于扩散模型(Diffusion Model),核心模块是Video Diffusion UNet,通过 “从噪声逐步去噪” 生成真实视频。输入与融合逻辑:
- 带噪声的视频潜在表示(Noisy Latent):扩散模型的 “起始状态”(纯噪声,后续逐步去噪)。
- Clip 文本特征:提供 “高层语义属性” 指导(如 “雨天”)。
- 语义 / 深度图:提供 “底层几何 + 语义” 约束(如 “车的位置 / 形状”)。
- 交叉注意力(Cross Attention):UNet 内部通过交叉注意力,让 “视频潜在特征” 与 “文本特征”“语义 / 深度图特征” 双向交互,确保生成内容同时满足多源约束。
生成的示例效果:

四、技术核心点:激光点云
激光点云的核心特点是 稀疏性(仅在激光射线碰到物体时产生点)与 物理真实性(深度、反射强度、遮挡丢弃等需符合真实传感器规律)。
UniScene 通过 “稀疏特征提取→先验引导采样→物理特性模拟” 三步,让生成的 LiDAR 点云既匹配语义占据的 3D 场景,又贴近真实 LiDAR 的采集结果。
- 核心逻辑是:先语义占据筛选,通过稀疏特征提取 “有物体的区域”,
- 再模拟 LiDAR“发射射线→碰物体→返回点” 的物理过程,
- 最后给点云添加 “深度、反射强度、射线丢弃” 等真实传感器特性。
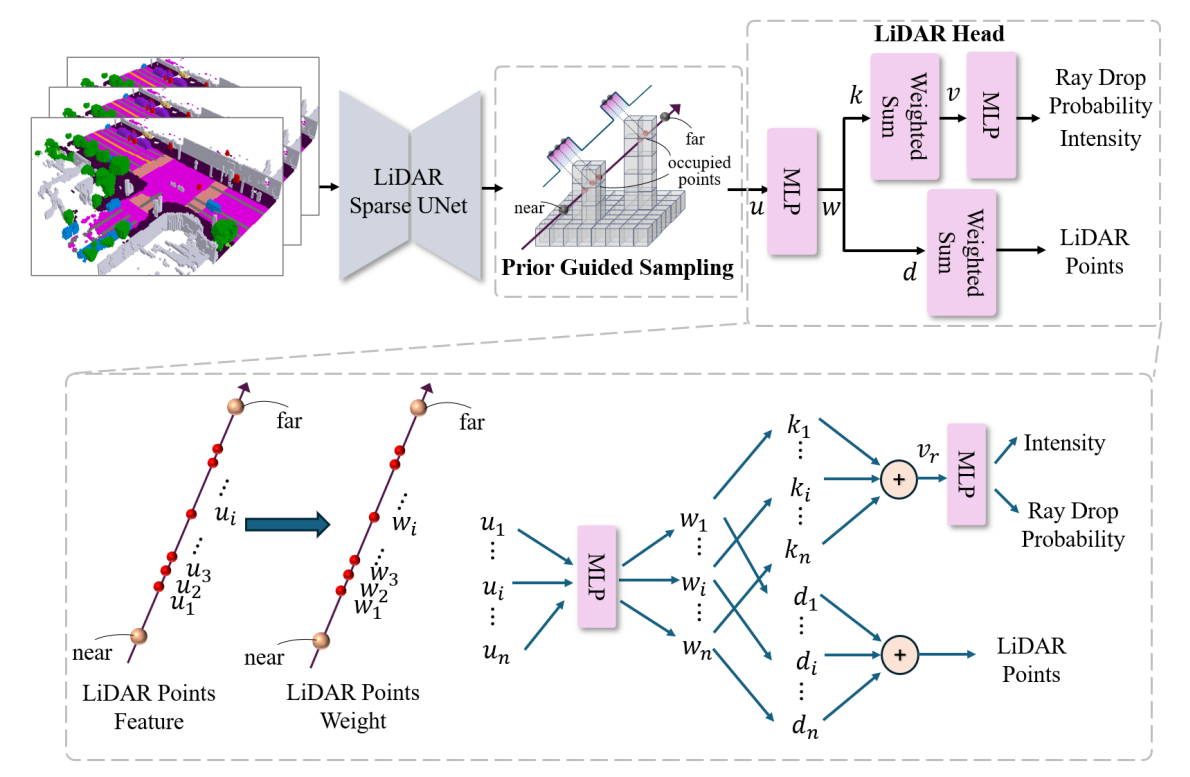
1. 稀疏特征提取:LiDAR Sparse UNet
语义占据是 “体素化” 的 3D 场景(每个小立方体标记 “是否有物体” 及 “物体语义”),但大量体素为 “空”(无物体)。
LiDAR Sparse UNet 采用稀疏卷积技术,仅对 “被占据的体素”(有物体的部分)进行特征提取,跳过空体素:
- 优势:既节省计算资源(避免对空区域的无效运算),又能精准捕获物体的 3D 几何与语义特征(如车辆轮廓、道路边界)。
2. 先验引导采样:模拟 LiDAR 射线的物理发射
真实 LiDAR 的工作逻辑是 “发射激光射线→射线碰到物体→返回点云”。
UniScene 以语义占据为 “先验知识”,模拟这一过程:
- 采样方式:沿 LiDAR 射线方向(从传感器出发的直线)均匀采样初始点,但仅在 “被占据的体素区域” 保留采样点(空体素区域的采样点会被过滤);
- 效果:生成的初始点云天生具备 “稀疏性”(仅物体区域有点),且与 3D 场景的几何结构严格匹配(有物体的地方才有点)。
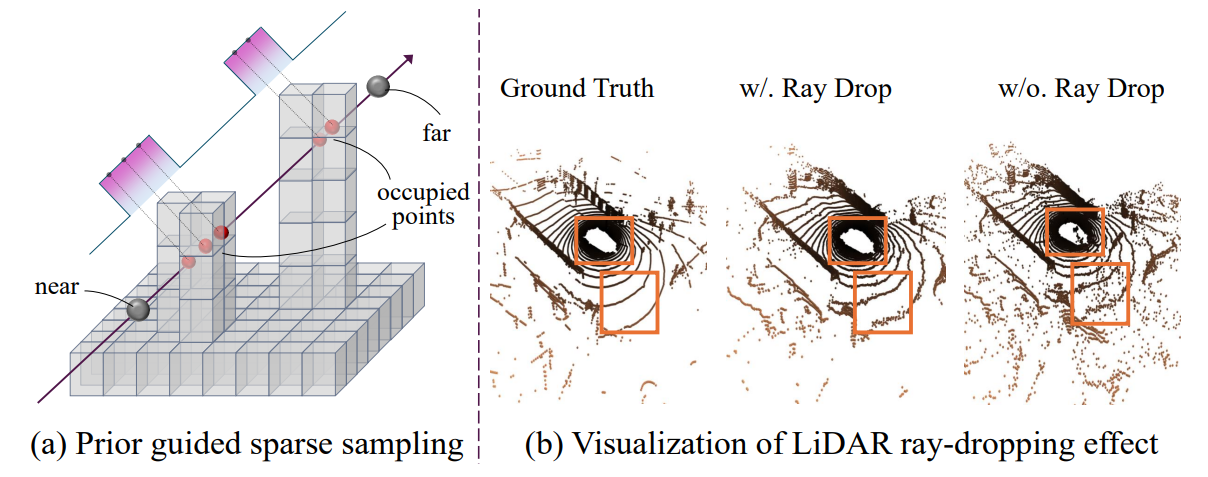
- a部分,“先验引导稀疏采样” 确保点云与场景语义 / 几何一致(点只在有物体的地方生成);
- b部分,“射线丢弃” 确保点云贴近真实传感器特性(模拟稀疏性与物理限制)。
3. LiDAR 头:还原真实传感器的物理特性
LiDAR Head 负责对采样点进行 “精细化加工”,模拟真实 LiDAR 的三大核心物理特性:
- 深度计算:激光射线可能穿透多个物体,需确定 “射线最先碰到的物体的深度”。
- 通过预测符号距离函数(SDF)(表示点到物体表面的距离,“正” 为体外、“负” 为体内),再加权计算射线深度(权重体现 “该点是射线第一个碰到物体” 的概率)。
- 反射强度预测:不同材质(如金属车辆、沥青路面)对激光的反射强度不同。
- LiDAR Head 通过多层感知机(MLP),根据采样点特征预测反射强度,使金属物体的点反射更强、路面点反射更弱,贴近真实物理规律。
- 射线丢弃(Ray Drop):真实 LiDAR 存在 “射线因距离过远 / 遮挡而无返回点” 的情况。
- LiDAR Head 预测每条射线的 “丢弃概率”,将概率高的射线对应的点过滤,保证点云稀疏性与真实感(避免生成 “过度密集的假点”)。
五、模型效果
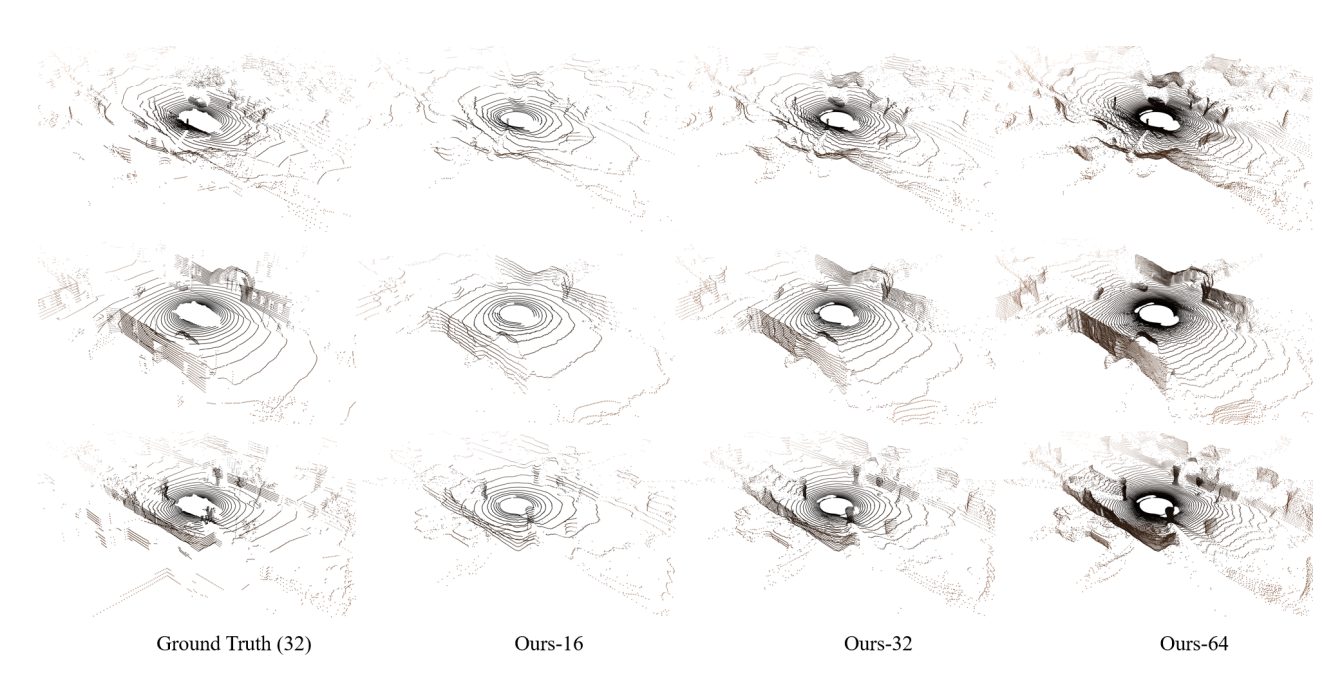
不同配置下 LiDAR 光束扫描模式的可视化。
- 真实数据采用 32 光束 LiDAR 设置,而所提出的方法(“Ours-16”、“Ours-32”和“Ours-64”)则展示了不同的光束密度。
- 对比结果凸显了该模型模拟真实 LiDAR 模式并在不同光束分辨率下保留场景几何形状的能力。
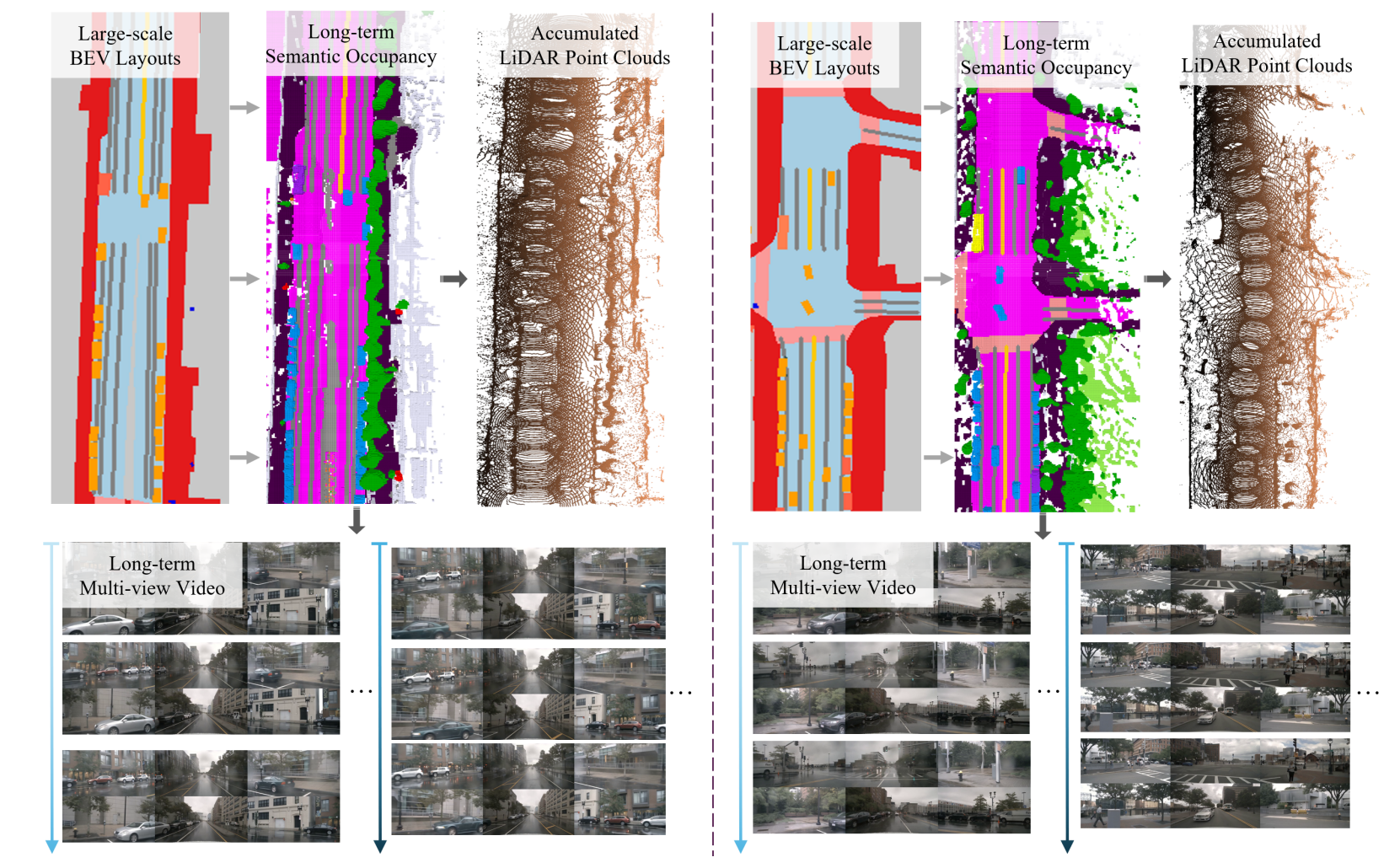
大规模驾驶场景数据生成的可视化,其中大规模 BEV 布局作为输入
- 给定的BEV布局,生成长期语义占用,然后指导 LiDAR 点云和多视角视频的生成。
- 结果证明了该模型在大规模环境中生成时间和空间一致的输出的能力。
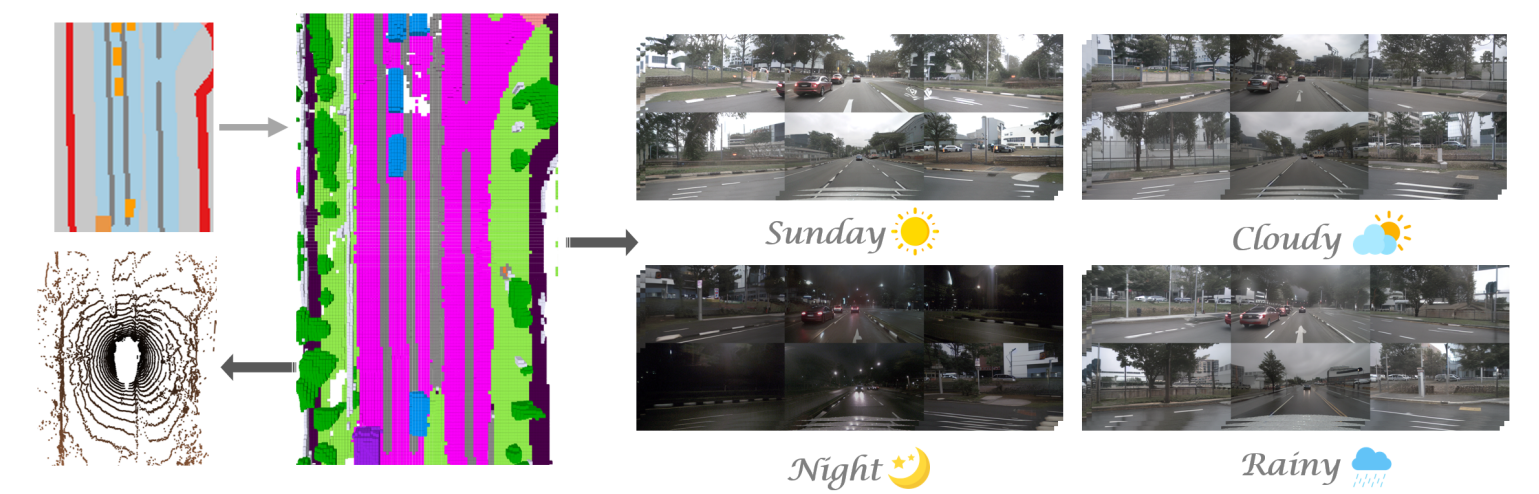
可视化可控视频生成,包含多种属性。
- 展示了生成基于 BEV 布局的视频的能力,并可控制各种属性,例如天气(晴天、多云、下雨)和时间(白天、夜晚)。
- 上下两行展示了不同的输入配置,从而生成具有所需属性变化的逼真视频输出。
分享完成~