【AI智能体】Dify 搭建数据分析应用实战操作详解
目录
一、前言
二、Dify 介绍
2.1 Dify是什么
2.2 Dify 核心特性
2.2.1 Dify 特点
2.2.2 多模型支持
2.2.3 Dify 适应场景
2.3 Dify 在数据分析应用场景中介绍
2.3.1 Dify 数据分析应用的核心能力
2.3.2 基于Dify 搭建数据分析应用一般流程
2.3.3 基于Dify搭建数据分析应用场景
三、基于Dify 搭建一个数据分析应用完整操作过程
3.1 前置准备
3.1.1 配置大模型
3.1.2 安装工具和插件
3.1.3 提前准备2张数据表
3.2 完整操作与配置过程
3.2.1 创建空白应用
3.2.2 增加一个大模型节点
3.2.3 增加数据库执行的第一个插件节点
3.2.4 增加一个模板转换节点
3.2.5 增加提取参数中的SQL大模型节点
3.2.6 增加第二个插件节点
3.2.7 增加条件分支节点
3.2.7.1 第一个条件分支增加大模型节点
3.2.7.2 增加大模型节点
3.2.7.3 增加数据转图表的插件节点
3.2.7.4 增加回复节点
3.2.8 第二个分支节点增加一个大模型节点
3.2.8.1 增加Markdown转换节点
3.2.8.2 增加回复节点
3.2.9 第三个分支增加一个大模型节点
3.2.9.1 增加回复节点
3.2.10 效果测试
四、写在文末
一、前言
在数字化浪潮席卷全球今天,数据已成为企业决策的核心驱动力。可以说,身处当下的时代,不管是否IT企业,都有自身沉淀下来的与企业经营相关的各种数据,比如销售数据,订单数据,各类报表,知识库文档等等,这些数据的存在,成为企业经营过程中必不可少的依赖和宝贵资产。
很多企业意识到数据资产对于企业经营发展的重要性之后,也逐步开始借助各类软件对数据进行开发,应用和消费,比如数据大屏就是很多公司使用的比较高频的形式。
然而,对于这种企业数据的消费模式,是严重依赖背后的技术开发团队的人力投入的。从提需求,到开发,再到最终的交付使用,这一系列的漫长过程会严重拖慢整个经营决策的过程。说到底,还是因为大多数使用数据的人员,对底层数据的使用上面存在较大的障碍。
以mysql为例来说,传统数据查询方式往往依赖于复杂的SQL语句,这对于缺乏编程背景的业务人员而言,无疑是一道难以逾越的鸿沟。正是在这样的背景下,自然语言处理(NLP)与数据库技术的融合,催生了"自然语言转SQL"(Natural Language to SQL,简称NL2SQL)这一创新技术,旨在打破数据查询的壁垒,让数据真正为每个人所用。
在这样的大背景下,随着各类AI智能体平台的诞生和普及,基于AI智能体平台快速搭建特定场景下的应用能力,已经展现出很大的市场潜力,传统的动则几个月甚至更久的软件交付的应用开发过程,在AI智能体平台上或许只需要几个小时,甚至几分钟就可以快速的搭建出来。这样便可以极大提升业务价值的验证周期,从而更快得到业务的反馈,提升业务协作效率。
本篇将基于Dify 智能体平台,以一个实际案例演示下如何快速搭建一个数据分析应用的智能体。
二、Dify 介绍
2.1 Dify是什么
Dify 是一个开源大模型应用开发平台,旨在帮助开发者(智能体应用爱好者)快速构建、部署和管理基于大型语言模型(LLM)的 AI 应用。它提供了一套完整的工具链,支持从提示词工程(Prompt Engineering)到应用发布的全流程,适用于企业级 AI 解决方案和个人开发者项目。
官网入口:https://cloud.dify.ai/apps
中文网入口:https://dify.ai/zh
2.2 Dify 核心特性
2.2.1 Dify 特点
Dify 具备如下核心特点:
-
可视化编排工作流
-
通过低代码界面设计 AI 应用流程,无需深入编程即可构建复杂的 LLM 应用。
-
支持 对话型(Chat App) 和 文本生成型(Completion App) 应用。
-
-
多模型支持
-
兼容主流大模型 API,如 OpenAI GPT、Anthropic Claude、Cohere、Hugging Face 等。
-
支持私有化部署的 Llama 2、ChatGLM、通义千问 等开源模型。
-
-
灵活的提示词工程
-
提供 Prompt 模板、变量插值、上下文管理等功能,优化 AI 输出效果。
-
支持 RAG(检索增强生成),可结合外部知识库提升回答准确性。
-
-
数据管理与持续优化
-
记录用户与 AI 的交互日志,用于分析和迭代改进模型效果。
-
支持 A/B 测试,对比不同提示词或模型版本的表现。
-
-
企业级功能
-
支持 多租户、权限管理,适合团队协作开发。
-
可私有化部署,保障数据安全。
-
2.2.2 多模型支持
在Dify控制台上,内置非常多的大模型可供用户选择,比如GPT系列,DeepSeek、千问系列模型等,基于这些模型,应用开发者可以自由灵活的选择并使用。
2.2.3 Dify 适应场景
Dify 适用于多种生成式 AI 应用开发场景:
-
内容创作与生成
-
自动化生成文章、报告、营销文案等
-
结合知识库实现专业领域内容生成(如法律、医疗文档)
-
-
智能对话系统
-
构建多轮对话客服机器人、虚拟助手
-
通过 Agent 框架实现任务分解与工具调用(如搜索、图像生成)
-
-
数据分析与自动化
-
解读复杂数据并生成可视化报告
-
自动化业务流程(如工单处理、邮件回复)
-
-
个性化推荐与营销
-
基于用户画像生成个性化推荐内容。
-
结合RAG实现精准信息检索与推送。
-
2.3 Dify 在数据分析应用场景中介绍
2.3.1 Dify 数据分析应用的核心能力
利用 Dify 搭建数据分析应用,你会发现它具备如下吸引人的能力:
-
自然语言查询 (Text2SQL/NL2SQL):
-
用户只需用日常语言提问(例如“展示本月各部门的销售额占比”),Dify 应用便能借助大模型自动生成相应的 SQL 查询语句。
-
-
自动化 SQL 执行与结果获取:
-
生成的 SQL 语句会被自动发送至目标数据库执行,并获取结果数据。
-
-
多样化的可视化展示:
-
执行结果数据可以进一步生成直观的图表,如饼图、柱状图、折线图等,也支持以表格形式展示6。
-
-
多数据源支持:
-
Dify 支持连接多种类型的数据库,常见的有 MySQL、PostgreSQL、SQL Server 等26。
-
-
低代码开发:
-
通过可视化的工作流 (Workflow) 编排方式连接各个环节5,大幅降低了开发门槛。
-
2.3.2 基于Dify 搭建数据分析应用一般流程
-
搭建一个智能数据分析应用,通常包含以下核心环节,你可以通过 Dify 的工作流来编排和实现这个过程:
-
用户输入自然语言:
-
用户在前端界面提出分析需求。一般是一段自然语言描述,不需要很专业的术语即可。
-
-
-
LLM 解析并生成 SQL:
-
大模型根据用户需求、预设的 Prompt 指令以及数据库结构信息,生成合规且高效的 SQL 查询语句。
-
此环节的 Prompt 设计非常重要,需要明确规则,例如指定输出仅包含 SQL 语句、确保语法兼容特定数据库、限制结果集数量等。
-
-
-
执行 SQL 查询:
-
Dify 调用数据库连接组件,安全地执行生成的 SQL 语句,并获取返回的数据集。
-
-
结果分析与格式化:
-
LLM 可能会对 SQL 查询结果进行进一步的分析、总结或解释。有时也需要将数据转换为特定格式以适应可视化组件,例如将 JSON 数据中的键和值拼接成字符串。
-
-
可视化展示:
-
将处理好的数据传递给可视化组件(如 ECharts),生成图表,并最终将分析报告(文本 + 图表)呈现给用户。
-
2.3.3 基于Dify搭建数据分析应用场景
Dify 数据分析应用可以广泛应用于各种业务场景:
-
销售与市场分析:快速生成销售报表、分析渠道效果、监控关键指标(KPI)。
-
人力资源管理:分析员工 demographics、薪酬分布、离职率等(基于经典的 employees 数据集)。
-
客户分析:分析客户行为、细分客户群体、计算客户生命周期价值(CLV)等。
-
财务与合规审计:跟踪费用支出、检测异常交易、辅助审计流程。
-
运营监控:可视化业务运营状态,快速定位问题。
三、基于Dify 搭建一个数据分析应用完整操作过程
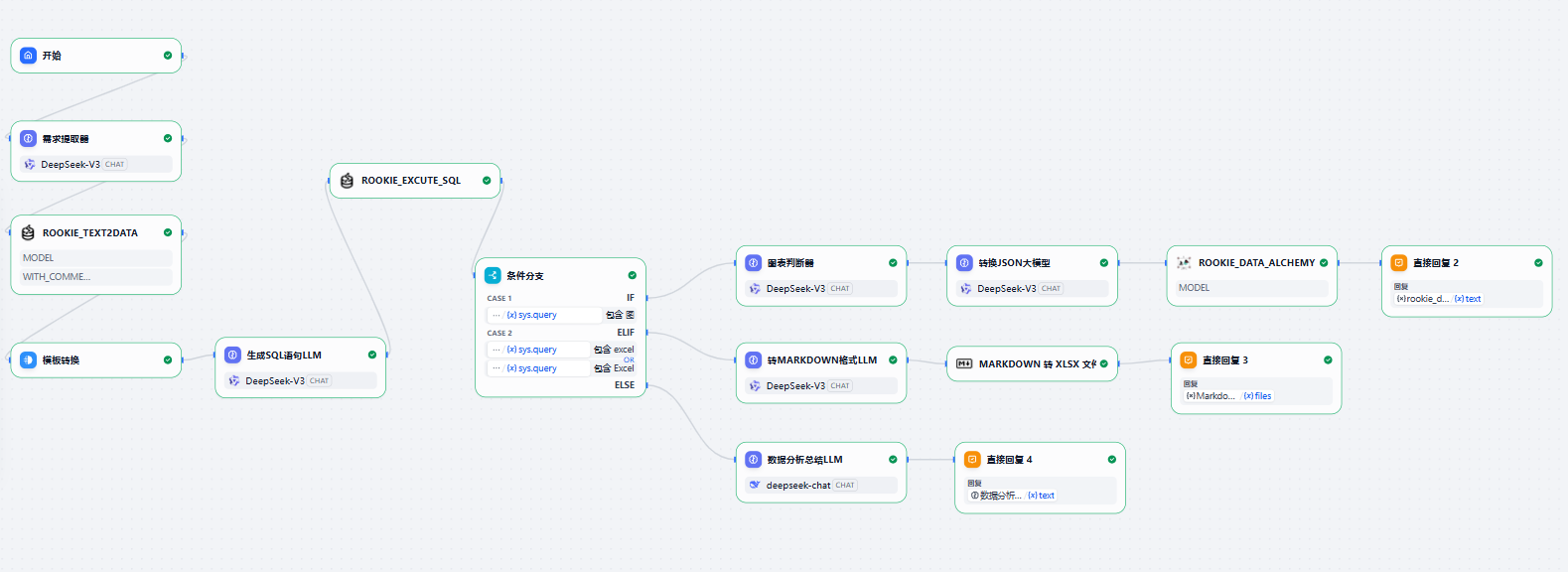
最终流程配置效果展示如下图
3.1 前置准备
3.1.1 配置大模型
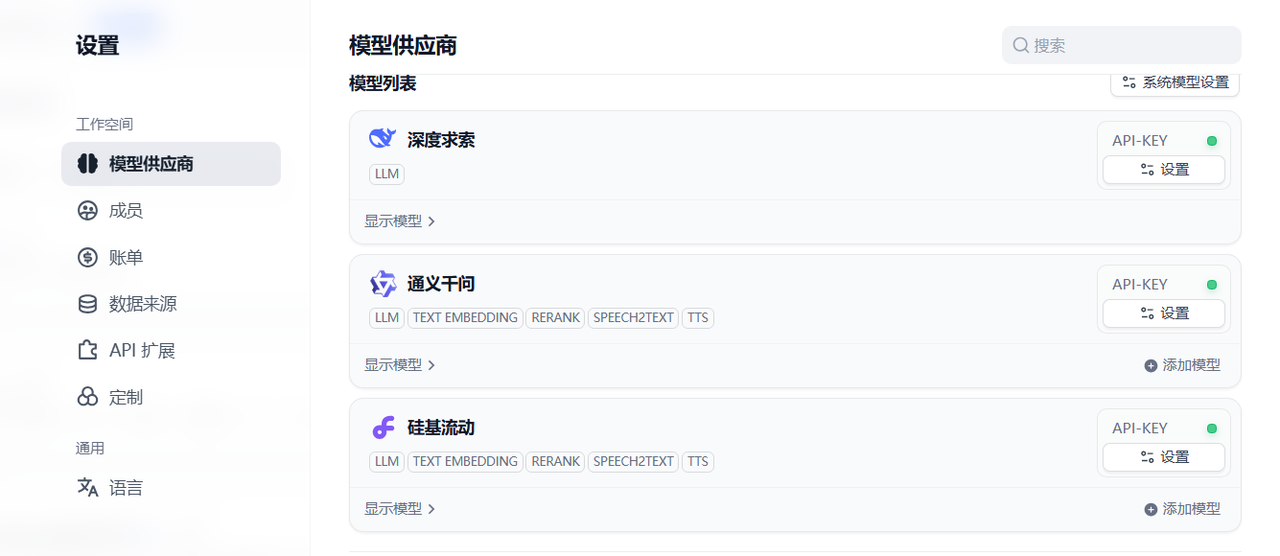
Dify提为应用开发者提供了众多大模型可供集成使用,但需要使用者以插件方式安装并集成进去。在账户那里右键设置,进入模型供应商设置那里,可以看到有很多大模型可供集成,入口:https://cloud.dify.ai/signin

你可以选择合适的模型供应商进行安装,比如我这里选择了DeepSeek ,通义千问大模型,以及国内的硅基流动大模型集成平台,主要是把对应的模型供应商的apikey配置进去即可。
3.1.2 安装工具和插件
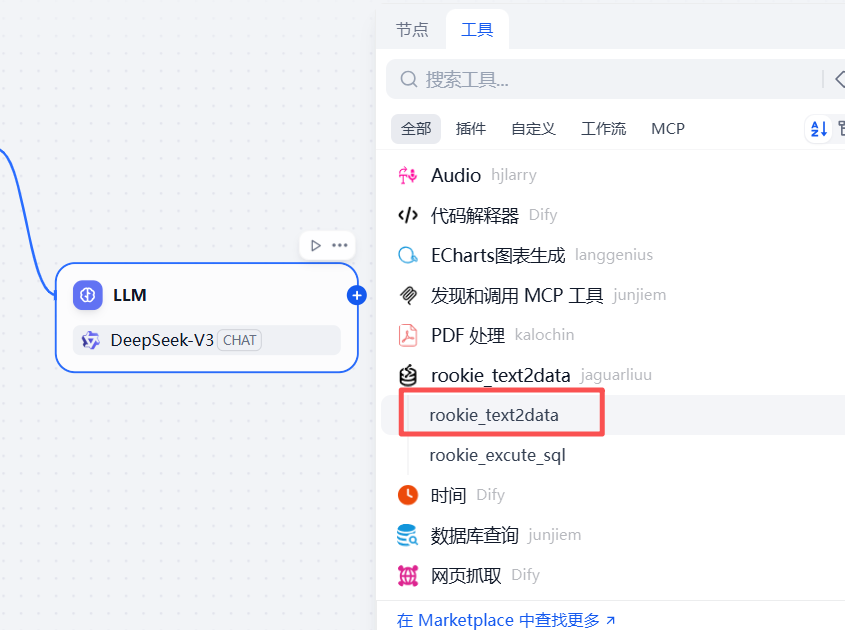
如下,安装这个rookie_text2data的工具,基于该插件,可以将自然语言转sql
再安装一个数据转图表的工具插件
安装Markdown转换器插件
3.1.3 提前准备2张数据表
后续会模拟从数据库查询数据,因此需要提前准备2张数据表
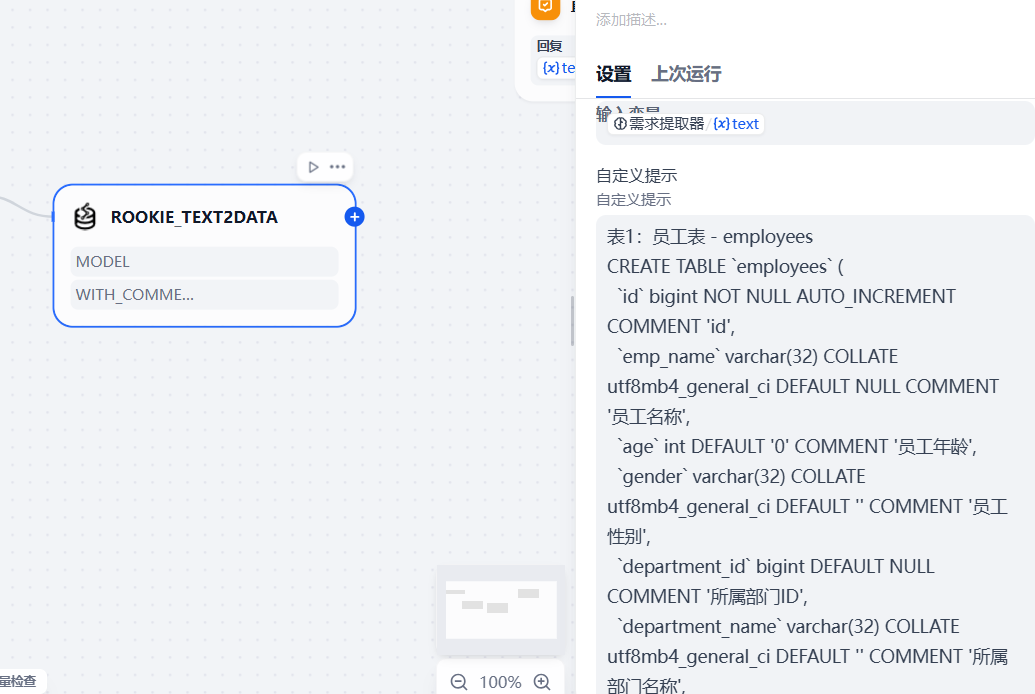
数据库相关表结构说明:1、员工表(employees)完整建表sql如下:
CREATE TABLE `employees` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',`emp_name` varchar(32) DEFAULT NULL COMMENT '员工名称',`age` int DEFAULT '0' COMMENT '员工年龄',`gender` varchar(32) DEFAULT '' COMMENT '员工性别',`department_id` bigint DEFAULT NULL COMMENT '所属部门ID',`department_name` varchar(32) DEFAULT '' COMMENT '所属部门名称',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 COMMENT='员工表';2、部门表(depart)完整建表sql如下:
CREATE TABLE `depart` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',`depart_name` varchar(32) DEFAULT NULL COMMENT '部门名称',`depart_code` varchar(32) DEFAULT NULL COMMENT '部门编码',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 COMMENT='部门表';两个表的关联关系说明:
employees(员工表)中的department_id字段为depart(部门表)的外键,即员工表的department_id是部门表的id主键这个字段3.2 完整操作与配置过程
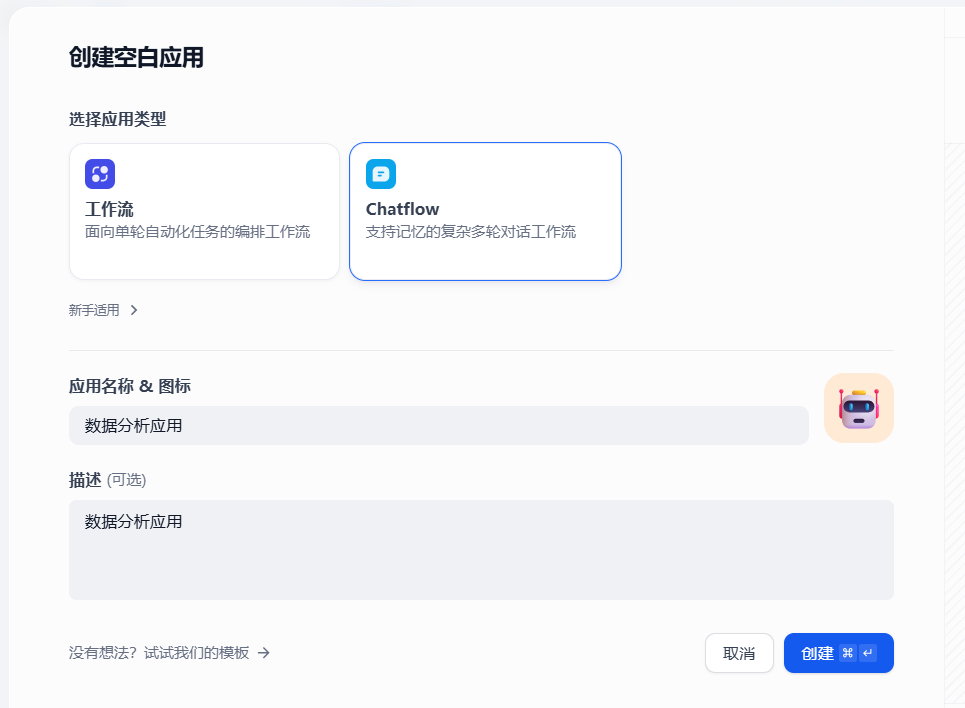
3.2.1 创建空白应用
如下,创建一个chatflow类型的应用
创建完成后,将默认跳转到下面的流程配置页面
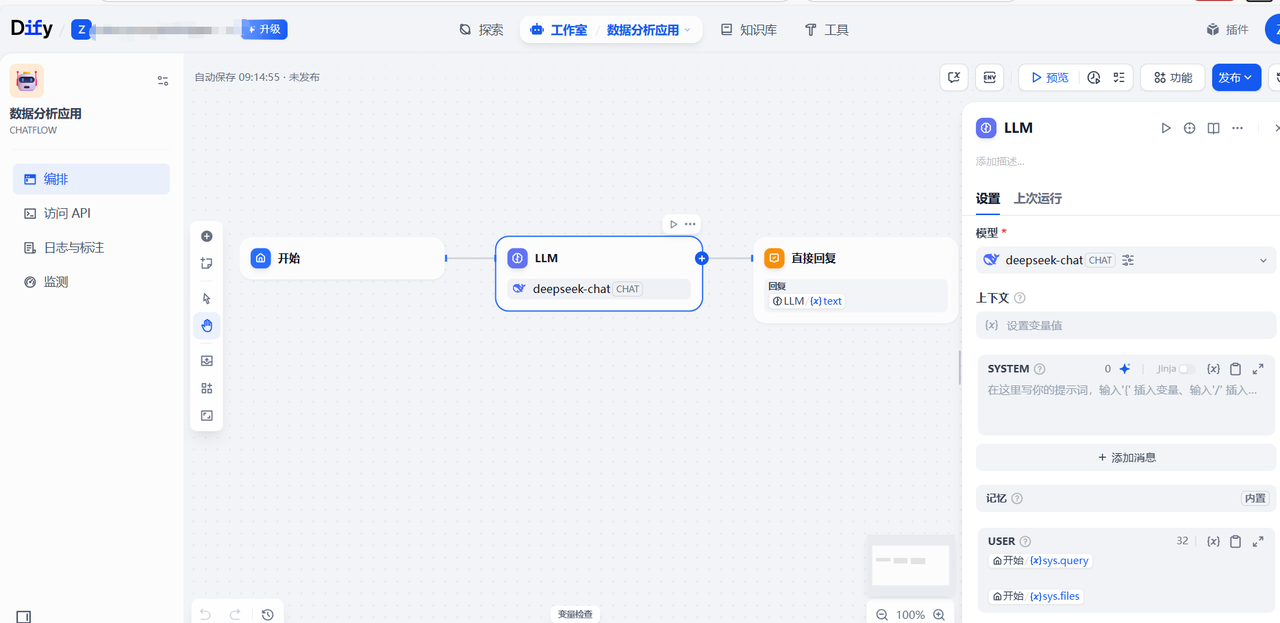
3.2.2 增加一个大模型节点
该大模型节点用于解析用户输入的问题,确保后续的步骤能够正常的执行,在系统提示词那里配置如下内容
# 角色
你是一位文字提炼专家# 任务
负责把用户的查询数据需求进行提炼和总结,抓取关键数据查询文字,去掉和数据查询无关的内容,比如生成图表、生成excel、生成表单和数据查询无关的内容,只保留提炼查询数据的文字# 输出
只输出你提炼后的结果,无需其他言语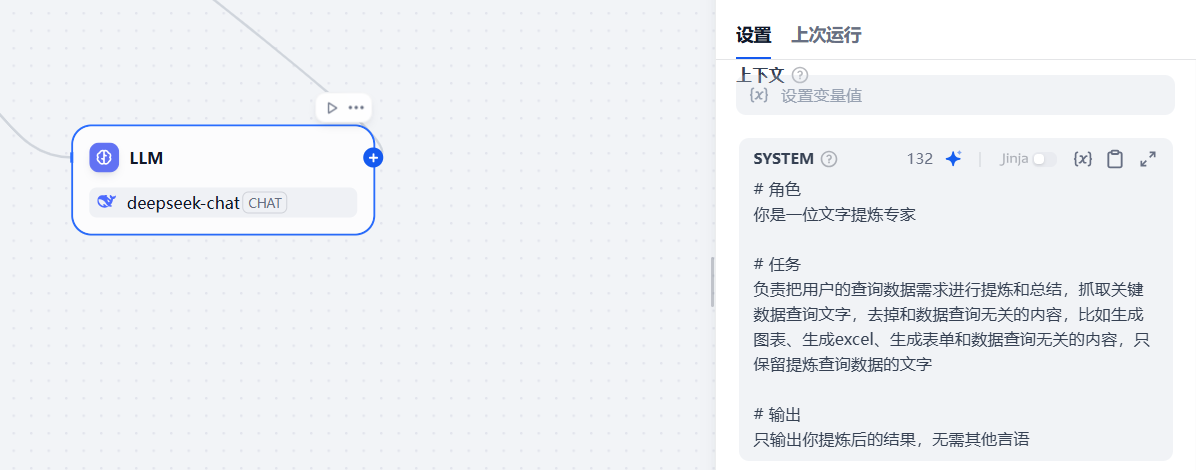
用户提示词那里,接收开始节点用户的输入信息
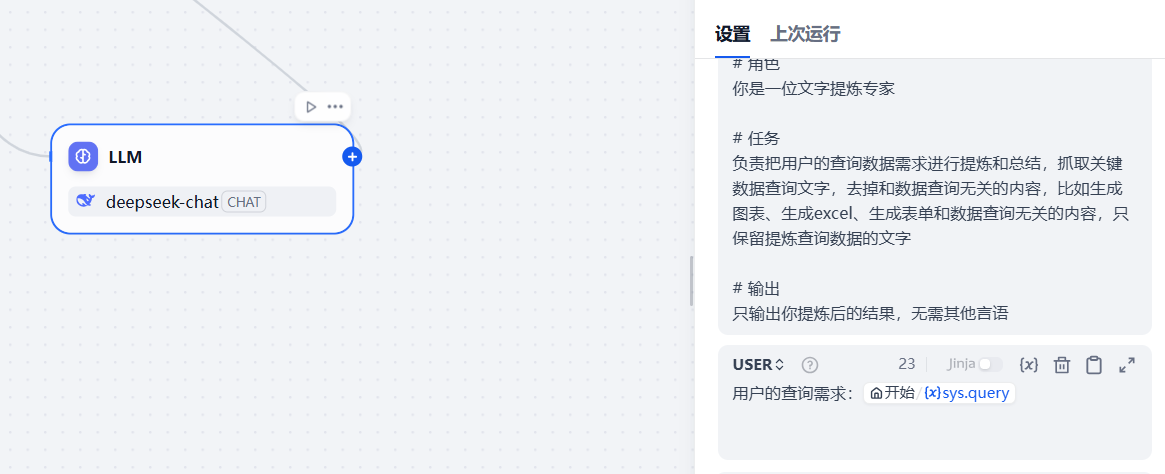
3.2.3 增加数据库执行的第一个插件节点
如下,添加一个text2data的插件节点
参考下面的配置信息,主要是填写数据库连接的相关信息,比如数据库账号,数据库名称,地址等
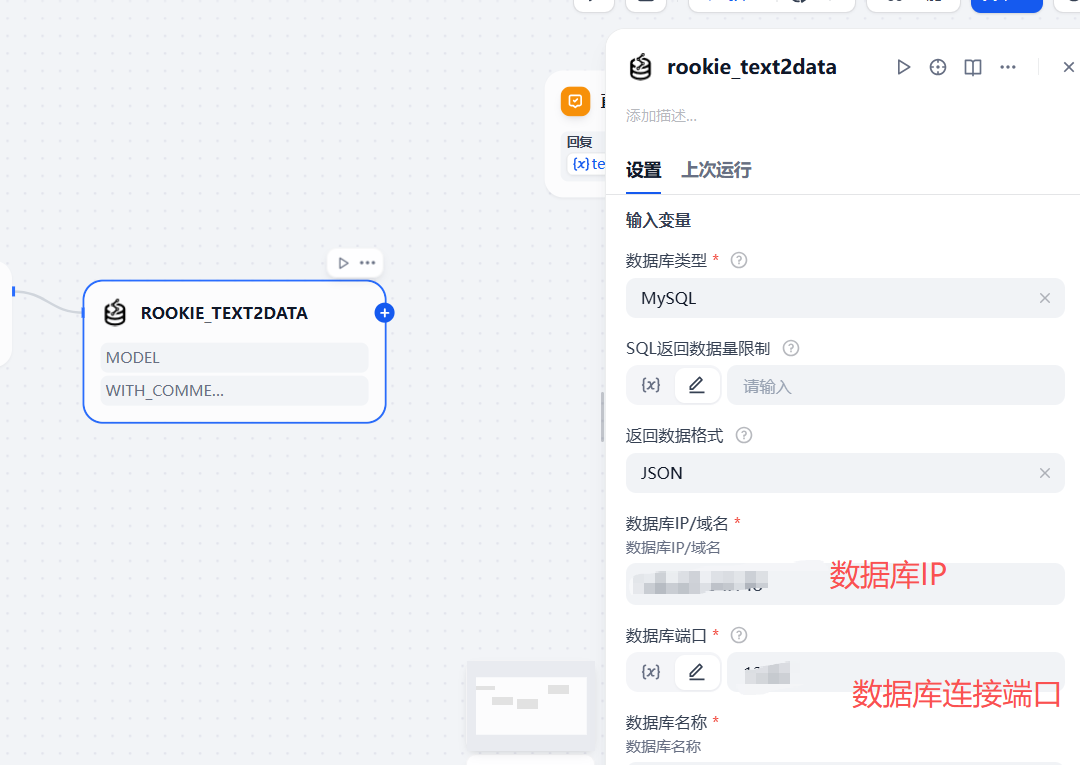
在自定义提示那里,将本次涉及到的相关mysql表结构填写进去
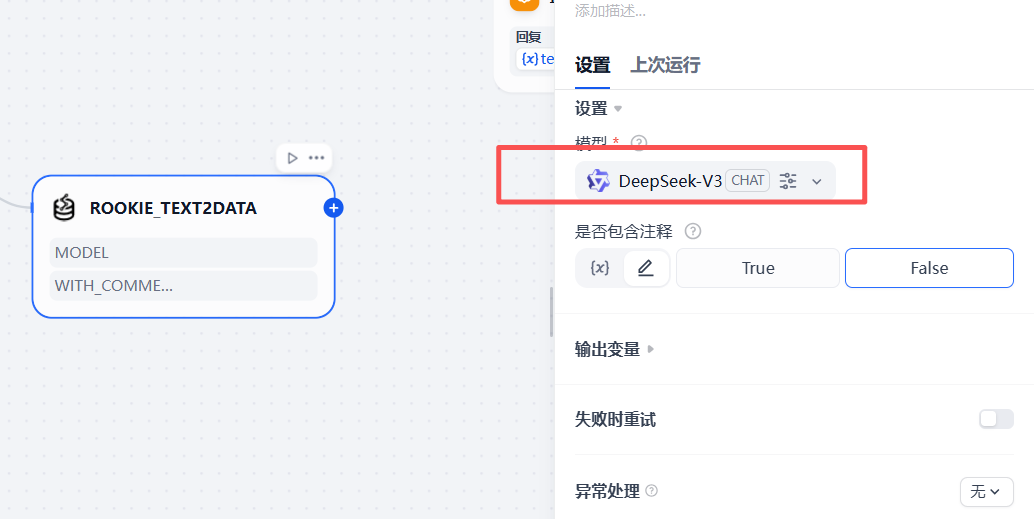
最后选择一下模型
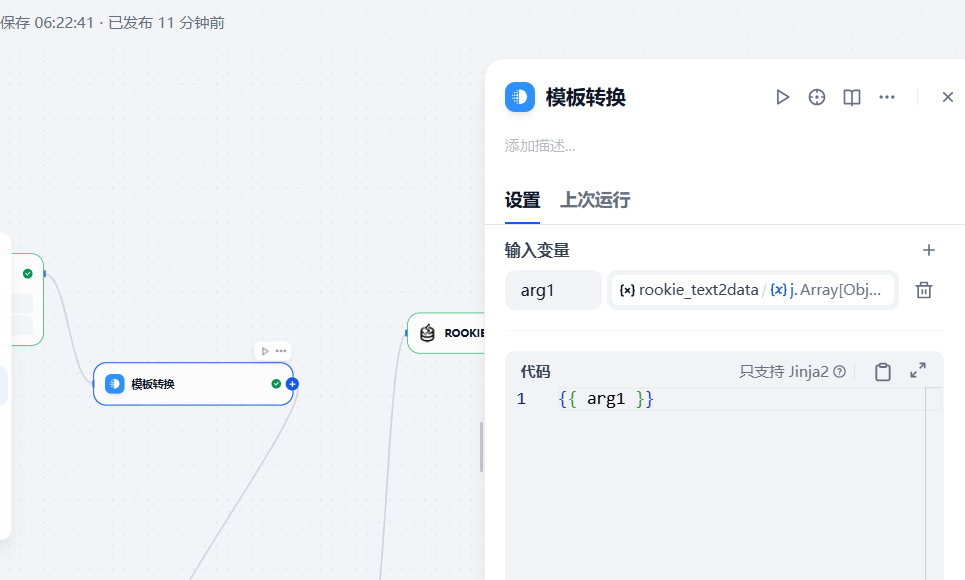
3.2.4 增加一个模板转换节点
上面的输出内容中,目标需要的sql在json参数中,需要从参数中将包含sql语句的参数提取出来
3.2.5 增加提取参数中的SQL大模型节点
通过该大模型节点,将上一步的参数中的SQL语句提取出来,在系统提示词中做如下配置:
你是一位精通SQL语言的数据库专家,熟悉MySQL数据库。你的的任务是检查该Sql语句是否有错,如果有错请更正,没有错则输出Sql语句。
回答要求:
1.不能包含任何多余的信息。
2.必须是可以执行的SQL语句。
3.删除掉Sql中的\n,用空格替换。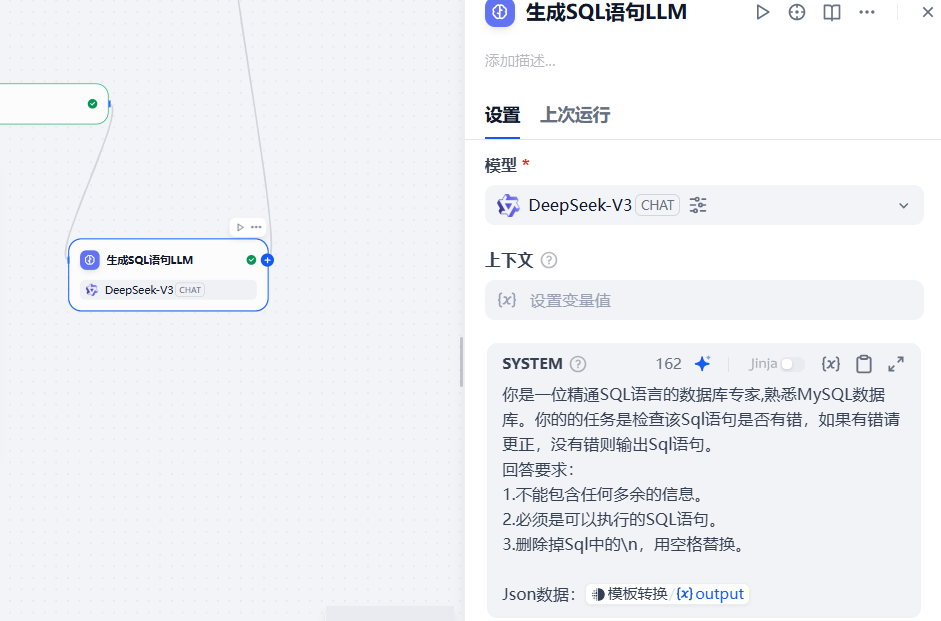
3.2.6 增加第二个插件节点
该节点用于从前一个节点的返回的sql进行执行,从而得到真正的sql执行结果
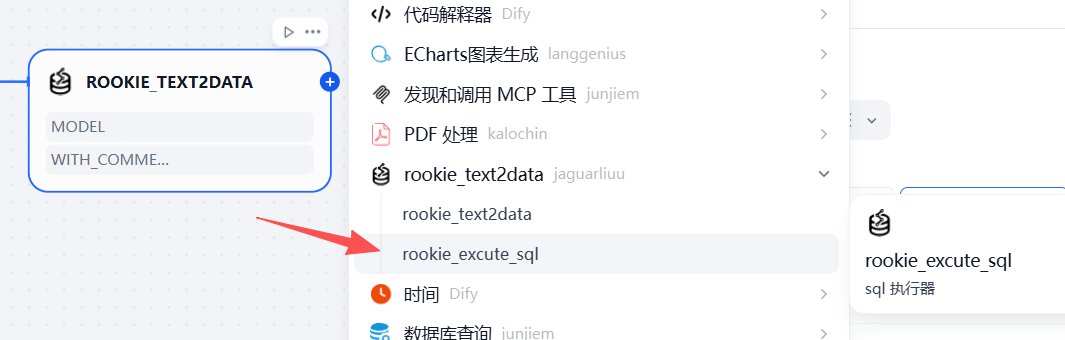
这个节点的配置也主要是数据库的连接信息,参考下面的图进行核心参数的配置即可
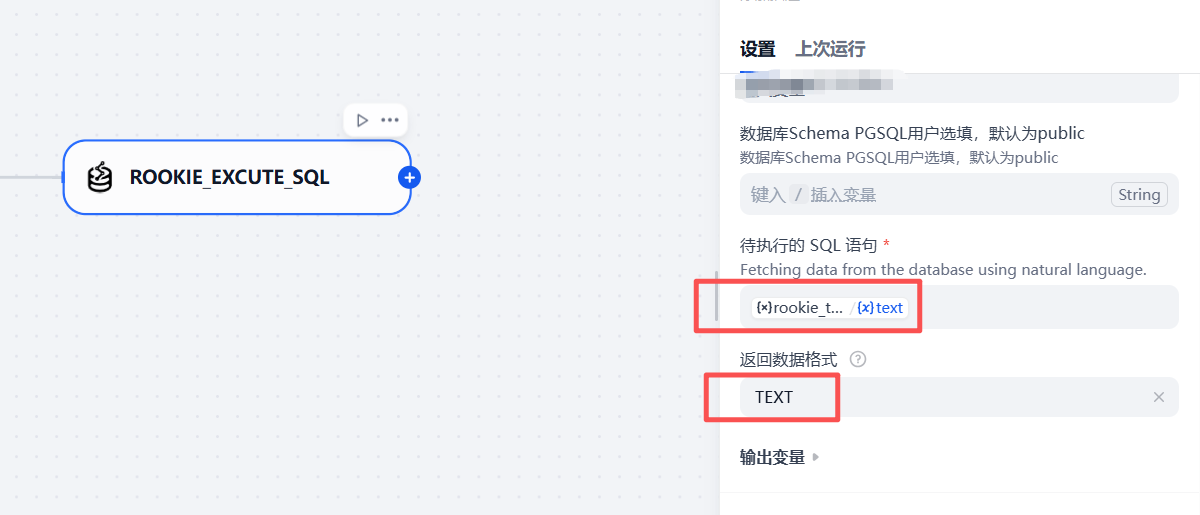
3.2.7 增加条件分支节点
在后续的处理逻辑中,会涉及到多种不同类型的业务处理,比如生成图表,生成markdown格式的输出,生成excel等,这里需要通过一个条件分支节点来进行判断
-
在下面的条件分支判断中表示,如果用户输入的问题中包含了图,说明后面要通过流程配置生成分析图
-
如果用户输入包含了 excel,表示需要为用户输出excel文件;
-
其他情况下走else的处理;
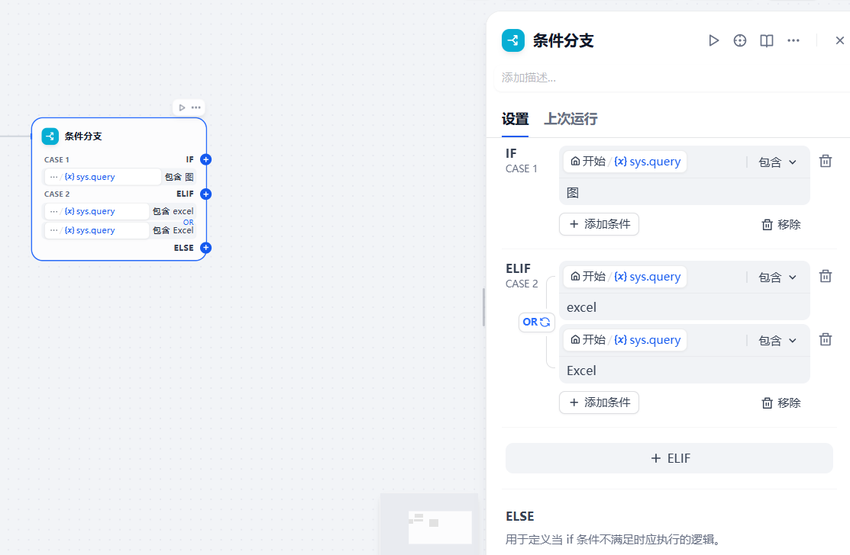
接下来依次配置各个流程分支的情况。
3.2.7.1 第一个条件分支增加大模型节点
如下,在第一个条件分支后面增加一个大模型节点,用于解析上一步的输出结果,推荐合适的图表类型,配置如下提示词
# 任务
根据用户的需求,以及数据内容,自行判断哪种图表类型合适# 输出
只输出你推荐的图表类型名称,从以下图表类型中选择一个输出:柱状图,折线图,饼图,散点图,带有涟漪特效动画的散点(气泡)图,K线图,雷达图,热力图,数图,矩形树图,旭日图,地图,路径图。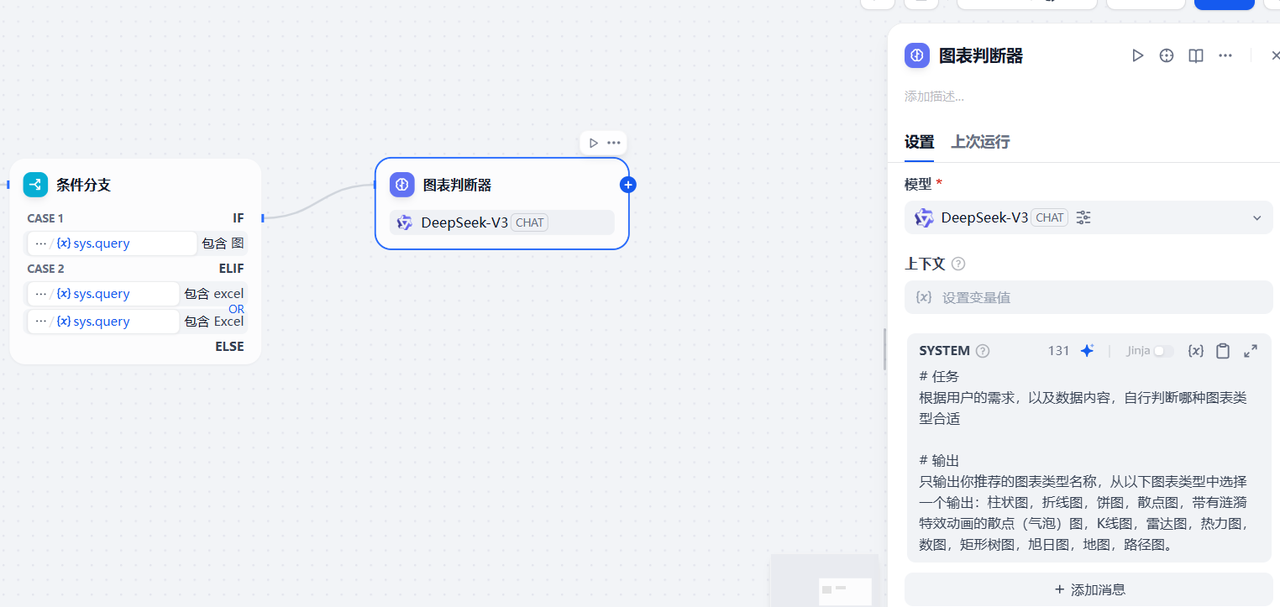
用户提示词配置如下内容,配置用户的提问内容,以及上一步执行sql的结果
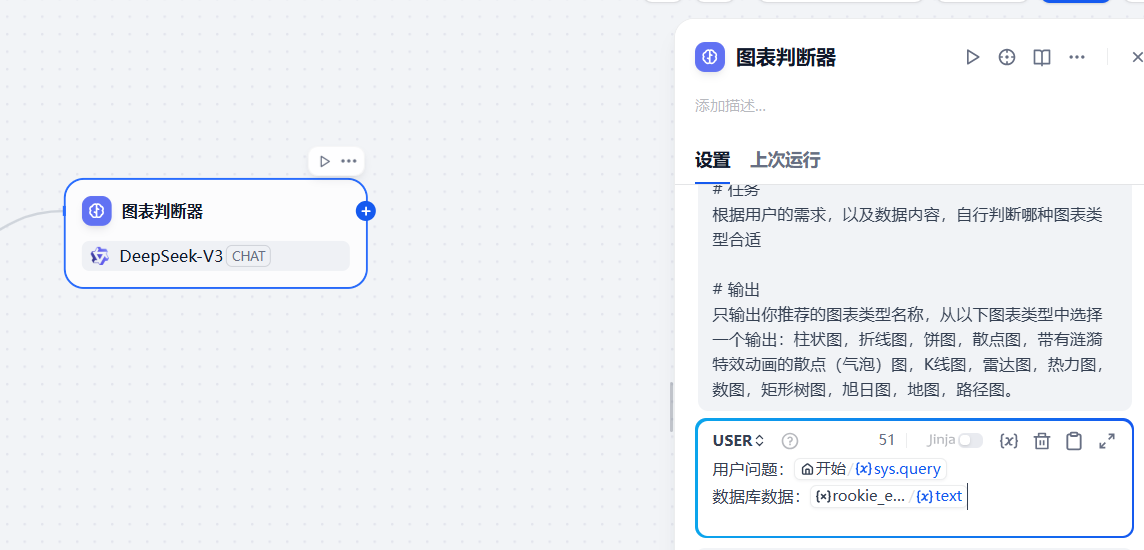
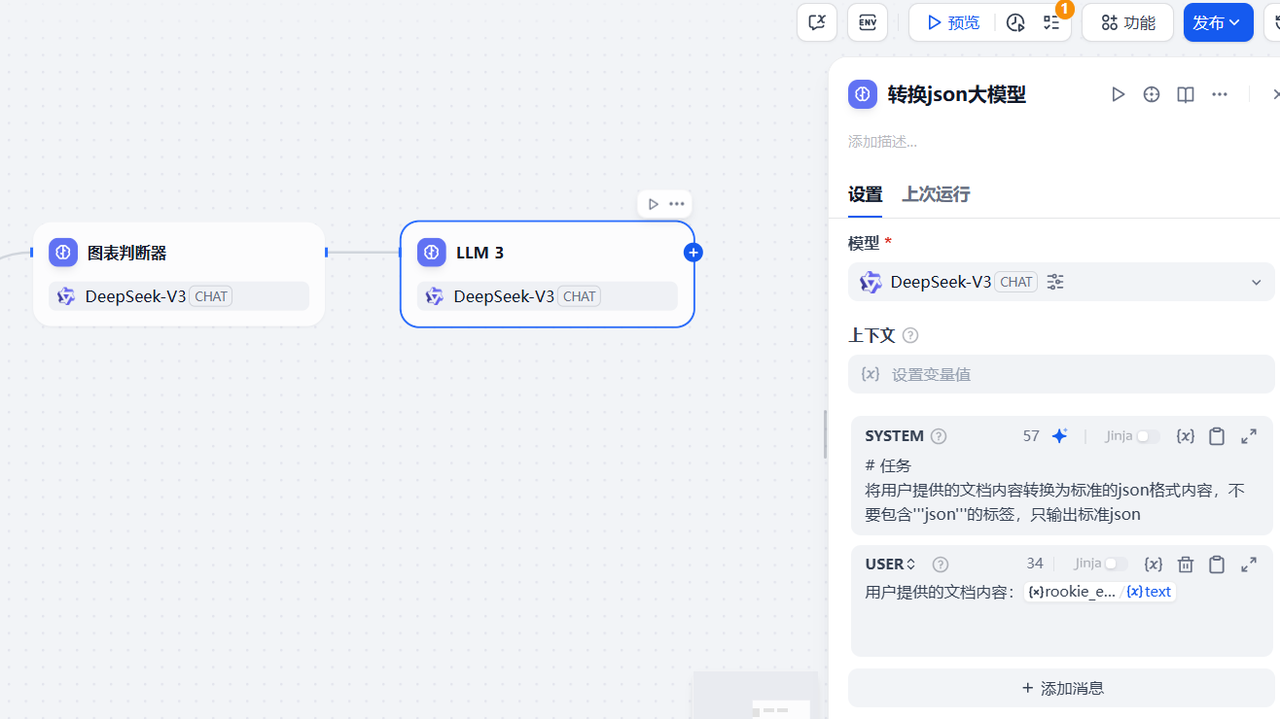
3.2.7.2 增加大模型节点
该大模型节点用于将前面sql执行器的结果转为json格式内容,参考下面的配置信息
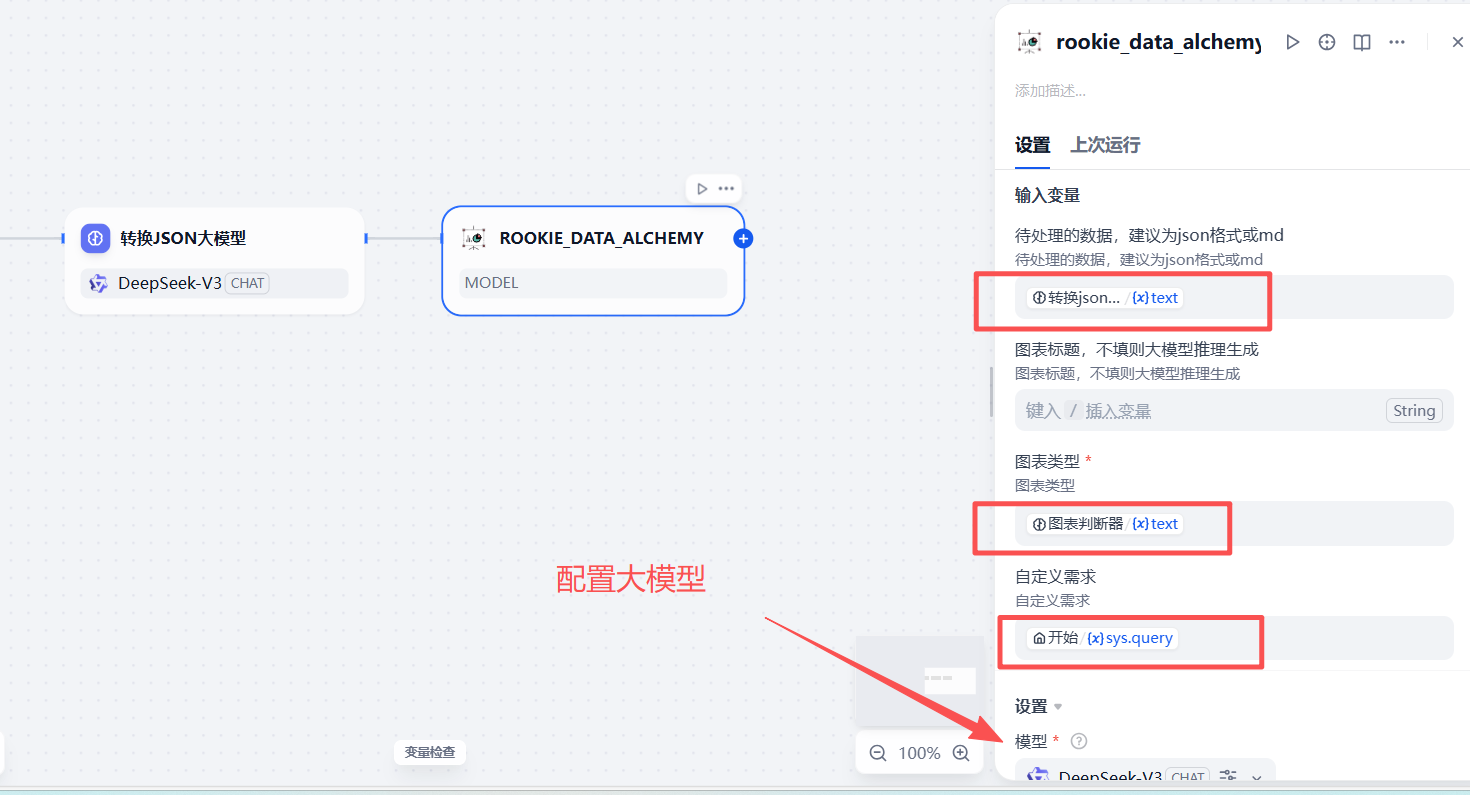
3.2.7.3 增加数据转图表的插件节点
增加一个新的插件节点,用于将json格式数据转为echarts图表需要的格式形式,从而展示图表,节点配置信息参考下面的图进行配置
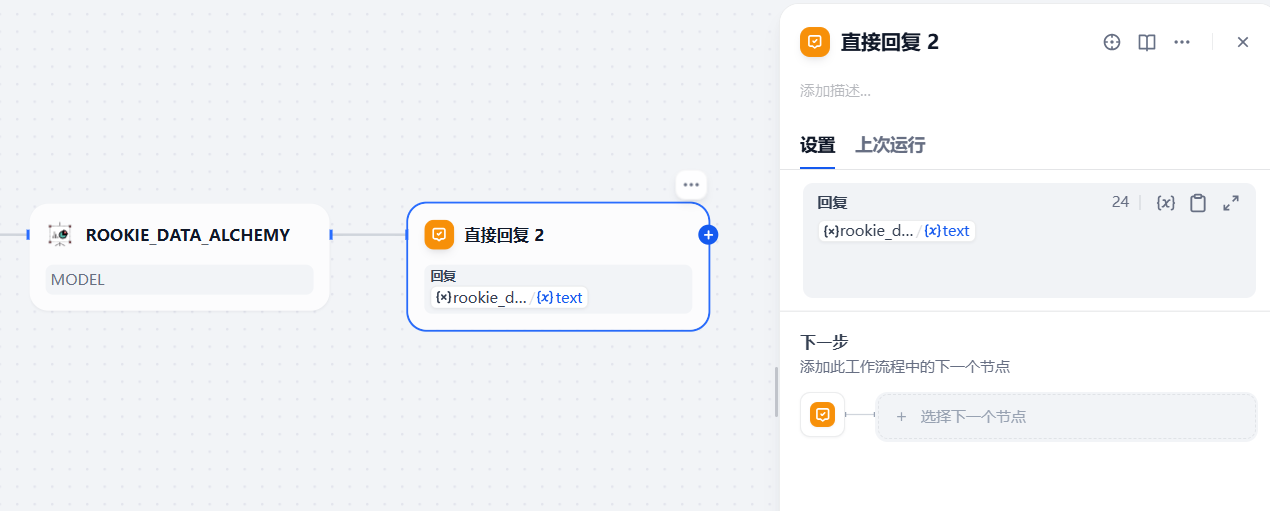
3.2.7.4 增加回复节点
最后增加一个直接回复节点
3.2.8 第二个分支节点增加一个大模型节点
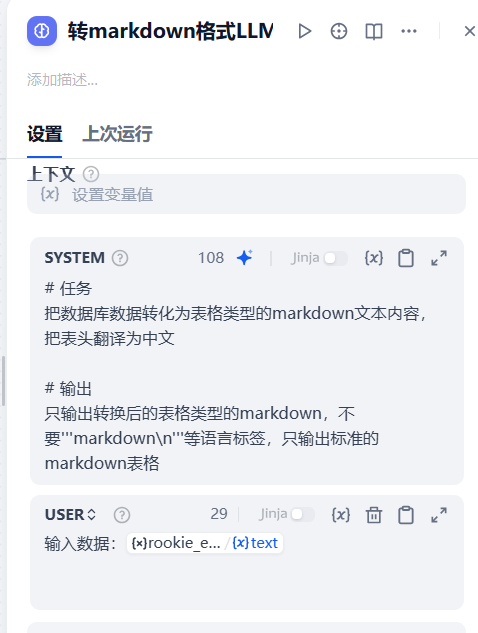
在第二个分支增加一个大模型节点,用于将sql执行的结果转为Markdown格式的内容,参考下面的节点配置信息
3.2.8.1 增加Markdown转换节点
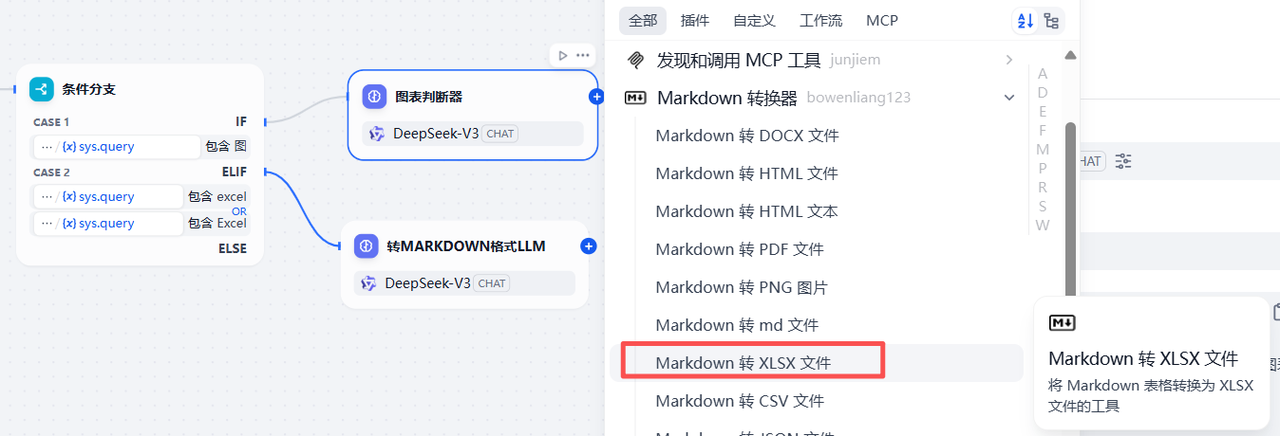
该节点用于将前一步的Markdown格式的内容转为excel文件
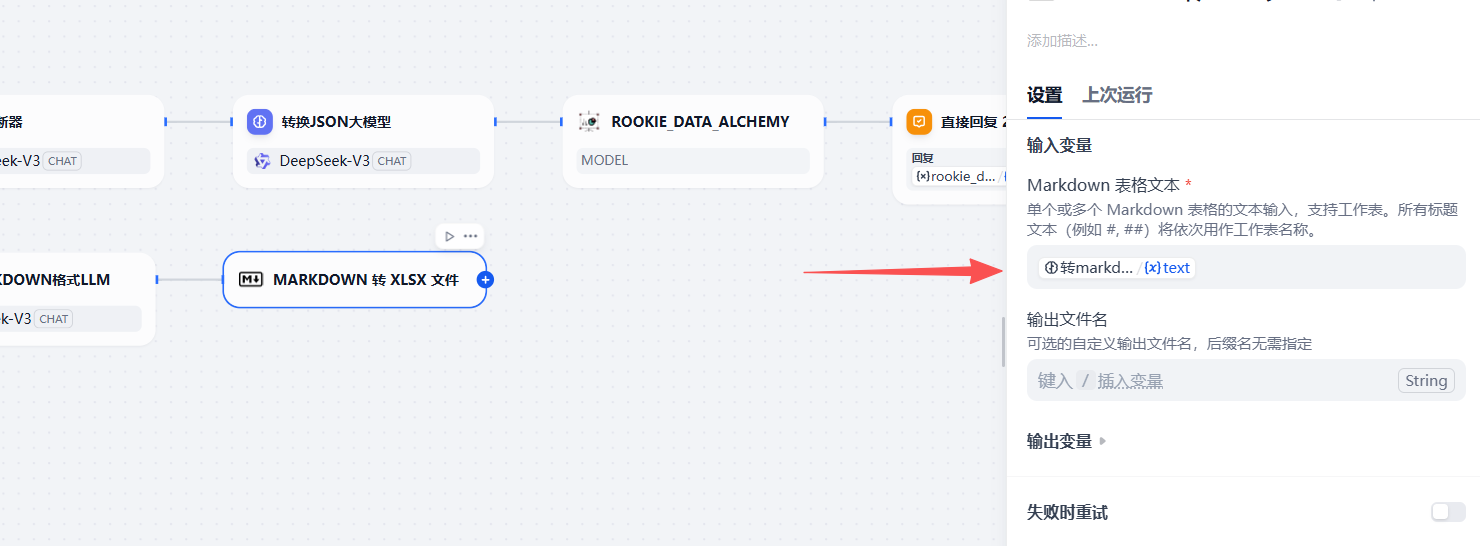
配置一下输入的参数即可
3.2.8.2 增加回复节点
最后增加一个回复节点,输出excel结果,这里选择上一步生成的excel文件
3.2.9 第三个分支增加一个大模型节点
该节点用于对sql执行的结果进行分析总结,系统提示词参考下面的内容进行配置
#角色
你是一个精通数据处理、分析和总结的大师# 任务
你可以根据用户的问题,从提供的数据库中检索相关信息,整合提炼后用精准合适的自然语言回复用户# 输出
1、若用户只是查询数据,则提炼后直接回复数据内容即可
2、若用户需要你分析数据,则可以结合数据给出专业的分析内容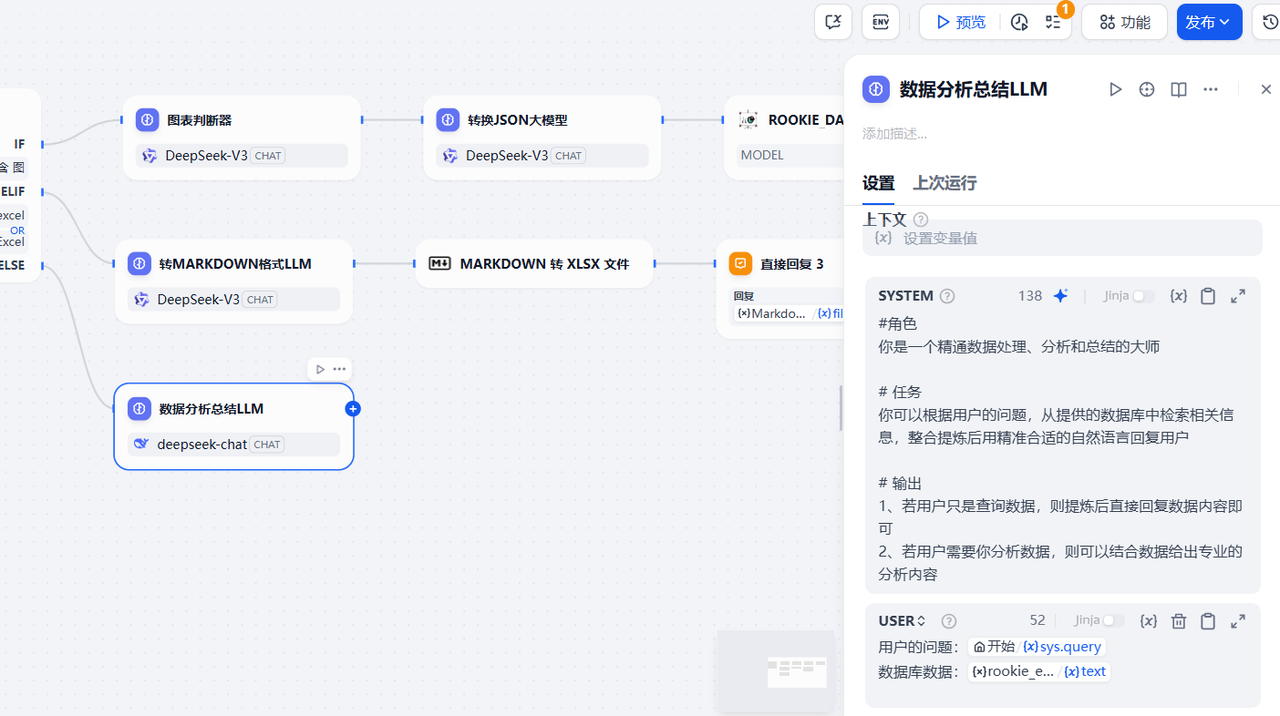
3.2.9.1 增加回复节点
最后增加一个回复节点,接收上一步的LLM节点的总结输出内容
3.2.10 效果测试
上面的流程配置完成后,点击发布更新、预览,然后分别测试下不同的分支下的效果
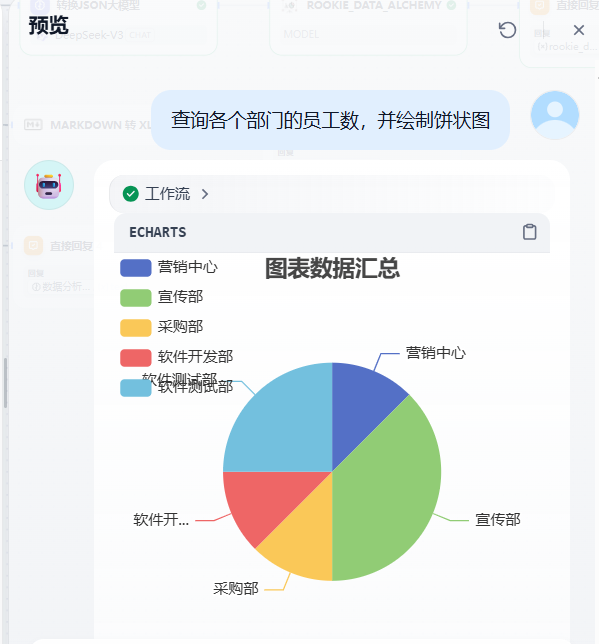
1)测试图表展示
如下,输入问题,统计各个部门的员工数,并绘制饼状图
2)测试生成excel
这一次测试生成一个excel
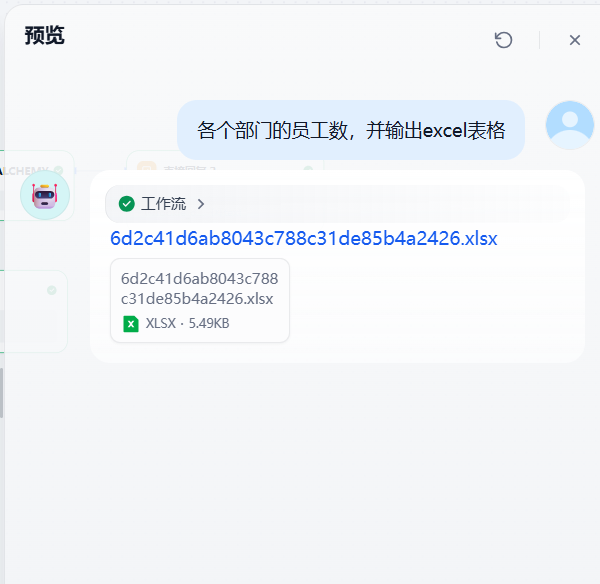
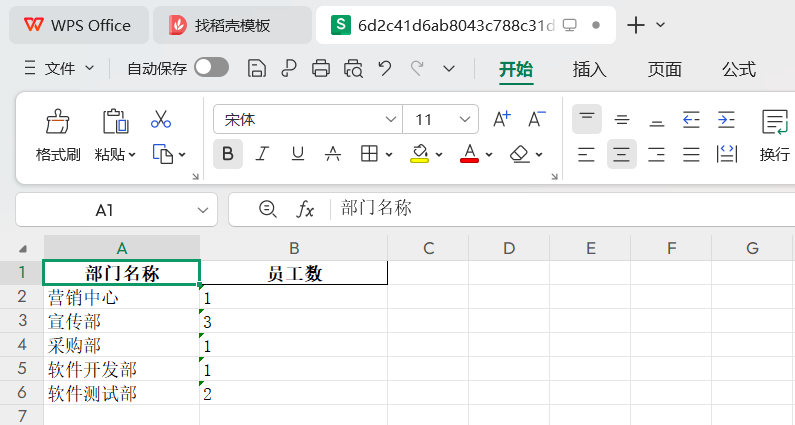
等待流程执行完成之后,下载excel,得到的也是符合预期的输出结果
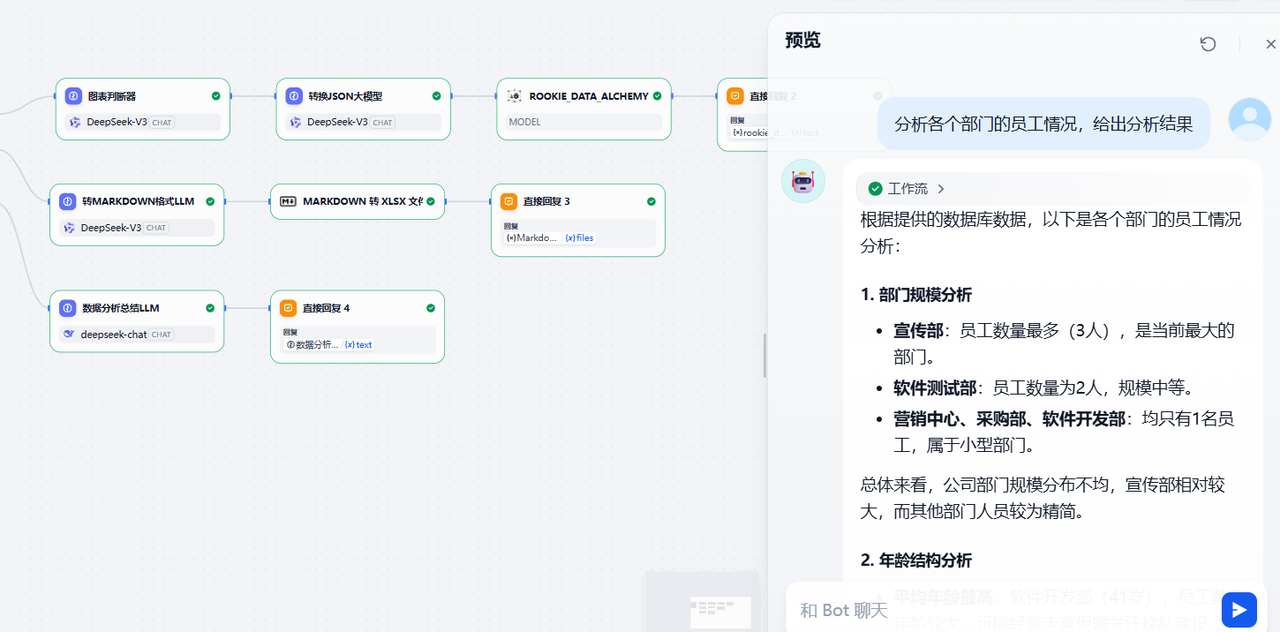
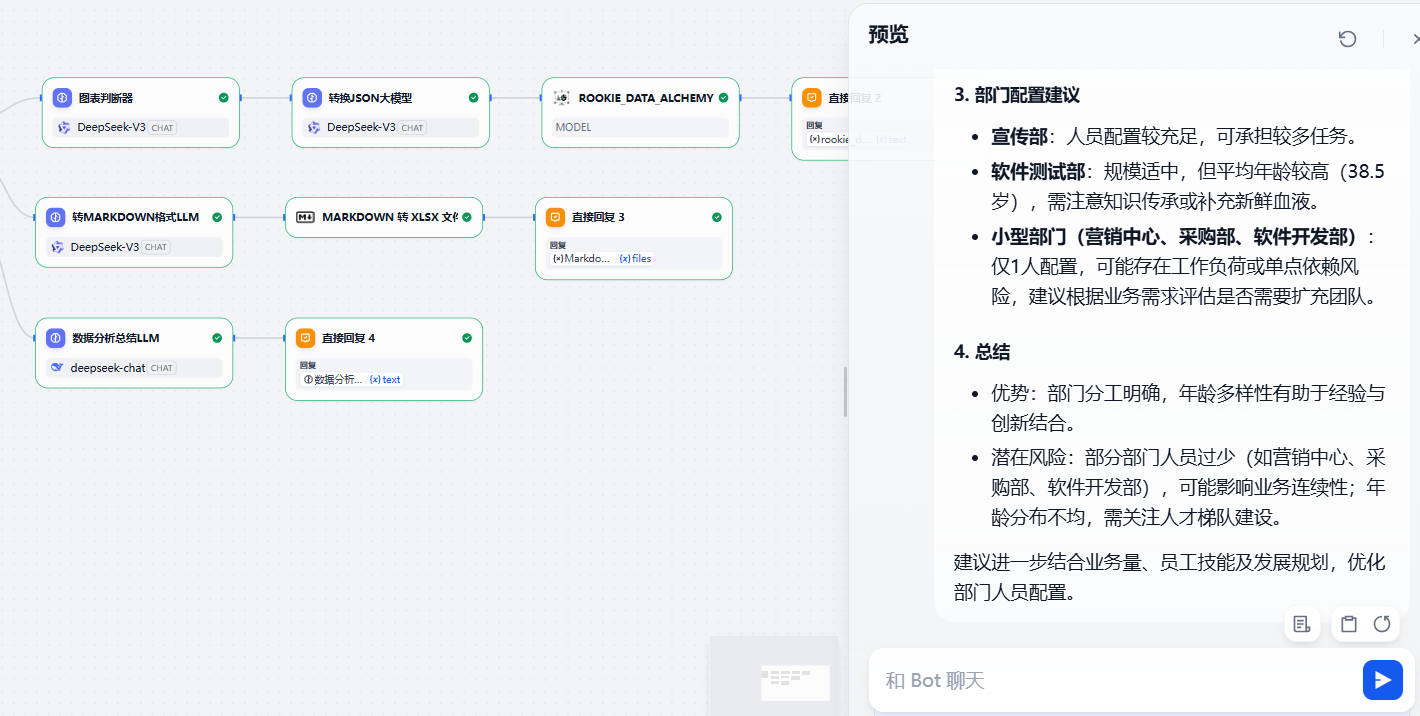
3)测试分析结果
如果上面两个分支都不满足,将会走内容分析的分支,比如输入下面的问题,将会给出比较详细的分析报告输出
四、写在文末
本文通过较大的篇幅详细介绍了基于Dify实现一个数据分析的智能体应用,并通过详细的操作步骤展现了完整的配置过程,希望对看到的同学有用哦,本篇到此介绍,感谢观看。