elasticsearch 的配制
1、下载 Elasticsearch7.17.3
下载Elasticsearch
7.17.3版本的zip包,并解压到指定目录- 下载地址:
- https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-3
安装中文分词器,注意下载与Elasticsearch对应的版本,在项目的releases里通过
tag:v7.17.3搜索- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载jdk11版本,因为这个版本要求是jdk11

2、安装
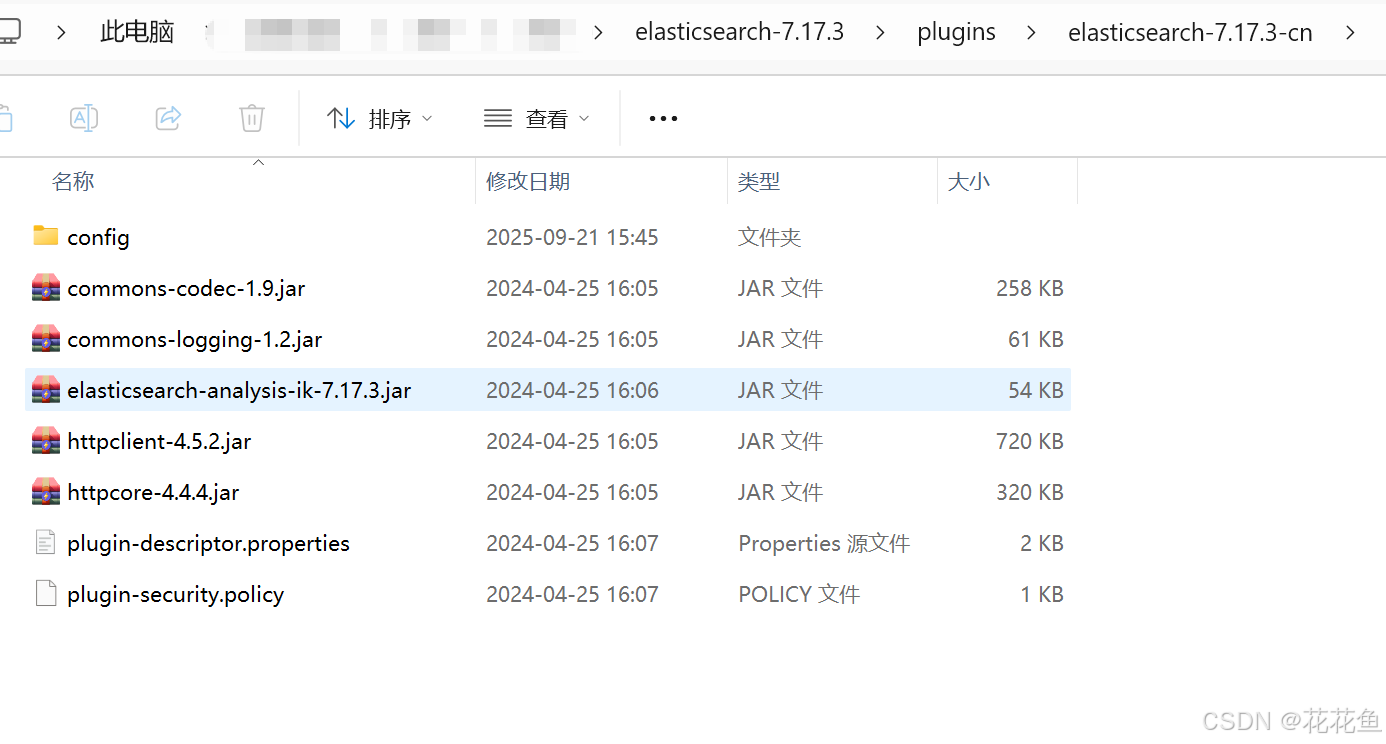
将这个文件analysis-ik,解压以后,放到plugins目录,这里要注册建个目录,然后将这个解压好的文件全部入里面:

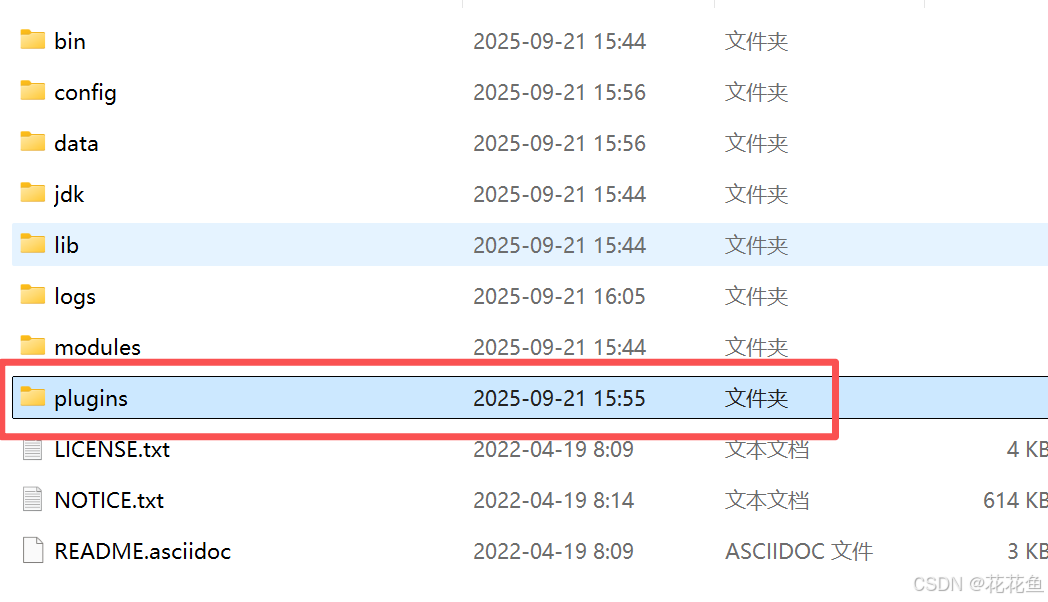
plugins下的目录:

目录下的文件:
加入一个环境变量ES_JAVA_HOME:
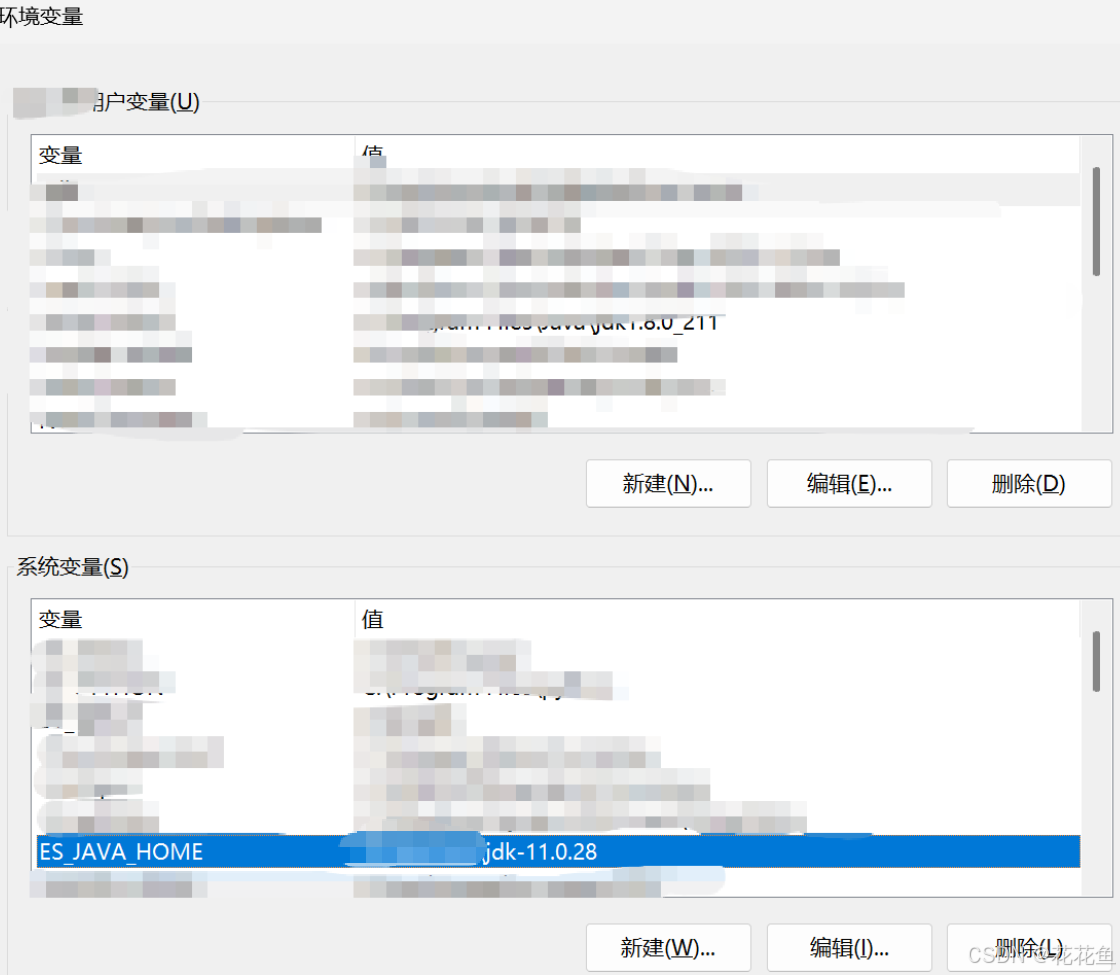
值:这里的jdk-11是完整路径。
3、启动
经过上面的步骤,就可以开始启动了:
定位目录:
新建终端,然后输入./elasticsearch.bat就可以正常启动了。
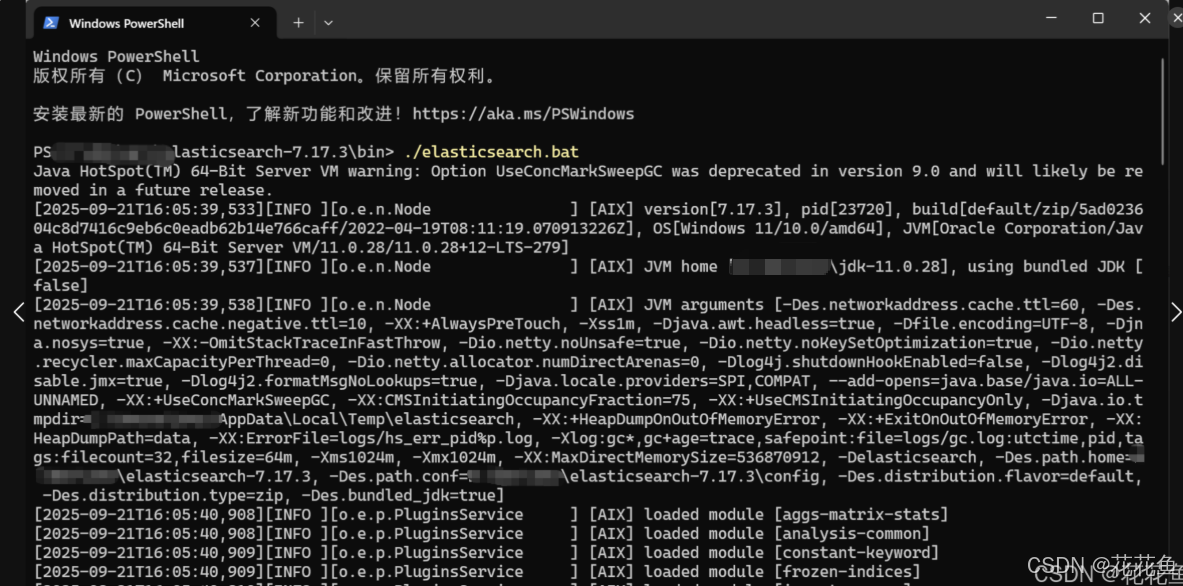
但是你可能会发现报个错connection reset:
[2025-09-21T16:01:16,035][ERROR][o.e.i.g.GeoIpDownloader ] [AIX] error updating geoip database [GeoLite2-Country.mmdb]
java.net.SocketException: Connection resetat java.net.SocketInputStream.read(SocketInputStream.java:186) ~[?:?]at java.net.SocketInputStream.read(SocketInputStream.java:140) ~[?:?]at sun.security.ssl.SSLSocketInputRecord.read(SSLSocketInputRecord.java:484) ~[?:?]at sun.security.ssl.SSLSocketInputRecord.readHeader(SSLSocketInputRecord.java:478) ~[?:?]at sun.security.ssl.SSLSocketInputRecord.decode(SSLSocketInputRecord.java:160) ~[?:?]at sun.security.ssl.SSLTransport.decode(SSLTransport.java:111) ~[?:?]at sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1383) ~[?:?]at sun.security.ssl.SSLSocketImpl.readHandshakeRecord(SSLSocketImpl.java:1296) ~[?:?]at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:416) ~[?:?]at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:388) ~[?:?]at sun.net.www.protocol.https.HttpsClient.afterConnect(HttpsClient.java:576) ~[?:?]at sun.net.www.protocol.https.AbstractDelegateHttpsURLConnection.connect(AbstractDelegateHttpsURLConnection.java:201) ~[?:?]at sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1631) ~[?:?]at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1559) ~[?:?]at java.net.HttpURLConnection.getResponseCode(HttpURLConnection.java:527) ~[?:?]at sun.net.www.protocol.https.HttpsURLConnectionImpl.getResponseCode(HttpsURLConnectionImpl.java:334) ~[?:?]at org.elasticsearch.ingest.geoip.HttpClient.lambda$get$0(HttpClient.java:55) ~[ingest-geoip-7.17.3.jar:7.17.3]at java.security.AccessController.doPrivileged(AccessController.java:551) ~[?:?]at org.elasticsearch.ingest.geoip.HttpClient.doPrivileged(HttpClient.java:97) ~[ingest-geoip-7.17.3.jar:7.17.3]at org.elasticsearch.ingest.geoip.HttpClient.get(HttpClient.java:49) ~[ingest-geoip-7.17.3.jar:7.17.3]at org.elasticsearch.ingest.geoip.GeoIpDownloader.processDatabase(GeoIpDownloader.java:166) [ingest-geoip-7.17.3.jar:7.17.3]at org.elasticsearch.ingest.geoip.GeoIpDownloader.updateDatabases(GeoIpDownloader.java:132) [ingest-geoip-7.17.这个不影响正确使用,可以禁用就行,或者下载离线的版本:
这里我是直接禁用了geoip,打开这个文件:
然后加上一句:
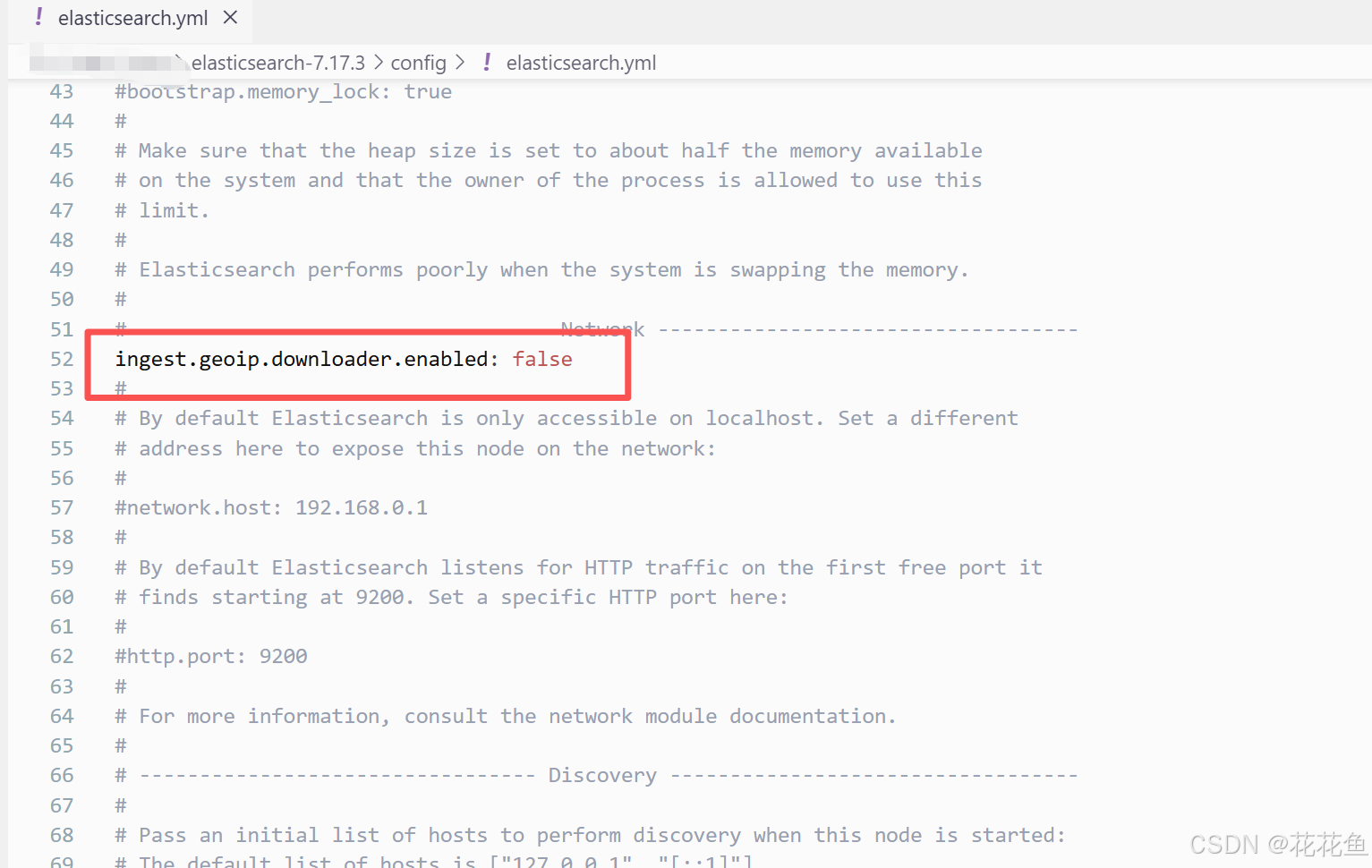
再次启动就不会再报错了。
4、elasticsearch的详解
Elasticsearch(简称 ES)是一个开源的分布式搜索和分析引擎,基于 Lucene 构建,专注于实时、分布式、高可用的数据存储与检索。它广泛应用于日志分析、全文检索、监控告警、数据可视化等场景,是 Elastic Stack(ELK Stack:Elasticsearch, Logstash, Kibana)的核心组件。
核心特性
分布式架构
- 数据自动分片(Shard)并分布在多个节点,支持水平扩展。
- 分片副本(Replica)机制确保高可用,副本可分担查询压力。
实时搜索
- 基于 Lucene 的倒排索引,写入数据后近实时(毫秒级)可检索。
- 支持复杂的全文检索、模糊匹配、聚合分析等。
RESTful API
- 所有操作通过 HTTP/JSON 接口完成,易于集成到各种语言(Python、Java 等)。
多数据类型支持
- 除文本外,支持数字、日期、地理坐标、数组、嵌套对象等。
高扩展性
- 动态添加节点扩展集群容量,自动负载均衡。
核心概念
索引(Index)
- 类似数据库中的 “表”,是一组具有相似结构的文档集合。
- 命名规则:小写字母,无特殊字符(如
user_logs)。
文档(Document)
- 索引中的一条数据,类似数据库中的 “行”,以 JSON 格式存储。
- 每个文档有唯一 ID(
_id),可手动指定或自动生成。
分片(Shard)
- 索引的分片单元,用于水平拆分数据(默认 1 主分片)。
- 主分片(Primary Shard):数据写入的原始分片,数量创建后不可修改。
- 副本分片(Replica Shard):主分片的备份,可提升查询性能和容错性(默认 1 副本)。
节点(Node)
- 一个运行中的 Elasticsearch 实例,多个节点组成集群。
- 节点类型:
- 主节点(Master Node):管理集群元数据(如索引创建 / 删除)。
- 数据节点(Data Node):存储数据并处理搜索 / 聚合请求。
- 协调节点(Coordinating Node):转发请求,汇总结果(默认所有节点都是)。
集群(Cluster)
- 多个节点组成的集合,共享同一个集群名称(默认
elasticsearch)。
- 多个节点组成的集合,共享同一个集群名称(默认
工作原理
写入流程
- 数据通过协调节点路由到对应主分片。
- 主分片写入成功后,同步到副本分片。
- 所有副本确认后,返回成功响应。
搜索流程
- 协调节点将查询分发到相关分片(主或副本)。
- 各分片执行查询并返回结果,协调节点汇总后返回给客户端。
基本操作(REST API)
创建索引
bash
PUT /my_index {"settings": {"number_of_shards": 3, // 主分片数"number_of_replicas": 1 // 副本数},"mappings": {"properties": {"name": { "type": "text" }, // 全文检索字段"age": { "type": "integer" }, // 数字类型"birth": { "type": "date" } // 日期类型}} }插入文档
bash
POST /my_index/_doc/1 {"name": "Alice","age": 30,"birth": "1993-05-15" }查询文档
- 全文检索:
bash
GET /my_index/_search {"query": {"match": { "name": "alice" } // 大小写不敏感} }- 聚合分析(统计年龄分布):
bash
GET /my_index/_search {"size": 0,"aggs": {"age_groups": {"range": {"field": "age","ranges": [{ "to": 20 },{ "from": 20, "to": 40 },{ "from": 40 }]}}} }删除索引
bash
DELETE /my_index
适用场景
- 日志 / 监控分析:结合 Logstash 收集日志,Kibana 可视化分析。
- 全文检索:电商商品搜索、站内搜索等。
- 时序数据存储:监控指标(如 CPU、内存)的实时分析。
- 地理信息检索:基于地理位置的查询(如 “附近的餐厅”)。
部署与配置
环境要求
- JDK 11+(Elasticsearch 7.x+ 依赖)。
- 足够的内存(建议至少 4GB)。
核心配置(
elasticsearch.yml)yaml
cluster.name: my_cluster # 集群名称 node.name: node-1 # 节点名称 path.data: /var/lib/elasticsearch # 数据存储路径 path.logs: /var/log/elasticsearch # 日志路径 network.host: 0.0.0.0 # 监听地址(允许外部访问) discovery.seed_hosts: ["host1", "host2"] # 集群节点发现 cluster.initial_master_nodes: ["node-1", "node-2"] # 初始主节点候选
常见问题
- 内存不足:调整
jvm.options中的-Xms和-Xmx(建议设为物理内存的 50%,不超过 31GB)。 - 分片不均衡:使用
_cluster/rebalanceAPI 手动均衡分片。 - 版本兼容性:Elastic Stack 组件(ES、Kibana 等)版本必须一致。
通过合理设计索引结构、优化分片策略和查询语句,Elasticsearch 可高效处理 PB 级数据的实时检索与分析。
好了,上面就是安装及启动的过程。