H2数据库(tcp 服务器模式)调优
启用mvcc
MVCC优势:
通过维护数据行的多个版本实现读写并发,减少锁竞争,适合高并发场景412。
内存影响:
MVCC会占用更多内存存储版本数据,但显著提升并发性能
jdbc:h2:tcp://localhost/~/mydatabase;MVCC=TRUE
如果是1.4.x版本或者以上可以不用配置默认启用MVCC
调优h2数据库(tcp服务器模式)启动命令参数
配置内存堆大小
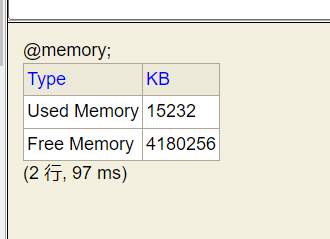
访问ip:8082 输入@memory; 可以查询数据库内存使用情况和大小
这就是总空间4g
1. JVM默认堆内存规则
初始堆大小(-Xms):默认为物理内存的1/64,但不超过1GB
最大堆大小(-Xmx):默认为物理内存的1/4,在物理内存小于192MB时为1/2
典型值示例:
8GB内存机器:初始堆约128MB,最大堆2GB
16GB内存机器:初始堆约256MB,最大堆4GB
2. H2的特殊内存行为
缓存占用:默认会占用JVM堆内存的50%作为数据缓存,但可通过CACHE_SIZE参数调整
MVCC模式影响:启用MVCC时需额外增加20%-30%内存用于版本链存储
建议配置显式设置固定堆大小,避免依赖不确定的默认值。实际值应根据数据量和并发需求调整,MVCC模式下建议不低于4GB
java -Xms2g -Xmx2g -cp h2*.jar org.h2.tools.Server...配置G1垃圾收集器参数
1. -XX:+UseG1GC
启用G1(Garbage-First)垃圾收集器,这是JDK 9及以后版本的默认收集器。其核心设计目标是平衡吞吐量与低延迟:
分区域收集:将堆划分为多个等大小的Region(默认2048个),动态分配为Eden/Survivor/Old区
并行与并发结合:年轻代回收(STW)与老年代并发标记交替进行
适用场景:堆内存>4GB且需要稳定低延迟的应用(如H2数据库服务端)
2. -XX=100
设置G1收集器的目标最大停顿时间为100毫秒:
动态调整机制:G1会根据历史GC数据自动调整新生代/老年代比例,优先回收高收益Region以满足该目标
实际影响:该值设置过低(如<50ms)可能导致GC频率上升,建议生产环境设为50-200ms区间
3. -XX=4m
指定每个堆区域(Region)的大小为4MB:
默认行为:未设置时根据堆大小自动计算(1MB~32MB,堆≥4GB时通常为2MB)
大对象优化:增大Region尺寸可减少Humongous对象(占Region 50%以上的对象)的分配开销
权衡点:过大的Region会降低垃圾回收的粒度灵活性
适用于大多数应用,JVM会自动优化Region数量与停顿时间
如果需要手动配置
java -Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:G1HeapRegionSize=4m -cp h2-1.4····G1垃圾收集器并发线程数(ConcGCThreads)配置建议
生产环境推荐值
- 通用场景:
- 4核机器:建议值1~2
- 8核机器:建议值2~4
- 16核及以上:建议值4~8,但需结合业务负载调整
java -Xms16g -Xmx16g -XX:+UseG1GC -XX:ConcGCThreads=8 -cp h2····