康奈尔大学视觉-语言-动作模型全面综述:概念、进展、应用与挑战
作者: Ranjan Sapkota, Yang Cao, KonstantinosI. Roumeliotis, Manoj Karkee
单位:康奈尔大学生物与环境工程系,香港科技大学计算机科学与工程系,希腊伯罗奔尼撒大学信息学与电信系
论文标题:Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
论文链接:https://arxiv.org/pdf/2505.04769
主要贡献
系统性综述:本文提供了对Vision-Language-Action(VLA)模型的全面综述,涵盖了从概念基础到最新进展、应用领域以及面临的挑战等多个方面。
架构创新总结:详细分析了VLA模型的架构创新,包括早期融合模型、双系统架构和自校正框架等,并探讨了这些架构如何平衡效率、模块化和鲁棒性。
训练与效率提升:总结了VLA模型在训练效率方面的进展,如数据高效学习、参数高效方法和加速技术,这些技术显著提高了模型的可扩展性和实时性。
应用领域拓展:探讨了VLA模型在人形机器人、自动驾驶车辆、工业机器人、医疗与医疗机器人、精准农业和增强现实导航等多个领域的应用,展示了其在现实世界中的广泛潜力。
挑战与解决方案:识别了VLA模型面临的重大挑战,如实时推理限制、多模态动作表示、数据集偏差、系统集成复杂性、鲁棒性和伦理问题,并提出了针对性的解决方案。
介绍
研究背景与动机
传统方法的局限性:
在Vision-Language-Action(VLA)模型出现之前,视觉系统、语言系统和动作系统大多是独立发展的。视觉系统擅长图像识别和目标检测,语言系统擅长文本理解和生成,动作系统则负责控制机器人的运动。
然而,这些独立的系统在处理复杂环境和新情况时表现出明显的局限性。例如,传统计算机视觉模型(如基于卷积神经网络的模型)需要大量的标注数据,并且在环境或任务稍有变化时就需要重新训练。
大语言模型虽然在文本处理方面表现出色,但无法感知物理世界或执行动作。动作系统则依赖于手工策略或强化学习,虽然能够实现特定行为,但在泛化能力上存在不足。
VLA模型的兴起:
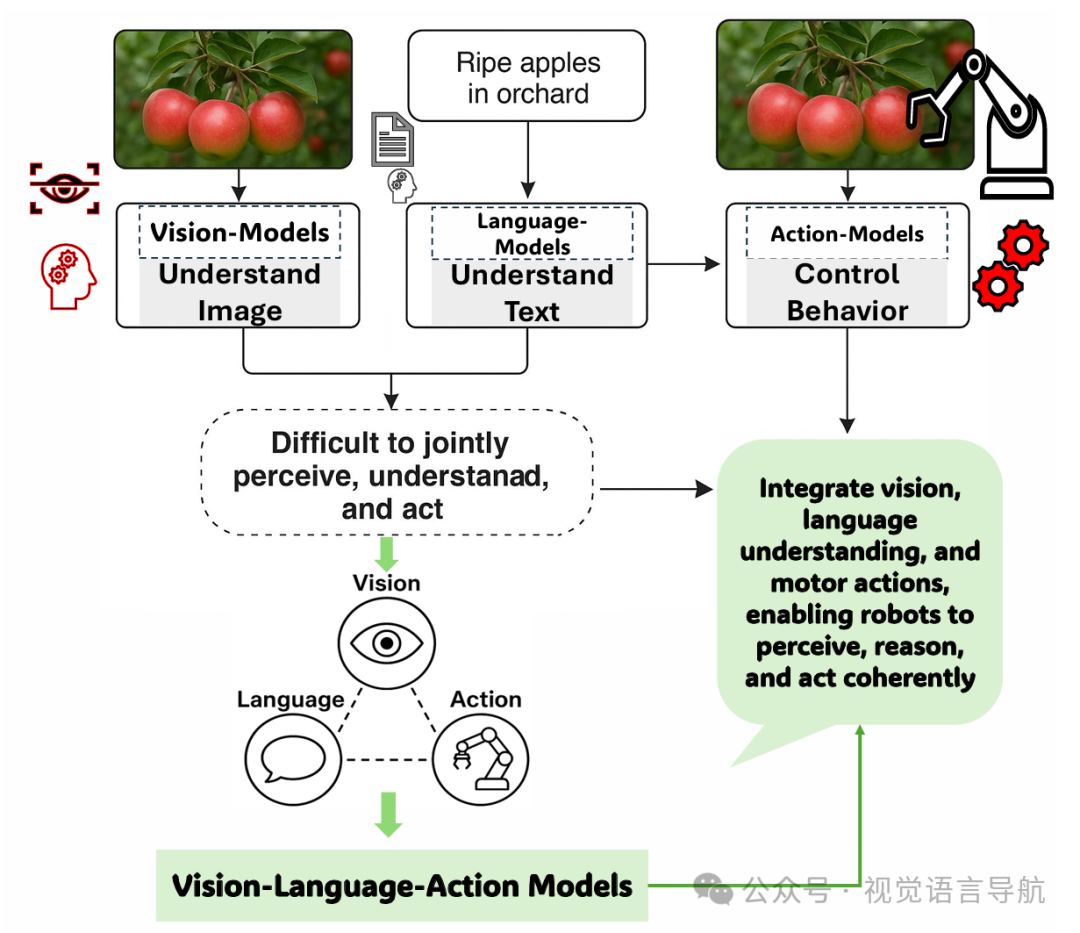
为了克服这些局限性,VLA模型应运而生。这些模型通过整合视觉、语言和动作,使机器人能够像人类一样感知环境、理解指令并执行任务。
VLA模型的出现标志着从孤立的视觉、语言和动作系统向统一的、端到端的框架的重大转变。
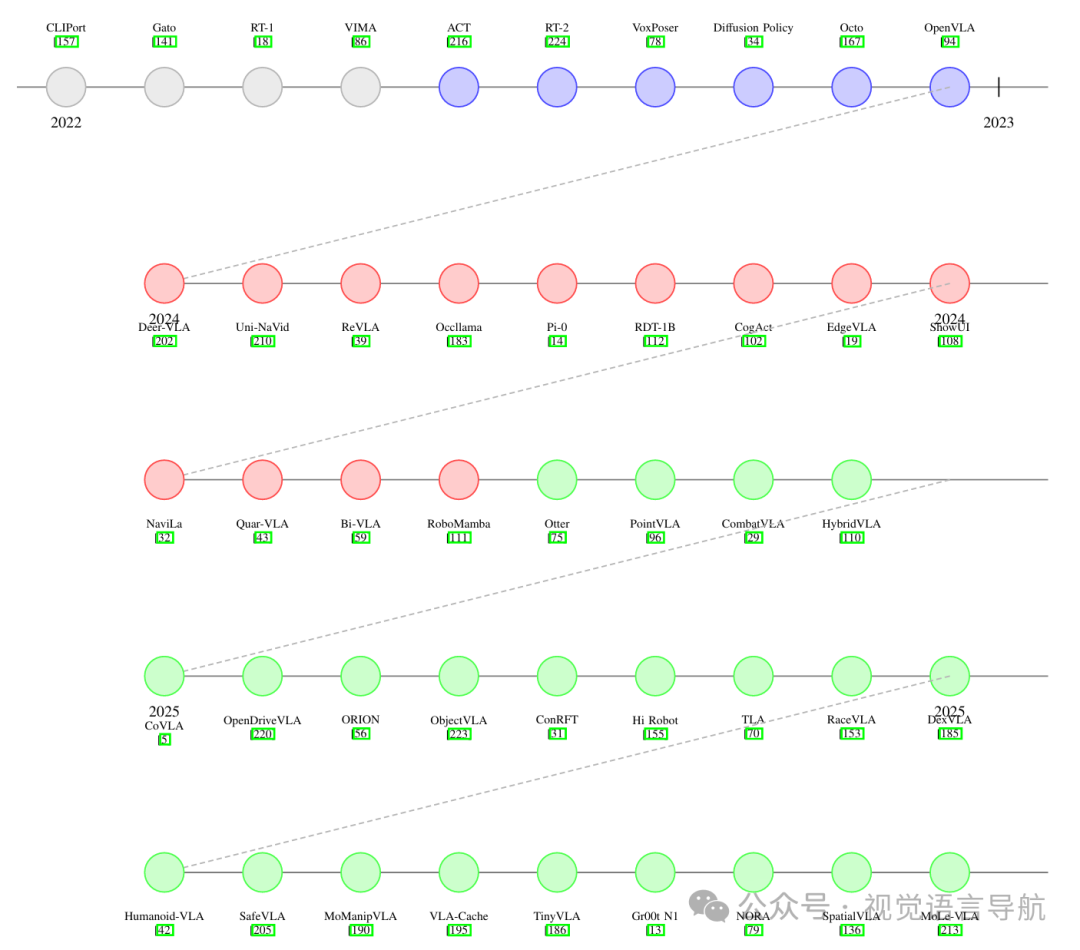
VLA模型的发展历程
早期融合阶段(2022-2023):早期的VLA模型通过多模态融合架构实现了基本的视觉-动作协调。例如,CLIPort通过结合CLIP嵌入和运动原语实现了视觉和语言的初步融合;RT-1通过大规模模仿学习在操纵任务中取得了97%的成功率。这些模型虽然在低级控制方面取得了进展,但在组合推理方面仍存在不足。
专业化与具身推理阶段(2024):第二代VLA模型引入了特定领域的归纳偏差。例如,Deer-VLA通过检索增强训练提高了少样本适应能力;Uni-NaVid通过3D场景图集成优化了导航能力。这些模型在特定领域表现出色,但也需要新的基准测试方法。
泛化与安全关键部署阶段(2025):当前的VLA模型更加注重鲁棒性和人类对齐。例如,SafeVLA通过形式化验证实现了风险感知决策;Humanoid-VLA通过层次化VLA实现了全身控制。这些模型不仅在性能上取得了进步,还在安全性和泛化能力上有了显著提升。
研究目的与贡献
系统性综述:本文旨在通过全面的文献综述,澄清VLA模型的基础概念、架构原则和发展历程,为研究人员和从业者提供一个清晰的框架。
技术进展分析:总结VLA模型在架构创新、训练效率提升和应用拓展方面的关键进展,为未来的研究提供参考。
挑战与解决方案:识别VLA模型在实时推理、多模态动作表示、数据集偏差、系统集成和鲁棒性等方面面临的挑战,并提出针对性的解决方案。
未来研究方向:探讨VLA模型的未来发展方向,包括与VLMs和代理AI的融合,以及如何实现更智能、更适应性强的具身智能体。
研究意义
推动智能机器人技术的发展:VLA模型通过整合视觉、语言和动作,使机器人能够更自然地与人类和环境互动,从而推动了智能机器人技术的发展。
促进跨学科研究:VLA模型的发展涉及计算机视觉、自然语言处理和机器人控制等多个领域,促进了跨学科研究的深入。
提高机器人的泛化能力:通过互联网规模的数据集和多模态融合技术,VLA模型能够更好地泛化到新的任务和环境中,减少了对大量标注数据的依赖。
VLA模型的概念
演变历程和时间线
VLA模型的发展经历了三个阶段:
基础整合 (2022–2023):早期VLA模型通过多模态融合架构建立了基本的视觉运动协调能力。例如,CLIPort结合了CLIP嵌入和运动原语,Gato展示了跨604个任务的通用能力。
专业化与具身推理(2024):第二代VLA模型引入了特定领域的归纳偏差,例如Deer-VLA通过检索增强训练实现了少样本适应,Uni-NaVid通过3D场景图优化了导航能力。
泛化与安全部署(2025):当前系统优先考虑鲁棒性和人类对齐。例如,SafeVLA集成了形式化验证以进行风险感知决策,Humanoid-VLA展示了全身控制能力。
多模态融合:从模块到统一智能体
核心进步:VLA模型能够将视觉、语言和动作联合处理,而不是像传统系统那样将感知、自然语言理解和控制视为离散模块。
多模态融合技术:现代VLA模型使用大型预训练编码器和基于Transformer的架构,通过交叉注意力、嵌入拼接或标记统一等技术将感官观察与文本指令对齐。
具体示例:
CLIPort:使用CLIP嵌入进行语义对齐,并通过卷积解码器实现像素级操作。
VIMA:使用Transformer编码器联合处理以对象为中心的视觉标记和指令标记,支持少样本泛化。
VoxPoser:通过体素级推理解决3D对象选择中的歧义。
编码与表示:VLA如何编码世界
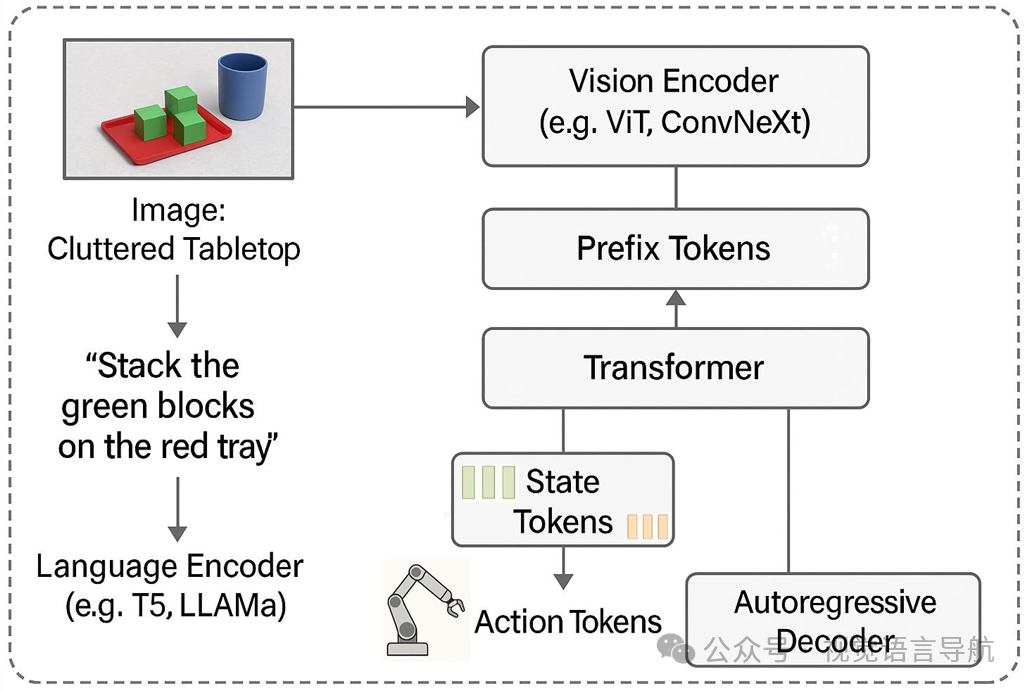
核心创新:VLA模型通过基于标记的表示框架将视觉、语言、状态和动作统一到一个共享的嵌入空间中,支持完整的可学习和组合式推理。
关键组成部分:
前缀标记:编码环境场景和自然语言指令,为模型的内部表示提供上下文。
状态标记:编码机器人当前的配置信息,如关节位置、力矩读数、夹持器状态等,确保情境感知和安全性。
动作标记:自回归生成的标记,代表下一步的运动控制信号,如关节角度更新或轮速。
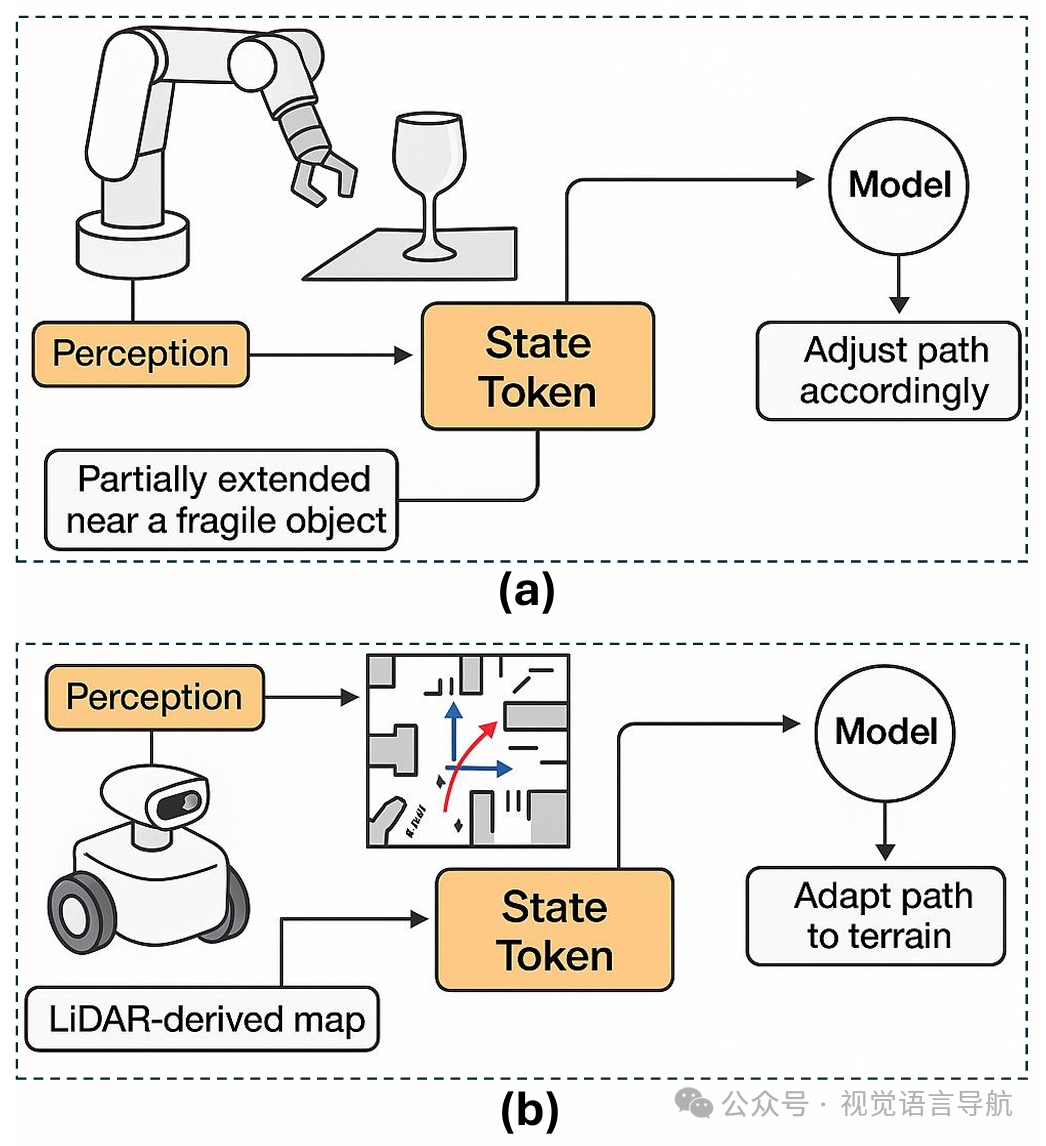
具体示例:
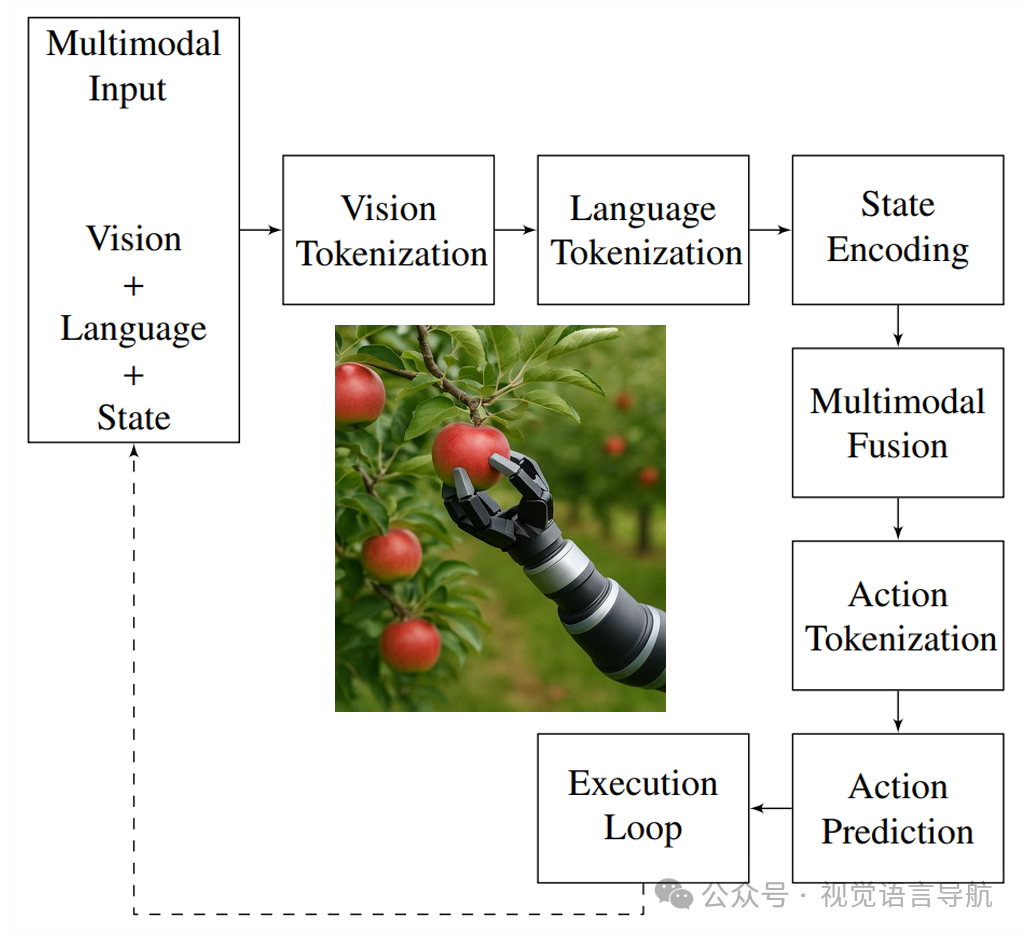
在机器人抓取任务中,视觉输入通过Vision Transformer编码为视觉标记,语言指令通过BERT编码为语言标记,机器人状态通过MLP编码为状态标记。这些标记通过交叉注意力机制融合,最终由Transformer解码器生成动作标记,控制机器人执行任务。
学习范式:数据源和训练策略
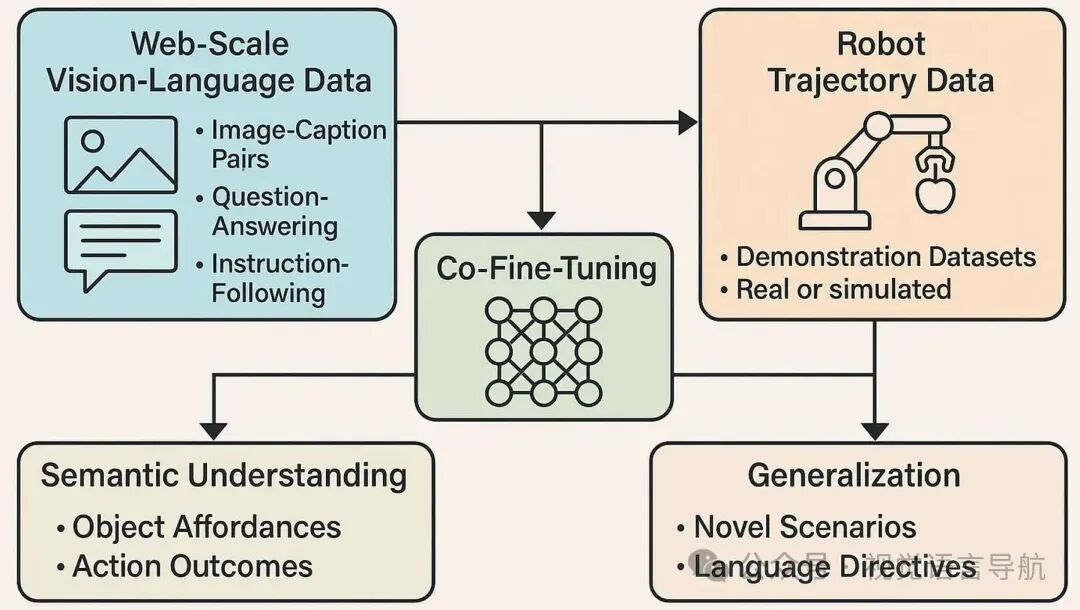
数据来源:
大规模互联网语料库:提供图像-标题对(如COCO)、指令跟随数据集(如HowTo100M)和视觉问答语料库(如VQA),用于预训练视觉和语言编码器,帮助模型获取对象、动作和概念的一般表示。
机器人轨迹数据集:如RoboNet和BridgeData,提供在自然语言指令下的视频-动作对和环境交互数据,用于将语言和感知与动作对齐。
训练策略:
协同微调:在大规模视觉-语言数据集上进行预训练,然后在机器人演示数据上进行微调,对齐语义知识与物理约束。
多任务训练:通过在多个任务上进行训练,提高模型的泛化能力。
领域适应:通过领域适应技术(如OpenVLA)或从模拟到现实的转移学习,弥合合成和真实世界分布之间的差距。
自适应控制和实时执行
实时反馈:VLA模型能够利用传感器的实时反馈动态调整行为,这对于动态、非结构化环境(如果园、家庭或医院)中的任务至关重要。
动态调整:在执行过程中,状态标记会根据传感器输入和关节反馈实时更新,模型可以据此修订计划的动作。例如,在苹果采摘任务中,如果目标苹果发生移动或有其他苹果进入视野,模型可以动态重新解释场景并调整抓取轨迹。
适应性优势:这种能力模拟了人类的适应性,是VLA系统相对于基于流水线的机器人系统的核心优势之一。
VLA模型的进展
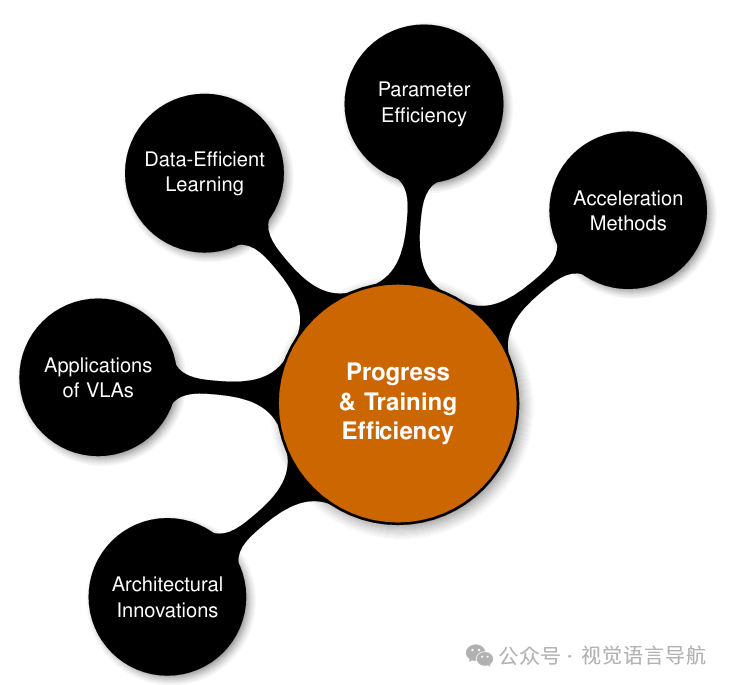
VLA模型的架构创新
早期融合模型:这类模型在输入阶段将视觉和语言表示融合,然后传递给策略模块。例如,EF-VLA模型保留了CLIP预训练期间建立的语义一致性,通过在Transformer主干中早期融合图像-文本对的嵌入,避免了过拟合并增强了泛化能力。
双系统架构:受人类双重认知过程理论的启发,这些模型包含两个互补的子系统:快速反应模块(System 1)和慢速推理规划器(System 2)。例如,NVIDIA的Groot N1模型结合了快速扩散策略(用于低层次控制)和基于LLM的规划器(用于高层次任务分解),提高了在动态环境中的适应性。
自校正框架:这些模型设计用于在没有外部监督的情况下检测并从失败状态中恢复。例如,SC-VLA模型引入了一个包含快速推理路径和慢速校正路径的混合执行循环,当检测到失败时,会调用一个内部LLM来诊断失败模式并生成校正策略。
VLA模型的训练和效率提升
数据高效学习:通过在大规模视觉-语言数据集和机器人轨迹数据集上进行协同微调,对齐语义理解与运动技能。例如,OpenVLA模型通过在LAION-5B数据集上进行预训练,并在Open X-Embodiment数据集上进行微调,实现了比RT-2模型更高的成功率。
参数高效适应:低秩适应(LoRA)通过在冻结的Transformer层中插入轻量级适配器矩阵,减少了可训练权重的数量,同时保留了性能。例如,OpenVLA模型使用LoRA适配器在普通GPU上对7亿参数的主干网络进行了微调,减少了70%的GPU计算量。
推理加速:通过压缩动作标记(FAST)和并行解码等技术,显著提高了模型的推理速度。例如,Pi-0 Fast模型通过将动作窗口标记化为离散标记,实现了15倍的推理加速,能够在桌面GPU上以200 Hz的频率执行策略。
VLA模型的参数高效和加速
低秩适应(LoRA):通过在冻结的Transformer层中插入低秩分解矩阵,仅使用几百万个额外权重即可对数十亿参数的VLA模型进行微调。
量化(Quantization):将权重精度降低到8位整数(INT8),可以将模型大小减半,并将芯片上的吞吐量提高一倍。
模型剪枝(Model Pruning):通过移除冗余的注意力头或前馈子层来减少模型大小。
压缩动作标记化(FAST):将连续的动作输出重新表述为频率域标记,将长控制序列压缩为简洁的描述符。
并行解码和动作块化(Parallel Decoding and Action Chunking):通过并行解码多个空间-时间标记,减少了端到端的延迟。
强化学习-监督混合训练(Reinforcement Learning–Supervised Hybrid Training):结合强化学习和监督学习,通过在模拟环境中进行强化学习和在人类演示数据上进行微调,稳定策略更新。
硬件感知优化(Hardware-Aware Optimizations):利用目标硬件特性(如张量核心、融合注意力和流水线内存传输)加速Transformer推理和扩散采样。
VLA模型的应用
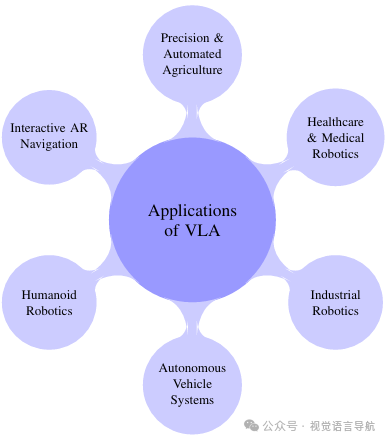
人形机器人(Humanoid Robotics):VLA模型使人形机器人能够理解自然语言指令并执行复杂的物理任务。例如,Helix模型能够实时控制全身运动,执行诸如抓取物体等任务。
自动驾驶车辆(Autonomous Vehicle Systems):VLA模型能够处理动态视觉流和自然语言指令,做出透明、适应性强的驾驶决策。例如,OpenDriveVLA和ORION模型通过将视觉和语言输入与动作对齐,实现了端到端的自动驾驶。
工业机器人(Industrial Robotics):VLA模型通过将视觉输入、自然语言指令和机器人状态融合,实现了高精度的装配、检查和协作制造。
医疗和医疗机器人(Healthcare and Medical Robotics):VLA模型能够理解自然语言指令并执行精确的手术操作。例如,RoboNurse-VLA模型能够协助外科医生进行手术工具的传递。
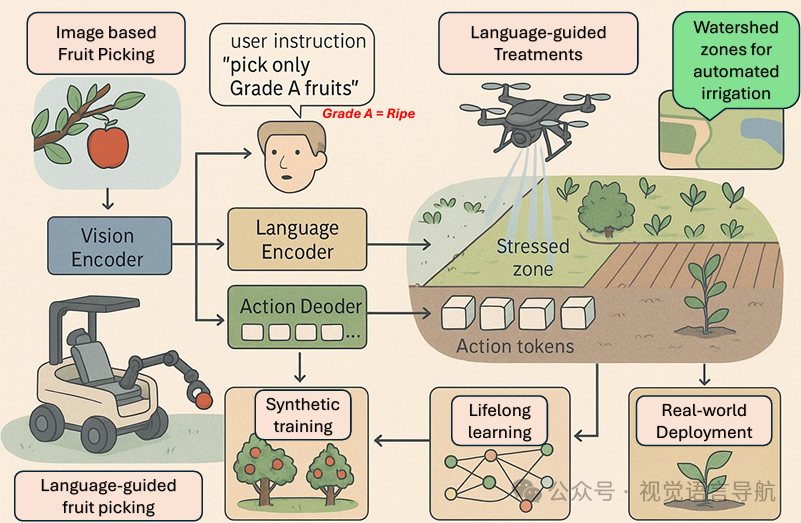
精准和自动化农业(Precision and Automated Agriculture):VLA模型能够指导机器人进行水果采摘、植物监测和异常检测,减少对人工劳动的依赖,提高可持续性。
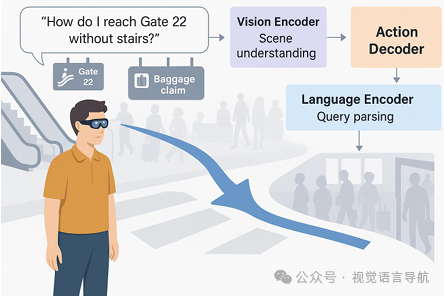
交互式增强现实导航(Interactive AR Navigation):VLA模型能够根据用户的自然语言指令和视觉场景生成动态导航提示,支持室内和室外的实时导航。
VLA模型的挑战与局限性
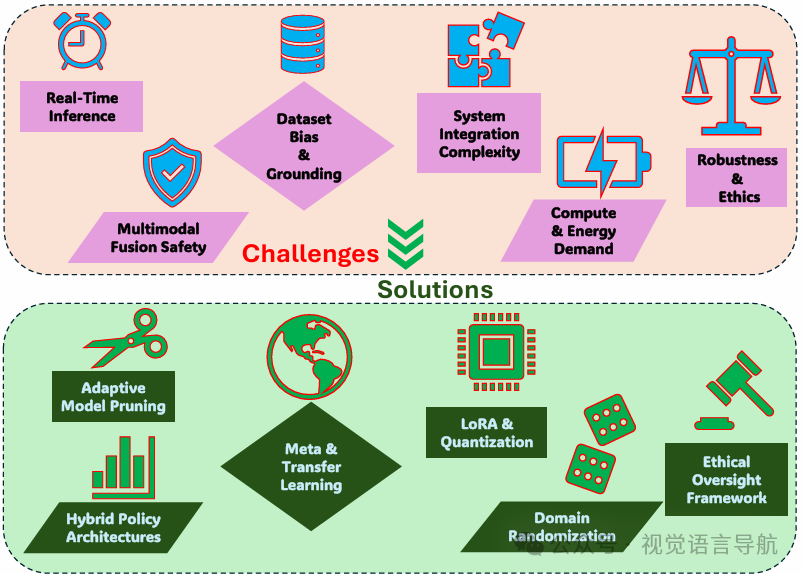
实时推理约束
挑战:VLA模型通常依赖于自回归解码策略,这限制了推理速度,通常只能达到3-5 Hz,远低于机器人系统所需的100 Hz或更高的频率。
解决方案:
并行解码:通过同时预测多个标记来加速推理,例如NVIDIA的Groot N1模型实现了约2.5倍的速度提升。
硬件加速:利用FPGA和张量核心等专用硬件加速器,执行卷积和Transformer层。
模型压缩:通过Low-Rank Adaptation (LoRA)和知识蒸馏减少参数数量,降低内存占用和推理时间。
动态词汇分配:通过子词补丁嵌入和动态词汇分配压缩视觉和语言输入,减少标记数量。
多模态动作表示与安全性保障
挑战:
多模态动作表示:传统的离散标记化方法缺乏精度,导致在精细任务中出现较大误差。连续的多层感知机(MLP)方法则面临模式坍塌的风险。
安全性保障:当前的VLA模型在动态、不可预测的环境中难以确保安全性,碰撞预测的准确率仅为82%,且紧急停止机制存在200-500毫秒的延迟。
解决方案:
混合策略架构:结合扩散采样用于低层次运动原语和自回归高层次规划器,以紧凑的随机表示捕获多样化的动作轨迹。
实时风险评估:通过多传感器融合流(视觉、深度、本体感知数据)预测碰撞概率和关节应力阈值,触发紧急停止电路。
强化学习与约束优化:通过强化学习算法和约束优化(如Lagrangian方法)学习在严格遵守安全约束的同时最大化任务成功率的策略。
数据集偏差、对齐和泛化
挑战:
数据集偏差:当前训练数据集存在固有偏差,导致模型在多样化的环境中产生语义不一致或上下文不适当的响应。
语义对齐:VLA模型在遇到罕见或不寻常的组合时会失败,例如“黄色马”。
泛化能力:VLA模型在熟悉环境或类似训练场景中表现出色,但在遇到全新的任务或不熟悉的变体时性能显著下降。
解决方案:
多样化数据集:结合大规模的图像-文本语料库(如LAION-5B)和机器人中心的轨迹档案(如Open X-Embodiment),以实现公平的语义对齐。
对比学习:通过对比学习对视觉-语言模型进行微调,减少错误关联并增强语义保真度。
元学习和持续学习:通过元学习框架快速适应新任务,并通过持续学习算法保留旧知识,同时整合新概念。
系统集成复杂性和计算需求
挑战:
时间不匹配:高层次认知规划(System 2)和实时物理控制(System 1)之间存在时间不匹配,导致同步困难。
特征空间不匹配:高维视觉编码器和低维动作解码器之间的特征空间不匹配,导致感知理解和可行动作之间的连贯性下降。
计算需求:VLA模型的参数量大,对计算资源的需求高,限制了在边缘计算环境中的部署。
解决方案:
模型模块化:通过注入LoRA适配器,实现任务特定的微调,而不修改核心权重。
知识蒸馏:将大型“教师”VLA的知识蒸馏到轻量级“学生”网络中,减少参数数量,同时保留任务性能。
混合精度量化:通过量化感知训练将权重压缩到4-8位,减少内存带宽和能耗。
VLA部署中的鲁棒性和伦理挑战
挑战:
环境鲁棒性:VLA模型在动态变化的环境中(如光照、天气条件或部分遮挡)的性能会显著下降。
伦理问题:VLA模型的部署需要考虑隐私保护、数据偏见缓解和社会影响。
解决方案:
领域随机化和合成增强:通过生成光照、遮挡和传感器噪声的逼真变化,增强模型对环境变化的鲁棒性。
隐私保护:通过设备端处理、同态加密和差分隐私保护用户数据。
伦理监督框架:建立监管框架和行业标准,确保VLA系统的安全性和问责性。
讨论
潜在解决方案
在讨论部分,论文提出了针对前面提到的挑战的潜在解决方案,并探讨了这些解决方案的预期影响。
实时推理约束:通过采用并行解码、量化Transformer和硬件加速(例如TensorRT)来减少自回归解码的开销,从而支持实时机器人控制,并在时间敏感的领域(例如无人机、操纵器)中实现更广泛的部署。
多模态动作表示:使用混合标记化方法(结合扩散和自回归策略)以及在多样化演示和多模态输出上进行训练,可以改善对复杂、动态操作任务的处理能力,这些任务可能有多种有效的解决方案。
安全性保障:通过集成动态风险评估模块、低延迟紧急停止电路和自适应规划层,确保在不可预测的环境中(如家庭、工厂、医疗保健环境)的可靠性和安全性。
数据集偏差和语义对齐:通过策划多样化、无偏见的数据集,并应用改进的语义对齐技术(例如使用硬负样本进行CLIP微调),增强模型的公平性、语义保真度和对新现实世界输入的泛化能力。
系统集成复杂性:开发统一的Transformer主干网络,并纳入时间对齐层和从模拟到现实的转移学习策略,实现规划和控制之间的无缝协调,并使模型能够更稳健地转移到物理机器人上。
计算和能源需求:通过应用模型剪枝、LoRA适配器、量化感知训练,并在低功耗加速器上进行部署,促进VLA在嵌入式和移动平台中的可扩展和高效部署。
泛化到未见任务:使用组合泛化、少样本元学习和任务不可知的预训练管道,减少任务特定的过拟合,实现稳健的零样本和少样本适应。
环境变化的鲁棒性:通过使用领域随机化、传感器融合和实时校准感知-动作管道,增强在变化或杂乱环境中(如家庭、工厂、医疗保健环境)的性能,同时尽量减少性能下降。
伦理和社会影响:通过在设备端处理和匿名化来强制执行隐私保护,审计模型公平性,并建立监管框架以建立信任,促进VLA在社会、医疗和劳动领域的公平和可信部署。
未来路线图
多模态基础模型作为“皮层”:未来的VLA模型将依赖于一个单一的、大规模的多模态基础模型,该模型在网页规模的图像、视频、文本和操作数据上进行训练,作为共享的感知和概念“皮层”。
代理式自我监督终身学习:未来的VLA模型将通过与环境的持续、自我监督的交互来学习,代理框架将推动快速技能获取。
层次化神经符号规划:为了从低层次的运动原语扩展到高层次的推理,VLA模型将采用层次化控制架构。
实时适应通过世界模型:未来的VLA模型将维护一个内部的预测世界模型,该模型是一个关于物体、接触和代理动态的最新模拟。
跨形态和转移学习:未来的VLA模型将能够在不同的机器人形态之间无缝转移技能。
安全性、伦理性和人类中心的对齐:随着VLA模型获得更大的自主性,内置的安全性和价值对齐变得不可或缺。
结论与未来工作
结论:
VLA模型通过整合视觉、语言和动作,显著提升了机器人的感知、理解和执行能力。
尽管在实时性、多模态动作表示、数据集偏差和系统集成等方面仍面临挑战,但通过数据高效学习、参数高效方法和加速技术,VLA模型的可扩展性和实时性得到了显著提升。
未来工作:
未来的研究方向包括进一步提高VLA模型的实时推理能力、改进多模态动作表示和安全保证、解决数据集偏差和系统集成复杂性问题,以及探索VLA模型在更多领域的应用。
此外,还需要在模型的鲁棒性和伦理部署方面进行更多的研究,以确保VLA模型在现实世界中的可靠性和安全性。
