深度学习(十):逻辑回归的代价函数
逻辑回归(Logistic Regression)是机器学习中最基础也是最经典的分类算法之一,它在深度学习的早期发展中扮演了重要角色,并且至今仍然是许多神经网络模型(特别是二分类问题)最后一层的核心组成部分。
逻辑回归:从线性模型到概率分类
逻辑回归虽然名字里带有“回归”二字,但它本质上是一种分类算法,专门用于处理二分类问题(例如:判断邮件是否为垃圾邮件、图片中是否包含猫)。
它在数学上的核心思想是:首先,像线性回归一样,通过一个线性方程对输入特征进行加权求和:
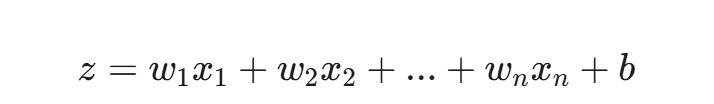
其中,z 是一个线性分数,w 是权重,x 是输入特征,b 是偏置项。
然后,它将这个线性结果 z 映射到 0 到 1 之间的一个概率值,这通过一个特殊的非线性激活函数——Sigmoid 函数来实现:
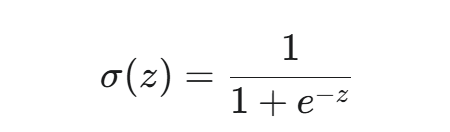
Sigmoid 函数将任意实数 z 压缩到 (0,1) 区间内。这个输出 σ(z) 可以被解释为样本属于正类别(例如:类别 1)的预测概率。
代价函数:衡量模型预测的好坏
在任何机器学习模型中,我们都需要一个**代价函数(Cost Function)或损失函数(Loss Function)**来量化模型预测的“好坏”。这个函数值越小,代表模型的预测越接近真实标签,模型表现越好。训练模型的过程,就是通过优化算法(如梯度下降)来不断调整权重 w 和偏置 b,以最小化这个代价函数。
对于逻辑回归,我们不能使用像线性回归中那样的均方误差(MSE),因为 Sigmoid 函数的非线性特性会导致 MSE 变得非凸(Non-Convex),拥有多个局部最小值,使得梯度下降难以找到全局最优解。
为了解决这个问题,逻辑回归引入了**交叉熵(Cross-Entropy)**作为其代价函数。
交叉熵损失:从信息论到分类损失
交叉熵源于信息论,用于衡量两个概率分布之间的差异。在逻辑回归中,它被巧妙地用来衡量模型的预测概率分布(y^)与真实的标签分布(y)之间的差异。
对于单个样本,逻辑回归的交叉熵损失函数定义如下:
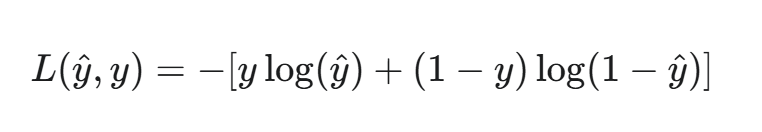
其中:
- y 是样本的真实标签,对于二分类问题,y 的值是 0 或 1。
- y^ 是模型的预测概率,即 y^=σ(z)。
这个公式看起来复杂,但我们可以分情况来理解:
- 当真实标签 y=1 时: 损失函数变为 L=−log(y^)。 如果模型预测概率 y^ 接近 1(预测正确),则 log(y^) 接近 0,损失 L 接近 0。 如果模型预测概率 y^ 接近 0(预测错误),则 log(y^) 接近 −∞,损失 L 接近 +∞。
- 当真实标签 y=0 时: 损失函数变为 L=−log(1−y^)。 如果模型预测概率 y^ 接近 0(预测正确),则 1−y^ 接近 1,损失 L 接近 0。 如果模型预测概率 y^ 接近 1(预测错误),则 1−y^ 接近 0,损失 L 接近 +∞。
可以看出,交叉熵损失函数完美地惩罚了错误的、高置信度的预测。如果模型对错误的类别给出了很高的预测概率,损失就会变得非常大,从而在梯度下降过程中产生巨大的梯度,促使模型快速修正其参数。
整个训练集上的总代价函数是所有样本损失的平均值:
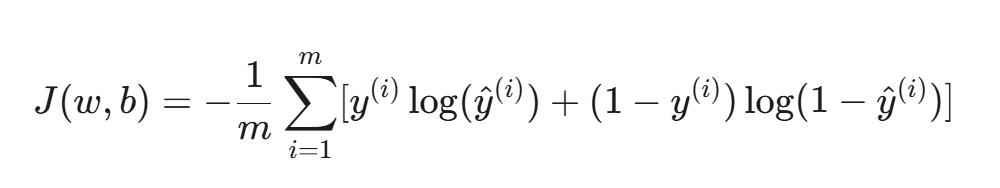
其中 m 是样本总数。
交叉熵损失的优点与在深度学习中的应用
交叉熵损失函数之所以成为分类问题中的首选,是因为它具备以下关键优点:
- 凸性(Convexity):对于逻辑回归模型,交叉熵损失函数是凸函数,这意味着它只有一个全局最小值,没有任何局部最小值。这确保了梯度下降等优化算法可以稳定地收敛到全局最优解,而不是卡在某个局部最优解中。
- 梯度特性:交叉熵的梯度非常平滑,尤其是在误差很大的时候,梯度也很大,这加速了训练过程。当误差很小时,梯度也随之减小,有助于模型平稳收敛。