数据结构(陈越,何钦铭) 第十一讲 散列查找
11.1 散列表
11.1.1 引子:散列的基本思路
编译处理时,涉及变量及属性(如:变量类型)的管理:
- 插入:新变量定义
- 查找:变量的引用



11.1.2 什么是散列表


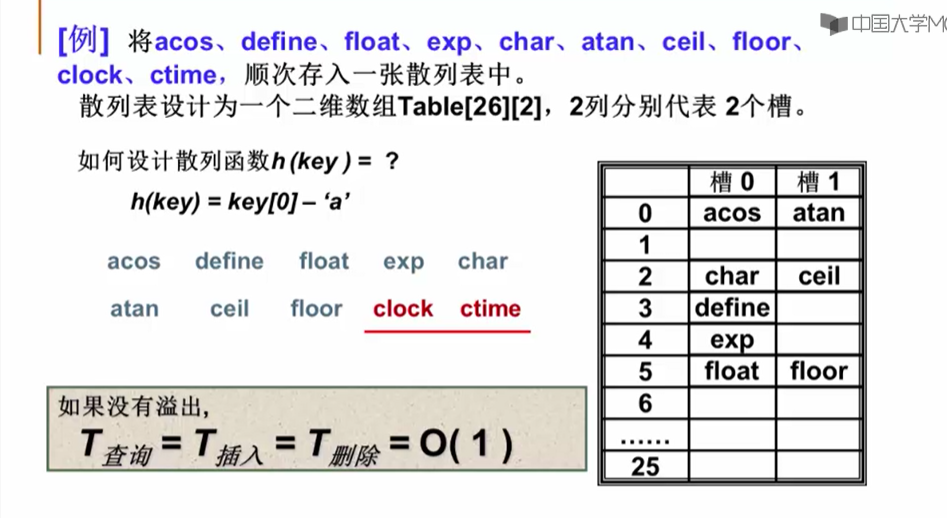

11.2 散列函数的构造方式
11.2.1 数字关键词的散列函数构造
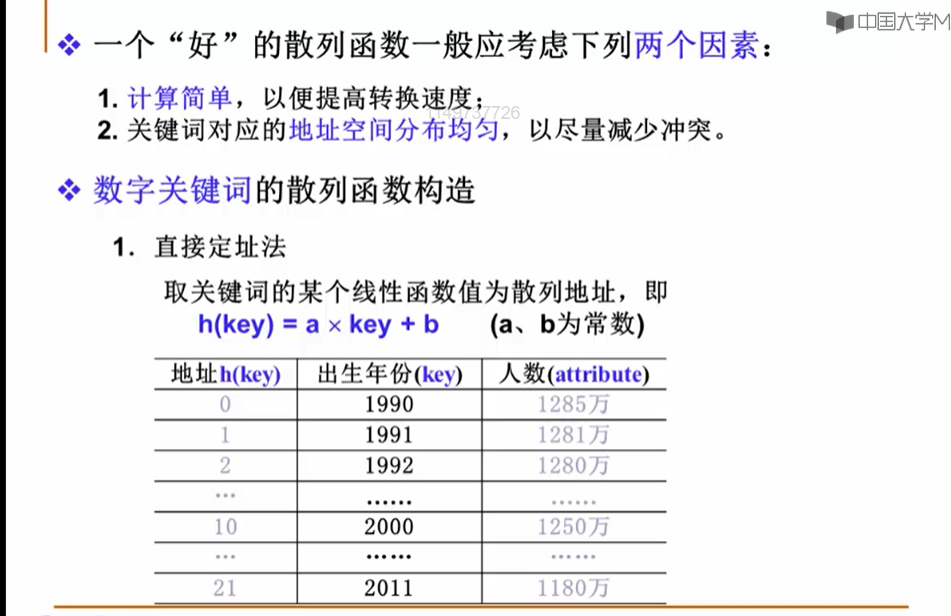
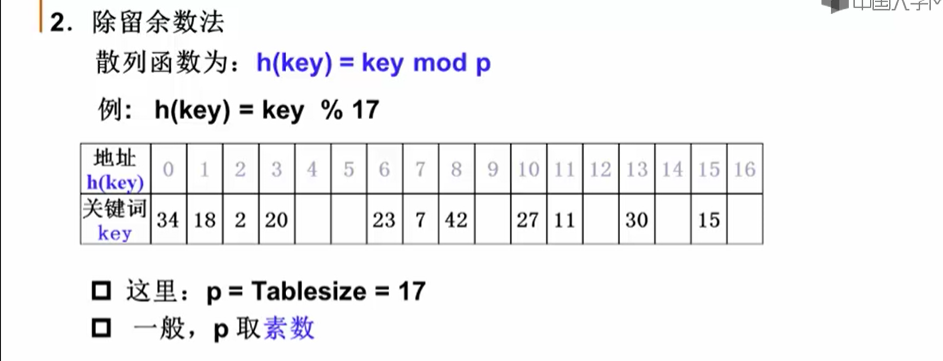
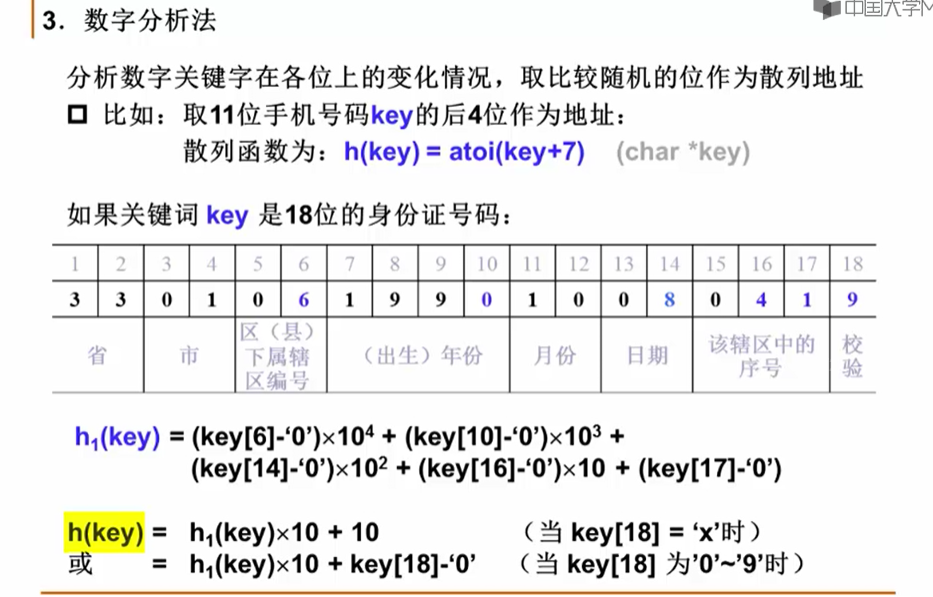

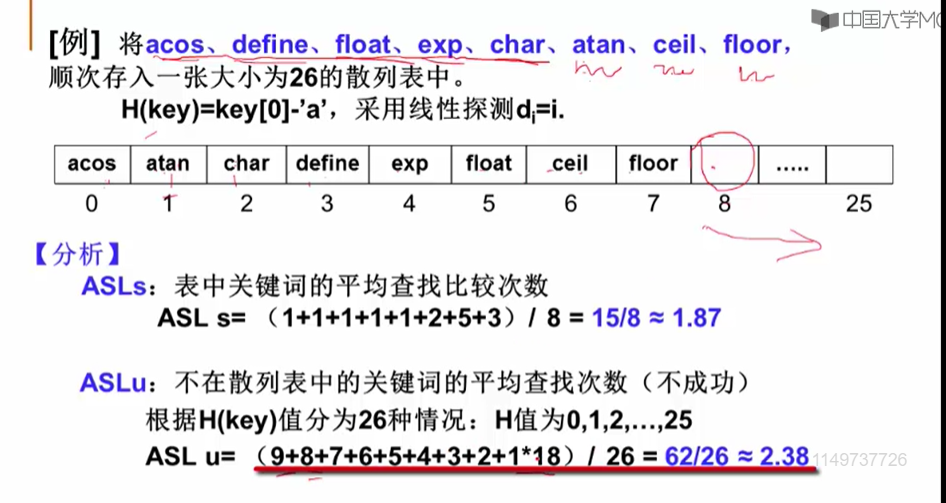
11.2.2 字符串关键词的散列函数构造


11.3 冲突处理方法
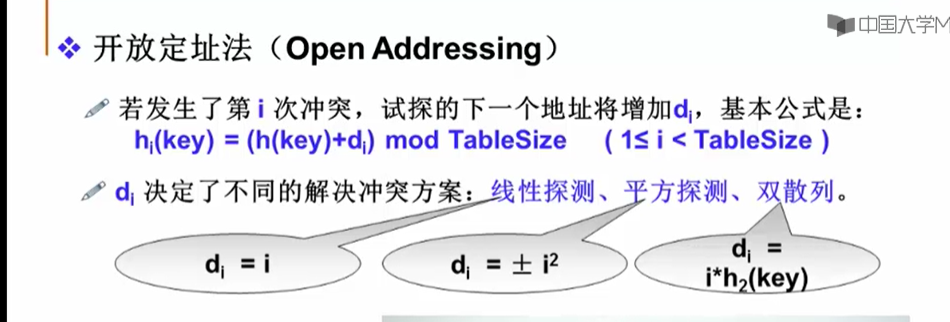
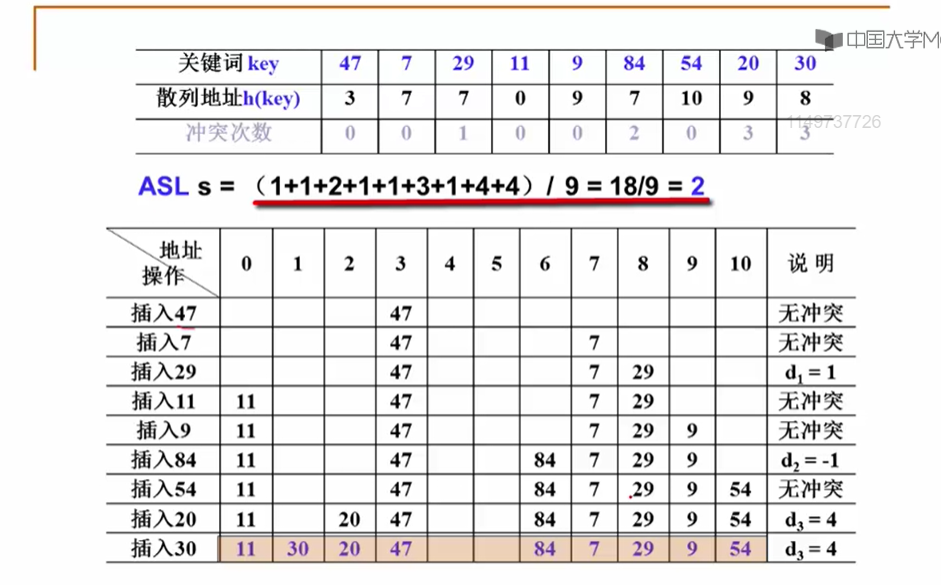
11.3.1 开放定址法

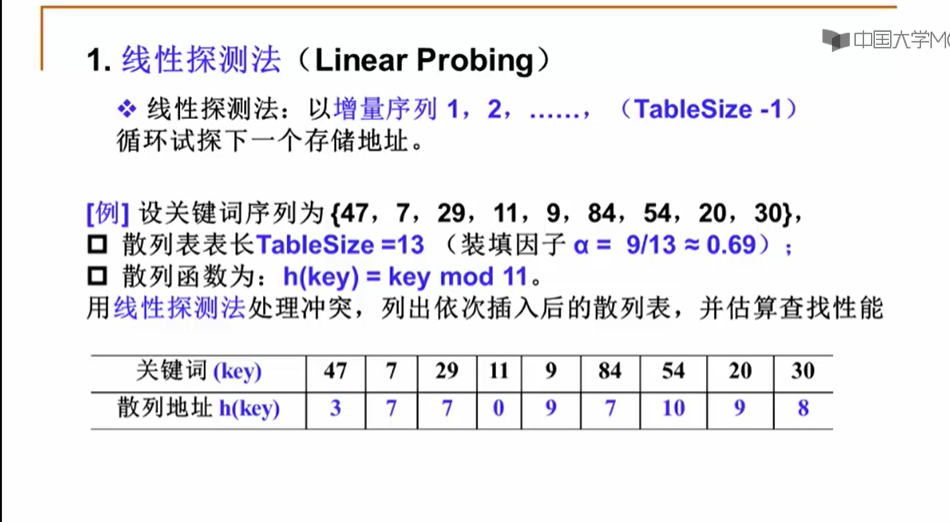
11.3.2 线性探测
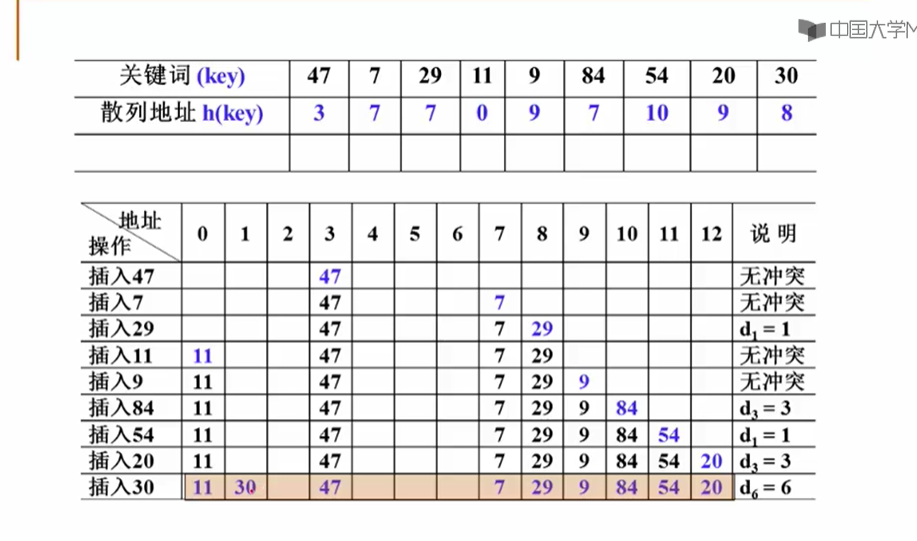
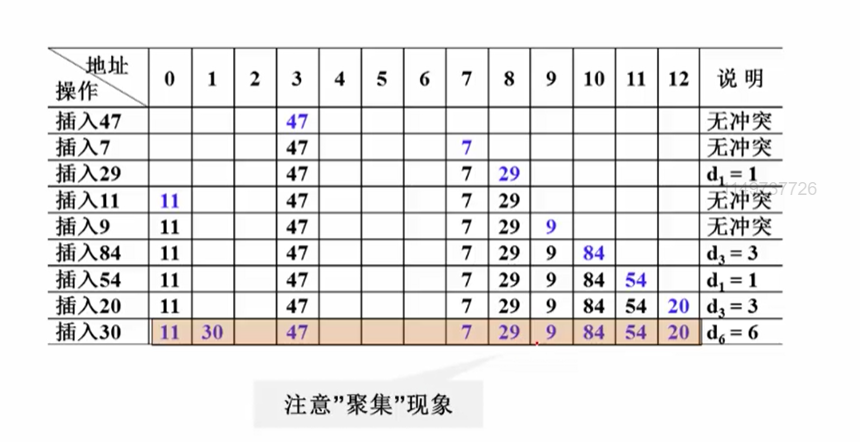
11.3.3 线性探测-字符串的例子
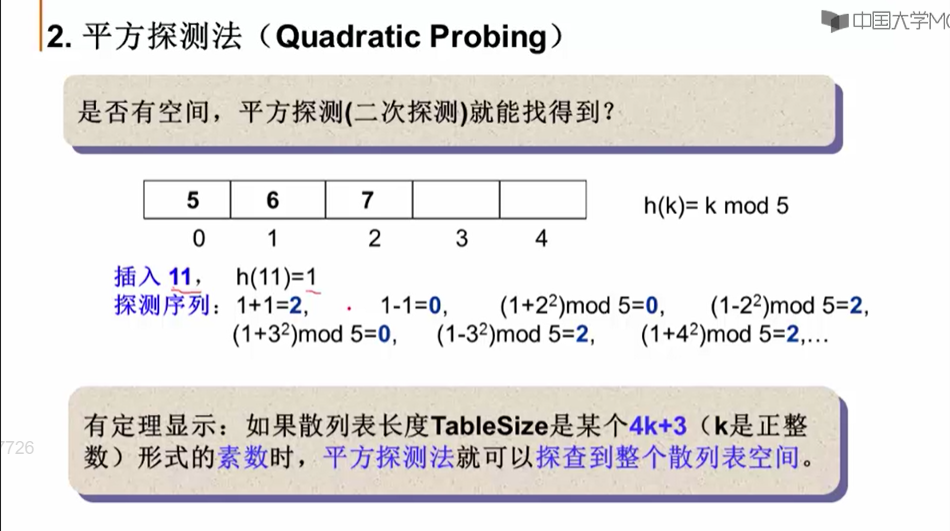
11.3.4 平方探测法

11.3.5 平方探测法的实现
#define MAXTABLESIZE 100000
typedef int ElementType;
typedef int Index;
typedef Index Position;
typedef enum {Legitimate,Empty,Deleted} EntryType;typedef struct HashEntry Cell;
struct HashEntry{ElementType Data;EntryType Info;
};typedef struct TblNode *HashTable;
struct TblNode{int TableSize;Cell *Cells;
};int NextPrime(int N){int i,p=(N%2)?N+2:N+1;while(p<=MAXTABLESIZE){for(i=(int)sqrt(p);i>2;i--){if(!(p%i)){break;}}if(i==2){break;}else{p+=2;}}return p;
}HashTable CreateTable(int TableSize){HashTable H;int i;H=(HashTable)malloc(sizeof(struct TblNode));H->TableSize=NextPrime(TableSize);H->Cells=(Cell*)malloc(H->TableSize*sizeof(Cell));for(i=0;i<H->TableSize;i++){H->Cells[i].Info=Empty;}return H;
}Position Find(HashTable H,ElementType Key){Position CurrentPos,NewPos;int CNum=0;NewPos=Current=Hash(Key,H->TableSize);while(H->Cells[NewPos].Info!=Empty&&H->Cells[NewPos]!=Key){if(++CNum%2){NewPos=CurrentPos+(CNum+1)*(CNum+1)/4;if(NewPos>=H->TableSize){NewPos=NewPos%H->TableSize;}}else{NewPis=CurrentPos-CNum*CNum/4;while(NewPos<0){NewPos+=H->TableSize;}}}return NewPos;
}bool Insert(HashTable H,ElementType Key){Position Pos=Find(H,Key);if(H->Cells[Pos].Info!=Legitimate){H->Cells[Pos].Info=Legitimate;H->Cells[Pos].Data=Key;return true;}else{printf("键值已存在");return false;}
}
11.3.6 分离链接法
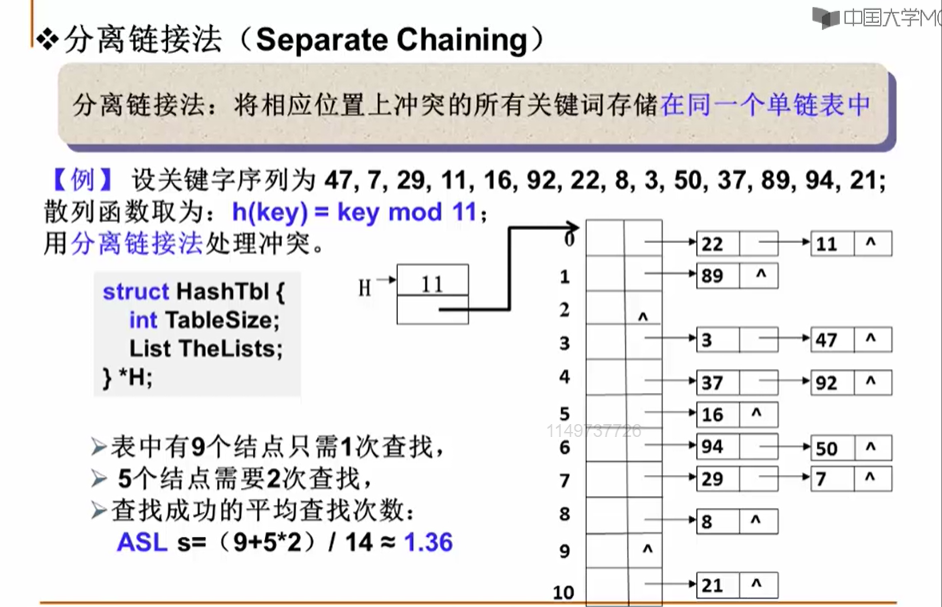
#define KEYLENGTH 15
typedef char ElementType[KEYLENGTH+1];
typedef int Index;typedef struct LNode *PtrToLNode;
struct LNode{ElementType Data;PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;typedef struct TblNode *HashTable;
struct TblNode{int TableSize;List Heads;
};HashTable CreateTable(int TableSize){HashTable H;int i;H=(HashTable)malloc(sizeof(struct TblNode));H->TableSize=NextPrime(TableSize);H->Heads=(List)malloc(H->TableSize*sizeof(struct LNode));for(i=0;i<H->TableSize;i++){H->Heads[i].Data[0]='\0';H->Heads[i].Next=NULL;}return H;
}Position Find(HashTable H,ElementType Key){Position P;Index Pos;Pos=Hash(Key,H->TableSize);P=H->Heads[Pos].Next;while(P&&strcmp(P->Data,Key)){P=P->Next;}return P;
}bool Insert(HashTable H,ElementType Key){Position P,NewCell;Index Pos;P=Find(H,Key);if(!P){NewCell=(Position)malloc(sizeof(struct LNode));strcpy(NewCell->Data,Key);Pos=Hash(Key,H->TableSize);NewCell->Next=H->Heads[Pos].Next;H->Heads[Pos].Next=NewCell;return true;}else{printf("键值已存在");return false;}
}void DestoryTable(HashTable H){int i;Position P,tmp;for(i=0;i<H->TableSize;i++){P=H->Heads[i].Next;while(P){tmp=P->Next;free(P);P=tmp;}}free(H->Heads);free(H);
}
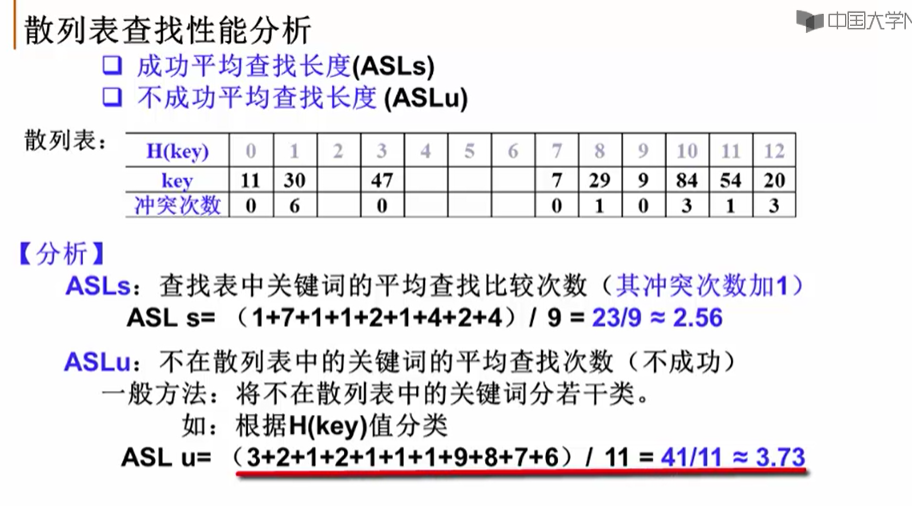
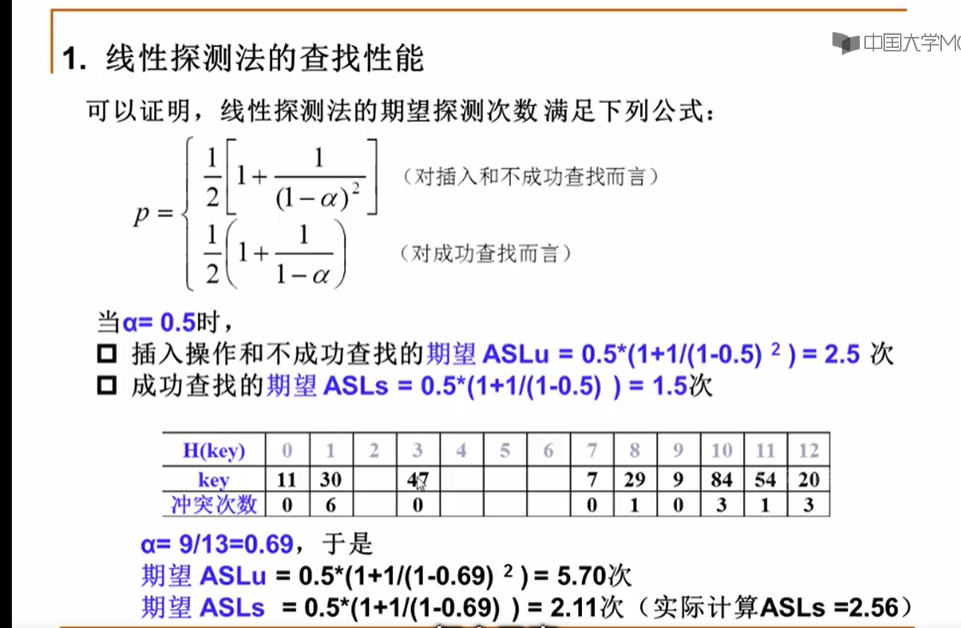
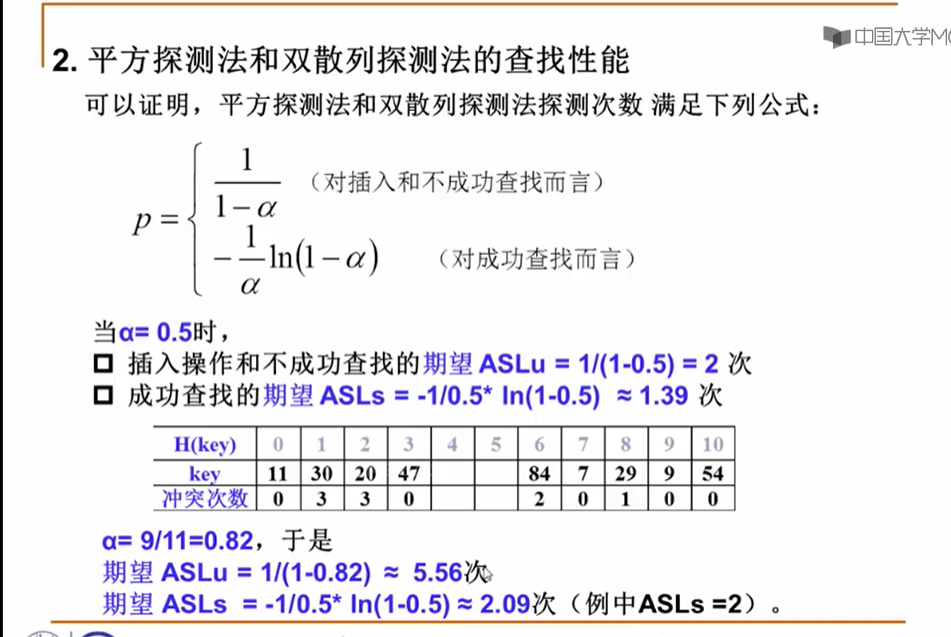
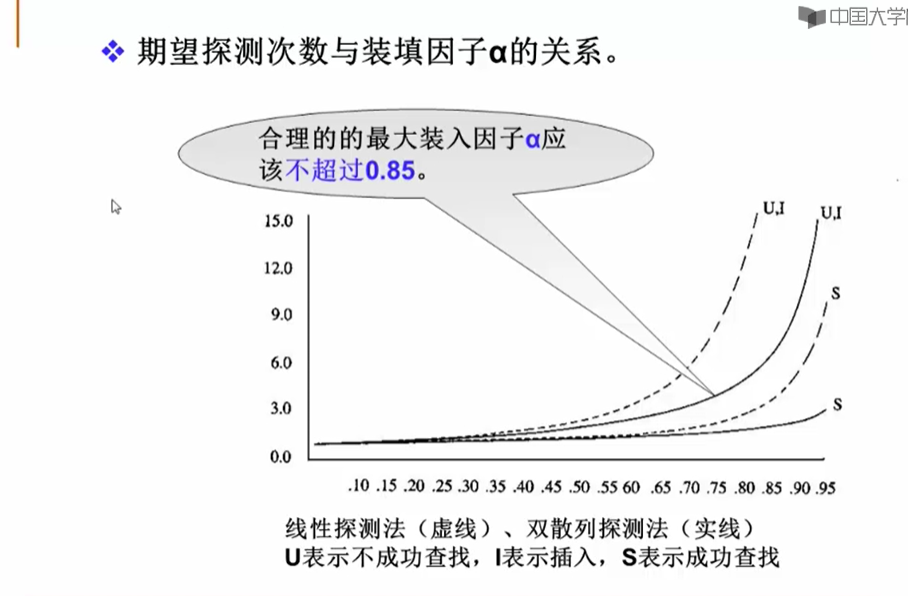
11.4 散列表的性能分析





11.5 应用实例:词频统计

int main(){int TableSize=10000;int wordcount=0,length;HashTable H;ElementType word;FILE *fp;char document[30]="HarryPottr.txt";H=initializeTable(TableSize);if((fp=fopen(document,"r"))==NULL){FatalError("无法打开文件!\n");}while(!feof(fp)){length=GetAWord(fp,word);if(length>3){wordcount++;InsertAndCount(word,H);}}fclose(fp);printf("该文档共出现%d个有效单词,",wordcount);Show(H,10.0/100);DestoryTable(H);return 0;
}