通义万相开源 Wan2.2-S2V-14B,实现图片+音频生成电影级数字人视频
Wan2.2-S2V-14B 是由阿里巴巴通义万相团队于 2025 年 8 月开源的一款音频驱动的视频生成模型。Wan2.2-S2V-14B 仅需一张静态图片和一段音频,能生成电影级数字人视频,视频时长可达分钟级,支持多种图片类型和画幅。用户通过输入文本提示,可对视频画面进行控制,让画面更丰富。模型融合多种创新技术,实现复杂场景的音频驱动视频生成,支持长视频生成及多分辨率训练与推理。模型在数字人直播、影视制作、AI 教育等领域有广泛应用。
教程链接:https://go.openbayes.com/s3GyT
使用云平台:OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
登录 http://OpenBayes.com,在「公共教程」页面,选择一键部署 「Wan2.2-S2V-14B:影视级音频驱动视频生成」教程。
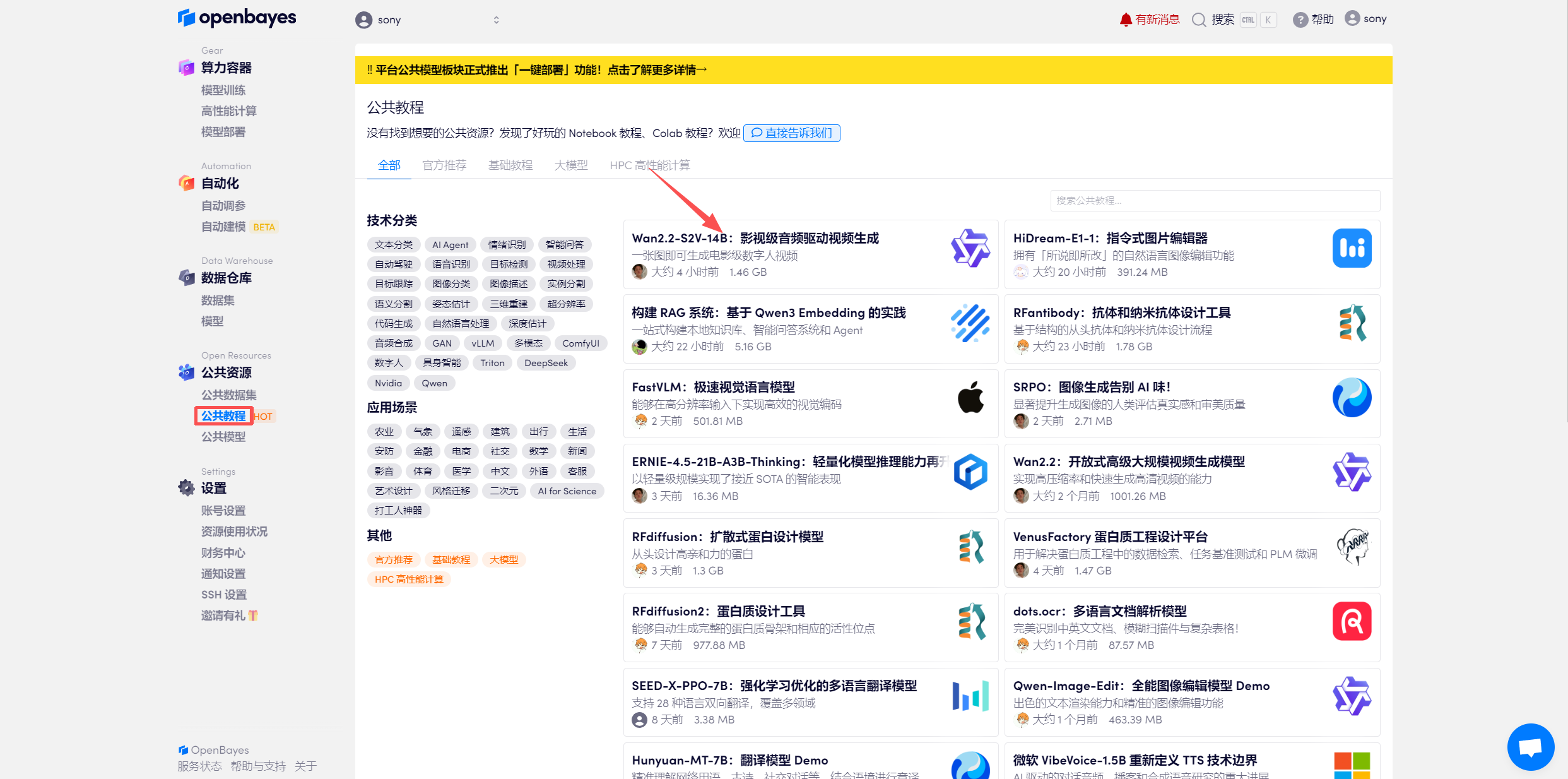
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
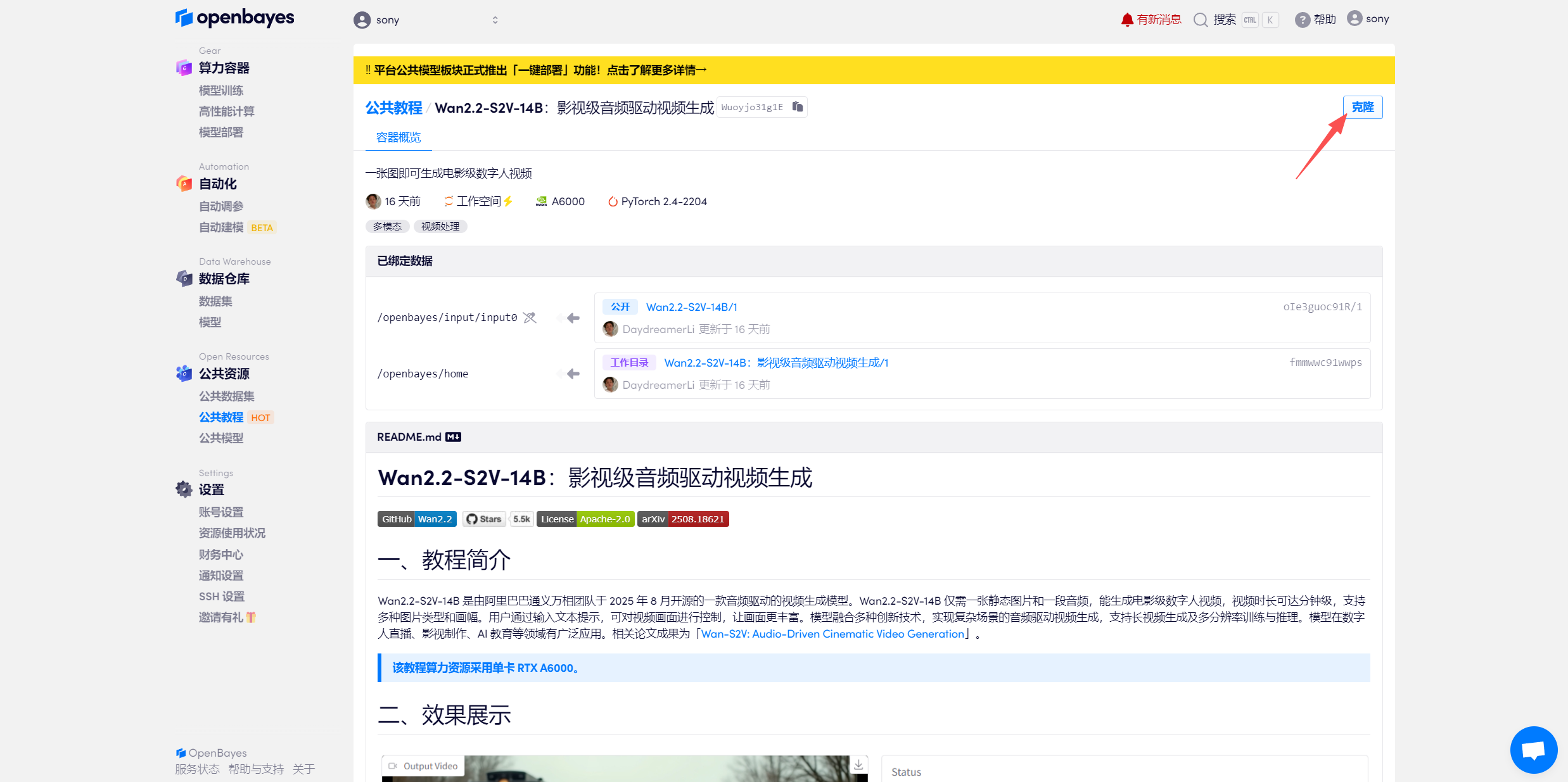
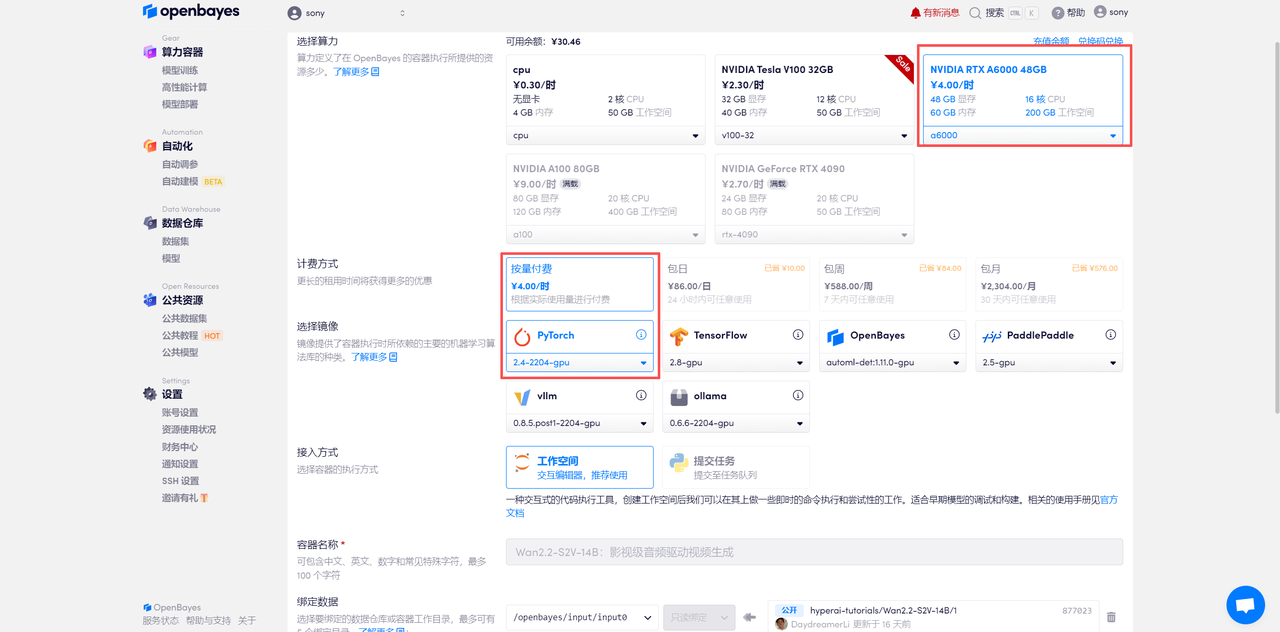
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
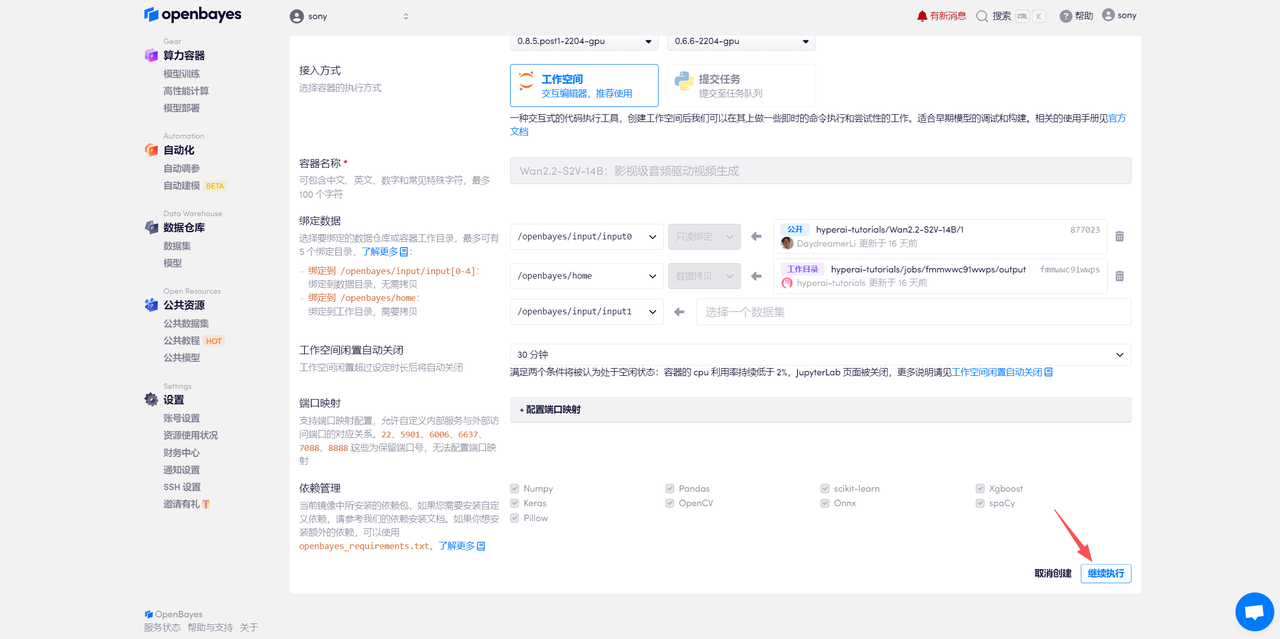
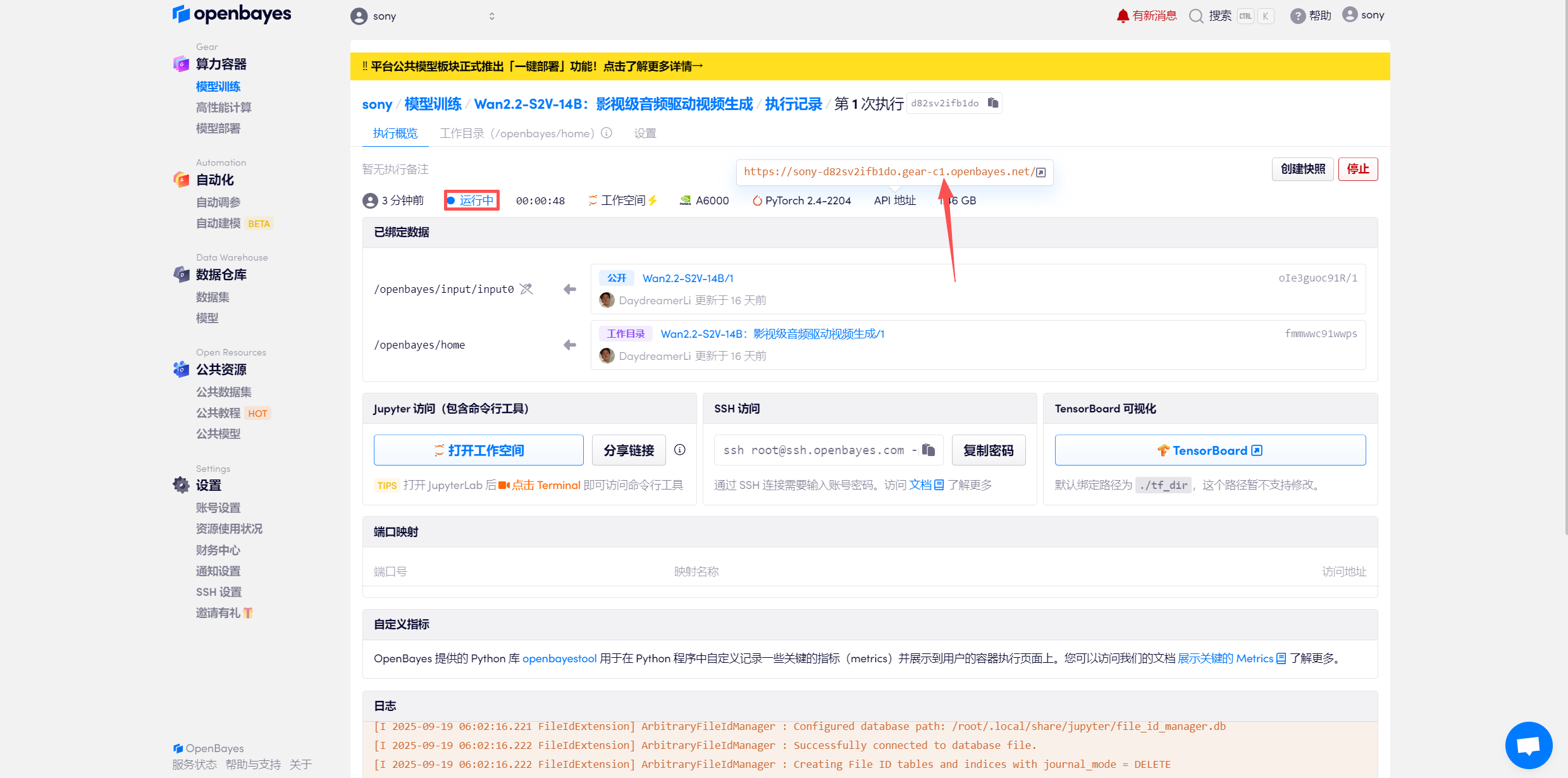
待系统分配好资源,当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
注意:推理步数越多,生成的效果越好,同时推理生成时间也会更长,请合理设置推理步数(示例一:推理步数为 10 时,生成视频大约需要 15 分钟左右)。
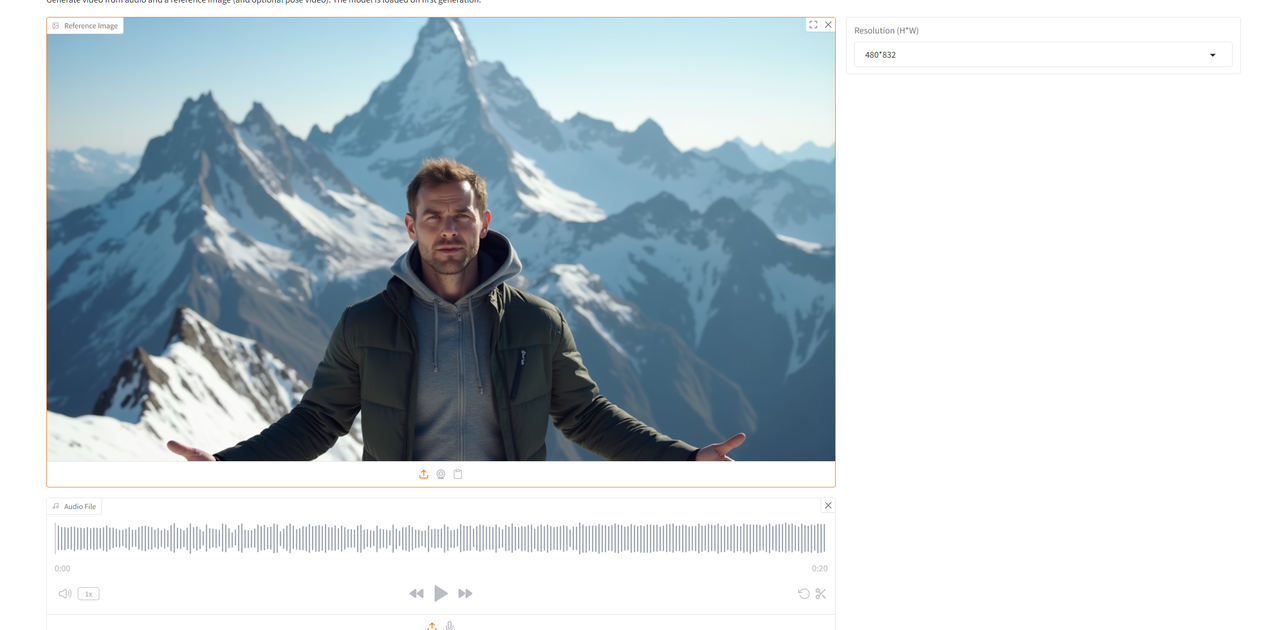
进入到模型页面后,首先在「Reference lmage」中上传一张图片,然后在「Audio file」中上传音频,此外还可以在「Pose Video (optional)」中上传姿态视频,在「Resolution (H*W)」中调整好分辨率后,点击「Start Generating」生成。
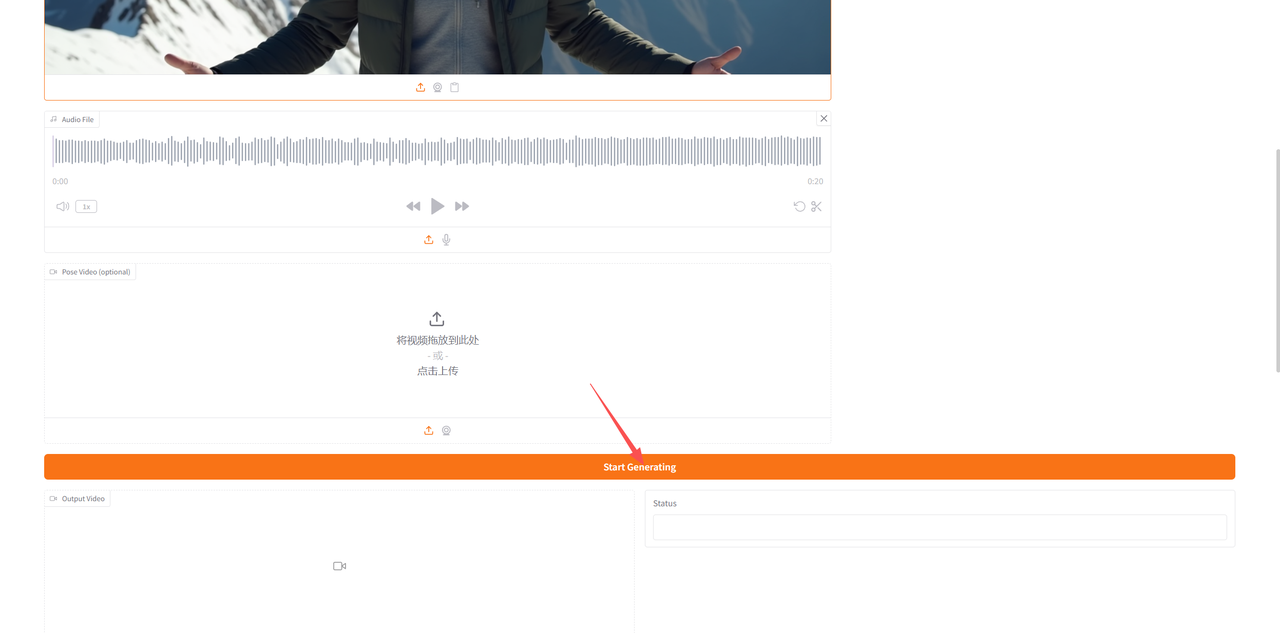
(由于平台限制,视频大家可以到「知乎-技术小白狮」同名文章内查看~)