在 Elasticsearch 和 GCP 上的混合搜索和语义重排序
作者:来自 Elastic Jhon Guzmán

学习如何仅使用 GCP 组件和 Elasticsearch 构建一个带语义重排序器的完整混合搜索应用。
更多阅读:
-
Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用
-
在本地电脑中部署阿里 Qwen3 大模型及连接到 Elasticsearch
Elasticsearch 与业界领先的 Gen AI 工具和提供商有原生集成。查看我们的网络研讨会,了解超越 RAG 基础,或使用 Elastic 向量数据库构建生产就绪的应用。
为了为你的用例构建最佳搜索解决方案,现在可以开始免费的 cloud 试用,或在本地机器上试用 Elastic。
混合搜索(Hybrid search)结合了传统的词汇搜索和语义搜索(semantic search),使结果既具有精确性又具有上下文理解。通过添加重排序器(reranker),你可以重新排序检索到的文档,将最相关的文档优先显示。使用 Elasticsearch,你可以在同一个 cloud 提供商 —— 在本例中是 Google Cloud Platform (GCP) —— 内构建整个系统。

在本文中,你将学习如何使用 GCP 上的 Elasticsearch Cloud Serverless 和 Vertex AI,在 Playground 中创建一个应用来查询模拟百科全书的文章。我们选择 Serverless 是因为它完全托管并自动扩展,但在 GCP 上使用 Elastic Cloud 也能实现本文的目的。
在嵌入(embedding)方面,我们将使用 gemini-embedding-001 模型,该模型可生成最多 3,072 维的向量(你可以用 MRL 将其调整为 1,536 或 768)。该模型每次输入最多可处理 2,048 个 token,并支持 100 多种语言。嵌入(embeddings)将文本转换为捕捉意义和上下文的数值向量,使得可以语义化地比较查询和文档,而不仅仅是按精确词匹配。
然后,我们将使用 semantic-ranker-fast-004 模型作为重排序器。这是 Ranking API 的低延迟版本,设计用于在不影响速度的情况下重新排序结果。在初步检索步骤后,重排序器会对候选结果进行重新排序,使最相关的文档显示在最前面。
在 Completions/Chat 中,我们将使用 gemini-2.5-flash-lite。这是一个为高速和低成本优化的模型。它具备思考能力,支持非常长的上下文(最多 1M token),可启用运行代码的工具,提供 Google Search 的基础信息支持,并支持多模态。Completions 模型用于生成自然语言答案。
GCP 准备
要使用 Vertex AI 模型,你需要有一个 GCP 服务账号。如果你没有账号,可以按照这个教程操作,该教程还会创建一个 Vertex AI
连接,用作 Kibana Playground 中的 RAG。
如果你已经有账号,可以跳过教程,但要确保手上有认证 JSON 文件,并且账号具有以下角色:
-
Vertex AI User
-
Service Account Token Creator
-
Discovery Engine Viewer
-
AI Platform Developer
Elasticsearch Serverless 安装
要构建我们的应用,首先需要创建一个 Elasticsearch Serverless 部署。如果你没有账号,可以在这里免费注册。
输入所需信息,并选择 Search 用例以继续本教程。
在被问到部署类型时,选择 Elastic Cloud Serverless,然后选择 Google Cloud 作为提供商,区域为 US Central 1(Iowa)。
Elasticsearch Cloud Serverless 通过根据需求自动适应并根据负载优化性能,消除了规划容量或管理部署的需要。它的设计允许你集成像 Vertex AI 这样的服务,从而利用混合搜索和高级处理,而无需担心底层基础设施。这使其非常适合需要快速迭代的工作流程。
创建 AI 连接器
一旦我们部署了 Elastic Cloud Serverless 并可以访问 Vertex AI,就可以创建 AI 连接器。这些是 Elasticsearch 与模型之间的链接。
在 Kibana 的 connectors 页面(需从侧边菜单进入,路径为 Management > Stack Management > Alerts and Insights > Connectors),创建一个连接器,并选择 AI Connector 作为类型。
我们需要为每个想要使用的模型功能创建一个连接器:text_embedding、rerank 和 chat_completion。由于都来自 Vertex AI,配置几乎相同;你只需要更改连接器类型和模型 ID。
-
text_embedding:该任务接收文本并返回该文本的向量嵌入。用于数据摄取时存储嵌入,以及将搜索查询转换为嵌入。
-
rerank:该任务的输入是查询和候选数组。输出是根据查询相关性排序的候选列表。
-
chat_completion:Chat completion 将接收不同类型的消息数组(System、User、Assistant 等),并使用 LLM 根据提供的对话生成增量回答。
这三个连接器需要配置的参数如下:
-
Connector name:Vertex AI
-
Service:Google Vertex AI
-
JSON Credentials:在此处复制/粘贴 GCP 服务账号的访问密钥
-
GCP Project:拥有服务账号和 Vertex AI 模型的项目 ID
-
GCP Region:us-central1(与 Elastic Cloud Serverless 部署相同)
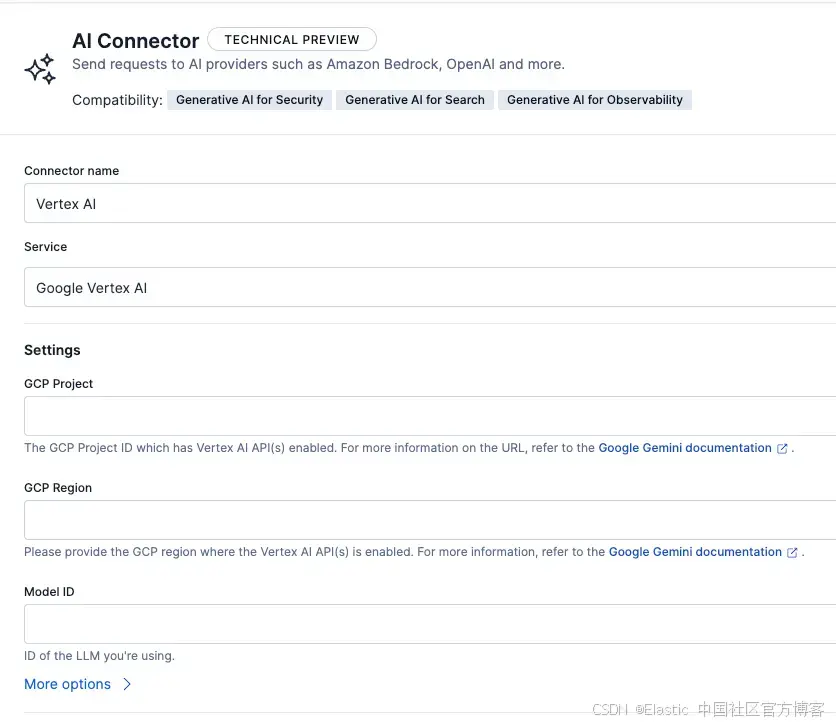
以下是每个连接器的具体配置:
Embeddings
-
Connector name:Vertex AI - Embeddings
-
Model ID:gemini-embedding-001
-
Task type:chat_completion。此类型连接器将文本转换为数值向量,可存储并在 Elasticsearch 中搜索。我们使用它是因为需要将文档和查询表示为向量空间,以实现语义搜索并与 BM25 结合进行混合搜索。
-
Inference Endpoint:vertex_embeddings
Reranker
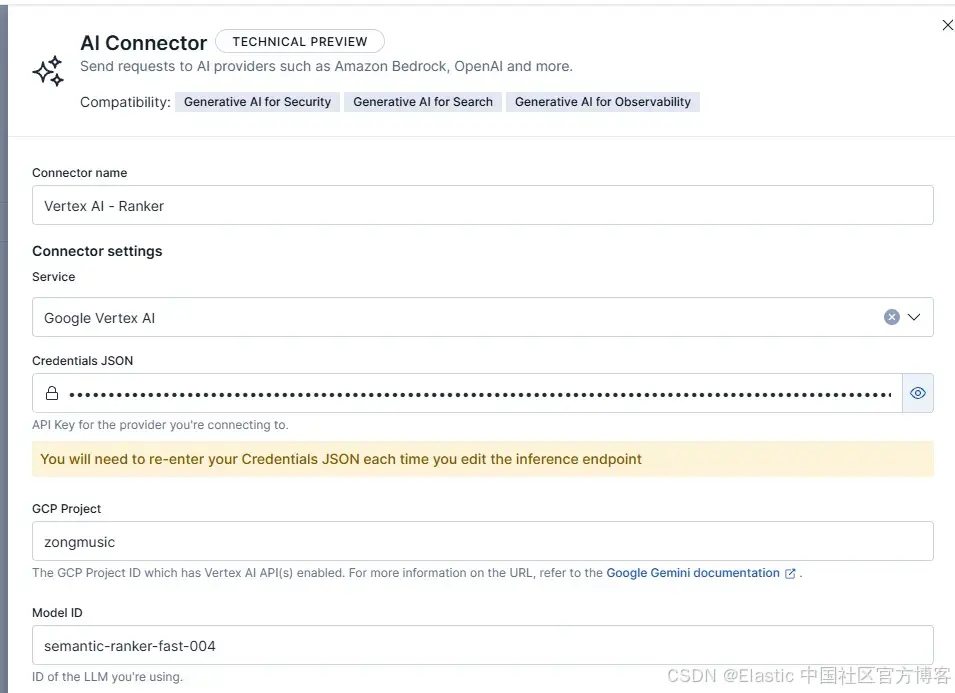
-
Connector name:Vertex AI - Ranker
-
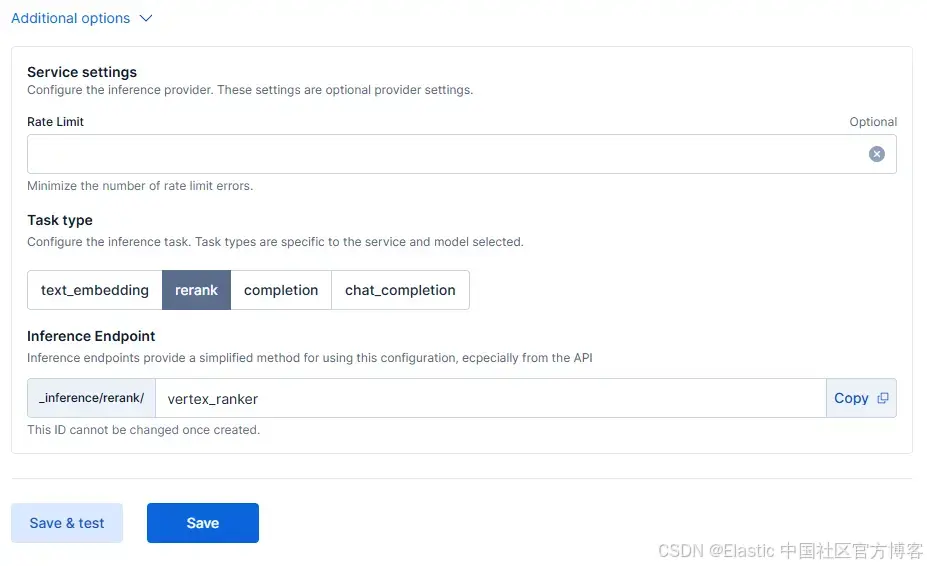
Model ID:semantic-ranker-fast-004
-
Task type:rerank。此类型用于获取一组初始结果,并按相关性返回排序后的结果。我们使用它是因为可以通过模型将结果排序得更好。
-
Inference Endpoint:vertex_ranker
Completions/Chat
-
Connector name:Vertex AI - Chat
-
Model ID:gemini-2.5-flash-lite
-
Task type:chat_completion。此类型允许你发送消息并获得模型生成的回答。我们在最终 RAG 阶段使用它,让模型生成基于自然语言的聊天答案。
-
Inference Endpoint:vertex_chat
例如,rerank 连接器的配置应如下所示:
以下是额外的参数:
数据摄取
为了测试我们配置的模型功能,我们将对一个包含多个主题信息的模拟百科全书进行索引。你可以在这里下载数据集。
我们索引的文档格式如下:
{"title":"Why the Sky Appears Blue","author":"Daniel Wright","content":"Sunlight looks white, but it contains many colors. As that light passes through Earth’s atmosphere it collides with tiny gas molecules. The shorter, bluer wavelengths scatter much more strongly than the longer, redder ones, so blue light is sent to your eyes from every direction and the sky appears blue.\n\nAt sunrise and sunset, sunlight travels through a longer slice of atmosphere. Along that path, much of the blue light is scattered out before it reaches you, leaving the transmitted light enriched in reds and oranges—hence the warm colors near the horizon.","date":"2023-10-05"
}在侧边菜单中,进入 Elasticsearch > Home > Upload a file。
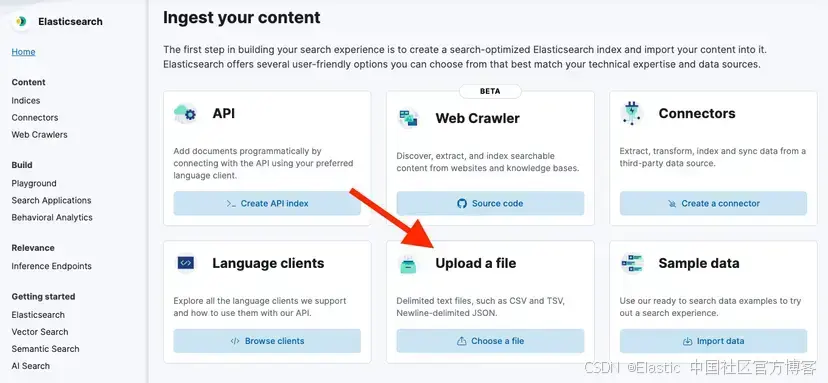
然后,点击 Upload a file 并选择你刚下载的文件。
现在点击蓝色的 Import 按钮,在下一个菜单中选择 “Advanced” 标签,并将索引命名为 “encyclopedia_articles”。
然后,选择 Add additional field,选择 Add semantic text field,并将 inference endpoint 设置为 vertex_embeddings,字段设置为 content,如下所示:
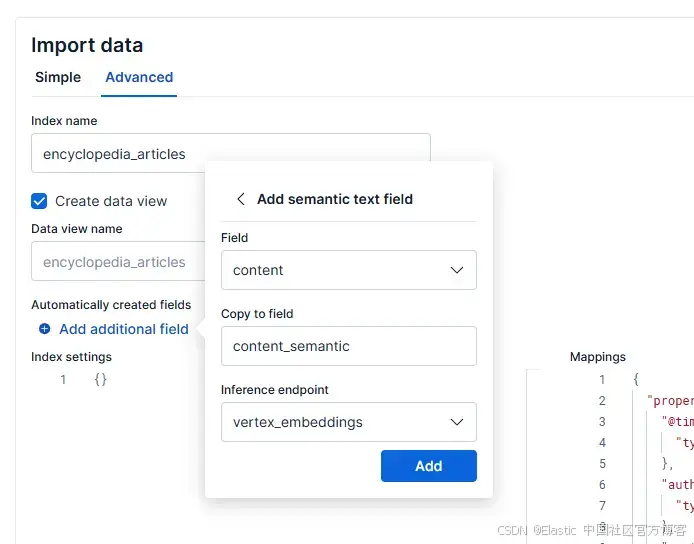
这将创建一个字段,用于存储每个文档生成的向量,使你能够使用刚配置的 embeddings 模型进行语义搜索。
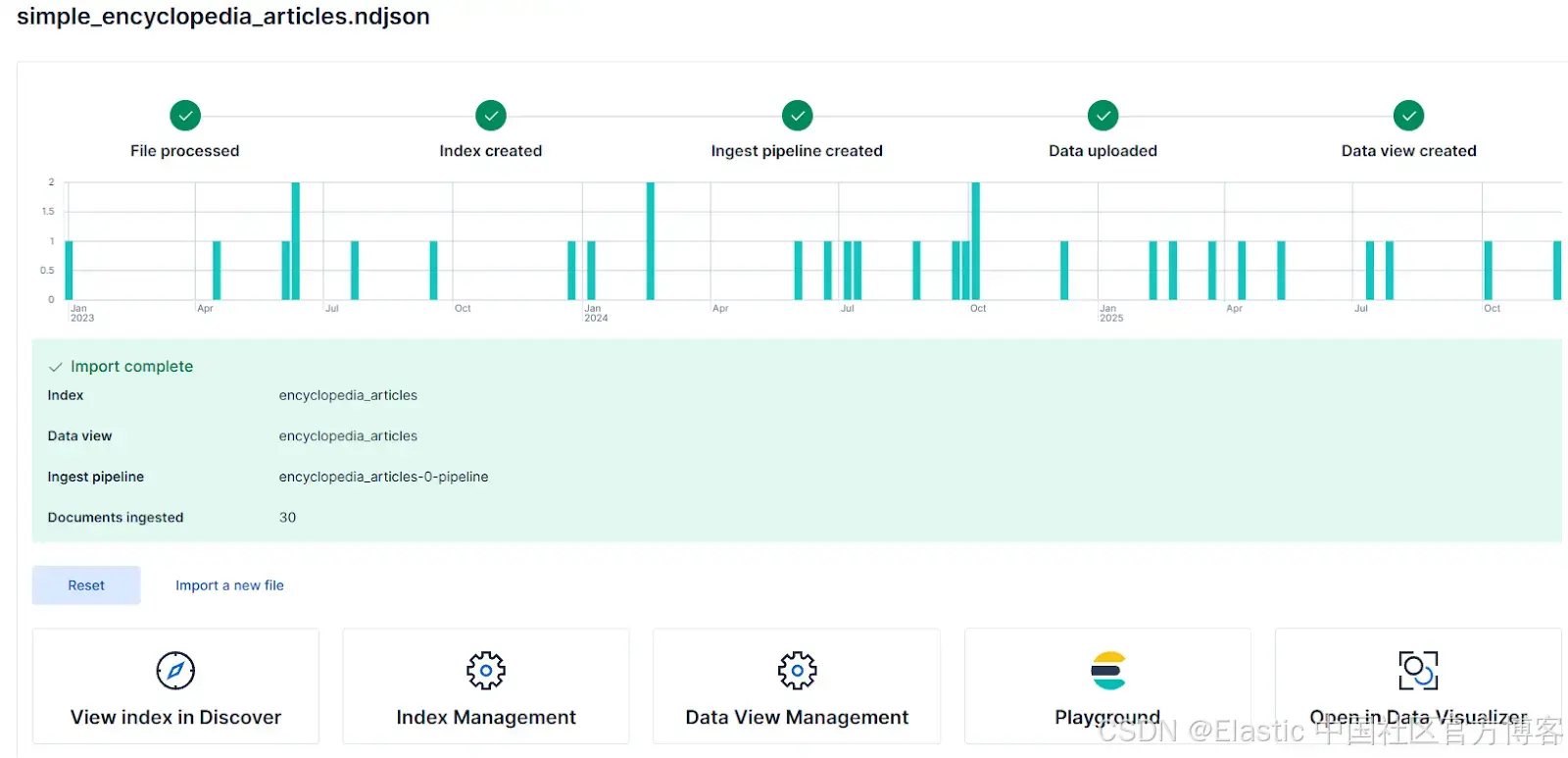
最后,点击 Add,然后点击 Import 完成索引创建。完成后,你会看到显示索引导入状态的界面,应该如下所示:
混合查询
混合查询是词汇搜索和语义搜索的结合,利用两种策略的优势:词汇搜索的关键词精确性和语义搜索捕捉相似概念的能力。
混合查询既可以覆盖那些明确知道自己要找什么并使用精确关键词的用户,也可以覆盖那些不太确定、搜索与索引文档相关词或概念的用户。你可以在这篇文章中了解更多关于混合搜索的内容。
在混合搜索之上,我们将放置一个重排序器。这个重排序器会对前几条结果进行最后排序,使用专门的模型根据查询相关性进行排名。
现在,我们将使用 retriever 功能结合 RRF 和语义重排序器,在一次 API 调用中利用语义搜索、文本搜索和重排序。
进入 Kibana DevTools(侧边菜单 > Developer Tools),运行以下查询:
{"retriever": {"text_similarity_reranker": {"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"match": {"content": "gas refrigerators"}}}},{"standard": {"query": {"semantic": {"query": "gas refrigerators","field": "content_semantic"}}}}]}},"field": "content","rank_window_size": 10,"inference_id": "vertex_ranker","inference_text": "gas refrigerators","min_score": 0.1}}
}此查询将语义搜索和文本搜索与 RRF 结合,然后使用 vertex_ranker 根据模型计算的相关性对结果进行排序。rank_window_size 控制在重排序阶段将评估多少初始结果,而 min_score 用于过滤低分文档。
Playground
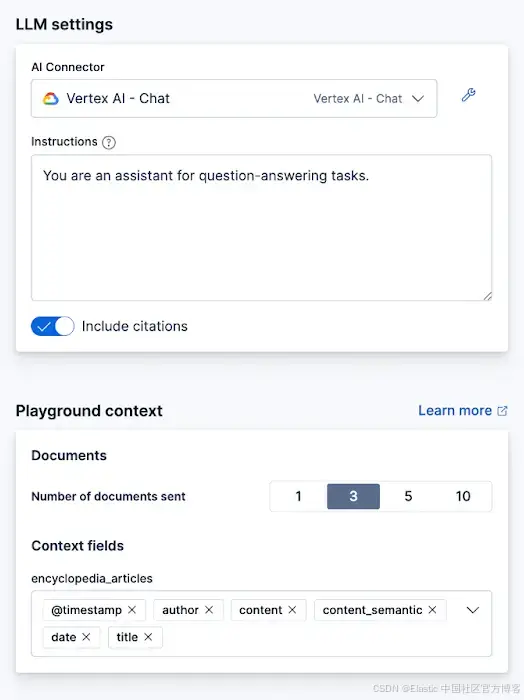
要在 RAG 中使用我们的数据,进入 Kibana 的 Playground 并使用我们之前连接的 Gemini 模型。在侧边菜单中,进入 Elasticsearch > Playground。
在 Playground 界面,如果连接器存在,你会看到一个绿色勾选和 “LLM Connected” 的文字。你可以在这里参考更详细的 Playground 指南。
点击 “Data” 按钮,并选择我们刚创建的 encyclopedia_articles 索引。
现在,你向 LLM 提出的任何问题都会基于你选择的索引得到回答,并会包含用于生成答案的文档参考。
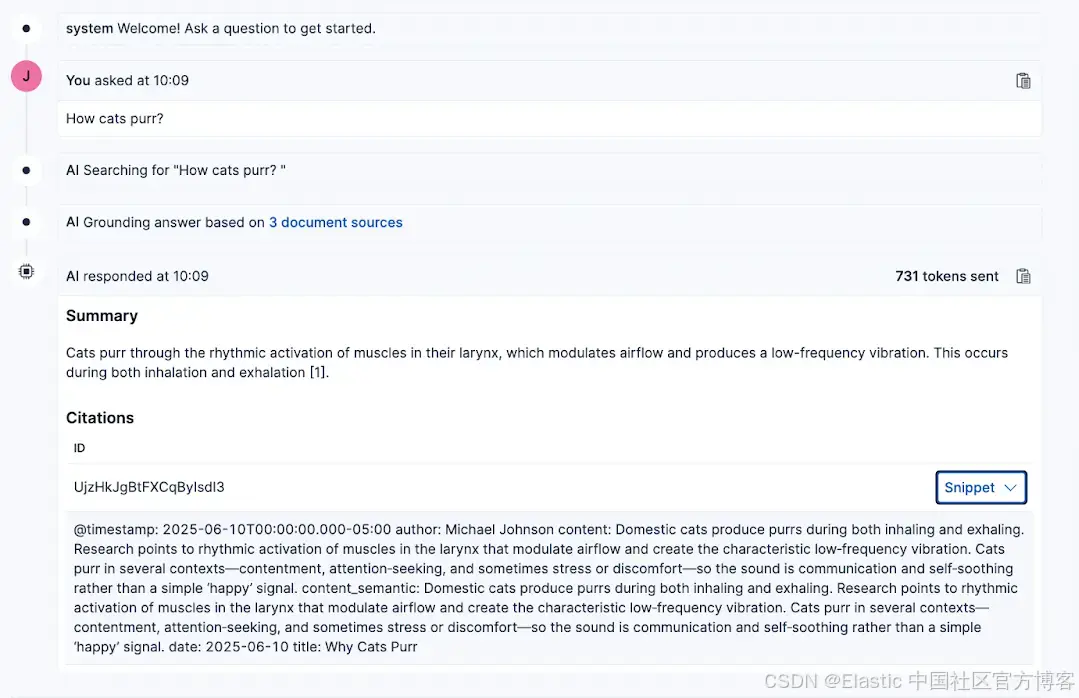
在 Playground 中,我们可以编辑用于获取答案上下文的 Elasticsearch 查询。点击页面顶部的 Query 按钮。
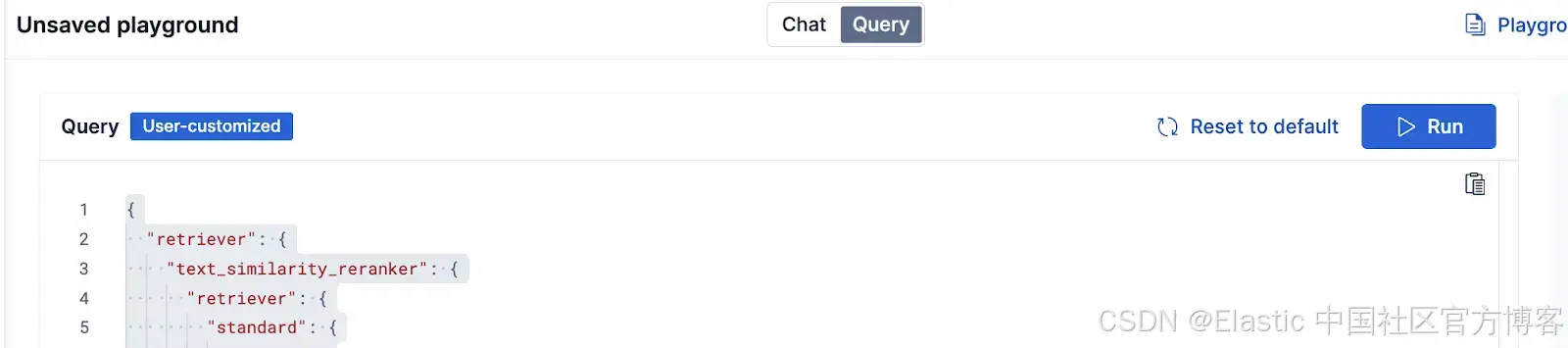
我们可以添加刚才介绍的相同功能。下面是重排序功能的示例:
{"retriever": {"text_similarity_reranker": {"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"match": {"content": "{query}"}}}},{"standard": {"query": {"semantic": {"field": "content_semantic","query": "{query}"}}}}],"rank_constant": 60}},"field": "content","rank_window_size": 25,"inference_id": "vertex_ranker","inference_text": "Articles about animals","min_score": 1}},"highlight": {"fields": {"content_semantic": {"type": "semantic","number_of_fragments": 2,"order": "score"}}}
}部署到 Google Cloud Run
一旦你对应用在 Playground 中的表现满意,就可以将代码部署到 Google Cloud Run,使你的应用可以通过外部 API 访问。
首先,在 Playground 右上角点击 View Code。
在那里,你会找到一个脚本,详细说明了构建自己的 RAG 应用所需的库和工作流程。你可以选择 LangChain 实现或 OpenAI client。我们选择 LangChain,因为它可以让我们轻松切换 LLM 模型。
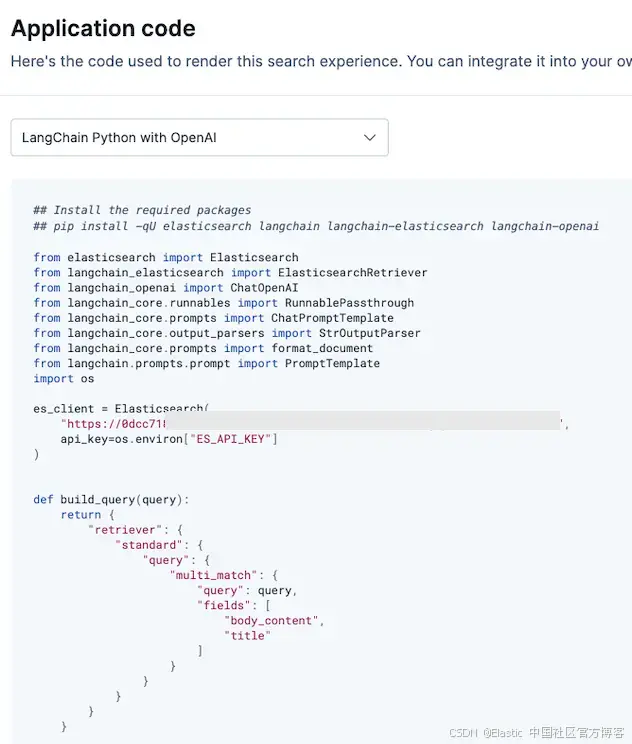
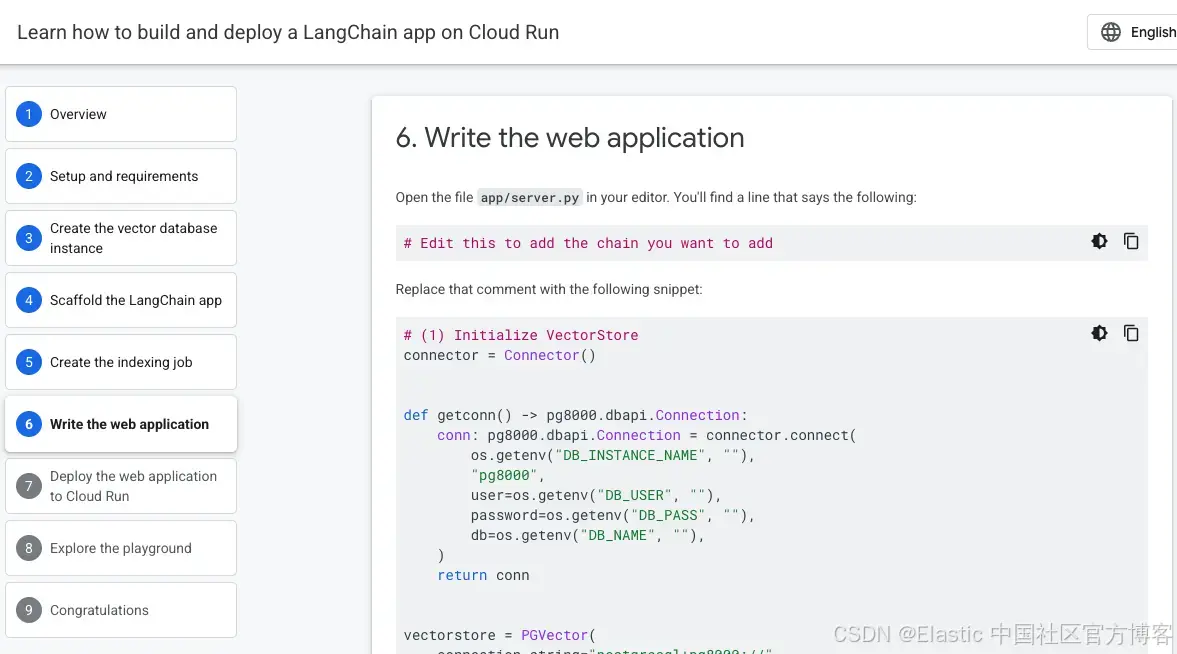
你可以通过以下教程学习如何在 Google Cloud Run 上部署代码:Build and deploy a LangChain app on Cloud Run。特别注意第 6 步:Write the web application。
结论
使用 Elasticsearch 和 GCP 模型,你可以从头到尾构建一个 RAG 应用,在 Google Cloud Platform 上完成信息索引、语义搜索、基于相关性重排序结果,以及基于这些功能生成答案——所有操作都在一个集成工作流中完成。
原文:https://www.elastic.co/search-labs/blog/hybrid-search-semantic-reranking-gcp-elasticsearch