数据库和数据仓库有什么区别
一句话核心区别
数据库(Database):像餐厅的后厨操作台。设计目标是快速处理一个个新来的订单(增删改查),保证每一道菜(单条数据)准确、快速出锅。
数据仓库(Data Warehouse):像餐厅经理的决策分析室。设计目标是整合分析过去一周、一个月的所有订单数据,来回答“什么菜最畅销?”、“哪个厨师效率最高?”等决策性问题。
为了更直观地理解这两者的定位和关系,下图展示了它们在一个典型数据架构中的角色:
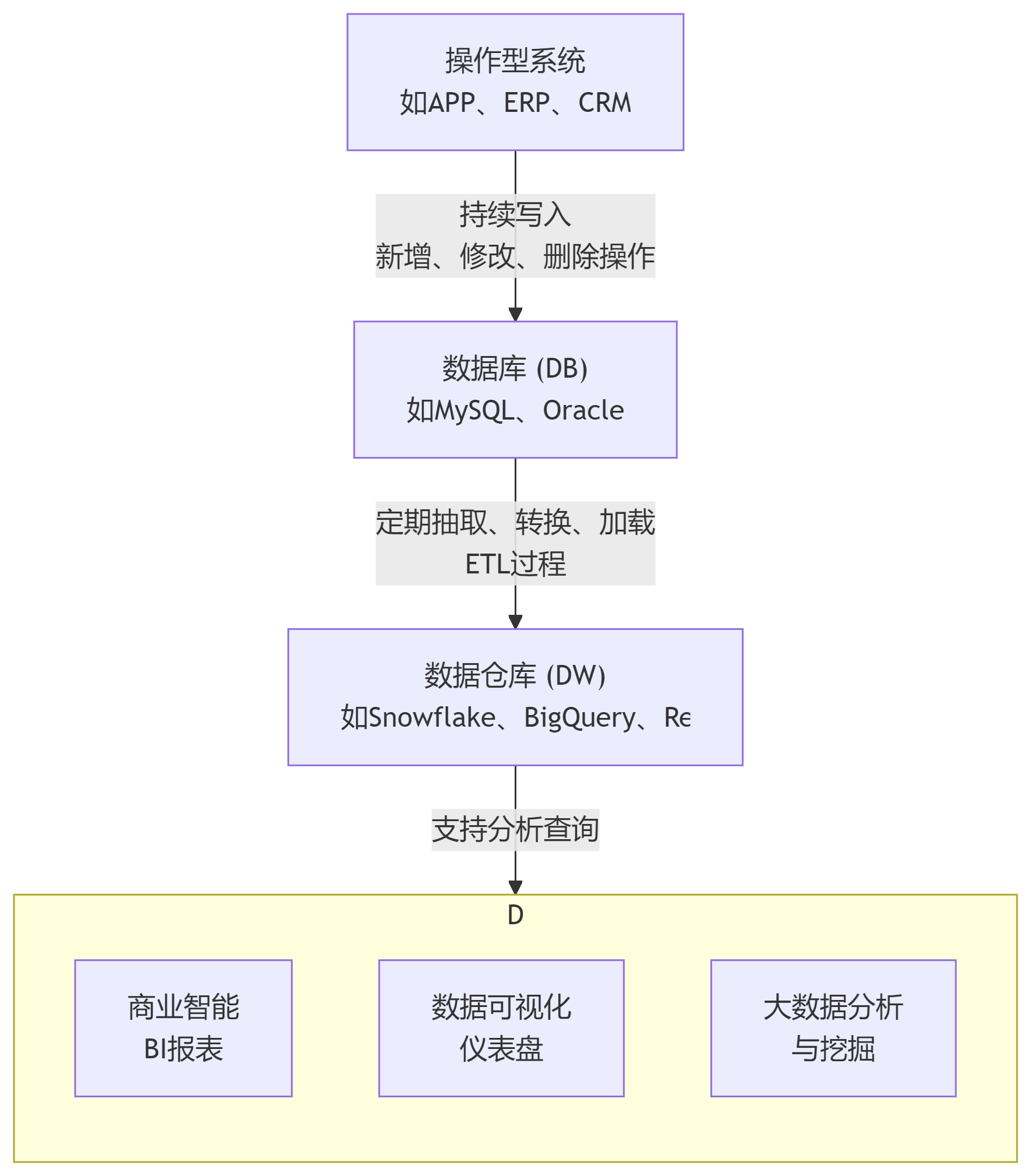
理解了它们的宏观角色后,我们再通过一个详细的表格来看看它们的核心差异:
详细对比表格
| 特性维度 | 数据库 (Database) | 数据仓库 (Data Warehouse) |
|---|---|---|
| 主要目的 | 操作型处理 (OLTP) 支持日常业务运营,高效处理事务。 | 分析型处理 (OLAP) 支持复杂查询和分析,用于决策支持。 |
| 处理的数据 | 当前的数据 最新的、细节的、可更新的操作数据。 | 历史的数据 来自多个系统的、整合的、随时间变化的历史数据。 |
| 数据特征 | 动态的 数据频繁更新、插入、删除。 高度规范化,减少冗余。 | 静态的 数据一旦加载,通常只读不写。 非规范化(如星型/雪花模型),优化查询速度。 |
| 主要操作 | 大量的简单操作 频繁的 INSERT, UPDATE, DELETE, SELECT(针对少量记录)。 | 少量的复杂操作 主要是复杂的 SELECT查询,涉及大量数据的聚合和表连接。 |
| 设计模型 | 面向应用 为特定业务功能设计(如交易、用户管理)。 | 面向主题 按分析主题组织数据(如销售、客户、库存主题)。 |
| 性能优化 | 优化写操作和短时间快读。 | 极致优化读操作和大数据量扫描。 |
| 用户 | 业务操作人员 前台员工、网站/App用户。 | 管理决策人员 经理、分析师、数据科学家。 |
| 典型产品 | MySQL, PostgreSQL, Oracle, SQL Server | Snowflake, Amazon Redshift, Google BigQuery Teradata, 阿里云MaxCompute |
一个具体的例子
假设我们有一个电商公司:
数据库的角色:
当你在网站上下单时,你的订单信息(订单号、商品ID、价格、收货地址)会立刻被写入订单数据库。
当你修改收货地址或取消订单时,数据库会执行
UPDATE和DELETE操作。这些操作要求极快的响应速度,以保证你的体验流畅。
数据仓库的角色:
到了晚上,订单数据库、用户数据库、商品数据库等的数据都会被抽取出来,经过清洗和转换(这个过程叫 ETL),然后加载到数据仓库中。
在数据仓库里,你的一条订单数据会和其他所有历史订单、用户信息、商品信息整合在一起。
第二天,数据分析师可以:
执行一个复杂查询,分析过去一年哪个品类的商品在哪个地区最畅销。
生成一份可视化报表,比较今年和去年的季度销售趋势。
这些查询会扫描数百万甚至数十亿条记录,但数据仓库的架构就是为了让这种分析查询变得更快。
总结与关联
数据库是数据之源,是业务系统运行时直接操作的地方,强调事务性和实时性。
数据仓库是数据之汇,将各个数据库的数据汇集起来,进行整合和沉淀,用于分析和洞察,强调查询性能和分析能力。
它们不是替代关系,而是协作关系:
数据库 负责支撑业务的 “现在” —— 处理实时交易。
数据仓库 负责分析业务的 “过去” —— 从历史数据中总结规律,以指导 “未来” 的决策。