2025年目标检测还有什么方向好发论文?
在目标检测领域发论文,竞争确实够激烈,但并不是完全没机会。就发展前景而言,它还远远没达到“瓶颈期”,因为只要机器还需要“看”和“理解”世界,它就是不可或缺的关键技术。
未来,目标检测的研究将更加强调实际场景下的可靠性、效率和适应性。而目前主流的四大创新方向(架构革新、任务拓展、信息融合、范式变革),不仅是它发展的核心逻辑,也是以上三个维度的重要支撑。
因此,建议论文er们围绕这4类创新找思路,参考多资源也多。我这边已经整理好了176篇目标检测前沿论文,配有代码+数据集,也按照上述方向做好了分类,大家可无偿自取。
全部论文+开源代码需要的同学看文末

核心模型架构革新
聚焦“模型骨架”的重构与优化,是技术突破的核心。本质是解决“如何更高效、更精准地提取特征、建模目标”的基础问题。
Mr. DETR: Instructive Multi-Route Training for Detection Transformers
方法:论文提出了一种基于Transformer的目标检测训练方法“Mr. DETR”,通过多路由训练机制(主路由进行一对一预测,辅助路由进行一对多预测)和指导性自注意力机制,提升模型训练效率和性能,同时保持推理时模型架构和成本不变。
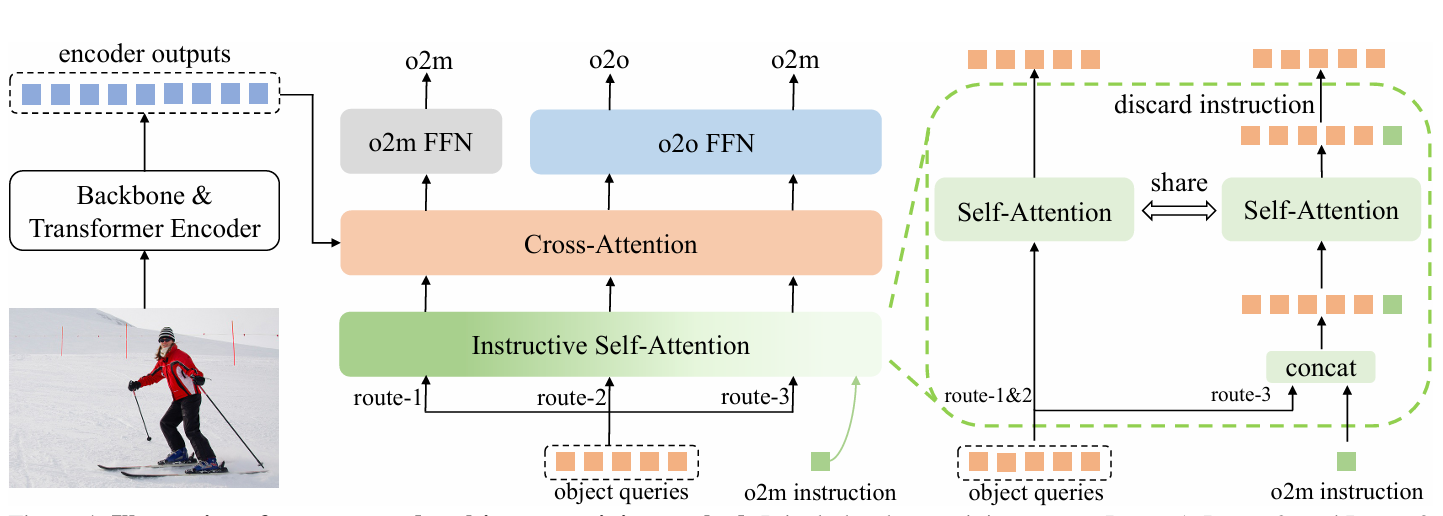
创新点:
提出多路由训练机制,包含主路由用于一对一预测和两个辅助路由用于一对多预测。
设计一种指导性自注意力机制,通过动态引导目标查询实现更精准的一对多预测,进一步增强模型的训练效果。
在推理阶段移除辅助训练路由,确保模型架构和推理成本保持不变,同时提升模型的检测精度和效率。
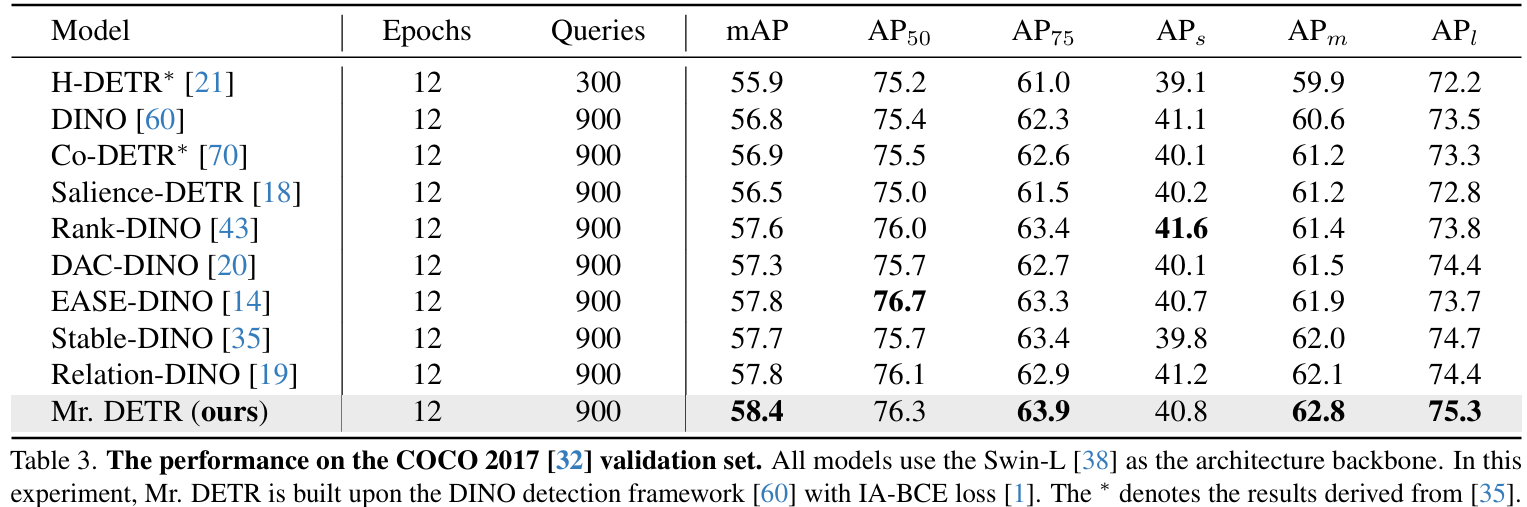
场景与任务范式拓展
突破传统目标检测“闭集、单一场景、固定任务”的固有设定,聚焦“任务边界”的拓展,或适配特殊应用场景,贴近真实应用需求。
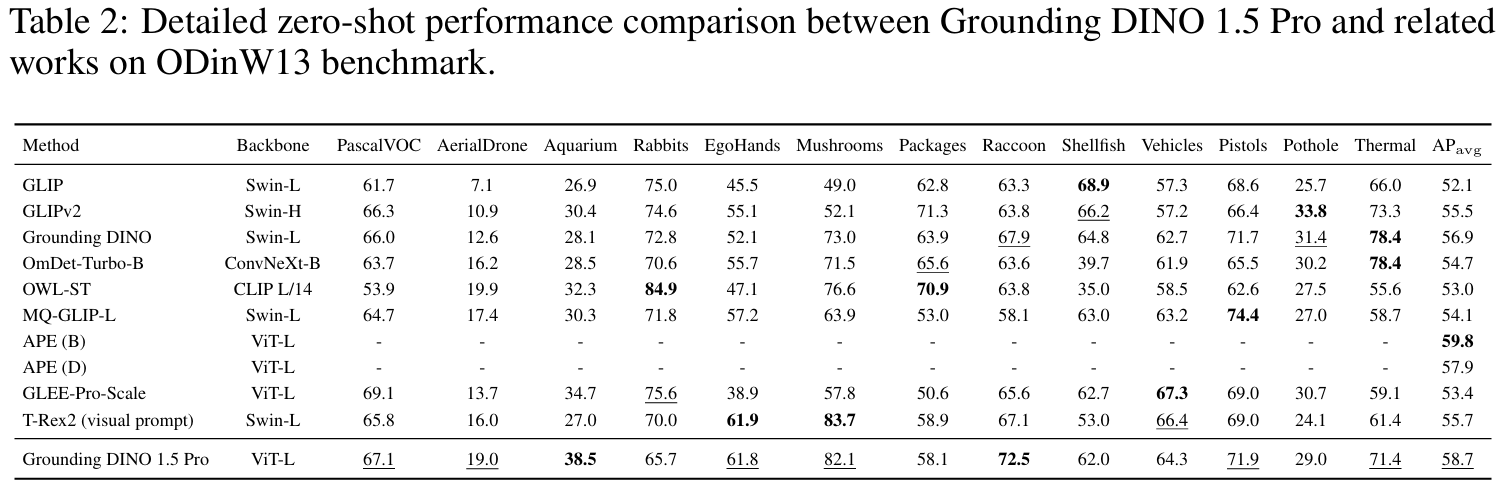
Grounding DINO 1.5: Advance the “Edge” of Open-Set Object Detection
方法:论文提出了Grounding DINO 1.5,这是一个用于开集目标检测的模型,包含高性能的Pro版本和适用于边缘设备的Edge版本。它通过扩大模型架构和使用超过2000万张图像的训练数据集,显著提升了目标检测的泛化能力和效率。
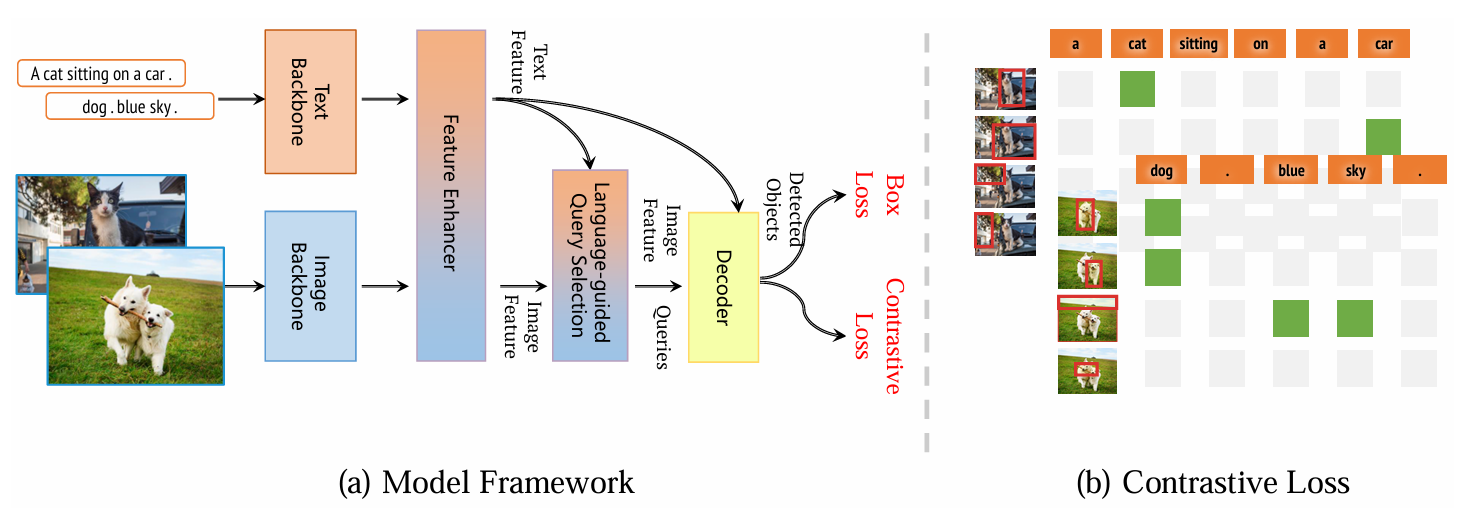
创新点:
提出 Grounding DINO 1.5 Pro,通过扩展模型架构和使用超过2000万张图像的训练数据集,提升检测性能。
设计 Grounding DINO 1.5 Edge,专注于计算效率,适用于边缘设备部署,优化后达到75.2 FPS的速度。
在COCO和LVIS数据集上,Pro版本和Edge版本均取得了显著的零样本性能提升。
信息融合与利用优化
不改变核心架构,聚焦“信息处理方式”的优化,侧重“如何让模型更高效地利用有效信息”,解决信息碎片化、异构化的问题。
SM3Det: A Unified Model for Multi-Modal Remote Sensing Object Detection
方法:论文提出了一种名为SM3Det的多模态目标检测模型,用于处理来自不同传感器模态的高分辨率图像。通过网格级稀疏MoE架构和动态学习率调整策略,有效处理多模态图像的目标检测任务,显著提升检测性能。
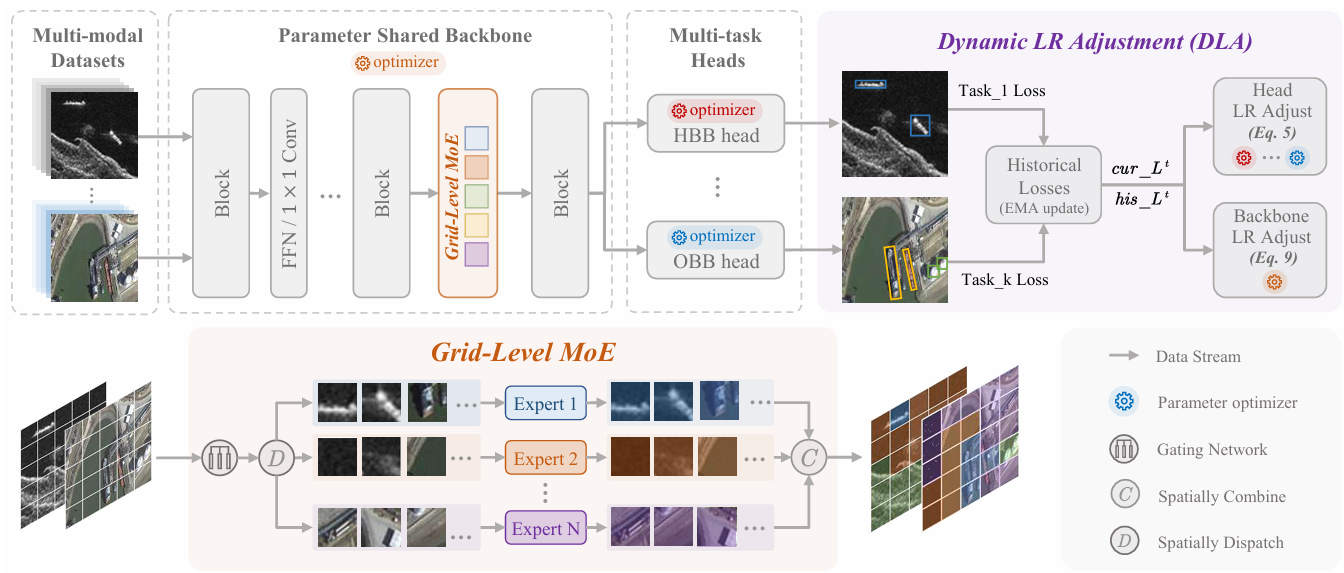
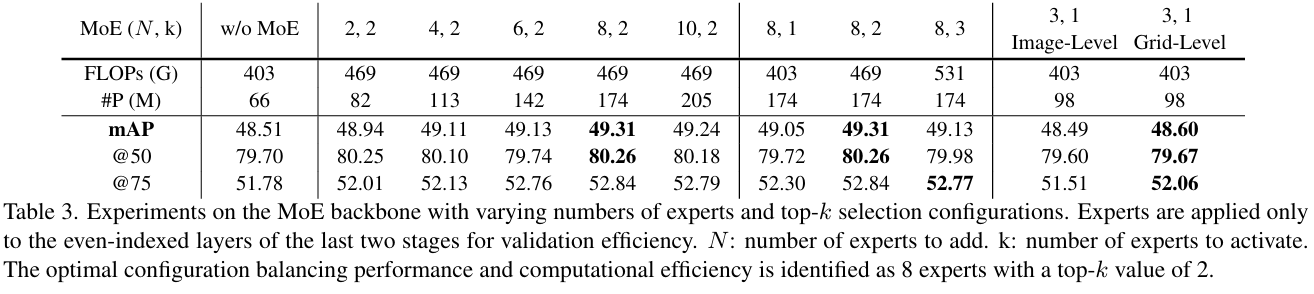
创新点:
提出SM3Det模型,通过网格级别的稀疏MoE架构,实现不同模态下的特征表示学习。
引入动态学习率调整策略,根据任务和模态的学习难度动态调整学习率,确保模型优化的一致性。
在多个数据集上验证了SM3Det模型的有效性,其性能显著优于单独训练的模型,具有强泛化能力。
大模型驱动的范式变革
以“视觉大模型的预训练-微调范式”为核心,改变传统检测的模式,聚焦“模型能力的迁移”,是从“专用”到“通用”的转变。
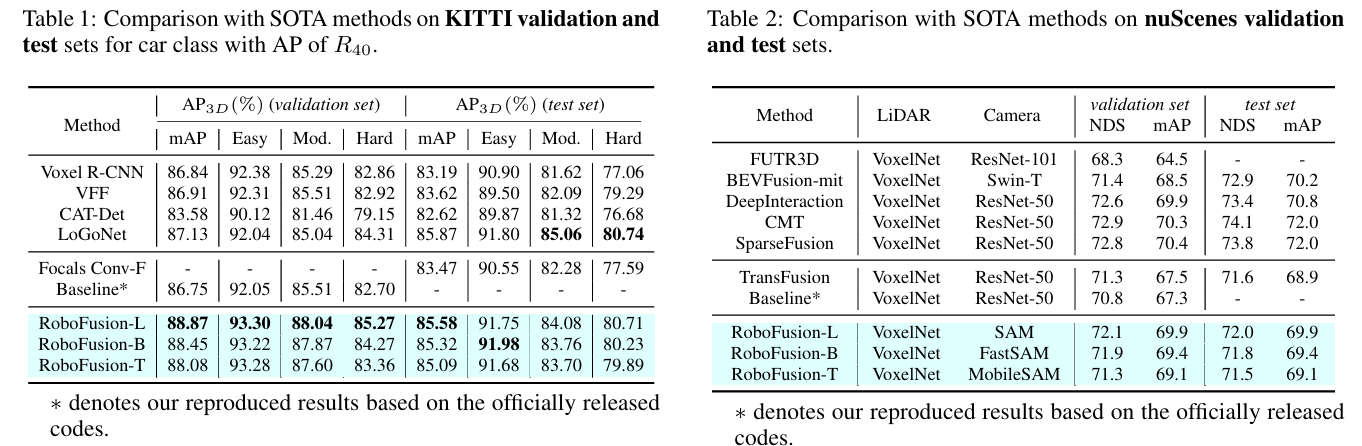
RoboFusion: Towards Robust Multi-Modal 3D Object Detection via SAM
方法:论文提出RoboFusion框架,利用视觉基础模型SAM的泛化能力,通过SAM-AD、AD-FPN、DGWA和自适应融合等模块,提升多模态3D目标检测在自动驾驶中的鲁棒性和泛化能力,尤其在噪声场景下表现优异。
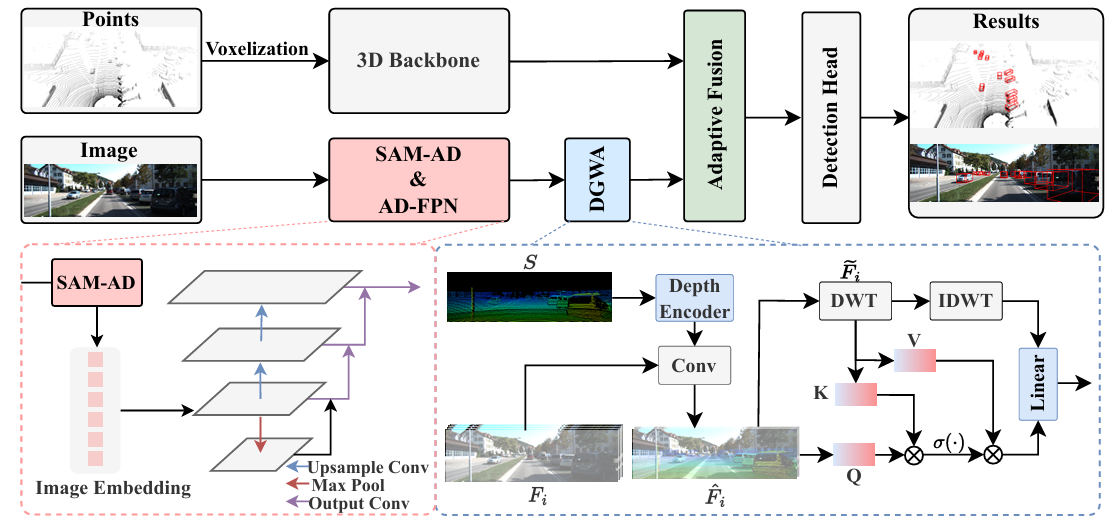
创新点:
提出SAM-AD,对SAM进行自动驾驶场景的适应性调整,使其更适合处理多模态3D目标检测任务。
引入AD-FPN模块,用于上采样图像特征,使SAM与多模态3D目标检测器对齐,增强特征融合效果。
设计深度引导的小波注意力模块,利用小波分解对深度引导的图像特征进行去噪,提升模型在噪声场景下的鲁棒性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏