大模型初识(基础模型 业务集成+智能体Agent+Prompt提示词优化)
大模型从无到有、再到落地业务
① 基础模型开发 (Foundation Model Development) 和
② 业务应用集成 (Business Application Integration)

①、基础模型开发(预训练)
- 使用 Hugging Face 的 transformers 库和 datasets 库,模拟一个极小规模的预训练流程
- 理解预训练的核心流程:准备数据 -> 分词 -> 初始化模型 -> 用LM目标函数训练
# pip install transformers datasets tokenizers accelerateimport torch
from transformers import(AutoTokenizer,GPT2Config,GPT2LMHeadModel,DataCollatorForLanguageModeling,TrainingArguments,Trainer
)
from datasets import Dataset #数据处理库
import numpy as np# 准备一个数据集(数据规模:真实预训练需要TB级文本,这里仅用4句话重复100次作为演示。)
texts = ["The quick brown fox jumps over the lazy dog. ","Machine learning is a subset of artificial intelligence. ","The capital of France is Paris. ","Python is a popular programming language for data science. "
] * 100 # 重复100次模拟一个小数据集
dataset = Dataset.from_dict({"text": texts})# 初始化一个 tokenizer(分词器) 从一个空的词汇表开始,在实际中会从一个大型语料库构建
tokenizer = AutoTokenizer.from_pretrained("gpt2")# 使用 GPT-2 的分词器,并添加了填充 token 用于批处理
tokenizer.add_special_tokens({"pad_token": "[PAD]"}) #对数据集进行分词 将文本转换为模型可接受的 token ID 序列,设置最大长度为 64
def tokenize_function(examples):# 对文本进行分词,truncation 和 padding 在实际预训练中通常不这样做,这里为了演示return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=64)tokenized_datasets = dataset.map(tokenize_function, batched=True, remove_columns=["text"])# 创建模型配置并初始化一个全新模型 (模型规模:真实GPT模型有数十到数百层,数十万个嵌入维度。这里仅用2层、64维嵌入,参数量约20万)
#使用非常小的参数,否则训练会非常慢且需要大量内存
config = GPT2Config(vocab_size=tokenizer.vocab_size, #词汇表大小n_positions=128, #最大位置编码长度n_ctx=128,n_embd=64, # 非常小的嵌入维度n_layer=2, # 仅2层Transformer块n_head=2, # 仅2个注意力头
)
model = GPT2LMHeadModel(config)
# 查看模型参数量
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}") # 约20万参数,真实GPT-3有1750亿# (计算资源:真实训练需数千GPU数月,这里用CPU或单个GPU几分钟即可完成演示)
# 6. 设置数据整理器(用于动态padding和构造语言模型标签)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False, # 对于GPT,我们使用因果语言建模(CLM),用于动态处理批数据,mlm=False 表示使用因果语言建模(预测下一个token)不是掩码语言建模(MLM)
)# 7. 配置训练参数
training_args = TrainingArguments(output_dir="./my_tiny_gpt2",overwrite_output_dir=True,per_device_train_batch_size=4, # 极小的批次大小num_train_epochs=10, # 训练轮数save_steps=100,logging_steps=50,prediction_loss_only=True,remove_unused_columns=False,
)# 8. 创建 Trainer 并开始训练
trainer = Trainer(model=model,args=training_args,data_collator=data_collator,train_dataset=tokenized_datasets,
)print("开始预训练...")
trainer.train()# 9. 保存模型以备后续使用
trainer.save_model()
tokenizer.save_pretrained("./my_tiny_gpt2")# 10. 测试生成效果
model.eval()
input_text = "The capital of France is"
inputs = tokenizer(input_text, return_tensors="pt")with torch.no_grad():outputs = model.generate(**inputs,max_length=20,num_return_sequences=1,do_sample=True,temperature=0.7,)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n生成文本: {generated_text}")②、业务应用集成(微调与部署)代码示例
目标:微调一个模型,能够将新闻标题分类到 科技、体育、财经 等类别
# pip install peft transformers datasets bitsandbytes acceleratefrom datasets import Dataset, load_dataset
from transformers import (AutoTokenizer,AutoModelForCausalLM,TrainingArguments,Trainer,DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, TaskType
import torch# 1. 加载一个新闻分类数据集(模拟企业数据)
# 假设我们有一个JSON格式的新闻数据: [{"title": "...", "label": "科技"}, ...]
# 这里我们使用一个公开数据集作为示例
dataset = load_dataset("ag_news")
dataset = dataset.map(lambda x: {"text": x["text"], "label": x["label"]})# 2. 定义标签映射
id2label = {0: "世界", 1: "体育", 2: "财经", 3: "科技"}
label2id = {"世界": 0, "体育": 1, "财经": 2, "科技": 3}# 3. 加载基座模型和分词器 (使用较小的模型如Llama-3-8B-Instruct)
model_name = "meta-llama/Llama-3-8B-Instruct" # 需有权限访问
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token# 4. 以4bit量化加载模型,极大减少显存占用
model = AutoModelForCausalLM.from_pretrained(model_name,load_in_4bit=True,device_map="auto",torch_dtype=torch.float16,
)# 5. 准备LoRA配置
lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 因果语言模型inference_mode=False,r=8, # LoRA秩lora_alpha=32,lora_dropout=0.1,target_modules=["q_proj", "v_proj"] # 针对LLaMA架构的模块
)# 6. 将原模型转换为PEFT模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 仅打印可训练参数(LoRA适配器)# 7. 格式化数据:将分类任务转换为文本生成任务
def format_classification_example(example):text = example["text"]label = id2label[example["label"]]# 格式化为指令遵循文本:指令 + 输入 + 输出formatted_text = f"""### Instruction:
请将以下新闻标题分类到【世界、体育、财经、科技】中的一类。### Input:
{text}### Response:
{label}"""return {"text": formatted_text}formatted_dataset = dataset.map(format_classification_example)# 8. 对格式化后的文本进行分词
def tokenize_function(examples):return tokenizer(examples["text"], truncation=True, max_length=256)tokenized_dataset = formatted_dataset.map(tokenize_function, batched=True)# 9. 设置训练参数
training_args = TrainingArguments(output_dir="./news_classifier_lora",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,num_train_epochs=3,logging_dir="./logs",logging_steps=10,save_strategy="epoch",report_to="none"
)# 10. 创建Trainer并开始训练
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)print("开始LoRA微调...")
trainer.train()# 11. 保存适配器权重
trainer.save_model()
使用FastAPI部署微调后的模型
# pip install fastapi uvicorn vllmfrom fastapi import FastAPI
from pydantic import BaseModel
from vllm import SamplingParams, LLM
import uvicorn# 1. 定义FastAPI应用
app = FastAPI(title="新闻分类API")# 2. 加载微调后的模型 (使用vLLM进行高性能推理)
# 注意:需要先将LoRA适配器与原模型合并,或使用vLLM的LoRA支持
llm = LLM(model="meta-llama/Llama-3-8B-Instruct",enable_lora=True, # vLLM支持LoRAlora_modules="./news_classifier_lora",max_num_seqs=10,max_model_len=512
)# 3. 定义请求和响应体
class ClassificationRequest(BaseModel):text: strmax_tokens: int = 10class ClassificationResponse(BaseModel):original_text: strpredicted_category: strgenerated_text: str# 4. 创建分类推理函数
def classify_news(text: str) -> str:# 构建与训练时格式一致的指令prompt = f"""### Instruction:
请将以下新闻标题分类到【世界、体育、财经、科技】中的一类。### Input:
{text}### Response:"""sampling_params = SamplingParams(temperature=0.1, # 低温度保证确定性输出max_tokens=50,stop=["\n"] # 遇到换行符停止生成)outputs = llm.generate(prompt, sampling_params)generated_text = outputs[0].outputs[0].textreturn generated_text.strip()# 5. 创建API端点
@app.post("/classify", response_model=ClassificationResponse)
async def classify_news_item(request: ClassificationRequest):predicted_category = classify_news(request.text)return ClassificationResponse(original_text=request.text,predicted_category=predicted_category,generated_text=f"分类结果: {predicted_category}")@app.get("/health")
async def health_check():return {"status": "healthy"}# 6. 启动服务 (生产环境使用Uvicorn或Docker部署)
if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000)
测试API
# 启动服务后,使用curl测试
curl -X POST "http://localhost:8000/classify" \
-H "Content-Type: application/json" \
-d '{"text": "Apple announced new iPhone with revolutionary AI chip"}'# 预期返回
{"original_text": "Apple announced new iPhone with revolutionary AI chip","predicted_category": "科技","generated_text": "分类结果: 科技"
}
大模型三种模式
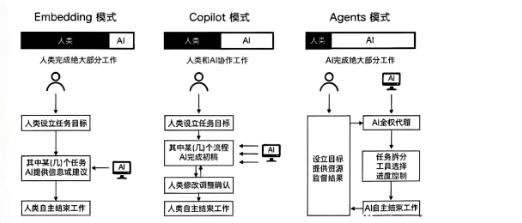
- 嵌入模式(Embedding):某个环节里去调用大模型
用户通过与AI进行语言交流,使用提示词来设定目标,然后AI协助用户完成这些目标。比如普通用户向生成式AI输入提示词创作小说、音乐作品、3D内容等
这种模式下,AI相当于执行命令的工具,人类担任决策者和指挥者的角色。
- 副驾驶模式(Copilot):每个环节都可以跟大模型进行交互
人类和AI共同工作,AI 更像是知识丰富的合作伙伴,辅助程序员编写代码、检测错误、优化性能
极度依赖prompt,产生不可控的幻觉逻辑
- 智能体模式(Agent):任务交给大模型,大模型自行计划、自动执行
智能体框架:AutoGen(Microsoft) LangGraph(LangChain) CrewAI OpenAI Swarm(OpenAI) Magentic-One(Microsoft)

财务数据分析助手案例
- 任务: 允许业务人员(如销售经理)通过自然语言查询公司内部的财务和销售数据,而无需编写复杂的SQL或学习BI工具。
- 成功标准: 查询准确率 > 95%,平均响应时间 < 10秒。
- 约束: 必须通过公司VPN访问,数据权限需与用户身份绑定。
ReAct模式+LangChain框架+ OpenAI GPT-4
关键代码节点:
- result_1 = agent.invoke({“input”: user_query_1}) user_query_1 = “上一季度销售额最高的产品是什么?”
- agent=initialize_agent(tools,llm,agent,memory,agent_kwargs,handle_parsing_errors)
memory = ConversationBufferMemory(memory_key=“chat_history”, return_messages=True)
system_message = SystemMessage(content=“系统提示词内容”)
llm= ChatOpenAI() 模型
tools=[] 主要是func调用数据库查询的类中方法
# requirements.txt
# langchain==0.1.0
# langchain-openai==0.0.2
# langchain-community==0.0.11
# openai==1.3.0
# python-dotenv==1.0.0import os
from langchain.agents import AgentType, initialize_agent, Tool
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import MessagesPlaceholder
from langchain.memory import ConversationBufferMemory
from typing import Any, Dict, List, Optional
import sqlite3 # 示例中使用sqlite,企业级可能是Snowflake、BigQuery等
import json# -------------------- 1. 工具实现 --------------------
# 注意:企业级应用中,数据库连接池、API密钥管理应使用更安全的方式(如Vault)class DatabaseQueryTool:"""一个模拟的数据库查询工具"""def __init__(self, db_path: str):self.conn = sqlite3.connect(db_path)def run(self, query: str) -> str:"""执行SQL查询并返回结果"""try:cursor = self.conn.cursor()cursor.execute(query)results = cursor.fetchall()# 将结果转换为字符串以便LLM理解return str(results)except Exception as e:return f"Query failed with error: {str(e)}"finally:# 注意:生产环境不会每次查询都关闭连接,会用连接池pass# 实例化工具,连接到一个示例数据库
db_tool_instance = DatabaseQueryTool("sample_finance.db")
# 模拟的财务API工具
def query_financial_api_tool(action: str, fiscal_period: str) -> str:"""查询内部财务API获取预算等信息。"""# 这里应该是调用真实API的代码,例如使用requests库# return requests.get(f"https://internal-api/finance/{action}?period={fiscal_period}").textreturn json.dumps({"budget": 500000, "period": fiscal_period})# -------------------- 2. 包装成LangChain Tool对象 --------------------
tools = [Tool(name="Sales_Database",func=db_tool_instance.run,description="Useful for querying sales data from the company database. Input should be a precise SQL query."),Tool(name="Financial_API",func=lambda params: query_financial_api_tool(**json.loads(params)),description="Useful for getting budget information from the internal financial system. Input should be a JSON string with 'action' (e.g., 'get_budget') and 'fiscal_period' (e.g., 'Q2-2024')."),
]# -------------------- 3. 设置LLM和Memory --------------------
llm = ChatOpenAI(model="gpt-4",temperature=0, # 降低创造性,保证准确性openai_api_key=os.getenv("OPENAI_API_KEY")
)# 系统提示词,至关重要!它定义了Agent的角色和能力边界。
system_message = SystemMessage(content=""You are a professional financial data analyst assistant for a large enterprise.
Your goal is to help users get insights from the company's financial and sales data by generating precise queries and interpreting the results.
You MUST follow these rules:
1. You MUST ONLY use the tools provided to you. Do not make up any data.
2. When querying the database, your SQL MUST be syntactically correct and efficient.
3. If the user's request is ambiguous, ask clarifying questions.
4. Be concise and professional in your responses.
5. If a query returns an empty result, suggest possible reasons to the user.
""")# 记忆,允许进行多轮对话
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)# -------------------- 4. 初始化Agent --------------------
# 使用CONVERSATIONAL_REACT_DESCRIPTION代理类型,它适合多轮对话场景
agent = initialize_agent(tools,llm,agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,verbose=True, # 开启详细日志,方便调试memory=memory,agent_kwargs={"system_message": system_message,"extra_prompt_messages": [MessagesPlaceholder(variable_name="chat_history")]},handle_parsing_errors=True # 优雅地处理解析错误
)# -------------------- 5. 运行Agent --------------------
if __name__ == "__main__":# 示例查询user_query_1 = "上一季度销售额最高的产品是什么?"user_query_2 = "这个产品的销售额超出了本季度预算吗?我们的预算是多少?"print(f"User: {user_query_1}")result_1 = agent.invoke({"input": user_query_1})print(f"Assistant: {result_1['output']}")print(f"\nUser: {user_query_2}")result_2 = agent.invoke({"input": user_query_2})print(f"Assistant: {result_2['output']}")
Prompt优化技巧









Transformer架构
自注意力机制(Self-Attention)让模型在处理一个词时,能同时权衡并聚焦于句子中所有其他词的重要性。比如处理“它”这个词时,模型能自动判断出“它”指的是前面的“苹果”还是“派”。
GPT(生成式预训练Transformer): 自回归模型,“作家”擅长根据上文生成下文。使用因果语言建模 (Causal Language Modeling)给定前文,预测下一个最可能的词。通过这个过程,模型学会了如何连贯地生成文本。用于:聊天机器人、文本创作、代码生成。
BERT(双向编码器表示): 自编码模型,“分析师” 擅长深度理解语言的含义。用于:情感分析、智能检索、内容分类。使用掩码语言建模 (Masked Language Modeling)。随机遮盖句子中15%的词,让模型预测被遮盖的词。这个过程让模型能深度理解每个词在上下文中的含义。
T5(文本到文本传输Transformer): “翻译官” 。把所有任务都当作“文本到文本”的转换。用于:摘要、翻译、问答。
LLaMA & 其他开源模型: “开源天才” 。能力接近GPT,但代码和权重公开,可自由商用和修改,是企业降本增效的首选。
RAG知识库

企业级案例:智能客服工单自动分类与起草系统
某大型电商平台:日均接收数万条客服工单,需人工阅读后分派给“物流”、“售后”、“投诉”等不同部门,并起草回复,效率低、成本高、易出错。
- 自动分类: 准确率 > 98%。
- 自动起草: 根据工单内容,自动生成初步回复草案,人工审核后即可发送。
- 响应速度: 单次处理(分类+起草) < 1秒。
- 成本: 支持业务增长,总拥有成本(TCO)低于原有纯人工方案。

①、从历史工单数据库提取<工单文本,分类标签,人工回复>,进行数据清洗与脱敏(去除用户ID、手机号等),格式化生成模型训练数据
// 对于物流话术模型
{"instruction": "你是一名电商物流客服,请根据用户工单内容,生成一段友好、专业的回复。","input": "用户问:我的订单88888为什么还没发货?","output": "尊敬的客户,您好!您的订单88888已审核通过,预计将在24小时内发出。发出后您将收到短信通知,感谢您的耐心等待!"
}
②、模型训练(微调)
- 分类模型:使用Transformers库的Trainer微调BERT
- 生成模型:使用PEFT库进行QLoRA微调
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer# 加载模型 (4bit量化加载,极大节省显存)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B-Instruct", device_map="auto",load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B-Instruct")# 配置LoRA
peft_config = LoraConfig(r=8,lora_alpha=32,target_modules=["q_proj", "v_proj"], # 针对LLaMA结构的关键模块lora_dropout=0.05,task_type="CAUSAL_LM"
)# 包装原模型
model = get_peft_model(model, peft_config)
# ... (后续配置训练参数并开始训练)
③、评估与测试
自动化测试:在预留测试集上计算分类准确率、生成文本的BLEU分数。
人工评估:最重要的环节。邀请业务专家对1000条模型生成结果进行盲测打分,确保达到上线标准。
④、高性能部署
推理引擎: 使用 vLLM 部署微调后的LLaMA模型,利用其PagedAttention技术应对高并发工单流量。
API服务: 使用 FastAPI 编写清晰的应用逻辑:
from fastapi import FastAPI
from pydantic import BaseModel
from classification_model import classify_ticket # 导入分类函数
from vllm import LLM, SamplingParamsapp = FastAPI()
# 加载vLLM引擎
llm_engine = LLM(model="path/to/merged-model", enable_prefix_caching=True) # 开启前缀缓存进一步优化class TicketRequest(BaseModel):content: str@app.post("/process_ticket/")
async def process_ticket(request: TicketRequest):# 1. 分类category = classify_ticket(request.content)# 2. 根据类别选择不同的提示模板prompt_templates = {"logistics": "作为物流客服,回复:{content}","after_sale": "作为售后客服,回复:{content}",# ...}prompt = prompt_templates[category].format(content=request.content)# 3. 生成回复sampling_params = SamplingParams(temperature=0.1, max_tokens=256)outputs = llm_engine.generate(prompt, sampling_params)draft_reply = outputs[0].textreturn {"category": category, "draft_reply": draft_reply}