【论文阅读 | IF 2025 | IF-USOD:用于水下显著目标检测的多模态信息融合交互式特征增强架构】
论文阅读 | IF 2025 | IF-USOD:用于水下显著目标检测的多模态信息融合交互式特征增强架构
- 1&&2. 摘要&&引言
- 3. 方法
- 3.1. 跨尺度交互嵌入模块
- 3.2. 全感知交叉注意力模块
- 3.3. 多尺度多模态解码器
- 4. 实验
- 4.1. 数据集
- 4.2. 实现细节
- 4.3. 评估指标
- 4.4. 与最先进技术的比较
- 4.5. 消融研究
- 5. 结论**

题目:IF-USOD: Multimodal information fusion interactive feature enhancement architecture for underwater salient object detection
期刊:IF(Information Fusion)
论文:paper
代码:未开源
年份:2025
1&&2. 摘要&&引言
水下显著目标检测(USOD)因其在各种水下视觉任务中的优越性能而受到越来越多的关注。尽管兴趣日益增长,但USOD的研究仍处于起步阶段,现有方法通常难以捕捉显著目标的远程上下文特征。
此外,这些方法经常忽略多模态信息的互补性。多模态信息融合可以使先前难以辨别的目标变得更容易检测,因为从不同源图像中捕获互补特征能够更准确地描述目标。
在这项工作中,我们探索了一种创新方法IF-USOD,该方法整合RGB和深度信息,并结合交互式特征增强,以推进水下显著目标的检测。
我们的方法首先利用Transformer和卷积神经网络架构的优势从源图像中提取特征。在此,我们采用了一种旨在优化特征融合的两阶段训练策略。随后,我们利用自注意力和交叉注意力机制来建模所提取特征之间的相关性,从而放大相关特征。最后,为了充分利用不同网络层的特征,我们引入了跨尺度学习策略以促进多尺度特征融合,通过生成粗粒度和细粒度的显著预测来提高水下显著目标的检测精度。
我们的主要贡献如下:
(1) 我们开发了一种用于深度和可见光图像多模态融合的交互式特征增强架构,用于水下显著目标检测,探索了多模态融合特征与下游视觉任务之间的特征桥接。
(2) 通过结合CNN和Transformer的优势,我们显著突出了适用于USOD任务的显著特征,同时基于交叉注意力机制引导多模态特征的融合和传播。
(3) 利用跨尺度协作学习策略,我们有效地利用了不同尺度和层次的融合特征,实现了更精确的水下显著目标检测。
3. 方法
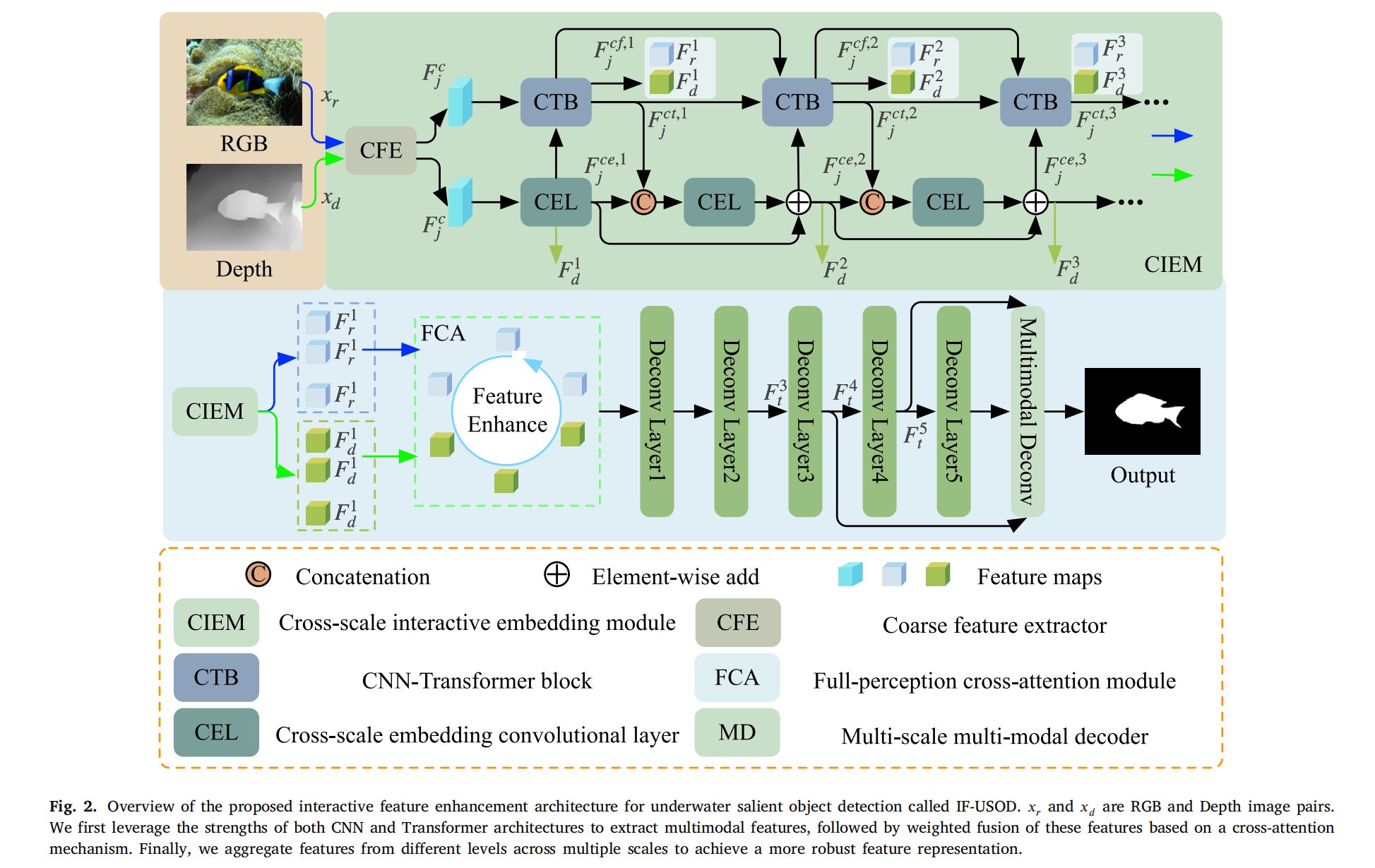
图2. 所提出的用于水下显著目标检测(underwater salient object detection, USOD)的交互式特征增强架构(命名为IF-USOD)概述。其中𝑥𝑟和𝑥𝑑分别表示红绿蓝(RGB)图像对和深度图像对。
该架构的工作流程如下:首先,利用卷积神经网络(Convolutional Neural Network, CNN)和Transformer架构两者的优势提取多模态特征;随后,基于交叉注意力机制对这些特征进行加权融合;最后,对多尺度下不同层级的特征进行聚合,以获得更稳健的特征表示。
提出的使用组合RGB和深度图像的水下显著目标检测交互式融合增强范式如图2所示。该范式包括两个阶段:(1)多模态特征融合阶段,和(2)水下显著目标检测阶段。在所提出的范式中,多模态特征融合促进了自上而下的水下显著目标检测。具体来说,首先通过跨尺度交互嵌入模块实现多模态特征交互和融合。然后,将融合后的特征输入全感知交叉注意力模块以进一步增强目标特征。最后,采用多尺度多模态解码器执行水下显著目标检测。
3.1. 跨尺度交互嵌入模块
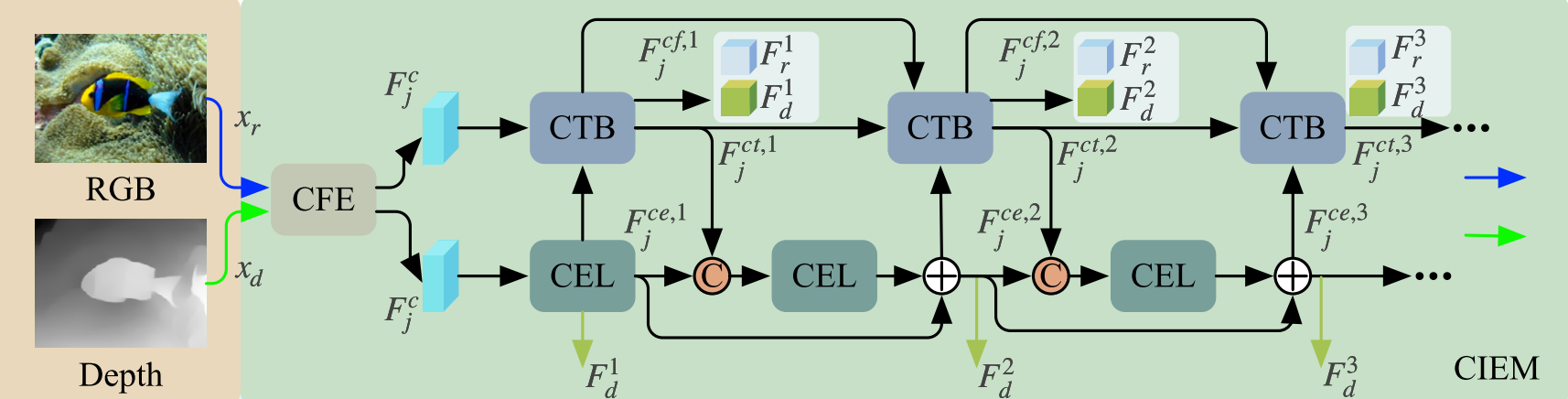
如图2所示,CIEM主要由跨尺度嵌入卷积层(CEL)和CNN-Transformer块(CTB)组成。CIEM模块之前是一个粗特征提取器(CFE),由两个卷积层和一个Leaky ReLU激活函数组成,用于捕获丰富的多通道特征图,方便后续模块进行特征提取。我们在不同级别的CTB和CEL之间交互地交换特征信息。具体来说,CEL捕获的特征被输入到CTB中,而CTB提取的特征被传输到下一个CEL。此外,我们采用跳跃连接来实现不同级别的CEL和CTB之间的信息传递。
首先,我们使用CFE从输入图像 (xr,xd)\left(x_{r}, x_{d}\right)(xr,xd) 中捕获粗特征,以支持后续CTB和CEL的特征提取。CFE的输出特征可以表示为:
Fjc=fcfe(cj),j=r,dF_{j}^{c}=f_{c f e}\left(c_{j}\right), j=r, dFjc=fcfe(cj),j=r,d ,
其中,fcfef_{c f e}fcfe 表示CFE的特征提取操作,j=r,dj=r, dj=r,d 代表输入图像 xrx_{r}xr 和 xdx_{d}xd。提取的特征 FjcF_{j}^{c}Fjc 随后被馈送到CTB和CEL。与ViT架构将输入图像转换为图像块(patches)以获得局部令牌(tokens)不同,我们使用由CFE输出的多通道特征图在同一空间位置 across different channels 的特征向量作为CTB中Transformer的局部令牌。
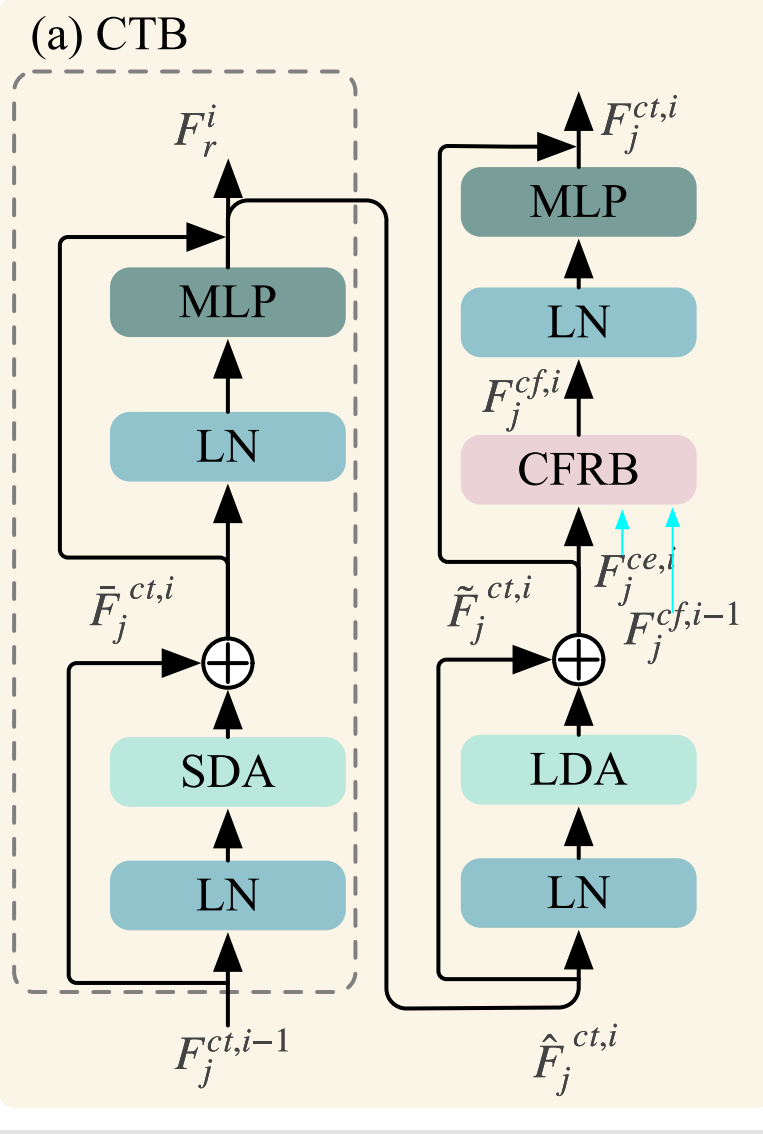
如图3(a)所示,CTB的网络结构包括层归一化(LN)、长短距离注意力模块(LSDA)、多层感知器(MLP)和卷积特征表示块(CFRB)。LSDA涉及短距离注意力(SDA)和长距离注意力(LDA),它们在不同的块之间交替使用。遵循经典的视觉Transformer设计,每个块内部都采用了残差连接。
对于第一个CTB,即 i=1i=1i=1,输入是 FjcF_{j}^{c}Fjc 和 Fjce,1F_{j}^{c e, 1}Fjce,1,其中 Fjce,1F_{j}^{c e, 1}Fjce,1 是第一个CEL的输出。对于第 i 个CTB (i≥2)(i\geq 2)(i≥2),令 Fjct,i−1F_{j}^{c t, i-1}Fjct,i−1 为第(i-1)个CTB的输出。需要注意的是,第 i 个CTB接收来自前一个CTB的两个输入。Fjct,i−1F_{j}^{c t, i-1}Fjct,i−1 被输入到LN,而 Fjct,i−1F_{j}^{c t, i-1}Fjct,i−1 被输入到CFRB。这里,Fjct,i−1F_{j}^{c t, i-1}Fjct,i−1 是前一个CTB中CFRB的输出特征。因此,CTB中第一个跳跃连接的输出是:
Fˉjct,i=fln,lsda/sda(Fjct,i−1)+Fjct,i−1\bar{F}_{j}^{c t, i}=f_{l n, l s d a/ s d a}\left(F_{j}^{c t, i-1}\right)+F_{j}^{c t, i-1}Fˉjct,i=fln,lsda/sda(Fjct,i−1)+Fjct,i−1 ,
其中,fln,lsda/sdaf_{l n, l s d a/ s d a}fln,lsda/sda 表示基于LN和SDA的特征提取。注意力机制分为两部分:短距离注意力和长距离注意力。
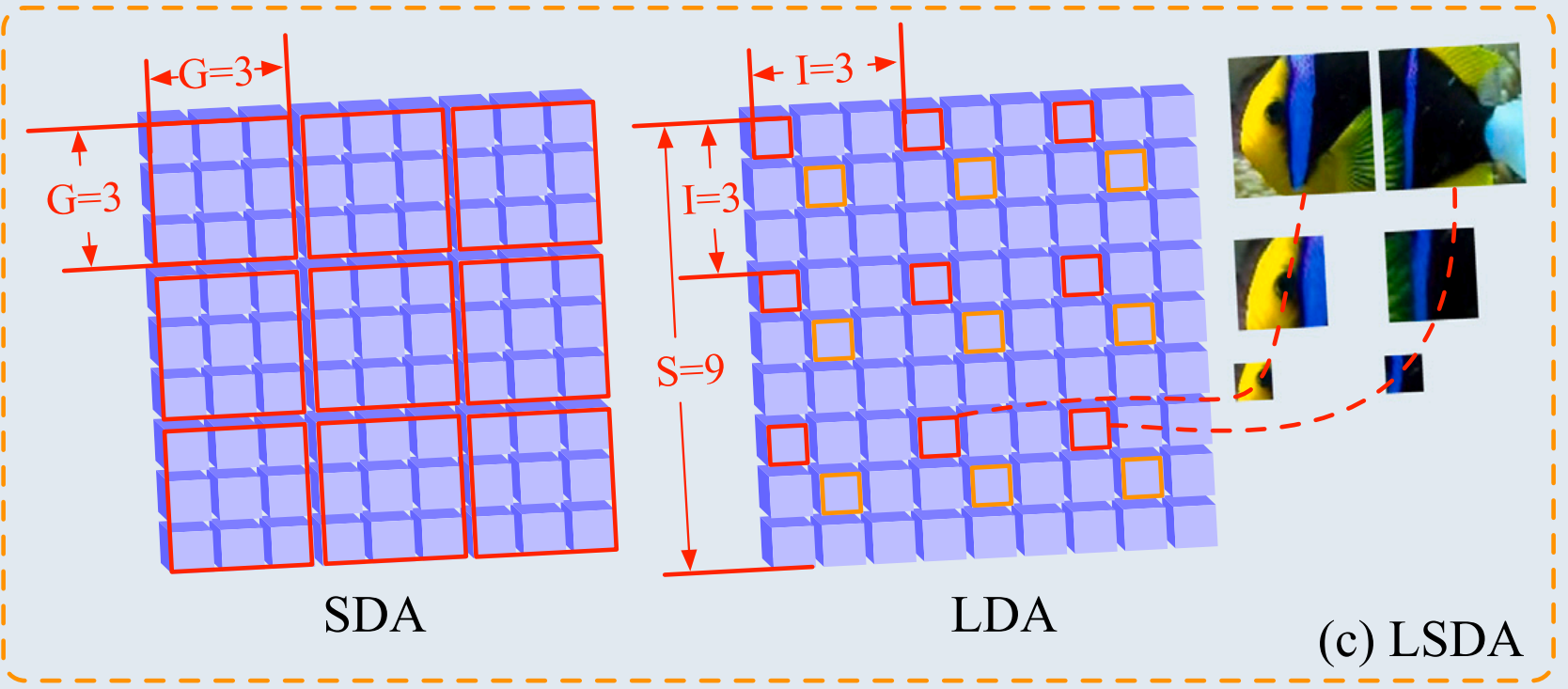
如图3©所示,对于SDA,所有相邻特征 within a G×GG\times GG×G grid 被分组在一起。在图3©所示的LDA中,输入特征大小为 S×SS\times SS×S,并以固定间隔 I 进行特征采样。在这种情况下,所有红色框属于一个特征组,而所有黄色框构成另一个特征组。对嵌入特征进行分组后,SDA和LDA都利用标准的自注意力机制。值得注意的是,嵌入大尺度的相邻图像块提供了足够的上下文来链接不同的特征,使得长程跨尺度注意力更容易计算且更有意义[57]。
第 i 个CTB中第一部分的输出特征,记为 F^jct,i\hat{F}_{j}{}^{c t, i}F^jct,i,可以表示为:
F^jct,i=fln,mlp(Fjct,i)+Fˉjct,i−1\hat{F}_{j}^{c t, i}=f_{l n, m l p}\left(F_{j}^{c t, i}\right)+\bar{F}_{j}^{c t, i-1}F^jct,i=fln,mlp(Fjct,i)+Fˉjct,i−1 ,
其中,fln,mlpf_{l n, m l p}fln,mlp 表示基于LN和MLP的特征提取。
CTB中第二部分的计算过程与第一部分类似,首先计算跳跃连接:
F~jct,i−1=fln,lsda/lda(F^jct,i−1)+F^jct,i−1\tilde{F}_{j}^{c t, i-1}=f_{l n, l s d a/ l d a}\left(\hat{F}_{j}^{c t, i-1}\right)+\hat{F}_{j}^{c t, i-1}F~jct,i−1=fln,lsda/lda(F^jct,i−1)+F^jct,i−1 ,
其中,fln,lsda/ldaf_{l n, l s d a/ l d a}fln,lsda/lda 表示基于LN和LDA的特征提取。
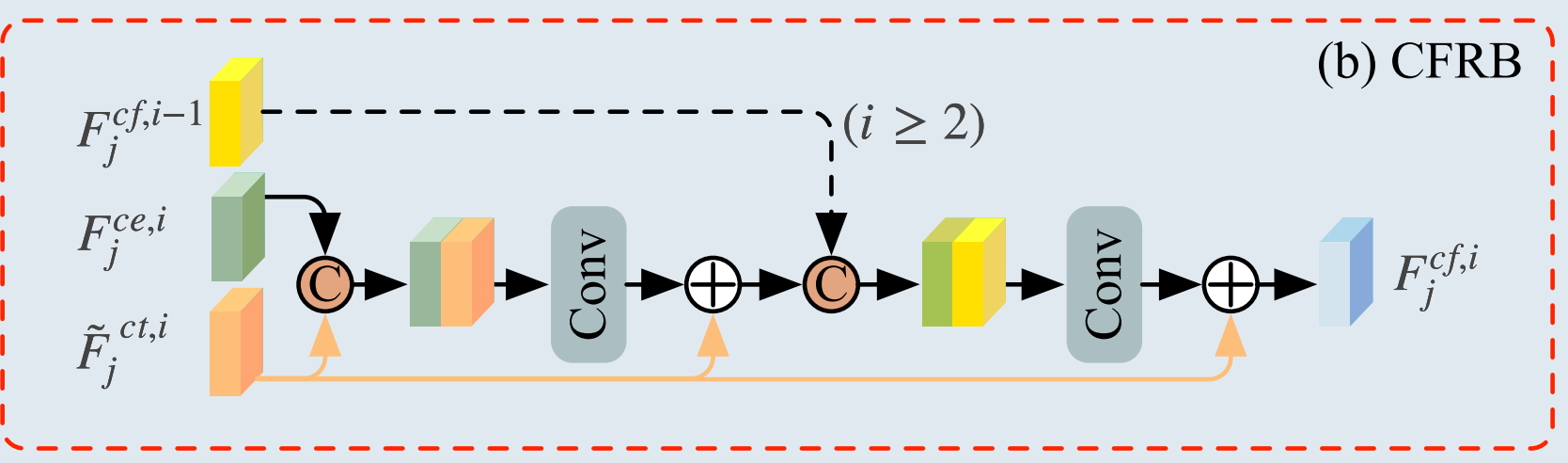
如图3(b)所示,CFRB主要包括特征连接、卷积层和跳跃连接。我们将CFRB嵌入到Transformer层中,以整合CNN和Transformer的优势。CFRB有三个输入:(1) Fjct,i−1F_{j}^{c t, i-1}Fjct,i−1,(2) 来自第(i-1)个CTB中CFRB的输出特征 Fjct,i−1F_{j}^{c t, i-1}Fjct,i−1,以及(3) 来自第 i 个CEL的输出特征 Fjce,iF_{j}^{c e, i}Fjce,i。因此,第 i 个CFRB的输出,记为 Fjcf,iF_{j}^{c f, i}Fjcf,i,可以表示为:
Fjf,i=fcfrb(Fˉjct,i,fjcf,i−1,Fjce,i)F_{j}^{f, i}=f_{c f r b}\left(\bar{F}_{j}^{c t, i}, f_{j}^{c f, i-1}, F_{j}^{c e, i}\right)Fjf,i=fcfrb(Fˉjct,i,fjcf,i−1,Fjce,i) ,
其中,fcfrbf_{c f r b}fcfrb 表示基于CFRB的特征提取操作。因此,第 i 个CTB的最终输出特征,记为 Fjct,iF_{j}^{c t, i}Fjct,i,可以表示为:
Fjct,i=fln,mlp(Fjcf,i)+F~jct,iF_{j}^{c t, i}=f_{l n, m l p}\left(F_{j}^{c f, i}\right)+\tilde{F}_{j}^{c t, i}Fjct,i=fln,mlp(Fjcf,i)+F~jct,i .

CIEM中使用的CEL架构如图4所示。CEL生成的令牌可以作为每个阶段CTB的输入。以第一个CEL为例,输入是原始图像。我们使用四种不同的卷积核大小进行图像块采样,所有四种卷积核的步长保持一致,以确保生成的嵌入特征数量相同。如图4所示,每个图像块共享相同的采样中心但尺度不同。最后,这四个图像块被连接并嵌入到一个单一的特征中。CEL通过对图像进行不同大小卷积核的多尺度采样,并将这些多尺度信息融合到一个嵌入表示中,从而丰富了输入特征的表示。
具体来说,采样和嵌入过程通过四个卷积层完成。以图4中D维(D=96D=96D=96)特征为例,我们使用大小为 4×4,8×8,16×16,32×324\times 4,8\times 8,16\times 16,32\times 324×4,8×8,16×16,32×32 的卷积核来提取相应尺度的特征图,每个的步长均为4。每个特征图被处理成多个图像块,然后将四个不同尺度上对应位置的图像块进行嵌入并转换为统一的嵌入表示。CEL的输出,记为 Fjce,iF_{j}^{c e, i}Fjce,i,可以表示为:
Fjce,i=Concat(Embed(ConvKi(I))),i=1,2,3,4F_{j}^{c e, i}=\operatorname{Concat}\left(\operatorname{Embed}\left(\operatorname{Conv}_{K i}(I)\right)\right), i=1,2,3,4Fjce,i=Concat(Embed(ConvKi(I))),i=1,2,3,4 ,
其中,I∈RH×W×CI\in R^{H\times W\times C}I∈RH×W×C 代表输入图像,ConvKi\operatorname{Conv}_{K i}ConvKi 表示卷积核大小为 KKK 的卷积操作,Embed(⋅)\operatorname{Embed}(\cdot)Embed(⋅) 表示将特征图块嵌入为向量表示,Concat(⋅)\operatorname{Concat}(\cdot)Concat(⋅) 表示多个嵌入向量的连接。需要注意的是,我们为大的卷积核分配较低的维度,为小的卷积核分配较高的维度,从而显著降低计算成本。
在CIEM模块中,我们促进了不同层次上CNN特征和Transformer特征的交互,有效实现了CNN和Transformer在特征提取上的优势互补,增强了所捕获特征对图像目标的表示能力。
3.2. 全感知交叉注意力模块
考虑到浅层特征通常包含更丰富的纹理和边缘细节,而深层特征包含更高级的语义信息,直接融合对应层次的特征不可避免地会导致一些有价值信息的丢失。为了解决这个问题,我们设计了一种全感知的特征融合机制。该机制利用注意力模块交互式地融合不同层次的特征,从而进一步增强弱边缘和纹理特征。
FCA模块的架构如图5所示。
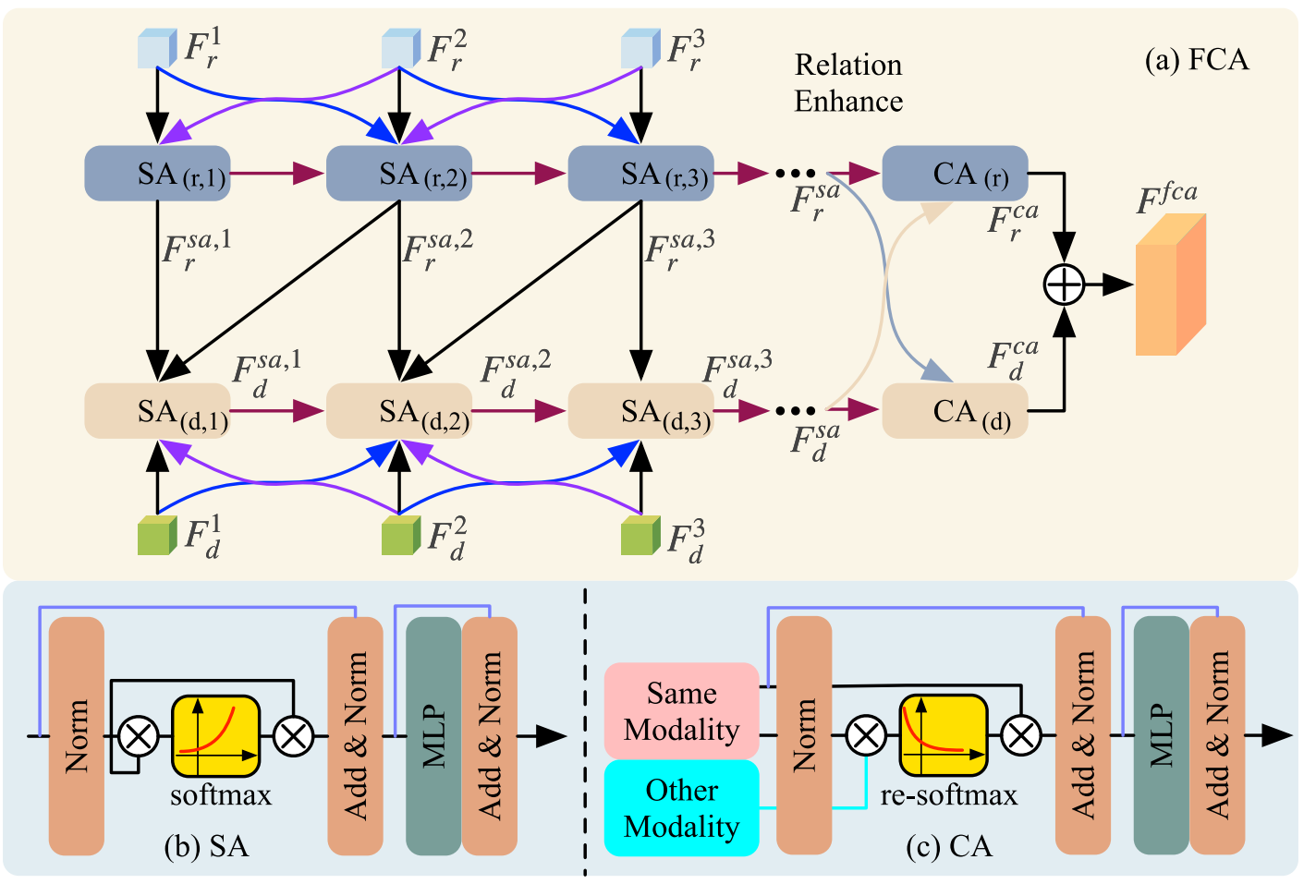
我们使用两个具有不同参数的分支从两种模态中提取特征。每种模态的特征首先输入到一个自注意力(SA)模块中以增强内部相关性。增强后的特征然后作为交叉注意力(CA)块的输入。SA遵循标准的Transformer架构,其中包括一个自注意力模块,而CA则是一种专注于不相关信息的交叉注意力机制。对于第一个SA,SA1S A^{1}SA1 的输入是 Fr1F_{r}^{1}Fr1 和 Fr2F_{r}^{2}Fr2,而 SAd1S A_{d}^{1}SAd1 的输入是 Fd1,Fd2,Frsa,1F_{d}^{1}, F_{d}^{2}, F_{r}^{s a, 1}Fd1,Fd2,Frsa,1 和 Frsa,2F_{r}^{s a, 2}Frsa,2。对于 SAi(i≥2)S A^{i}(i\geq 2)SAi(i≥2),CTB的输出 Fji(i=2,3,…,n)F_{j}^{i}(i=2,3,\ldots, n)Fji(i=2,3,…,n) 用作 SAriS A_{r}^{i}SAri 的输入。SA的输出可以计算为:
{Frsa,i=frsa,i(Fri−1,Fri,Fri+1,frsa,i−1),Fdsa,i=fdsa,i(Fdi−1,Fdi,Fdi+1,fdsa,i−1,frsa,i,frsa,i+1),\begin{align*}&\left\{\begin{array}{l}F_r^{s a, i}=f_r^{s a, i}\left(F_r^{i-1}, F_r^i, F_r^{i+1}, f_r^{s a, i-1}\right),\\ F_d^{s a, i}=f_d^{s a, i}\left(F_d^{i-1}, F_d^i, F_d^{i+1}, f_d^{s a, i-1}, f_r^{s a, i}, f_r^{s a, i+1}\right),\end{array}\right.\\ &\end{align*}{Frsa,i=frsa,i(Fri−1,Fri,Fri+1,frsa,i−1),Fdsa,i=fdsa,i(Fdi−1,Fdi,Fdi+1,fdsa,i−1,frsa,i,frsa,i+1),
其中,Frsa,iF_{r}^{s a, i}Frsa,i 表示可见光图像的SA输出,Fdsa,iF_{d}^{s a, i}Fdsa,i 表示深度图像的SA输出,frsa,if_r^{s a, i}frsa,i 是可见光图像的特征调制SA,fdsa,if_{d}^{s a, i}fdsa,i 是深度图像的特征调制SA。SA模块的计算公式如下:
{[Qj,Kj,Vj]=xjsaUqkv,xjsa=xjsa+norm(softmax(QjKjTd)Vj),s.t.Uqkv∈Rd×3d,xjsa=xjsa+MLP(norm(xjsa)),\left\{\begin{array}{l}{\left[Q_{j}, K_{j}, V_{j}\right]=x_{j}^{s a} U_{q k v},}\\ x_{j}^{s a}=x_{j}^{s a}+\operatorname{norm}\left(\operatorname{softmax}\left(\frac{Q_{j} K_{j}^{T}}{\sqrt{d}}\right) V_{j}\right),\quad\text{ s.t.} U_{q k v}\in R^{d\times 3 d},\\ x_{j}^{s a}=x_{j}^{s a}+M L P\left(\operatorname{norm}\left(x_{j}^{s a}\right)\right),\end{array}\right.⎩⎨⎧[Qj,Kj,Vj]=xjsaUqkv,xjsa=xjsa+norm(softmax(dQjKjT)Vj), s.t.Uqkv∈Rd×3d,xjsa=xjsa+MLP(norm(xjsa)),
其中,xjsax_{j}^{s a}xjsa 表示SA的输入,Qj,KjQ_{j}, K_{j}Qj,Kj 和 VjV_{j}Vj 表示输入的不同表示,d是输入向量的维度,UqkvU_{q k v}Uqkv 是一个可以通过全连接层学习的变换矩阵。norm(⋅\cdot⋅) 表示线性归一化操作,MLP(⋅)M L P(\cdot)MLP(⋅) 表示多层感知器。可见光图像和深度图像的SA特征随后被馈送到CA。CA的输出可以计算为:
{Frca=frca(Frsa,Fdsa),Fdca=fdca(Frsa,Fdsa),\begin{align*}&\begin{cases}& F_r^{c a}=f_r^{c a}\left(F_r^{s a}, F_d^{s a}\right),\\ & F_d^{c a}=f_d^{c a}\left(F_r^{s a}, F_d^{s a}\right),\end{cases}\end{align*}{Frca=frca(Frsa,Fdsa),Fdca=fdca(Frsa,Fdsa),
其中,FrcaF_{r}^{c a}Frca 表示可见光图像的CA输出,FdcaF_{d}^{c a}Fdca 表示深度图像的CA输出,frcaf_{r}^{c a}frca 是可见光图像的特征调制CA,fdcaf_{d}^{c a}fdca 是深度图像的特征调制CA。最后,CA输出 FrcaF_{r}^{c a}Frca 和 FdcaF_{d}^{c a}Fdca 被连接起来形成FCA模块的输出,记为 FfcaF^{f c a}Ffca。
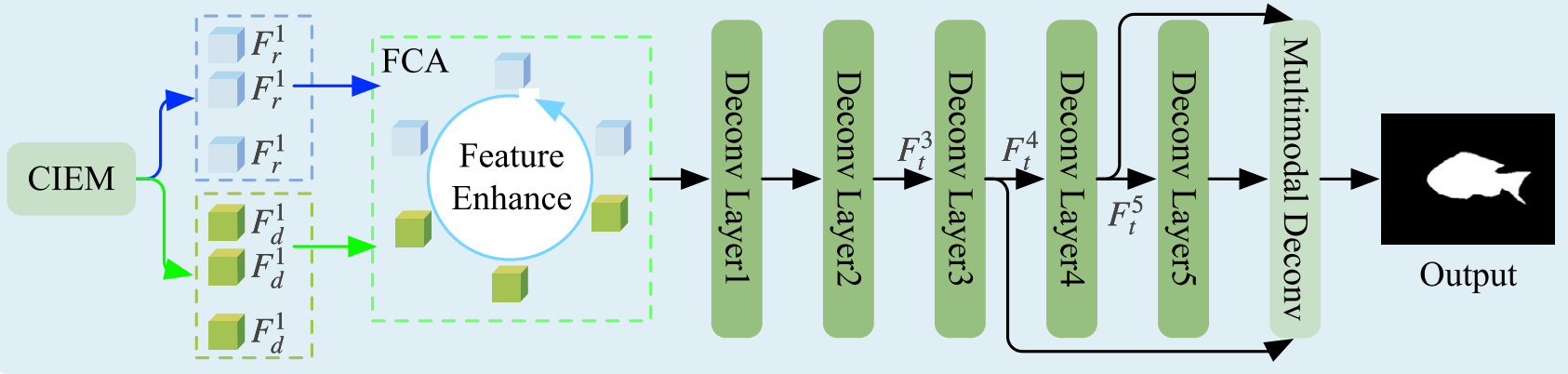
3.3. 多尺度多模态解码器
在学习到融合特征后,我们引入了一个多尺度多模态解码器来预测水下目标显著图。与传统的对称编码器-解码器架构不同,我们采用了一种具有多级特征融合策略的卷积解码器,将融合特征解码为显著图。该解码器包含六个阶段。前五个阶段结构相同,每个阶段包含三个卷积层、批归一化层和ReLU激活函数。如图6所示,最终的解码器阶段涉及将解码后的特征 Ft3,Ft4F_{t}^{3}, F_{t}^{4}Ft3,Ft4 和 Ft5F_{t}^{5}Ft5 输入到多尺度多模态解码器模块。
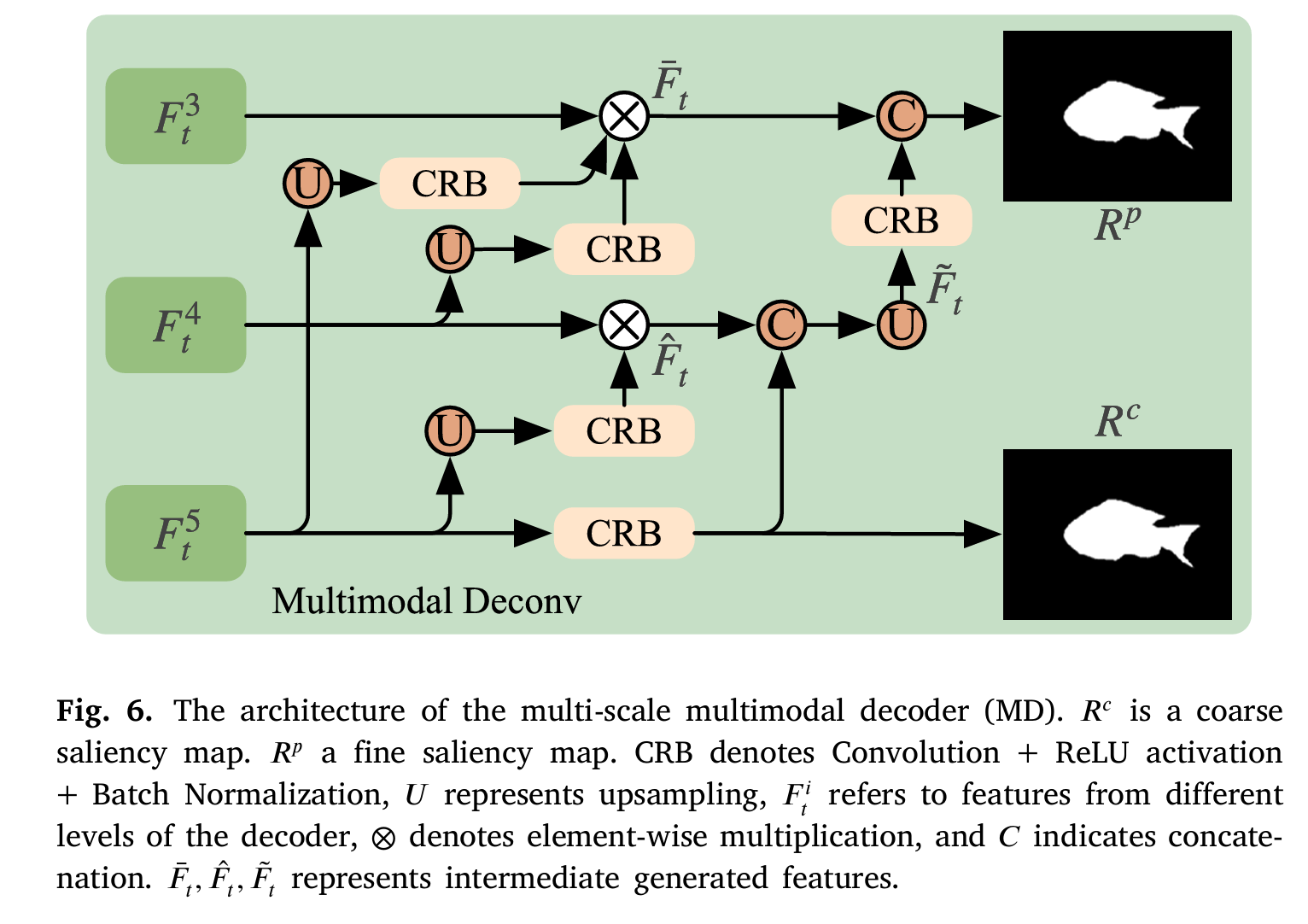
在MD模块中,我们利用了一个上下文模块和级联的CBR(卷积-批归一化-激活)层来预测显著图。具体来说,我们同时预测两个显著图:一个粗粒度显著图 RcR^{c}Rc 和一个细粒度显著图 RpR^{p}Rp。粗粒度显著图提供目标的大致位置和形状信息,而细粒度显著图则进一步细化并优化目标的边界和细节。MD模块的输出可以表示为:
{Rc=CRB(Ft5),Rp=Concat(Fˉt,CRB(F~t)),Fˉt=Ft3⊗CRB(UP(Ft4))⊗CBR(UP(Ft5)),Fˉt=UP(Concat(F^t,CRB(Ft5))),F^t=Ft4⊗CRB(UP(Ft5)),\left\{\begin{array}{l}R^{c}=C R B\left(F_{t}^{5}\right),\\ R^{p}=\operatorname{Concat}\left(\bar{F}_{t}, C R B\left(\tilde{F}_{t}\right)\right),\\ \bar{F}_{t}=F_{t}^{3}\otimes C R B\left(U P\left(F_{t}^{4}\right)\right)\otimes C B R\left(U P\left(F_{t}^{5}\right)\right),\\ \bar{F}_{t}=U P\left(\operatorname{Concat}\left(\hat{F}_{t}, C R B\left(F_{t}^{5}\right)\right)\right),\\ \hat{F}_{t}=F_{t}^{4}\otimes C R B\left(U P\left(F_{t}^{5}\right)\right),\end{array}\right.⎩⎨⎧Rc=CRB(Ft5),Rp=Concat(Fˉt,CRB(F~t)),Fˉt=Ft3⊗CRB(UP(Ft4))⊗CBR(UP(Ft5)),Fˉt=UP(Concat(F^t,CRB(Ft5))),F^t=Ft4⊗CRB(UP(Ft5)),
其中,CRB 表示卷积(Convolution)+ ReLU激活 + 批归一化(Batch Normalization),FtiF_{t}^{i}Fti 指的是来自解码器不同层次的特征。Fˉt,F^t,F~t\bar{F}_{t},\hat{F}_{t},\tilde{F}_{t}Fˉt,F^t,F~t 表示中间生成的特征。⊗\otimes⊗ 表示逐像素乘法,UP 指上采样。通过这种多模态解码器结构,我们可以有效地组合和利用不同模态的特征,从而显著提高水下目标显著性检测的准确性和鲁棒性。
粗粒度和细粒度显著图的组合旨在充分利用不同尺度的特征信息,从而增强模型的整体性能。粗粒度显著图提供全局上下文信息,捕获目标的大致位置和整体轮廓。这种全局信息有助于缩小目标的搜索范围,并为模型提供初始的焦点,特别是在复杂场景或具有显著背景噪声的情况下。另一方面,细粒度显著图专注于捕获目标的局部细节和边界信息,这对于精确描绘目标的边界和形状至关重要,尤其是在需要区分细微差异或相似物体的场景中。两者的结合使得模型能够首先通过粗粒度显著图快速聚焦于目标的大致区域,然后利用细粒度显著图进一步细化和优化目标的边界和细节特征。这种多尺度特征融合在提高检测精度的同时,确保了处理复杂场景时具有更强的鲁棒性。
3.4. 训练策略
为了增强所提出网络的特征捕获能力,我们采用了一种两阶段训练策略。首先,为每种模态构建一个编码器-解码器网络以重建输入图像。随后,使用多模态输入和提出的总损失函数来训练整个网络。
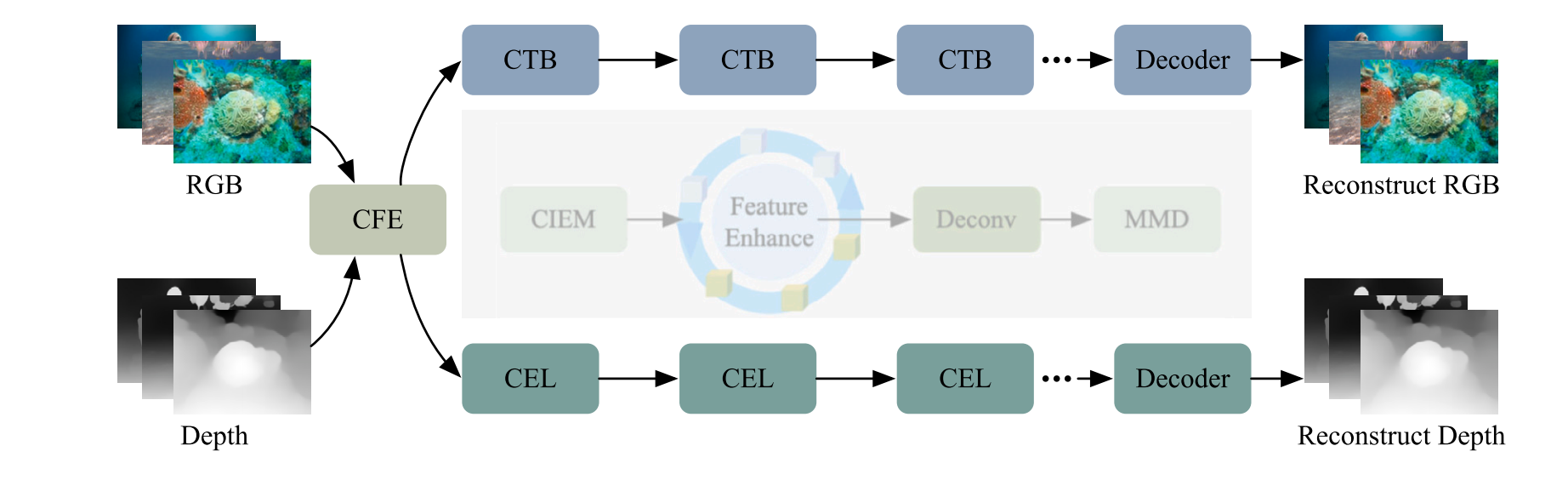
在第一阶段,我们的目标是训练编码器以提取丰富的特征,为后续的USOD任务奠定基础。由于RGB图像和深度图像之间存在差异,我们使用不同的编码器-解码器网络来重建输入图像。如图7所示,RGB分支使用Transformer架构,而深度分支使用卷积架构。此外,我们使用跳跃连接来保留网络中的深层和浅层特征。在第一阶段的训练过程中,我们使用结构相似性指数(SSIM)损失来训练网络。
在第一阶段,RGB和深度图像编码器-解码器网络是独立训练的,这使得网络能够专注于从每种单一模态中提取丰富的特征。鉴于RGB和深度图像之间的特征存在显著差异,分别使用Transformer和卷积架构有助于更好地捕获每种模态的特征信息。通过使用SSIM损失函数训练网络,确保了重建图像在感知质量上的一致性,有效增强了编码器的特征提取能力。这种分阶段的训练方法使得编码器在后续任务中能够提取具有更高精度和更好鲁棒性的特征。
第二阶段的训练涉及标准的端到端训练过程,如图2所示。在此阶段,整个CIEM、FCA和MD模块被联合训练。在第二阶段,我们使用加权二元交叉熵(wBCE)损失、加权IoU(wIoU)损失、Dice损失和SSIM损失来监督网络的训练。损失函数的具体配置在第3.5节详述。需要注意的是,第一阶段训练得到的编码器参数并非固定不变,而是被用作预训练模型。
在第二阶段,整个网络使用多模态输入进行训练,在此期间CIEM、FCA和MD模块得到充分优化。多模态输入的使用使得网络能够促进不同模态间信息的交互和融合,从而增强了模型对复杂场景的适应性。wBCE、wIoU、Dice和SSIM等多种损失函数的组合使用,使得网络能够在多个目标下进行优化。这种多损失函数的联合监督有助于网络在提高分类精度的同时减少假阳性和假阴性,从而增强了图像分割的精细度和结构一致性。
使用第一阶段获得的编码器参数作为预训练模型,为第二阶段的训练提供了良好的初始化。这种方法不仅加速了网络的收敛速度,还有效地缓解了随机初始化可能带来的不稳定性。此外,由于预训练模型已经具备了强大的特征提取能力,网络在多模态联合训练期间能够更快地调整和优化不同模态间的特征融合,从而获得优异的分割结果。两阶段训练策略通过分阶段的特征提取和融合优化,使得所提出的网络在处理复杂的USOD任务时能够充分发挥其特征捕获和融合能力。这不仅提高了网络的训练效率和收敛性,而且在多模态数据联合训练中实现了高精度和高鲁棒性的图像分割。
3.5. 损失函数
我们使用加权二元交叉熵(Weighted Binary Cross-Entropy)损失和加权IoU(Weighted IoU)损失来监督网络训练。在显著性检测中,目标区域(正样本)通常远小于背景区域(负样本)。wBCE通过加权有效平衡了正负样本之间的不平衡,从而提高了对目标区域的检测性能。加权机制使模型能够更多地关注难以分类的样本,增强了模型的鲁棒性和泛化能力。IoU是显著性检测中常用的评估指标,wIoU损失直接对IoU进行优化,使得模型在训练过程中能更好地改善预测结果与真实值(GT)之间的重叠度。wIoU损失在优化过程中有效抑制了假阳性和假阴性,减少了误检和漏检,从而提高了检测精度。
给定输出的粗粒度显著图 RcR^{c}Rc 和细粒度显著图 RpR^{p}Rp,粗损失计算如下:
Lcoarse=Lbcew(Rc,GT)+Liouw(Rc,GT),(14){\mathcal L}_{coarse}={\mathcal L}_{bce}^{w}\left(R^{c},GT\right)+{\mathcal L}_{iou}^{w}\left(R^{c},GT\right),\qquad(14)Lcoarse=Lbcew(Rc,GT)+Liouw(Rc,GT),(14)
细损失计算为:
Lprecise=Lbcew(Rp,GT)+Liouw(Rp,GT)\mathcal{L}_{\text{precise}}=\mathcal{L}_{\text{bce}}^{w}\left(R^{p}, G T\right)+\mathcal{L}_{\text{iou}}^{w}\left(R^{p}, G T\right)Lprecise=Lbcew(Rp,GT)+Liouw(Rp,GT) ,(15)
SOD总损失可表示为:
Lsod=Lcoarse+Lprecise\mathcal{L}_{\text{sod}}=\mathcal{L}_{\text{coarse}}+\mathcal{L}_{\text{precise}}Lsod=Lcoarse+Lprecise 。(16)
wBCE和wIoU损失函数的结合使用可以在样本平衡和重叠度优化方面实现互补 benefits,显著提高显著性检测的整体性能。对粗粒度和细粒度显著图的联合监督使得模型能够在不同层次上进行优化,从而产生更精细和准确的显著性检测结果。
此外,我们还采用Dice损失和SSIM损失来进一步监督模型的训练过程。Dice损失评估两个样本之间的相似性,而SSIM损失监督图像内的结构信息,使模型能够更好地学习显著目标的边界信息。因此,总损失函数可以表示为:
Ltotal=Lsod+Ldice+Lssim\mathcal{L}_{\text{total}}=\mathcal{L}_{\text{sod}}+\mathcal{L}_{\text{dice}}+\mathcal{L}_{\text{ssim}}Ltotal=Lsod+Ldice+Lssim 。(17)
4. 实验
我们在USOD10K和COD10K等水下显著目标检测数据集上评估模型。这些数据集包含RGB图像和相应的深度图,支持多模态融合。此外,我们还在USOD和SOC数据集上进行了泛化性研究,以验证模型的泛化性能。使用S-measure、F-measure、E-measure和MAE等经典评估指标进行定量分析。还提供了不同方法的可视化比较,以证明IF-USOD模型在水下显著目标检测方面的优越性。
4.1. 数据集
USOD10K是一个专为水下显著目标检测设计的大规模数据集[4]。该数据集包含10,255张水下图像,涵盖12种不同的水下场景和20种不同类型的显著目标。USOD10K不仅包含RGB图像,还包括每张图像对应的深度图和边界标注。USOD10K的目标是通过提供反映真实水下条件的多样化和复杂图像集,来改进水下场景中显著目标的检测和分割。
COD10K数据集是一个专为伪装目标检测设计的高质量数据集[58]。它包含10,000多张高分辨率图像,覆盖了广泛的场景和目标类型。其中,水下检测目标是伪装目标检测任务的关键组成部分。COD10K数据集中的水下目标主要包括各种海洋生物,如鱼类、海龟、海蛇、海星和海胆。这些生物通常具有保护色或伪装能力,使它们能够在自然环境中躲避捕食者或捕食。除了自然生物,数据集还可能包含一些人工物体,如沉船、潜水设备和其他碎片,这些物体在水下环境中经常与周围背景融为一体,进一步增加了检测难度。伪装目标检测任务本身具有挑战性,因为伪装目标通常在颜色、纹理和形状上与背景高度相似,使得传统的图像分割和检测算法难以有效识别。
USOD数据集[53]专为水下环境中的显著目标检测而设计。USOD数据集包含来自海洋、湖泊和河流等各种场景的数千张水下图像,代表了广泛的环境。该数据集提供中到高分辨率的图像,通常范围从 300×300300\times 300300×300 到 600×600600\times 600600×600 像素,保留了足够的细节,使算法能够提取显著目标的有意义特征。数据集中的显著目标包括各种水下实体,如鱼类、海洋动物、珊瑚礁、水下物体和植物。
SOC数据集是一个专为研究视觉搜索和显著性检测而设计的高质量数据集[59]。SOC主要用于不同场景和背景下的显著目标检测任务研究。SOC数据集包含来自80多个常见类别的3569张图像,其中包括2412张训练图像和1159张测试图像。这些图像具有各种复杂的背景和多种类型的显著目标,旨在为计算机视觉领域的显著性检测算法提供标准化基准。在本文中,我们使用SOC数据集来评估我们模型的泛化性能。
请注意,当数据集中未提供深度图像时,我们使用DPT方法[60]生成相应的深度图像以实现多模态训练。
4.2. 实现细节
我们在USOD10K和COD10K数据集上进行了实验。在训练阶段,每对RGB和深度图像被随机裁剪成 140×140140\times 140140×140 的图像块。我们使用Adam优化器在训练期间更新参数,批量大小设置为4。初始学习率设置为 1×10−41\times 10^{-4}1×10−4。在整个网络训练过程中,学习率按照余弦调度逐渐衰减至 1×10−61\times 10^{-6}1×10−6。为了公平比较,所有基于深度学习的方法都使用默认设置在USOD10K数据集上重新训练,并使用相同的评估代码评估结果。
4.3. 评估指标
在这项工作中,我们使用以下四个指标来评估模型的性能。
结构相似性度量(SαS_{\alpha}Sα)[61]评估预测图像与真实值(GT)之间的结构相似性。SαS_{\alpha}Sα 通常结合亮度、对比度和结构信息来评估分割结果的质量,能更好地反映图像的感知质量。
Sα=αSo+(1−α)SrS_{\alpha}=\alpha S_{o}+(1-\alpha) S_{r}Sα=αSo+(1−α)Sr ,
其中,SoS_{o}So 和 SrS_{r}Sr 分别表示对象感知和区域感知的结构相似性,α\alphaα 设置为0.5。
加权F-measure(FβωF_{\beta}^{\omega}Fβω)[62]结合了精确率和召回率指标,引入加权因子 β\betaβ 以强调精确率和召回率之间的平衡。FβωF_{\beta}^{\omega}Fβω 通过调整精确率和召回率的不同权重,有效解决了数据集不平衡的问题,使其在实际应用中更加灵活。
Fβω=(1+β2)PωRωβ2Pω+RωF_{\beta}^{\omega}=\left(1+\beta^{2}\right)\frac{P^{\omega} R^{\omega}}{\beta^{2} P^{\omega}+R^{\omega}}Fβω=(1+β2)β2Pω+RωPωRω ,
其中,β\betaβ 表示检测的有效性,PωP^{\omega}Pω 表示加权精确率,RωR^{\omega}Rω 表示加权召回率。
自适应E-measure(EξE_{\xi}Eξ)[63]同时考虑了像素级匹配和图像级统计信息。EξE_{\xi}Eξ 特别关注分割图像与真实值之间的相似性,包括整体结构和局部细节的对齐。
Eξ=1w×h∑x=1w∑y=1hΦ(x,y)E_{\xi}=\frac{1}{w\times h}\sum_{x=1}^{w}\sum_{y=1}^{h}\Phi(x, y)Eξ=w×h1∑x=1w∑y=1hΦ(x,y) ,
其中,h 和 w 分别表示分割结果图像的高度和宽度。Φ\PhiΦ 是增强对齐矩阵。
平均绝对误差(MAE)测量预测结果与真实标签之间绝对误差的平均值,表示预测值与实际值之间的差异。MAE 直接直观地反映了预测结果的偏差。
MAE=1n∑i=1n∣yi−y^i∣M A E=\frac{1}{n}\sum_{i=1}^{n}\left|y_{i}-\hat{y}_{i}\right|MAE=n1∑i=1n∣yi−y^i∣
其中,yiy_{i}yi 代表真实值,y^i\hat{y}_{i}y^i 代表预测值。
4.4. 与最先进技术的比较
在本节中,我们将提出的方法与其他最先进的方法进行比较。定量评估和定性分析的结果清楚地证明了我们提出的方法的优势。我们将我们的方法与13种先进方法进行了比较,包括深度SOD方法:F3Net[15]、CSNet[13]、MFNet[6]、PSGLoss[10];深度RGB-D SOD方法:DANet[7]、BTSNet[17]、CMX[14]、HiDANet[12];USOD方法:TC-USOD[4]、Dual-SAM[2]、SwinFusion[23];以及深度RGB-T方法:BDLFusion[20]、CrossFuse[21]。
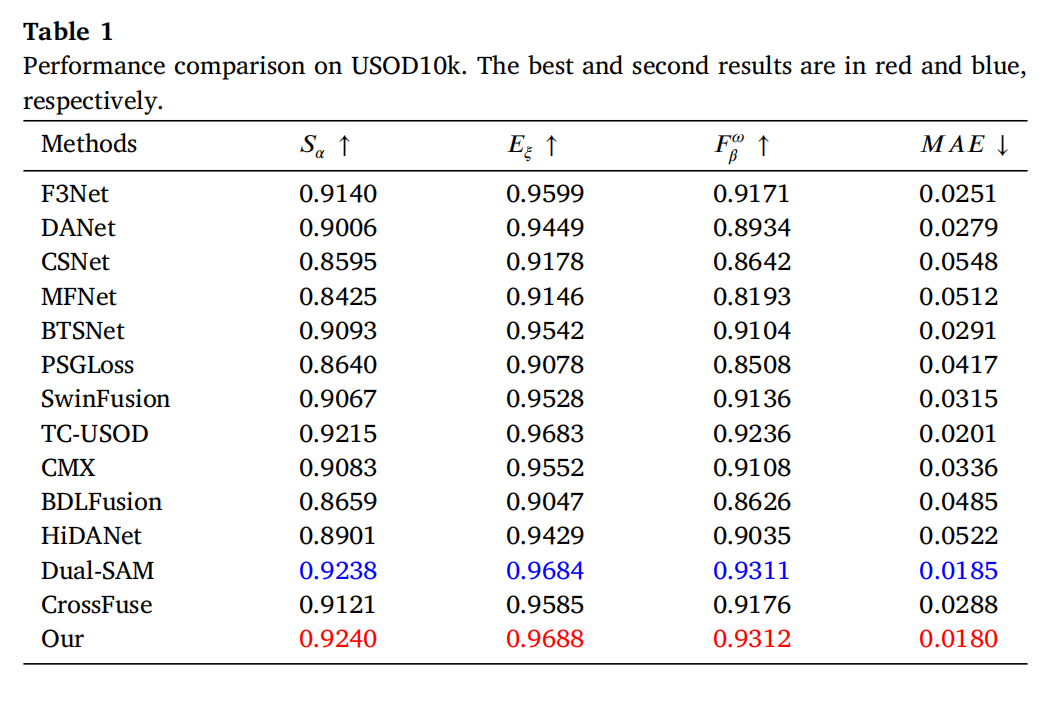
定量评估。 表1总结了13种显著目标检测方法在USOD10K数据集上的性能。从表中可以清楚地看出,我们的方法在所有定量评估指标上均优于所有竞争对手,表现出更高的分割精度和更低的错误率。TC-USOD和Dual-SAM也表现良好,特别是在 EξE_{\xi}Eξ 和 FβωF_{\beta}^{\omega}Fβω 指标上,接近我们的方法,但在MAE上略有差距。F3Net、BTSNet和CrossFuse在S和E指标上表现良好,但在MAE方面不如我们的方法。CSNet和MFNet在所有指标上得分相对较低,尤其是在MAE方面,表明其在处理错误方面性能较差。具体来说,在 SαS_{\alpha}Sα 评估中,我们的方法分别比TC-USOD和DualSOD高出0.0025和0.0002。它比CSNet高出0.0645,表明其在保持图像整体结构一致性方面能力更强。在 EξE_{\xi}Eξ 评估中,我们的方法超过了TC-USOD的0.9683和Dual-SAM的0.9684,在边缘对齐一致性方面显示出轻微优势。与MFNet相比,我们的方法提高了0.1263,进一步证明了在细节捕获和边缘精度方面的显著增强。在 FβωF_{\beta}^{\omega}Fβω 评估中,我们的方法在 FβωF_{\beta}^{\omega}Fβω 上比得分较低的SwinFusion高出0.0176,展示了其在平衡精确率和召回率方面的卓越能力。
对表1的综合分析表明,MFNet和PSGLoss在处理图像复杂性和细节方面存在某些不足,这使得模型在特定场景中难以准确对齐边缘,从而影响整体分割性能。HiDANet和BDLFusion可能在提取和融合不同信息来源的特征方面遇到困难,特别是在复杂场景或多模态输入的情况下,模型可能难以保持高分割精度,导致整体性能下降。SwinFusion和CrossFuse在不同评估指标上取得了更好的结果,这主要归功于它们有效处理多尺度信息、优化的特征融合策略以及精确的细节捕获能力。SwinFusion的优势在于其Transformer架构和多尺度特征处理能力,而CrossFuse则通过跨模态信息融合和特征对齐策略确保了在复杂场景中的鲁棒性和高精度。
我们的方法在所有四个评估指标上都表现出色,尤其是在MAE和 SαS_{\alpha}Sα 方面。这一成功很大程度上归功于跨尺度交互嵌入模块和全感知交叉注意力模块,它们不仅有效捕获了多模态特征,还促进了这些特征之间的交互学习,从而充分发挥了多模态特征的互补优势。
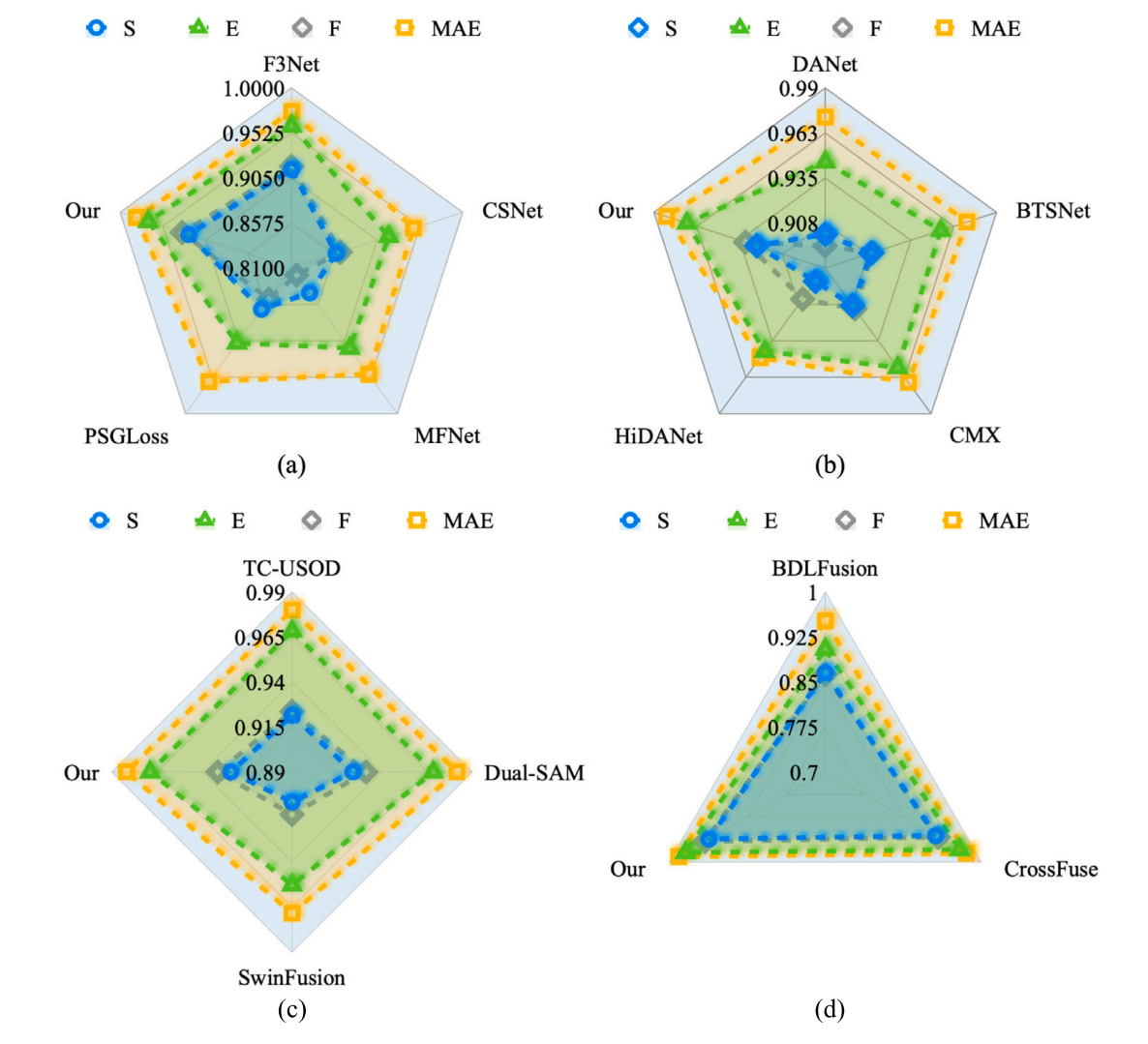
图8. 定量评估结果可视化 (a) 与经典多模态融合方法的对比(The comparison with classical multimodal fusion methods) (b) 与双流融合架构的对比(The comparison with dual-stream fusion architectures) © 本文方法与当前最先进方法的对比(The comparison of our method with state-of-the-art approaches,原文“The compares”存在语法误差,已修正为“The comparison”) (d) 与注意力机制的对比(The comparison with attention mechanisms)
图8进一步说明了不同算法在USOD10k数据集上的评估结果。我们使用雷达图来更好地展示定量评估结果。图8(a)展示了与经典多模态融合方法的比较。F3Net通过多层次特征融合和注意力机制增强了模型捕获细节的能力。然而,在 SαS_{\alpha}Sα 评估中,由于其在整合全局信息方面的不足,F3Net的结构相似性略低。图8(b)展示了与双流融合架构的比较。DANet采用双重注意力机制,有效捕获全局上下文信息,从而提高了其在S和E指标上的性能。图8©主要将我们的方法与最先进的方法进行比较。TC-USOD通过引入上下文感知机制增强了对图像结构和边缘信息的捕获,从而在E和F评估中取得了更好的结果。最后,图8(d)评估了各种注意力机制之间的性能差异。SwinFusion、CrossFuse和我们的方法在多尺度信息处理和特征融合方面展现出独特优势,使它们能够在全局结构一致性、边缘对齐和错误控制方面实现卓越性能。
定性分析。 图9展示了SOD和USOD算法在USOD10k数据集上的定性比较结果。

显然,我们提出的方法实现了卓越的准确性,几乎与真实值(GT)完美匹配,并且在边缘、细节和形状保持方面表现出色。无论是处理复杂背景中的目标还是具有丰富边缘细节的目标(例如倒数第二行的多刺生物),我们的模型都能准确分割目标区域,同时避免明显的噪声或错误。SwinFusion和TC-USOD在大多数情况下也表现出高精度,分割边缘清晰,与GT紧密对齐。特别是在处理复杂背景(如潜水员和水下生物的图像)时,这些方法能有效区分前景和背景,保持目标的形状完整性。虽然SwinFusion和TC-USOD表现一致,具有良好的边缘处理和细节保持能力,但在一些极端情况下(例如,具有显著噪声或模糊区域的图像)效果略逊于我们提出的方法。CrossFuse和Dual-SAM在处理形状相对简单且对比度高的图像方面表现出色。然而,在处理具有复杂形状或丰富细节的目标(如海星或具有复杂边缘的物体)时,它们有时会出现边缘模糊或细节丢失。F3Net和DANet能够在分割过程中准确识别和分离目标,但在某些场景下(例如,具有复杂背景或模糊目标边缘的场景),分割边缘可能变得模糊或受到噪声影响,导致目标形状不够准确(如第三行和倒数第二行的物体所示)。PSGLoss、BDLFusion和HiDANet在处理具有复杂边缘或低对比度的图像时表现不佳。比较不同算法的分割结果,可以清楚地看出,所提出的模型在各种场景下始终表现出最稳定和准确的性能,有效处理复杂背景、细节丰富的场景,并保持目标的形状完整性。
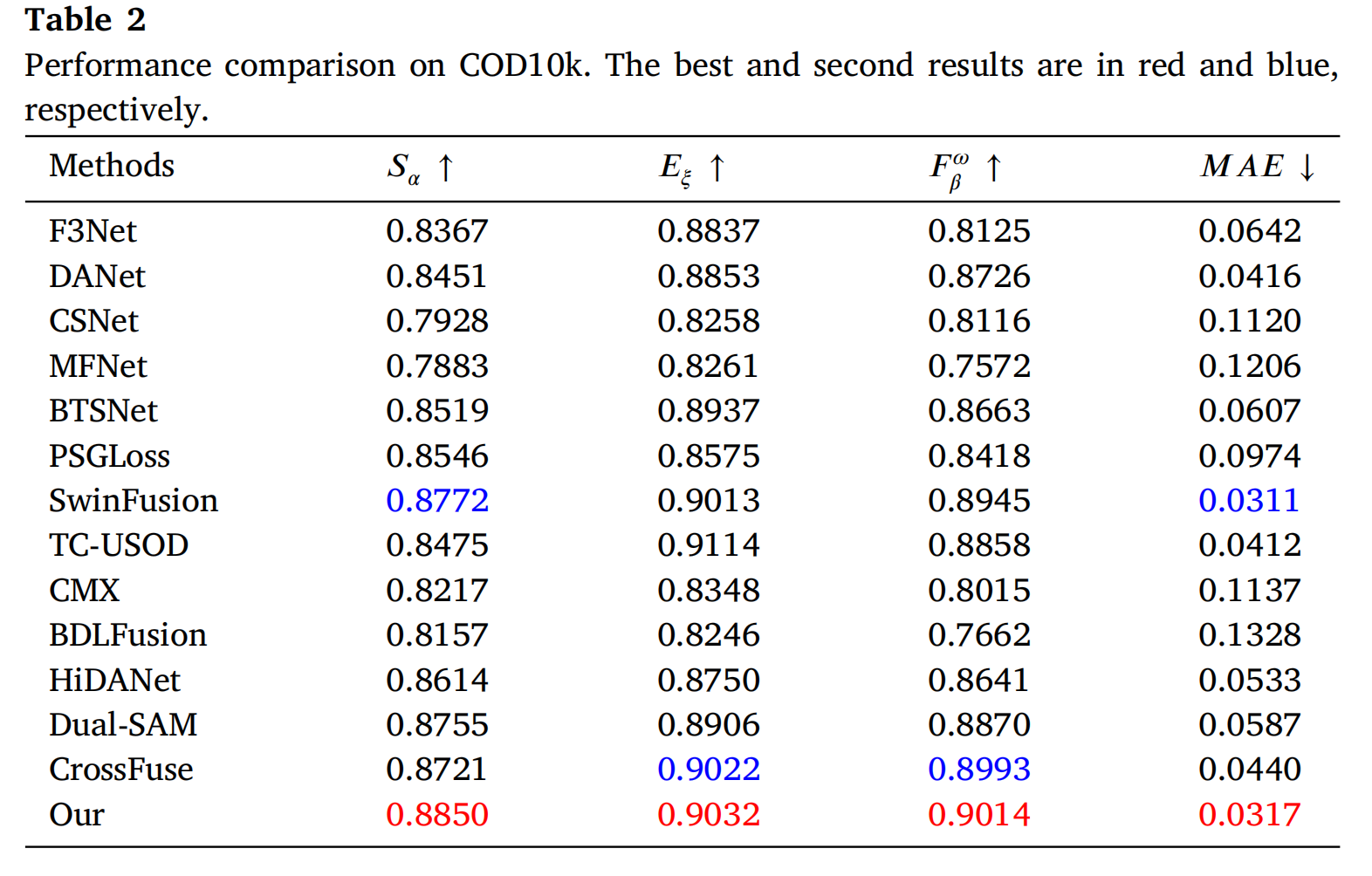
如表2所示,在COD10K数据集上,我们的模型表现出强大的竞争力。首先,在 SαS_{\alpha}Sα 评估中,模型得分为0.8850,比F3Net的0.8367提高了0.0483,也超过了SwinFusion的0.8772。这一显著改进表明,该模型在处理具有复杂背景的伪装目标时,能更好地保持图像的结构一致性。FCA模块在平衡局部细节和全局信息方面发挥了关键作用。在 EξE_{\xi}Eξ 评估中,我们的模型得分为0.9032,比F3Net提高了0.0195,并比SwinFusion高出0.0019。这表明我们的模型在复杂边缘的对齐和处理方面具有更强的能力。SSIM损失的引入进一步增强了这一优势,使模型能够更好地关注边缘信息,从而提高了整体分割精度。
对于 FβωF_{\beta}^{\omega}Fβω 指标,我们提出的模型相比F3Net提高了0.0889,相比SwinFusion提高了0.0069。这一结果进一步证明了模型在平衡精确率和召回率方面的优越性,尤其是在分割水下目标的任务中。Dice损失显著增强了模型捕获显著区域的能力,使其在不同背景复杂性下都能保持高水平的分割质量。最后,模型的MAE为0.0317,显著低于F3Net的0.0642,与SwinFusion的0.0311相当。这一性能表明模型在整体错误控制方面表现出色,进一步证实了FCA模块和多种损失函数的有效结合。这使得模型在处理细节丰富和噪声图像时能有效减少错误。

图10展示了各种最先进模型在COD10K数据集上的定性分析结果。通过比较这些模型在伪装目标检测任务中的性能,我们可以更好地理解各种方法在处理多样化和复杂水下场景时的优缺点。
从F3Net显示的结果可以看出,虽然该模型能够检测到伪装目标的主要区域,但在边界定义方面存在困难。它经常产生具有明显伪影或过度平滑的分割输出,尤其是在珊瑚礁或植被茂密区域等复杂环境中。这表明F3Net在保持精细边缘细节和准确分割具有复杂形状的目标方面存在局限性。相比之下,DANet表现出改进的边缘保持能力,特别是在简单场景中。然而,在结构复杂或对比度低的区域,该模型未能清晰勾勒目标边界,导致分割输出模糊。尽管DANet的双重注意力机制有助于捕获全局上下文,但在处理复杂纹理和精细细节时可能仍然不足。CSNet和MFNet表现出类似的缺点,分割结果通常缺乏清晰度和一致性。两种模型似乎在捕获精细细节方面存在困难,经常产生不完整或碎片化的目标掩码。这个问题在具有高度伪装目标的图像中尤为明显,模型无法有效将目标与背景区分开。相比之下,SwinFusion和TC-USOD在分割准确性方面显示出显著改进,特别是在保持伪装目标的整体形状和结构方面。SwinFusion利用其基于Transformer的架构,擅长捕获全局依赖关系并将其与局部细节对齐,从而在背景高度复杂的场景中实现更精确的分割。类似地,TC-USOD受益于其上下文感知机制,增强了边缘对齐和目标轮廓描绘。
图10所示的结果清楚地表明,我们的模型在所有测试案例中均优于所有其他方法。无论背景复杂性或伪装程度如何,我们的方法在边缘定义和目标内部结构方面都保持了高精度。CIEM和FCA模块通过整合浅层和深层特征并对其进行增强,显著提升了模型的性能。我们的分割结果更接近GT,表明我们的模型在处理各种水下环境和复杂目标时表现出卓越的鲁棒性。在复杂水下场景中准确分割伪装目标的能力进一步强调了CIEM和FCA模块的有效性,以及精心设计的损失函数在指导训练过程中的重要性。
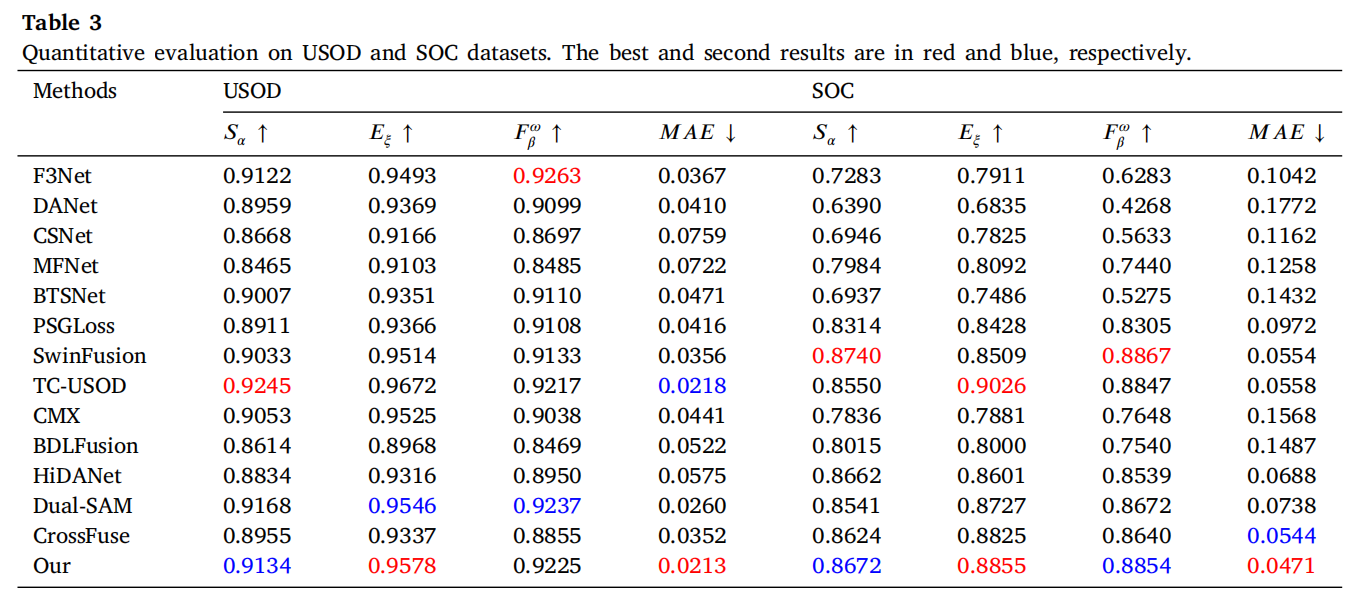
扩展泛化性。 表3展示了各种方法在USOD和SOC单模态数据集上的定量评估结果。在USOD数据集上,我们的模型在E、F和MAE指标上表现出色。具体来说,提出的方法将E分数比F3Net的0.9493提高了0.0085,显著优于大多数比较方法。TC-USOD获得了最高的E分数,略微超过了我们的方法,这可能归因于其处理边缘和捕获全局信息的独特设计。在F评估中,我们的模型与F3Net相比略有下降。然而,这种轻微下降可能是为了优化其他指标(如MAE)而做出的权衡。在MAE方面,提出的方法表现出色,显著优于F3Net和所有其他方法,表明在细节保持和错误控制方面具有显著优势。尽管我们的方法在 SαS_{\alpha}Sα 指标上略低于TC-USOD,但总体而言,我们的模型在平衡多个评估指标方面表现出强大的综合能力,特别是在错误控制和边缘对齐方面。
在SOC数据集上,我们的方法也表现出卓越的性能。在 SαS_{\alpha}Sα 评估中,我们的模型略微超过了HiDANet的0.8662和Dual-SAM,表明提出的方法在复杂背景下能更好地保持图像的结构一致性。相比之下,F3Net在SOC数据集上表现相对较差,可能因为其在处理复杂背景时难以有效区分目标区域与背景,导致整体结构相似性下降。在 EξE_{\xi}Eξ 方面,我们的方法略低于TC-USOD,但仍然显著优于其他方法,展示了其在边缘对齐和处理复杂边缘方面的能力。值得注意的是,在MAE指标上,我们的模型得分显著低于TC-USOD,表明更好的整体错误控制,尤其是在处理高噪声和复杂场景时减少错误方面。
在S-measure和F-measure方面,我们的方法在SOC数据集上表现不如SwinFusion和TC-USOD。这可能归因于提出的方法在处理单模态数据时,在捕获全局结构和目标边界方面存在局限性。对于E-measure和MAE指标,TC-USOD方法在区分显著区域与背景方面表现出卓越能力。相比之下,我们的方法在复杂环境中进行细粒度显著目标检测时可能遇到困难。然而,值得注意的是,我们的方法在各种场景中始终表现出出色的泛化能力,能在复杂视觉场景中准确捕获显著目标,这凸显了我们的特征提取和融合策略的有效性。虽然TC-USOD和SwinFusion在某些细节导向的方面表现卓越,但我们的方法在多个评估指标上保持了全面而稳健的性能,展示了在处理多样化数据集方面的强大竞争力。
IF-USOD在多模态和单模态数据集上始终表现出强大的性能,这主要归功于其创新的多模态信息融合和交互式特征增强架构。首先,通过整合RGB和深度信息,模型充分利用了不同模态之间的互补性,解决了单一模态(例如仅RGB或仅深度)在复杂场景中准确捕获显著目标的局限性。其次,IF-USOD模型中的跨尺度交互嵌入模块有效结合了卷积神经网络和Transformer架构的优势。此外,融合的特征通过全感知交叉注意力模块重新加权,进一步增强了跨模态互补性,确保融合图像在下游视觉任务中保持出色性能。最后,IF-USOD采用多尺度多模态解码器,整合了来自不同层次的多尺度、多源特征,以产生精确的显著性预测结果。
4.5. 消融研究
在这项工作中,提出的IF-USOD采用了一种融合了Transformer编码器和卷积编码器的混合架构。为了验证这种架构的有效性,我们使用纯卷积编码器-解码器架构作为基线1(Baseline 1),使用纯Transformer编码器-解码器架构作为基线2(Baseline 2)。这些基线使我们能够评估在这些条件下所提出模块的有效性。
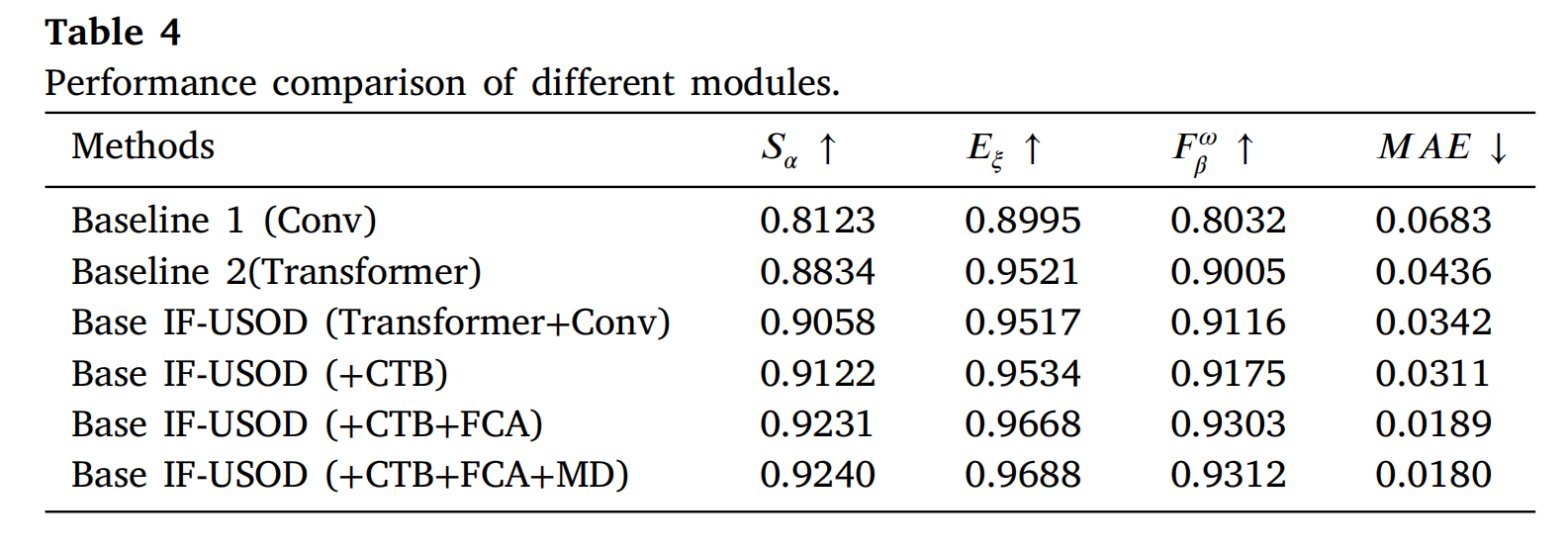
表4说明了不同模块组合对模型性能的影响。我们分析了基于卷积和Transformer架构的基线模型,以及通过逐步添加不同模块所实现的性能提升。基线1(Conv)使用传统的卷积神经网络方法。评估结果表明,在不使用Transformer的情况下,卷积方法在整体结构相似性和边缘对齐方面表现出相对较弱的性能,且错误率较高。基线2(Transformer)引入了Transformer架构,显著增强了性能。与基线1相比,其 EξE_{\xi}Eξ 和 FβωF^{\omega}_{\beta}Fβω 分数分别提高了0.0526和0.097。
CIEM模块的有效性。 CIEM模块的核心优势在于其高效捕获和融合跨尺度信息的能力。USOD任务中的一个关键挑战是有效捕获不同尺度上的全局和局部信息。传统的卷积神经网络擅长捕获局部特征,但通常在整合全局信息方面存在不足。CIEM模块通过SDA和LDA的组合,实现了不同尺度特征之间的交互和整合。这种设计使模型能够在保留细节信息的同时,有效整合全局语义,尤其是在处理复杂背景或高度多样化图像时。此外,CIEM模块充分利用了CNN和Transformer架构的优势。卷积层善于提取局部空间特征,而Transformer则擅长捕获全局依赖关系和长程信息。通过在CIEM中交替使用CEL和CTB,模型可以动态调整不同尺度的特征表示。这种混合架构使模型能够在细节丰富的区域提供精细的分割边缘,同时在全局尺度上保持结构一致性。还值得注意的是,卷积操作通常会在不同通道上产生各种特征表示,但这些特征在传统网络中可能未得到充分利用。CFRB模块重新组织和重新加权跨通道的特征,使模型能够更有效地利用这些信息。这种特征重组有助于减少冗余并增强对关键特征的关注,从而进一步提高模型在边缘对齐和细节保持方面的性能。
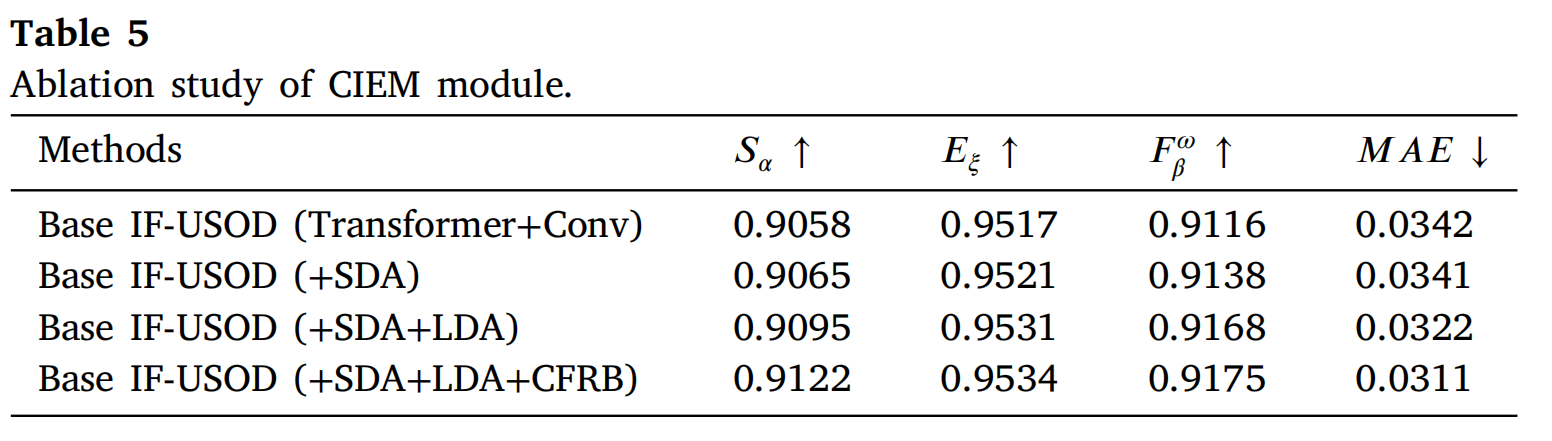
表5展示了在CIEM模块上进行的消融研究结果,旨在评估CEL和CTB对模型性能的影响。通过逐步加入这些模块,可以观察到它们对各种评估指标的贡献。最初,基础模型(Base IF-USOD(Transformer+Conv))的性能较弱。引入SDA模块后,模型性能有所改善,SαS_{\alpha}Sα 增加了0.0007,EξE_{\xi}Eξ 增加了0.0004,FβωF_{\beta}^{\omega}Fβω 增加了0.0022,MAE略微降低了0.0001。这些结果表明,SDA模块有效增强了特征捕获和边缘对齐能力,从而提高了整体分割性能。进一步加入LDA后,观察到性能提升更为显著。具体来说,SαS_{\alpha}Sα 增加了0.0030,EξE_{\xi}Eξ 增加了0.0010,FβωF_{\beta}^{\omega}Fβω 显著增加了0.0030,MAE降低了0.0019。LDA模块的引入增强了多尺度特征间的交互,有效提高了模型保留细节和保持全局一致性的能力。最后,加入CFRB模块后,模型达到了最佳性能。SαS_{\alpha}Sα 从0.9095提高了0.0027,达到0.9122。EξE_{\xi}Eξ 增加了0.0003,达到0.9534。FβωF_{\beta}^{\omega}Fβω 进一步增加了0.0007,达到0.9175,MAE又降低了0.0011。CFRB模块增强了通道间的信息流动,进一步提高了模型的整体性能,特别是在处理复杂背景和边缘细节方面。CIEM模块通过有效的特征处理和多尺度信息融合,显著提升了图像分割模型的整体性能。
FCA模块的有效性。 FCA模块的出色性能归功于其在不同特征层次间的全感知融合机制。浅层特征通常包含丰富的纹理和边缘信息,而深层特征则承载高层语义,两者对于分割任务都至关重要。简单地在对应层次融合这些特征可能会导致一些关键信息的丢失。FCA模块通过引入交叉注意力机制来解决这个问题,允许对每个层次的特征融合进行精细控制,确保模型充分利用每一层的信息,从而增强整体分割性能。具体来说,CA和SA的结合使FCA模块能够动态调整特征间的交互,使模型能够提供更准确的分割结果,尤其是在处理复杂背景和边缘时。
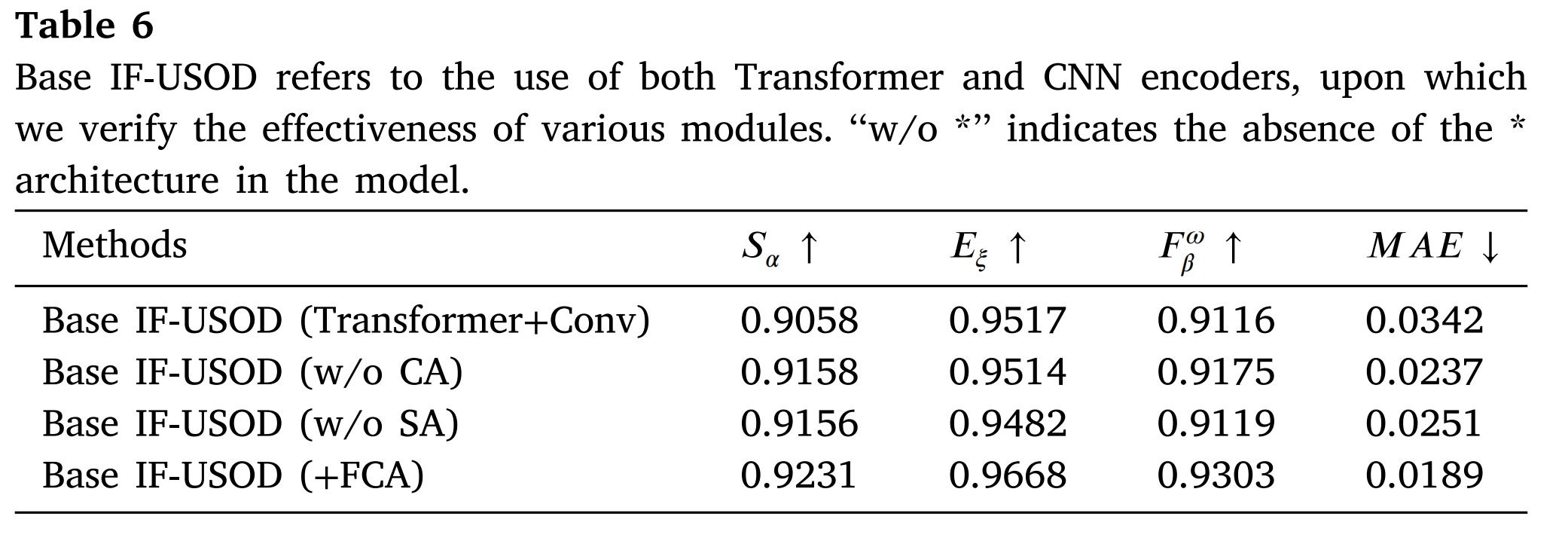
表6展示了FCA模块的消融研究结果,其中逐步移除或保留了FCA的关键组件,以评估它们对模型性能的影响。FCA模块旨在通过交互式地融合不同层次的特征来增强弱边缘和纹理特征的表示,从而提高模型在复杂场景中的性能。表中的评估结果表明,基础模型在处理全局语义信息和捕获局部细节方面表现良好,但在优化弱边缘和纹理特征方面仍有改进空间。移除CA模块后,模型的性能出现轻微变化:SαS_{\alpha}Sα 提高了0.0100,EξE_{\xi}Eξ 略微下降了0.0003,FβωF_{\beta}^{\omega}Fβω 增加了0.0059,MAE显著降低了0.0105。移除CA模块导致模型处理跨通道特征的方式发生细微变化,这可能是因为缺乏通道间信息的重新加权,导致模型更依赖于空间信息融合,从而增强了细节处理能力,但略微降低了全局特征整合。移除SA模块后,SαS_{\alpha}Sα 与移除CA模块的结果相近,但EξE_{\xi}Eξ 下降了0.0035,FβωF_{\beta}^{\omega}Fβω 略微增加了0.0003。移除SA模块导致边缘对齐和全局一致性略有下降,表明SA在加强边缘特征对齐和提高模型捕获细节能力方面起着关键作用。
损失函数的有效性。 表7中的评估结果反映了不同损失函数在模型训练过程中的关键作用。wBCE和wIoU损失函数作为基础,使模型具备了平衡样本均衡和重叠优化的能力。对粗粒度和细粒度显著图的联合监督使模型能够在不同尺度上进行优化,从而更好地处理复杂的图像场景。Dice损失进一步优化了预测区域与目标区域之间的相似性,显著提高了模型在显著性检测中的准确性。SSIM损失通过监督图像的结构信息,确保模型不仅在数值指标上表现出色,而且在视觉外观上保持高度的结构一致性。
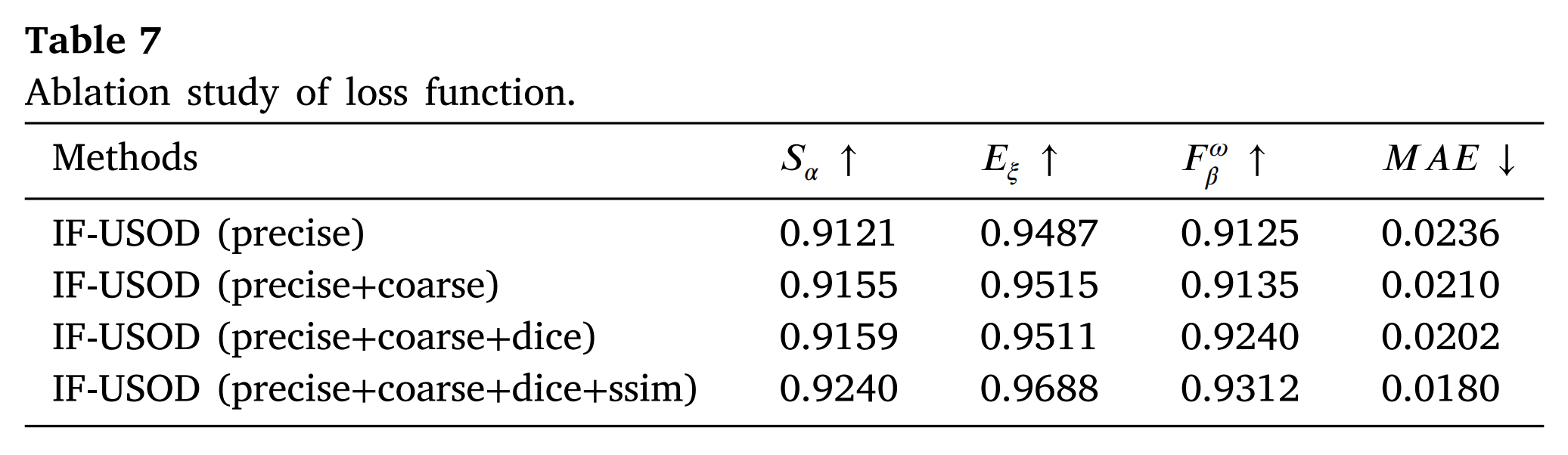
表7展示了不同损失函数组合对IF-USOD模型性能的影响。通过逐步引入各种损失函数,可以清楚地看到每种损失函数对模型性能提升的具体贡献。实验结果表明,仅使用精细显著图监督已经使模型在结构相似性和边缘对齐方面达到了一定的性能水平,但在细节捕获和整体错误控制方面仍存在局限性。当在精细显著图监督的基础上加入粗糙显著图监督后,模型的性能得到进一步提升。具体来说,SαS_{\alpha}Sα 提高了0.0034,EξE_{\xi}Eξ 提高了0.0028,FβωF_{\beta}^{\omega}Fβω 提高了0.0010,MAE显著降低了0.0026。粗糙显著图的引入使模型能够在更大尺度上捕获全局信息,从而增强了对复杂场景的适应性,并使目标区域检测更加稳健。在先前配置的基础上加入Dice损失后,性能得到进一步改善。Dice损失通过直接优化目标与预测区域之间的相似性,有效提高了模型捕获显著区域的能力,特别是在细节处理和区域相似性方面。最后,SSIM损失优化了图像的结构相似性,确保模型在捕获细节的同时保持结构一致性。这对于在处理复杂边缘信息时提高分割精度特别有益。
5. 结论**
在这项工作中,我们提出了一种名为IF-USOD的新型USOD架构。该架构包含Transformer和CNN组件的双重结构,以更好地从水下图像中提取特征。此外,为了更好地表示特征之间的相关性,我们建议使用自注意力和交叉注意力机制来重新聚合特征。在我们提出的方法中,多模态特征融合更倾向于水下显著目标特征,符合USOD任务的要求。我们还采用了多种损失函数来强制融合特征中包含更多的显著特征和细节信息。大量实验表明,我们提出的方法在USOD任务中实现了最先进的性能,消融研究验证了所提出模块的有效性。在未来的工作中,我们将进一步探索特征融合中的动态调整,以满足USOD在极端条件下的实际需求。