【踩坑】ELK日志解析优化实战:解决多行合并与字段提取问题
【踩坑】ELK日志解析优化实战:解决多行合并与字段提取问题
- 前言
- 优化前现状
- 优化后
- 问题排查与解决过程
- 1. 解决多行日志合并问题
- 日志字段解析配置
- 3. 字段命名冲突问题
- 4. 字段类型映射问题
- 5. 字段统一优化
- 总结
前言
近期入职新公司后,接到一项任务:解决项目中 ELK 日志采集系统存在的问题。当前日志解析格式混乱,且部分关键字段未能正确采集,严重影响了问题排查效率。经过深入分析和调试,最终成功解决了这一问题。本文将记录整个优化过程中的关键步骤与踩坑经验。
优化前现状
-
多行日志合并异常:不同时间段的日志被错误地采集到同一条 ES 文档中
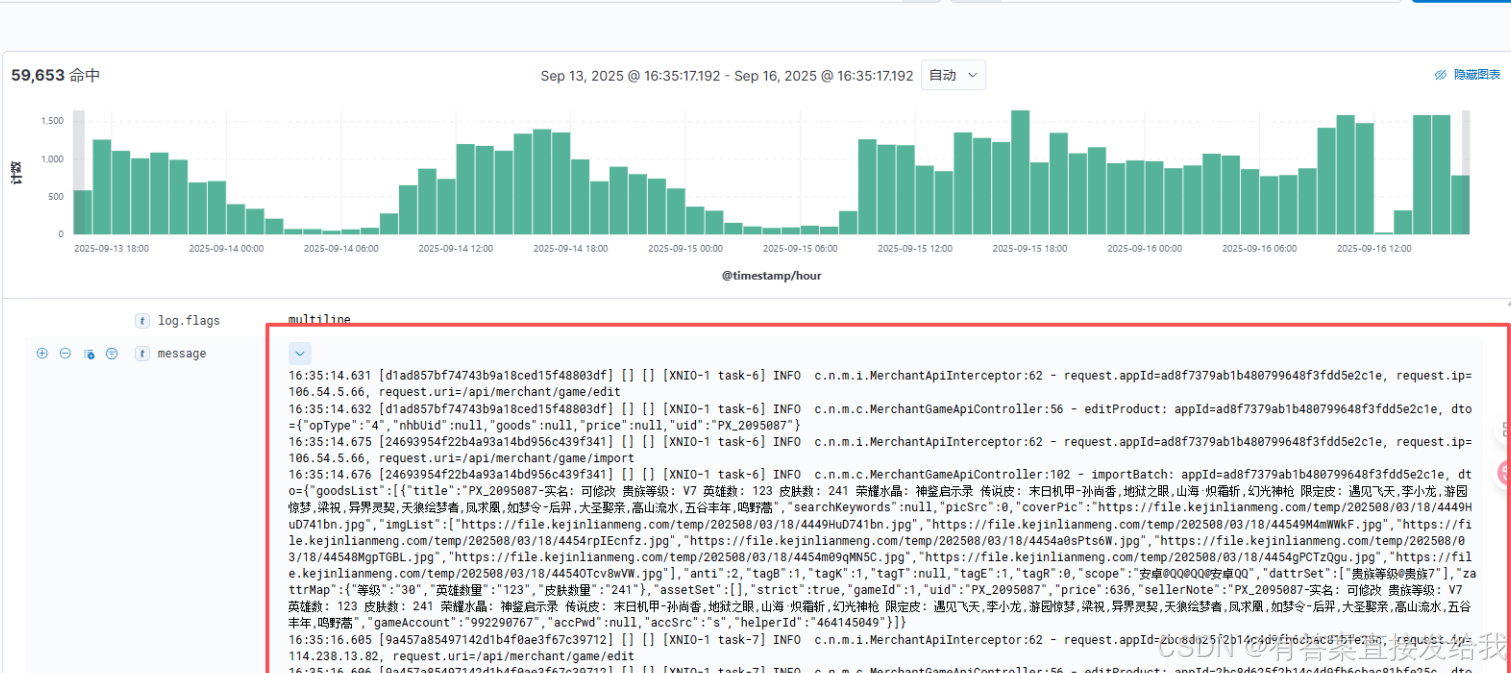
-
字段解析缺失:所有日志内容均堆积在 message 字段中,未按预期解析为独立字段
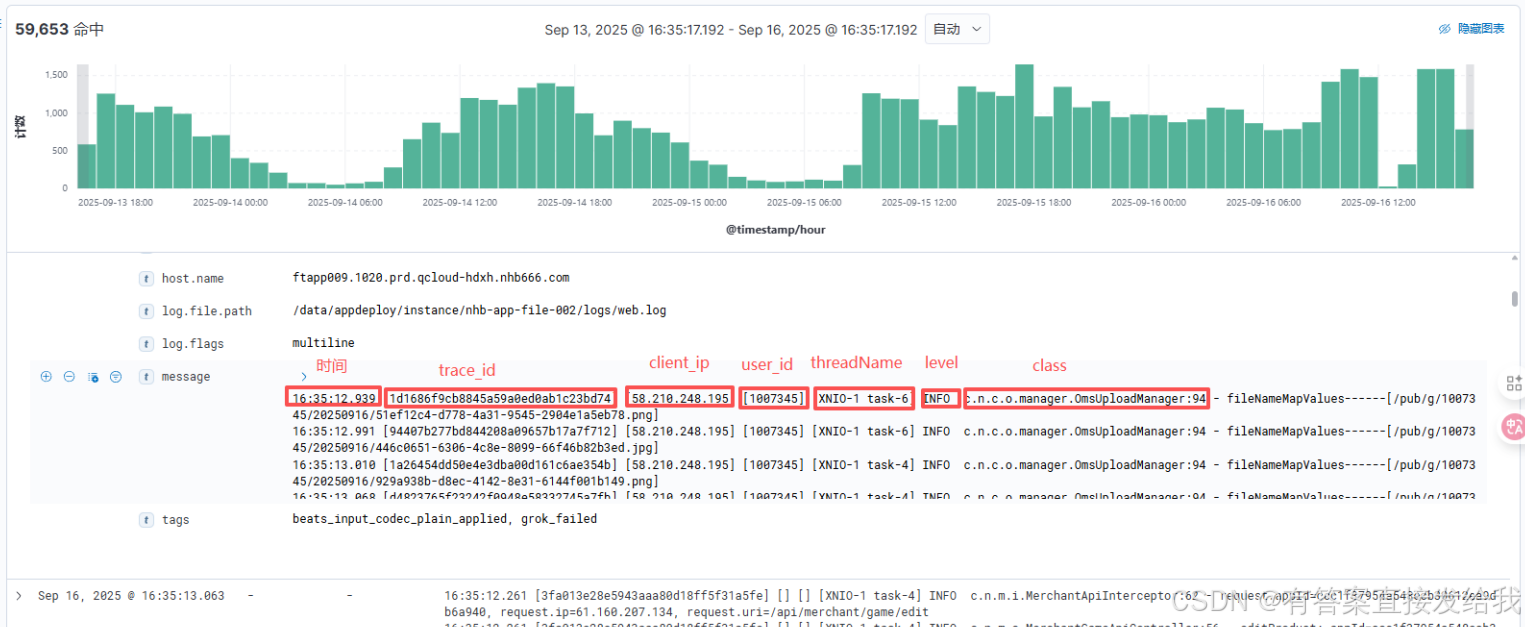
理想状态应该是:
- message 字段仅保存日志正文内容
- 其他属性(如 trace_id、client_ip、level 等)应解析为独立字段
优化后
日志中各字段被成功提取,支持按需进行字段筛选和查询
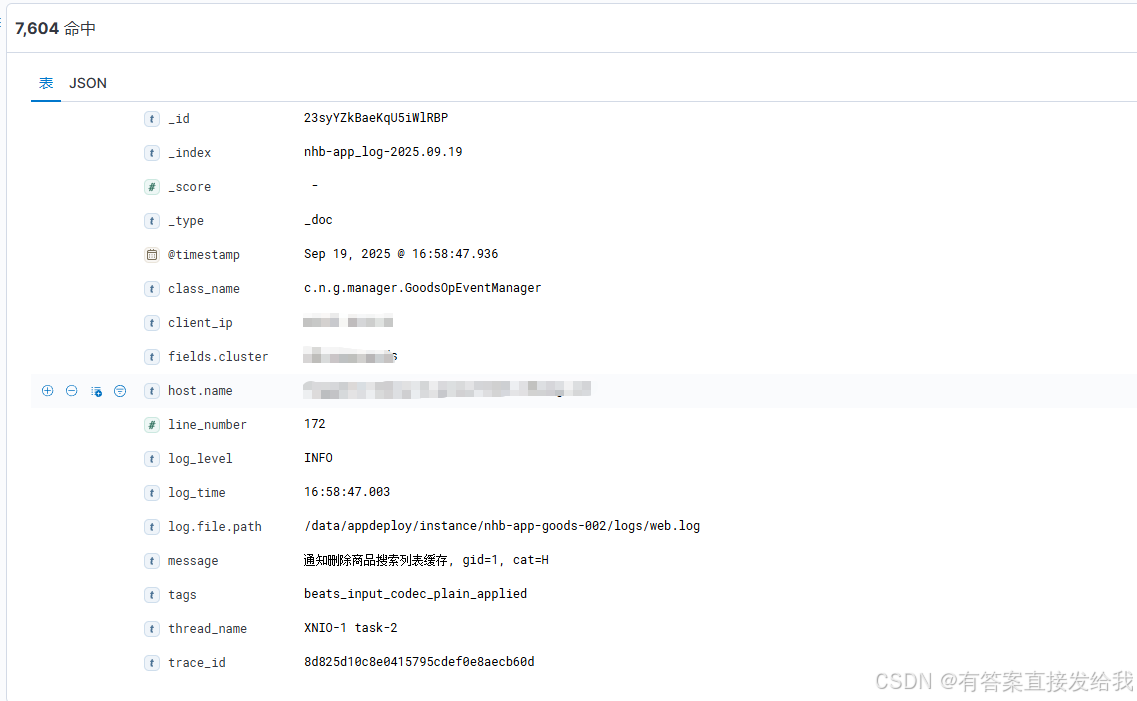
问题排查与解决过程
1. 解决多行日志合并问题
检查 FileBeat 配置文件时,发现使用了 multiline 模式,配置模式为 [0-9]{4}-[0-9]{1,2}-[0-9]{1,2}
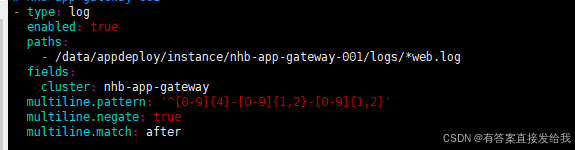
配置原理解析:
FileBeat 通过匹配行首模式判断日志起始位置,从匹配日期格式的行开始,直到下一个匹配行之间的内容被视为一条完整日志。
问题定位:
检查实际日志源文件后发现,日志行并非以 2023-09-11 类日期格式开头,而是采用 16:43:06.081 时间戳格式开头。

由于 multiline.pattern 无法匹配实际日志开头格式,导致所有行均被识别为"不匹配"行,合并逻辑紊乱。
解决方案:
调整multiline.pattern为 ^(\d{2}:\d{2}:\d{2}\.\d{3}|\d{4}-\d{2}-\d{2}),同时支持时间和日期两种开头格式。
日志字段解析配置
检查 Logstash 配置发现仅包含基础输入输出配置,缺少字段解析处理:
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["http://127.0.0.1:9200"]user => "elastic"password => "123456"index => "app_log-%{+YYYY.MM.dd}"}
}
解决方案:
添加 filter 配置实现字段解析:
filter {grok {match => {"message" => ["%{TIME:logtime} \\(%{DATA:traceId} \\(%{DATA:clientIp} \\(%{DATA:userId} \\[%{DATA:thread}\\] %{LOGLEVEL:level} %{DATA:className} - %{GREEDYDATA:log_message}"]}tag_on_failure => ["grok_failed"]}
}
配置解析:
-
通过 grok 模式将日志内容解析到指定字段
-
开头时间部分解析为 logtime 字段
-
后续内容依次解析为 traceId、clientIp 等字段
-
tag_on_failure 用于标记解析失败的日志
调试建议:
可使用 Kibana 的 Grok Debugger 工具测试模式匹配准确性
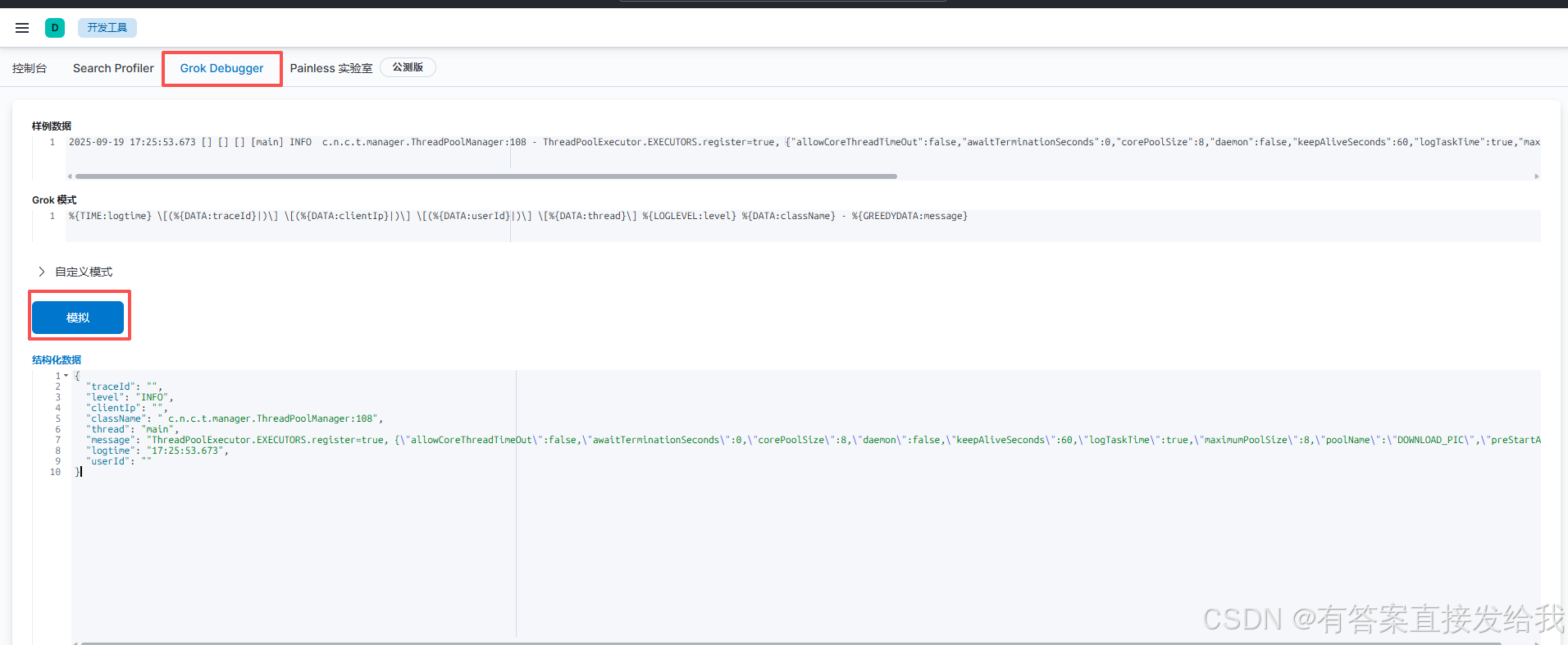
3. 字段命名冲突问题
配置后发现 message 字段内容未变化,原因是 grok 模式中定义的message字段与系统默认字段重名。
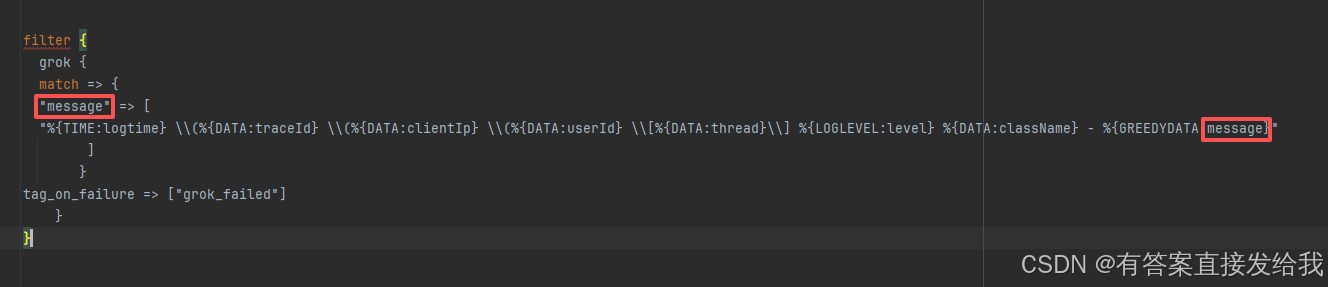
解决方案:
将字段重命名为 log_message 避免冲突:
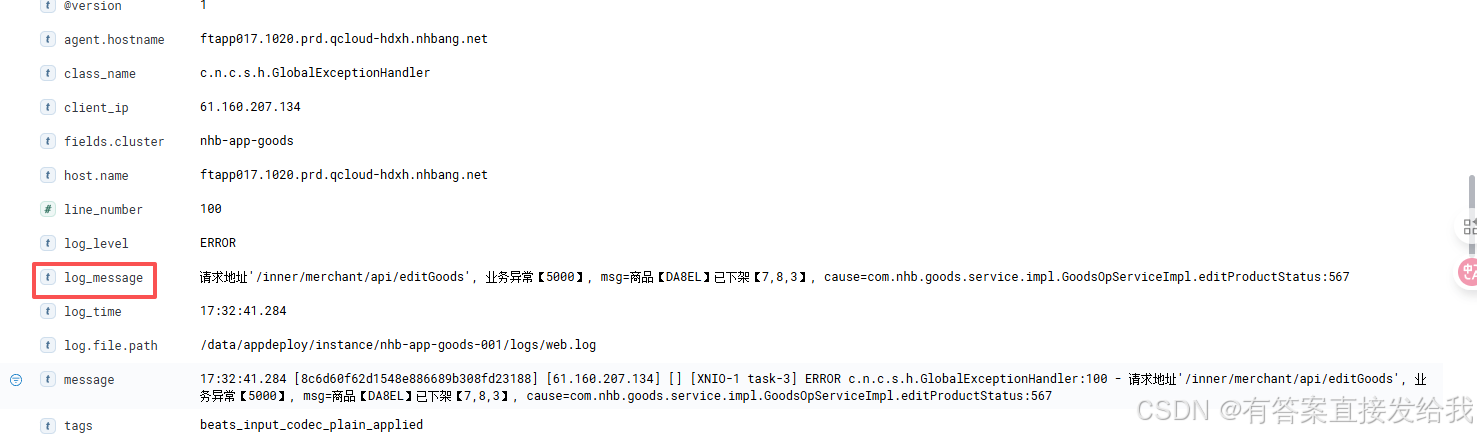
成功!新的字段的确出现了
4. 字段类型映射问题
字段解析成功后,发现无法通过 log_message 进行搜索。经检查发现字段被识别为 keyword 类型,不支持全文搜索。
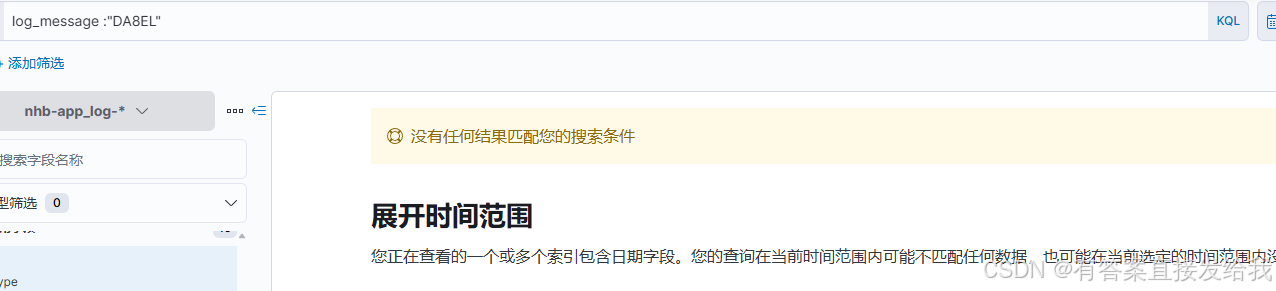
注:ES 索引字段类型一旦创建不支持修改,需通过配置模板保证新索引字段类型正确。
解决方案:
配置索引模板指定字符串字段类型:
PUT _index_template/nhb-app-logs
{"index_patterns": ["nhb-app_log-*"],"template": {"mappings": {"dynamic_templates": [{"strings_as_text": {"match_mapping_type": "string","mapping": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}]}}
}
5. 字段统一优化
为解决新旧日志字段不一致(log_message vs message)导致的查询不便问题,通过Logstash字段重命名实现统一:
rename => { "log_message" => "message" }
此举确保所有日志均使用 message 字段存储正文内容,保持查询一致性。
总结
通过本次优化实践,成功解决了 ELK 日志采集中的多行合并、字段解析、类型映射等关键问题。建议在日志系统建设初期就明确日志格式规范,并建立相应的字段映射模板,可避免后续大量的调整工作。同时推荐使用 Kibana 提供的调试工具进行配置验证,确保解析规则的准确性。