Oceanbase tablegroup表组与负载均衡实践
实验目的
在负载均衡机制中,OceanBase 对表组(TableGroup)采用特殊的均衡策略,依据表组的 Sharding 属性来对调整表组中的表、分区的位置,从而使得表组中的表、分区按照一定的规则分布,表现为物理位置关系的亲和性。
- Sharding=none:表组中的所有表聚合在同一个日志流中。
- Sharding=partition:表组中的所有表的一级分区方式相同,相同序号的一级分区聚合在同一个日志流,不同序号的一级分区分散在多个日志流中。
- Sharding=adaptive:表组中的所有表的分区方式完全相同。如果都不分区,则所有表聚合在同一个日志流;如果都是一级分区表,则规则与 sharding=partition 相同;如果都是组合分区表,则相同序号的二级分区聚合在同一个日志流,不同序号的二级分区分散在多个日志流中。
本实验使用不同 Sharding 属性的表组来观察表组的负载均衡策略。
实验环境
1 台 OCP 机器 + 3 台 OBServer 服务器
Observer:192.192.103.125/192.192.103.126/192.192.103.127
OCP:192.192.103.128
Obcluser(1-1-1):test_ob_cluster
ObproxyCluster:test_odp_cluster
用户租户:test
OceanBase 版本号4.2.4.0(社区版)
Obproxy版本号4.2.3.0-3(社区版)
实验步骤
步骤 1 在 test租户的 test_db 中创建 sharding=none 的表组 tbg1,并将 np_t1 和 hp_t1 两个表加入到 tbg1 中。
obclient(root@test)[TEST_DB]> create tablegroup tbg1 sharding='NONE';
Query OK, 0 rows affected (0.521 sec)
obclient(root@test)[TEST_DB]> alter tablegroup tbg1 add table np_t1,hp_t1;
Query OK, 0 rows affected (0.412 sec)
obclient(root@test)[TEST_DB]> show tablegroups like 'tbg1';
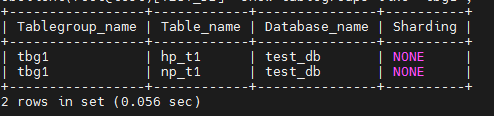
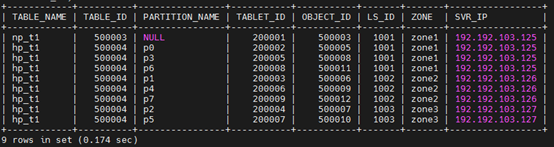
步骤 2 查看加入表组后两个表、分区的位置(日志流归属),发现并没有变化。
obclient(root@test)[TEST_DB]> SELECT TABLE_NAME, TABLE_ID, PARTITION_NAME, TABLET_ID, OBJECT_ID, LS_ID, ZONE, SVR_IP FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE DATABASE_NAME='TEST_DB' AND ROLE='LEADER' ORDER BY SVR_IP;
步骤 3 修改租户级配置项 partition_balance_schedule_interval,将分区负载均衡任务的时间间隔设置为10 秒,以快速触发负载均衡。
obclient(root@test)[TEST_DB]> ALTER SYSTEM SET partition_balance_schedule_interval='10s';
ERROR 4179 (HY000): DBMS_SCHEDULER job 'SCHEDULED_TRIGGER_PARTITION_BALANCE' is enabled. Operation is not allowed
修改是报错,因为oceanbase4.x默认启用了SCHEDULED_TRIGGER_PARTITION_BALANCE任务,无法手动修改,需要先禁用该任务,如下:
obclient(root@test)[TEST_DB]> CALL DBMS_SCHEDULER.DISABLE('SCHEDULED_TRIGGER_PARTITION_BALANCE');
Query OK, 0 rows affected (0.928 sec)
obclient(root@test)[TEST_DB]> ALTER SYSTEM SET partition_balance_schedule_interval='10s';
Query OK, 0 rows affected (0.113 sec)
等待10s以上,查看加入表组后两个表、分区的位置(日志流归属),发现所有分区均聚合在同一个日志流1001上了。
SELECT TABLE_NAME, TABLE_ID, PARTITION_NAME, TABLET_ID, OBJECT_ID, LS_ID, ZONE, SVR_IP FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE DATABASE_NAME='TEST_DB' AND ROLE='LEADER' ORDER BY SVR_IP;
步骤 4 创建 sharding=partition 的表组 tbg2。在 tbg2 中创建两个分区表 tbg2_t1,tbg2_t2。
obclient(root@test)[TEST_DB]> create tablegroup tbg2 sharding='PARTITION';
Query OK, 0 rows affected (0.656 sec)
obclient(root@test)[TEST_DB]> CREATE TABLE tbg2_t1 (C1 INT,C2 VARCHAR(100)) TABLEGROUP='tbg2' PARTITION BY HASH(C1) PARTITIONS 3;
Query OK, 0 rows affected (1.176 sec)
obclient(root@test)[TEST_DB]> CREATE TABLE tbg2_t2 (C1 INT,C2 VARCHAR(100),C3 TIMESTAMP) TABLEGROUP='tbg2' PARTITION BY HASH(C1) SUBPARTITION BY RANGE(UNIX_TIMESTAMP(C3)) SUBPARTITION TEMPLATE
-> ( SUBPARTITION M2023 VALUES LESS THAN(UNIX_TIMESTAMP('2023/12/31')) ,SUBPARTITION M2024 VALUES LESS THAN(UNIX_TIMESTAMP('2024/12/31')) ) PARTITIONS 3;
Query OK, 0 rows affected (1.179 sec)
obclient(root@test)[TEST_DB]> show tablegroups like 'tbg2';
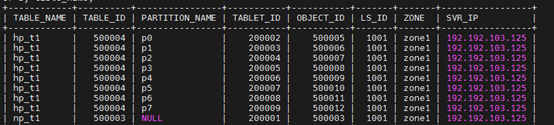
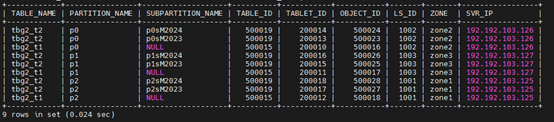
步骤 5 查看表组 tbg2 中两个表的分区位置的分布情况,发现相同的一级分区(包含其下的二级分区)都聚合在相同的日志流上,不同的一级分区均匀分散到 3 个日志流。
obclient(root@test)[TEST_DB]> SELECT TABLE_NAME, PARTITION_NAME, SUBPARTITION_NAME, TABLE_ID, TABLET_ID, OBJECT_ID, LS_ID, ZONE, SVR_IP FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE DATABASE_NAME='TEST_DB' AND TABLEGROUP_NAME='TBG2' AND ROLE='LEADER' ORDER BY PARTITION_NAME;
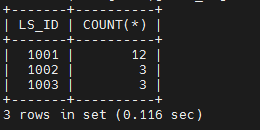
步骤 6 因为使用表组的原因,会导致日志流之间的分区数量不再均衡。
obclient(root@test)[TEST_DB]> SELECT LS_ID,COUNT(*) FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE LS_ID>1000 AND ROLE='LEADER' GROUP BY LS_ID;