clip——手写数字识别
b站视频
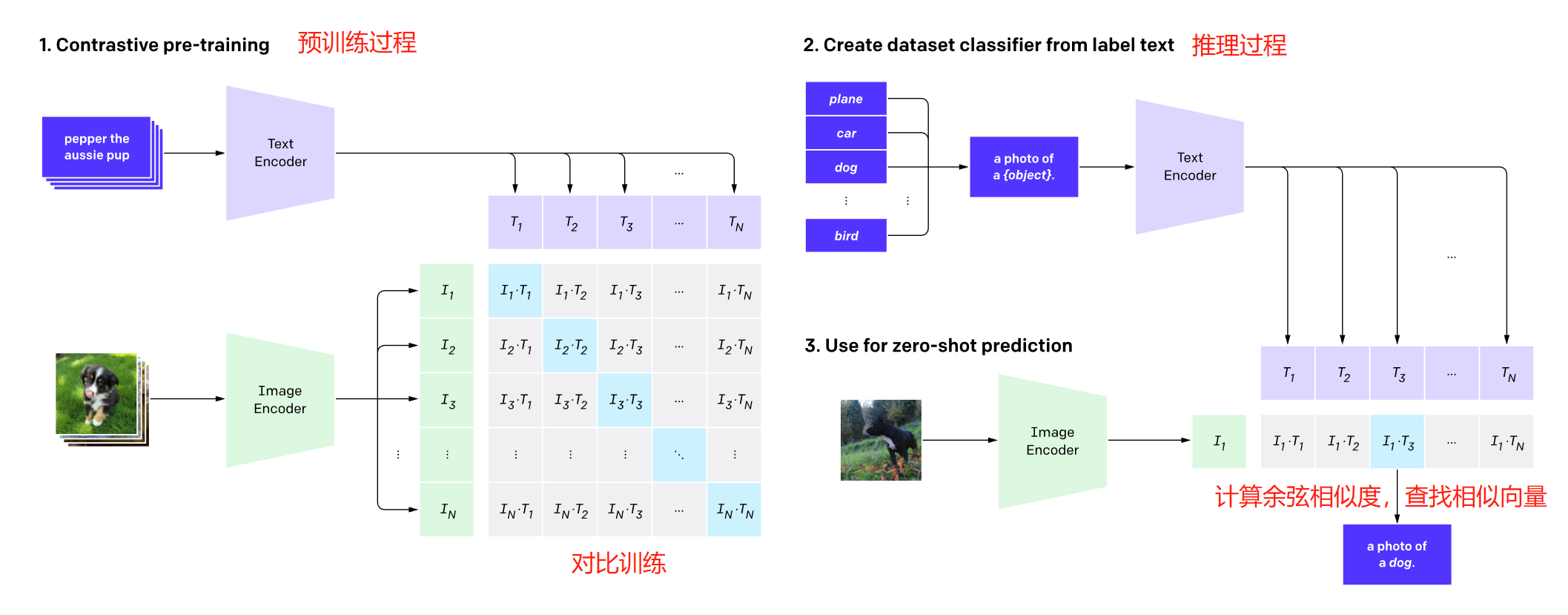
准备数据集
from torch.utils.data import Dataset
from torchvision.transforms.v2 import PILToTensor,Compose
import torchvision# 手写数字
class MNIST(Dataset):def __init__(self,is_train=True):super().__init__()# 加载数据集本身self.ds=torchvision.datasets.MNIST('./mnist/',train=is_train,download=True)# 数据转换操作self.img_convert=Compose([PILToTensor(), # 将原始的 PIL 图像对象转换为 Tensor 类型,shape 会从 (H, W) 变为 (C,H,W),对于MNIST这种灰度图,C=1])# 使用 len(dataset) 时会自动调用 def __len__(self):return len(self.ds)# 使用 dataset[index] 时会自动调用def __getitem__(self,index):img,label=self.ds[index]img = self.img_convert(img)/255.0 # 将 PIL 图像转换为 PyTorch 张量,并将像素值归一化到 0-1 范围return img,labelif __name__=='__main__':import matplotlib.pyplot as plt ds=MNIST() # 创建数据集实例print(len(ds)) # 调用 __len()__img,label=ds[0] # 调用 __getitem__(0)print(label)plt.imshow(img.permute(1,2,0)) # permute(1,2,0) 将维度顺序从 (C, H, W) 重新排列为 (H, W, C),因为 imshow() 函数要求图像的维度顺序是 (H, W, C)plt.show()
图像编码器
使用resnet
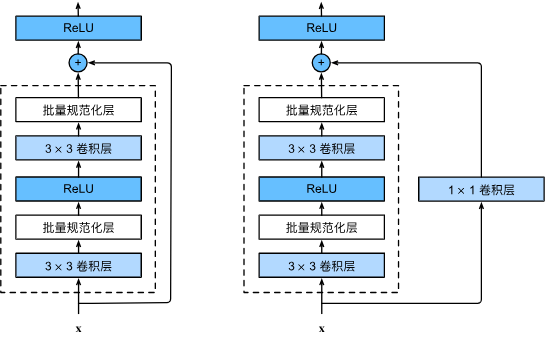
from torch import nn
import torch
import torch.nn.functional as Fclass ResidualBlock(nn.Module):""" 残差块实现 """def __init__(self,in_channels,out_channels,stride):super().__init__()# 卷积层1(3*3)self.conv1=nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,padding=1,stride=stride)# 批量归一化,加速训练self.bn1=nn.BatchNorm2d(out_channels)# 卷积层2(3*3)self.conv2=nn.Conv2d(in_channels=out_channels,out_channels=out_channels,kernel_size=3,padding=1,stride=1)# 批量归一化self.bn2=nn.BatchNorm2d(out_channels)# 卷积层3(1*1)# 跳跃连接的卷积层:当输入输出通道数或尺寸不同时,用于匹配维度# 1x1卷积不改变空间尺寸,仅调整通道数self.conv3=nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1,padding=0,stride=stride)def forward(self,x):y=F.relu(self.bn1(self.conv1(x))) # 卷积->归一化->ReLU激活y=self.bn2(self.conv2(y)) # 卷积->归一化(暂不激活)z=self.conv3(x) # 跳跃分支:调整维度以匹配主分支输出# 残差连接:主分支输出 + 跳跃分支输出,再经过激活return F.relu(y+z)class ImgEncoder(nn.Module):""" 图像编码器:通过残差块提取特征,最终输出特征向量 """def __init__(self):super().__init__()# 第一个残差块:输入1通道(灰度图),输出16通道,步长2(尺寸减半)# 输入尺寸:(batch, 1, 28, 28) → 输出尺寸:(batch, 16, 14, 14)self.res_block1=ResidualBlock(in_channels=1,out_channels=16,stride=2) # 第二个残差块:输入16通道,输出4通道,步长2(尺寸再减半)# 输入尺寸:(batch, 16, 14, 14) → 输出尺寸:(batch, 4, 7, 7)self.res_block2=ResidualBlock(in_channels=16,out_channels=4,stride=2) # 第三个残差块:输入4通道,输出1通道,步长2(尺寸减半)# 输入尺寸:(batch, 4, 7, 7) → 输出尺寸:(batch, 1, 4, 4)self.res_block3=ResidualBlock(in_channels=4,out_channels=1,stride=2) # 全连接层:将特征图展平后映射到8维向量# 输入特征数:1×4×4=16 → 输出特征数:8self.wi=nn.Linear(in_features=16,out_features=8)# 层归一化:对输出向量进行归一化,稳定训练self.ln=nn.LayerNorm(8)def forward(self,x):# 经过三个残差块的特征提取和尺寸缩减x=self.res_block1(x)x=self.res_block2(x)x=self.res_block3(x)# 将三维特征图展平为一维向量:(batch, 1, 4, 4) → (batch, 16)x = x.view(x.size(0), -1) # -1表示自动计算剩余维度# 映射到低维特征空间并归一化x = self.wi(x) # 16维 → 8维x = self.ln(x) # 层归一化return xif __name__=='__main__':img_encoder=ImgEncoder()out=img_encoder(torch.randn(1,1,28,28))print(out.shape) # (1, 8) 一个样本,8维特征
img_encoder(x) → 触发 nn.Module 的 call(x) → call 内部调用 self.forward(x) → 最终返回 forward 的输出结果,赋值给 out。
文本编码器
可以用transformer,这里只用到简单的embedding
from torch import nn
import torch
import torch.nn.functional as Fclass TextEncoder(nn.Module):""" 文本编码器 """def __init__(self):super().__init__()# 嵌入层:将离散的文本索引映射到连续的向量空间# num_embeddings=10:表示词汇表大小为10(共有10个不同的符号)# embedding_dim=16:每个符号将被编码为16维的向量self.emb=nn.Embedding(num_embeddings=10,embedding_dim=16)# 全连接层1:提升特征维度,增加表达能力# 输入维度16(与嵌入维度一致),输出维度64self.dense1=nn.Linear(in_features=16,out_features=64)# 全连接层2:将特征维度从64降回到16self.dense2=nn.Linear(in_features=64,out_features=16)# 全连接层3:将特征映射到目标维度8self.wt=nn.Linear(in_features=16,out_features=8)# 层归一化:对输出特征进行归一化,稳定训练过程self.ln=nn.LayerNorm(8)def forward(self, x):# 第一步:通过嵌入层将文本索引转换为嵌入向量# 输入x形状:(seq_len,) 或 (batch_size, seq_len)# 输出形状:(seq_len, 16) 或 (batch_size, seq_len, 16)x = self.emb(x) # 第二步:通过第一个全连接层并应用ReLU激活函数# 输出形状:(seq_len, 64) 或 (batch_size, seq_len, 64)x = F.relu(self.dense1(x))# 第三步:通过第二个全连接层并应用ReLU激活函数# 输出形状:(seq_len, 16) 或 (batch_size, seq_len, 16)x = F.relu(self.dense2(x))# 第四步:映射到目标特征维度8# 输出形状:(seq_len, 8) 或 (batch_size, seq_len, 8)x = self.wt(x)# 第五步:层归一化,保持特征分布稳定x = self.ln(x)return xif __name__=='__main__':text_encoder=TextEncoder()# 创建输入张量:包含10个整数的序列,每个整数范围是0-9(符合词汇表大小10)# 输入形状:(10,) 表示序列长度为10x=torch.tensor([0,1,2,3,4,5,6,7,8,9])# 前向传播计算输出y=text_encoder(x)print(y.shape) # (10, 8)# 注意这里self.emb已经固定好了,是一本有 10 个条目的字典(索引从0-9),每个条目的值是16维的向量
# self.emb(x) 就是查找x在该字典中对应的值(向量),x是数组表示可以“批量查”(一次查找多个)
CLIP
from torch import nn
import torch
from img_encoder import ImgEncoder
from text_encoder import TextEncoderclass CLIP(nn.Module):"""CLIP (Contrastive Language-Image Pretraining) 模型的简化实现核心思想:将图像和文本映射到同一特征空间,通过对比学习让匹配的图文对距离更近"""def __init__(self,):super().__init__()# 初始化图像编码器:将图像转换为8维特征向量self.img_enc=ImgEncoder()# 初始化文本编码器:将文本序列转换为8维特征向量self.text_enc=TextEncoder()def forward(self,img_x,text_x):# 1. 图像编码:将输入图像转换为特征向量img_emb=self.img_enc(img_x)# 2. 文本编码:将输入文本转换为特征向量text_emb=self.text_enc(text_x)return img_emb@text_emb.Tif __name__=='__main__':clip=CLIP()img_x=torch.randn(5,1,28,28)text_x=torch.randint(0,10,(5,))logits=clip(img_x,text_x) # 编码后形状均为(5,8),点积后变成(5,5)print(logits.shape)
train
为什么需要在训练前筛选数据?
因为dataloader随机返回的批次(比如 64 个样本),可能存在 “缺少某些数字”(比如没有数字 7)或 “某个数字重复多次”(比如数字 2 有 8 个)的情况,无法满足对比学习的需求 —— 所以必须筛选。
从随机批次中,先筛选出‘包含 0-9 所有数字’的批次,再从这个批次中挑出‘每个数字各 1 个’的样本,最终得到 10 张图 + 10 个标签的标准对比批次,为后续计算图文相似度和对比损失铺路。
import torch
from dataset import MNIST
from clip import CLIP
import torch.nn.functional as F
from torch.utils.data import DataLoader
import os def main():# ========================== 超参数 ==============================ITER_BATCH_COUNT = 5000 # 迭代次数BATCH_SIZE = 64 # 批次大小TARGET_COUNT = 10 # 共10种数字# =========================== 准备材料(设备、数据、模型、优化器) ===============================DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu' # 设备print(f"Using device: {DEVICE}")dataset = MNIST() # 数据集dataloader = DataLoader( # 数据加载器dataset,batch_size=BATCH_SIZE, # 每批64个样本shuffle=True, # 打乱数据,保证训练随机性num_workers=4, # 4个进程并行加载数据,提升效率persistent_workers=True # 保持进程存活,避免反复创建销毁进程,进一步提速)model = CLIP().to(DEVICE) # 先搭骨架(创建 CLIP 模型实例)# 再填血肉(加载预训练参数,在此基础上继续训练,没有则用新模型)# 这里的参数是指图像编码器、文本编码器中涉及的所有可训练的 “权重和偏置”,比如卷积层的try: model.load_state_dict(torch.load('model.pth', weights_only=True))print("Model loaded successfully")except Exception as e:print(f"Could not load model: {e}")print("Starting with fresh model")optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 优化器# ============================== 训练 =============================for i in range(ITER_BATCH_COUNT):while True:imgs, labels = next(iter(dataloader)) # 从数据加载器取一批数据(dataloader会自动打乱数据,iter把datloader变成迭代器,next主动从迭代器中取出下一个元素)# 普通用法:for batch_idx, (imgs, labels) in enumerate(train_dataloader): for循环会自动帮忙调用iter和next# 确保批次中包含所有10种数字(0-9),否则重新取if torch.unique(labels).shape[0] < TARGET_COUNT:continue# 从该批次中挑选出“每种数字各1个”,共10个样本target = set() indexes = [] # 样本的索引for j in range(BATCH_SIZE): # 注意这里是批次if labels[j].item() in target:continue target.add(labels[j].item()) # .item()把数字从张量形式变回普通形式indexes.append(j)if len(target) == TARGET_COUNT: # 选够10个不同数字就停止breakimgs = imgs[indexes]labels = labels[indexes]break# 模型前向传播logits = model(imgs.to(DEVICE), labels.to(DEVICE))# 计算损失targets = torch.arange(0, TARGET_COUNT).to(DEVICE)loss_i = F.cross_entropy(logits, targets) # 图像侧损失:把logits看作“图像→文本的分类任务”loss_t = F.cross_entropy(logits.permute(1, 0), targets) # 文本侧损失:把logits转置后看作“文本→图像的分类任务”loss = (loss_i + loss_t) / 2# 反向传播和参数更新optimizer.zero_grad() loss.backward()optimizer.step() # 定期(这里是每1000轮)打印损失并保存模型if i % 1000 == 0:print(f'iter: {i}, loss: {loss.item()}')# 先保存到临时文件,再替换,防止模型保存中途失败导致原有的有效模型文件(model.pth)被破坏torch.save(model.state_dict(), '.model.pth')if os.path.exists('model.pth'):os.remove('model.pth')os.rename('.model.pth', 'model.pth') # 修正了错误的符号——→renameif __name__ == '__main__':# 在Windows系统中添加多进程支持,适配num_workers>0import multiprocessingmultiprocessing.freeze_support()main()
inference
'''
CLIP能力演示1、对图片做分类
2、对图片求相图片'''from dataset import MNIST
import matplotlib.pyplot as plt
import torch
from clip import CLIP
import torch.nn.functional as FDEVICE='cuda' if torch.cuda.is_available() else 'cpu' # 设备dataset=MNIST() # 数据集model=CLIP().to(DEVICE) # 模型
model.load_state_dict(torch.load('model.pth'))model.eval() # 预测模式'''
1、对图片分类
'''
image,label=dataset[1000]
print('正确分类:',label)
plt.imshow(image.permute(1,2,0))
plt.show()targets=torch.arange(0,10) #10种分类
logits=model(image.unsqueeze(0).to(DEVICE),targets.to(DEVICE)) # 1张图片 vs 10种分类
print(logits)
print('CLIP分类:',logits.argmax(-1).item())'''
2、图像相似度
'''
other_images=[]
other_labels=[]
for i in range(1,101):other_image,other_label=dataset[i]other_images.append(other_image)other_labels.append(other_label)# 其他100张图片的向量
other_img_embs=model.img_enc(torch.stack(other_images,dim=0).to(DEVICE))# 当前图片的向量
img_emb=model.img_enc(image.unsqueeze(0).to(DEVICE))# 计算当前图片和100张其他图片的相似度
logtis=img_emb@other_img_embs.T
values,indexs=logtis[0].topk(5) # 5个最相似的plt.figure(figsize=(15,15))
for i,img_idx in enumerate(indexs):plt.subplot(1,5,i+1)plt.imshow(other_images[img_idx].permute(1,2,0))plt.title(other_labels[img_idx])plt.axis('off')
plt.show()