Hystrix:熔断器
目录
一、概念
1.1 问题背景
1.2 概念
1.3 核心价值
1.4 能力边界
1.5 应用场景
1.6 现状与替代方案
二、原理与架构
2.1 核心架构与原理
2.1.1 熔断器模式 (Circuit Breaker)
2.1.2 资源隔离 (Isolation)
2.1.3 降级/回退 (Fallback)
2.1.4 请求缓存 (Request Caching)
2.1.5 请求折叠(Request Collapsing)
2.2 工作流程
三、使用
3.1 常见配置
3.2 使用
3.2.1 创建Eureka Server(服务注册中心)
3.2.2 创建服务提供者(Eureka Client)
3.2.3 创建服务消费者(集成Ribbon和Hystrix)
3.2.4 使用Hystrix实现熔断
3.2.5 测试熔断
3.3 监控
3.3.1 监控指标
3.3.2 指标流发布(hystrix-stream)
3.3.3 可视化监控(Hystrix Dashboard)
3.3.4 监控集群:Turbine
一、概念
1.1 问题背景
想象一个典型的微服务调用链:用户服务 -> 订单服务 -> 商品服务 -> 库存服务。
-
场景:某个时刻,
库存服务因为数据库压力过大或网络波动,响应变得非常缓慢(高延迟)。 -
问题:
-
如果
商品服务中没有保护措施,它对库存服务的调用线程会因等待响应而被大量阻塞。 -
这会导致
商品服务的线程池被耗尽,无法再处理新的请求(即使这些请求与库存无关)。 -
阻塞会向上蔓延,导致
订单服务、用户服务的线程也被耗尽。 -
最终,一个边缘服务的故障像雪崩一样席卷了整个应用系统,导致所有服务不可用。
-
这就是 “级联故障” 或 “服务雪崩”。
雪崩的诱因:
-
服务提供者响应缓慢:大量请求被阻塞,耗尽调用者的线程资源。
-
服务提供者失败:调用者会持续重试,进一步加剧系统负担。
1.2 概念
Hystrix 是一个由 Netflix 开源的延迟和容错库,旨在隔离对远程系统、服务和第三方库的访问点,停止级联故障,并在复杂的分布式系统中实现弹性。
它的名字来源于动物“猬鼠” (Hystrix),因为猬鼠在危险时会蜷缩成一团,形成自我保护,这形象地比喻了其熔断器 (Circuit Breaker) 的核心模式。
核心要解决的问题:在分布式环境中,不可避免的服务调用失败(如超时、异常)会通过复杂的调用链扩散,最终导致整个系统雪崩。
核心思想是:当某个服务单元发生故障后,通过断路器的故障监控,向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延。
目标:
-
隔离:通过线程池或信号量隔离依赖,避免一个依赖出问题拖垮整个应用。
-
熔断:快速失败,防止不断重试可能失败的依赖而耗尽整个系统的资源。
-
降级:提供备选方案(Fallback,如返回缓存数据、默认值等),当依赖失败时执行,保证核心流程可用。
-
监控:实时监控运行状态和配置变更。
1.3 核心价值
Hystrix 的核心价值在于为分布式系统提供了弹性和容错能力,具体体现在以下几个方面:
-
服务熔断(Circuit Breaker):
-
核心机制。当某个目标服务的调用失败率(如因网络超时、服务宕机)达到一个预设的阈值时,Hystrix 会启动熔断机制。
-
在熔断状态下,所有对该服务的请求会立即失败,而不再真正发起网络调用。这给了故障服务恢复的时间,避免了资源(如线程)的持续消耗。
-
经过一段时间的“睡眠期”后,Hystrix 会进入“半开”状态,尝试放行一部分请求。如果这些请求成功,则关闭熔断器,恢复正常调用;如果仍然失败,则继续保持熔断状态。
-
-
服务降级(FallBack):
-
当服务调用发生超时、异常、熔断时,Hystrix 允许提供一个备用的处理方案(FallBack Method)。
-
降级策略可以包括:返回一个默认值、使用本地缓存的数据、执行一个另一条查询路径、或者返回一个友好的提示信息。
-
价值:保证了主逻辑失败时,用户依然能得到一个响应,而不是一个错误页面或长时间的等待,提升了用户体验。
-
-
资源隔离(Bulkhead Pattern - 舱壁模式):
-
线程池隔离:Hystrix 默认会为每一个依赖服务(或命令)分配一个小的、独立的线程池。这样,即使某个依赖服务的调用变得缓慢,也只会耗尽该依赖自己的线程池,而不会影响其他依赖服务的调用。
-
信号量隔离:一种更轻量级的隔离方式,用于限制并发调用的数量。
-
价值:实现了依赖与服务调用者之间的隔离,避免了某个慢依赖拖垮整个系统(雪崩效应)。这是实现“弹性”的基石。
-
-
请求缓存(Request Caching):
-
在同一个用户请求范围内(如一次 Web 请求),对同一个依赖服务的多次重复调用,Hystrix 可以只执行第一次调用,后续的调用直接返回第一次的结果。
-
价值:减少不必要的网络开销,提升系统性能。
-
-
请求聚合(Request Collapsing):
-
可以将一段时间窗口内(如10ms)对同一个依赖服务的多个请求合并为一个批量请求发起。
-
价值:通过减少网络请求次数来降低开销,尤其适用于高频但低并发的场景。
-
-
近实时监控(Metrics & Monitoring):
-
Hystrix 会记录所有命令的执行结果、延迟、成功率等指标,并通过 Hystrix Dashboard 以近乎实时的方式展示。
-
价值:运维和开发人员可以直观地看到系统的健康状况和各个熔断器的状态,便于快速定位问题和进行决策。
-
1.4 能力边界
-
增加系统复杂性:引入熔断、降级、隔离等概念,意味着代码和配置会变得更加复杂。需要仔细地为每个依赖设置超时时间、线程池大小、熔断阈值等参数,配置不当可能适得其反。
-
资源开销:线程池隔离模式会带来额外的线程上下文切换开销。对于延迟极其敏感的应用,这可能成为性能瓶颈。此时可考虑信号量模式,但信号量模式不支持超时和异步。
-
主要用于同步调用:Hystrix 的设计核心是围绕命令模式(
HystrixCommand)包装同步或异步(返回Future)的调用。对于响应式编程(如 Reactor, RxJava)的支持并非其原生强项。 -
维护模式:Netflix 已宣布 Hystrix 进入维护模式,不再开发新功能。其内部已迁移至更具弹性的系统(如
resilience4j和Spring Cloud Circuit Breaker)。对于新项目,建议考虑这些更现代、对响应式编程支持更好的替代方案。
1.5 应用场景
Hystrix 非常适合用于同步调用占主导地位的微服务架构中,尤其是以下场景:
-
第三方服务/API 调用:
-
调用外部支付网关、地图服务、短信服务等。这些服务不在自己的控制范围内,其可用性和延迟无法保证。使用 Hystrix 可以避免因为第三方服务不稳定而导致你的核心业务流程中断。
-
-
数据库和中间件访问:
-
对数据库、缓存(Redis)、消息队列(Kafka)的访问。如果这些中间件响应变慢,Hystrix 可以快速失败,避免大量应用线程被阻塞,导致整个应用无响应。
-
-
微服务间的内部调用:
-
在微服务架构中,服务 A 调用服务 B,服务 B 又调用服务 C。这是级联故障的高发地。为每个服务间的调用配置 Hystrix,是保证整个系统弹性的关键。
-
-
耗时且非核心的操作:
-
例如,生成报表、发送通知邮件、记录详细的操作日志等。这些操作可以配置降级逻辑(如将日志先写入本地文件队列),保证核心交易链路(如下单、支付)的流畅性。
-
1.6 现状与替代方案
| 特性 | Hystrix | Resilience4j | Sentinel | Spring Cloud Circuit Breaker |
|---|---|---|---|---|
| 开发者 | Netflix | Resilience4j 社区 | 阿里巴巴 | Spring 社区 |
| 当前状态 | 维护模式 (已停止新功能开发) | 活跃维护 | 活跃维护 | 活跃维护 (抽象层) |
| 设计定位 | 容错和延迟管理 | 轻量级容错库 | 流量控制和熔断降级 | 熔断器抽象 |
| 核心功能 | 熔断、降级、请求缓存、请求合并 | 熔断、限流、隔板、重试、降级 | 流量控制、熔断降级、系统负载保护 | 熔断、降级 (依赖底层实现) |
| 隔离机制 | 线程池隔离、信号量隔离 | 信号量隔离 (默认) | 信号量隔离 (基于并发数) | 依赖底层实现 |
| 性能开销 | 较高 (线程池隔离带来额外开销) | 较低 | 较低 | 依赖底层实现 |
| 动态配置 | 不支持 (需自行实现) | 支持 | 支持 (强大Dashboard) | 依赖底层实现 |
| 实时监控 | 有限支持 (需Hystrix Dashboard) | 支持 (与Micrometer等集成好) | 强大支持 (开箱即用控制台) | 依赖底层实现 |
| 规则配置 | 相对静态 | 支持动态配置 | 支持多种数据源动态配置 | 依赖底层实现 |
| 适用场景 | 遗留系统、需要请求缓存/合并的场景 | 新项目、轻量级容错、函数式编程 | 高性能流量控制、实时监控需求高 | Spring Cloud项目、希望灵活切换底层实现 |
选择建议:
-
新项目或技术栈升级:不建议再选择 Hystrix。应从 Resilience4j 或 Sentinel 中根据具体需求选择。
-
现有 Hystrix 遗留系统:若系统稳定且暂无改造计划,可继续使用并关注社区安全动态。但对于新功能开发或长远考虑,建议制定计划逐步迁移到 Resilience4j 或 Sentinel。
-
Spring Cloud 用户:可以优先考虑 Spring Cloud Circuit Breaker 配合 Resilience4j 或 Sentinel 使用,以获得更好的生态一致性和灵活性。
二、原理与架构
2.1 核心架构与原理
Hystrix 通过 HystrixCommand 或 HystrixObservableCommand 封装所有的外部调用(通常是一个方法)。执行这个命令时,Hystrix 会应用以下弹性模式:
2.1.1 熔断器模式 (Circuit Breaker)
这是 Hystrix 最核心的机制。它类似于家庭电路中的保险丝。
熔断器的工作流程是一个状态机,包含三种状态:
-
关闭 (Closed):请求正常通过,熔断器关闭。同时熔断器会统计最近一段时间内的失败率(如超时、异常等)。如果在一个统计时间窗口内,失败的请求比例超过设定的阈值(默认:10秒内超过20次请求失败,且失败率>50%),熔断器就会跳闸,进入
Open状态。 -
打开 (Open):在此状态下,所有请求都会被立即拒绝并抛出
HystrixRuntimeException,不再发起真实调用。这样做是为了给依赖服务时间来自我修复。会设置一个休眠时间窗口(例如 5 秒)。超过这个窗口后,熔断器会进入Half-Open状态。 -
半开 (Half-Open):熔断器会“小心翼翼地”允许一个请求通过,去调用依赖服务。如果这个请求成功了,熔断器认为依赖服务已恢复,则状态变为
Closed,恢复正常调用;如果这个请求失败了,熔断器则认为依赖服务仍然有问题,状态变回Open,并进入下一个休眠时间窗口。
2.1.2 资源隔离 (Isolation)
这是 Hystrix 的基石。Hystrix 使用 “舱壁模式” 来实现隔离。就像轮船的防水舱壁将船体分隔成多个船舱一样,即使一个船舱进水,整艘船也不会沉没。Hystrix 对每个依赖服务分配一个小的、独立的线程池(或信号量),这样每个依赖的调用都在自己的隔离舱内进行,避免了某个慢依赖耗尽整个系统的所有线程资源。
Hystrix 提供了两种隔离策略:
-
线程隔离(默认且推荐):
-
每个依赖服务有自己独立的线程池,执行命令在一个单独的线程中进行。
-
优点:超时控制天然可用,调用线程可以异步返回,不受依赖服务耗时影响。
-
开销:线程调度和上下文切换有一定性能开销,但对于 Netflix 这种规模的公司,这点开销远优于系统雪崩带来的损失。
-
-
信号量隔离:
-
使用原子计数器(信号量)来限制对某个依赖的并发调用量。
-
优点:轻量级,无额外线程开销。
-
缺点:无法支持超时,调用是同步的,一旦阻塞,会占用调用者线程。
-
适用场景:通常用于非网络调用(如内存缓存查询)、或信任度极高的高频高速调用。
-
选择:通常远程调用(网络I/O)使用线程池隔离;内部内存调用使用信号量隔离。
2.1.3 降级/回退 (Fallback)
当命令执行失败(超时、异常、熔断器打开、线程池满)时,Hystrix 会执行一个预先定义好的降级逻辑,试图提供一个替代的响应。
常见Fallback方案:
-
返回静态默认值。
-
从本地缓存中返回过时但可用的数据。
-
调用另一个备用的服务。
-
返回一个空值或友好的错误提示。
实现方式:重写HystrixCommand.getFallback()方法。
2.1.4 请求缓存 (Request Caching)
在同一请求上下文中(如一次Web请求),对相同参数的HystrixCommand可以直接返回缓存的结果,避免重复执行。但需要手动开启和清理。通过 @CacheResult 等注解实现。
2.1.5 请求折叠(Request Collapsing)
将一段时间内(如10ms窗口)对同一依赖的多个请求自动合并为一个批量请求,减少网络开销。(通常用于高频、小批量的场景)。特别适用于高延迟的命令操作。但需要后端服务提供相应的批量接口。过 HystrixCollapser 实现。
2.2 工作流程
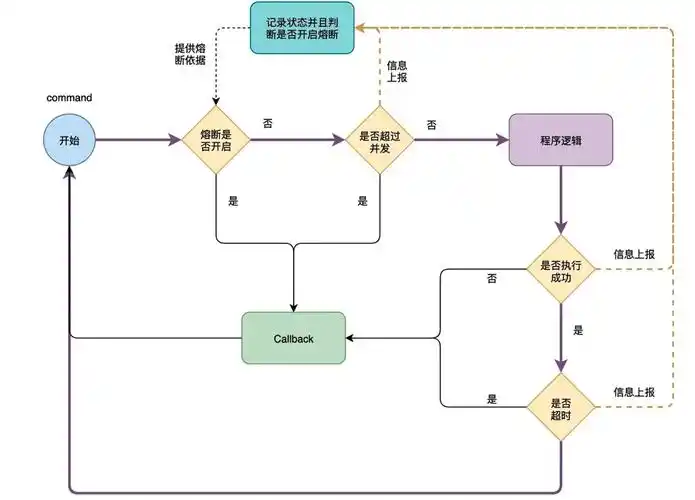
-
构建命令:将调用请求封装成
HystrixCommand或HystrixObservableCommand对象。 -
执行命令:通过调用
execute()(同步)、queue()(异步Future)或observe()(响应式Observable)来执行命令。 -
检查缓存:(可选) 如果启用了请求缓存(Request Cache),并且本次请求的响应已在缓存中,则立即返回缓存的结果。
-
检查熔断器:如果熔断器是打开
Open状态,直接跳到第8步(执行Fallback)。如果为Closed,继续下一步。 -
检查资源:检查资源隔离池(线程池或信号量)是否已满。如果已满,则拒绝请求,直接跳到步骤 8(执行 Fallback)。这一步实现了限流。
-
执行调用:在独立的线程中(线程池隔离)或当前线程中(信号量隔离)执行真正的依赖调用。在
HystrixCommand.run()或HystrixObservableCommand.construct()方法中,执行业务逻辑(如网络请求)。如果执行超时或失败,也会跳到步骤 8。 -
计算统计:收集成功、失败、超时、拒绝等请求数量指标,用于熔断器的决策。
-
获取Fallback:当第4、5、6步出现任何错误时(熔断器打开、线程池满、
run执行异常等),执行getFallback()方法获取降级结果(如缓存值、友好提示、空结果等)。如果Fallback也失败,则抛出异常。 -
返回响应:将成功或降级的结果返回给调用者。
三、使用
3.1 典型的应用场景:电商网站的下单流程
-
依赖:下单服务需要调用:库存服务(扣减库存)、优惠券服务(核销优惠券)、用户服务(校验用户状态)。
-
风险:在大促期间,库存服务可能因为压力过大导致响应极慢。
-
Hystrix 方案:
-
为“调用库存服务”这个命令设置一个较小的超时时间(如 500ms)。
-
配置熔断器(失败率阈值 50%, 睡眠窗口 5秒)。
-
设置降级逻辑:当调用库存服务失败(超时、熔断)时,降级到一个预扣库存的本地缓存,先将订单创建成功,并记录下需要异步扣减库存的任务。
-
这样,用户下单这个核心流程就不会被一个慢的依赖所阻塞,订单能先成功创建。后续通过一个异步任务去最终完成库存的扣减。
-
同时,通过 Hystrix Dashboard 监控,运维人员可以清晰地看到库存服务的熔断器已经“跳闸”,从而快速定位到系统瓶颈。
-
3.1 常见配置
主要可配置项(以注解方式为例):
| 配置类别 | 配置项 | 说明 | 常用默认值 |
|---|---|---|---|
| 执行策略 | execution.isolation.strategy | 隔离策略:THREAD(线程池)或 SEMAPHORE(信号量) | THREAD |
| 超时控制 | execution.isolation.thread.timeoutInMilliseconds | 命令执行超时时间(毫秒) | 1000 |
| 熔断器 | circuitBreaker.requestVolumeThreshold | 熔断触发前在滚动时间窗口内的最小请求数 | 20 |
circuitBreaker.errorThresholdPercentage | 触发熔断的错误百分比阈值 | 50 | |
circuitBreaker.sleepWindowInMilliseconds | 熔断后经过多久尝试半开(毫秒) | 5000 | |
| 降级 | fallback.isolation.semaphore.maxConcurrentRequests | 允许执行 fallback 方法的最大并发请求数 | 10 |
| 线程池 | threadPoolProperties 中的 coreSize | 线程池核心线程数 | 10 |
maxQueueSize | 线程池最大队列大小(-1 使用 SynchronousQueue) | -1 |
执行策略:
-
线程池隔离 (
THREAD): 默认策略。每个依赖服务使用独立的线程池执行调用。即使某个依赖服务变慢或故障,也不会耗尽所有资源,避免级联故障。但线程上下文切换会带来额外开销。 -
信号量隔离 (
SEMAPHORE): 在调用线程上执行,通过信号量计数器限制最大并发请求数。开销更小,适用于内部调用或延迟极低的场景,但不如线程池隔离安全。
3.2 使用
在springboot项目中,用Eureka+Ribbon+Hystrix构建
-
Eureka:服务注册与发现中心。
-
Ribbon:通过
@LoadBalanced实现客户端负载均衡。 -
Hystrix:
-
使用
@HystrixCommand注解快速实现熔断。 -
通过
fallbackMethod指定降级逻辑。 -
监控熔断状态(可通过Hystrix Dashboard可视化)。
-
3.2.1 创建Eureka Server(服务注册中心)
1、创建Spring Boot项目,添加依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>2、主类添加注解:
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {public static void main(String[] args) {SpringApplication.run(EurekaServerApplication.class, args);}
}3、配置 application.yml:
server:port: 8761
eureka:client:register-with-eureka: false # 不注册自己fetch-registry: false # 不拉取注册信息3.2.2 创建服务提供者(Eureka Client)
1、创建新Spring Boot项目,添加依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>2、主类添加注解:
@SpringBootApplication
@EnableEurekaClient
public class ProviderApplication {public static void main(String[] args) {SpringApplication.run(ProviderApplication.class, args);}
}3、配置 application.yml:
server:port: 8081
spring:application:name: service-provider # 服务名称
eureka:client:service-url:defaultZone: http://localhost:8761/eureka/4、创建测试接口:
@RestController
public class ProviderController {@GetMapping("/hello")public String hello() {return "Hello from Provider!";}
}3.2.3 创建服务消费者(集成Ribbon和Hystrix)
1、创建新Spring Boot项目,添加依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!-- Eureka Client 依赖 (通常已包含 ribbon) -->
<!-- <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency> -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>2、主类添加注解:
@SpringBootApplication
@EnableEurekaClient
@EnableHystrix // 启用Hystrix
public class ConsumerApplication {public static void main(String[] args) {SpringApplication.run(ConsumerApplication.class, args);}
}3、配置application.yml:
server:port: 8082
spring:application:name: service-consumer
eureka:client:service-url:defaultZone: http://localhost:8761/eureka/
hystrix:command:default:execution:isolation:thread:timeoutInMilliseconds: 3000 # 熔断超时时间4、配置Ribbon的负载均衡 RestTemplate:
@Configuration
public class RibbonConfig {@Bean@LoadBalanced // 开启负载均衡public RestTemplate restTemplate() {return new RestTemplate();}
}3.2.4 使用Hystrix实现熔断
方式1:注解方式(推荐)
在服务调用方法上添加 @HystrixCommand:
@Service
public class ConsumerService {@Autowiredprivate RestTemplate restTemplate;// 调用服务提供者的接口,并指定熔断方法@HystrixCommand(fallbackMethod = "fallbackHello")public String callHello() {// 通过服务名调用(Ribbon负载均衡)return restTemplate.getForObject("http://service-provider/hello", String.class);}// 熔断方法(参数和返回值需与原方法一致)public String fallbackHello() {return "Fallback: Service is down!";}
}方式2:自定义Hystrix命令
public class HelloCommand extends HystrixCommand<String> {private final RestTemplate restTemplate;public HelloCommand(RestTemplate restTemplate) {super(HystrixCommandGroupKey.Factory.asKey("HelloGroup"));this.restTemplate = restTemplate;}@Overrideprotected String run() throws Exception {return restTemplate.getForObject("http://service-provider/hello", String.class);}@Overrideprotected String getFallback() {return "Fallback: Custom Command";}
}扩展:
配置熔断器机制: 熔断器是 Hystrix 的核心。它会在失败率达到阈值时打开熔断,短时间内快速失败,过后再尝试恢复。可以通过 commandProperties 配置熔断器行为。
@HystrixCommand(fallbackMethod = "fallback",commandProperties = {@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"), // 滚动窗口内最小请求数@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"), // 错误百分比阈值@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "10000"), // 熔断后多久尝试恢复(半开状态)@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") // 超时时间})
public String doSomething() {// ... 可能失败的业务逻辑
}线程池配置与隔离:默认情况下,Hystrix 使用线程池隔离。可以为不同的命令配置独立的线程池,避免资源竞争。
@HystrixCommand(fallbackMethod = "fallback",threadPoolKey = "myThreadPool", // 线程池标识threadPoolProperties = {@HystrixProperty(name = "coreSize", value = "20"), // 核心线程数@HystrixProperty(name = "maxQueueSize", value = "100") // 最大队列大小},commandProperties = {@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD") // 明确指定线程池隔离})
public String withThreadPool() {// ... 业务逻辑
}高级特性:请求合并
对于高并发场景中短时间内的大量相同请求,Hystrix 提供了请求合并(Request Collapsing)功能,可以将多个请求合并为一个批量请求,减少网络开销。
@HystrixCollapser(batchMethod = "batchGetUsers", collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds", value = "100"), // 合并时间窗口100ms@HystrixProperty(name = "maxRequestsInBatch", value = "100") // 批处理最大请求数})
public Future<User> getUserByIdCollapsed(Long id) {return null; // 方法体通常为空,实际执行在 batchMethod
}@HystrixCommand
public List<User> batchGetUsers(List<Long> ids) {// 一次性批量查询多个用户return restTemplate.getForObject("http://user-service/users/batch?ids={ids}", List.class, StringUtils.join(ids, ","));
}3.2.5 测试熔断
1、启动所有服务:
-
Eureka Server(端口8761)
-
服务提供者(端口8081)
-
服务消费者(端口8082)
2、正常访问消费者接口:
GET http://localhost:8082/call-hello
返回:"Hello from Provider!"3、触发熔断:
-
停止服务提供者
-
再次访问消费者接口:
返回:"Fallback: Service is down!"3.3 监控
3.3.1 监控指标
HystrixCommand 指标:反映了每个被封装命令的执行情况。
-
流量(Volume):
-
请求数(Request Count):单位时间内的请求总量。
-
-
延迟(Latency):
-
延迟百分位数(Latency Execute Percentile):如 p50, p90, p99, p99.5,反映了请求执行时间的分布,对性能调优至关重要。
-
-
错误比例(Errors):
-
错误计数 和 错误百分比:失败请求的数量和比例。这里的“错误”是广义的,包括:
-
失败(Failure):
run()方法抛出的异常(如业务异常、网络异常)。 -
超时(Timeout):执行超过设定的
timeoutInMilliseconds。 -
短路(Short-Circuited):因熔断器打开而被拒绝的请求。
-
线程池拒绝(Thread Pool Rejected):因线程池/队列已满而被拒绝的请求。
-
-
-
熔断器状态(Circuit Breaker):
-
状态:直接显示熔断器是
CLOSED,OPEN, 还是HALF-OPEN。 -
错误百分比:当前统计窗口内的错误百分比,是熔断器跳闸的依据。
-
-
并发执行(Concurrent Execution):
-
当前正在执行的命令数量。
-
-
降级(Fallback):
-
成功执行降级逻辑的请求数量。
-
HystrixThreadPool 指标:反映了隔离线程池本身的健康状况。
-
线程池活跃线程数:当前活跃的线程数。
-
线程池队列大小:当前排队等待执行的任务数。如果这个数持续很高,说明线程池可能已经饱和。
-
线程池大小:核心线程池大小和最大线程池大小。
-
线程池执行次数:线程池完成的任务数量。
3.3.2 指标流发布(hystrix-stream)
要让监控数据能被外部系统(如 Dashboard)消费,需要在服务中暴露一个端点。
-
对于 Spring Boot 应用:只需在依赖中引入
spring-cloud-starter-netflix-hystrix,它就会自动注册一个Servlet。 -
访问方式:应用启动后,你可以通过
http://your-service-ip:port/actuator/hystrix.stream来访问这个指标流。 -
数据格式:这个端点返回的是
text/event-stream格式的数据(SSE),内容是一系列连续的 JSON 文档,每个文档包含了所有HystrixCommand和HystrixThreadPool的最新指标。
示例 hystrix-stream 输出片段:
data: {"type": "HystrixCommand","name": "GetUserByIdCommand","group": "UserService","currentTime": 1646389200000,"isCircuitBreakerOpen": false,"errorPercentage": 0,"requestCount": 100,"rollingCountFailure": 2,"rollingCountTimeout": 1,"rollingCountSuccess": 97,"rollingCountShortCircuited": 0,"rollingCountThreadPoolRejected": 0,"latencyExecute": { "0": 10, "25": 15, "50": 20, "75": 30, "90": 40, "95": 50, "99": 100, "99.5": 150, "100": 200 },... // 其他指标
}data: {"type": "HystrixThreadPool","name": "UserService","currentTime": 1646389201000,"currentActiveCount": 3,"currentQueueSize": 0,...
}3.3.3 可视化监控(Hystrix Dashboard)
它是一个独立的 Spring Boot Web 应用程序,专门用于监控 hystrix-stream 端点。它提供了一个图形化界面,将枯燥的 JSON 数据转化为直观的、信息丰富的仪表盘。
Dashboard 为每个 HystrixCommand 显示一个卡片,卡片包含以下关键信息:
-
Circuit(熔断器状态):
-
圆圈的颜色和数字表示状态和流量。绿色(健康)、黄色(偶尔失败)、红色(熔断打开)。
-
圆圈下方的数字是流量(请求数)。
-
-
Host & Cluster(主机与集群):显示请求的吞吐量(每秒请求数)。
-
Success / Short-Circuited / Bad Request etc.(成功/短路/错误请求等):这是一系列计数器,以每秒的形式展示了各种结果的请求数。颜色对应结果类型(绿色成功,蓝色短路,紫色超时等)。
-
Thread Pools(线程池):显示线程池的活跃线程数和队列大小。
-
Latency Percentiles(延迟百分位):以仪表盘形式展示最近一分钟的延迟分布(中位数、90线、99线等)。
-
Counts(计数器聚合):以数字形式展示成功、失败等请求的总数。
创建 Hystrix Dashboard 项目:
1、新建项目并添加依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<!-- 如果需要监控单体应用,通常还需要此依赖 -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>2、启用 Dashboard 功能:在 Spring Boot 的主启动类上添加 @EnableHystrixDashboard 注解。
@SpringBootApplication
@EnableHystrixDashboard // 启用 Hystrix Dashboard 功能
public class HystrixDashboardApplication {public static void main(String[] args) {SpringApplication.run(HystrixDashboardApplication.class, args);}
}3、基础配置:在 application.yml 中进行基本配置,例如指定端口和应用名称。
server:port: 7979 # Dashboard 自身的访问端口,可按需修改
spring:application:name: hystrix-dashboard完成后启动项目,访问 http://localhost:7979/hystrix(端口请替换为你的实际配置)即可看到 Hystrix Dashboard 的主页。
配置要被监控的微服务:
要让 Dashboard 能监控到你的微服务,需要在被监控的服务中进行一些配置。
1、添加必要的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>2、暴露 Hystrix 监控端点
Actuator 2.x 版本后,端点需要显式暴露。在微服务的 application.yml 中配置:
management:endpoints:web:exposure:include: "hystrix.stream" # 暴露 hystrix.stream 端点3、启用 Hystrix 并注册 Servlet(可选)
-
在微服务的启动类上添加
@EnableCircuitBreaker或@EnableHystrix注解以启用 Hystrix。 -
注意:对于 Spring Boot 2.2+ 和 Spring Cloud Greenwich+ 版本,通常只需暴露端点即可通过
/actuator/hystrix.stream访问。如果你遇到无法访问的情况,或者使用的是较旧版本,可以尝试通过注册Servlet的方式:
@Configuration
public class HystrixConfig {@Beanpublic ServletRegistrationBean<HystrixMetricsStreamServlet> getServlet() {HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();ServletRegistrationBean<HystrixMetricsStreamServlet> registrationBean = new ServletRegistrationBean<>(streamServlet);registrationBean.setLoadOnStartup(1);registrationBean.addUrlMappings("/hystrix.stream"); // 通过 /hystrix.stream 访问registrationBean.setName("HystrixMetricsStreamServlet");return registrationBean;}
}注册 Servlet 后,监控数据端点通常是 /hystrix.stream,而非 /actuator/hystrix.stream。
4、验证监控端点
启动微服务后,尝试访问 http://你的微服务地址:端口/actuator/hystrix.stream(如果配置了 Servlet,也可能是 http://你的微服务地址:端口/hystrix.stream)。如果看到持续输出的 ping: 数据,说明监控端点配置成功。
在 Dashboard 中监控微服务:
-
输入监控地址
在 Hystrix Dashboard 主页 (
http://localhost:7979/hystrix) 的输入框中:-
填写要监控的微服务的 hystrix.stream 端点地址(例如:
http://localhost:8100/actuator/hystrix.stream)。 -
设置一个合适的 Delay(毫秒),如
2000,这是数据刷新频率。 -
给这个监控起一个 Title(例如:
Order-Service)。
-
-
点击监控
点击 "Monitor Stream" 按钮,即可进入该微服务的实时监控面板。
-
观察监控数据
刚开始可能会显示 "Loading..."。需要触发一些被 Hystrix 保护的请求(即使用了
@HystrixCommand注解的方法)后,监控数据才会显示出来。你可以通过访问微服务的相关接口来产生请求。
Hystrix Dashboard 监控面板上的关键元素含义:
| 指标元素 | 含义 |
|---|---|
| 实心圆 (Circle) | 健康度与流量:颜色表示健康度(绿色>黄色>橙色>红色递减),大小表示流量大小,流量越大实心圆越大。 |
| 曲线 (Line Chart) | 2分钟内流量变化趋势:折线图,反映流量波动情况。 |
| Host | 集群节点信息(监控单实例时意义不大)。 |
| Cluster | 集群信息(监控单实例时意义不大)。 |
| Circuit Breaker Status | 熔断器状态:CLOSED (关闭)、OPEN (开启熔断)、HALF_OPEN (半开)。非常关键的状态指示。 |
3.3.4 监控集群:Turbine
在微服务架构中,一个服务通常有多个实例。如果逐个去监控每个实例的 hystrix-stream 会非常繁琐且无法形成全局视图。
Turbine 就是为了解决这个问题而生的。它是一个服务器端组件,用于聚合多个实例的 hystrix-stream。
-
工作原理:
-
Turbine 配置一个需要监控的服务列表(如
user-service)。 -
通过服务发现(如 Eureka)找到
user-service的所有实例。 -
Turbine 会持续从每个实例的
hystrix-stream拉取数据。 -
将这些数据聚合成一个单一的、聚合后的指标流。
-
-
使用:在 Hystrix Dashboard 中,你不再输入单个实例的流地址(如
http://instance1:port/actuator/hystrix.stream),而是输入 Turbine 聚合后的流地址(如http://turbine-server:port/turbine.stream?cluster=USER-SERVICE)。这样,Dashboard 显示的就是整个user-service集群的聚合健康状况。
Turbine 集成与使用步骤:
1、添加 Maven 依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
<!-- 如果使用 Eureka 进行服务发现 -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!-- 如果需要同时在此服务中开启 Hystrix Dashboard -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>2、启用 Turbine
在 Turbine 服务主启动类上添加 @EnableTurbine 注解。如果此服务也作为 Dashboard,则可添加 @EnableHystrixDashboard。
@SpringBootApplication
@EnableTurbine // 核心注解,启用Turbine
@EnableHystrixDashboard // 如果此服务也作为Dashboard
@EnableDiscoveryClient // 如果使用服务发现(如Eureka)
public class TurbineServerApplication {public static void main(String[] args) {SpringApplication.run(TurbineServerApplication.class, args);}
}3、配置 application.yml
server:port: 8787 # Turbine服务端口,按需修改spring:application:name: turbine-aggregator-service # 服务名# Turbine 配置
turbine:# 指定需要聚合监控数据的服务名(即注册到Eureka上的服务名称),多个用逗号分隔app-config: service-user,service-order,service-product# 集群名称表达式,通常设置为 'default' 或引用Eureka中的元数据cluster-name-expression: new String("default")# 组合主机和端口作为服务实例ID,用于区分同一主机上的不同实例combine-host-port: true# 如果使用Eureka
eureka:client:service-url:defaultZone: http://localhost:8761/eureka/ # Eureka服务器地址instance:prefer-ip-address: true-
turbine.app-config: 这是最重要的配置,指定了想要聚合哪些微服务的 Hystrix 数据。这些名称应与被监控微服务在 Eureka 上注册的spring.application.name一致。 -
turbine.cluster-name-expression: 定义集群名称。new String("default")是常见设置,表示一个默认集群。你也可以根据 Eureka 实例的元数据(metadata)来定义更复杂的集群划分。 -
turbine.combine-host-port: 建议设为true,确保以主机名:端口来唯一标识实例,防止本地调试时多个实例被误认为一个。
4、配置被监控的微服务
确保被监控微服务(如 service-user, service-order)满足:
-
已经集成了
spring-cloud-starter-netflix-hystrix。 -
已经通过
@EnableCircuitBreaker或@EnableHystrix启用了 Hystrix。 -
暴露了 Hystrix 监控端点(通常在
application.yml中配置):
management:endpoints:web:exposure:include: hystrix.stream # 暴露actuator的hystrix.stream端点-
已经注册到了服务发现组件(如 Eureka)。
5、启动与监控
-
启动服务:按顺序启动 Eureka Server → 所有被监控的微服务 → Turbine 聚合服务。
-
访问 Turbine 流:在浏览器中访问
http://<turbine-server-host>:<port>/turbine.stream(例如http://localhost:8787/turbine.stream)。应该会看到一个持续输出 ping 事件但暂时没有具体监控数据的流。 -
在 Dashboard 中查看:
-
打开 Hystrix Dashboard(可能是独立服务,也可能是 Turbine 服务自身,取决于是否添加了依赖并开启了
@EnableHystrixDashboard)。 -
在监控地址输入框中,填入 Turbine 流的地址,即
http://<turbine-server-host>:<port>/turbine.stream。 -
点击 Monitor Stream,即可看到一个聚合了所有配置服务监控信息的界面。
-