Python语法学习篇(七)【py3】
内建模块
除去前文提到过的模块,Py内置了许多有用的模块。本文详细附上一些示例代码来了解一些模块。
collections
nametuple
普通的 tuple 只能通过下标取值,不够直观。p=(1,2),直观来看很难看懂这个是坐标还是别的。
namedtuple 可以让元素带名字,用属性访问,更易读
from collections import namedtuple# 定义一个 Point 类型,包含 x 和 y
Point = namedtuple('Point', ['x', 'y'])p = Point(1, 2)print(p.x, p.y) # 1 2
print(isinstance(p, tuple)) # True
再比如表示圆:
Circle = namedtuple('Circle', ['x', 'y', 'r'])
c = Circle(0, 0, 5)
print(c) # Circle(x=0, y=0, r=5)
其式子如下:
# namedtuple('名称', [属性 list])
deque
普通的 list 在头部插入/删除效率低,deque(双端队列)在两端操作都很快,适合用于队列和栈
from collections import dequeq = deque(['a', 'b', 'c'])
q.append('x') # 右侧添加
q.appendleft('y') # 左侧添加print(q) # deque(['y', 'a', 'b', 'c', 'x'])print(q.pop()) # 从右取出 → 'x'
print(q.popleft()) # 从左取出 → 'y'
defaultdict
普通 dict 访问不存在的 key 会报错,抛出KeyError,defaultdict 可以给个默认值
from collections import defaultdictdd = defaultdict(lambda: "N/A")dd["name"] = "Tom"
print(dd["name"]) # Tom
print(dd["age"]) # N/A (不存在的 key 返回默认值)
OrderedDict
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d)od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od)
d1=dict()
d1['a']=1
d1['b']=2
d1['c']=3
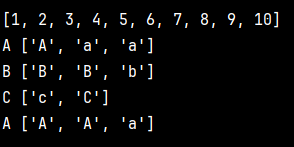
print(d1.keys())od1=OrderedDict()
od1['a']=1
od1['c']=3
od1['b']=2
print(od1.keys())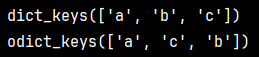
可以看到,现在dict已经默认带有了order属性
📌 特殊用法:实现一个 固定大小的 FIFO 缓存。
from collections import OrderedDictclass LastUpdatedOrderedDict(OrderedDict):def __init__(self, capacity):super().__init__()self._capacity = capacitydef __setitem__(self, key, value):if key in self:del self[key] # 先删除旧的elif len(self) >= self._capacity:self.popitem(last=False) # 删除最早的super().__setitem__(key, value)# 使用
cache = LastUpdatedOrderedDict(2)
cache["a"] = 1
cache["b"] = 2
cache["c"] = 3
print(cache) # OrderedDict([('b', 2), ('c', 3)])
Counter
最常见的计数器,本质也是dict的子类
from collections import Counterc = Counter("programming")
print(c)
# Counter({'r': 2, 'g': 2, 'm': 2, 'p': 1, 'o': 1, 'a': 1, 'i': 1, 'n': 1})
print(isinstance(c, dict))
print(c.most_common(2))#前两个高频元素
words = ["apple", "banana", "apple", "orange", "banana", "apple"]
c = Counter(words)
print(c) # Counter({'apple': 3, 'banana': 2, 'orange': 1})

小结
| 工具 | 功能 | 常见场景 | 示例代码(简化版) |
|---|
| namedtuple | 给 tuple 元素起名字,支持属性访问 | 坐标、圆形、学生成绩等固定数据结构 | python\nfrom collections import namedtuple\nPoint = namedtuple('Point', ['x', 'y'])\np = Point(1, 2)\nprint(p.x, p.y) # 1 2 |
| deque | 双端队列,两端插入/删除效率高 | 队列(FIFO)、栈(LIFO)、BFS 算法 | python\nfrom collections import deque\nq = deque(['a','b'])\nq.append('x'); q.appendleft('y')\nprint(q) # deque(['y','a','b','x']) |
| defaultdict | dict 的扩展,不存在的 key 返回默认值 | 统计、分组,避免 KeyError | python\nfrom collections import defaultdict\ndd = defaultdict(list)\ndd['fruits'].append('apple')\nprint(dd) # {'fruits': ['apple']} |
| OrderedDict | 保持插入顺序的 dict | FIFO 缓存、顺序敏感的字典操作 | python\nfrom collections import OrderedDict\nod = OrderedDict()\nod['a']=1; od['b']=2\nprint(od) # OrderedDict([('a',1),('b',2)]) |
| Counter | 计数器,统计元素出现次数 | 统计字符/单词频率,高频分析 | python\nfrom collections import Counter\nc = Counter('banana')\nprint(c) # Counter({'a':3,'n':2,'b':1}) |
Base64
Base64是一种用64字符来表示任意二进制数据的方法。我们常常遇到用记事本打开某些文件时能看见一堆乱码。记事本这种文本处理软件没法处理一些二进制文件里的字符。所以需要一个二进制到字符串的转换方法。Base64就是其中一种。
其原理涉及计算机组成知识,本质是对二进制文件处理时每3个字节一组,也就是24bit。而后划分为4组,也就是6bit一组。这4个数字作为索引去查表,获得对应的4个字符,也就是编译后的字符串。因此整个流程下来会把3字节的二进制数据编码为4字节的文本。长度增加了1/3。
那如果出现二进制数据不是3的倍数怎么办?Base64会用\x00字节在末尾补足,同时加上1个或2个=号,用以表示补充了多少字节。在解码时就自动去掉了。
import base64
print(base64.b64encode(b'hello,World'))![]() ,b表示Buffer类型
,b表示Buffer类型
print(base64.b64decode(b'aGVsbG8sV29ybGQ='))![]()
由于标准的 Base64 编码后可能出现字符+和/,在 URL 中就不能直接作为参数,所以又有一种"url safe"的 base64 编码,其实就是把字符+和/分别变成-和_
Base64 是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。Base64 适用于小段内容的编码,比如数字证书签名、Cookie 的内容等。由于=字符也可能出现在 Base64 编码中,但=用在 URL、Cookie 里面会造成歧义,所以,很多 Base64 编码后会把=去掉
print(base64.b64encode(b'abcd'))
print(base64.b64decode(b'YWJjZA=='))
print(safe_b64decode('YWJjZA'))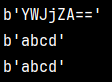
print(base64.b64decode('YWJjZA'))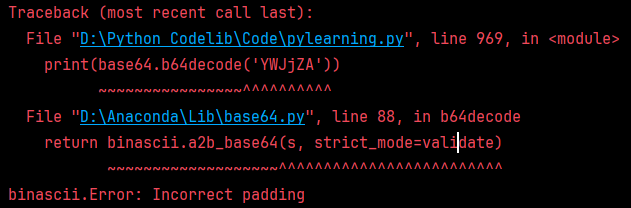
故而为了去掉=号也能正常解码,就采用safe_b64decode,其函数逻辑可以为下:
import base64def safe_b64decode(s: str) -> bytes:padding = 4 - len(s) % 4 if len(s) % 4 else 0s += "=" * paddingreturn base64.b64decode(s)print(safe_b64decode("YWJjZA")) # b'abcd'
struct
作用:二进制数据 ↔ Python 基本类型。
用法:
pack(fmt, data...)→ bytes
unpack(fmt, bytes)→ tuple常见格式符:
I4字节无符号整数
H2字节无符号整数
>大端序,<小端序
import struct# 解析 BMP 文件头信息
def bmp_info(path: str):with open(path, "rb") as f:header = f.read(30)sig, _, size, _, offset, hdr_size, width, height, _, colors = \struct.unpack("<ccIIIIIIHH", header)if sig == b'B' and hdr_size == 40:print(f"Size: {width}x{height}, Colors: {colors}")else:print("Not a valid BMP")bmp_info("./test.bmp")test.bmp请打开画图软件自行绘画,这里可以参考我的,在该文章绑定资源里寻找bmp文件。或是根据描述自行绘制。其程序结果大致如下:
![]()
关键点解析
struct.unpack("<ccIIIIIIHH", header)
<→ 小端序(BMP 文件使用小端格式)
cc→ 2 个char(对应文件标识,通常是"BM")
I→ 4 字节无符号整数 (unsigned int)
H→ 2 字节无符号整数 (unsigned short)所以这个格式一共解析:
cc I I I I I I H H
2 + 4 + 4 + 4 + 4 + 4 + 4 + 2 + 2 = 32 字节注意:代码里只读了 30 字节,其实严格来说应该读 32 字节才完整。
变量含义
sig→ 文件标识(通常b'B'和b'M',就是"BM")
_→ 占位,不关心的字段(比如保留字段)
size→ 整个 BMP 文件的大小(字节)
offset→ 像素数据的起始偏移量
hdr_size→ 信息头大小,标准 BMP 为 40
width→ 图片宽度
height→ 图片高度
colors→ 调色板中的颜色数(如果为 0,则表示使用默认 2^n)验证是否为标准 BMP
文件开头必须是
"BM"信息头大小必须是 40(Windows 常见的 BITMAPINFOHEADER 结构)
struct请参考官方文档:struct — Interpret bytes as packed binary data — Python 3.13.7 documentation
hashlib
就是常见的哈希算法,散列算法。这种又称摘要算法。通过一个函数把任意长度的data转换成长度固定的数据串(一般是十六进制),也就是映射成类似于密钥的串来防止原文被篡改。
摘要算法是单向函数,计算f(data)得到结果很容易,但拿着结果反推data很困难。因此在网络安全领域有着广泛应用。
其代表有MD5、SHA1、SHA256…,感兴趣读者自行搜索
import hashlibdef get_md5(s: str) -> str:return hashlib.md5(s.encode("utf-8")).hexdigest()# 简单存储(不安全)
db = {"michael": get_md5("123456")}def login(user, pwd):return db.get(user) == get_md5(pwd)print(login("michael", "123456")) # True
常用口令的MD5很容易就计算出来,我们可以通过对原始口令加一个复杂字符串来实现,也就是加盐防御:
db = {}
def register(username, password):db[username] = get_md5(password + username + "the-Salt")def login(username, password):return db.get(username) == get_md5(password + username + "the-Salt")
经过 Salt 处理的 MD5 口令,只要 Salt 不被黑客知道,即使用户输入简单口令,也很难通过 MD5 反推明文口令。但是如果有两个用户都使用了相同的简单口令比如 123456,在数据库中,将存储两条相同的 MD5 值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的 MD5 呢?如果假定用户无法修改登录名,就可以通过把登录名作为 Salt 的一部分来计算 MD5,从而实现相同口令的用户也存储不同的 MD5。
总之,摘要算法也不是加密算法,因为没法通过摘要反推明文,但可以防篡改,只需做验证就能确定用户身份。
itertools
-
特点:生成迭代器,惰性计算,适合无限序列。
-
常用函数:
-
count(start)→ 无限自然数 -
cycle(seq)→ 无限循环序列 -
repeat(obj, n)→ 重复 n 次 -
takewhile(func, iter)→ 条件截取 -
chain(iter1, iter2)→ 串联
-
for c in chain('ABC', 'XYZ'):print c# 迭代效果:'A' 'B' 'C' 'X' 'Y' 'Z
-
groupby(iter, keyfunc)→ 相邻分组,迭代器中相邻的重复元素挑出来放在一起
import itertools# 取前10个自然数
nums = itertools.takewhile(lambda x: x <= 10, itertools.count(1))
print(list(nums)) # [1..10]# 分组
for k, g in itertools.groupby("AaaBBbcCAAa", key=lambda c: c.upper()):print(k, list(g))