多层感知机:从感知机到深度学习的关键一步
在深度学习的发展历程中,感知机是重要的起点,而多层感知机则是突破感知机局限、迈向深度神经网络的关键。
一、感知机:深度学习的 “基石”
感知机由美国学者 Frank Rosenblatt 于 1957 年提出,是最简单的线性分类模型,其核心是通过权重和偏差对输入信号进行处理,实现二分类任务。
1. 核心原理
给定输入(x)、权重(w)和偏置(b),感知机的输出规则如下:
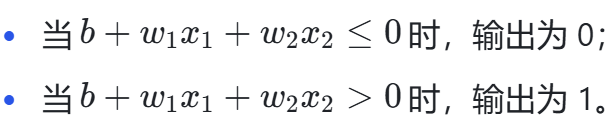
其中,权重(w)用于控制输入信号的重要性,偏差(b)则调整神经元被激活的容易程度。
2. 与其他任务模型的区别
模型类型 | 输出结果 | 适用任务 |
感知机 | 0 或 1 | 二分类 |
回归模型 | 实数 | 回归任务(如预测房价) |
Softmax 模型 | 概率值 | 多分类任务 |
3. 实际应用:简单逻辑电路
感知机可直接实现与门、与非门、或门等简单逻辑电路,通过设定合适的权重和偏差即可满足真值表要求:
- 与门:满足 “两个输入都为 1 时输出 1,否则输出 0”,例如权重和偏差设为(0.5, 0.5, -0.7);
- 与非门:与 “与门” 输出相反,权重和偏差可设为(-0.5, -0.5, 0.7);
- 或门:满足 “至少一个输入为 1 时输出 1”,权重和偏差可设为(0.5, 0.5, -0.3)。
4. 局限性:线性不可分难题
感知机只能表示由一条直线分割的线性空间,无法处理 “异或门” 这类线性不可分问题。异或门的真值表要求 “输入不同时输出 1,输入相同时输出 0”,无论如何调整权重和偏差,都无法用单一感知机实现。
二、多层感知机:突破局限的 “升级方案”
为解决感知机的线性不可分问题,多层感知机(即最简单的深度神经网络)应运而生。它通过引入隐藏层,将线性变换与非线性激活函数结合,实现对非线性空间的划分。
1. 核心结构
多层感知机通常包含输入层、隐藏层和输出层,其中隐藏层的数量和每层神经元个数是重要的超参数。
- 输入层:接收原始数据(如特征向量);
- 隐藏层:对输入信号进行非线性变换,增强模型表示能力,单隐藏层结构已能解决部分复杂问题;
- 输出层:根据任务输出结果,二分类任务输出 0/1,多分类任务可通过 Softmax 输出概率。
2. 激活函数:赋予模型非线性能力
激活函数的作用是将输入信号的总和转换为输出信号,是多层感知机实现非线性表达的关键,需满足连续可导(允许少数点不可导)、计算简单、导数值域合适的性质。常见激活函数如下:
- 阶跃函数:以 0 为界,输入 > 0 时输出 1,否则输出 0,感知机即使用此函数,但因不连续,难以用于多层网络训练;
- tanh 函数(双曲正切):将输入映射到(-1, 1)区间,输出具有对称性;
- ReLU 函数(线性修正函数):输入 > 0 时输出输入值,否则输出 0,计算简单且能缓解梯度消失问题,是当前应用最广泛的激活函数之一。
- S型(sigmoid)激活函数(挤压函数): 将输入投影到(0,1)
3. 多分类拓展
对于多分类任务,多层感知机可通过增加输出层神经元数量,并结合 Softmax 函数,使输出结果为各分类的概率值,满足多分类任务需求。
三、模型训练:从 “学习” 到 “优化”
多层感知机的学习过程本质是动态调整网络连接权值,以让模型输出接近期望值,核心环节包括参数更新、误差评估、过拟合与欠拟合处理等。
1. 参数更新:前向传播与反向传播
- 前向传播:输入样本从输入层经过各隐藏层,最终传递到输出层,计算模型预测值;
- 反向传播:从输出层反向计算误差,根据误差梯度修正各层权重和偏差,是优化模型参数的核心方法。
2. 误差评估:训练误差与泛化误差
- 训练误差:模型在训练数据集上的误差,反映模型对训练数据的拟合程度;
- 泛化误差:模型在新数据集(未见过的数据)上的误差,更能体现模型的实际性能。
例如,用历年考试真题备考时,真题得分(训练误差)高不代表未来考试(新数据)能取得好成绩(泛化误差)。
3. 数据集划分:验证集与测试集
为准确评估误差,需将数据划分为训练集、验证集和测试集:
- 训练集:用于模型训练,更新参数;
- 验证集:用于评估模型好坏,调整超参数(如隐藏层数量),通常占训练数据的 50%,需与训练集独立;
- 测试集:仅用于评估最终模型性能,理论上只能使用一次(如高考,仅用于评估学习成果)。
4. K - 折交叉验证:小数据的 “救星”
当数据量不足时,可采用 K - 折交叉验证:
- 将训练数据划分为 K 个部分;
- 依次用其中 1 个部分作为验证集,其余 K-1 个部分作为训练集;
- 计算 K 次验证的平均误差,作为模型性能评估结果。
常见 K 值为 5 或 10。
5. 过拟合与欠拟合:模型复杂度的 “平衡术”
- 欠拟合:模型对训练数据的一般性质尚未学好,表现为训练误差和泛化误差都较高,通常因模型复杂度过低(如隐藏层过少);
- 过拟合:模型 “过度学习” 训练数据的特点,甚至学习到噪声,表现为训练误差低但泛化误差高,通常因模型复杂度过高(如参数过多)或数据量不足。
6. 优化策略:降低过拟合风险
- 权重衰减:通过在损失函数中加入权重的 L2 范数,限制权重过大,降低模型复杂度;
- 暂退法(丢弃法):训练时随机丢弃部分神经元,减少神经元间的依赖,增强模型泛化能力。
四、总结
多层感知机通过引入隐藏层和非线性激活函数,突破了感知机的线性局限,是深度学习的重要基础。其核心要点可概括为:
- 以感知机为基础,通过多层结构实现非线性建模;
- 激活函数(如 ReLU、tanh)赋予模型非线性能力;
- 利用反向传播更新参数,结合验证集、测试集和 K - 折交叉验证评估模型;
- 通过权重衰减、暂退法等策略缓解过拟合,平衡模型复杂度与泛化能力。
掌握多层感知机的原理与训练方法,将为深入学习更复杂的深度神经网络(如 CNN、RNN)打下坚实基础。