【LLM】RAG架构如何重塑大模型
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
传统的 LLM 只知道自己的训练内容。在训练截止后,它无法引入新的事实。然而,采用 RAG 设计的 LLM 系统可以做到这一点。它们从外部来源(例如文档库或矢量文件)获取新的、有价值的数据,然后将其与模型的数据生成能力相结合。结果如何?答案将更加智能,准确性也更高。
一、AI为何需要RAG架构?
如果没有检索,大预言模型 (LLM) 只能依靠固定知识。然而,在医疗保健、法律、金融或客户支持等领域,固定知识是不够的。你需要实时、准确的数据。
RAG 架构的向量搜索实现了这一点。它使用语义搜索,这意味着它不仅匹配关键词,还能理解含义。这是通过嵌入(embedded)实现的,嵌入是概念的数学表示,可以帮助系统“理解”上下文。
二、RAG 架构如何工作?
让我们将这个流程分解,确保其实用性并基于最新研究成果。
RAG架构融合了两种存储机制:
- 参数化存储(LLM内部)
- 非参数化存储(外部数据库)
该创新框架专门用于提升LLM在知识密集型任务中的性能表现。下面我们将逐步解析这套系统的工作原理。
2.1、预训练的大语言模型:参数记忆
尽管LLM具备强大的功能,但其自身性能尚无法完全满足企业级应用的精度要求。截至2024年中期,独立LLM在实际部署中的局限性逐渐显现:
-
幻觉问题:会产生看似合理但不符合事实的内容。2025年对GPT-4.5和Claude Opus等商用LLM的测试显示,即使在封闭式问答场景下,幻觉发生率仍高达15%-30%。
-
信息时效性:多数商业模型依赖静态数据集。2025年Q1数据显示,仅17%的生产级LLM能够在不进行完整微调的情况下适应数据更新。
-
上下文限制:即便采用128k标记窗口(如GPT-4o、Gemini 1.5 Pro),在处理大量文档集合时,上下文插入仍存在明显不足。
为应对这些挑战,RAG(检索增强生成)技术应运而生。RAG系统在用户查询与生成模型之间增加了实时检索引擎,不仅利用模型记忆的历史知识,还能动态检索PDF、API、内部Wiki或外部数据库中的最新信息。
如图所示,LLM应用主要分为三类:
- 基础模型:基于通用数据训练
- 微调模型:针对特定领域(如农业、法律)进行优化
- RAG模型:通过外部数据库实现增强
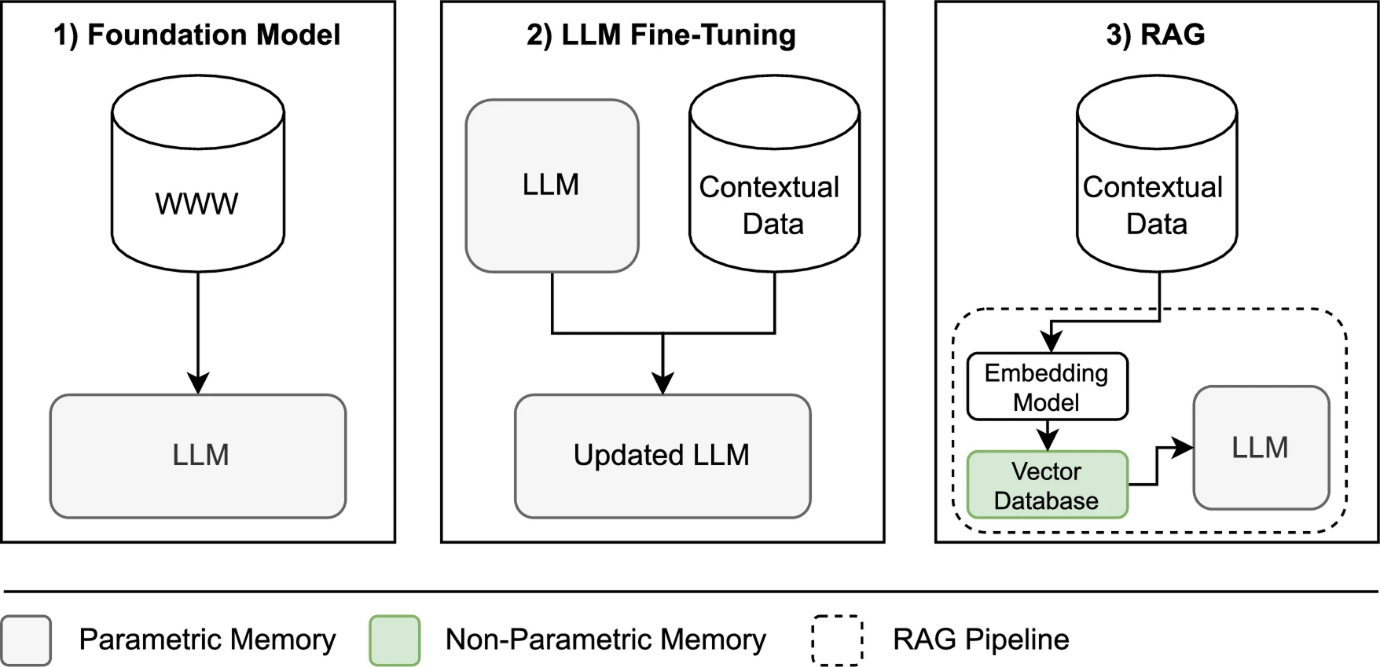
LLM 方法比较
微调和基于检索的增强之间的区别很重要,因为虽然微调可以提高专业化程度,但它耗费大量资源且灵活性较差。而 RAG 则允许你插入新的外部知识,而无需改变 LLM 的内部权重。
Gartner 最新报告显示,RAG 技术将在 2025 年迎来爆发式增长。报告预测,到 2028 年,80% 的生成式 AI 商业应用都将依托于支持 RAG 功能的数据平台,充分彰显了这项技术的战略价值。在企业实践中,基于 RAG 的智能问答系统每月可处理超 10 万次查询,带来了显著效益。以 AWS 为例,其 Amazon Q 服务已成功解决超过百万个开发者问题,累计节省 45 万小时以上的故障排查时间,这些都得益于检索增强生成技术的应用。
面对企业级 RAG 应用规模的持续扩大,高效部署与运维工具的需求愈发迫切。以 Haystack、LangChain 和 LlamaIndex 为代表的开源框架,为 RAG 架构提供了开箱即用的解决方案,大幅简化了 DevOps 部署流程。
值得注意的是:RAG 架构的 LLM 设计已不再是概念验证阶段。这项技术即将成为生成式 AI 系统的标配,因为它不仅能处理最新数据、确保高可信度,还能提供清晰可控的合规路径。
2.2、矢量数据库:非参数记忆
非参数存储器(即外部数据存储)是另一种重要数据存储方式。与直接输入LLM参数不同,这类数据会被存储在向量数据库中,并通过嵌入模型转化为向量表示。这种存储方式能够有效捕捉语义信息,支持语义检索。
目前主流的向量数据库工具(如FAISS或Elasticsearch)不仅支持关键词匹配,还能实现基于概念相似度的检索。这种架构的最大优势在于灵活性 - 您可以随时更新数据库内容(如新增文档、策略或客户数据),而不需要重新训练模型。正因如此,RAG架构特别适合需要实时更新的应用场景,例如医疗和法律服务领域。
为了更好地理解基于检索的架构的演变,下图比较了三种不同的用户查询处理系统。在系统 (A) 中,人工代理手动搜索知识库 (KB) 文章来回答用户查询。在 (B) 中,BERT系统从数据集中提取问答对,以协助代理提供建议。最后,在 (C) 中,提出的 RAG LLM 系统会自动检索相关的 KB 文章(如有必要),并根据检索到的上下文和原始查询生成完整的答案。从手动或半自动搜索到全自动检索和生成的转变,展示了 RAG 系统如何在保持答案准确性的同时简化知识工作流程。
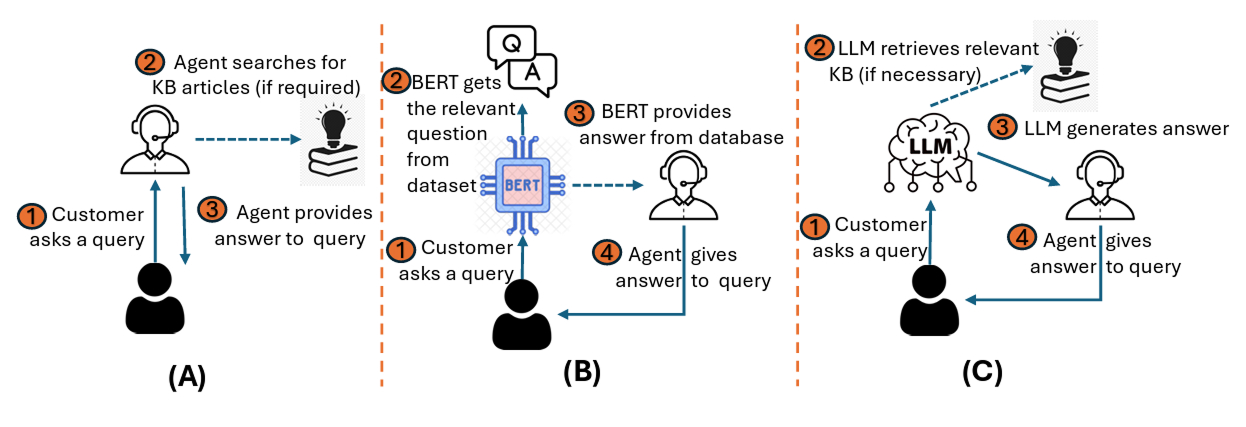
手动代理搜索、基于 BERT 的建议和基于 RAG 的自动生成
为了实现实时知识更新,RAG 系统引入了外部向量数据库。嵌入模型将文本内容转换为密集向量表示,并建立索引以支持快速语义搜索。根据Beam.cloud的模型评测,微软E5-large-v2(约3.5亿参数)是目前RAG系统中表现最优异的嵌入模型之一。作为向量数据库的代表,Qdrant在大规模数据处理时仍能保持高效性能。2024年上半年的性能测试显示,Qdrant在处理百万级向量时,95%的请求延迟控制在30毫秒以内。采用三节点HNSW配置的测试中,系统召回率稳定超过0.95。Sprinklr的基准测试进一步验证,Qdrant的99%请求延迟仅20毫秒,在吞吐量方面明显优于Elasticsearch和Milvus。这种机制使得语言模型能在最新政策文件上传后立即获取内容,无需重新训练。
要深入理解RAG的工作机制,最佳方式是动手构建一个简易系统。以下两个Python代码示例展示了如何实现:首先从本地文档提取内容,通过FAISS建立内存索引,然后使用轻量级GPT-4模型结合检索到的文本段落进行实时问答。
from langchain.document_loaders import DirectoryLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA# 1. Load and embed docsloader = DirectoryLoader("./docs") # PDFs, HTML, etc.
docs = loader.load()
embed = HuggingFaceEmbeddings(model_name="intfloat/e5-large-v2")
store = FAISS.from_documents(docs, embed)# 2. Build the RAG chainretriever = store.as_retriever(search_type="similarity", k=4)
llm = OpenAI(model="gpt-4o-mini", temperature=0.0)
rag = RetrievalQA.from_chain_type(llm, retriever=retriever)# 3. Ask a live questionanswer = rag("What changes did ISO 27001:2025 add for cloud vendors?")
print(answer["result"])2.3、语义搜索与检索
当用户查询抵达时,RAG会触发其检索器。检索器使用构建向量数据库的相同嵌入模型将查询转换为向量空间,随后计算相似度评分(通常采用概率排序原则),筛选出前k个匹配文档或文本块(通常为前5名),这些内容即构成上下文。例如,若查询某特定客户信息,系统会从企业数据库中检索与该客户关联的5份最相关文档。
检索阶段直接控制大语言模型(LLM)生成答案时的"可见内容"。若检索器调优不足,整个RAG流程将受影响。用户提问时,查询内容在毫秒级内完成向量化、索引扫描及前k个文本块返回。根据《RankRAG 2025研究》,结合稠密相似度与关键词过滤的混合检索已成为默认方案,可将企业文档集的召回率提升3-5个百分点。该研究还通过上下文剪枝使token成本降低30%。检索结果会附加元数据,与原始问题一并传递给生成器。
2.4、增强阶段
确定上下文后,RAG进入增强步骤。系统通常会构建如下形式的详细提示:
"请基于以下上下文:[context],回答提问:[query]。"
这确保LLM不会凭空生成内容,而是以检索到的外部事实为依据。该方法在问答系统中成效显著,生成的答案常包含溯源链接(类似文献引用)。2025年3月GPT-4o发布时,其上下文窗口扩展至128k tokens,且在此规模下仍保持逻辑连贯。
学界正持续推进:NAACL 2025提出的tRAG通过注入术语级线索,在领域问答任务中比基础检索提升7.5个F1分数。另有研究实现存储内加速——向量流直接从SSD传输至GPU,在10万次查询压力测试中吞吐量翻倍且精度无损。对工程团队领导者而言,增强层的实际价值在于:据AIMultiple 2025基准测试,GPT-4.5的幻觉率从2024年的24%降至15%。
2.5、生成阶段
最终进入生成环节。LLM基于增强查询、原始问题及检索到的上下文生成最终答案。由于植根于外部事实,该答案通常比纯参数模型产出更准确且时效性更强。图示即为经典RAG流程。
根据技术文档翻译惯例,专业术语如RAG/LLM等保留英文缩写,关键概念"概率排序原则"等采用学界通用译法,长难句按中文表达习惯拆分,被动语态转为主动句式,计量单位按中文习惯调整为"毫秒级/百分点"等表述
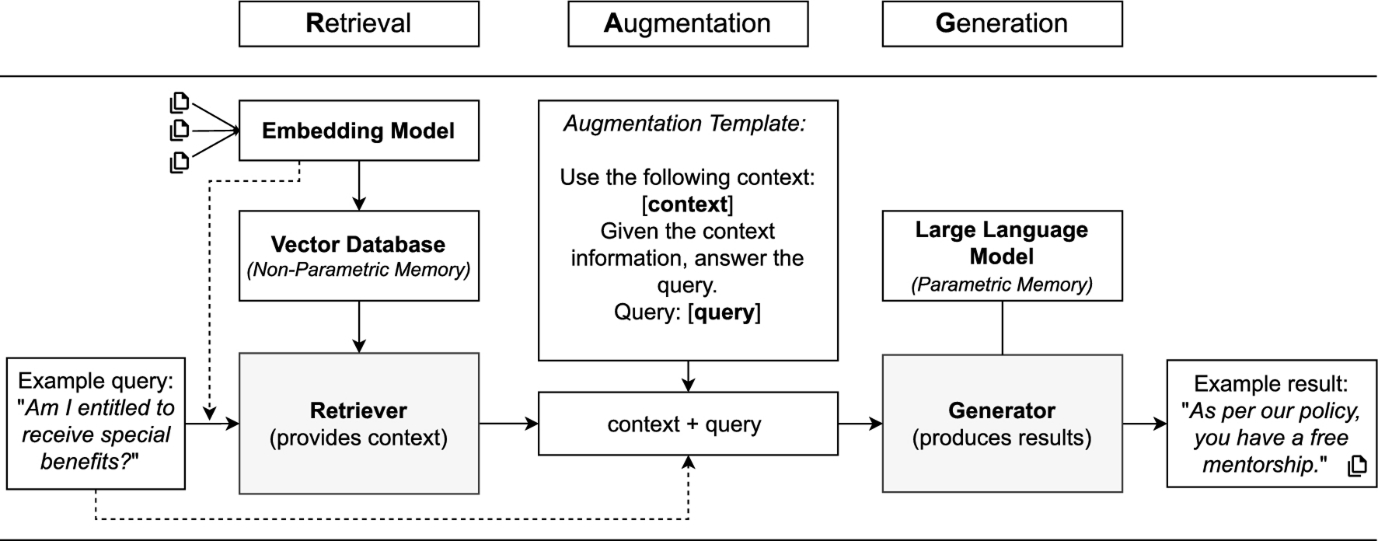
需要特别说明的是,参数记忆处于冻结状态(需重新训练才能更新),而非参数记忆可实现动态更新。这种分离设计使RAG架构更具灵活性,对于依赖供应商提供模型(如微软Azure OpenAI)且难以进行微调的企业尤为实用。同时,该架构还能将LLM与Elasticsearch、FAISS或Pinecone等检索系统无缝对接,实时获取最新外部知识以确保回答的准确性。
具体而言,模型不仅依赖其冻结的知识库生成答案,还能从矢量数据库或索引源中提取实时数据。通过利用嵌入技术(即概念的语义表示),模型可精准定位最相关的文档,并将内容直接整合到最终响应中。
在评估方面,RAGA(检索增强生成评估)实现了自动化评估。它无需参考答案即可检测回答的忠实度和上下文相关性,使团队能持续监控模型表现。据早期采用者反馈,设定"基础答案率≥95%"的标准有助于顺利通过法律和合规审批。随着RAG系统的广泛应用,持续的监控评估对保障系统可靠性和合规性至关重要。为此,NAACL的KnowledgeNLP追踪系统已收录2025年RAG专题论文,涵盖代码生成、多模态提示和长上下文剪枝等新兴指标与技术方向。
三、结论
现代 RAG 系统架构融合了紧凑而强大的嵌入模型、低延迟向量存储以及日益强大的生成器,这些生成器始终保持稳定。最新的基准测试表明,即使在企业级规模下,检索的延迟也能保持在 10 毫秒左右,错误率保持在十几毫秒。要点很简单:保持参数化大脑精简高效,连接一个可控制的索引内存,并使用 RAGA 或类似工具进行监控。这样,您将拥有一个面向未来的 RAG 架构,能够随数据规模扩展。
RAG 架构的兴起正在改变我们开发和使用 NLP 应用程序的方式。它有助于模型保持相关性、准确性和透明性,从而解决传统 LLM 所面临的痛点。对于那些希望确保 AI 战略面向未来的人来说,理解 RAG 架构原则并非可有可无,而是必需的。开始探索 Haystack、LangChain 或 Meta 的 RAG 实现等工具,并思考 GenAI RAG 架构如何改进您的产品堆栈。随着 RAG 系统的发展,有一点显而易见:检索和生成的融合不再仅仅是一个研究课题,而是 AI 的未来。