# 深入理解栈、栈帧与递归:从迭代与递归归并排序双视角解析
栈和栈帧是理解函数调用机制的核心概念,尤其在递归算法中,二者的工作原理直接决定了程序的执行逻辑与内存布局。本文将结合迭代与递归两种归并排序实现,系统拆解栈与栈帧的本质,剖析递归过程中变量的内存位置与生命周期。
一、算法基础:“迭代”与“递归”——归并排序实现
为了后续分析更具针对性,这里给出两种归并排序的核心实现代码,作为后续讨论的载体。
1.1 迭代式归并排序
// 分割链表:从head开始取step个节点,返回剩余部分的头指针
ListNode* split(ListNode* head, int step) {if (!head) return nullptr;ListNode* curr = head;// 移动到第step个节点的前一个位置for (int i = 1; i < step && curr->next; i++) {curr = curr->next;}ListNode* rest = curr->next;curr->next = nullptr; // 切断链表return rest;
}// 合并两个有序链表
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {ListNode dummy(0);ListNode* curr = &dummy;while (l1 && l2) {if (l1->val < l2->val) {curr->next = l1;l1 = l1->next;} else {curr->next = l2;l2 = l2->next;}curr = curr->next;}curr->next = l1 ? l1 : l2;return dummy.next;
}// 迭代式归并排序
ListNode* mergeSortIterative(ListNode* head) {if (!head || !head->next) return head;// 计算链表长度int length = 0;ListNode* current = head;while (current) {length++;current = current->next;}ListNode dummy(0);dummy.next = head;// 按步长迭代合并for (int step = 1; step < length; step *= 2) {ListNode* prev = &dummy;ListNode* curr = dummy.next;while (curr) {ListNode* left = curr;ListNode* right = split(left, step);curr = split(right, step);prev->next = mergeTwoLists(left, right);// 移动prev到合并后链表的末尾while (prev->next) prev = prev->next;}}return dummy.next;
}
1.2 递归式归并排序
// 找到链表中点(快慢指针法)
ListNode* findMiddle(ListNode* head) {if (!head || !head->next) return head;ListNode* slow = head;ListNode* fast = head->next;while (fast && fast->next) {slow = slow->next;fast = fast->next->next;}return slow;
}// 递归式归并排序
ListNode* mergeSortRecursive(ListNode* head) {// 递归终止条件:链表为空或只有一个节点if (!head || !head->next) return head;// 分割链表为左右两部分ListNode* mid = findMiddle(head);ListNode* rightHead = mid->next;mid->next = nullptr; // 切断链表// 递归排序左右两部分ListNode* left = mergeSortRecursive(head);ListNode* right = mergeSortRecursive(rightHead);// 合并排序后的链表return mergeTwoLists(left, right);
}
二、核心概念:栈、栈帧与堆的本质解析
要理解两种实现的内存差异,首先需要明确栈、栈帧与堆这三个内存区域的核心区别。我们先通过生活化比喻建立直观认知,再深入技术细节。
2.1 生活化比喻:厨房中的内存模型
把计算机内存比作厨房,三个核心区域的角色清晰明了:
堆(Heap):厨房的中央食材仓库
- 存储内容:所有"实体食材"(如鱼、肉、蔬菜)和"做好的成品菜",对应程序中的动态数据(如链表节点、对象实例)。
- 核心特点:
- 空间大且持久:食材放入仓库后,除非主动清理,否则会一直存在;
- 自由存取:可随时取用任何食材,没有固定顺序;
- 人工管理:厨师(程序员)需自己决定拿取、存放和清理,若只拿不清理,仓库会被塞满(内存泄漏)。
栈(Stack):厨师的工作台/案板
- 存储内容:当前正在处理的"食谱步骤"和"临时食材",对应程序中的函数调用上下文。
- 核心特点:
- 空间有限:工作台面积固定,不能堆放过多物品;
- 临时存储:做完一道菜后,台面会清空,为下道菜腾空间;
- 有序叠放:若做复杂菜品A时需要先做汤B,会把A的食谱推到一边,铺好B的食谱;汤做好后收走B的食谱,再继续A的步骤(后进先出LIFO);
- 自动管理:厨房助理(CPU/系统)自动铺放和收走食谱,厨师无需干预。
栈帧(Stack Frame):案板上的一份完整食谱
- 包含内容:做一道菜所需的全部信息——“返回位置”(做完后回到上道菜的哪一步)、“原料清单”(参数)、“临时工具”(局部变量)。
- 核心作用:隔离不同菜品的处理过程,每道菜的食谱独立存在,互不干扰。
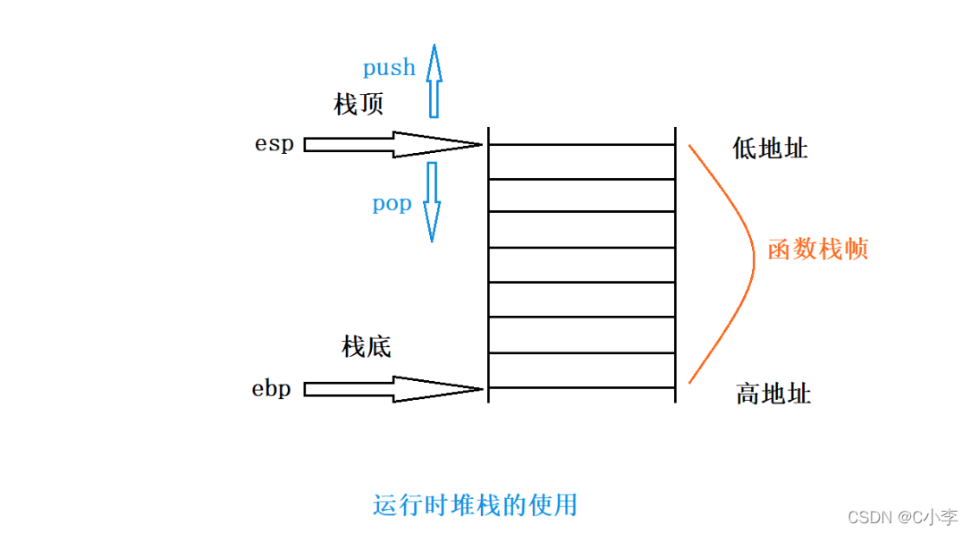
2.2 技术性定义与核心区别
1. 堆(Heap)
- 本质:动态分配的内存区域,生命周期不依赖函数调用。
- 作用:存储大小未知、需跨函数使用的数据(如链表节点、动态数组)。
- 操作方式:程序员通过
new/malloc主动申请,delete/free主动释放,不释放会导致内存泄漏。 - 性能:分配速度慢(需寻找合适内存块),但灵活性高。
2. 栈(Stack)
- 本质:系统自动管理的LIFO内存区域,专门服务于函数调用。
- 作用:存储函数调用上下文(返回地址、参数、局部变量),保证调用与返回的顺序正确性。
- 操作方式:函数调用时自动分配栈帧,函数返回时自动销毁,无需程序员干预。
- 性能:分配速度快(仅移动栈指针),但空间有限(通常MB级)。
3. 栈帧(Stack Frame)
- 本质:栈上的连续内存块,代表一次独立的函数调用。
- 作用:隔离每次函数调用的上下文,使同名局部变量在不同调用中互不干扰(递归的核心基础)。
- 生命周期:始于函数调用,终于函数返回。
2.3 三者对比表
| 特性 | 栈(Stack) | 堆(Heap) | 栈帧(Stack Frame) |
|---|---|---|---|
| 管理者 | 系统自动管理 | 程序员手动管理 | 系统随函数调用自动创建/销毁 |
| 生命周期 | 随函数调用起止 | 随分配/释放起止(可跨函数) | 随单次函数调用起止 |
| 分配速度 | 快(移动栈指针) | 慢(寻找内存块) | 与栈一致,创建/销毁极快 |
| 内存大小 | 较小(MB级) | 大(受虚拟内存限制) | 随函数局部变量多少动态变化 |
| 存储内容 | 参数、局部变量、返回地址 | 动态对象、链表节点等 | 单次函数的参数、局部变量等 |
| 核心问题 | 栈溢出(递归过深) | 内存泄漏、碎片化 | 无(系统自动管理) |
三、迭代归并排序:栈帧的"循环复用"机制
迭代实现通过for和while循环替代递归,其栈帧行为具有"复用性",我们结合代码深入分析。
3.1 函数调用栈帧的创建与销毁
迭代版中,主要的函数调用是split()和mergeTwoLists(),每次调用都会产生新栈帧,但核心逻辑仍在mergeSortIterative()的主栈帧中执行。
以step=1时的内层while循环为例:
while (curr) {ListNode* left = curr; // 主栈帧中创建leftListNode* right = split(left, step); // 调用split,创建split栈帧curr = split(right, step); // 再次调用split,创建新的split栈帧prev->next = mergeTwoLists(left, right); // 调用mergeTwoLists,创建其栈帧while (prev->next) prev = prev->next;
}
栈帧变化过程:
- 初始状态:仅存在
mergeSortIterative()的主栈帧,包含length、dummy、step等变量; - 调用split():系统在栈顶创建
split()的栈帧,存储其参数(left、step)和局部变量(curr、rest);调用结束后,该栈帧立即销毁,返回值赋值给right; - 调用mergeTwoLists():同理创建其栈帧,执行完毕后销毁,返回值赋值给
prev->next; - 循环迭代:下一次
while循环时,在主栈帧中重新创建left变量(覆盖原位置或使用新位置,但属于同一主栈帧),重复上述过程。
3.2 关键洞察:局部变量的"复用与消亡"
- 指针变量的位置:
left、right等指针变量存储在mergeSortIterative()的主栈帧中,每次循环迭代会重新赋值(或创建新变量,但处于同一栈帧); - 指向数据的位置:这些指针指向的链表节点始终存储在堆中,不受栈帧变化影响;
- 栈帧复用性:迭代过程中没有新的
mergeSortIterative()调用,仅存在一个主栈帧,split()和mergeTwoLists()的栈帧"即用即销",不会累积。
四、递归归并排序:栈帧的"嵌套累积"机制
递归实现的核心是函数自身调用,每次调用都会创建新栈帧,形成"嵌套累积"的结构,这也是递归与迭代的本质区别。
4.1 递归栈帧的创建与销毁过程
以链表[4→2→1→3]的排序为例,递归调用链与栈帧变化如下:
第一步:第一层递归(栈帧1)
- 调用
mergeSortRecursive(4→2→1→3),创建栈帧1; - 分割链表为
[4→2]和[1→3]; - 执行
left = mergeSortRecursive(4→2),暂停栈帧1,创建栈帧2。
第二步:第二层递归(栈帧2)
- 调用
mergeSortRecursive(4→2),创建栈帧2; - 分割链表为
[4]和[2]; - 执行
left = mergeSortRecursive(4),暂停栈帧2,创建栈帧3。
第三步:第三层递归(栈帧3)
- 调用
mergeSortRecursive(4),创建栈帧3; - 满足终止条件(仅一个节点),返回
4; - 栈帧3销毁,返回值赋值给栈帧2的
left。
第四步:栈帧2继续执行
- 执行
right = mergeSortRecursive(2),创建栈帧4; - 栈帧4满足终止条件,返回
2,栈帧4销毁; - 调用
mergeTwoLists(4,2),返回2→4; - 栈帧2销毁,返回值赋值给栈帧1的
left。
第五步:栈帧1继续执行
- 执行
right = mergeSortRecursive(1→3),重复上述过程,最终返回1→3; - 调用
mergeTwoLists(2→4, 1→3),返回1→2→3→4; - 栈帧1销毁,排序完成。
4.2 关键洞察:同名变量的"多栈帧共存"
- 栈帧累积性:递归最深层时,栈中同时存在多个栈帧(如上述过程中的栈帧1、2、3),形成"栈帧链";
- 变量独立性:每个栈帧中都有独立的
left、right变量——虽然名字相同,但存储在不同栈帧的内存地址中,互不干扰; - 销毁顺序:符合栈的LIFO特性,内层栈帧(如栈帧3)先销毁,外层栈帧(如栈帧1)后销毁。
五、内存布局可视化:两种实现的对比
为了更直观地理解差异,我们分别绘制迭代与递归实现的内存布局图。
5.1 迭代归并排序内存布局
栈 (Stack)
+-------------------------------+
| mergeSortIterative() 主栈帧 |
| - length: 4 |
| - current: 已销毁(循环结束)|
| - dummy: 指向堆中哨兵节点 |
| - step: 2(当前迭代步长) |
| - prev: 指向堆中节点 |
| - curr: 指向堆中节点 |
| - left: 指向堆中节点 |
| - right: 指向堆中节点 |
+-------------------------------+
| mergeTwoLists() 栈帧(调用中)|
| - dummy: 局部哨兵节点 |
| - curr: 指向局部哨兵节点 |
+-------------------------------+
| split() 栈帧(已销毁) |
+-------------------------------+堆 (Heap)
+-------------------------------+
| ListNode: val=1, next→2 |
+-------------------------------+
| ListNode: val=2, next→3 |
+-------------------------------+
| ListNode: val=3, next→4 |
+-------------------------------+
| ListNode: val=4, next→null |
+-------------------------------+
| dummy(哨兵节点): next→1 |
+-------------------------------+
5.2 递归归并排序内存布局(最深层时)
栈 (Stack)
+-------------------------------+
| mergeSortRecursive() 栈帧1 |
| - head: 4→2→1→3 |
| - mid: 2 |
| - rightHead: 1→3 |
| - left: 待赋值 |
| - right: 待赋值 |
+-------------------------------+
| mergeSortRecursive() 栈帧2 |
| - head: 4→2 |
| - mid: 4 |
| - rightHead: 2 |
| - left: 4 |
| - right: 待赋值 |
+-------------------------------+
| mergeSortRecursive() 栈帧3 |
| - head: 4 |
| - mid: 4 |
| - rightHead: null |
| - left: null(未执行) |
| - right: null(未执行) |
+-------------------------------+堆 (Heap)
+-------------------------------+
| ListNode: val=4, next→2 |
+-------------------------------+
| ListNode: val=2, next→null |
+-------------------------------+
| ListNode: val=1, next→3 |
+-------------------------------+
| ListNode: val=3, next→null |
+-------------------------------+
六、实践启示:性能与可靠性考量
理解栈与栈帧的机制,对实际编程中的性能优化和错误规避至关重要。
6.1 栈溢出风险:递归的"隐形陷阱"
- 递归实现中,每次调用都会创建新栈帧,若链表过长(如10万节点),栈帧累积会超出栈的内存限制,导致栈溢出;
- 迭代实现仅使用一个主栈帧,栈内存占用恒定(O(1)),不存在栈溢出风险,更适合大规模数据。
6.2 内存效率:堆与栈的权衡
- 两种实现均在堆中存储链表节点(O(n)空间),但递归额外消耗栈内存(O(logn),递归深度);
- 迭代的栈内存开销可忽略,且避免了递归调用的函数切换开销,实际执行效率通常更高。
参考文献:函数栈帧的创建与销毁(超详解)
参考文献:函数的调用过程,栈帧的创建和销毁
