从零开始构建Kubernetes Operator:一个完整的深度学习训练任务管理方案
从零开始构建Kubernetes Operator:一个完整的深度学习训练任务管理方案
- 一、引言
- 二、为什么需要Operator?
- 1. Controller vs Operator:本质区别
- 2. 有状态服务 vs 无状态服务的挑战
- 三、项目架构设计
- 3.1整体架构图
- 3.2核心组件
- 4.核心实现解析
- 1. CRD定义 - 声明式API设计
- 2. Controller实现 - 调和循环核心
- 3. GPU资源调度 - 智能资源管理
- 五、实际使用场景
- 场景1:简单训练任务
- 场景2:分布式多GPU训练
- 六、开发经验分享
- 1. 项目结构设计
- 2. 开发工具链
- 3. 调试技巧
- 七、部署和使用
- 快速部署
- 八、监控和管理
- 九、项目亮点
- 1. 完整的生产就绪特性
- 2. 丰富的使用示例
- 3. 完善的文档
- 十、技术收获
- 1. Kubernetes扩展开发
- 2. Go语言实践
- 3. 运维自动化
- 十一、下一步计划
作者: mmwei3
邮箱: 1300042631@qq.com / mmwei3@iflytek.com
日期: 2025年08月16日
项目地址: GitHub - PyJob Operator
CSDN博客: 从零开始构建Kubernetes Operator
一、引言
在云原生时代,Kubernetes已经成为容器编排的事实标准。然而,当我们面临复杂的业务场景,特别是需要管理有状态服务时,原生的Kubernetes资源往往显得力不从心。今天,我将分享如何从零开始构建一个完整的Kubernetes Operator,用于管理深度学习训练任务。
这个PyJob Operator项目是一个完整的、生产就绪的Kubernetes Operator实现,它不仅展示了Operator开发的最佳实践,还提供了丰富的示例和详细的文档。无论是学习Kubernetes Operator开发,还是作为实际项目的起点,都具有很高的价值。可以帮助SRE和运维开发工程师们在运维的海洋里尽情扩展定制。这也是我入手的第一个operator实现,给我带来了很大的启发,也是因为这个我学习了contorller和operator的区别以及理解有状态和无状态的区别,包括哪些适合daemonset,不需要早轮子,哪些是需要定制开发的场景,如果你也刚好接触operator可以一起交流,1300042631@qq.com。
这个operator的开发和2022年时在云计算研究院二次开发openstack-nova/cinder/ironic组件还是不太一样的,不过都能学习到很多优秀的逻辑和思维以及异常处理,我认为思想非常重要,因为思想决定目标。
二、为什么需要Operator?
1. Controller vs Operator:本质区别
在深入开发之前,我们需要理解Controller和Operator的核心区别:
Controller(控制器):
- 管理单一资源类型的基础生命周期
- 通过调和循环确保实际状态向期望状态收敛
- 适用于无状态服务的简单场景
Operator(操作器):
- 封装复杂应用的自动化运维逻辑
- 将运维专家的知识编码到Kubernetes中
- 特别适合有状态服务的复杂场景
2. 有状态服务 vs 无状态服务的挑战
无状态服务:
# 使用Deployment管理,Pod可以随意调度/重建
apiVersion: apps/v1
kind: Deployment
spec:replicas: 3template:spec:containers:- name: nginximage: nginx:1.20
有状态服务(如训练任务):
- 需要GPU资源调度
- 需要持久化存储
- 需要状态监控和故障恢复
- 需要复杂的生命周期管理
这就是为什么我们需要Operator的原因!
三、项目架构设计
3.1整体架构图
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ PyJob CRD │───▶│ PyJob Controller│───▶│ Kubernetes Job │
└─────────────────┘ └──────────────────┘ └─────────────────┘│ │ │▼ ▼ ▼
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ User Input │ │ Reconcile Loop │ │ Pod Creation │
└─────────────────┘ └──────────────────┘ └─────────────────┘
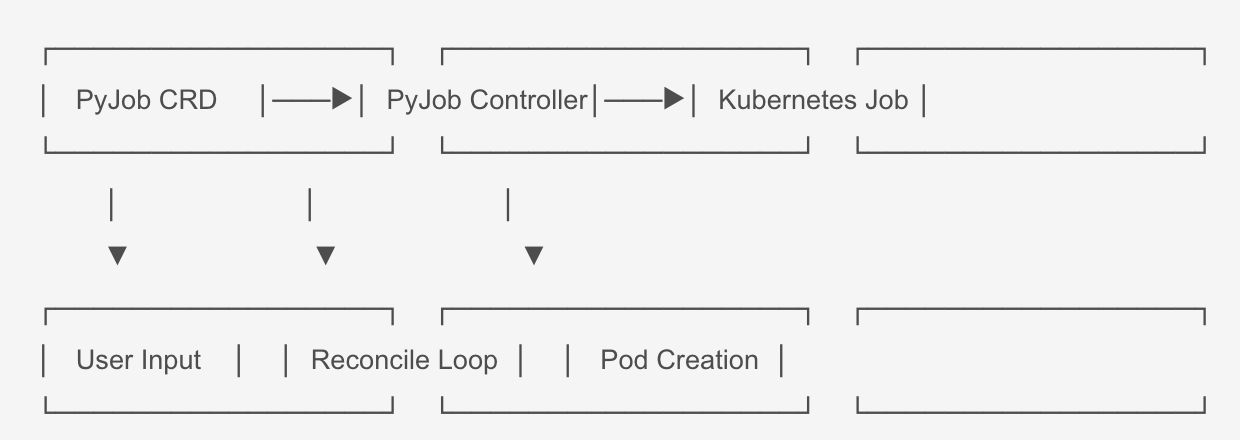
3.2核心组件
- PyJob CRD:自定义资源定义,描述训练任务的期望状态
- PyJob Controller:控制器,负责调和实际状态和期望状态
- Kubernetes Job:底层Kubernetes资源,实际执行训练任务
- PersistentVolumeClaim:持久化存储,存储数据和模型
4.核心实现解析
1. CRD定义 - 声明式API设计
// PyJobSpec 定义用户期望的任务配置
type PyJobSpec struct {Image string `json:"image"` // 训练镜像Command []string `json:"command"` // 执行命令GPU int32 `json:"gpu"` // GPU数量DatasetPath string `json:"datasetPath"` // 数据集路径OutputPath string `json:"outputPath"` // 输出路径Resources *ResourceRequirements `json:"resources"` // 资源限制
}// PyJobStatus 记录任务状态
type PyJobStatus struct {Phase string `json:"phase"` // 任务阶段Message string `json:"message"` // 状态信息StartTime *metav1.Time `json:"startTime"` // 开始时间CompletionTime *metav1.Time `json:"completionTime"` // 完成时间
}
2. Controller实现 - 调和循环核心
func (r *PyJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {// 1. 获取PyJob实例var pyjob trainingv1.PyJobif err := r.Get(ctx, req.NamespacedName, &pyjob); err != nil {return ctrl.Result{}, err}// 2. 检查是否需要创建JobjobName := fmt.Sprintf("%s-job", pyjob.Name)var job batchv1.Joberr := r.Get(ctx, types.NamespacedName{Name: jobName, Namespace: pyjob.Namespace}, &job)if err != nil && errors.IsNotFound(err) {// 3. 创建新的Jobif err := r.createJob(ctx, &pyjob, jobName); err != nil {return ctrl.Result{}, err}// 4. 更新状态pyjob.Status.Phase = "Running"r.Status().Update(ctx, &pyjob)}// 5. 监控Job状态并更新PyJobreturn r.updatePyJobStatus(ctx, &pyjob, &job)
}
3. GPU资源调度 - 智能资源管理
// 创建包含GPU资源的Job
func (r *PyJobReconciler) createJob(ctx context.Context, pyjob *trainingv1.PyJob, jobName string) error {// 配置GPU资源if pyjob.Spec.GPU > 0 {resourceRequirements.Limits["nvidia.com/gpu"] = *resource.NewQuantity(int64(pyjob.Spec.GPU), resource.DecimalSI)}// 创建Pod模板container := corev1.Container{Name: "trainer",Image: pyjob.Spec.Image,Command: pyjob.Spec.Command,Resources: resourceRequirements,}// 创建Job资源job := &batchv1.Job{ObjectMeta: metav1.ObjectMeta{Name: jobName,Namespace: pyjob.Namespace,},Spec: batchv1.JobSpec{Template: corev1.PodTemplateSpec{Spec: corev1.PodSpec{Containers: []corev1.Container{container},},},},}return r.Create(ctx, job)
}
五、实际使用场景
场景1:简单训练任务
apiVersion: training.example.com/v1
kind: PyJob
metadata:name: bert-training
spec:image: "pytorch/pytorch:2.0-cuda11.7-cudnn8-devel"command: ["python", "train_bert.py"]gpu: 1resources:cpu: "4"memory: "8Gi"
传统方式需要创建:
- ConfigMap(训练脚本)
- Job(训练任务)
- Service(日志收集)
- PVC(数据存储)
Operator方式只需要:
- 一个PyJob资源!
场景2:分布式多GPU训练
apiVersion: training.example.com/v1
kind: PyJob
metadata:name: distributed-training
spec:image: "pytorch/pytorch:2.0-cuda11.7-cudnn8-devel"command: - "python"- "train_distributed.py"- "--world-size=4"gpu: 4datasetPath: "/mnt/dataset"outputPath: "/mnt/output"resources:cpu: "16"memory: "32Gi"
Operator自动处理:
- GPU资源调度
- 分布式训练配置
- 存储卷挂载
- 状态监控
六、开发经验分享
1. 项目结构设计
k8s_operator_train/
├── api/v1/ # API定义
│ ├── pyjob_types.go # 资源结构定义
│ └── groupversion_info.go # API版本信息
├── controllers/ # Controller实现
│ └── pyjob_controller.go # 核心业务逻辑
├── config/ # 部署配置
│ ├── crd/ # CRD定义
│ ├── rbac/ # 权限配置
│ └── manager/ # 部署配置
├── examples/ # 使用示例
└── scripts/ # 构建脚本
2. 开发工具链
- Kubebuilder:Operator开发框架
- controller-runtime:Controller运行时
- Kustomize:配置管理
- Docker:容器化部署
3. 调试技巧
# 本地开发调试
make run# 查看资源状态
kubectl get pyjobs
kubectl describe pyjob <name># 查看Controller日志
kubectl logs -n system deployment/pyjob-controller-manager# 查看事件
kubectl get events --sort-by=.metadata.creationTimestamp
七、部署和使用
快速部署
# 1. 克隆项目
git clone git@github.com:pwxwmm/k8s_operator_train.git
cd k8s_operator_train# 2. 构建和部署
./scripts/dev-setup.sh
./scripts/build.sh
./scripts/deploy.sh# 3. 运行示例
kubectl apply -f examples/simple-training.yaml# 4. 查看状态
kubectl get pyjobs
八、监控和管理
# 查看所有训练任务
kubectl get pyjobs -A# 监控任务状态
kubectl get pyjob <name> -w# 查看任务日志
kubectl logs -l pyjob-name=<name># 删除任务
kubectl delete pyjob <name>
九、项目亮点
1. 完整的生产就绪特性
- ✅ RBAC权限控制:安全的资源访问
- ✅ 状态监控:实时任务状态跟踪
- ✅ 错误处理:自动重试和故障恢复
- ✅ 资源管理:智能的GPU和存储调度
- ✅ 可扩展性:支持复杂的训练场景
2. 丰富的使用示例
- 简单训练任务
- 多GPU分布式训练
- 带持久化存储的训练
- 自定义资源配置
3. 完善的文档
- 详细的README文档
- 快速开始指南
- 开发文档
- 故障排除指南
十、技术收获
1. Kubernetes扩展开发
- 深入理解CRD和Controller机制
- 掌握Operator开发最佳实践
- 学习云原生架构设计模式
2. Go语言实践
- 大型项目的代码组织
- 并发编程和错误处理
- 测试和调试技巧
3. 运维自动化
- 将运维知识编码到系统中
- 声明式API设计
- 自动化运维流程
通过这个项目,我们实现了一个完整的Kubernetes Operator,它展示了如何:
- 简化复杂操作:将多个Kubernetes资源的创建和管理抽象为一个PyJob资源
- 自动化运维:自动处理GPU调度、存储管理、状态监控等复杂逻辑
- 提升用户体验:用户只需要定义期望状态,Operator自动处理实现细节
- 保证可靠性:通过调和循环确保系统始终处于期望状态
这正是Operator模式的核心价值:将运维专家的知识编码到Kubernetes中,让复杂的应用管理变得简单可靠。我认为这也是声明式的一个探索吧
十一、下一步计划
- 添加Webhook验证功能
- 集成Prometheus监控
- 支持多集群训练
- 添加工作流编排能力
项目地址: GitHub - PyJob Operator
CSDN博客: 从零开始构建Kubernetes Operator
联系方式: 1300042631@qq.com / mmwei3@iflytek.com
如果你对这个项目感兴趣,欢迎Star、Fork和提交Issue!让我们一起推动云原生技术的发展! 🚀
本文首发于CSDN技术博客,转载请注明出处。