c过渡c++应知应会(2)
c过渡c++应知应会(2)
- 1.缺省参数
- 2.函数重载
- 3.引用
- 4.inline
1.缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参,则采用该形参的缺省值,否则使用指定的实参,缺省参数分为全缺省和半缺省参数。
全缺省:
全部形参给缺省值。
半缺省:
部分形参给缺省值。
注意:c++规定半缺省参数必须从右往左依次连续缺省,不能跳跃的给。
调用带缺省参数的函数时,必须从右往左依次给实参,不能跳跃的给。
关键:
函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须在声明中给缺省值
int add(int a, int b=1)//半缺省
{return a + b;
}
int main()
{add(1);//b使用缺省值return 0;
}
int add(int a=1, int b=1)//全缺省
{return a + b;
}
int main()
{add();//没有传参的话,使用缺省值return 0;
}
2.函数重载
在上一次学习中我们知道c++支持在不同域使用同名变量,函数等。
除此之外,c++还可以在同一作用域出现同名函数。
但是有些人就要问了,为什么非得创建同名函数呢?名字不一样不照样可以使用吗?
让我们看这个例子:
int Add1(int l,int r)
{return l+r;
}
double Add1(double l,double r)
{return l+r;
}
我们想实现两个数相加函数,但针对不同类型时却可能要将函数名变成Add1,Add2…
这无疑会在将来调用时产生隐患。所以c++支持出现同名函数,要求同名函数的形参不同,可以参数个数不同或者类型不同。
int Add(int l,int r)
{return l+r;
}
double Add(double l,double r)
{return l+r;
}
这样在将来调用相加函数时,一律写成Add即可。
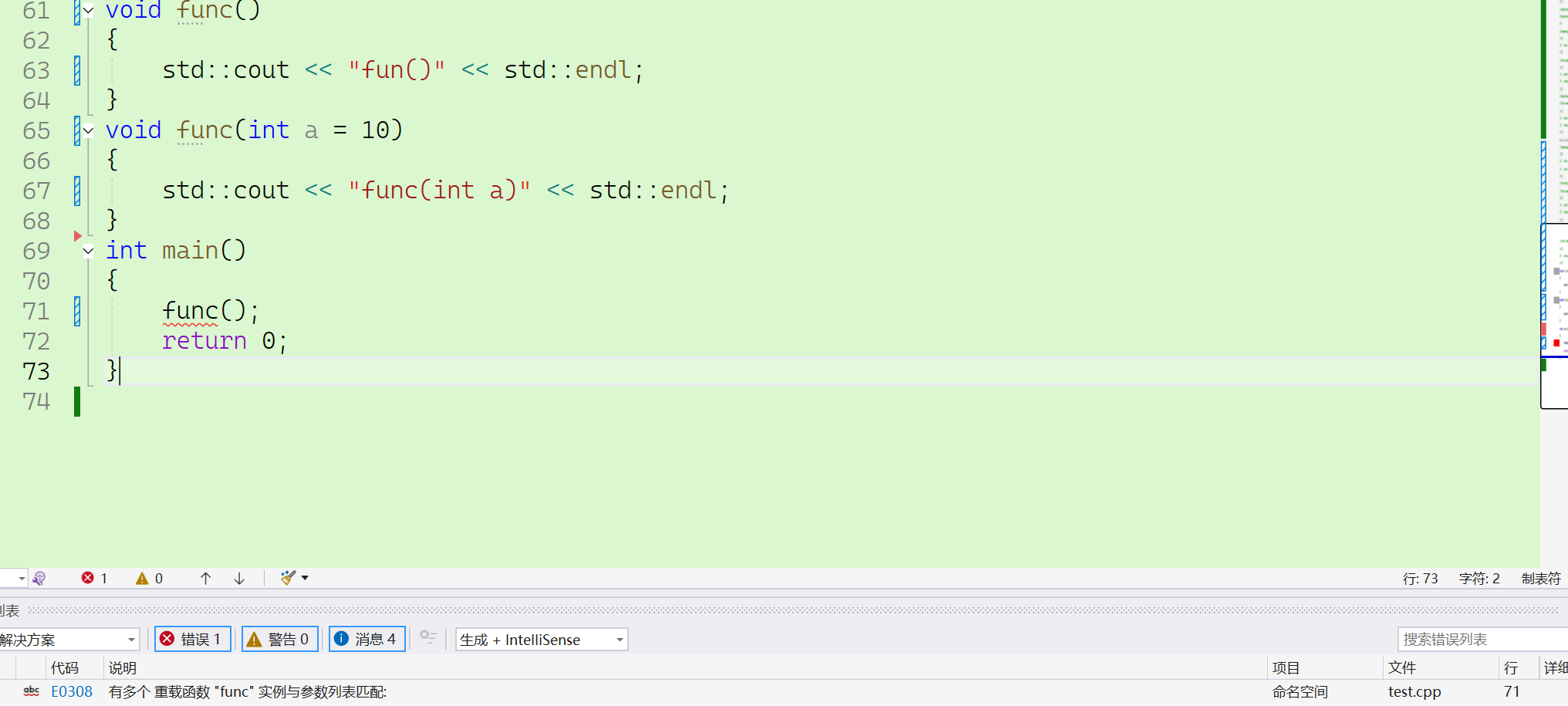
这段代码有问题吗?
void func()
{std::cout << "fun()" << std::endl;
}
void func(int a = 10)
{std::cout << "func(int a)" << std::endl;
}
毋庸置疑,两个函数构成重载。如果程序中没有func();就不会报错,但是如果有这一条语句,编译器就不认得到底要调用哪一个函数。
3.引用
概念:引用就是给已存在变量取了一个别名。
编译器不会为引用变量开辟内存空间。它和它引用的变量共用同一块内存空间。
例如:这里有一只猫,你可以叫它猫,也可以叫它哈基米,也可以叫它专属的名字。
定义方式:
类型& 引用别名 = 引用对象
int main()
{int a = 0;int& b = a;a++;std::cout << b << std::endl;//输出结果为1return 0;
}
关于引用需要注意的点:
1.引用在定义时必须初始化,例如int a = 0; int& b = a;不允许等号右边没有变量。
**2.**一个变量可以有多个引用。
**3.**引用只能引用一个实体,不能改变
引用的用处:
在c语言阶段,我们经常使用指针来操作并解决问题。有了引用后,指针涉及到的一些场景就可以被替代了。而且引用理解起来要比指针容易,能减轻代码错误。
例如,在交换两个变量的值时:
void Swap(int& a,int& b)
{int tmp=a;a=b;b=tmp;
}
这样写非常容易理解。
再比如,在学习数据结构栈时,我们在操作改动栈时,必须要用一级指针来传参。但有了引用以后,我们可以直接传引用。比方说在入栈时:我们直接进行操作即可,不用使用->操作符了
void STPush(ST& rs, STDataType x)
{assert(ps);// 满了, 扩容 if (rs.top == rs.capacity){printf("扩容\n");int newcapacity = rs.capacity == 0 ? 4 : rs.capacity * 2;STDataType* tmp = (STDataType*)realloc(rs.a, newcapacity *sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}rs.a = tmp;rs.capacity = newcapacity;}rs.a[rs.top] = x;rs.top++;
}
4.inline
用inline修饰的函数叫做内联函数,编译时编译器会再调用的地方展开内联函数,这样就不需要建立栈帧,提高效率了。
inline int add(int a, int b)
{return a + b;
}
int main()
{//如果汇编中有call add语句就是没有展开,否则就是展开了add(1, 2);return 0;
}
注意:
-
在vs编译器debug版本下默认是不展开inline,这样方便调试。

(出现了call add说明没有展开) -
inline不建议声明和定义分离到两个文件。因为如果inline被展开,就没有函数地址。在链接阶段,链接器需要根据函数调用找到对应的函数定义,但此时可能找不到该函数的地址,从而导致链接错误。
完
如果发现错误,欢迎打在评论区。
主页还有更多优质内容OvO