【卷积神经网络详解与实例】10——经典CNN之GoogLeNet
1 提出背景
GoogLeNet(也称为Inception v1)是由Google团队于2014年提出的一种深度卷积神经网络架构。该网络在当年的ImageNet大规模视觉识别挑战赛(ILSVRC2014)中取得了突破性成绩,在分类任务上以6.67%的错误率夺得第一名,同时在检测任务中也表现出色。
论文:1409.4842] Going Deeper with Convolutions![]() https://arxiv.org/abs/1409.4842
https://arxiv.org/abs/1409.4842
论文详解:(51 封私信 / 62 条消息) 经典神经网络超详细(六)GoogLeNet网络(论文精读+网络详解+代码实战) - 知乎![]() https://zhuanlan.zhihu.com/p/28851135887
https://zhuanlan.zhihu.com/p/28851135887
在GoogLeNet提出之前,卷积神经网络的发展趋势主要是增加网络的深度(层数)和宽度(每层的神经元数量)。例如,2012年的AlexNet有8层,2014年的VGG网络有16-19层。然而,这种简单增加网络深度和宽度的方法带来了几个主要问题:
-
计算资源消耗剧增:更深的网络意味着更多的参数,需要更多的计算资源和内存。例如,VGG-16拥有约138M参数,计算开销巨大。
-
过拟合风险增加:参数数量增多容易导致模型在训练集上表现很好,但在测试集上泛化能力不佳。
-
梯度消失/爆炸问题:随着网络层数增加,梯度在反向传播过程中容易消失或爆炸,虽然ReLU激活函数和批归一化等技术可以缓解,但仍需更高效的设计。
在这样的背景下,GoogLeNet的作者们在论文《Going Deeper with Convolutions》中提出了一种新的网络架构,旨在提高计算效率和性能,同时控制参数数量。GoogLeNet的核心思想是通过"Inception模块"和"网络中的网络"(Network In Network)技术,更有效地利用计算资源。
2 创新点
GoogLeNet的设计引入了几项重要的创新,这些创新不仅提高了模型性能,还大大减少了参数数量和计算复杂度。
2.1 Inception模块
Inception模块是GoogLeNet的核心创新。传统的卷积神经网络在每一层只使用一种尺寸的卷积核(如3×3或5×5),而Inception模块在同一层中同时使用不同尺寸的卷积核(1×1、3×3、5×5)和池化操作,然后将所有结果拼接在一起。这种设计允许网络在同一层次上捕捉不同尺度的特征。
Inception模块的主要优势是:
-
可以在同一层次上捕获不同尺度的特征,增强网络的表达能力
-
通过1×1卷积进行降维,减少计算量
-
增加了网络的宽度,而不是深度,从而提高了特征表达能力
2.2 1×1卷积的使用
GoogLeNet大量使用了1×1卷积,主要用于降维和升维。1×1卷积有以下优势:
-
减少计算复杂度:在3×3或5×5卷积之前使用1×1卷积可以减少输入通道数,从而大大降低计算量。例如,将输入从256维减少到64维,再进行3×3卷积,计算量可减少近4倍。
-
增加非线性:1×1卷积后接ReLU激活函数可以增加网络的非线性表达能力。
-
跨通道的信息交互:1×1卷积可以实现跨通道的信息整合和交互。
2.3 全局平均池化替代全连接层
传统的CNN网络在最后几层通常使用全连接层,但这些层包含了大量参数。例如,AlexNet的全连接层参数占总参数的90%以上。GoogLeNet使用全局平均池化替代了全连接层,这带来了以下好处:
-
大大减少了参数数量,降低了过拟合风险
-
更好地适应不同尺寸的输入图像
-
强化了特征图与类别之间的对应关系,使网络更具可解释性
2.4 辅助分类器
GoogLeNet在网络中间层添加了两个辅助分类器,用于解决深层网络中的梯度消失问题。这些辅助分类器只在训练阶段使用,在测试阶段会被丢弃。辅助分类器的作用是:
-
将梯度直接传播到浅层网络,缓解梯度消失问题
-
增加正则化效果,提高模型的泛化能力
-
提供额外的监督信号,帮助网络更好地收敛
3 网络结构
3.1 整体结构
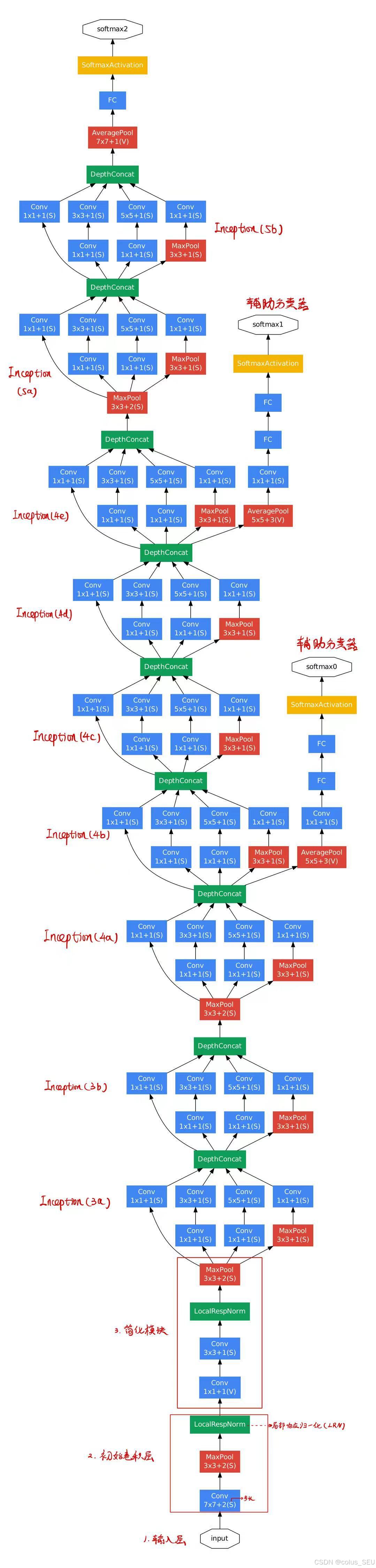
GoogLeNet的整体结构由多个Inception模块堆叠而成,包括9个Inception模块。
-
输入层:接受224×224×3的RGB图像
-
初始卷积层:
-
卷积层:7×7卷积,64个滤波器(卷积核),步长为2,padding为3
-
最大池化:3×3,步长为2
-
局部响应归一化(LRN)
-
-
简化模块:
-
卷积层:1×1卷积,64个滤波器
-
卷积层:3×3卷积,192个滤波器,padding为1
-
局部响应归一化(LRN)
-
最大池化:3×3,步长为2
-
-
Inception模块组:
-
Inception模块(3a)
-
Inception模块(3b)
-
最大池化:3×3,步长为2
-
Inception模块(4a)
-
Inception模块(4b)
-
Inception模块(4c)
-
Inception模块(4d)
-
Inception模块(4e)
-
最大池化:3×3,步长为2
-
Inception模块(5a)
-
Inception模块(5b)
-
-
输出层:
-
全局平均池化
-
Dropout层
-
全连接层
-
Softmax分类器
-
此外,在Inception模块(4a)和Inception模块(4d)之后,各有一个辅助分类器。
3.2 Inception结构
-
总体结构
| 原始结构 | 降维后 |
|---|---|
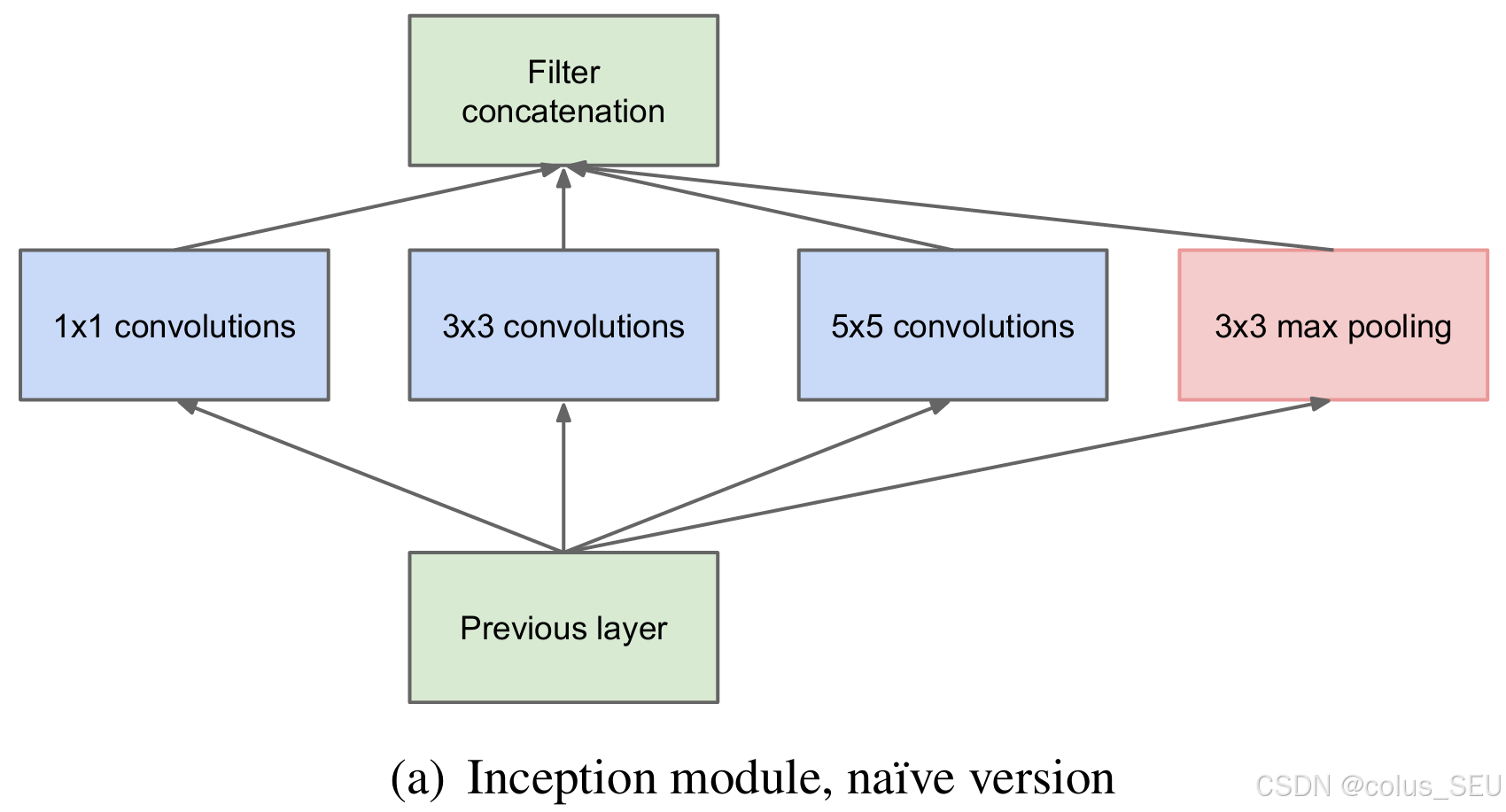 | 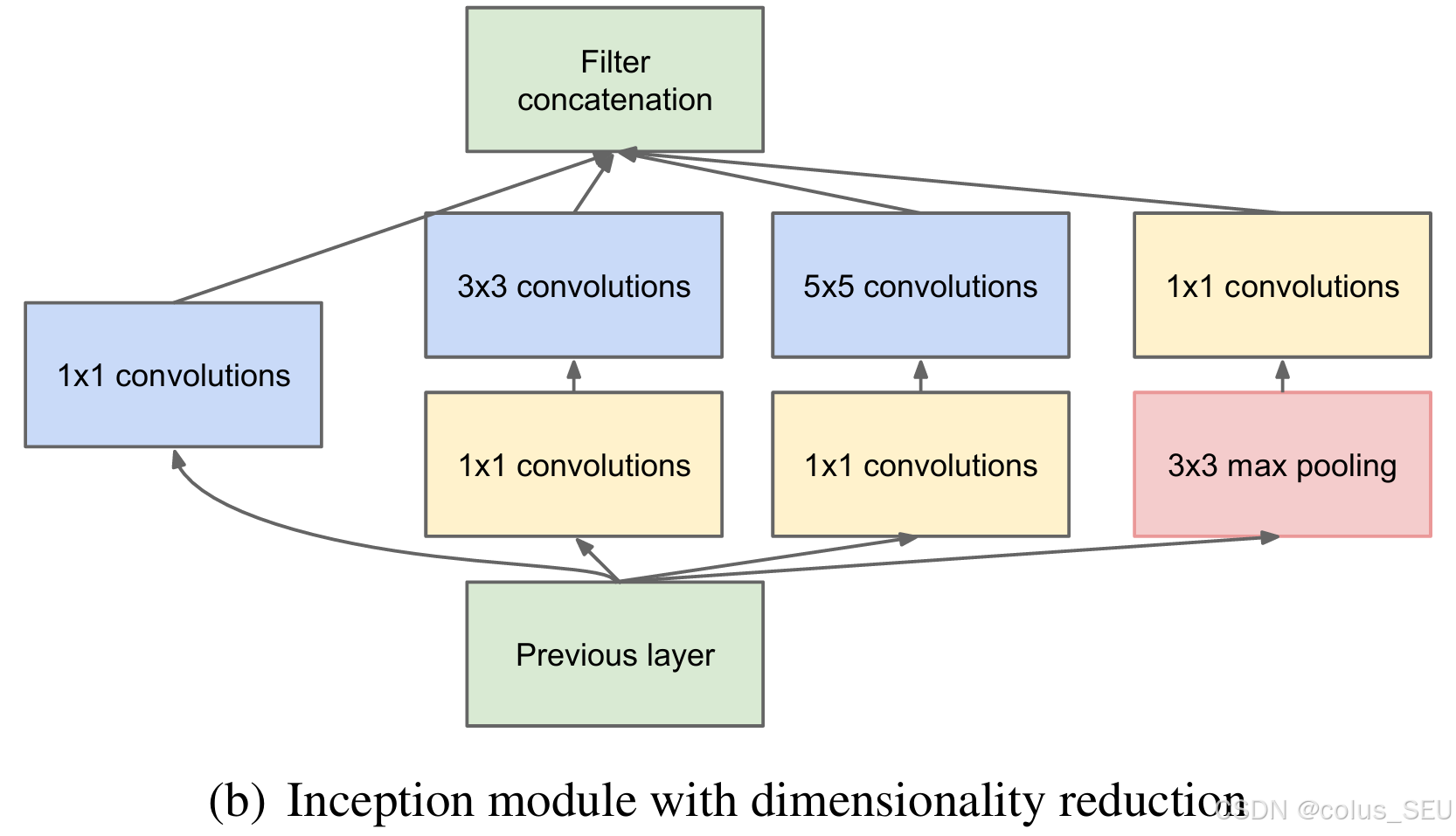 |
左图是论文中提出的inception原始结构,右图是inception加上降维功能的结构。
先看左图,inception结构一共有4个分支,也就是说我们的输入的特征矩阵并行的通过这四个分支得到四个输出,然后在在将这四个输出在深度维度(channel维度)进行拼接得到我们的最终输出(注意,为了让四个分支的输出能够在深度方向进行拼接,必须保证四个分支输出的特征矩阵高度和宽度都相同)。
分支1是卷积核大小为1×1的卷积层,stride=1,
分支2是卷积核大小为3×3的卷积层,stride=1,padding=1(保证输出特征矩阵的高和宽和输入特征矩阵相等),
分支3是卷积核大小为5×5的卷积层,stride=1,padding=2(保证输出特征矩阵的高和宽和输入特征矩阵相等),
分支4是池化核大小为3×3的最大池化下采样,stride=1,padding=1(保证输出特征矩阵的高和宽和输入特征矩阵相等)。
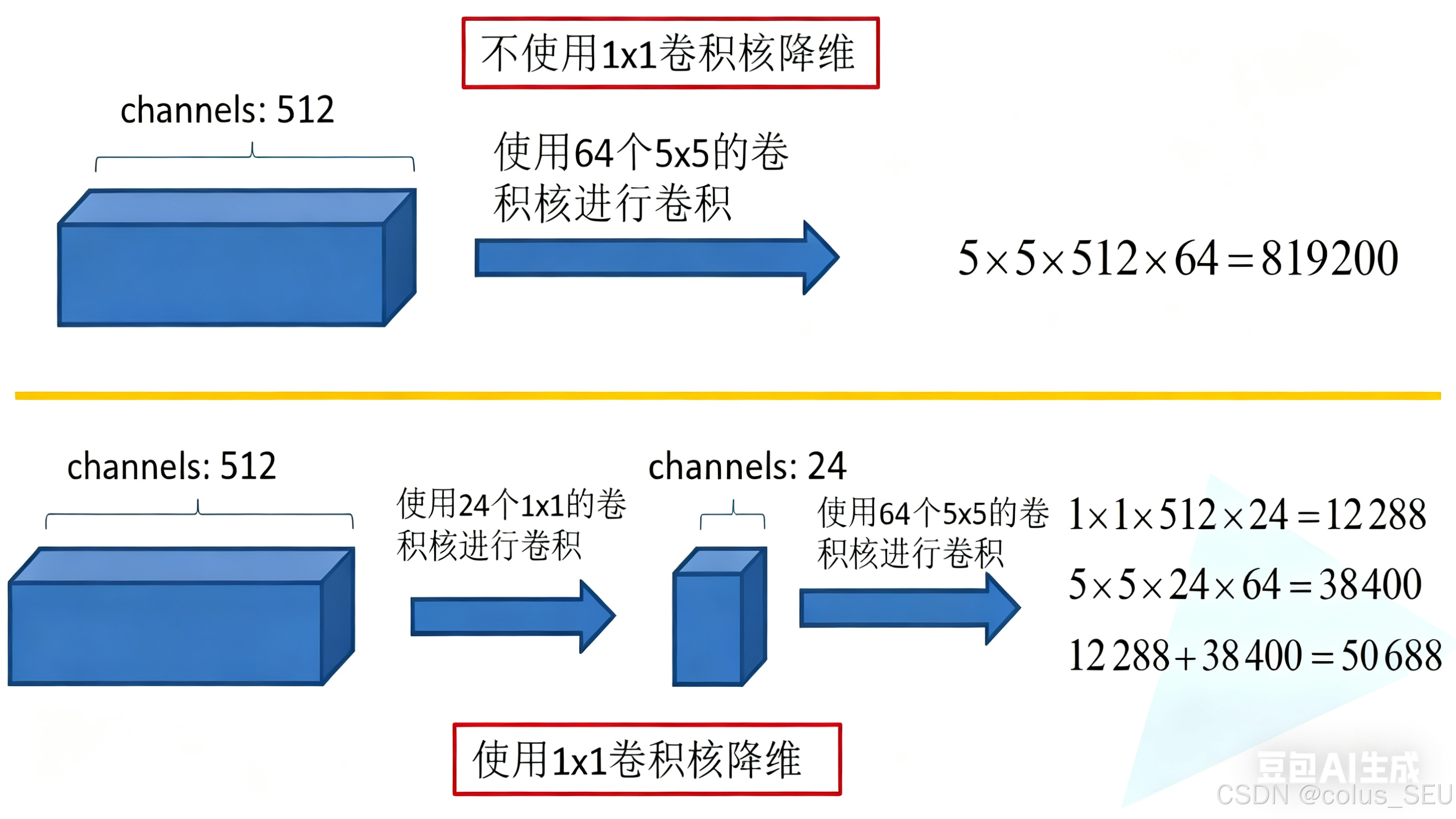
再看右图,对比左图,就是在分支2,3,4上加入了卷积核大小为1×1的卷积层,目的是为了降维,减少模型训练参数,减少计算量,下面我们看看1×1的卷积核是如何减少训练模型参数的。同样是对一个深度为512的特征矩阵使用64个大小为5×5的卷积核进行卷积,不使用1×1卷积核进行降维话一共需要819200个参数,如果使用1×1卷积核进行降维一共需要50688个参数,明显少了很多。
-
具体结构举例
每个Inception模块的结构略有不同,但基本思想是一致的。以Inception(3a)为例,其结构如下:
-
分支1:
-
1×1卷积,64个滤波器
-
-
分支2:
-
1×1卷积,96个滤波器(降维)
-
3×3卷积,128个滤波器,padding为1
-
-
分支3:
-
1×1卷积,16个滤波器(降维)
-
5×5卷积,32个滤波器,padding为2
-
-
分支4:
-
3×3最大池化,步长为1,padding为1
-
1×1卷积,32个滤波器
-
然后将四个分支的输出在通道维度上拼接起来,形成256个通道的特征图。
其他Inception模块的结构类似,只是滤波器数量有所不同。例如,Inception(4a)的输出通道数为512,Inception(5a)的输出通道数为832。
3.3 辅助分类器结构
辅助分类器的结构如下:
-
平均池化:5×5,步长为3
-
1×1卷积,128个滤波器,后接ReLU激活函数
-
全连接层,1024个节点,后接ReLU激活函数
-
Dropout层,丢弃率为70%
-
全连接层,1000个节点(对应ImageNet的1000个类别)
-
Softmax分类器
在训练过程中,辅助分类器的损失会以权重0.3加到总损失中,帮助网络更好地收敛。
GoogLeNet的参数数量约为6.8百万(6.8M),远少于AlexNet的60M和VGG-16的138M。这主要得益于Inception模块的设计和1×1卷积的降维作用。
4 基于Pytorch实现
以下项目通过PyTorch实现GoogLeNet并在CIFAR-10上进行训练。
项目目录如下:
GoogLeNet_CIFAR10/│├── data/│ ├── raw/ # 原始数据(代码中有自动下载数据的逻辑)│ └── processed/ # 处理后的数据(代码中有自动下载数据的逻辑)│├── models/│ ├── __init__.py│ └── googlenet.py # GoogLeNet模型定义│├── utils/│ ├── __init__.py│ ├── data_utils.py # 数据处理工具│ └── visualization.py # 可视化工具│├── train.py # 训练脚本├── test.py # 测试脚本└── config.py # 配置文件配置文件
# config.pyimport os# 数据配置DATA_DIR = 'data'CIFAR10_DIR = os.path.join(DATA_DIR, 'cifar10')BATCH_SIZE = 128NUM_WORKERS = 4# 模型配置NUM_CLASSES = 10 # CIFAR-10有10个类别AUX_LOGITS = True # 是否使用辅助分类器DROPOUT = 0.4 # Dropout率# 训练配置LEARNING_RATE = 0.001MOMENTUM = 0.9WEIGHT_DECAY = 5e-4NUM_EPOCHS = 100DEVICE = 'cuda' if os.environ.get('CUDA_VISIBLE_DEVICES') is not None else 'cpu'# 保存配置CHECKPOINT_DIR = 'checkpoints'os.makedirs(CHECKPOINT_DIR, exist_ok=True)模型定义
# googlenet.pyimport torchimport torch.nn as nnimport torch.nn.functional as Fclass Inception(nn.Module):def __init__(self, in_channels, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_proj):super(Inception, self).__init__()# 1x1 conv branchself.b1 = nn.Sequential(nn.Conv2d(in_channels, n1x1, kernel_size=1),nn.BatchNorm2d(n1x1),nn.ReLU(True))# 1x1 conv -> 3x3 conv branchself.b2 = nn.Sequential(nn.Conv2d(in_channels, n3x3red, kernel_size=1),nn.BatchNorm2d(n3x3red),nn.ReLU(True),nn.Conv2d(n3x3red, n3x3, kernel_size=3, padding=1),nn.BatchNorm2d(n3x3),nn.ReLU(True))# 1x1 conv -> 5x5 conv branchself.b3 = nn.Sequential(nn.Conv2d(in_channels, n5x5red, kernel_size=1),nn.BatchNorm2d(n5x5red),nn.ReLU(True),nn.Conv2d(n5x5red, n5x5, kernel_size=5, padding=2),nn.BatchNorm2d(n5x5),nn.ReLU(True))# 3x3 pool -> 1x1 conv branchself.b4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(True))def forward(self, x):y1 = self.b1(x)y2 = self.b2(x)y3 = self.b3(x)y4 = self.b4(x)return torch.cat([y1, y2, y3, y4], 1)class AuxClassifier(nn.Module):def __init__(self, in_channels, num_classes, dropout=0.7):super(AuxClassifier, self).__init__()# 使用自适应平均池化确保输出尺寸合适self.avgpool = nn.AdaptiveAvgPool2d((4, 4))self.conv = nn.Sequential(nn.Conv2d(in_channels, 128, kernel_size=1),nn.BatchNorm2d(128),nn.ReLU(True))# 计算展平后的尺寸: 128 * 4 * 4 = 2048self.fc1 = nn.Linear(2048, 1024)self.dropout = nn.Dropout(p=dropout)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):x = self.avgpool(x)x = self.conv(x)x = x.view(x.size(0), -1) # 展平x = F.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return xclass GoogLeNet(nn.Module):def __init__(self, num_classes=10, aux_logits=True, dropout=0.4):super(GoogLeNet, self).__init__()self.aux_logits = aux_logits# 前面的卷积层self.pre_layers = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64),nn.ReLU(True),nn.MaxPool2d(kernel_size=3, stride=2, padding=1),nn.Conv2d(64, 64, kernel_size=1),nn.BatchNorm2d(64),nn.ReLU(True),nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.BatchNorm2d(192),nn.ReLU(True),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))# Inception模块self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)# 修改池化参数,减小步长self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)if self.aux_logits:self.aux1 = AuxClassifier(512, num_classes, dropout)self.aux2 = AuxClassifier(528, num_classes, dropout)self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)# 修改池化参数,减小步长self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)# 后面的分类器self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(p=dropout)self.linear = nn.Linear(1024, num_classes)def forward(self, x):out = self.pre_layers(x)out = self.a3(out)out = self.b3(out)out = self.maxpool(out)out = self.a4(out)if self.training and self.aux_logits:aux1 = self.aux1(out)out = self.b4(out)out = self.c4(out)out = self.d4(out)if self.training and self.aux_logits:aux2 = self.aux2(out)out = self.e4(out)out = self.maxpool(out)out = self.a5(out)out = self.b5(out)out = self.avgpool(out)out = out.view(out.size(0), -1)out = self.dropout(out)out = self.linear(out)if self.training and self.aux_logits:return out, aux1, aux2return out数据处理
# data_utils.pyimport torchimport torchvisionimport torchvision.transforms as transformsdef get_cifar10_loaders(data_dir, batch_size=128, num_workers=4):"""获取CIFAR-10数据加载器参数:data_dir: 数据目录batch_size: 批大小num_workers: 数据加载的线程数返回:train_loader: 训练数据加载器test_loader: 测试数据加载器"""# 定义数据预处理transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])# 加载训练集train_set = torchvision.datasets.CIFAR10(root=data_dir, train=True, download=True, transform=transform_train)train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=num_workers)# 加载测试集test_set = torchvision.datasets.CIFAR10(root=data_dir, train=False, download=True, transform=transform_test)test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=num_workers)return train_loader, test_loader可视化
# visualization.pyimport matplotlib.pyplot as pltimport numpy as npfrom sklearn.metrics import confusion_matriximport itertoolsdef plot_loss_accuracy(train_losses, val_losses, train_accs, val_accs, save_path=None):"""绘制训练和验证的损失和准确率曲线参数:train_losses: 训练损失列表val_losses: 验证损失列表train_accs: 训练准确率列表val_accs: 验证准确率列表save_path: 保存路径,如果为None则不保存"""plt.figure(figsize=(12, 4))# 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(train_losses, label='Train Loss')plt.plot(val_losses, label='Validation Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.title('Loss Curve')# 绘制准确率曲线plt.subplot(1, 2, 2)plt.plot(train_accs, label='Train Accuracy')plt.plot(val_accs, label='Validation Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.title('Accuracy Curve')plt.tight_layout()if save_path:plt.savefig(save_path)plt.show()def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues, save_path=None):"""绘制混淆矩阵参数:cm: 混淆矩阵classes: 类别列表normalize: 是否归一化title: 标题cmap: 颜色映射save_path: 保存路径,如果为None则不保存"""if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')plt.figure(figsize=(10, 8))plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')if save_path:plt.savefig(save_path)plt.show()模型训练
# train.pyimport torchimport torch.nn as nnimport torch.optim as optimfrom tqdm import tqdmfrom config import *from models.googlenet import GoogLeNetfrom utils.data_utils import get_cifar10_loadersfrom utils.visualization import plot_loss_accuracydef train_model():# 设置设备device = torch.device(DEVICE)print(f"Using device: {device}")# 加载数据train_loader, test_loader = get_cifar10_loaders(CIFAR10_DIR, BATCH_SIZE, NUM_WORKERS)# 创建模型model = GoogLeNet(num_classes=NUM_CLASSES, aux_logits=AUX_LOGITS, dropout=DROPOUT)model = model.to(device)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=LEARNING_RATE,momentum=MOMENTUM, weight_decay=WEIGHT_DECAY)scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30, 60, 90], gamma=0.1)# 记录训练过程train_losses = []val_losses = []train_accs = []val_accs = []best_acc = 0.0# 训练循环for epoch in range(NUM_EPOCHS):model.train()running_loss = 0.0correct = 0total = 0# 训练阶段train_pbar = tqdm(train_loader, desc=f'Epoch {epoch + 1}/{NUM_EPOCHS} [Train]')for inputs, targets in train_pbar:inputs, targets = inputs.to(device), targets.to(device)# 梯度清零optimizer.zero_grad()# 前向传播if AUX_LOGITS:outputs, aux1, aux2 = model(inputs)loss1 = criterion(outputs, targets)loss2 = criterion(aux1, targets)loss3 = criterion(aux2, targets)loss = loss1 + 0.3 * (loss2 + loss3)else:outputs = model(inputs)loss = criterion(outputs, targets)# 反向传播和优化loss.backward()optimizer.step()# 统计running_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# 更新进度条train_pbar.set_postfix({'Loss': running_loss / (total / BATCH_SIZE), 'Acc': 100. * correct / total})train_loss = running_loss / len(train_loader)train_acc = 100. * correct / totaltrain_losses.append(train_loss)train_accs.append(train_acc)# 验证阶段model.eval()val_loss = 0.0correct = 0total = 0with torch.no_grad():val_pbar = tqdm(test_loader, desc=f'Epoch {epoch + 1}/{NUM_EPOCHS} [Val]')for inputs, targets in val_pbar:inputs, targets = inputs.to(device), targets.to(device)# 前向传播outputs = model(inputs)loss = criterion(outputs, targets)# 统计val_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# 更新进度条val_pbar.set_postfix({'Loss': val_loss / (total / BATCH_SIZE), 'Acc': 100. * correct / total})val_loss = val_loss / len(test_loader)val_acc = 100. * correct / totalval_losses.append(val_loss)val_accs.append(val_acc)# 更新学习率scheduler.step()# 打印统计信息print(f'Epoch {epoch + 1}/{NUM_EPOCHS}:')print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')# 保存最佳模型if val_acc > best_acc:best_acc = val_acctorch.save({'epoch': epoch + 1,'state_dict': model.state_dict(),'optimizer': optimizer.state_dict(),'best_acc': best_acc,}, os.path.join(CHECKPOINT_DIR, 'googlenet_best.pth'))# 绘制训练曲线if (epoch + 1) % 10 == 0:plot_loss_accuracy(train_losses, val_losses, train_accs, val_accs,save_path=os.path.join(CHECKPOINT_DIR, f'train_curve_epoch_{epoch + 1}.png'))print(f'Training completed. Best validation accuracy: {best_acc:.2f}%')# 绘制最终训练曲线plot_loss_accuracy(train_losses, val_losses, train_accs, val_accs,save_path=os.path.join(CHECKPOINT_DIR, 'train_curve_final.png'))if __name__ == '__main__':train_model()模型测试
# test.pyimport torchimport torch.nn as nnfrom sklearn.metrics import confusion_matrix, classification_reportfrom config import *from models.googlenet import GoogLeNetfrom utils.data_utils import get_cifar10_loadersfrom utils.visualization import plot_confusion_matrixdef test_model(model_path):# 设置设备device = torch.device(DEVICE)print(f"Using device: {device}")# 加载数据_, test_loader = get_cifar10_loaders(CIFAR10_DIR, BATCH_SIZE, NUM_WORKERS)# 创建模型model = GoogLeNet(num_classes=NUM_CLASSES, aux_logits=False, dropout=0)model = model.to(device)# 加载模型权重if os.path.exists(model_path):checkpoint = torch.load(model_path, map_location=device)model.load_state_dict(checkpoint['state_dict'])print(f"Model loaded from {model_path}")print(f"Best accuracy: {checkpoint['best_acc']:.2f}%")else:print(f"No model found at {model_path}")return# 定义损失函数criterion = nn.CrossEntropyLoss()# 测试模型model.eval()test_loss = 0.0correct = 0total = 0all_targets = []all_predictions = []with torch.no_grad():for inputs, targets in test_loader:inputs, targets = inputs.to(device), targets.to(device)# 前向传播outputs = model(inputs)loss = criterion(outputs, targets)# 统计test_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# 保存真实标签和预测结果all_targets.extend(targets.cpu().numpy())all_predictions.extend(predicted.cpu().numpy())test_loss = test_loss / len(test_loader)test_acc = 100. * correct / totalprint(f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')# CIFAR-10类别classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')# 计算并绘制混淆矩阵cm = confusion_matrix(all_targets, all_predictions)plot_confusion_matrix(cm, classes, normalize=True,title='Normalized Confusion Matrix',save_path=os.path.join(CHECKPOINT_DIR, 'confusion_matrix.png'))# 打印分类报告print("\nClassification Report:")print(classification_report(all_targets, all_predictions, target_names=classes))if __name__ == '__main__':model_path = os.path.join(CHECKPOINT_DIR, 'googlenet_best.pth')test_model(model_path)