《WINDOWS 环境下32位汇编语言程序设计》学习17章 PE文件(2)
17.4 资源
17.4.1 资源简介
资源是PE文件中非常重要的部分,几乎所有的PE文件中都包含资源,与导入表和导出表相比,资源的组织方式要复杂得多,读者只要看看图17.8中的示意图,就知道笔者所言不虚。
如果一开始就扎进一堆与资源相关的数据结构中去分析各字段的含义,恐怕会越来越糊涂,要了解资源的话,重在理解资源整体上的组织结构。
我们知道,PE文件资源中的内容包括光标、图标、位图、菜单等十几种标准的类型,除此之外,还可以使用自定义的类型(这些类型的资源在第5章中已经有所介绍)。每种类型的资源中可能存在多个资源项,这些资源项用不同的ID或者名称来分辨,在某个资源ID下,还可以同时存在不同代码页的版本。
要将这么多种类型的不同ID的资源有序地组织起来,用类似于磁盘目录结构的方式是很不错的。打个比方,假如在磁盘的根目录下按照类型建立若干个第2层目录,目录名是“光标”、“图标”、“位图”和“菜单”等,就可以将各种资源分类放入这些目录中,假设现在有n个光标,那么在“光标”目录中再以光标ID为名建立n个第3层子目录,进入某个子目录后,再以代码页为名称建立不同文件,这样所有的资源就按照树型目录的方式组织起来了。现在要查找某个资源的话,那么按照根目录→资源类型→资源ID→资源代码页这样的步骤一层层地进入相应的子目录并找到正确的资源。
如图17.8所示,PE文件中组织资源的方式与上面的构思极其相似,正是按照根目录→资源类型→资源ID的3层树型目录结构来组织资源的,只不过在第3层目录中放置的代码页“文件”不是资源本身而是一个用来描述资源的结构罢了,通过这个结构中的指针才能最后找到资源数据。
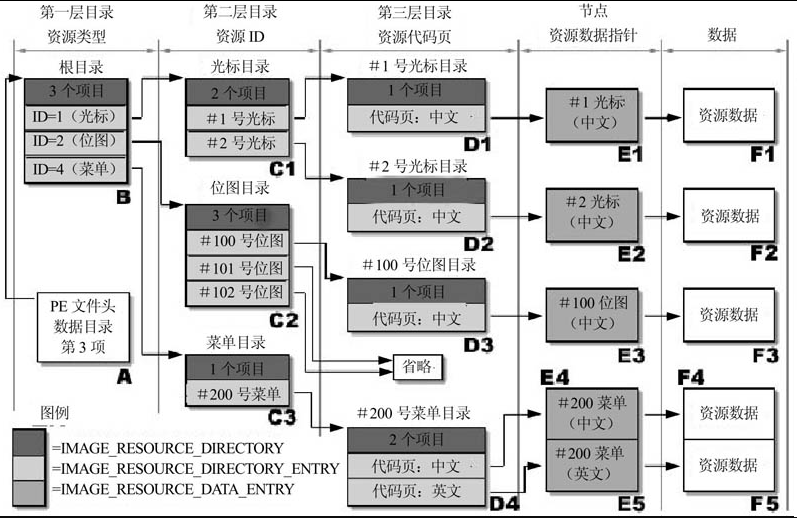
图17.8 PE文件中资源的组织方式
17.4.2 资源的组织方式
1.获取资源的位置
图17.8所示的所有目录结构数据和所有的资源数据都集中放在一个资源数据块中,资源数据块的位置和大小可以从PE文件头中的IMAGE_OPTIONAL_HEADER32结构的数据目录字段中获取,与资源对应的项目是数据目录中的第3个IMAGE_DATA_DIRECTORY结构(如表17.4所示),从这个结构的VirtualAddress字段得到的就是资源块地址的RVA值。如图17.8中的A所示,从数据目录表中得到的资源块的起始地址就是资源根目录的起始地址,从这里开始就可以一层层地找到资源的所有信息了。
如图17.8中的A所示,从数据目录表中得到的资源块的起始地址就是资源根目录的起始地址,从这里开始就可以一层层地找到资源的所有信息了。
在获取资源块地址的时候,注意不要使用查找“.rsrc”节起始地址的方法,虽然在一般情况下资源总是在“.rsrc”节中,但这并不是必然的。
2.资源目录
好了,现在继续深入一步,资源目录树的根目录地址已经得到了,那么整个目录树上的目录是如何描述的呢?注意图17.8左下角的图例在整个目录树中出现的位置,这样就可以发现:不管是根目录,还是第2层或第3层中的每个目录都是由一个IMAGE_RESOURCE_ DIRECTORY结构和紧跟其后的数个IMAGE_RESOURCE_DIRECTORY_ENTRY结构组成的,这两种结构一起组成了一个目录块。
IMAGE_RESOURCE_DIRECTORY结构中包含的是本目录的各种属性信息,其中有两个字段说明了本目录中的目录项数量,也就是后面的IMAGE_RESOURCE_DIRECTORY_ENTRY结构的数量。
IMAGE_RESOURCE_DIRECTORY结构的定义如下所示:
IMAGE_RESOURCE_DIRECTORY STRUCTCharacteristics dd ? ;理论上为资源的属性,不过事实上总是0TimeDateStamp dd ? ;资源的产生时刻MajorVersion dw ? ;理论上为资源的版本,不过事实上总是0MinorVersion dw ?NumberOfNamedEntries dw ? ;以名称命名的入口数量NumberOfIdEntries dw ? ;以ID命名的入口数量
IMAGE_RESOURCE_DIRECTORY ENDS在这个结构中,最重要的是最后两个字段,它们说明了本目录中目录项的数量,那么为什么有两个字段呢?
原因是这样的:不管是资源种类,还是资源名称都可以用名称或者ID两种方式定义,比如,在*.rc文件中这样定义:
100 ICON "Test.ico" //(例1)
101 WAVE "Test.wav" //(例2)
HelpFile HELP "Test.chm" //(例3)
102 12345 "Test.bin" //(例4)例1定义了一个资源ID为100的光标资源,其资源类型为“ICON”,但“ICON”只是一个用在rc文件中的助记符,在资源编译器里面会被换成数值型的类型ID,所有的标准类型都是以数值型ID定义的,在资源定义中,1到10h的ID编号保留给标准类型使用。
在例2中,标准的资源类型中并没有“WAVE”这一类型,这时资源的类型属于自定义型,类型的名称就是“WAVE”。
例3则定义了资源名称是“HelpFile”,类型名称为自定义字符串“HELP”的资源。
在例4中,资源的ID编号是102,而类型则是数值型ID,由于标准类型中并没有编号为12345的资源,所以这也是一个自定义类型的资源。
在IMAGE_RESOURCE_DIRECTORY结构中,对以ID命名和以字符串命名的情况是分别指定的:NumberOfNamedEntries字段是以字符串命名的资源数量,而NumberOfIdEntries字段的值是以ID命名的资源数量,所以两者的数量加起来才是本目录中的目录项总和,也就是当前IMAGE_RESOURCE_DIRECTORY结构后面紧跟的IMAGE_RESOURCE_DIRECTORY_ENTRY结构的数量。
现在来介绍一下IMAGE_RESOURCE_DIRECTORY_ENTRY结构,每个结构描述了一个目录项,IMAGE_RESOURCE_DIRECTORY_ENTRY结构是这样定义的:
IMAGE_RESOURCE_DIRECTORY_ENTRY STRUCTName1 dd ? ;目录项的名称字符串指针或IDOffsetToData dd ? ;目录项指针
IMAGE_RESOURCE_DIRECTORY_ENTRY ENDS结构中的两个字段说明如下:
● Name1字段
这个字段的名称应该是“Name”,同样是因为和关键字冲突的原因改为“Name1”,它定义了目录项的名称或者ID,这个字段的含义要看目录项用在什么地方,当结构用于第1层目录的时候(如图17.8中的B所示),这个字段定义的是资源的类型,也就是前面例子中的“ICON”,“WAVE”,“HELP”和12345等;当结构用于第2层目录的时候(如图17.8中的C1到C3),这个字段定义的是资源的名称,也就是前面例子中的100,101,“HelpFile”和102等;而当结构用于第3层目录的时候(如图17.8中的D1到D4),这里定义的是代码页编号。
读者肯定会发现一个问题:当字段作为ID使用的时候,是可以放入一个双字的,如果使用字符串定义的时候,一个双字是不够的,这就需要将两种情况分别对待,区分的方法是使用字段的最高位(位31)。当位31是0的时候,表示字段的值作为ID使用;而位31为1的时候,字段的低位作为指针使用,但由于资源名称字符串是使用UNICODE来编码的,所以这个指针并不直接指向字符串,而是指向一个IMAGE_RESOURCE_DIR_STRING_U结构,这个结构包含UNICODE字符串的长度和字符串本身,其定义如下:
IMAGE_RESOURCE_DIR_STRING_U STRUCTLength1 dw ? ;字符串的长度NameString dw ? ;UNICODE字符串,由于字符串是不定长的,所以这里只能;用一个dw表示,实际上当长度为100的时候,这里的数据;是NameString dw 100 dup (?)
IMAGE_RESOURCE_DIR_STRING_U ENDS如果要得到ANSI类型的以0结尾的字符串,需要将NameString字段中包括的UNICODE字符串用WideCharToMultiByte函数转换一下,具体的方法读者可以参考后面的例子。
● OffsetToData字段
这个字段是一个指针,当它的最高位(位31)为1时,低位数据指向下一层目录块的起始地址,也就是一个IMAGE_RESOURCE_DIRECTORY结构,这种情况一般出现在第1层和第2层目录中;当字段的位31为0时,指针指向的是用来描述资源数据块情况的IMAGE_RESOURCE_DATA_ENTRY指针,这种情况出现在第3层目录中。
当将Name1字段和OffsetToData用做指针时需要注意两点,首先是不要忘记将最高位清除(使用7fffffffh来and一下);其次就是这两个指针是从资源块开始的地方算起的偏移量,也就是根目录的起始位置算起的偏移量。
注意:千万不要将这两个指针作为RVA来对待,否则会得到错误的地址。正确的计算方法是将指针的值加上资源块首地址,结果才是真正的地址。
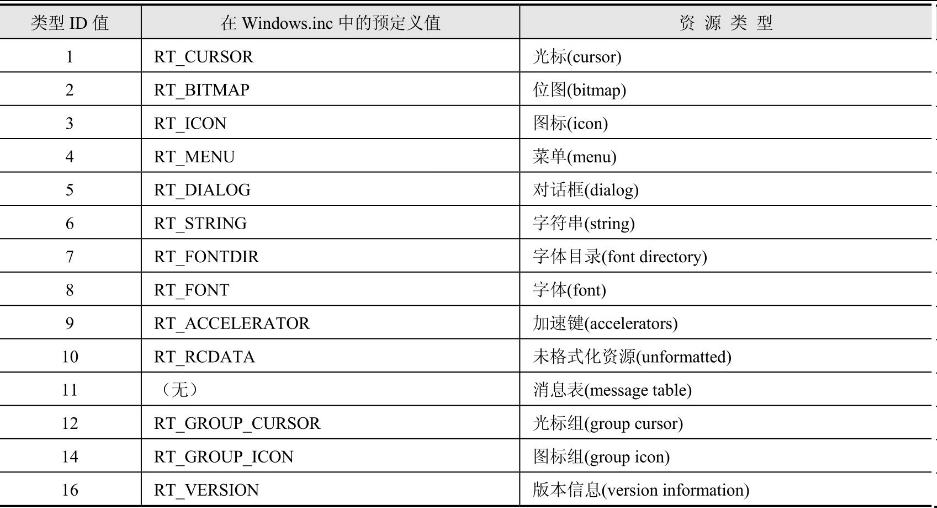
最后还需要说明的是,当IMAGE_RESOURCE_DIRECTORY_ENTRY用在第1层目录中的时候,它的Name1字段是作为资源类型来使用的。当资源类型以ID定义(最高位等于0),并且ID数值在1到16之间时,表示这是系统预定义的类型,ID与类型的对应关系请参考表17.6;如果资源类型是以ID定义的并且数值在16以上,表示这是一个自定义的类型。
表17.6 预定义的资源类型
3.资源数据入口
沿着资源目录树按照根目录→资源类型→资源ID的顺序到达第3层目录后,这一层目录的IMAGE_RESOURCE_DIRECTORY_ENTRY结构的OffsetToData字段指向的是一个IMAGE_RESOURCE_DATA_ENTRY结构(如图17.8中的E1到E5所示)。
IMAGE_RESOURCE_DATA_ENTRY结构的定义如下所示:
IMAGE_RESOURCE_DATA_ENTRY STRUCTOffsetToData dd ? ;资源数据的RVASize1 dd ? ;资源数据的长度CodePage dd ? ;代码页Reserved dd ? ;保留字段
IMAGE_RESOURCE_DATA_ENTRY ENDSIMAGE_RESOURCE_DATA_ENTRY结构描述了资源数据所处的位置和大小,换句话说,就是经过了这么多层结构的长途跋涉以后,终于得到了某一个资源的详细信息。
结构中的OffsetToData字段的值是指向资源数据的指针,奇怪的是,这个指针却是一个RVA值,而不是以资源块的起始地址为基址的,这是读者需要特别注意的地方。Size1字段的值是资源数据的大小。结构中的第3个字段是CodePage,这个字段的名称有些奇怪,因为当前资源的代码页已经在第3层目录中指明了,在这里再定义一次有重复之嫌,在实际的应用中,这个字段好像未被使用,因为随便找一个PE文件看看就会发现这里的值总是为0。
17.4.3 查看PE文件中的资源列表举例
本节中的例子遍历PE文件中的资源目录树并显示每个资源的详细信息,例子的源代码放在本书所附光盘的Chapter17\Resource目录中,同样,为了节省篇幅,界面代码沿用前面的Main.asm和Main.rc文件,下面是Main.asm中包括的_ProcessPeFile.asm文件的内容:
; _ProcessPeFile.asm ---- Resource例子的 PE文件处理模块
.const
szMsg byte '文件名: %s',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '资源所处的节:%s',0dh,0ah,0
szErrNoRes byte '这个文件中没有包含资源!',0
szLevel1 byte 0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '资源类型:%s',0dh,0ahbyte '------------------------------------------------',0dh,0ah,0
szLevel1byID byte '%d (自定义编号)',0
szLevel2byID byte ' ID: %d',0dh,0ah,0
szLevel2byName byte ' Name: %s',0dh,0ah,0
szResData byte ' 文件偏移:%08X (代码页=%04X, 长度%d字节)',0dh,0ah,0
szType byte '光标 ',0 ;1byte '位图 ',0 ;2byte '图标 ',0 ;3byte '菜单 ',0 ;4byte '对话框 ',0 ;5byte '字符串 ',0 ;6byte '字体目录 ',0 ;7byte '字体 ',0 ;8byte '加速键 ',0 ;9byte '未格式化资源',0 ;10byte '消息表 ',0 ;11byte '光标组 ',0 ;12byte '未知类型 ',0 ;13byte '图标组 ',0 ;14byte '未知类型 ',0 ;15byte '版本信息 ',0 ;16
.code
include _RvaToFileOffset.asm _ProcessRes proc _lpFile, _lpRes, _lpResDir, _dwLevel local @dwNextLevel, @szBuffer[1024]:byte local @szResName[256]:byte pushad mov eax, _dwLevel inc eax mov @dwNextLevel, eax ;检查资源目录表,得到资源目录项的数量mov esi, _lpResDir assume esi:ptr IMAGE_RESOURCE_DIRECTORY mov cx, [esi].NumberOfNamedEntries add cx, [esi].NumberOfIdEntries movzx ecx, cx add esi, sizeof IMAGE_RESOURCE_DIRECTORY assume esi:ptr IMAGE_RESOURCE_DIRECTORY_ENTRY ;循环处理每个资源目录项.while ecx > 0 push ecx mov ebx, [esi].OffsetToData .if ebx & 80000000hand ebx, 7fffffffhadd ebx, _lpRes .if _dwLevel == 1 ;第一层:资源类型mov eax, [esi].Name1 .if eax & 80000000h and eax, 7fffffffhadd eax, _lpRes movzx ecx, word ptr [eax] ;IMAGE_RESOURCE_DIR_STRING_U结构add eax, 2 mov edx, eax invoke WideCharToMultiByte, CP_ACP, WC_COMPOSITECHECK, \edx, ecx, addr @szResName, sizeof @szResName, \NULL, NULL lea eax, @szResName .else .if eax <= 10h dec eax mov ecx, sizeof szType mul ecx add eax, offset szType .else invoke wsprintf, addr @szResName, addr szLevel1byID, eax lea eax, @szResName .endif .endif invoke wsprintf, addr @szBuffer, addr szLevel1, eax ;第二层:资源ID(或名称).elseif _dwLevel == 2 mov edx, [esi].Name1 .if edx & 80000000h;资源以字符串方式命名and edx, 7fffffffh add edx, _lpRes ;IMAGE_RESOURCE_DIR_STRING_U结构movzx ecx, word ptr [edx]add edx, 2 invoke WideCharToMultiByte, CP_ACP, WC_COMPOSITECHECK, \edx, ecx, addr @szResName, sizeof @szResName, \NULL, NULL invoke wsprintf, addr @szBuffer, \addr szLevel2byName, addr @szResName .else ;资源以 ID 命名invoke wsprintf, addr @szBuffer, \addr szLevel2byID, edx .endif .else .break .endif invoke _AppendInfo, addr @szBuffer invoke _ProcessRes, _lpFile, _lpRes, ebx, @dwNextLevel ;不是资源目录则显示资源详细信息.else add ebx, _lpRes mov ecx, [esi].Name1 ;代码页assume ebx:ptr IMAGE_RESOURCE_DATA_ENTRY mov eax, [ebx].OffsetToData invoke _RVAToOffset, _lpFile, eax invoke wsprintf, addr @szBuffer, addr szResData, \eax, ecx, [ebx].Size1 invoke _AppendInfo, addr @szBuffer .endif add esi, sizeof IMAGE_RESOURCE_DIRECTORY_ENTRY pop ecx dec ecx .endw
_Ret:assume esi:nothing assume ebx:nothing popad ret
_ProcessRes endp _ProcessPeFile proc _lpFile, _lpPeHead, _dwSize local @szBuffer[1024]:byte, @szSectionName[16]:byte pushad mov esi, _lpPeHead assume esi:ptr IMAGE_NT_HEADERS ;检测是否存在资源mov eax, [esi].OptionalHeader.DataDirectory[8*2].VirtualAddress .if !eax invoke MessageBox, hWinMain, addr szErrNoRes, NULL, MB_OK jmp _Ret .endif push eax invoke _RVAToOffset, _lpFile, eax add eax, _lpFile mov esi, eax pop eax invoke _GetRVASection, _lpFile, eax invoke wsprintf, addr @szBuffer, addr szMsg, addr szFileName, eax invoke SetWindowText, hWinEdit, addr @szBuffer invoke _ProcessRes, _lpFile, esi, esi, 1
_Ret:assume esi:nothing popad ret
_ProcessPeFile endp
运行结果:

在_ProcessPeFile子程序中,程序首先从数据目录的第3项得到资源数据块的入口地址,并用它来调用_ProcessRes子程序,这个子程序将递归调用自己来处理所有资源目录树上的节点。
由于资源目录不同层次的含义是不同的,所以_ProcessRes子程序定义了一个_dwLevel参数,用来指定当前处理的目录所处的层次,在主程序中第一次调用_ProcessRes子程序的时候,这个参数被指定为1。在_ProcessRes中,_dwLevel的值被加1放到局部变量@dwNextLevel变量中,当需要继续处理下一层目录的时候,@dwNextLevel的值将被用在递归调用_ProcessRes子程序的参数中,同时传给子程序的参数中还包括了PE文件的起始指针、资源根目录的指针和需要处理的目录块的指针。
_ProcessRes子程序首先处理目录块中的第一个结构IMAGE_RESOURCE_DIRECTORY,将结构中的NumberOfNamedEntries字段和NumberOfIdEntries字段相加得到后续的目录项总数,并构造一个循环来处理这些目录项。
在循环体中,每次将处理一个IMAGE_RESOURCE_DIRECTORY_ENTRY结构,循环体的代码结构如下:
.if OffsetToData字段的位31=1(表明OffsetToData字段指向的是下一层的目录块).if当前是第1层(表明Name1字段代表的是资源类型).if Name1字段的位31=1Name1指向的是一个UNICODE字符串.elseName1中包含的是资源类型ID.endif.elseif当前是第2层(表明Name1字段代表的是资源名称).if Name1字段的位31=1Name1指向的是一个UNICODE字符串.elseName1中包含的是资源名称ID.endif.endif将层次加1继续递归处理OffsetToData所指的下一层目录块
.else(表明OffsetToData字段指向的是IMAGE_RESOURCE_DATA_ENTRY结构)(表明Name1字段代表的是资源的代码页)IMAGE_RESOURCE_DATA_ENTRY结构地址=OffsetToData字段资源RVA=IMAGE_RESOURCE_DATA_ENTRY.OffsetToData资源大小=IMAGE_RESOURCE_DATA_ENTRY.Size1
.endif
例子代码在每次处理一个目录项或者资源数据的时候,都将它们的名称或ID等信息显示出来。如果例子中的代码被移植到其他地方用来寻找资源的话,这些显示信息的语句就可以全部去掉了,因为这时程序的最终目的就是最后两句获取资源RVA和大小的指令。
17.5 重定位表
什么是重定位,代码又是在什么情况下才需要重定位呢?这个问题早在13.4.2节中就回答过了,那就是在32位代码中,涉及直接寻址的指令都是需要重定位的(而在DOS的16位代码中,只有涉及段操作的指令才是需要重定位的,对此感兴趣的读者可以参考相关的资料),虽然13.4.2节的例子中给出了一段不需要重定位的代码,但这段代码的精髓在于将所有的直接寻址指令用寄存器寻址方式代替,如果这种方法成为操作系统处理重定位问题的标准办法,那就相当于不存在直接寻址指令了,这在编程中带来的麻烦是不可想象的,所以那种能自身完成重定位的代码只能在小范围内使用。
对于操作系统来说,其任务就是在对可执行程序透明的情况下完成重定位操作,在现实中,重定位信息是在编译的时候由编译器生成并被保留在可执行文件中的,在程序被执行前由操作系统根据重定位信息修正代码,这样在开发程序的时候就不用考虑重定位问题了。
重定位信息在PE文件中被存放在重定位表中,本节要讨论的就是重定位表的结构和使用方法。
17.5.1 重定位表的结构
1.重定位所需的数据
在开始分析重定位表的结构之前需要了解两个问题:第一,对一条指令进行重定位需要哪些信息;第二,这些信息中哪些应该被保存在重定位表中。下面举例来说明这两个问题。
作为例子,现将13.4.2节中的那段代码搬回来:
:00400FFC 0000 ;dwVar变量
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 83C4FC add esp, FFFFFFFC
:00401006 A1FC0F4000 mov eax, dword ptr [00400FFC] ;mov eax,dwVar
:0040100B 8B45FC mov eax, dword ptr [ebp-04] ;mov eax,@dwLocal
:0040100E 8B4508 mov eax, dword ptr [ebp+08] ;mov eax,_dwParam
:00401011 C9 leave
:00401012 C20400 ret 0004
:00401015 68D2040000 push 000004D2
:0040101A E8E1FFFFFF call 00401000 ;invoke Proc1,1234其中地址为00401006h处的mov eax,dword ptr [00400ffc]就是一句需要重定位的指令,当整个程序的起始地址位于00400000h处的时候,这句代码是正确的,假如将它移到00500000h处的时候,这句指令必须变成mov eax,dword ptr [00500ffc]才是正确的。这就意味着它需要重定位。
让我们看看需要改变的是什么,重定位前的指令机器码是A1 FC 0F 40 00,而重定位后将是A1 FC 0F 50 00,也就是说00401007h开始的双字00400ffch变成了00500ffch,改变的正是起始地址的差值(00500000h-00400000h)=00100000h。
所以,重定位的算法可以描述为:将直接寻址指令中的双字地址加上模块实际装入地址与模块建议装入地址之差。为了进行这个运算,需要有3个数据,首先是需要修正的机器码地址;其次是模块的建议装入地址;最后是模块的实际装入地址。这就是第一个问题的答案。
在这3个数据中,模块的建议装入地址已经在PE文件头中定义了,而模块的实际装入地址是Windows装载器确定的,到装载文件的时候自然会知道,所以第二个问题的答案很简单,那就是应该被保存在重定位表中的仅仅是需要修正的代码的地址。
事实上正是如此,PE文件的重定位表中保存的就是一大堆需要修正的代码的地址。
2.重定位表的位置
重定位表一般会被单独存放在一个可丢弃的以“.reloc”命名的节中,但是和资源一样,这并不是必然的,因为重定位表放在其他节中也是合法的,唯一可以肯定的是,如果重定位表存在的话,它的地址肯定可以在PE文件头中的数据目录中找到。如表17.4所示,重定位表的位置和大小可以从数据目录中的第6个IMAGE_DATA_DIRECTORY结构中获取。
3.重定位表的结构
虽然重定位表中的有用数据是那些需要重定位机器码的地址指针,但为了节省空间,PE文件对存放的方式做了一些优化。
在正常的情况下,每个32位的指针占用4个字节,如果有n个重定位项,那么重定位表的总大小是4×n字节大小。
直接寻址指令在程序中还是比较多的,在比较靠近的重定位表项中,32位指针的高位地址总是相同的,如果把这些相近表项的高位地址统一表示,那么就可以省略一部分的空间,当按照一个内存页来分割时,在一个页面中寻址需要的指针位数是12位(一页等于4096字节,等于2的12次方),假如将这12位凑齐16位放入一个字类型的数据中,并用一个附加的双字来表示页的起始指针,另一个双字来表示本页中重定位项数的话,那么占用的总空间会是4+4+2×n 字节大小,计算一下就可以发现,当某个内存页中的重定位项多于4项的时候,后一种方法的占用空间就会比前面的方法要小。
PE文件中重定位表的组织方法就是采用类似的按页分割的方法,从PE文件头的数据目录中得到重定位表的地址后,这个地址指向的就是顺序排列在一起的很多重定位块,每一块用来描述一个内存页中的所有重定位项。
每个重定位块以一个IMAGE_BASE_RELOCATION结构开头,后面跟着在本页面中使用的所有重定位项,每个重定位项占用16位的地址(也就是一个word),结构的定义是这样的:
IMAGE_BASE_RELOCATION STRUCTVirtualAddress dd ? ;重定位内存页的起始RVASizeOfBlock dd ? ;重定位块的长度
IMAGE_BASE_RELOCATION ENDSVirtualAddress字段是当前页面起始地址的RVA值,本块中所有重定位项中的12位地址加上这个起始地址后就得到了真正的RVA值。SizeOfBlock字段定义的是当前重定位块的大小,从这个字段的值可以算出块中重定位项的数量,由于SizeOfBlock=4+4+2×n,也就是sizeof IMAGE_BASE_RELOCATION+2×n,所以重定位项的数量 n 就等于(SizeOfBlock-sizeof IMAGE_BASE_RELOCATION)÷2。
IMAGE_BASE_RELOCATION结构后面跟着的n个字就是重定位项,每个重定位项的16位数据位中的低12位就是需要重定位的数据在页面中的地址,剩下的高4位也没有被浪费,它们被用来描述当前重定位项的种类,其定义如表17.7所示。
表17.7 重定位项高4位的含义
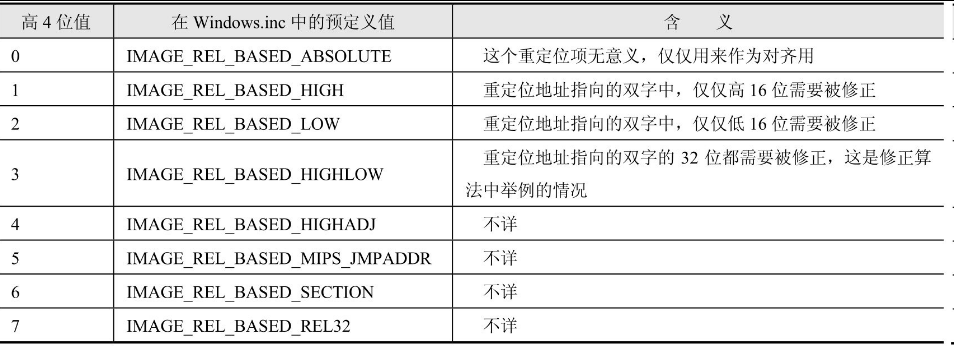
虽然高4位定义了多种重定位项的属性,但实际上在PE文件中只能看到0和3这两种情况。
所有的重定位块最终以一个VirtualAddress字段为0的IMAGE_BASE_RELOCATION结构作为结束,读者现在一定明白了为什么可执行文件的代码总是从装入地址的1000h处开始定义的了(比如,装入00400000h处的.exe文件的代码总是从00401000h开始,而装入10000000h处的.dll文件的代码总是从10001000h处开始),要是代码从装入地址处开始定义,那么第一页代码的重定位块的VirtualAddress字段就会是0,这就和重定位块的结束方式冲突了。
下面的例子举出了一个重定位表的实际情况,假设模块被装入00400000h处:
重定位表偏移 数据 说明
0000h 00001000h 第一个块:页面起始地址是00401000h
0004h 00000010h 重定位块长度是10h
0008h 3012h 16位重定位项,重定位位置:00401012h
000ah 3040h 16位重定位项,重定位位置:00401040h
000ch 306fh 16位重定位项,重定位位置:0040106fh
000eh 0000h 用于对齐的空白数据
0010h 00002000h 第二个块:页面起始地址是00402000h
0014h 0000000ch 重定位块长度是0ch
0018h 3080h 16位重定位项,重定位位置:00402080h
001ah 30f0h 16位重定位项,重定位位置:004020f0h
001ch 00000000h 重定位数据块结束17.5.2 查看PE文件的重定位表举例
本节中用一个简单的例子来说明重定位表的操作,所有的源代码在本书所附光盘的Chapter17\Reloc目录中,同样,例子的界面文件使用前面的Main.rc和Main.asm文件,这里仅仅列出包含处理重定位表的子程序文件_ProcessPeFile.asm:
; Reloc例子的 PE文件处理模块
.const
szMsg byte '文件名: %s',0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '重定位表所处的节:%s',0dh,0ah,0
szMsgRelocBlk byte 0dh,0ahbyte '------------------------------------------------',0dh,0ahbyte '重定位基地址: %08X',0dh,0ahbyte '重定位项数量: %d',0dh,0ahbyte '------------------------------------------------',0dh,0ah,0byte '需要重定位的地址列表',0dh,0ahbyte '------------------------------------------------',0dh,0ah,0
szMsgReloc byte '%08X ',0
szCrLf byte 0dh,0ah,0
szErrNoReloc byte '这个文件中不包括重定位信息!',0.code
include _RvaToFileOffset.asm
_ProcessPeFile proc _lpFile, _lpPeHead, _dwSize local @szBuffer[1024]:byte, @szSectionName[16]:byte pushad mov esi, _lpPeHead assume esi:ptr IMAGE_NT_HEADERS ;根据 IMAGE_DIRECTORY_ENTRY_BASERELOC 目录表找到重定位表位置mov eax, [esi].OptionalHeader.DataDirectory[8*5].VirtualAddress .if !eax invoke MessageBox, hWinMain, addr szErrNoReloc, NULL, MB_OK jmp _Ret .endif push eax invoke _RVAToOffset, _lpFile, eax add eax, _lpFile mov esi, eax pop eax invoke _GetRVASection, _lpFile, eax invoke wsprintf, addr @szBuffer, addr szMsg, addr szFileName, eax invoke SetWindowText, hWinEdit, addr @szBuffer assume esi:ptr IMAGE_BASE_RELOCATION ;循环处理每个重定位块.while [esi].VirtualAddress cld lodsd ;eax = [esi].VirtualAddressmov ebx, eax lodsd ;eax = [esi].SizeOfBlocksub eax, sizeof IMAGE_BASE_RELOCATION shr eax, 1 push eax ;eax = 重定位项数量invoke wsprintf, addr @szBuffer, addr szMsgRelocBlk, ebx, eax invoke _AppendInfo, addr @szBuffer pop ecx .repeat push ecx lodsw mov cx, ax and cx, 0f000h ;仅处理 IMAGE_REL_BASED_HIGHLOW 类型的重定位项.if cx == 03000h and ax, 0fffh movzx eax, ax add eax, ebx .else mov eax, -1 .endif invoke wsprintf, addr @szBuffer, addr szMsgReloc, eax inc edi .if edi == 4 ;每显示4个项目换行invoke lstrcat, addr @szBuffer, addr szCrLf xor edi, edi .endif invoke _AppendInfo, addr @szBuffer pop ecx .untilcxz .if edi invoke _AppendInfo, addr szCrLf .endif .endw
_Ret:assume esi:nothing popad ret
_ProcessPeFile endp 17.6 应用实例
本章的前5节介绍了PE文件的结构,所举的例子只涉及对PE文件的静态分析,但在实际的应用中还有很多其他方面的内容,比如,对PE文件加密、压缩,编写杀毒软件等都涉及修改及重组PE文件,另外,像API Hook,PE文件的内存映像Dump等应用则涉及分析内存中的PE映像。
本节将用另外的两个例子来进一步说明这些方面的应用,17.6.1节将演示如何从内存中动态获取某个API的地址;17.6.2节将演示如何在PE文件上添加一段可执行代码。
17.6.1 动态获取API入口地址
学习这个例子是为了加深对PE文件到内存的映射和使用导出表这两方面的知识的理解。
在Win32环境下编程,不使用API几乎是不可能的事情,一般情况下,在代码中使用API不外乎两种办法:第一是编译链接的时候使用导入库,那么生成的PE文件中就会包含导入表,这样程序执行时会由Windows装载器根据导入表中的信息来修正API调用语句中的地址;第二种方法是使用LoadLibrary函数动态装入某个DLL模块,并使用GetProcAddress函数从被装入的模块中获取API函数的地址。
假如有一段代码由于特殊的原因无法(或者实现的难度很大)在PE文件中使用导入表,比如,17.6.2节中被加到其他PE文件上的代码或者在第13章中介绍的远程线程中运行的代码就是如此,在这种代码中,如何使用API函数呢?有人可能会说,那就用第二种办法好了!听起来不错,但这里有一个“先有鸡还是先有蛋”的问题,固然所有的API函数都可以用LoadLibrary函数和GetProcAddress函数配合来动态获取,但这两个函数本身也是API,又怎样首先得到它们的地址呢?
本节的内容讲述如何用一种变通的办法来解决这个问题。
1.原理
在DOS环境下,一个可执行文件既可以用INT 21h/4ch来结束程序,也可以用一个Ret指令来结束程序。实际上,在Win32下也可以用这种方法来结束程序,虽然大部分的Win32程序都使用ExitProcess函数来终止执行,但是使用Ret指令确实也是有效的。
如图17.9所示,当父进程要创建一个子进程的时候,它会调用Kernel32.dll中的CreateProcess函数,CreateProcess函数在完成装载应用程序后,会将一个返回地址压入堆栈并转而执行应用程序,如果应用程序用ExitProcess函数来终止,那么这个返回地址没有什么用途,但如果应用程序使用Ret指令的话,程序就会返回CreateProcess函数设定的地址。也就是说,应用程序的主程序可以看做是被Windows调用的一个子程序。
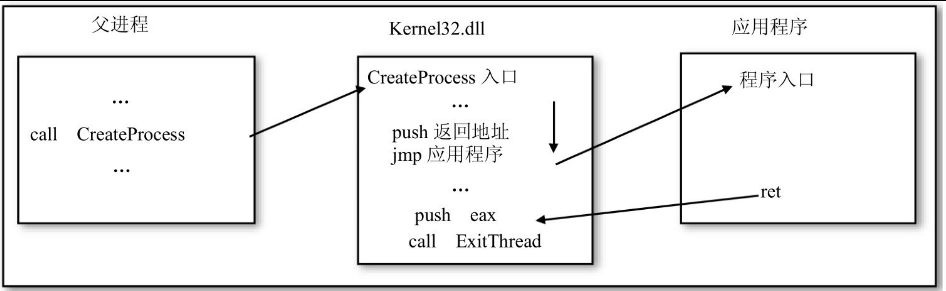
图17.9 Win32可执行文件退出的示意图
那么Ret指令返回到的地址上究竟有什么指令呢?用Soft-ICE看看就会发现,它包含一句push eax指令和一句call ExitThread,也就是说,假如用Ret指令返回的话,Windows会替程序去调用ExitThread函数,如果这是进程的最后一个线程的话,ExitThread函数又会自动去调用ExitProcess,这样程序就会被终止执行。
从这个过程可以得到一个很重要的数据,那就是堆栈中的返回地址,这个地址只要在程序入口的地方用[esp]就可以将它读出,说它重要是因为它位于Kernel32.dll模块中,而LoadLibrary和GetProcAddress函数正是处于Kernel32.dll模块中,换句话说就是,我们得到的地址和这两个函数近在咫尺,完全可以从这个地址经过某种算法来找到这两个函数的入口地址,得到这两个函数的入口地址以后,什么问题都解决了。
结合本章前面内容中提到过的两个事实,可以确定这种想法是可行的。
首先,PE文件被装入内存后(包括Kernel32.dll文件),除了一些可丢弃的节如重定位节以外,其他的内容都会被装入内存,这样获取导出函数地址所需的PE文件头、导出表等数据都存在于内存中;其次,PE文件被装入内存时是按64k对齐的,只要从Ret指令返回的地址按照对齐边界以64k为单位向低地址搜寻,就必然可以找到Kernel32.dll文件的文件头位置。
好了,有了Kernel32.dll的基址,接下来的事情就是按照17.3.1节的第4点所列的过程去操作了!
2.例子
例子演示了上面所设想的功能,全部的源代码包含在本书所附光盘的Chapter17\NoImport目录中,主程序NoImport.asm的内容如下:
; NoImport.asm ----- 以从内存中动态获取的办法使用 API
; ------------------------------------------------------------------
; 使用 nmake 或下列命令进行编译和链接:
; ml /c /coff NoImport.asm
; Link /subsystem:windows NoImport.com
.386
.model flat,stdcall
option casemap:none include c:/masm32/include/windows.inc _ProtoGetProcAddress typedef proto :dword, :dword
_ProtoLoadLibrary typedef proto :dword
_ProtoMessageBox typedef proto :dword, :dword, :dword
_ApiGetProcAddress typedef ptr _ProtoGetProcAddress
_ApiLoadLibrary typedef ptr _ProtoLoadLibrary
_ApiMessageBox typedef ptr _ProtoMessageBox ; 数据段
.data?
hDllKernel32 dword ?
hDllUser32 dword ?
_GetProcAddress _ApiGetProcAddress ?
_LoadLibrary _ApiLoadLibrary ?
_MessageBox _ApiMessageBox ?.const
szLoadLibrary byte 'LoadLibraryA',0
szGetProcAddress byte 'GetProcAddress',0
szUser32 byte 'user32',0
szMessageBox byte 'MessageBoxA',0
szCaption byte 'A MessageBox !',0
szText byte 'Hello, World !',0; 代码段
.code
include _GetKernel.asm
start:;********************************************************************; 从堆栈中的 Ret 地址转换 Kernel32.dll 的基址,并在 Kernel32.dll; 的导出表中查找 GetProcAddress 函数的入口地址;********************************************************************invoke _GetKernelBase, [esp].if eax mov hDllKernel32, eax invoke _GetApi, hDllKernel32, addr szGetProcAddress mov _GetProcAddress, eax .endif ;********************************************************************; 用得到的 GetProcAddress 函数得到 LoadLibrary 函数地址并装入其他 Dll;********************************************************************.if _GetProcAddress invoke _GetProcAddress, hDllKernel32, addr szLoadLibrary mov _LoadLibrary, eax .if eax invoke _LoadLibrary, addr szUser32 mov hDllUser32, eax invoke _GetProcAddress, hDllUser32, addr szMessageBox mov _MessageBox, eax .endif .endif .if _MessageBox invoke _MessageBox, NULL, offset szText, offset szCaption, MB_OK .endif ret
end start
这个程序的主要功能是用前面描述的方法获取Kernel32.dll的基址,并扫描导出表得到GetProcAddress函数的地址,然后调用这个函数得到LoadLibrary函数的地址。获得这两个关键函数的地址后,程序使用LoadLibrary函数装入User32.dll并获取MessageBox函数的地址,在显示了一个消息框以后用Ret指令结束程序。
如果用第17章的查看导入表的例子程序去查看这个NoImport.exe文件,就可以发现文件中没有导入表部分。
由于获取Kernel32.dll基址和GetProcAddress入口地址的功能在17.6.2节的例子中还要用到,在本例中将它们分离出来放在_GetKernel.asm文件中,并在主程序中用include伪指令将它包含到程序中,_GetKernel.asm文件的内容如下:
; 公用模块:_GetKernel.asm
; 根据程序被调用的时候堆栈中有个用于 Ret 的地址指向 Kernel32.dll
; 而从内存中扫描并获取 Kernel32.dll 的基址
;--------------------------------------------------------------------
; 错误 Handler
_SEHHandler proc C _lpExceptionRecord, _lpSEH, _lpContext, _lpDispatcherContext pushad mov esi, _lpExceptionRecord mov edi, _lpContext assume esi:ptr EXCEPTION_RECORD, edi:ptr CONTEXT mov eax, _lpSEH push [eax + 0ch]pop [edi].regEbp push [eax + 8]pop [edi].regEip push eax pop [edi].regEsp assume esi:nothing, edi:nothing popad mov eax, ExceptionContinueExecution ret
_SEHHandler endp ; 在内存中扫描 Kernel32.dll 的基址
_GetKernelBase proc _dwKernelRet local @dwReturn pushad mov @dwReturn, 0 ;重定位call @F
@@:pop ebx sub ebx, offset @B ;创建用于错误处理的 SEH 结构assume fs:nothing push ebp lea eax, [ebx + offset _PageError]push eax lea eax, [ebx + offset _SEHHandler]push eax push fs:[0]mov fs:[0], esp ;查找 Kernel32.dll 的基地址mov edi, _dwKernelRet and edi, 0ffff0000h .while TRUE .if word ptr [edi] == IMAGE_DOS_SIGNATURE mov esi, edi add esi, [esi+003ch].if word ptr [esi] == IMAGE_NT_SIGNATURE mov @dwReturn, edi .break .endif .endif _PageError:sub edi, 010000h.break .if edi < 070000000h .endw pop fs:[0]add esp, 0ch popad mov eax, @dwReturn ret
_GetKernelBase endp ; 从内存中模块的导出表中获取某个 API 的入口地址
_GetApi proc _hModule, _lpszApi local @dwReturn, @dwStringLength pushad mov @dwReturn, 0 ;重定位call @F
@@:pop ebx sub ebx, offset @B ;创建用于错误处理的 SEH 结构assume fs:nothing push ebp lea eax, [ebx + offset _Error]push eax lea eax, [ebx + offset _SEHHandler]push eax push fs:[0]mov fs:[0], esp ;计算 API 字符串的长度(带尾部的0)mov edi, _lpszApi mov ecx, -1 xor al, al cld repnz scasb mov ecx, edi sub ecx, _lpszApi mov @dwStringLength, ecx ;从 PE 文件头的数据目录获取导出表地址mov esi, _hModule add esi, [esi + 3ch]assume esi:ptr IMAGE_NT_HEADERS mov esi, [esi].OptionalHeader.DataDirectory.VirtualAddress add esi, _hModule assume esi:ptr IMAGE_EXPORT_DIRECTORY ;查找符合名称的导出函数名mov ebx, [esi].AddressOfNames add ebx, _hModule xor edx, edx .repeat push esi mov edi, [ebx] add edi, _hModule mov esi, _lpszApi mov ecx, @dwStringLength repz cmpsb .if ZERO?pop esi jmp @F .endif pop esi add ebx, 4 inc edx .until edx >= [esi].NumberOfNames jmp _Error
@@:;API名称索引 --> 序号索引 --> 地址索引sub ebx, [esi].AddressOfNames sub ebx, _hModule shr ebx, 1 add ebx, [esi].AddressOfNameOrdinals add ebx, _hModule movzx eax, word ptr [ebx]shl eax, 2 add eax, [esi].AddressOfFunctions add eax, _hModule ;从地址表得到导出函数地址mov eax, [eax]add eax, _hModule mov @dwReturn, eax
_Error:pop fs:[0]add esp, 0ch assume esi:nothing popad mov eax, @dwReturn ret
_GetApi endp
文件中的_GetKernelBase子程序的参数是主程序从堆栈中得到的返回地址,程序首先设置一个SEH异常处理子程序,以免在搜寻内存的过程中访问到无效的页面后出错;接下来将参数中传递过来的目标地址按64K对齐(与0ffff0000h进行and操作);然后以每次一个页的间隔在内存中寻找DOS MZ文件头标识和PE文件头标识,如果找到的话,表示这个页的起始地址就是Kernel32.dll模块的基址。
_GetApi子程序从指定的PE内存映像中扫描导出表并获取某个函数的入口地址,这个子程序的结构完全是按照17.3.1节的第4点内容写的,读者可以对比分析一下。另外,这两个子程序是按照能够自定位的方式写的(还记得13.4.2节中的call/pop/sub指令组合吗?),这样就可以将它们使用在任何地方。
当调用_GetApi子程序的时候,传递过来的API名称中不要忘了最后的“A”或“W”字符,比如LoadLibrary函数和MessageBox函数的真实函数名称根据版本的不同分别是“LoadLibraryA”,“MessageBoxA”或者“LoadLibraryW”和“MessageBoxW”,如果仅仅将“LoadLibrary”字符串传递过来的话,在导出表中是找不到这个函数的。
17.6.2 在PE文件上添加执行代码
本例将演示如何在PE文件上添加一段可执行代码,并且让这段代码在原来的代码之前被执行,经过修改的目标PE文件被运行后,将首先弹出一个带“Yes”和“No”的消息框并提示“一定要运行这个程序吗?”,如果用户选择“Yes”的话,原文件被运行,否则程序直接退出。
1.原理
根据前面对PE文件各部分进行的分析,不难写出在PE文件上添加代码所必需的几个步骤,如下所示:
● 将添加的代码写到目标PE文件中,这段代码既可以插入原代码所处的节的空隙中(由于每个节保存在文件中时是按照FileAlignment的值对齐的,所以节的最后必然会有一些空余的空间),也可以通过添加一个新的节来附在原文件的尾部。
● PE文件原来的入口指针必须被保存在添加的代码中,这样,这段代码执行完以后可以转移到原始文件处执行。
● PE文件头中的入口指针需要被修改,指向新添加代码中的入口地址。
● PE文件头中的一些值需要根据情况做相应的修正,以符合修改后PE文件的情况。
另外,有一些操作是应该避免的,因为它们是无法实现的,或者实现它们的复杂性远远超过它们带来的好处,这些操作是:
● 如果节的空隙不足以插入代码的话,应该在文件尾新建一个节而不是去扩大原来的代码节并将它后面的其他节后移,因为程序无法得知整个PE文件中有多少个RVA值会指向这些被移动位置的节,修正所有这些RVA值几乎是不可能的。
● 如果附加的代码中要用到API函数的话,不要尝试在原始目标文件的导入表中添加导入函数名称,因为这样将涉及在目标PE文件的导入表中插入新的模块名和函数名,其结果同样是造成导入表的一些项目被移动位置,修正指向这些项目的RVA同样是很难实现的。
2.例子
全部的源程序包含在本书所附光盘的Chapter17\AddCode目录中,为了节省篇幅,界面文件同样使用17.1节中的Main.asm和Main.rc文件,需要修改的只是由Main.asm文件所包含的_ProcessPeFile.asm文件,其内容如下:
; _ProcessPeFile.asm
; AddCode 例子的功能模块 在PE文件上添加可执行代码
; ------------------------------------------------------------------
.const
szErrCreate byte '创建文件错误!',0dh,0ah,0
szErrNoRoom byte '程序中没有多余的空间可供加入代码!',0dh,0ah,0
szMySection byte '.adata',0
szExt byte '_new.exe',0
szSuccess byte '在文件后附加代码成功,新文件:',0dh,0ahbyte '%s',0dh,0ah,0
.code
include _AddCode.asm
;计算按照指定值对齐后的数值
_Align proc _dwSize, _dwAlign push edx mov eax, _dwSize xor edx, edx div _dwAlign .if edx inc eax .endif mul _dwAlign pop edx ret
_Align endp _ProcessPeFile proc _lpFile, _lpPeHead, _dwSize local @szNewFile[MAX_PATH]:byte local @hFile, @dwTemp, @dwEntry, @lpMemory local @dwAddCodeBase, @dwAddCodeFile local @szBuffer[256]:byte pushad ;(Part 1)准备工作:1-建立新文件,2-打开文件invoke lstrcpy, addr @szNewFile, addr szFileName invoke lstrlen, addr @szNewFile lea ecx, @szNewFilemov byte ptr [ecx+eax-4], 0invoke lstrcat, addr @szNewFile, addr szExt invoke CopyFile, addr szFileName, addr @szNewFile, FALSE invoke CreateFile, addr @szNewFile, GENERIC_READ or GENERIC_WRITE, FILE_SHARE_READ or \FILE_SHARE_WRITE, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_ARCHIVE, NULL .if eax == INVALID_HANDLE_VALUE invoke SetWindowText, hWinEdit, addr szErrCreate jmp _Ret .endif mov @hFile, eax ;(Part 2)进行一些准备工作和检测工作; esi --> 原PeHead,edi --> 新的PeHead; edx --> 最后一个节表,ebx --> 新加的节表mov esi, _lpPeHead assume esi:ptr IMAGE_NT_HEADERS, edi:ptr IMAGE_NT_HEADERS invoke GlobalAlloc, GPTR, [esi].OptionalHeader.SizeOfHeaders mov @lpMemory, eax mov edi, eax invoke RtlMoveMemory, edi, _lpFile, [esi].OptionalHeader.SizeOfHeaders add edi, esi sub edi, _lpFile movzx eax, [esi].FileHeader.NumberOfSections dec eax mov ecx, sizeof IMAGE_SECTION_HEADER mul ecx mov edx, edi add edx, eax add edx, sizeof IMAGE_NT_HEADERS mov ebx, edx add ebx, sizeof IMAGE_SECTION_HEADER assume ebx:ptr IMAGE_SECTION_HEADER, edx:ptr IMAGE_SECTION_HEADER ;(Part 2.1)检查是否有空闲的位置可供插入节表pushad mov edi, ebx xor eax, eax mov ecx, IMAGE_SECTION_HEADER repz scasb popad .if !ZERO?;(Part 3.1)如果没有新的节表空间的话,则查看现存代码节的最后;是否存在足够的全零空间,如果存在则在此处加入代码xor eax, eax mov ebx, edi add ebx, sizeof IMAGE_NT_HEADERS .while ax <= [esi].FileHeader.NumberOfSections mov ecx, [ebx].SizeOfRawData .if ecx && ([ebx].Characteristics & IMAGE_SCN_MEM_EXECUTE)sub ecx, [ebx].Misc.VirtualSize .if ecx > offset APPEND_CODE_END - offset APPEND_CODE or [ebx].Characteristics, IMAGE_SCN_MEM_READ or IMAGE_SCN_MEM_WRITE jmp @F .endif .endif add ebx, IMAGE_SECTION_HEADER inc ax .endw invoke CloseHandle, @hFile invoke DeleteFile, addr @szNewFile invoke SetWindowText, hWinEdit, addr szErrNoRoom jmp _Ret @@:;将新增代码加入代码节的空隙中mov eax, [ebx].VirtualAddress add eax, [ebx].Misc.VirtualSize mov @dwAddCodeBase, eax mov eax, [ebx].PointerToRawData add eax, [ebx].Misc.VirtualSize mov @dwAddCodeFile, eax add [ebx].Misc.VirtualSize, offset APPEND_CODE_END - offset APPEND_CODE invoke SetFilePointer, @hFile, @dwAddCodeFile, NULL, FILE_BEGIN mov ecx, offset APPEND_CODE_END - offset APPEND_CODE invoke WriteFile, @hFile, offset APPEND_CODE, ecx, addr @dwTemp, NULL .else ;(Part 3.2)如果有新的节表空间的话,加入一个新的节inc [edi].FileHeader.NumberOfSections push edx @@:mov eax, [edx].PointerToRawData ;当最后一个节是未初始化数据时,PointerToRawData和SizeOfRawData等于0;这时应该取前一个节的PointerToRawData和SizeOfRawData数据.if !eax sub edx, sizeof IMAGE_SECTION_HEADER jmp @B .endif add eax, [edx].SizeOfRawData pop edx mov [ebx].PointerToRawData, eax mov ecx, offset APPEND_CODE_END - offset APPEND_CODE invoke _Align, ecx, [esi].OptionalHeader.FileAlignment mov [ebx].SizeOfRawData, eax invoke _Align, ecx, [esi].OptionalHeader.SectionAlignment add [edi].OptionalHeader.SizeOfCode, eax ;修正SizeOfCodeadd [edi].OptionalHeader.SizeOfImage, eax ;修正SizeOfImageinvoke _Align, [edx].Misc.VirtualSize, [esi].OptionalHeader.SectionAlignment add eax, [edx].VirtualAddress mov [ebx].VirtualAddress, eax mov [ebx].Misc.VirtualSize, offset APPEND_CODE_END - offset APPEND_CODE mov [ebx].Characteristics, IMAGE_SCN_CNT_CODE \or IMAGE_SCN_MEM_EXECUTE or IMAGE_SCN_MEM_READ or IMAGE_SCN_MEM_WRITE invoke lstrcpy, addr [ebx].Name1, addr szMySection ;将新增代码作为一个新的节写到文件尾部invoke SetFilePointer, @hFile, [ebx].PointerToRawData,NULL, FILE_BEGIN invoke WriteFile, @hFile, offset APPEND_CODE, [ebx].Misc.VirtualSize, \addr @dwTemp, NULL mov eax, [ebx].PointerToRawData add eax, [ebx].SizeOfRawData invoke SetFilePointer, @hFile, eax, NULL, FILE_BEGIN invoke SetEndOfFile, @hFile push [ebx].VirtualAddress ;eax = 新加代码的基地址pop @dwAddCodeBase push [ebx].PointerToRawData pop @dwAddCodeFile .endif ;(Part 4)修正文件入口指针并写入新的文件头mov eax, @dwAddCodeBase add eax, (offset _NewEntry - offset APPEND_CODE)mov [edi].OptionalHeader.AddressOfEntryPoint, eax invoke SetFilePointer, @hFile, 0, NULL, FILE_BEGIN invoke WriteFile, @hFile, @lpMemory, [esi].OptionalHeader.SizeOfHeaders, \addr @dwTemp, NULL ;(Part 5)修正新加代码中的 Jmp oldEntry 指令push [esi].OptionalHeader.AddressOfEntryPoint pop @dwEntry mov eax, @dwAddCodeBase add eax, (offset _ToOldEntry - offset APPEND_CODE + 5)sub @dwEntry, eax mov ecx, @dwAddCodeFile add ecx,(offset _dwOldEntry - offset APPEND_CODE)invoke SetFilePointer, @hFile, ecx, NULL, FILE_BEGIN invoke WriteFile, @hFile, addr @dwEntry, 4, addr @dwTemp, NULL ;(Part 6)关闭文件invoke GlobalFree, @lpMemory invoke CloseHandle, @hFile invoke wsprintf, addr @szBuffer, addr szSuccess, addr @szNewFile invoke SetWindowText, hWinEdit, addr @szBuffer
_Ret:assume esi:nothing popad ret
_ProcessPeFile endp 首先来看一下AddCode.asm中要被添加到其他可执行文件中的代码。这段代码是按照能够自身重定位的方式写的,而且必须按照这种格式书写,因为当它被添加到目标PE文件后,对于不同的PE文件所处的位置肯定是不同的,不进行重定位处理必然无法正常运行。
附加代码实现的功能和17.6.1节的NoImport例子大致相同,也是首先使用17.6.1节中的两个子程序获取Kernel32.dll模块的基址和GetProcAddress函数的入口地址,并由此最后得到MessageBox函数的入口地址以便显示消息框。
程序最后的_ToOldEntry标号处的数据0e9h是jmp xxxxxxxx的机器码的第一个字节,它与下面的_dwOldEntry标号处的双字一起组成整个jmp指令,这条jmp指令将在主程序中根据具体情况修正。
好!现在来分析一下_ProcessPeFile.asm文件中的代码。请读者注意源代码中的注释,注释将代码分为从Part1到Part6共6个部分。
Part 1从原始PE文件拷贝一个名为“原始文件名_new.exe”的文件,这个文件将被添加上可执行代码,原来的“原始文件名.exe”文件则不会被改动。当文件成功拷贝后,程序将打开拷贝生成的新文件以便进行修改。其中用到了CopyFile和CreateFile函数。
Part 2的开始部分,程序使用GlobalAlloc函数分配一个等于目标PE文件的文件头大小的内存块,并使用RtlMoveMemory将PE文件头拷贝到这个内存块中,所有对PE文件头的修改操作都是在这个内存块中完成的,这个内存块的内容最终将被写到“原始文件名_new.exe”文件中。
完成拷贝工作以后,程序计算两个指针以备后用:指向节表最后一项的指针和指向节表尾部的指针,这两个指针可以从节表的数量和节表的长度计算而来,节表的数量是从PE文件头中的FileHeader.NumberOfSections字段获取的。
正如本节的开始所述,新增的代码既可以插入原代码所处的节的空隙中,也可以通过添加一个新的节来附在原文件的尾部。为了增加成功的机会,应该对这两种情况都予以考虑,于是程序在Part 2.1中对节表的尾部进行全零数据的扫描,如果存在一段全零的位置可供放入一个新的节表,那么采取增加新节的办法(Part 3.2),否则采用在代码节的空隙中插入的办法(Part 3.1)。
如下代码所示,Part3.1中对所有节表进行循环扫描,以便于找到代码节并检测节的空隙是否可以容纳新增的代码,程序首先判断SizeOfRawData是否为0,这个数值为0说明这个节是包含未初始化数据的节,不能用于插入代码,如果SizeOfRawData大于0的话,则检测Characteristics字段查看当前节是否为代码节(包含IMAGE_SCN_MEM_EXECUTE标志)。
; ebx为某个节表的起始地址
mov ecx,[ebx].SizeOfRawData
.if ecx && ([ebx].Characteristics & IMAGE_SCN_MEM_EXECUTE)sub ecx,[ebx].Misc.VirtualSize.if ecx > offset APPEND_CODE_END-offset APPEND_CODEor [ebx].Characteristics,\IMAGE_SCN_MEM_READ or IMAGE_SCN_MEM_WRITEadd [ebx].Misc.VirtualSize,\offset APPEND_CODE_END-offset APPEND_CODEjmp 将附加代码写入节的空隙中.endif
.endif通过检测以后,程序计算空隙的大小(SizeOfRawData和Misc.VirtualSize之差)是否大于插入代码的长度,如果空隙足够大的话,则进行插入操作。在插入代码的同时,这个节的属性中必须被加上IMAGE_SCN_MEM_READ和IMAGE_SCN_MEM_WRITE标志,因为附加代码中使用了对被加入部分进行写操作的指令。另外,VirtualSize字段中的实际数据大小也需要被修正。
上面的程序只考虑了在代码节中插入的情况,要是代码节中的空隙大小不够,那么程序就退出了。实际上,程序也可以在其他的节中插入代码,只要将节的属性同时也加上IMAGE_SCN_MEM_EXECUTE标志就可以了。要是进一步将程序完善的话,当单个节的空隙大小不够的时候,也可以将附加代码分块插入多个节中(CIH病毒就是这么做的),不过这时附加代码中就必须考虑在执行前将代码重新拼装到一起这个步骤了。
当节表后面有多余空间的时候,程序采用增加新节区的办法来添加代码,这一部分由Part 3.2完成,程序首先在节表中加入一个新的节表项目,节表项中的VirtualSize,VirtualAddress,SizeOfRawData,PointerToRawData,Characteristics和Name1字段需要被设置。其中Name1中的名称被设置为“.adata”;Characteristics字段中的标志被设置为可执行和可读写,其他几个字段值的算法如下(下面的“上一节”指原始PE文件的最后一节):
● PointerToRawData=(上一节的PointerToRawData)+(上一节的SizeOfRawData)
● SizeOfRawData=附加代码的长度按FileAlignment值对齐
● VirtualAddress=(上一节的VirtualAddress)+(上一节的VirtualSize按SectionAlignment的对齐值)
● VirtualSize=附加代码的长度按SectionAlignment值对齐
其中的对齐算法是用_Align子程序来完成的。
由于这种方法部分修改了文件的结构,所以必须同时对PE文件头中的相关字段进行调整,它们是NumberOfSections、SizeOfCode和SizeOfImage字段。如果SizeOfImage的值不被修正的话,Windows将无法装入修改后的PE文件,系统会报“这不是一个有效的Win32可执行文件”的错误。Part 3.2的最后,程序将附加代码写到文件的最后,由于附加代码的长度还没有按FileAlignment的值对齐,所以程序再次使用SetFilePointer函数将文件指针移动到对齐后的位置并用SetFileEnd函数将文件长度扩展到这里。
无论是Part 3.1还是Part 3.2的最后,程序将新增代码在文件中的位置和在内存中的位置分别保存在@dwAddCodeFile和@dwAddCodeBase变量中以备后用。
Part 4修改PE文件头中的文件入口地址,并将修改后的整个PE文件头写入新文件中。
Part 5将原始PE文件的入口地址取出,和附加代码的入口地址计算得出“jmp原入口地址”这条指令中的二进制码值,并将这个值写到附加代码的对应位置中。jmp指令的编码方式是由一个0e9h字节加上指令执行后的EIP的修正值,也就是说,当jmp指令的下一句指令地址是addr1,而跳转的目标地址是addr2的话,那么0e9h字节后的双字的值就是addr2-addr1,所以下面几句就是将指令改成“jmp原入口地址”的样子:
push [esi].OptionalHeader.AddressOfEntryPointpop @dwEntrymov eax,@dwAddCodeBase
(1) add eax,(offset _ToOldEntry-offset APPEND_CODE+5)
(2) sub @dwEntry,eax在指令序列执行前,esi指向PE文件头,@dwAddCodeBase中保存有新增代码被装载到内存后的起始地址,所以由(1)标出的指令执行后,eax的值是_ToOldEntry后面5字节的位置,或者说是jmp xxxxxxxx后一条指令的位置,也就是上面算式中的addr1。@dwEntry中的原始值是可执行文件原来的入口地址,也即addr2,指令(2)执行后,@dwEntry中的值就是addr2-addr1了,这就是需要填入_dwOldEntry位置的数据。
接下来程序用SetFilePointer函数将文件指针移动到新增代码中的_dwOldEntry位置,并将上面计算出的结果写入文件中。
Part 6进行扫尾工作,如释放内存、关闭文件和显示成功信息等。至此,程序的所有功能就完成了。