深度学习快速复现平台AutoDL
笔者目前的研究方向是计算机视觉(CV)。自2016年以来,各类基于深度学习的视觉算法层出不穷,而对于这一方向而言,最有效的学习方式之一就是复现前辈们的代码。在此,笔者推荐一个值得使用的云服务器平台——AutoDL(AutoDL算力云 | 弹性、好用、省钱,GPU算力零售价格新标杆)。
以下内容为笔者的个人使用经验分享。
硬件配置
在复现经典算法的过程中,常常会遇到环境与硬件不兼容的问题。例如,一些较早的算法依赖于当时的深度学习框架版本,而这些版本往往难以在新一代显卡上正常运行。这会导致无法充分利用GPU加速,进而影响代码的正确复现与实验效果。
以笔者的经历为例:在复现经典的多模态图像融合算法 U2Fusion(U2Fusion: A Unified Unsupervised Image Fusion Network | IEEE Journals & Magazine | IEEE Xplore)时,论文所使用的框架为较早的 TensorFlow 1.x 版本。由于笔者使用的40系显卡无法兼容 TF1,直接复现受阻。为了解决这一问题,笔者在 AutoDL 平台上租用了 RTX 2080Ti 显卡,并配置了作者提供的实验环境。最终,顺利完成了代码复现,运行所用的 TensorFlow 版本为 1.15。
 这次复现印象深十分深刻,因为当时以为TF1升级到TF2,可能只需要对某些代码进行适配就好了,但是折腾了很久一直报错,最后果断选择AutoDL。
这次复现印象深十分深刻,因为当时以为TF1升级到TF2,可能只需要对某些代码进行适配就好了,但是折腾了很久一直报错,最后果断选择AutoDL。
显卡算力
在运行基于 Transformer 的算法以及点云相关的算法时,对显卡的计算性能要求极高。以复现 CDDFuse(CVPR 2023 Open Access Repository (thecvf.com)) 为例,笔者在较低性能显卡上跑完整个数据集耗时约 3 天,而在 RTX 4090 上同样的任务仅需 18 小时即可完成。再如 KITTI 数据集的实验,在 4090 上仍需约 3 天的训练时间,因此笔者在本地设备上便放弃了尝试。由此可见,显卡性能对于深度学习算法复现的效率与可行性具有至关重要的影响。
环境快速部署
AutoDL最大的优点就是简单与方便
复现代码首先就是准备环境,通常来说我们一般使用anaconda来部署虚拟环境,其中比较麻烦的就是pytorch版本与python选择,部署环境可参考笔者这篇博客:使用pytorch深度学习框架搭建神经网络_pytorch框架搭建-CSDN博客
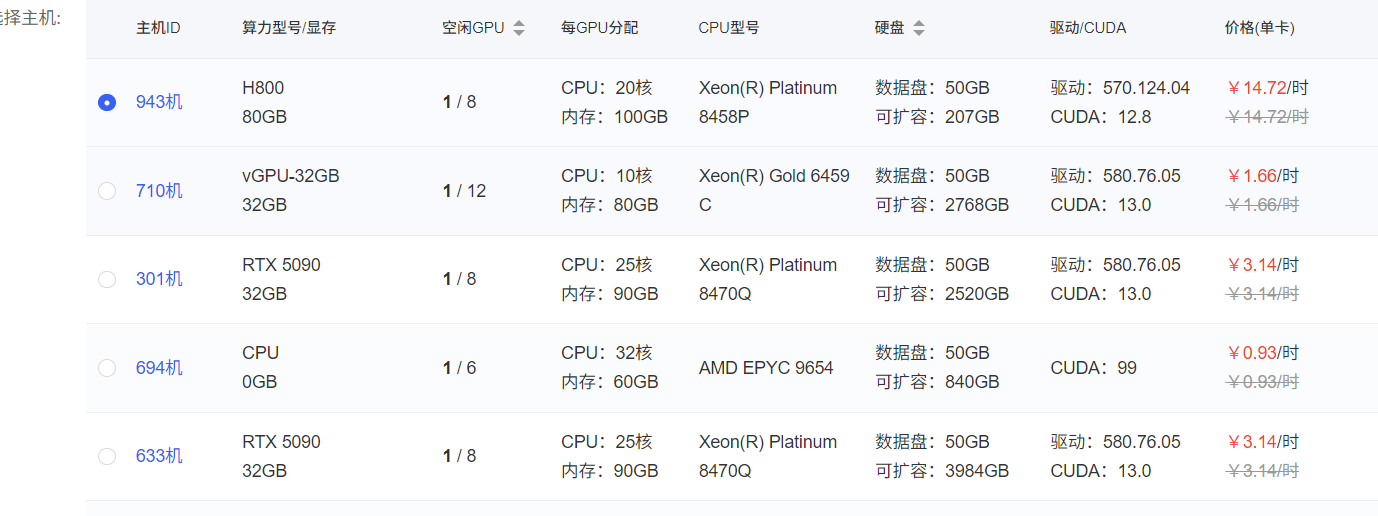
对于小白就更痛苦了,还需安装cuda与cudnn,但是使用AutoDL就完全没有这样的担忧,这也是我喜欢它的原因,直接在交互界面选择自己需要的环境就行。
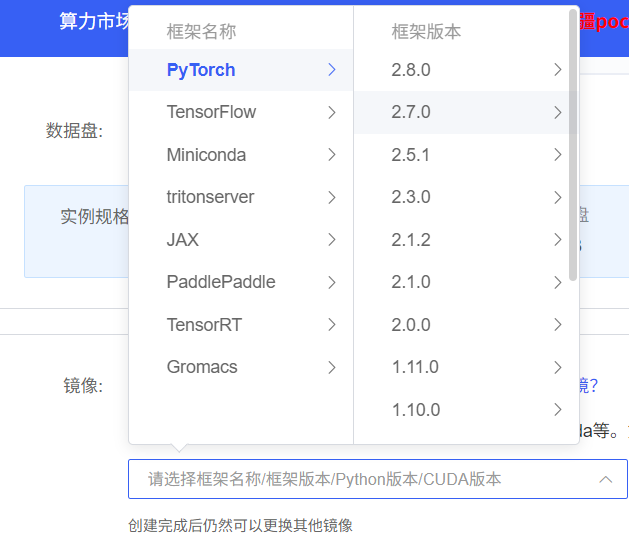
甚至一些比较火的环境可以直接部署,比如yolo系列,在社区镜像直接搜索就可以
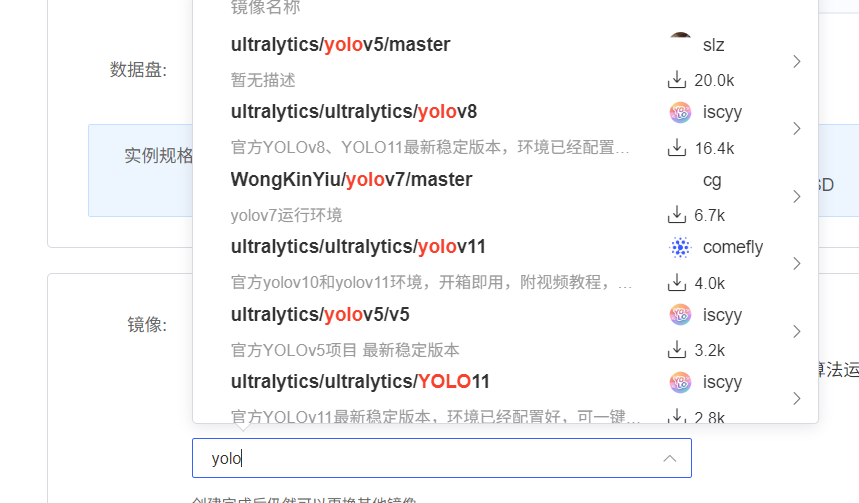
凭借上述操作,我们就可以快速复现yolov5算法,可以参考我这篇博客:yolov5快速复现(超快云服务器部署)_yolov5复现-CSDN博客里面分享了我使用AutoDL平台使用自建数据集快速部署yolov5算法。
数据传输
wincsp
这里支持使用Winscp,这个就比较简单,但是传输速度会慢点,但是很好用,具体使用方法可以参考笔者这篇博客:yolov5快速复现(超快云服务器部署)_yolov5复现-CSDN博客
Xshell
这里可以参考AutoDL的官方帮助手册,详细介绍了怎么使用Xshell。Xshell笔者个人使用经验就是要进行个人认证,且时不时更新,但是上传速度更快。
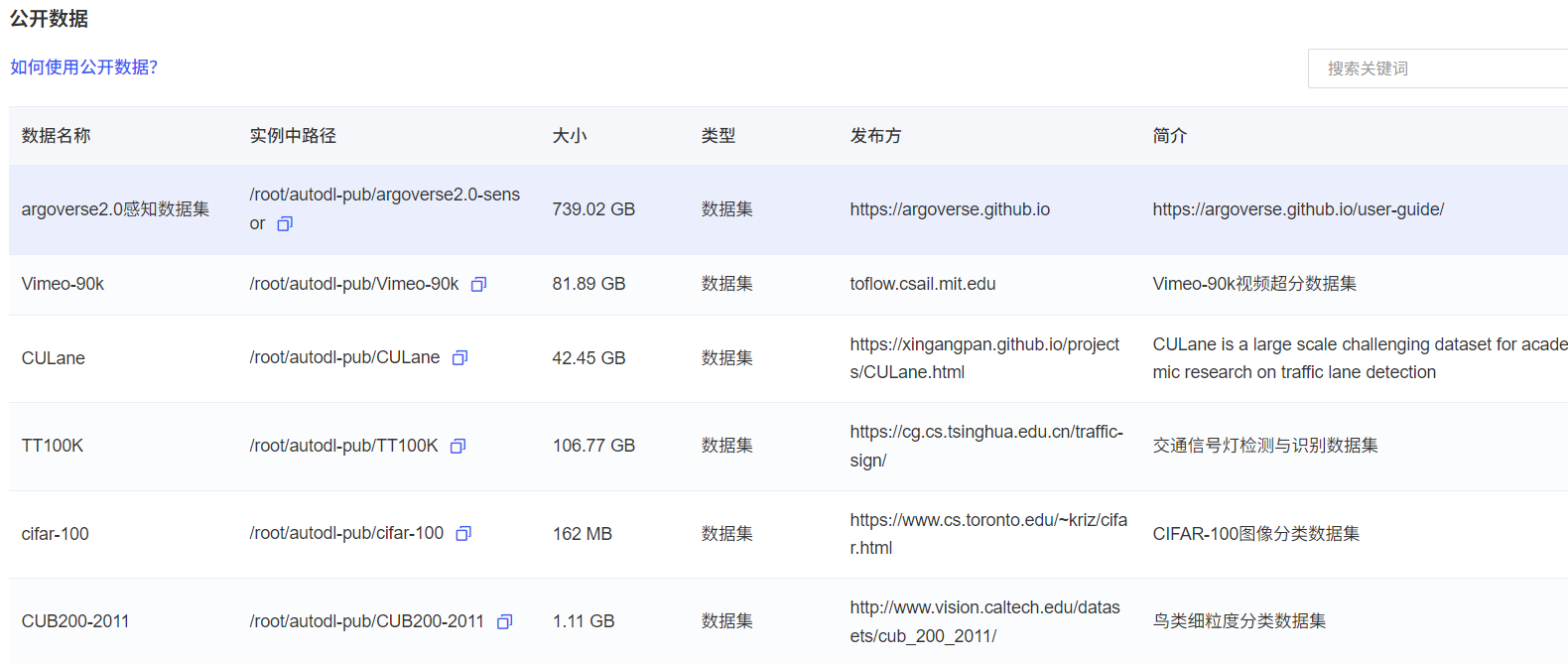
如果大家使用公共数据集跑模型的话,可以先查看AutoDL是否包含这个数据集,这样就不用再上传数据集了。AutoDL算力云 | 弹性、好用、省钱,GPU算力零售价格新标杆
到此为止,我的分享就到此结束了,感谢大家的阅读!^u^