实测AI Ping,一个大模型服务选型的实用工具
作为一名长期奋战在一线的AI应用工程师,我在技术选型中最头疼的问题就是:“这个模型服务的真实性能到底如何?” 官方的基准测试总是在理想环境下进行,而一旦投入使用,延迟波动、吞吐下降、高峰期服务不可用等问题就接踵而至。
直到我发现了由清华系团队打造的AI Ping,这个平台号称能提供真实、客观的大模型服务性能评测。经过一段时间的深度体验,我来分享下自己的使用感受和发现。
一、为什么我们需要大模型服务性能评测?
随着大模型应用开发的爆发式增长,MaaS(Model-as-a-Service)已成为开发者调用模型能力的首选方式。然而,面对众多服务商和模型版本,开发者在选型时往往陷入“性能不透明、数据不统一、评测不客观”的困境。正是在这样的背景下,AI Ping 应运而生。
二、AI Ping 是什么?
AI Ping 是由清华系AI Infra创新企业清程极智推出的大模型服务性能评测与信息聚合平台。它通过延迟、吞吐、可靠性等核心性能指标,对国内外主流MaaS服务进行持续监测与排名,为开发者提供客观、实时、可操作的选型参考。
官网直达:https://aiping.cn/?utm_source=cs&utm_content=k
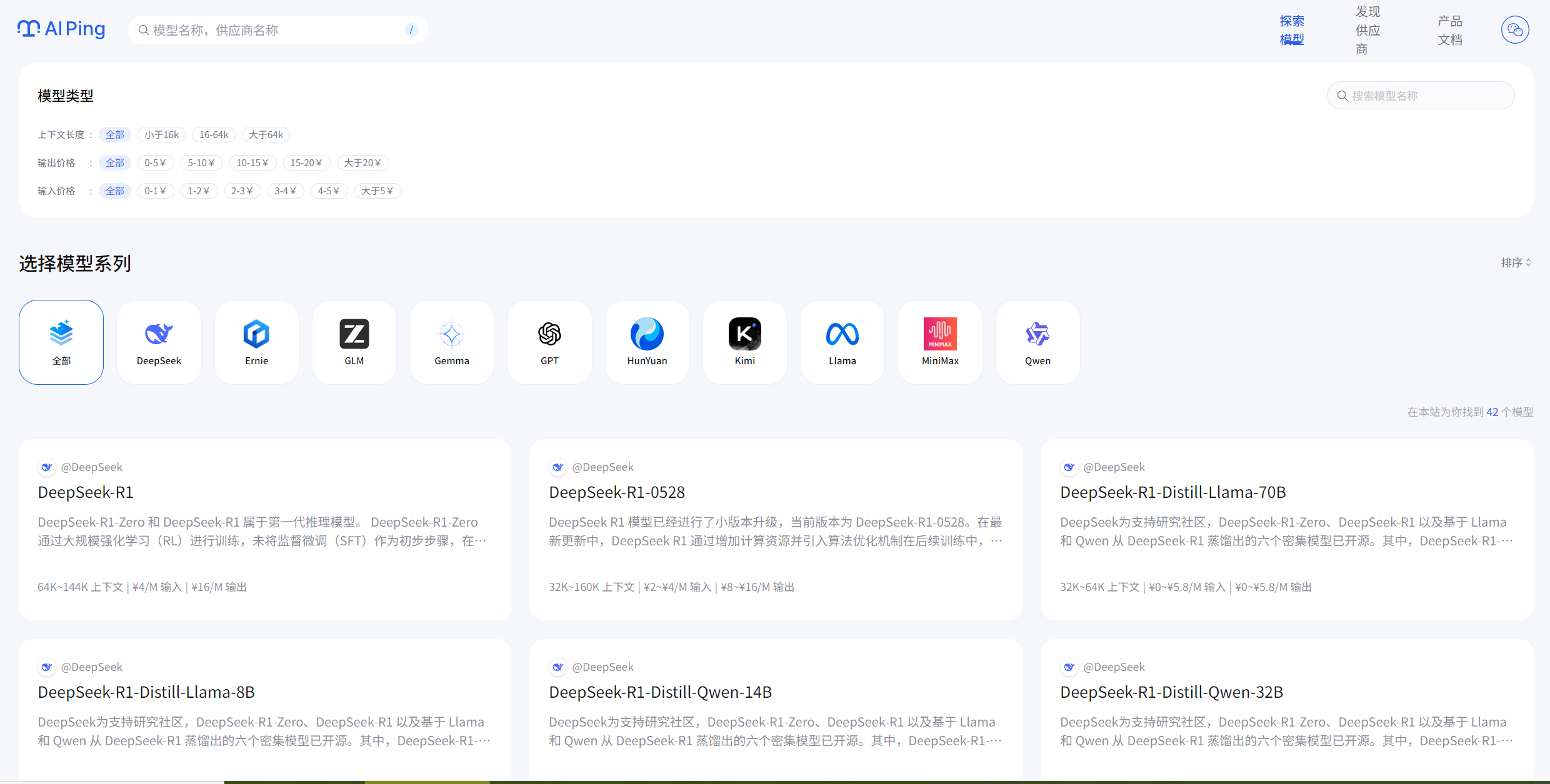
打开AI Ping官网,第一印象是简洁、直接、信息密度高 - 典型的工程师风格设计。首页核心位置就是那个备受关注的「大模型服务性能排行榜」,默认展示的是基于多个指标的综合排名。
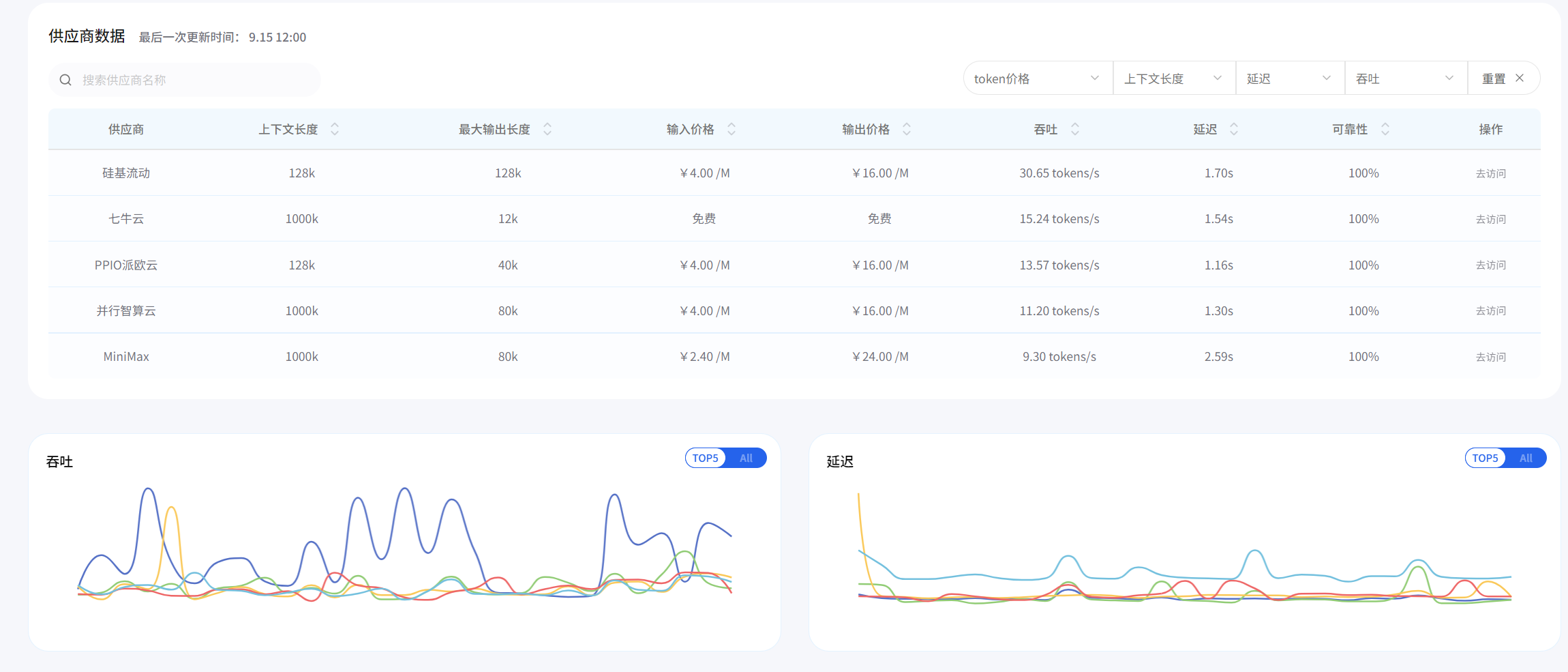
首页性能排行榜,第一眼看到这个深深的吸引了我,因为之前有很多专业记者问我怎么检查大模型,我一直回答不上,因为网上太多文章写排行榜,但真正有合理、客观、真实的评价很少很少,体验了AI Ping之后,我可以联系他们,正面答复了!
左上角这里有模型和供应商搜索,可以快速定位到自己想要找的大模型,如下图所示:
右上角有产品文档https://aiping.cn/docs/product入口,可以帮助快速上手和查看相关资料:

说来惭愧,作为一家创业公司的技术负责人,我去年在选大模型API时栽过大跟头。当时轻信了某厂商的 benchmark 数据,结果上线后才发现,他们的服务每晚凌晨准时"抽风",延迟从300ms直接飙到2000ms+,我们的夜间客服机器人差点成了"智障机器人"。
直到朋友介绍和听了清华翟季冬教授的分享,才知道他们联合中国软件评测中心推出了《2025大模型服务性能排行榜》,背后的数据支持来自一个叫AI Ping的平台。
会后我第一时间注册体验,没想到这一用就后续选大模型就先打开这个软件来参考。今天就跟大家聊聊这个让我眼前一亮的神器。
三、终于有个说人话的评测平台
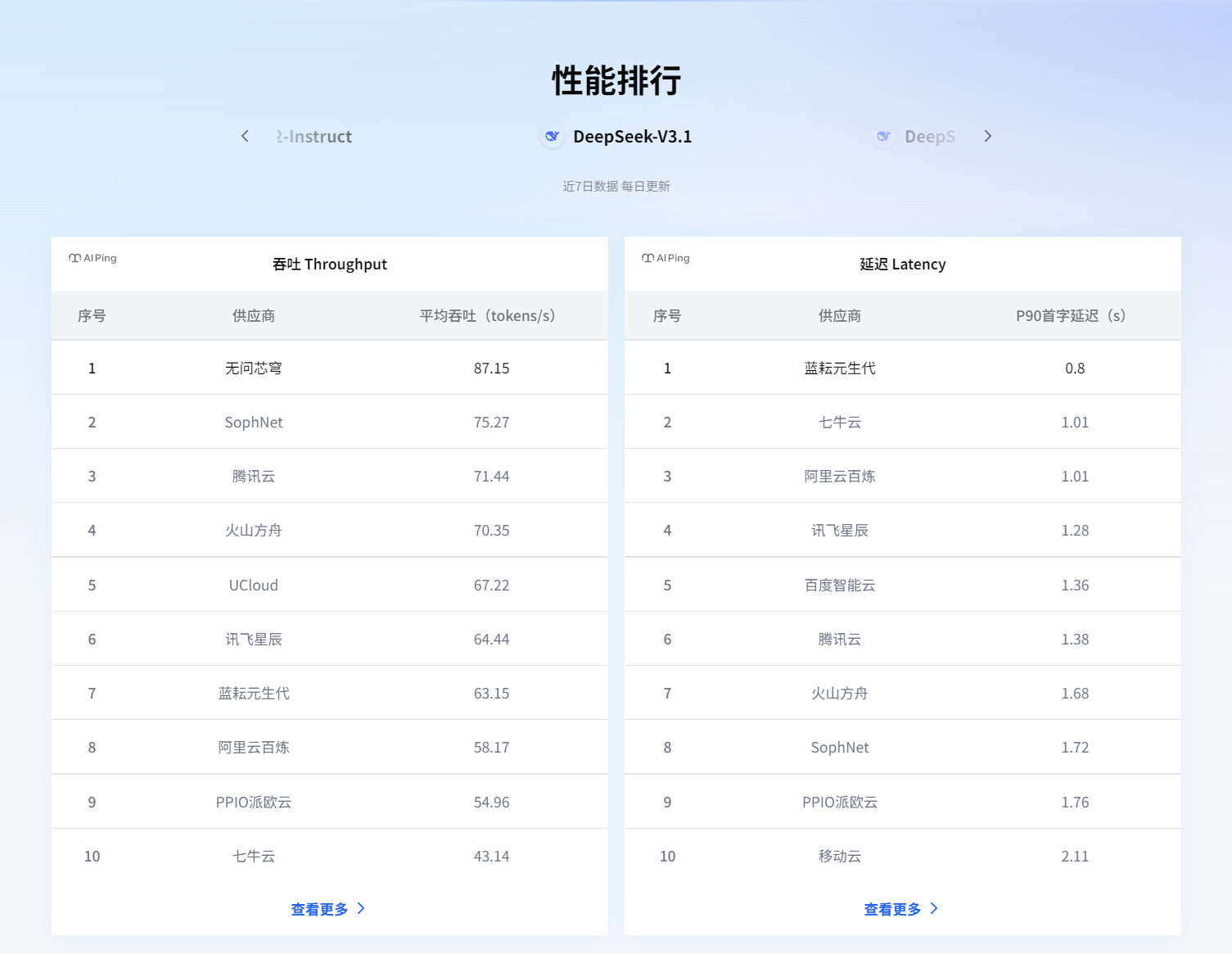
我最喜欢的是那个性能坐标图——可以看近7日数据、每日更新、平均吞吐量。这个设计太实用了!还记得上次我们的项目就是在晚上8点流量高峰时段崩的,现在我能专门盯着这个时间点看哪个服务最稳。
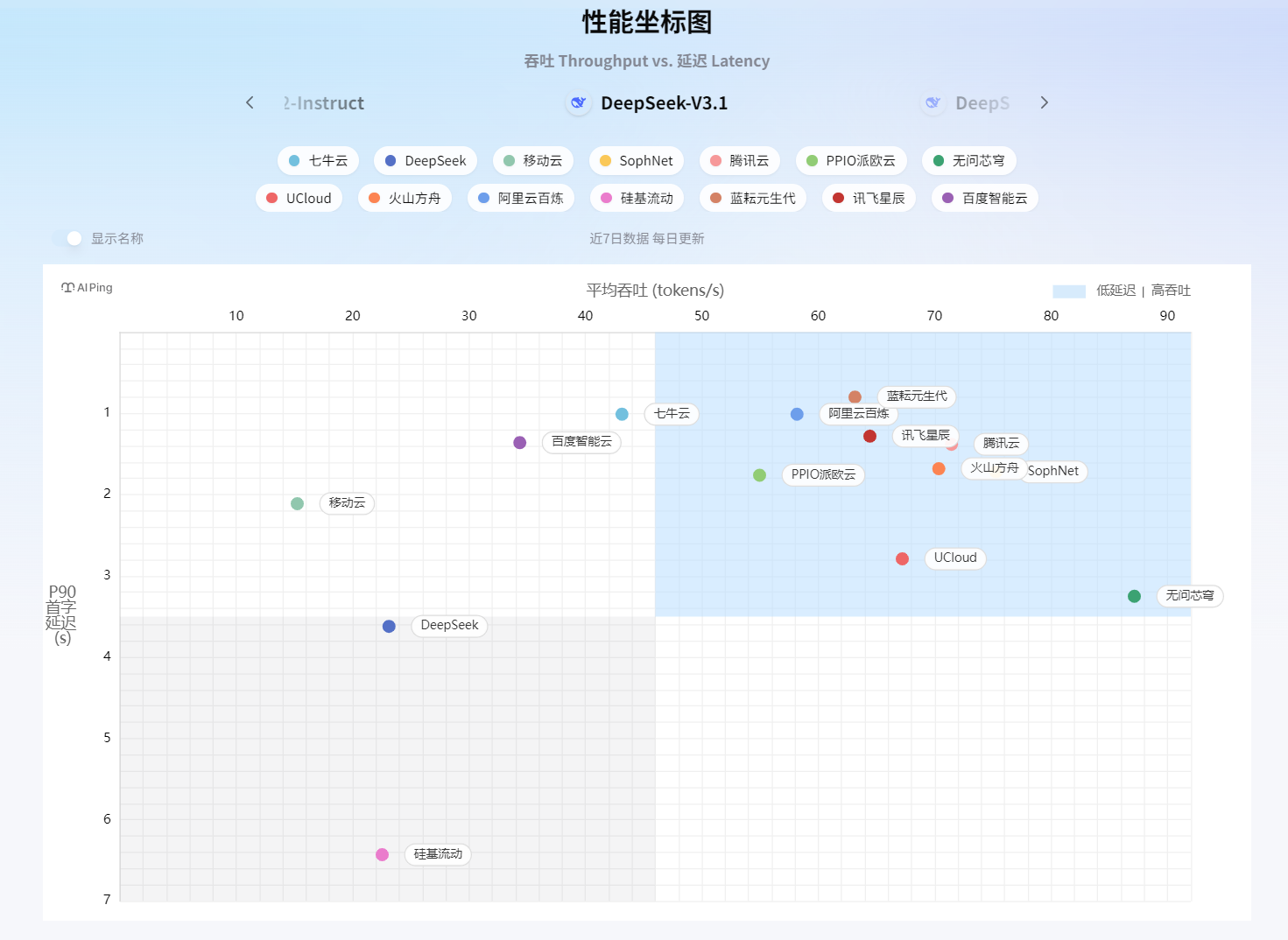
随手翻了几个模型的详情页,差点笑出声。某个经常打广告的厂商,页面显示其服务在每天凌晨2点到4点延迟飙升,这不就是我们当时踩的坑么!要是早点有这个工具,我也不用背那个"选型失误"的锅了。
四、深度使用:发现了更多宝藏功能
1. 性能曲线会说话
平台里的历史性能曲线简直是个宝藏。以DeepSeek-V3为例,它的7天延迟曲线平稳得让人怀疑是不是假数据。相比之下,某些友商的曲线就跟心电图似的,忽高忽低。
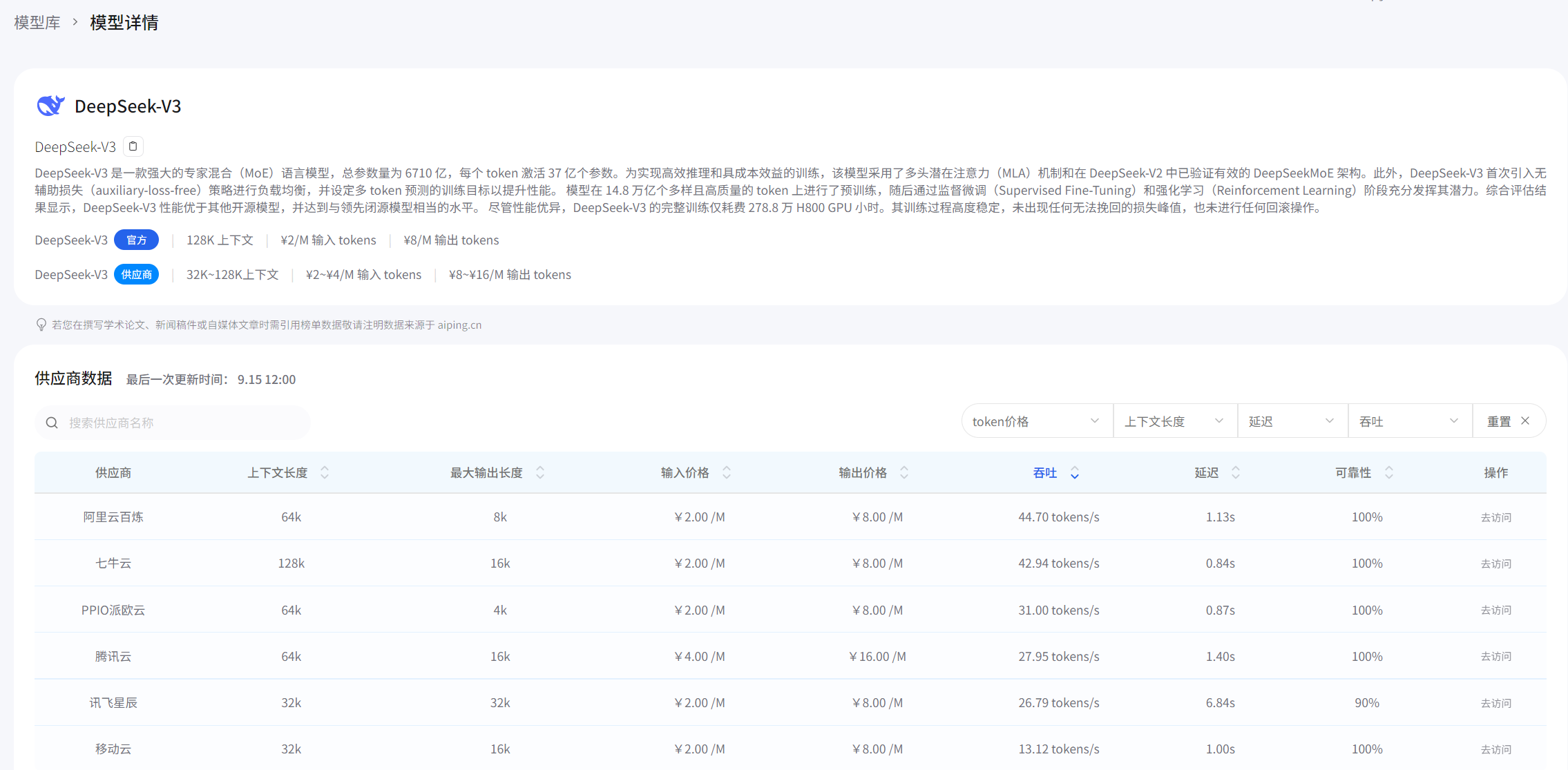
最绝的是,我发现有家厂商的曲线每天下午3点准时出现一个小高峰,后来才知道那是他们每天定时做模型热更新的时间。这种细节,不去长期监测根本发现不了。
2. 价格对比透明得惊人
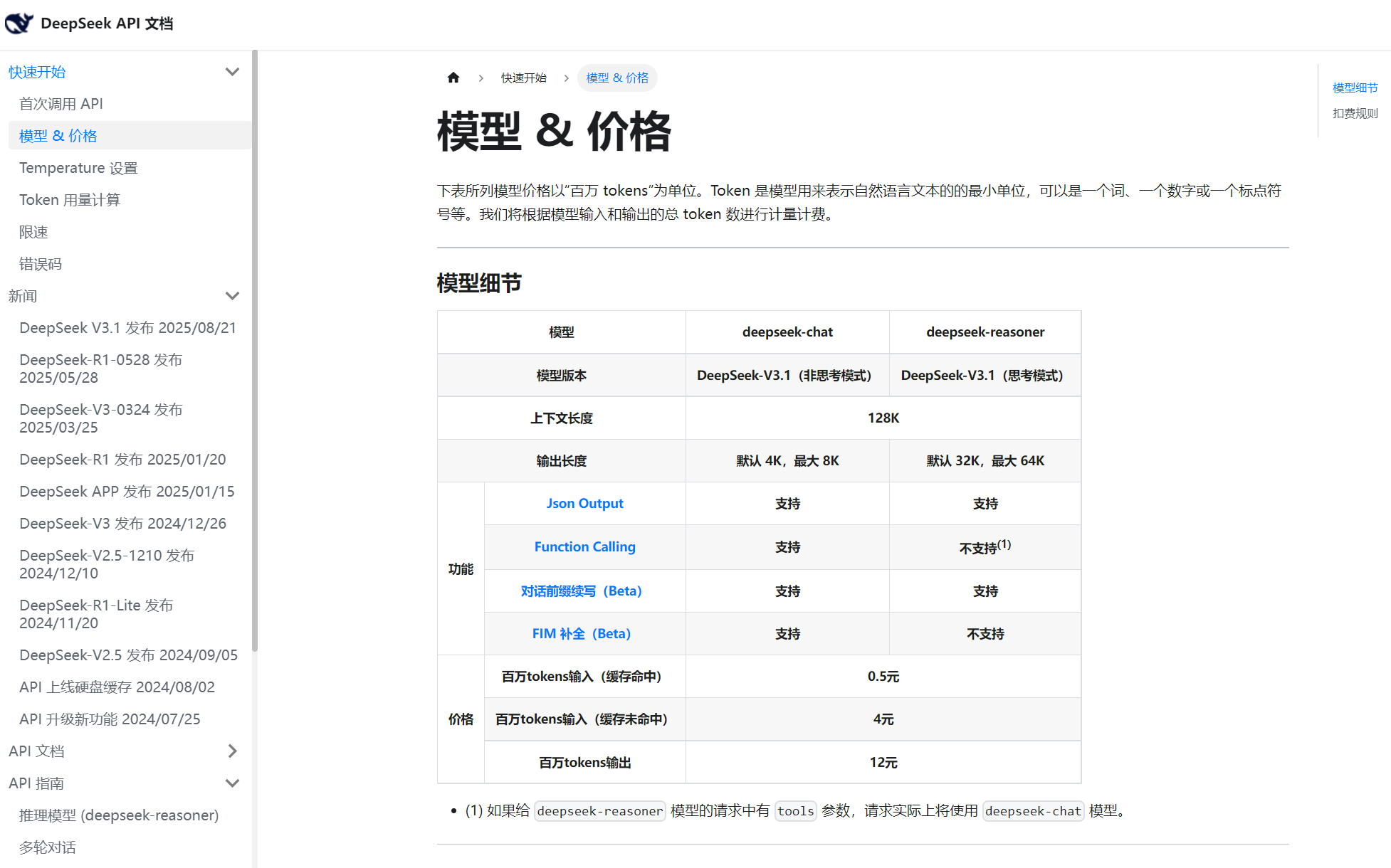
之前要对比不同模型的价格,我每次接入几个新的大模型,老板总是问我,这个模型怎么样?价格多少钱?性能怎样?我明白他作为一名老板,最关心的还是价格,这样我得一个个去翻各家官网,还要自己换算单位,头疼得要命。AI Ping直接把所有模型的单价列得明明白白,还能按"每元token吞吐量"排序。
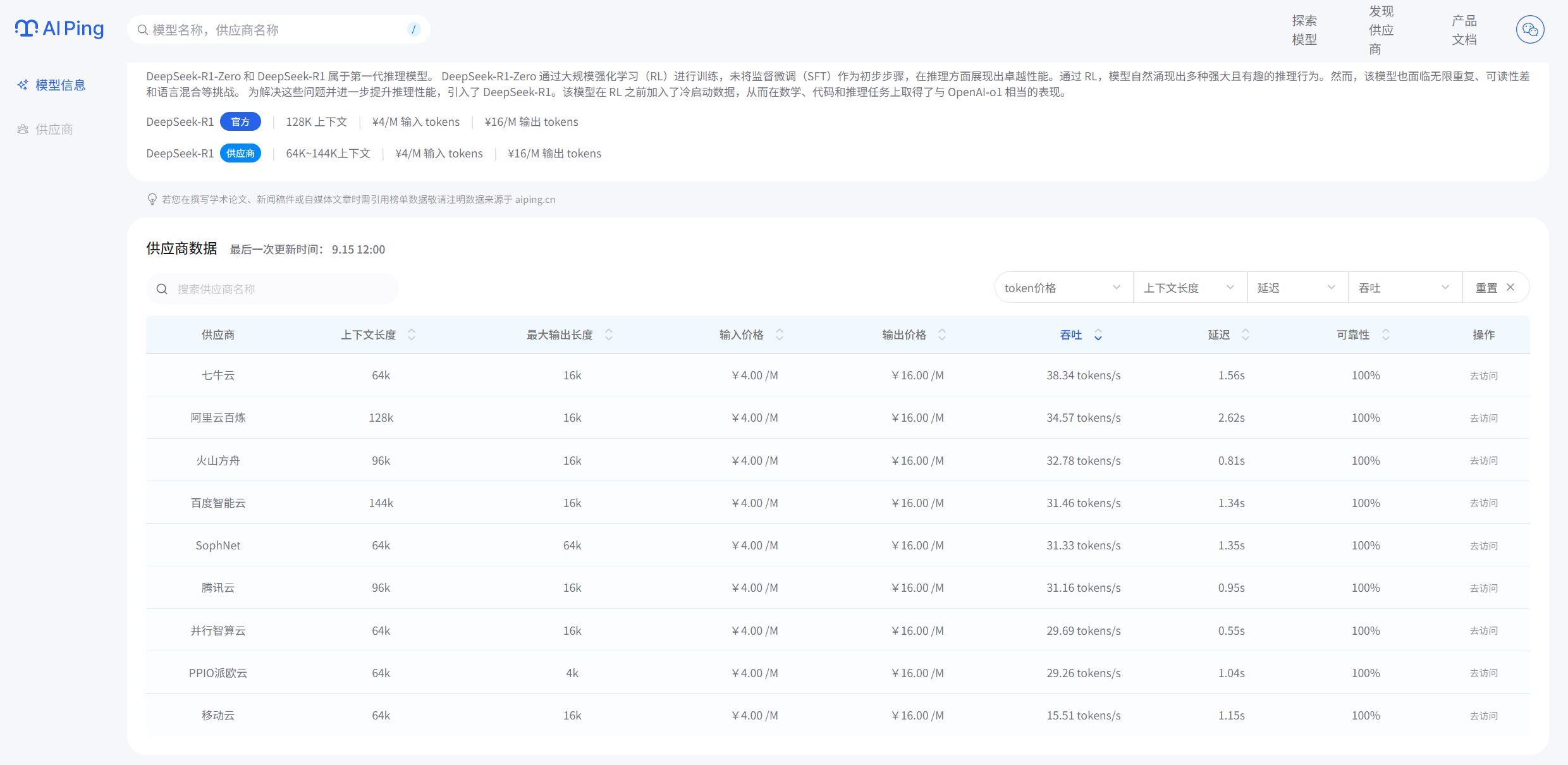
对比一下DeepSeek官网,看得出数据是准确的,值得信赖!
我就这样发现了一个宝藏厂商:虽然名气不大,但吞吐量的性价比居然排进前三。试着接了一下,效果确实不错,每个月能省下小一万的API调用费。
3. 可靠性数据防踩雷
有个细节让我印象深刻:某知名厂商的详情页里,可靠性曲线显示每周二上午都会有个明显的 dips(下降)。一问才知道,他们每周二上午做例行维护。
要是早知道这个,我们就能避开这个时间段安排重要任务了。现在我都养成习惯了,每周二上午绝对不安排批量处理任务。
五、实战案例:如何用AI Ping做选型
最近接了个新项目,需要选一个处理长文档的模型。我的筛选过程是这样的:
首先,用大于128k上下文长度作为过滤条件,一下子筛掉了一半选项。
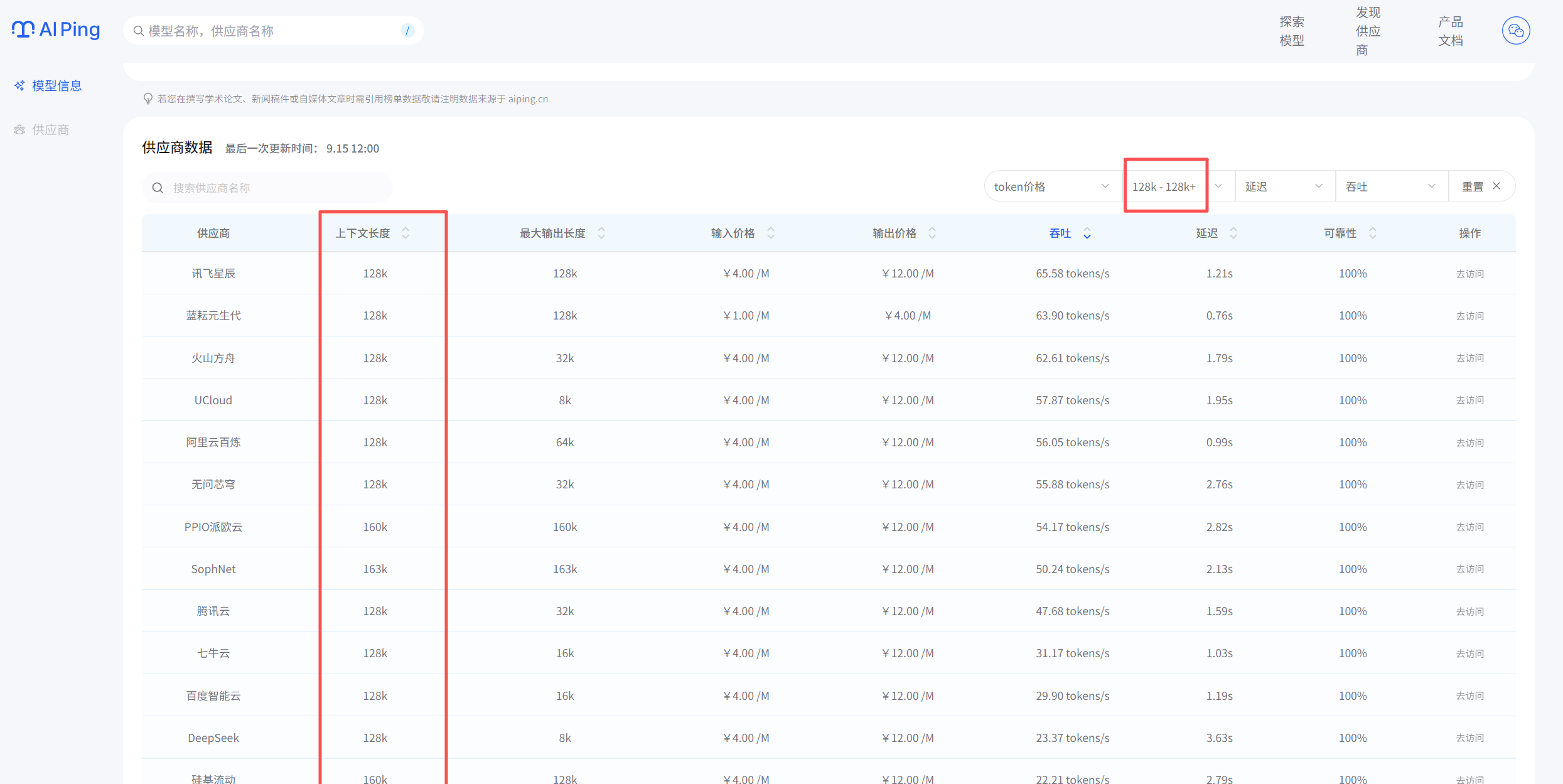
然后,按吞吐量排序,选前5名进入决赛圈。
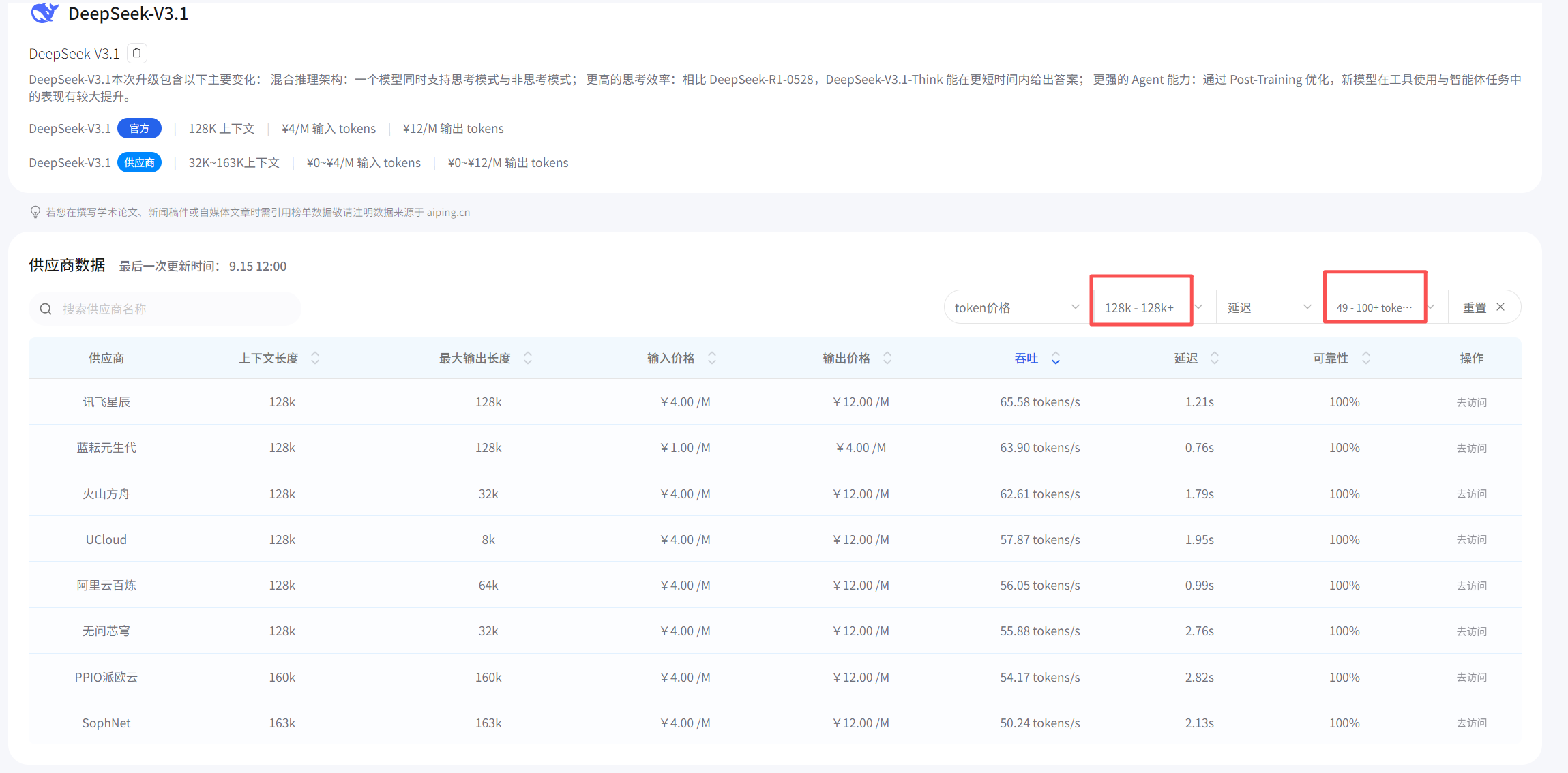
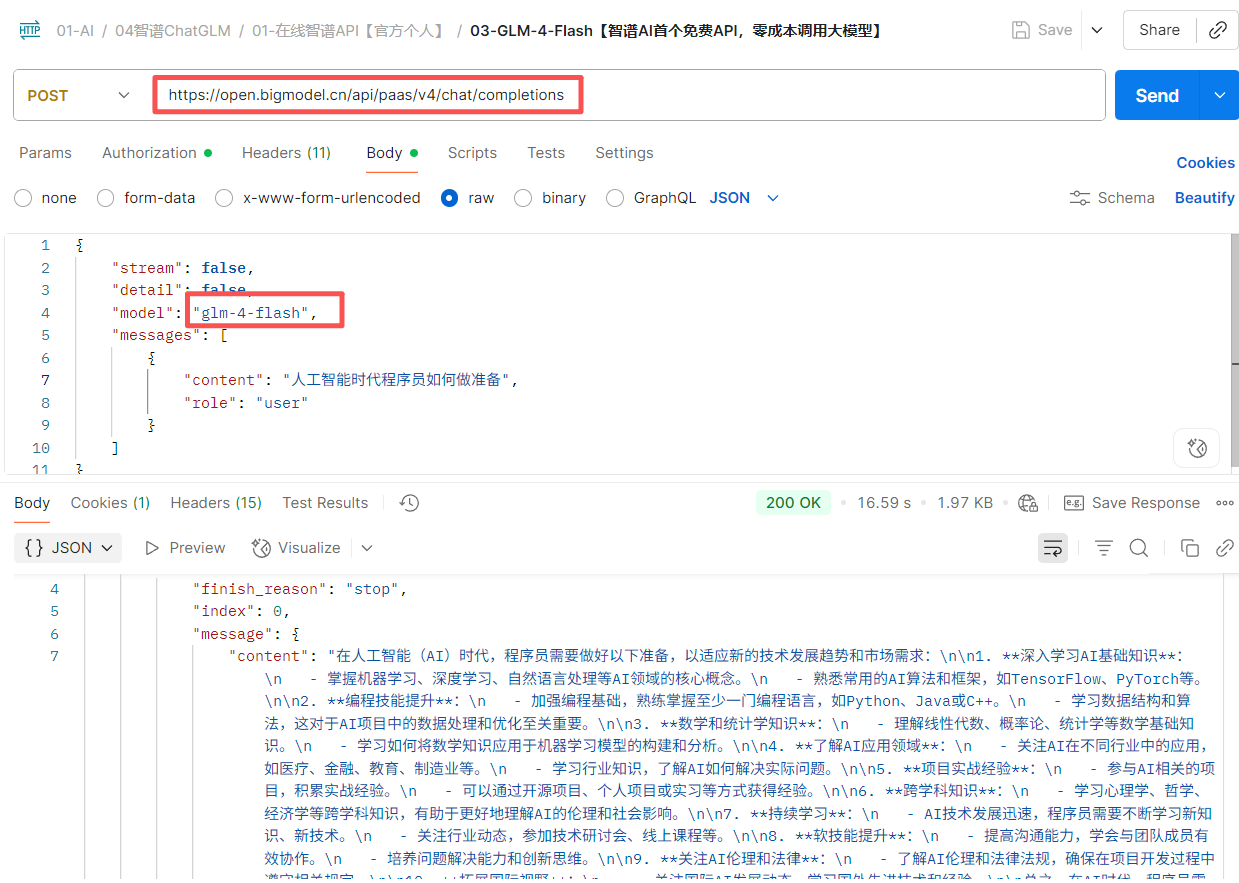
为了验证这些数据是否准确,我用postman对接了9个厂商分别测试监督,答案令人出乎所料,跟平台描述的一致,体验过程如下:
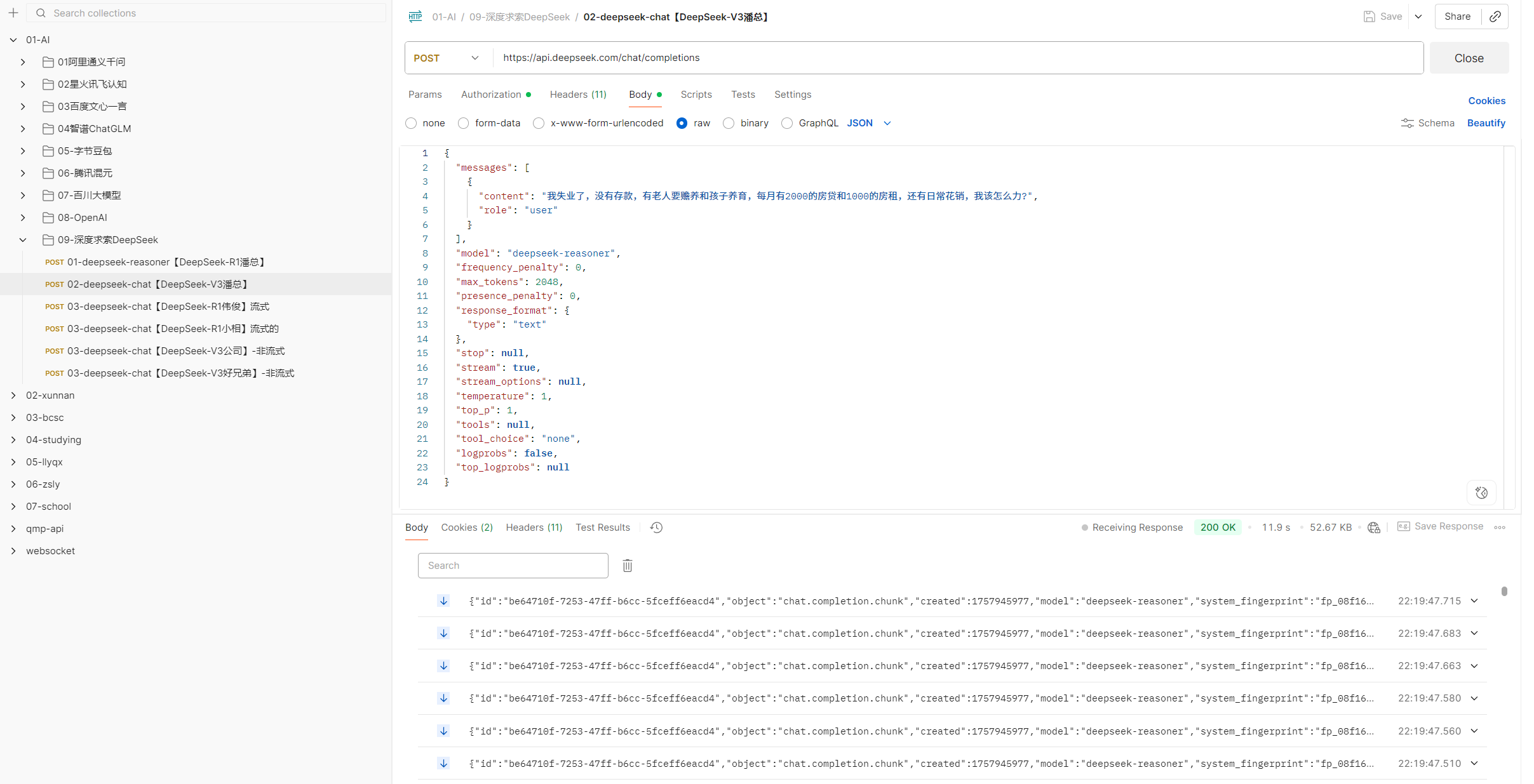
例如智谱官方请求:
还有其他大模型测试记录,这里我就不一一列举了,如下图所示:
接着,逐个点开详情页,特别关注它们处理长文本时的性能衰减情况——有些模型处理短文本很快,但一到长文本就崩。
最后,对比价格和高峰时段表现,选了性价比最高的那个。
整个过程只用了20分钟。放在以前,光测试每个模型的性能就要花上一周时间。
六、期待未来更强大的功能
在使用过程中,我也注意到了一些可以进一步提升的方面,相信随着平台的迭代,这些功能都会逐步完善:
首先是在测试场景方面,目前平台提供了标准化的测试框架,如果未来能够支持用户上传自己的测试用例和业务场景,想必能更好地满足不同团队的个性化需求。想象一下,如果能用我们实际业务中的对话场景和文本数据来测试模型表现,那选型精准度肯定能再上一个台阶。
其次是数据接入方面,现在是通过网页端查看数据,如果未来能提供API接口,就可以把性能数据对接到我们自己的监控系统中,实现自动化报警和性能趋势分析。这样一来,我们的运维团队就能更及时地发现潜在问题。
虽然这些功能暂时还没有上线,但我注意到平台一直在快速迭代。相信以清华团队的技术实力,这些功能应该已经在开发路线图上了。毕竟,一个好的工具就是这样,越用越顺手,越用越贴心。
七、总结一下
用了一段时间AI Ping,最大的感受是:大模型选型终于从"玄学"变成了"科学"。
以前选型靠的是厂商PPT、技术博客、朋友推荐,现在终于有了客观的数据支持。特别是那个长时段性能监测功能,简直就是防坑神器。
如果你也在为选型发愁,不妨去试试这个平台。反正我们是已经把它列入技术选型标准流程了。
PS:最近看到消息,清华大学和中国软件评测中心要在GOSIM大会上发布《2025大模型服务性能排行榜》,用的就是AI Ping的数据。能获得这么权威的认可,说明这个平台确实有点东西。