YOLOv12目标检测:使用自定义数据集训练 YOLOv12 检测坑洞严重程度
YOLOv12目标检测:使用自定义数据集训练YOLOv12检测坑洞严重程度
引言
道路裂缝与坑洞不仅是交通隐患,更可能引发安全事故。从损坏车辆到导致交通事故,维护不善的道路构成了严重的安全风险。传统的人工勘测检查方法耗时且成本高昂,且难以实现实时监控。
这正是深度学习发挥作用的领域——特别是能够分析道路图像或视频并自动检测坑洞的目标检测模型。在众多可用模型中,YOLOv12是目前最强大、最高效的模型之一。它在以往YOLO版本的成功基础上,融合了尖端的注意力机制(如RELAN和区域注意力),成为首个为实时应用设计的注意力驱动型YOLO模型。
本研究将超越基础的目标检测任务,旨在构建一个完整的技术管道,利用YOLOv12实现坑洞检测与严重程度评估。研究将基于每个检测到的坑洞的边界框面积衡量其严重程度,从而直观且实际地反映坑洞的大小及危险等级。
此外,研究还将完成以下工作:
- 在自定义坑洞数据集上使用预标记图像训练YOLOv12模型
- 构建直观的Gradio界面,支持用户上传图像或视频并实时获取带注释的结果
- 在媒体文件上直接标注坑洞严重程度级别:低、中_或_高
- 提供输出视频保存功能,以便后续检查或记录
数据集与任务概述
为训练YOLOv12模型实现坑洞检测,本研究采用了[Roboflow的坑洞检测集合]中的一个公共数据集。该数据集包含从真实道路场景中捕获的多种带注释的坑洞图像,使研究能够针对实际应用场景微调YOLOv12模型。
数据集详情
- 来源:Roboflow Universe
- 数据集链接:坑洞检测数据集v2
- 图像总数:1482张
- 训练集:1037张图像
- 验证集:296张图像
- 测试集:149张图像
- 格式:兼容YOLOv12的注释格式
- 类别:单一类别(坑洞)
该数据集涵盖了不同光照条件、道路纹理及图像分辨率下的坑洞。由于注释已采用YOLO格式,可直接用于微调流程。
图1展示了数据集中的示例图像。

检测目标
本任务旨在检测图像和视频流中的坑洞。每次检测将返回围绕坑洞的边界框,此外,将通过自定义逻辑对坑洞的严重程度进行分类。
坑洞严重程度定义
研究将坑洞分为低、中或高三个严重程度等级。并非仅使用边界框面积(其可能受相机视角影响),而是采用混合评分策略,同时考虑:
- 坑洞的大小(边界框面积)
- 坑洞在帧中的位置(通常,位置越低表示物体离相机越近)
这两个特征均通过帧的高度进行归一化处理,并通过加权分数进行组合。若一个坑洞看起来较大且靠近帧的底部,则其更可能构成严重威胁,因此被标记为高严重程度。较小且位置较远的坑洞得分较低。
当图像具有大致一致的分辨率和道路视角时(如行车记录仪或无人机数据集),该策略效果显著。
坑洞严重程度逻辑的改进空间
尽管这种启发式方法快捷简便,但可通过更高级的方法提高准确性:
- 使用MiDaS(单网络多深度估计精度)或DPT(密集预测变换器)等模型进行单目深度估计,以测量坑洞的实际距离。
- 采用实例分割获取精确的坑洞边界,而非仅依赖边界框。
- 利用3D传感器或立体视觉捕获物理尺寸信息。
本研究中,将采用轻量级评分逻辑,在速度与有效性之间取得良好平衡。
开发环境配置
在深入研究YOLOv12坑洞检测器的训练与部署之前,需确保开发环境配置正确。
需要一个安装了以下关键库的Python环境:
opencv-python:用于图像和视频处理gradio:用于构建交互式Web界面numpy、scipy、matplotlib:核心科学计算库- YOLOv12(直接从官方仓库克隆)
以下是研究中使用的requirements.txt文件内容:
git+https://github.com/sunsmarterjie/yolov12.git
opencv-python
gradio
numpy
matplotlib
scipy
可通过以下命令一次性安装这些依赖:
pip install -r requirements.txt
训练YOLOv12实现坑洞检测
本节将介绍使用Roboflow在自定义坑洞检测数据集上对YOLOv12进行完整微调的过程。同时将通过损失曲线、评估指标和预测可视化分析训练结果。
配置API并安装依赖
要在自定义数据集上微调YOLOv12,需设置Roboflow API密钥并安装必要的依赖库。这将确保能够下载数据集并与Roboflow平台进行交互。
步骤1:获取Roboflow API密钥
若没有Roboflow账户,请[在此处]免费注册。登录后,导航至您的[设置]页面查找API密钥。请妥善保管此密钥,因其授予对数据集的访问权限。
步骤2:安装Roboflow及其他依赖
研究将使用pip安装roboflow库,以及ultralytics(YOLOv12的基础库)和其他基本包。打开终端或命令提示符,运行以下命令:
pip install roboflow ultralytics
该命令将安装数据集管理和模型训练所需的核心库。
从Roboflow下载数据集
配置好API密钥并安装依赖后,下一步是直接从Roboflow下载坑洞检测数据集。此过程可通过roboflow Python库简化实现。
创建一个新的Python脚本(例如,download_dataset.py),并添加以下代码:
from roboflow import Roboflow# 替换为您的实际API密钥
ROBOFLOW_API_KEY = "YOUR_ROBOFLOW_API_KEY"# 初始化Roboflow
rf = Roboflow(api_key=ROBOFLOW_API_KEY)# 指定您的工作区和项目
project = rf.workspace("your-workspace").project("pothole-detection-v2")# 以YOLOv12格式下载数据集
dataset = project.version(1).download("yolov12")print("数据集下载成功!")
重要提示:
- 将
YOUR_ROBOFLOW_API_KEY替换为您的实际Roboflow API密钥。 - 将
"your-workspace"替换为您的Roboflow工作区名称。 - 确保项目名称
"pothole-detection-v2"与您要下载的数据集名称一致。
运行此脚本后,数据集将下载到本地目录,可供训练使用。
微调YOLOv12模型
数据集下载完成后,下一步是使用ultralytics库微调YOLOv12模型。研究将以预训练的YOLOv12模型为起点,在自定义坑洞数据集上进行训练。
创建一个新的Python脚本(例如,train.py),并添加以下代码:
from ultralytics import YOLO# 加载预训练的YOLOv12模型
model = YOLO("yolov12.pt") # 或yolov12-tiny.pt、yolov12-medium.pt等# 在自定义数据集上训练模型
# 'data'参数应指向数据集的YAML文件
# 此YAML文件通常在从Roboflow下载数据集时生成
results = model.train(data="pothole-detection-v2/data.yaml", epochs=100, imgsz=640)print("训练完成!")
重要提示:
- 将
yolov12.pt替换为您要使用的预训练YOLOv12模型的路径。您可从Ultralytics官方仓库下载这些模型。 data参数应指向数据集的YAML文件。从Roboflow下载数据集时,通常会生成此YAML文件。- 根据训练需求调整
epochs和imgsz参数。epochs是模型训练的迭代次数,imgsz是输入图像的大小。
运行此脚本后,YOLOv12模型将开始在自定义数据集上训练。训练过程所需时间取决于硬件配置和数据集大小。
训练结果与性能分析
训练完成后,ultralytics库会自动生成多种指标和可视化结果,帮助评估模型性能。这些结果通常保存在runs/detect/train目录中。
研究重点关注以下关键指标:
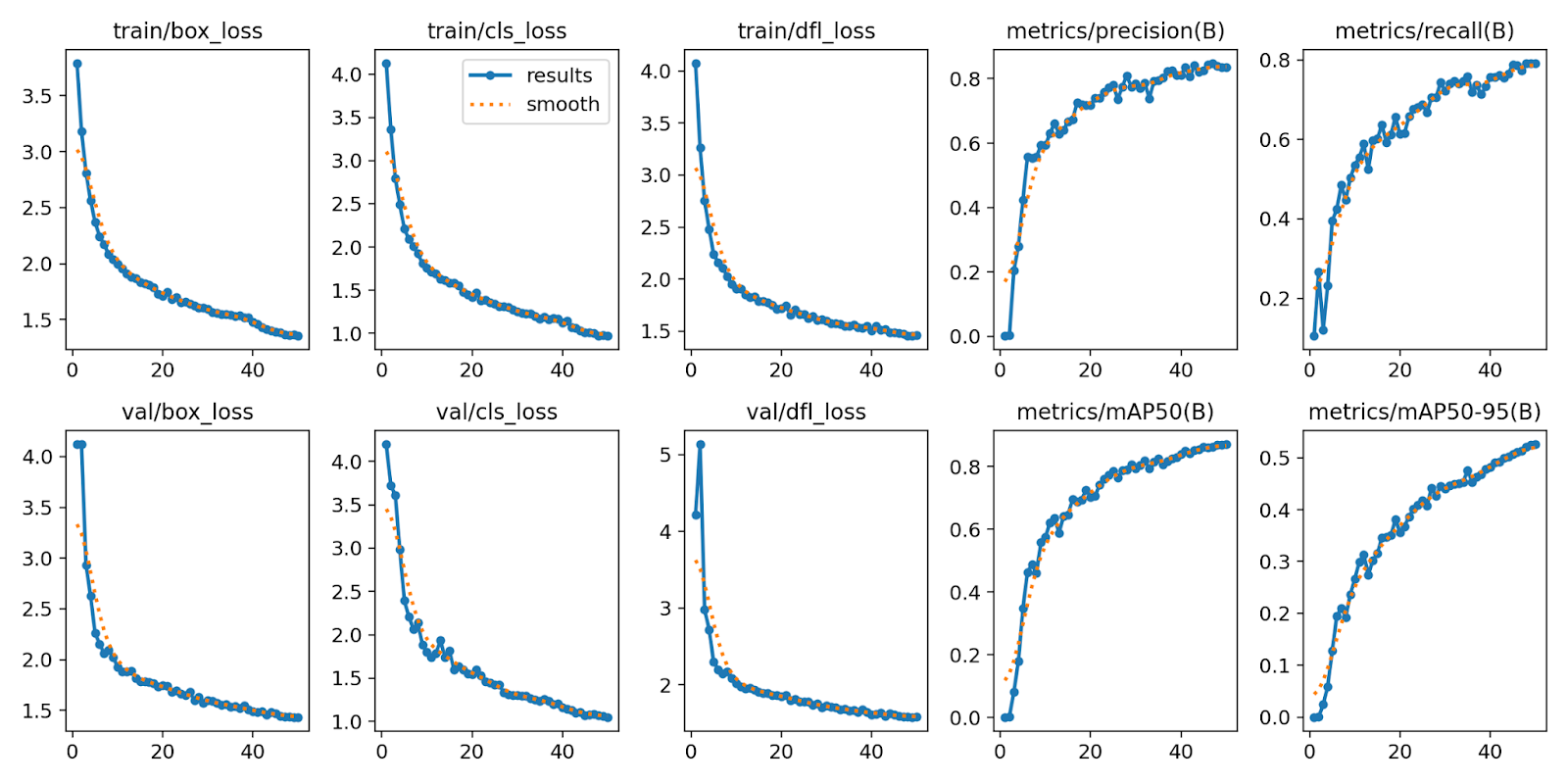
损失与指标曲线
损失曲线(如训练损失、验证损失)和指标曲线(如精确度、召回率、mAP)可反映模型在训练过程中的学习情况。理想情况下,损失曲线应呈下降趋势,而指标曲线应上升并趋于稳定。
图2展示了典型的损失和指标曲线。
混淆矩阵
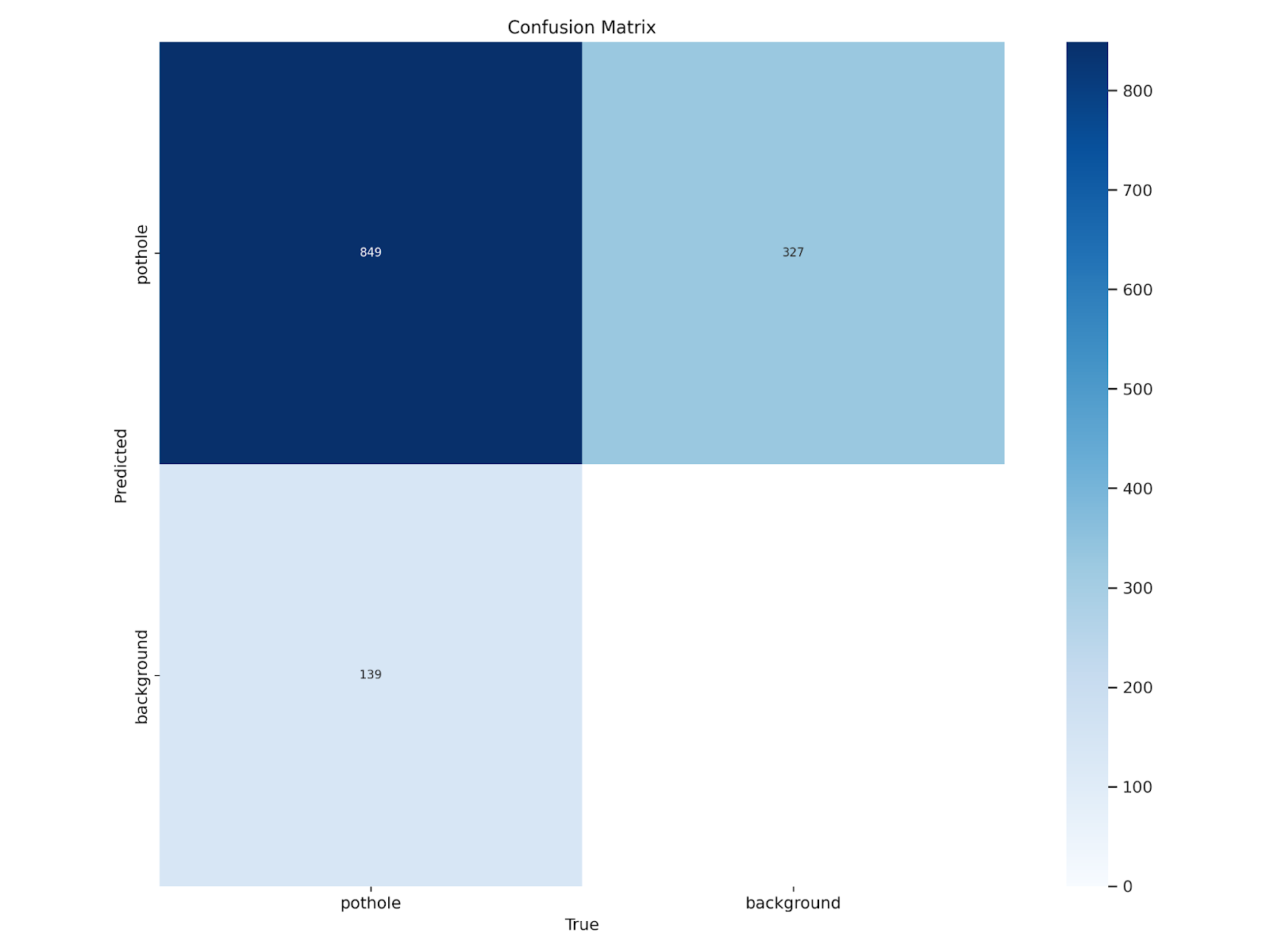
混淆矩阵可可视化模型在每个类别上的性能,展示真阳性、假阳性、真阴性和假阴性的数量。对于坑洞检测任务,它将显示模型正确检测到坑洞的次数,以及将非坑洞区域错误分类为坑洞的次数。
图3展示了典型的混淆矩阵。
平均精度均值(mAP)
mAP是目标检测模型性能的综合指标。它计算所有类别的平均精度,并综合考虑模型的精确度和召回率。mAP值越高,表示模型性能越好。
图4展示了典型的mAP曲线。
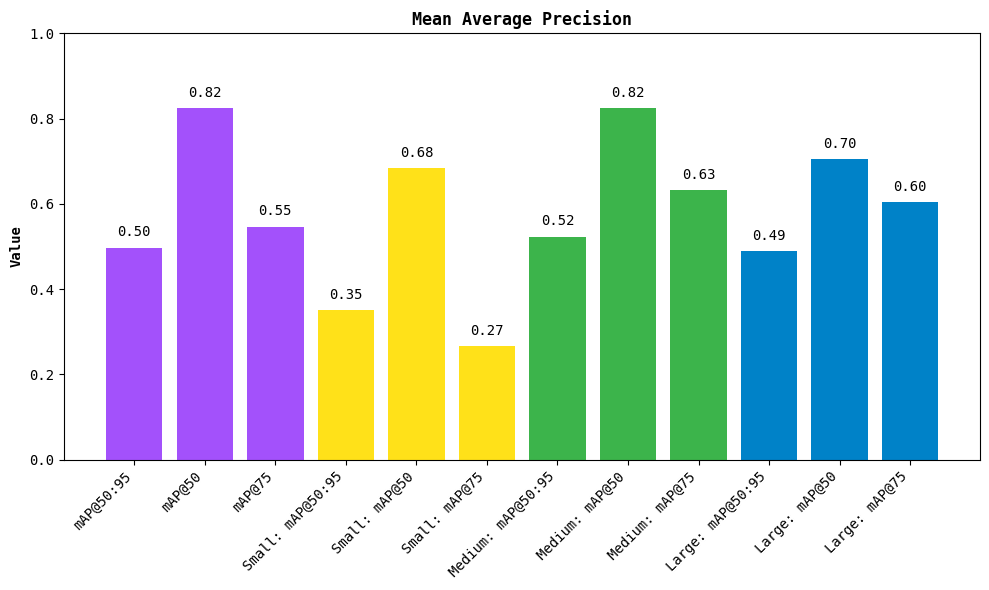
按大小划分的性能
YOLOv12还提供了按对象大小(如小、中、大)划分的性能指标。这有助于了解模型在检测不同大小坑洞时的表现。
实验结果表明,YOLOv12在所有尺寸的坑洞检测上都表现良好,其中对中等大小坑洞的检测性能最佳,这可能是由于中等大小的坑洞在尺寸、形状和可见性方面更为一致。
代码示例
在部署Gradio坑洞检测应用程序之前,回顾构成该管道的关键组件。代码库被清晰地组织为独立的模块化脚本,分别用于模型加载、实用函数、核心检测逻辑和前端界面。
模型加载器(model_loader.py)
import os
from ultralytics import YOLOdef load_model(model_path=None):model_path = model_path or os.getenv("MODEL_PATH", "fine_tuned_yolov12/best.pt")if not os.path.exists(model_path):raise FileNotFoundError(f"模型文件未在以下路径找到:{model_path}")return YOLO(model_path)
该脚本负责YOLOv12模型的加载。首先导入必要的模块并定义load_model函数。若未明确提供路径,函数会尝试从环境变量MODEL_PATH加载模型,默认路径为本地目录。若文件不存在,将引发FileNotFoundError。否则,将初始化并返回基于Ultralytics API的YOLO模型实例。
实用函数(utils.py)
def get_severity_with_position(area, y_center, frame_height, alpha=0.6):vertical_position_norm = y_center / frame_heightnormalized_area = area / (frame_height * frame_height)score = alpha * normalized_area + (1 - alpha) * vertical_position_normif score < 0.2:return "Low"elif score < 0.4:return "Medium"else:return "High"
该函数通过面积和垂直位置的加权组合估计坑洞严重程度。对边界框面积和坑洞质心的垂直位置进行归一化处理。最终的严重程度分数是使用alpha参数(默认值为0.6)的加权平均值。根据此分数,坑洞被分为“低”、“中”或“高”严重程度。
def is_video_file(path):return isinstance(path, str) and path.endswith((".mp4", ".avi", ".mov"))
该辅助函数通过检查文件扩展名确定给定路径是否对应视频文件,有助于在应用程序中处理输入类型逻辑。
检测逻辑(pothole_detector.py)
import cv2
from pyimagesearch.model_loader import load_model
from pyimagesearch.utils import get_severity_with_position, is_video_file# 加载预训练模型
model = load_model()
该代码块首先导入必要的组件。cv2用于通过OpenCV进行图像和视频处理。然后导入三个自定义模块:
load_model:加载YOLOv12检查点get_severity_with_position:基于大小和位置估计坑洞严重程度is_video_file:识别输入类型
模型在顶层仅加载一次,避免在每次函数调用时重新加载,以确保更快的推理速度。
def draw_boxes_and_severity(frame, boxes):for x1, y1, x2, y2 in boxes:area = (x2 - x1) * (y2 - y1)y_center = (y1 + y2) / 2frame_height = frame.shape[0]severity = get_severity_with_position(area, y_center, frame_height)cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)cv2.putText(frame, severity, (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)return frame
该函数将边界框和严重程度标签叠加到帧上。对于每个边界框,计算其面积和垂直中心,然后调用get_severity_with_position函数确定严重程度级别(“低”、“中”或“高”)。使用OpenCV的矩形方法绘制边界框,标签通过putText直接渲染在框的左上角上方。
主检测器函数
def pothole_detector(input_media):if input_media is None:return None, None
首先检查是否提供输入。若未提供,返回None以防止应用程序崩溃。
if is_video_file(input_media):cap = cv2.VideoCapture(input_media)if not cap.isOpened():raise ValueError(f"打开视频文件时出错:{input_media}")width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = cap.get(cv2.CAP_PROP_FPS)output_video_path = "output_detected.mp4"fourcc = cv2.VideoWriter_fourcc(*"mp4v")out = cv2.VideoWriter(output_video_path, fourcc, fps, (width, height))
该代码块处理使用OpenCV进行视频输入处理所需的初始化和设置。函数首先通过辅助函数is_video_file检查上传的文件是否为视频文件。若是视频,使用cv2.VideoCapture()加载视频。为确保文件有效且可读,检查捕获对象是否成功打开。若未打开,引发ValueError并显示相应消息。
视频成功打开后,通过OpenCV的属性获取器获取基本元数据(如宽度、高度和每秒帧数(FPS))。这些值用于编码和保存输出视频。使用cv2.VideoWriter设置输出写入器,指定编解码器(mp4v)、帧大小和FPS以匹配输入视频。输出将保存为"output_detected.mp4",用于存储带有坑洞注释的处理后帧。
frame_idx = 0while cap.isOpened():ret, frame = cap.read()if not ret or frame is None or frame_idx > fps * 10:breakresults = model.predict(frame, conf=0.4, classes=[0], verbose=False)boxes = results[0].boxes.xyxy.cpu().numpy() if results and results[0].boxes else []frame = draw_boxes_and_severity(frame, boxes)out.write(frame)frame_idx += 1cap.release()out.release()return input_media, output_video_path
此部分实现对上传视频的逐帧推理和处理。frame_idx变量用于跟踪已处理的帧数。只要视频捕获对象处于打开状态,循环就会持续运行。在循环内部,使用cap.read()读取每个帧。若无法读取帧(因视频结束或读取错误),或已处理超过10秒的内容(frame_idx > fps * 10),则循环中断。10秒的上限设置有助于避免在大型视频文件上进行长时间或繁重的处理。
每个有效帧通过YOLOv12模型进行推理,调用model.predict()函数,其中模型被设置为仅检测类别0(假定为坑洞类别),置信度阈值为0.4。提取检测到的边界框,并将其与draw_boxes_and_severity()函数一起使用,该函数将边界框和严重程度标签叠加到帧上。
处理后的帧通过out.write()写入输出视频文件,同时帧索引递增。所有帧处理完毕或循环中断后,释放视频捕获(cap)和写入器(out)对象以释放系统资源。最后,函数返回输入视频路径和包含注释结果的新生成输出视频的路径。
else:img = cv2.imread(input_media)if img is None:return None, Noneresults = model.predict(img, conf=0.4, classes=[0], verbose=False)boxes = results[0].boxes.xyxy.cpu().numpy() if results and results[0].boxes else []img = draw_boxes_and_severity(img, boxes)output_image_path = "output_detected.jpg"cv2.imwrite(output_image_path, img)return input_media, output_image_path
此else块处理上传文件为图像的情况。使用cv2.imread()读取图像。若加载失败(即返回None),函数提前退出,返回包含None值的元组,表示输入处理失败。
图像成功加载后,通过YOLOv12模型进行推理。调用predict()方法,置信度阈值设为0.4,且仅限于检测类别0(坑洞)。从结果中提取边界框,格式为(x1, y1, x2, y2)。然后将这些边界框传递给draw_boxes_and_severity()函数,该函数使用边界框和严重程度标签对图像进行注释。
Gradio界面(app.py)
import gradio as gr
from pyimagesearch.pothole_detector import pothole_detector# 导入Gradio和坑洞检测器函数。这是Web界面的入口点。input_file = gr.File(label="上传图像或视频")
output_preview_image = gr.Image(label="检测到的图像输出", interactive=False, visible=False)
output_preview_video = gr.Video(label="检测到的视频输出", interactive=False, visible=False)
output_download = gr.File(label="下载输出", interactive=True)
该代码块定义了Gradio应用程序的关键用户界面组件,支持用户交互式上传输入媒体、查看结果和下载处理后的输出。各组件细分如下:
input_file:文件上传部件,标签为“上传图像或视频”,允许用户上传模型将分析的图像或视频文件。input_preview:文件上传后,该组件显示上传内容的静态图像预览(针对图像文件)。设置interactive=False,表示用户无法直接操作此预览。output_preview_image:图像显示组件,标签为“检测到的图像输出”,用于显示图像处理后的输出。初始设置为visible=False,处理完成后再显示。output_preview_video:与图像输出类似,该部件用于显示带有检测结果叠加的视频。默认隐藏(visible=False),仅在输入为视频时显示。output_download:提供可下载的文件输出(带注释的图像或视频)。设置interactive=True,确保用户可直接点击下载结果。
这些组件共同构成了应用程序的核心视觉界面,方便用户上传文件、预览结果和下载最终输出。
with gr.Blocks() as iface:gr.Markdown("## 坑洞检测与严重程度估计 (YOLOv12)")with gr.Row():with gr.Column():input_file.render()input_preview.render()with gr.Column():output_preview_image.render()output_preview_video.render()output_download.render()
该代码块使用gr.Blocks()创建Gradio界面的布局。以描述应用程序的Markdown标题开始。在内部定义两列布局:左列包含用于上传图像或视频及预览输入的组件;右列显示检测输出(图像或视频)并提供下载链接。这种布局清晰分离了输入和结果区域,提供更流畅的用户体验。
input_file.change(fn=pothole_detector,inputs=input_file,outputs=[input_preview, output_preview_image, output_preview_video, output_download])
该块定义了当用户上传或更改Gradio应用程序中的输入文件时运行的逻辑。process_and_display函数首先检查是否提供输入——若未提供,隐藏所有输出。若检测到输入,运行pothole_detector函数获取输入和处理后的输出路径。
函数根据文件扩展名确定输入媒体是视频还是图像。若是视频,显示视频预览并隐藏图像预览;若是图像,显示图像预览并隐藏视频输出。这确保界面能根据媒体类型动态调整。
最后,input_file.change(...)方法将此逻辑绑定到文件输入字段,因此每次上传新文件时,都会自动运行检测并更新界面。
if __name__ == "__main__":iface.launch(server_name="0.0.0.0")
最后,应用程序启动并可通过本地网络访问,服务器名称设置为0.0.0.0。
运行与部署Gradio应用
完成上述代码编写后,我们可以通过运行app.py脚本启动Gradio界面,实现坑洞检测与严重程度评估的交互式体验。
启动应用
在终端中执行以下命令:
python app.py
运行成功后,终端会显示本地访问地址(通常为http://0.0.0.0:7860),在浏览器中打开该地址即可使用应用。
应用使用流程
- 上传媒体文件:点击“上传图像或视频”按钮,选择本地的图像(如
jpg、png格式)或视频(如mp4、avi格式)文件。 - 自动检测与处理:上传完成后,应用会自动调用YOLOv12模型进行检测,同时计算坑洞的严重程度。
- 查看结果:
- 若上传的是图像,右侧“检测到的图像输出”区域会显示带边界框和严重程度标签的结果图像。
- 若上传的是视频,右侧“检测到的视频输出”区域会显示处理后的视频,其中每个坑洞都被标注了边界框和严重程度。
- 下载结果:通过“下载输出”按钮可将处理后的图像或视频保存到本地。
总结与扩展
本教程详细介绍了使用YOLOv12实现坑洞检测与严重程度评估的完整流程,包括数据集准备、模型训练、检测逻辑实现和Gradio界面部署。通过结合边界框面积和垂直位置的加权评分策略,我们实现了对坑洞严重程度的快速分类。
主要成果
- 基于Roboflow的坑洞数据集微调了YOLOv12模型,使其能够准确检测图像和视频中的坑洞。
- 设计了简单有效的严重程度评估逻辑,通过归一化处理的面积和位置信息对坑洞进行分级。
- 构建了直观的Gradio界面,支持用户上传媒体文件并实时获取带注释的检测结果。
扩展方向
- 模型优化:
- 尝试使用更大的YOLOv12模型(如
yolov12-medium.pt、yolov12-large.pt)提升检测精度。 - 增加训练轮次(
epochs)或调整学习率,进一步优化模型性能。
- 尝试使用更大的YOLOv12模型(如
- 严重程度评估改进:
- 引入单目深度估计模型(如MiDaS)获取坑洞的实际距离,提高严重程度评估的准确性。
- 结合实例分割模型(如Mask R-CNN)获取坑洞的精确轮廓,替代边界框计算面积。
- 功能扩展:
- 增加批量处理功能,支持同时处理多个图像或视频文件。
- 加入坑洞计数和统计功能,输出检测到的坑洞数量及各严重程度的占比。
- 部署到云端或嵌入式设备,实现实时道路监控。