PySpark处理超大规模数据文件:Parquet格式的使用
本篇文章5 Things Every Data Scientist Should Know About Parquet in PySpark为数据科学家提供了关于Parquet格式在PySpark中的使用技巧,适合希望提升大数据处理效率的读者。文章的技术亮点在于强调了Parquet的压缩、列式存储和模式演化等优势,帮助用户优化数据存储和查询性能。
文章目录
- 1 数据集背景
- 1.1 写入Parquet文件
- 1.2. 读取Parquet文件
- 1.3. 分区以提高性能
- 1.4. 分桶(高级选项)
- 2 Parquet为何重要
- 3 实际比较
- 4 结论

作为一名数据科学家,我经常处理大到无法轻松载入内存的数据集。在我的PySpark学习初期,我使用CSV和JSON进行存储和交换;但很快意识到这些格式对于大规模分析来说效率低下。查询速度慢,文件大小臃肿,并且模式管理不一致。
直到我开始使用 Parquet,一切才豁然开朗。Parquet是一种为分布式系统设计的列式存储格式,提供压缩、高效编码和模式演变。在PySpark中,它是大数据存储的默认选择,但许多数据科学家并没有充分探索在读写Parquet文件时可用的选项。
在本文中,我将展示如何在PySpark中使用Parquet,内容涵盖:
- 为什么Parquet在大数据工作流中更受欢迎。
- 如何使用不同的模式和压缩方式写入Parquet文件。
- 如何处理模式读取Parquet文件。
- 分区和分桶如何影响性能。
到最后,你将清楚地理解在PySpark中写入和读取Parquet文件到底意味着什么,以及如何控制这个过程。
1 数据集背景
为了演示,我将使用一个合成的书籍数据集(已扩展为更大的集合,使其感觉真实)。
Jupyter Notebook Cell: 创建数据集
from pyspark.sql import SparkSession
import randomspark = SparkSession.builder.appName("PySpark Parquet Guide").getOrCreate()authors = [ "Stephen Hawking", "Richard Dawkins", "Yuval Noah Harari", "Neil deGrasse Tyson", "Jared Diamond", "Siddhartha Mukherjee", "Carl Sagan", "Charles Darwin",
]
titles = [ "A Brief History of Time", "The Selfish Gene", "Sapiens", "Astrophysics for People in a Hurry", "Guns, Germs, and Steel", "The Gene", "Cosmos", "Homo Deus", "The Blind Watchmaker", "The Origin of Species",
]rows = [ ( random.choice(titles), random.choice(authors), random.randint(1800, 2022), round(random.uniform(3.5, 5.0), 2), random.randint(1000, 2000000), ) for _ in range(100000)
]df = spark.createDataFrame( rows, schema=["Title", "Author", "Year", "Avg_Rating", "Total_Ratings"]
)
df.show(5)
print("Dataset size:", df.count())
输出:
1.1 写入Parquet文件
将DataFrame写入Parquet很简单:
df.write.parquet("books_parquet")
但选项很重要。PySpark允许你控制数据写入的方式。
- 保存模式(Save Modes):
"error"(默认):如果路径存在则失败。"overwrite":替换现有数据。"append":添加新数据。"ignore":如果路径存在则不执行任何操作。
df.write.mode("overwrite").parquet("books_parquet_overwrite")
- 压缩(Compression):
Parquet支持"snappy"、"gzip"、"brotli"等编解码器。
Snappy是默认选项,速度最快;Gzip和Brotli提供更高的压缩率但写入速度较慢。
df.write.option("compression", "gzip").parquet("books_parquet_gzip")
1.2. 读取Parquet文件
读取同样简单:
df_parquet = spark.read.parquet("books_parquet")
df_parquet.show(5)
输出:
PySpark会自动从文件中推断模式。你还可以:
- 合并模式(Merge schema): 当文件具有演变模式时非常有用。
df_parquet = spark.read.option("mergeSchema", "true").parquet( "books_parquet", "books_parquet_gzip"
)
- 显式模式(Explicit schema): 无论文件内容如何,都强制执行一致的模式。
from pyspark.sql.types import ( StructType, StructField, StringType, IntegerType, DoubleType,
)schema = StructType( [ StructField("Title", StringType(), True), StructField("Author", StringType(), True), StructField("Year", IntegerType(), True), StructField("Avg_Rating", DoubleType(), True), StructField("Total_Ratings", IntegerType(), True), ]
)df_parquet_schema = spark.read.schema(schema).parquet("books_parquet")
1.3. 分区以提高性能
分区根据列值将数据拆分为子目录。这允许Spark在过滤时修剪分区(跳过文件),从而加快查询速度。
df.write.partitionBy("Year").parquet("books_partitioned")
仅查询相关分区:
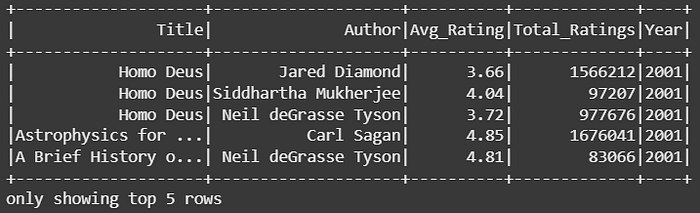
df_partitioned = spark.read.parquet("books_partitioned")df_partitioned.filter(df_partitioned["Year"] > 2000).show(5)
输出:
1.4. 分桶(高级选项)
分桶基于列哈希将行分布到固定数量的桶中。这有助于处理大型数据集上的连接。
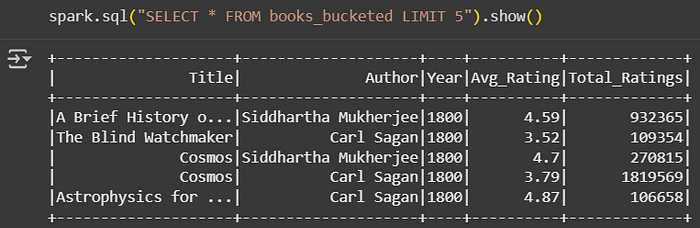
df.write.bucketBy(8, "Author").sortBy("Year").saveAsTable("books_bucketed")
注意:分桶需要Spark中启用Hive支持。
2 Parquet为何重要
与CSV或JSON相比,Parquet提供:
- 由于压缩,文件更小。
- 由于只扫描相关列(列式格式),读取速度更快。
- 模式演变和元数据存储。
在大规模工作流中,这些优势转化为更低的存储成本和更快的查询。
3 实际比较
以下是我在测试10万行不同格式时观察到的结果:
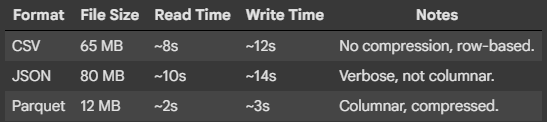
4 结论
作为一名数据科学家,我发现充分理解PySpark中的Parquet改变了我设计数据管道的方式。我不再将其视为另一种文件格式,而是学会了如何利用:
- 保存模式进行安全写入。
- 压缩选项权衡空间与速度。
- 模式管理处理演变的数据集。
- 分区和分桶进行查询优化。
这些技术使Parquet不仅成为PySpark中的_默认_选择,更是可扩展、可维护和高效数据科学工作流的_最明智_选择。