结合图像-文本信息与特征解纠缠的多标签广义零样本胸部X射线分类|文献速递-最新医学人工智能文献
Title
题目
Multi-Label Generalized Zero Shot Chest X-RayClassification by Combining Image-TextInformation With Feature Disentanglement
结合图像-文本信息与特征解纠缠的多标签广义零样本胸部X射线分类
01
文献速递介绍
基于全监督的深度学习方法 基于全监督的深度学习方法在各类医学图像分析任务中展现出最优(SOTA)性能,例如糖尿病视网膜病变分级[15]和胸部X射线诊断[19]。全监督方法之所以能成功,关键在于其在训练过程中能够接触到所有类别。然而,在放射学工作流程中,可能会遇到以往未见过的疾病类型,例如新冠病毒的新毒株,或是组织病理学数据中出现的新肿瘤类型。因此,在传统全监督方法中,新的疾病亚型会被错误分类到以往见过的某一类别中。除了这类不利的误分类问题外,深度学习分类系统对新类别的适应性不足,还可能导致临床部署的人工智能系统需要经历漫长的重新认证流程。 与之相反,自监督学习提供了一种不完全依赖标签数据的范式,有望提升模型对未见过类别的泛化能力。通过从未标记数据中学习丰富的特征表示,自监督学习方法[4]、[5]能够为监督学习方法提供补充——无需明确的先验知识,就能对新类别形成初步认知[48]。但需注意的是,尽管自监督学习能缓解未标记数据和未见过数据带来的部分挑战,它通常仍需后续使用标记数据进行微调才能达到最优性能;而在新类别数据稀缺或无法获取的场景中,这种微调往往难以实现。 零样本学习(ZSL)旨在利用已见类别的可用特征,学习未见过类别的合理表示。在更广义的场景中,我们期望在测试阶段同时遇到已见类别和未见过类别,这就是广义零样本学习(GZSL)的应用场景,该任务的挑战性更高。以往针对医学图像的广义零样本学习研究,大多聚焦于单标签场景——即一幅图像仅对应一个疾病类别[34]、[32]、[39]。但胸部X射线(CXR)数据集的图像往往带有多个标签,单标签方法在这种场景下表现不佳。文献[16]提出了一种多标签广义零样本学习方法,用于预测胸部X射线图像中的多种已见和未见过疾病。该方法将视觉模态和语义模态均映射到一个潜在特征空间,并借助从医学文本语料库中提取的输入对应语义,来学习视觉表示。然而,在外部NIH胸部X射线数据集[50]上,该方法在已见类别(0.79)和未见过类别(0.66)的AUROC值方面表现欠佳,这可能是由于对文本和影像数据的利用不够优化所致。为此,我们提出一种多标签广义零样本学习方法,该方法利用编码文本和影像信息的多模态字典,对多种疾病标签间的语义关系进行编码,从而能够学习到精度更高的特征表示,而这种表示在合成特征生成过程中发挥着重要作用。 与用于广义零样本学习的医学图像数据集不同,自然图像领域广义零样本学习的数据集具有一项优势:它们为所有类别提供了属性向量,使得模型能够建立属性向量与已见类别对应特征表示之间的关联。而要为医学图像定义明确的属性向量,不仅需要深厚的临床专业知识,还需投入大量时间对放射学图像进行标注。在多标签场景下,这种复杂性进一步加剧——许多疾病的外观和纹理具有相似性。在我们之前的研究[34]中,曾提出一种不依赖属性向量的广义零样本学习方法:该方法以SwAV[8]这一基线聚类方法为基础,并融入基于自监督学习的额外约束,以实现单标签广义零样本学习。但多标签广义零样本学习的主要挑战在于,如何生成融合多种标签特征的特征向量。这一任务难度较大,因为它需要在类别特定特征(class-specific features)和类别无关特征(class-agnostic features)之间实现恰当的解纠缠。为应对这一具有挑战性的特征生成问题,我们在研究[34]的基础上,针对多标签广义零样本学习提出以下创新点: 1)提出一种新颖的特征解纠缠方法,将给定图像分解为类别特定特征和类别无关特征。对于多标签问题而言,这一步骤至关重要,因为此类问题需要对类别特定特征进行精准组合。 2)对类别特定特征应用图聚合(graph aggregation),基于不同标签在全局范围内的相互作用,学习一种基于图像特征的多标签字典。这有助于实现更具区分性的特征学习,并为更优的多标签特征合成提供支持。 3)学习不同疾病类别文本嵌入(text embeddings)之间的语义关系,并利用这一知识指导真实特征向量的生成,确保多种疾病标签间的语义关系得以保留。
Aastract
摘要
In fully supervised learning-based medical**image classification, the robustness of a trained modeldepends on its exposure to various disease classes. Generalized Zero Shot Learning (GZSL) aims to predict both seenand novel unseen classes. While most GZSL approachesfocus on single-label cases, chest X-rays often have multipledisease labels. We propose a novel multi-modal multi-labelGZSL approach that leverages feature disentanglement andmulti-modal information to synthesize features of unseenclasses. Disease labels are processed through a pre-trainedBioBert model to obtain text embeddings, which create adictionary encoding similarity among labels. We use disentangled features and graph aggregation to learn a seconddictionary of inter-label similarities, followed by clusteringto identify representative vectors for each class. Thesedictionaries and representative vectors guide the featuresynthesis step, generating realistic multi-label disease samples of seen and unseen classes. Our method outperformscompeting methods in experiments on the NIH and CheXpert chest X-ray datasets.Index Terms—Multi-label, GZSL, text embeddings, chestx-rays, feature synthesis, disentanglement.
在基于全监督学习的医学图像分类中,训练后模型的鲁棒性取决于其对各类疾病类别的接触程度。广义零样本学习(GZSL)旨在对已见类别(seen classes)和未见过的新类别(novel unseen classes)均进行预测。尽管大多数广义零样本学习方法聚焦于单标签场景,但胸部X射线图像往往带有多个疾病标签。 为此,我们提出一种新颖的多模态多标签广义零样本学习方法,该方法利用特征解纠缠(feature disentanglement)和多模态信息来合成未见过类别的特征。具体而言,通过预训练的BioBert模型对疾病标签进行处理以获取文本嵌入(text embeddings),进而构建一个编码标签间相似性的字典;利用解纠缠特征和图聚合(graph aggregation)学习第二个标签间相似性字典,随后通过聚类为每个类别确定代表性向量。这些字典与代表性向量将指导特征合成步骤,生成已见类别和未见过类别的真实多标签疾病样本。 在NIH和CheXpert胸部X射线数据集上的实验表明,我们的方法性能优于其他对比方法。 关键词——多标签、广义零样本学习(GZSL)、文本嵌入、胸部X射线、特征合成、解纠缠
Method
方法
A. Method Overview
Figure 1 depicts the proposed workflow. Let us denote agiven image as xi and the corresponding latent representationis denoted as zi . The corresponding encoder for class Lis denoted as El and the decoder is denoted as G**l . Ourmethod consists of the following stages: 1) Image featuredisentanglement to get class-specific component, z i specl forclass l, and a class-agnostic component, z i agnl from the originallatent vector zi using LDisent (Eqn. 1); 2) Creating two multilabel dictionaries, DictSpe (from class specific image features)and DictT ext using text embeddings of disease labels. Theclass-specific features are used to learn more global relationship between label features, whereas the text embeddings fordifferent labels are obtained from BioBert [27]; 3) Clusteringof seen and unseen class samples using LM L−Seen in Eqn 7and LM L−All in Eqn.8 to obtain class centroids that functionas class representative vectors. LM L−Seen is the differencebetween DicSpe and centroid of seen classes and definedin Eq. 7. LM L−All is the difference between DicT ext andcentroids of all classes and is defined in Eq. 8. Both are part ofthe clustering step.; 4) Feature synthesis to generate multi-labelfeatures of different label combinations using Eqn.13. The centroid vectors are used as reference vectors for feature synthesis.The synthesized vectors are compared with the centroids usingLM L−Syn defined in Eq. 12 to determine whether they belongto the desired classes; 5) Training a classifier to identify thecorrect set of labels for each test image (Eqn.14). Synthesizedand real features of unseen and seen classes are used to traina multi-label classifier. Different from [34] we propose novelloss functions introduced in the clustering stage (Eqns. 7,8).The feature synthesis stage (Step 4) is similar to [34], but weuse a completely different loss function (Eqn. 12) for multilabel considerations.
A. 方法概述 图1展示了所提方法的工作流程。我们将给定图像记为(x_i),其对应的潜在表示记为(z_i);类别(L)对应的编码器记为(E_l),解码器记为(G_l)。该方法包含以下阶段: 1. 图像特征解纠缠:利用解纠缠损失(L{Disent})(公式1),从原始潜在向量(z_i)中分离出类别特定分量(针对类别(l)的(z{i,\text{spec}}^l))和类别无关分量((z{i,\text{agn}}^l)); 2. 构建两个多标签字典:分别构建(\text{Dict}{Spe})(基于类别特定图像特征)和(\text{Dict}{Text})(基于疾病标签的文本嵌入)。其中,类别特定特征用于学习标签特征间更具全局性的关系,而不同标签的文本嵌入则通过BioBert模型[27]获取; 3. 已见与未见类别样本聚类:利用公式7中的(L{ML-Seen})和公式8中的(L{ML-All})对已见类别和未见类别样本进行聚类,得到作为类别代表性向量的类别质心。(L{ML-Seen})表示(\text{Dic}{Spe})与已见类别质心的差异(定义见公式7),(L{ML-All})表示(\text{Dic}{Text})与所有类别质心的差异(定义见公式8),二者均属于聚类步骤; 4. 特征合成:通过公式13生成不同标签组合的多标签特征。将质心向量作为特征合成的参考向量,利用公式12定义的(L{ML-Syn})将合成向量与质心进行比对,判断合成向量是否属于目标类别; 5. 分类器训练:训练分类器以识别每张测试图像的正确标签集(公式14)。训练过程采用已见类别和未见类别的真实特征与合成特征。 与文献[34]相比,本文的创新点在于:在聚类阶段提出了新的损失函数(公式7、8);特征合成阶段(步骤4)虽与文献思路相似,但针对多标签场景,采用了完全不同的损失函数(公式12)。
Conclusion
结论
We propose a multi-label GZSL approach for chest xrayimages. Our novel method can accurately synthesize featurevectors of unseen classes by learning multi-modal multi-labeldictionary using graph aggregation and class-specific features,along with text embedding relationships. Experimental resultsshow our method outperforms other recent GZSL approachesin literature, and is consistently better across multiple publicCXR datasets. Our approach is useful in scenarios where thenumber of disease classes are known but labeled samples of allclasses cannot be accessed due to the infrequent occurrenceof such cases or lack of expert clinicians to annotate complex cases. While fully supervised settings still provide thebest performance, they are dependent upon sufficient labeledsamples.
我们提出一种针对胸部X射线图像的多标签广义零样本学习(multi-label GZSL)方法。该创新方法通过以下方式实现对未见类别特征向量的精准合成:利用图聚合(graph aggregation)与类别特定特征,结合文本嵌入(text embedding)关系,学习多模态多标签字典。 实验结果表明,该方法性能优于文献中其他近期广义零样本学习方法,且在多个公开胸部X射线数据集上均展现出稳定的优势。对于“已知疾病类别数量,但因部分疾病发病率低或缺乏专业临床医生标注复杂病例,导致无法获取所有类别的带标签样本”的场景,该方法具有实际应用价值。尽管全监督场景仍能提供最优性能,但其依赖于充足的带标签样本。
Results
结果
We also show in Table VI results on the multi-classMedMNIST dataset [57] due to its balanced and standardized datasets spanning across various modalities. Theimages in the dataset have one label out of multiple possible labels. We select subsets of the collection appropriatefor multi-class disease classification, namely, BreastMNIST having 546/78/156 breast ultrasound images in thetraining/validation/test split for malignancy detection, RetinaMNIST [29] having 1080/120/400 training/validation/testfundus images for diabetic retinopathy severity grading,and TissueMNIST having 165, 466/23, 640/47, 280 training/validation/test Kidney Cortex Microscope images formultiple disease classification. The results show clearly thatour approach outperforms other competing methods for themulti-class setting where images can have only one label outof multiple possible labels.
我们还在表6中展示了在“多类别”MedMNIST数据集上的结果,选用该数据集是因其涵盖多种模态,且数据平衡、标准化。该数据集的图像在多个可能的标签中仅对应一个标签。我们从数据集中选取了适用于多类别疾病分类的子集,即: - BreastMNIST[2](乳腺超声图像数据集):用于恶性肿瘤检测,训练集/验证集/测试集分别包含546/78/156张图像; - RetinaMNIST[29](眼底图像数据集):用于糖尿病视网膜病变严重程度分级,训练集/验证集/测试集分别包含1080/120/400张图像; - TissueMNIST(肾皮质显微镜图像数据集):用于多种疾病分类,训练集/验证集/测试集分别包含165,466/23,640/47,280张图像。 结果清楚表明,在“图像仅对应多个可能标签中的一个”这一多类别场景下,我们的方法性能优于其他竞争方法。
Figure
图
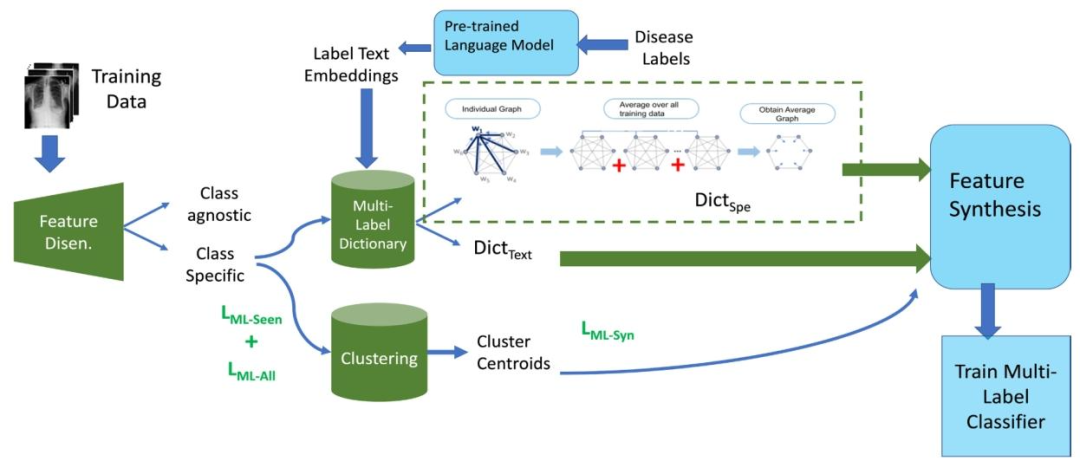
Fig. 1. Workflow of the proposed method. Training data goes through a feature disentanglement stage, followed by multi-modal and multi-labeldictionary learning and clustering, feature synthesis and training of a multi-label classifier. Our novel contributions and loss functions are highlightedas green blocks and letters. Dic**Spe is the dictionary created from class specific features of seen classes and DicText is the dictionary obtained fromlabel texts. LML-Seen is the difference between DicSpe and centroid of seen classes and defined in Eq. 7. LML-All is the difference between DicTextand centroids of all classes and is defined in Eq. 8. Both are part of the clustering step. LML-Syn is defined in Eq. 12 and is part of the featuregeneration step
图1 所提方法的工作流程 训练数据依次经过以下阶段:特征解纠缠阶段、多模态与多标签字典学习及聚类阶段、特征合成阶段,最终用于多标签分类器的训练。 本文的创新点与损失函数分别以绿色模块和绿色字母突出显示。其中,DicSpe 是基于已见类别的类别特定特征构建的字典,Dic**Text 是从标签文本中获取的字典;LML-Seen 表示 Dic**Spe 与已见类别质心的差异(定义见公式7),LML-All 表示 DicText 与所有类别质心的差异(定义见公式8),二者均属于聚类步骤;LML-Syn(定义见公式12)属于特征生成步骤。
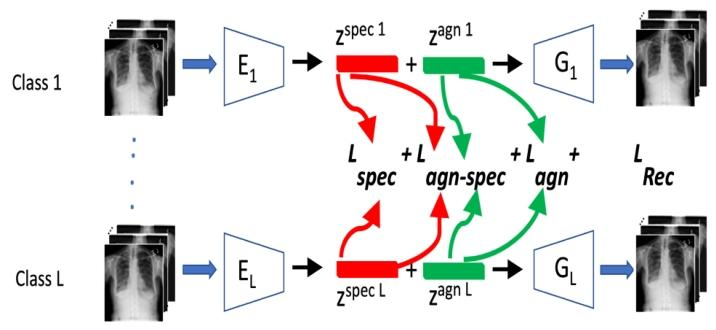
Fig. 2. Architecture of class specific feature disentanglement network.Given training images from different classes of the same domain,we disentangle features into class-specific and class-agnostic usingautoencoders. The different feature components are used to define thedifferent loss terms
图2 类别特定特征解纠缠网络的架构 输入来自同一领域不同类别的训练图像,通过自编码器(autoencoders)将特征解纠缠为类别特定特征(class-specific features)与类别无关特征(class-agnostic features)。分离得到的不同特征分量用于定义不同的损失项。
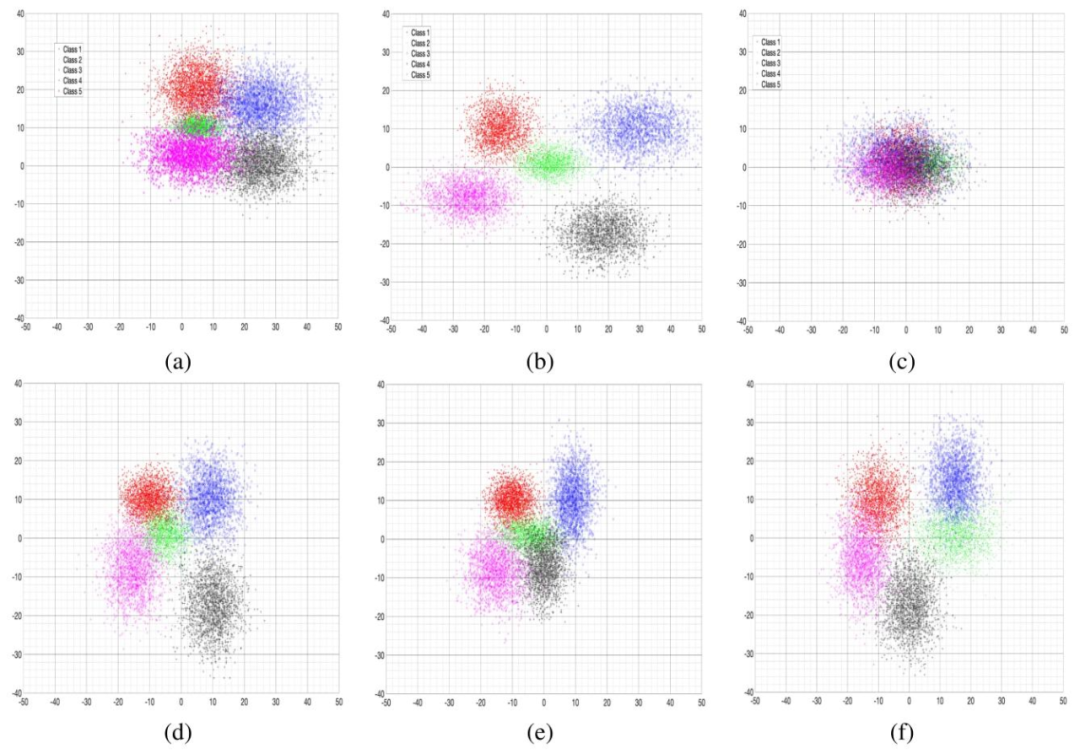
Fig. 3. T-sne results comparison between original image features and feature disentanglement output. (a) Original image features; (b) Classspecific features; (c) Class agnostic features. Visualizations of synthetic features for: (d) ML-GZSLw /o Lspec ; (e) ML-GZSLw /o LML-Seen ; (f) MLGZSLw /o LML-All
图3 原始图像特征与特征解纠缠输出的t-SNE结果对比 (a)原始图像特征;(b)类别特定特征;(c)类别无关特征。 以下为合成特征的可视化结果:(d)未使用(L{spec})的多标签广义零样本学习(ML-GZSL);(e)未使用(L{ML-Seen})的多标签广义零样本学习(ML-GZSL);(f)未使用(L_{ML-All})的多标签广义零样本学习(ML-GZSL)
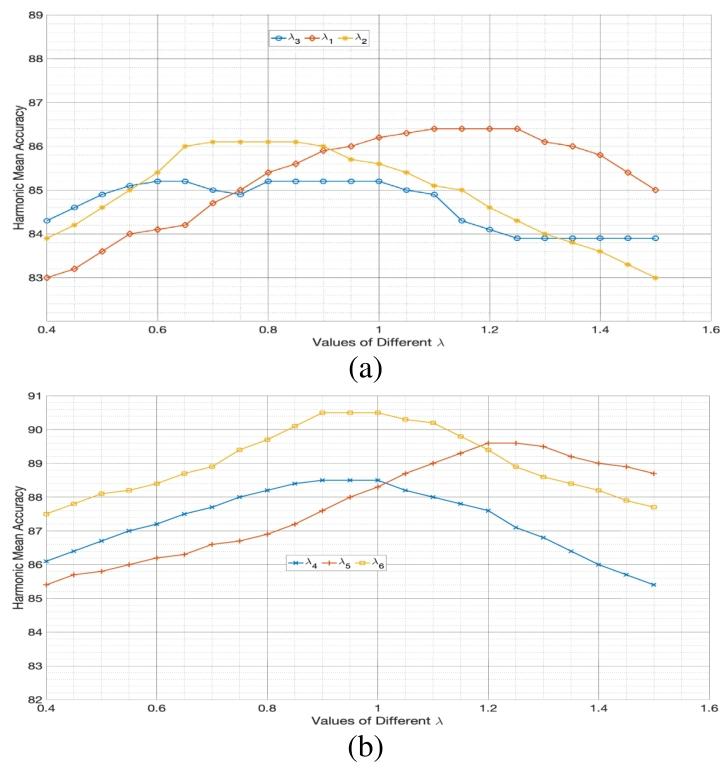
Fig. 4. Hyperparameter Plots showing the value of H and classificationaccuracy for different values of λ. The observed trends justify our finalchoice of the values.
图4 超参数曲线图 该图展示了不同λ值对应的调和平均准确率(H)与分类准确率。所观察到的趋势为我们最终选择λ值提供了依据。
Table
表
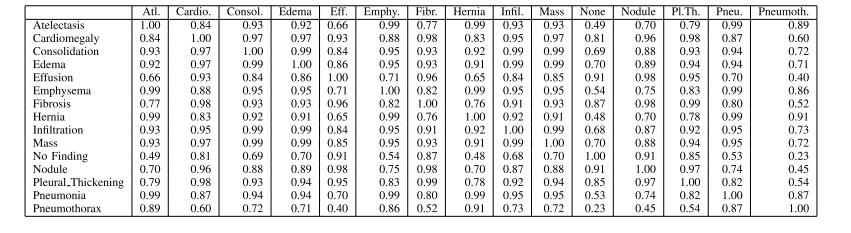
Table i table showing the cosine similarity values of the labels’ biobert embeddings (seed value=1367). this information is used to guide the clustering and feature generation stages
表1 标签的BioBert嵌入向量余弦相似度值(随机种子值=1367) 该信息用于指导聚类阶段与特征生成阶段
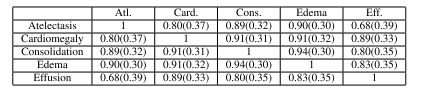
Table ii example of the multi-label similarity dictionary from saliency maps for seen classes only. this is an example dictionary for k=5 seen classes
表2 仅基于已见类别的显著图(saliency maps)构建的多标签相似度字典示例 此为K=5个已见类别对应的字典示例
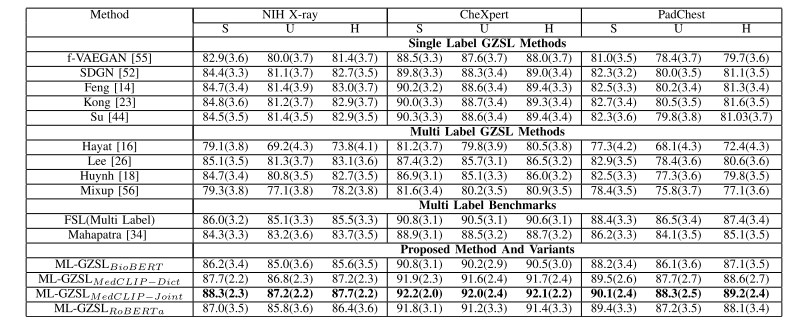
Table iii gzsl results for chest xray images in multi-label setting: average per-class classification accuracy (%) and harmonic mean accuracy (h) of generalized zero-shot learning when test samples are from seen or unseen classes. results demonstrate the superior performance of our proposed method. the fsl performance is the upper bound for a specific classifier. the best results are shown in bold
表3 多标签场景下胸部X射线图像的广义零样本学习(GZSL)结果 该表展示了测试样本分别来自已见类别和未见类别时,广义零样本学习的平均每类分类准确率(%)与调和平均准确率(H)。结果表明,所提方法性能更优。少样本学习(FSL)性能为特定分类器的性能上限。最优结果以粗体标出。
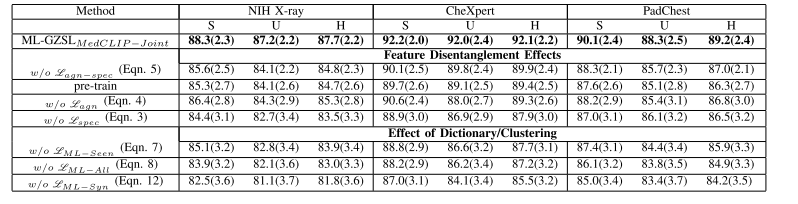
Table iv ablation results using ml-gzslmedclip −joint : average per-class classification accuracy (%) and harmonic mean accuracy (h) of generalized zero-shot learning when test samples are from seen (setting s) or unseen (setting u) classes. the best results are shown in bold
表4 基于ML-GZSLMedCLIP−Joint的消融实验结果 该表展示了测试样本来自已见类别(设置S)或未见类别(设置U)时,广义零样本学习的平均每类分类准确率(%)与调和平均准确率(H)。最优结果以粗体标出。
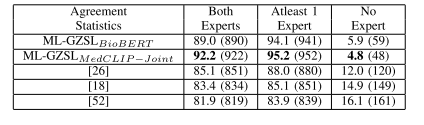
Table v agreement statistics on nih dataset for different gzsl methods amongst 2 radiologists. numbers outside the bracket indicate agreement percentage while numbers within brackets indicate actual numbers out of 1000 samples. the best results are shown in bold
表5 两种广义零样本学习(GZSL)方法在NIH数据集上的两位放射科医生一致性统计结果 括号外的数值表示一致性百分比,括号内的数值表示在1000个样本中对应的实际数量。最优结果以粗体标出。
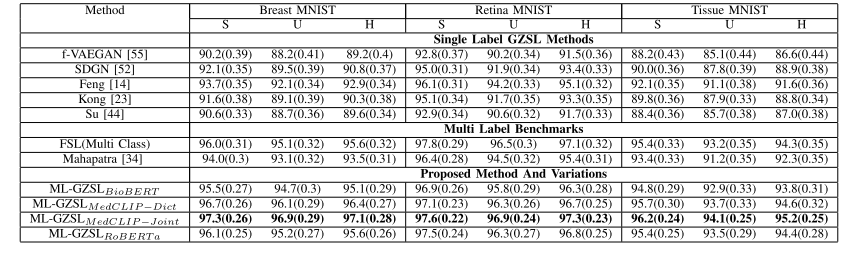
Table vi gzsl results for different subsets of medmnist dataset in single-label setting: average per-class classification accuracy (%) and harmonic mean accuracy (h) of generalized zero-shot learning when test samples are from seen or unseen classes. results demonstrate the superior performance of our proposed method. the fsl performance is the upper bound for a specific classifier. the best results are shown in bold
表6 单标签场景下MedMNIST数据集不同子集的广义零样本学习(GZSL)结果 该表展示了测试样本分别来自已见类别和未见类别时,广义零样本学习的平均每类分类准确率(%)与调和平均准确率(H)。结果表明,所提方法性能更优。少样本学习(FSL)性能为特定分类器的性能上限。最优结果以粗体标出。