【AI论文】3D与四维4D世界建模综述
摘要:世界建模已成为人工智能研究领域的基石,使智能体能够理解、表征并预测其所处动态环境。尽管先前的研究大多侧重于针对二维(2D)图像和视频数据的生成方法,却忽视了大量利用原生三维(3D)和四维(4D)表征(如RGB-D图像、占用网格和激光雷达点云)进行大规模场景建模的研究工作,且这类研究正日益增多。与此同时,由于缺乏对“世界模型”的标准化定义和分类体系,相关文献中的论述较为零散,有时甚至自相矛盾。本综述通过首次对三维和四维世界建模与生成进行全面详尽的回顾,填补了这些空白。我们给出了精确的定义,引入了涵盖基于视频(VideoGen)、基于占用(OccGen)和基于激光雷达(LiDARGen)方法的有条理的分类体系,并系统总结了针对三维/四维场景定制的数据集和评估指标。我们还进一步探讨了实际应用,指出了尚未解决的挑战,并强调了有前景的研究方向,旨在为推动该领域发展提供连贯且具有基础性的参考。现有文献的系统总结详见https://github.com/worldbench/survey。Huggingface链接:Paper page,论文链接:2509.07996
研究背景和目的
研究背景:
随着人工智能(AI)和机器人技术的快速发展,世界建模(World Modeling)已成为这些领域的基石,旨在使智能体能够理解、表示和预测其所在的动态环境。传统的世界建模方法主要集中于二维(2D)图像和视频数据的生成模型,如变分自编码器(VAEs)、生成对抗网络(GANs)、扩散模型(Diffusion Models)和自回归模型(Autoregressive Models)。然而,现实世界的场景本质上是三维(3D)的,并且是动态变化的,这要求模型能够利用原生的3D和4D表示形式,如RGB-D图像、占用网格(Occupancy Grids)和激光雷达(LiDAR)点云,来构建更加准确和鲁棒的世界模型。
尽管3D和4D世界建模的重要性日益凸显,但现有文献中缺乏对该领域的系统性综述,且“世界模型”这一术语在不同研究中存在不一致的使用。此外,与基于2D数据的方法相比,基于原生3D和4D表示的世界建模方法在独特挑战和机遇方面的探索仍然不足。因此,本研究旨在填补这一知识空白,通过系统地回顾和分析现有文献,为3D和4D世界建模提供一个全面的参考框架。
研究目的:
本研究的主要目的包括:
- 明确“世界模型”和“3D/4D世界建模”的定义:通过建立精确的定义,为研究社区提供一致性的术语和概念清晰度。
- 提出层次化的方法分类:根据表示形式(视频生成VideoGen、占用生成OccGen和激光雷达生成LiDARGen)对现有方法进行分类,并详细介绍每种方法的功能类型。
- 总结数据集和评估指标:系统总结用于3D和4D世界建模的常用数据集和评估指标,为实验比较提供基准。
- 探讨实际应用:识别3D和4D世界模型在自动驾驶、机器人技术和模拟环境中的实际应用。
- 讨论主要挑战和未来研究方向:指出当前方法的主要局限性,并强调未来研究的有希望方向,以推动该领域的持续创新。
研究方法
本研究采用文献综述的方法,系统地回顾和分析现有关于3D和4D世界建模的研究。具体步骤包括:
- 文献收集:通过学术数据库(如arXiv、IEEE Xplore、ACM Digital Library等)搜索与3D和4D世界建模相关的文献,重点关注近五年内发表的高影响力论文。
- 文献筛选:根据研究主题和相关性,筛选出符合条件的文献进行详细阅读和分析。
- 分类与归纳:根据文献中提出的方法和表示形式,将现有研究分为视频生成(VideoGen)、占用生成(OccGen)和激光雷达生成(LiDARGen)三类,并进一步细分为不同的功能类型。
- 数据集和评估指标总结:收集并整理用于3D和4D世界建模的常用数据集和评估指标,分析其特点和适用范围。
- 实际应用探讨:通过案例研究,探讨3D和4D世界模型在自动驾驶、机器人技术和模拟环境中的实际应用。
- 挑战与未来研究方向:分析当前方法的主要局限性,提出未来研究的有希望方向。
研究结果
1. 方法分类与功能类型:
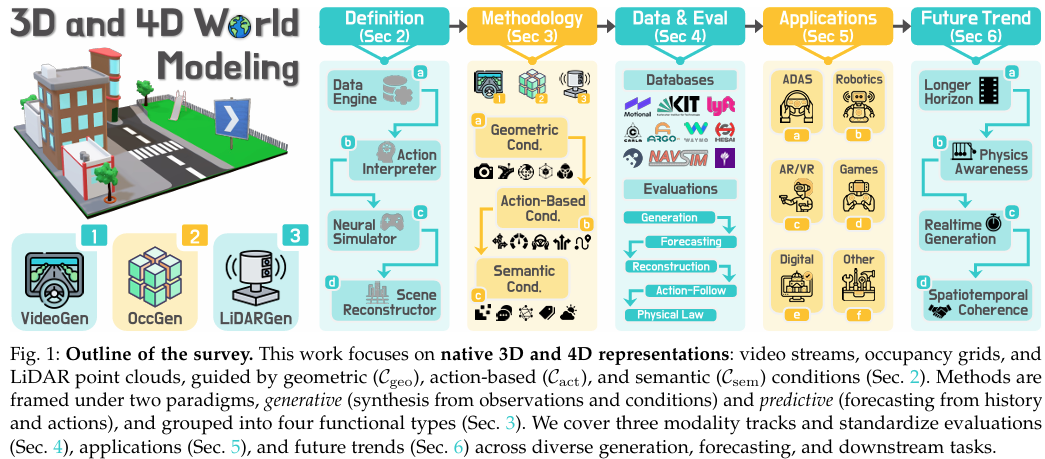
本研究将现有3D和4D世界建模方法分为视频生成(VideoGen)、占用生成(OccGen)和激光雷达生成(LiDARGen)三类,并进一步细分为数据引擎(Data Engines)、动作解释器(Action Interpreters)、神经模拟器(Neural Simulators)和场景重建器(Scene Reconstructors)四种功能类型。这种分类方法有助于比较不同方法的共同轴,如保真度、一致性、可控性和可扩展性。
2. 数据集和评估指标:
本研究总结了用于3D和4D世界建模的常用数据集和评估指标。数据集方面,包括nuScenes、KITTI、Waymo Open等真实世界数据集,以及CARLA、Occ3D-nuScenes等模拟数据集。评估指标方面,涵盖了生成质量(如FID、FVD)、预测质量(如IoU、L2误差)、规划中心质量(如碰撞率、轨迹误差)和重建中心质量(如PSNR、SSIM)等多个维度。
3. 实际应用:
通过案例研究,本研究展示了3D和4D世界模型在自动驾驶、机器人技术和模拟环境中的广泛应用。例如,在自动驾驶领域,世界模型可用于交通模拟、闭环驾驶评估和场景合成;在机器人技术领域,世界模型可支持导航、操作和模拟环境的生成;在视频游戏和XR领域,世界模型可实现程序化世界生成、沉浸式渲染和自适应环境。
4. 主要挑战:
当前3D和4D世界建模方法面临的主要挑战包括:
- 标准化基准测试的缺乏:现有研究常使用不同的数据集或临时指标,导致难以公平比较不同方法的性能。
- 长期生成的高保真度:短期预测可能足够准确,但长期预测中误差的累积会导致场景不一致。
- 物理真实性、可控性和泛化能力:现有模型常产生物理上不合理的场景,缺乏精细控制能力,且难以泛化到新环境。
- 计算效率和实时性能:现有方法常依赖重型架构和多步采样策略,导致显著延迟和内存开销。
- 跨模态生成的一致性:视觉、几何和语义模态之间的一致性难以保证,影响下游感知和规划任务的可靠性。
研究局限
尽管本研究系统地回顾了3D和4D世界建模的现有文献,但仍存在以下局限性:
- 文献覆盖范围有限:尽管努力收集全面文献,但仍可能遗漏某些相关研究,尤其是近期发表但尚未广泛传播的论文。
- 评估指标的主观性:不同研究可能使用不同的评估指标,导致难以直接比较不同方法的性能。
- 实际应用场景的局限性:案例研究主要集中于自动驾驶、机器人技术和模拟环境,可能忽略其他潜在应用领域。
- 技术细节的深度不足:由于篇幅限制,对某些技术细节的讨论可能不够深入,需要读者进一步查阅原始文献。
未来研究方向
针对现有研究的局限性和挑战,未来研究可进一步探索以下方向:
- 标准化基准测试和评估协议:建立统一的基准测试和评估协议,涵盖关键指标如物理合理性、时间一致性和可控性,以促进公平比较和确保模型的真实性能。
- 高保真度和长期生成:开发先进的生成技术,探索新的训练范式和记忆机制,有效惩罚长期偏差,实现可靠的长期模拟。
- 物理真实性、可控性和泛化能力:确保生成场景的物理合理性,提供精细控制能力,并增强模型对新环境和罕见对象的泛化能力。
- 计算效率和实时性能:优先研究稀疏计算和推理加速技术,实现准确、响应迅速且可扩展的世界模型。
- 跨模态生成的一致性:开发集成架构,联合学习多种传感器数据,同时强制执行严格的跨模态一致性约束,以准确建模现实驾驶环境中的动态交互。
通过不断探索这些方向,未来的3D和4D世界建模研究将能够更好地支持智能体在复杂动态环境中的理解和决策,推动AI和机器人技术的进一步发展。