Hadoop HDFS-高可用集群部署
作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
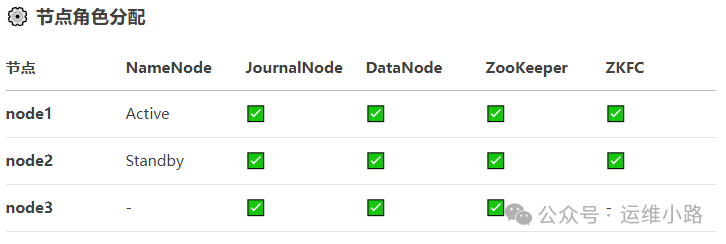
前面介绍高可用集群部署的几个组件,本小节就以常见的3节点来搭建一个高可用的HDFS集群。基于下面的规划来实现(实际为了简单,这里的ZooKeeper使用的单节点)。由于进程比较多,所以我这里给了每台机器8G内存,实际4G应该也可以。
1.准备ZooKeeper节点
由于zkfc依赖ZooKeeper,所以需要准备一个ZooKeeper集群,这里省略,可参考我的历史文章:ZooKeeper-单机部署&集群部署。
2.配置主机名&环境变量
由于HDFS依赖主机名进行通信,所以我们需要配置hosts和主机名。
#3台集群都需要配置
vi /etc/hosts192.168.31.161 node1
192.168.31.162 node2
192.168.31.163 node3#161执行
hostnamectl set-hostname node1
#162执行
hostnamectl set-hostname node2
#163执行
hostnamectl set-hostname node3vi /etc/profile#下面的内容具体以现场为准,3个节点都需要配置
export HADOOP_HOME=/root/hadoop-2.10.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64/jresource /etc/profile3.配置免密
由于hdfs很多通信还需要依赖ssh,所以我们还需要配置3个节点相互之间免密,我这里省略,可参考历史文章:Linux进阶-sshd。
4.配置文件core-site.xml
定义zk地址和临时文件目录,3个节点都需要。
vi ./etc/hadoop/core-site.xml
<configuration><!-- 指定HA逻辑名称和ZK地址 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property><name>ha.zookeeper.quorum</name><value>192.168.31.161:2181</value> <!-- 单机ZK地址 --></property><!-- 全局临时目录 --><property><name>hadoop.tmp.dir</name><value>/data/hadoop/tmp</value></property>
</configuration>5.配置文件hdfs-site.xml
这里就是规划里面的2个nn节点,3个jn节点,3个dn节点。数据目录(这个在生产上一个目录就是单独的一个盘,可以有多个),故障隔离(需要准备ssh免密文件,并且3个节点相互之间都需要免密,故障自动切换。
vi ./etc/hadoop/hdfs-site.xml <configuration><!-- HA集群定义 --><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- NN1配置 (192.168.31.161) --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>192.168.31.161:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>192.168.31.161:9870</value></property><!-- NN2配置 (192.168.31.162) --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>192.168.31.162:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>192.168.31.162:9870</value></property><!-- 存储目录 --><property><name>dfs.namenode.name.dir</name><value>file:///data/hadoop/nn</value></property><property><name>dfs.datanode.data.dir</name><value>file:///data/hadoop/dn</value></property><property><name>dfs.journalnode.edits.dir</name><value>/data/hadoop/jn</value></property><!-- JN集群 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://192.168.31.161:8485;192.168.31.162:8485;192.168.31.163:8485/mycluster</value></property><!-- 隔离机制 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 自动故障转移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property>
</configuration>6.创建目录&初始化&启动jn
由于我这里是为了演示,所以我这里直接使用的本地目录,真实环境这里还是建议单独的磁盘目录(主要是dn目录)。
由于jn启动的时候会生成文件内容,而共享初始化日志要求jn目录必须为空,所以这里必须要删除jn目录内容。这里尝试很多方法都没有办法跳过。
#创建目录 ,3个节点执行
mkdir -p /data/hadoop/{nn,dn,jn,tmp}#启动jn,3个节点执行
hadoop-daemon.sh start journalnode#格式化NameNode
#仅仅在node1执行
hdfs namenode -format#删除jn数据,3个节点执行
rm -rf /data/hadoop/jn/*#初始化共享编辑日志
#仅仅在node1执行
hdfs namenode -initializeSharedEdits7.启动nn
#node1执行
hadoop-daemon.sh start namenode用于 初始化 Standby NameNode。它的核心作用是从 Active NameNode 获取当前的元数据状态(fsimage 和 edits),为 Standby NameNode 建立初始的、与 Active 一致的命名空间,使其具备作为热备节点的能力。
#node2执行
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode8.启动zkfc
#初始化,node1执行
hdfs zkfc -formatZK#node1和node2执行
hadoop-daemon.sh start zkfc9.启动dn
#所有节点执行
hadoop-daemon.sh start datanode10.检查进程
[root@node1 ~]# jps
2368 JournalNode
2244 DataNode
1766 NameNode
2423 Jps
2060 DFSZKFailoverController
[root@node1 ~]# [root@node2 jn]# jps
2185 Jps
1739 NameNode
1261 JournalNode
1645 DFSZKFailoverController
2095 DataNode
[root@node2 jn]# [root@node3 ~]# jps
1363 Jps
1158 JournalNode
1277 DataNode
[root@node3 ~]#