计算机视觉 - 对比学习(上)MoCo + SimCLR + SWaV
在当今深度学习的浪潮中,对海量高质量标注数据的依赖已成为制约人工智能发展的关键瓶颈。如何让机器像人类一样,通过观察世界本身而非大量注释来学习知识,是通向更通用智能体的必经之路。自监督学习(Self-supervised Learning)正是在这一背景下成为研究焦点,而其中,对比学习(Contrastive Learning)无疑是最具影响力的方向之一。
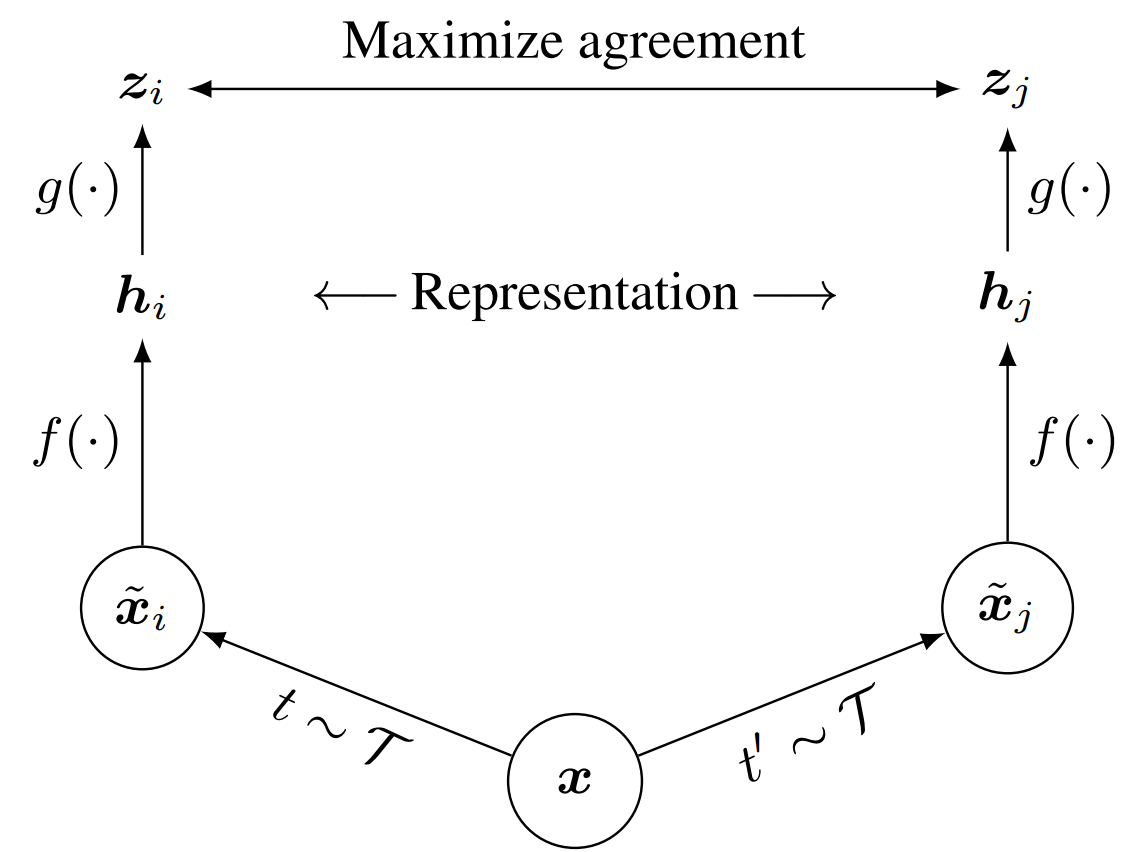
对比学习的核心思想源于一个直观的认知:同一事物的不同视角应具有相似的语义表征,而不同事物则应相距甚远。将这一理念转化为数学模型,催生了一系列开创性的工作。早期研究如InstDisc和CPC,开创了“个体判别”和“预测未来”等代理任务,验证了从无标注数据中学习高质量特征的可行性。
然而,真正的革命始于2019至2020年。MoCo(Momentum Contrast)通过引入动量编码器和队列式字典,巧妙地构建了一个庞大且一致的负样本库,解决了大规模对比学习的内存与一致性难题。几乎同时,SimCLR以一个看似简单的框架,结合极强的数据增强与非线性投影头,证明了“大力出奇迹”的惊人效果。它们的出现,首次在多个视觉任务上让无监督学习媲美甚至超越了有监督预训练模型。
此后,研究向着更高效、更智能的方向演进。SwAV(Swapping Assignments between Views)不再依赖于显式的海量负样本对比,而是通过在线聚类和交换预测的新范式,实现了性能与效率的双重提升。
目录
1. 第一阶段:百花齐放
1. Inst Disc 个体判别
2. InvSpread 个体判别 minibatch版
3. CPC 生成式
4. CMC 多视图
第二阶段:19-20年CV双雄 MoCo + SimCLR
1. MoCov1 动量对比
2. SimCLRv1
3. MoCov2
4. SimCLRv2
5. SWaV 对比+聚类
对比学习论文综述【论文精读】
1. 第一阶段:百花齐放
1. Inst Disc 个体判别
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
在有监督分类中 对于豹子的前几名分类也都是和豹子特别相关的。这是因为这些类别的图片本身就很相似。
提出代理任务:个体判别
代理任务pretext的意思是 不是分类 分割 检测 这种有实际应用场景的任务,主要为了学习一个好的特征。
在无监督学习中 训练没有标签 代理任务用途是生成一个自监督信号充当ground truth.
目标函数 往往是为了衡量 现有值和目标值的差异。
判别式(比如一个pretext是 给中间的图和另一张图 问另一张图在中间图的哪个方位)
生成式(比如重构整张图) 对抗性(如GAN)是两个概率分布之间的差异。
对比学习特殊在 目标函数是变动的。

我们现在把每一张图片 都单独看作一个类别,目标把每一张图片都区分开来。
通过CNN把所有的图片 编码成一个128D的特征(因为数据集有128w张图片 每张图不能存太多)。
希望他们在最后的特征空间里尽可能分开。
正样本就是图片本身 以及数据增强;负样本就是数据集中所有其他的样本 存放在Memory Bank。
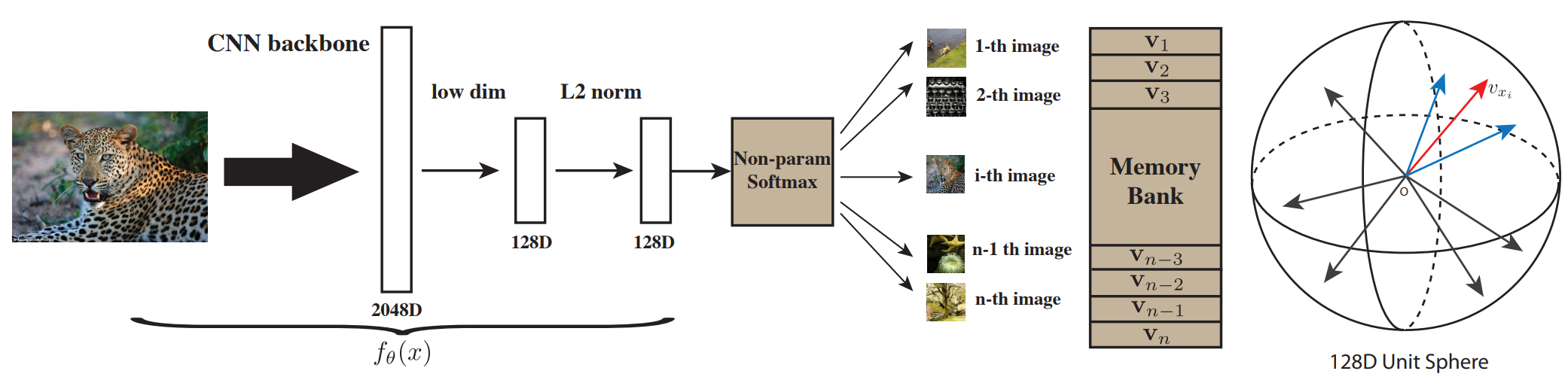
这篇论文 对比学习时用一个batch 256个正样本 以及从Memory Bank抽取4096个负样本。
用NCE loss 噪声对比估计 对比学习后 再更新Memory Bank 这个样本的特征 损失函数如下。
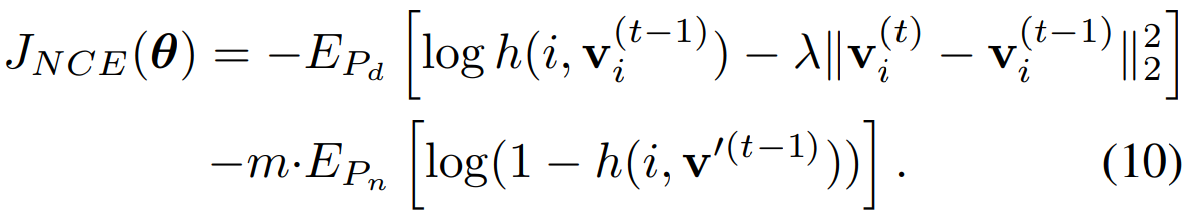
传统Softmax在计算损失时,需要为每个样本计算与所有其他数百万个实例的相似度并进行归一化,计算成本(O(n))高到无法承受。
NCE 将一个复杂的多分类问题转化为许多简单的二分类问题。只需要学会区分它和随机采样的一小部分“噪声”样本(负样本)即可。
每个“类”(实例)只有一个样本,每个epoch只被看到一次。导致网络参数和记忆库中的特征更新非常剧烈和不稳定,损失震荡大,收敛慢。
Proximal Regularization (近端正则化)在损失函数中添加一个约束项,限制当前迭代计算出的新特征 v_i^(t) 与上一迭代中存储在记忆库里的旧特征 v_i^(t-1) 之间的变化不要过大。
2. InvSpread 个体判别 minibatch版
Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
一个编码器 端到端 不需要借助外部数据结构存储大量负样本。正负样本都来自一个minibatch。
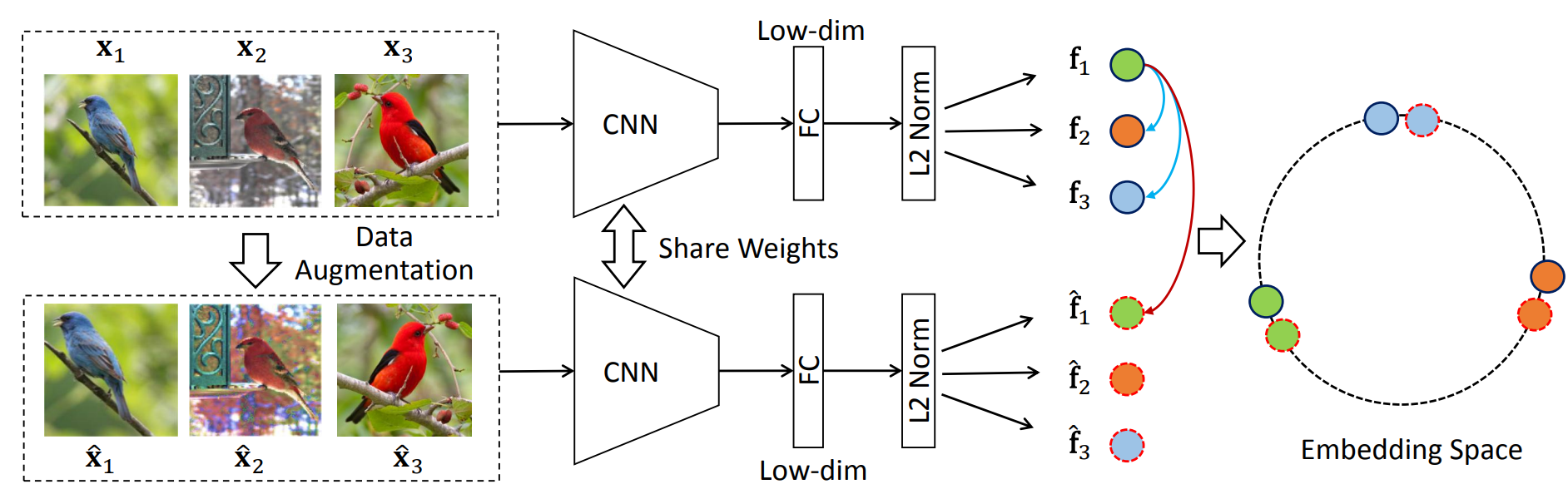
取一个minibatch 比如256张图片。每个图像 都对应数据增强一个样本。
正样本用这个数据增强的,负样本用其余255*2张图。
SimCLR 前身,但是负样本数目不够多,SimCLR还有强大的数据增广和MLP projector。
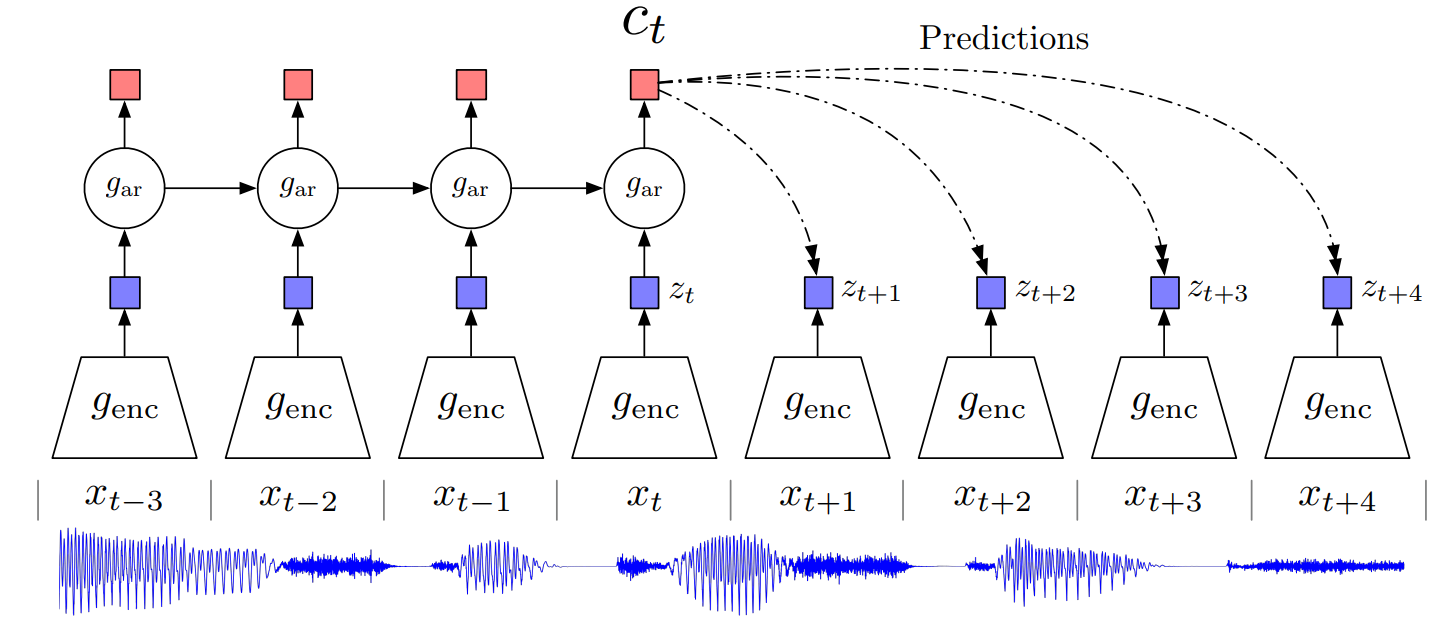
3. CPC 生成式
Representation Learning with Contrastive Predictive Coding
预测 生成式代理任务(前两个个体判别 属于判别式);
t 时刻之前的时间点,先进一个encoder编码器,再用自回归模型(autoregressive 如RNN LSTM)
得到 上下文表征 complex representation 再用这些C预测后面的时间点。
正样本 未来的真实输入 通过编码器的结果。负样本 随机一个段 通过编码器的结果。
这个架构普适性(把独立单元 换成 patch 单词)可以在音频 图片 文字 强化学习等多个方面应用。
4. CMC 多视图
Contrastive Multiview Coding
最重要的信息 应该会在所有视角中共享。
学习一种表征,最大化同一场景不同视图间的互信息。(各个视角下都是这个物体 都是正样本)
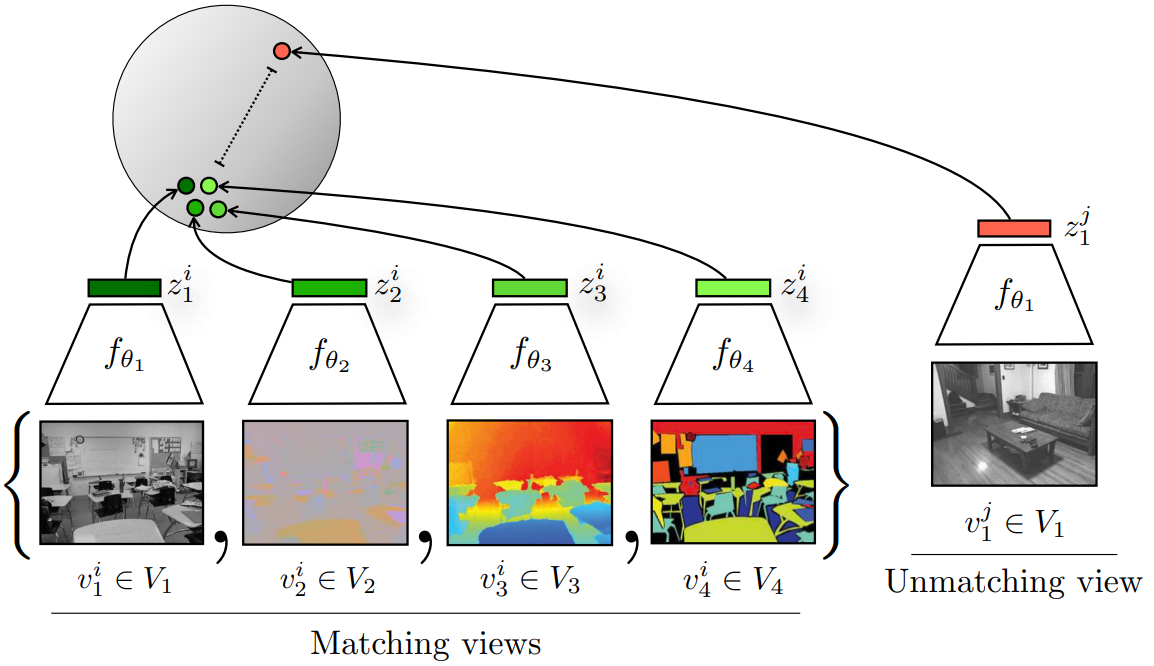
NYU RGBD数据集 提供不同传感器/模态:RGB图像、深度图像、表面法线和物体分割。
上面前四张图片 对应的绿豆应该靠近 红豆应该远离。
多视角多模态可行性 openAI后续推出 clip 一组图像和文本作为正样本对。
蒸馏工作想法:teacher模型输出与student模型输出 相对应。
局限性:不同视角处理起来不同 可能需要多种编码器 比如clip需要一个大语言模型处理文章 ViT处理图像。
未来考虑 用Transformer 处理两个模态。
第二阶段:19-20年CV双雄 MoCo + SimCLR
1. MoCov1 动量对比
Momentum Contrast for Unsupervised Visual Representation Learning
MoCo 论文逐段精读【论文精读】
无监督和监督表示学习之间的差距已被大幅缩小。MoCo在7个下游任务 超过了ImageNet有监督训练模型。
把之前的对比学习方法归纳总结成一个字典查询的问题。
好的字典特性:1.大 2.训练时一致性 ; 好的无监督预训练表征 能在下游任务表现很好。
维护一个队列来存储最近批次的特征作为负样本,解决大字典问题;还有好处是 FIFO 让最古老的那些样本先出队,更利于一致性。
用移动平均编码器 解决字典特征不一致问题。![]()
损失函数 InfoNCE 一个正样本和K个负样本。
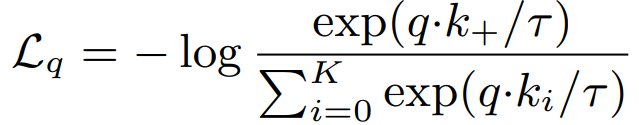
目标函数 query 和 key 同类别的时候 损失尽量小;不同类别 损失尽量大
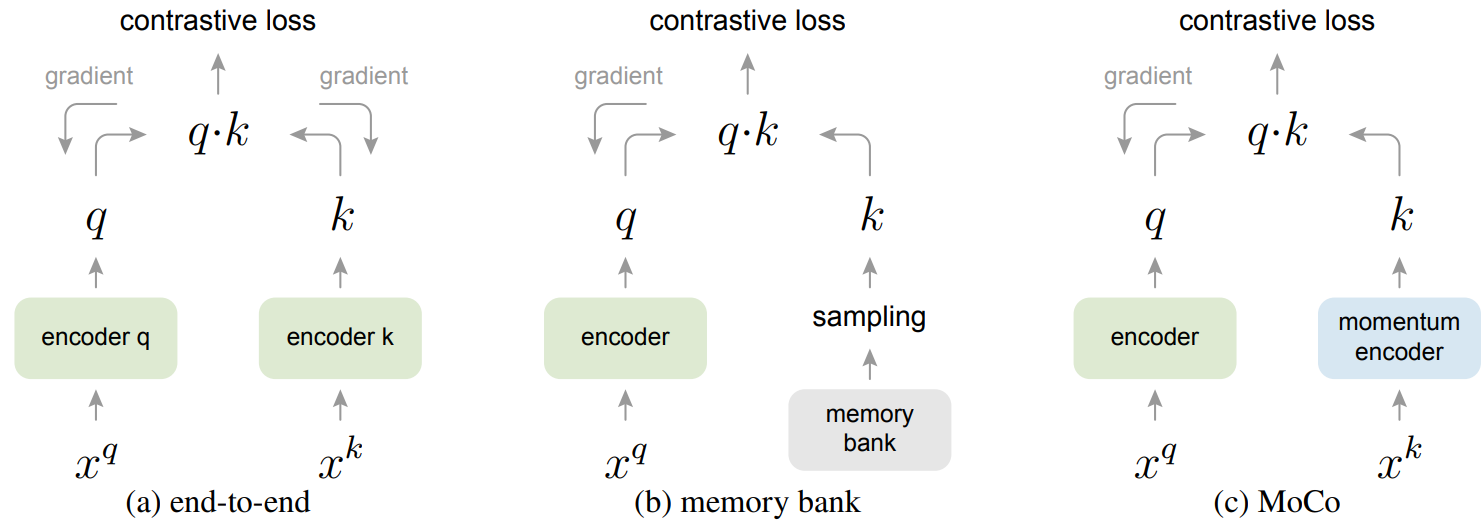
编码器 q 负责梯度学习;编码器k不能梯度进行 否则一直变化(参考答案不稳定 可能导致一起退化)
memory bank采样会导致特征长时期不变化 特征更新学习了很多 标准答案还是之前的 影响学习更新效率。
MoCo采用动量更新的方式更新编码器k。
-
Memory Bank(旧方法):像一个停滞不动的老教授。学生一直在进步,但教授还用几十年前的老标准来考你,无法衡量学生的真实水平。
-
如果用梯度更新k(错误方法):像一个毫无主见的考官。学生说什么,考官就立刻把自己的答案改成和学生一样,考试失去了意义。
-
MoCo的动量编码器k(正确方法):像一个经验丰富、稳重权威的首席教授。他会关注优秀学生(
Encoder_q)的最新研究成果,并审慎地、一点点地吸收到自己的知识体系(参数)中,以此来更新自己的教案(字典)。他既保持了自己知识体系的一致性和权威性(稳定性),又在不断与时俱进(渐进性),是学生最理想的学习对象。

2. SimCLRv1
A Simple Framework for Contrastive Learning of Visual Representations
在InvSpread基础上
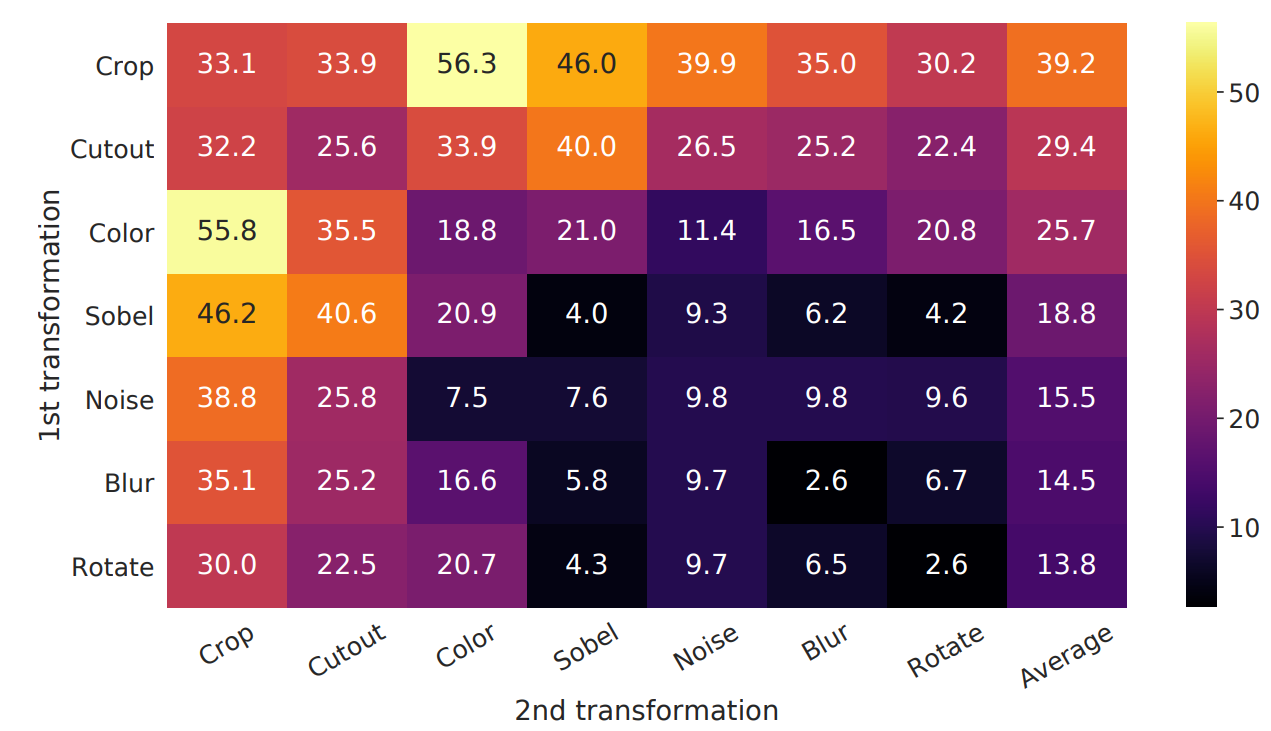
(1)用了更多的数据增强(裁剪、改变色彩、旋转、cutout、高斯噪声、高斯模糊、sobel滤波器)

哪些数据增强有用?进行消融实验:对角线为一种 其余为横纵两种结合。
图中表现出 Crop裁剪 和Color改变颜色是最有效的。
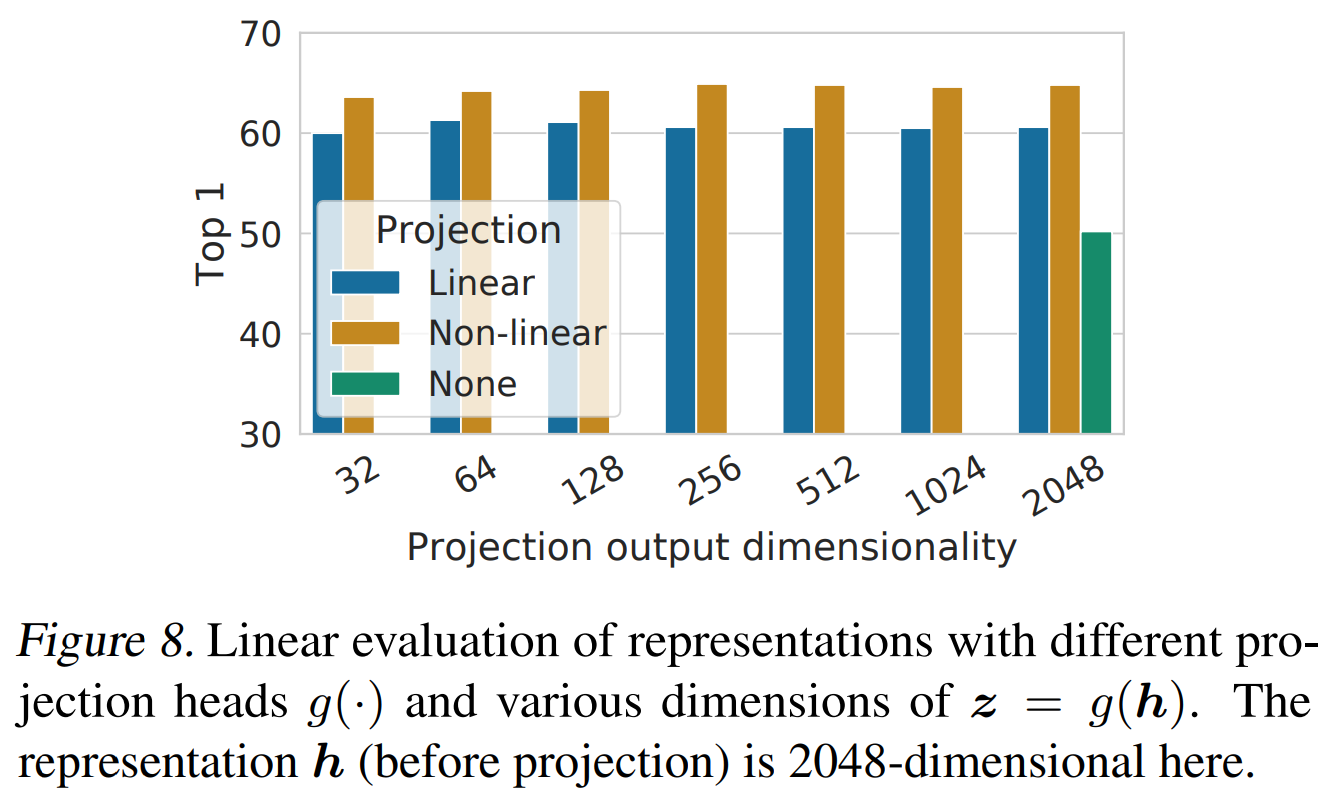
(2)在表征h和衡量损失的特征z 之间加了一个g函数(可学习的非线性变换)MLP层。
为了公平比较效果 下游任务时用h 不用中间的投射函数。
(3)对比损失函数 使用归一化与温度参数;
(4)更大的批次(更多负样本)更长的训练(epoch)更深的网络 对比学习从海量无标签数据中学到更强大的表示
3. MoCov2
Improved Baselines with Momentum Contrastive Learning
在SimCLR出来之后 使用它的数据增强 以及加MLP层的trick 效果更好。
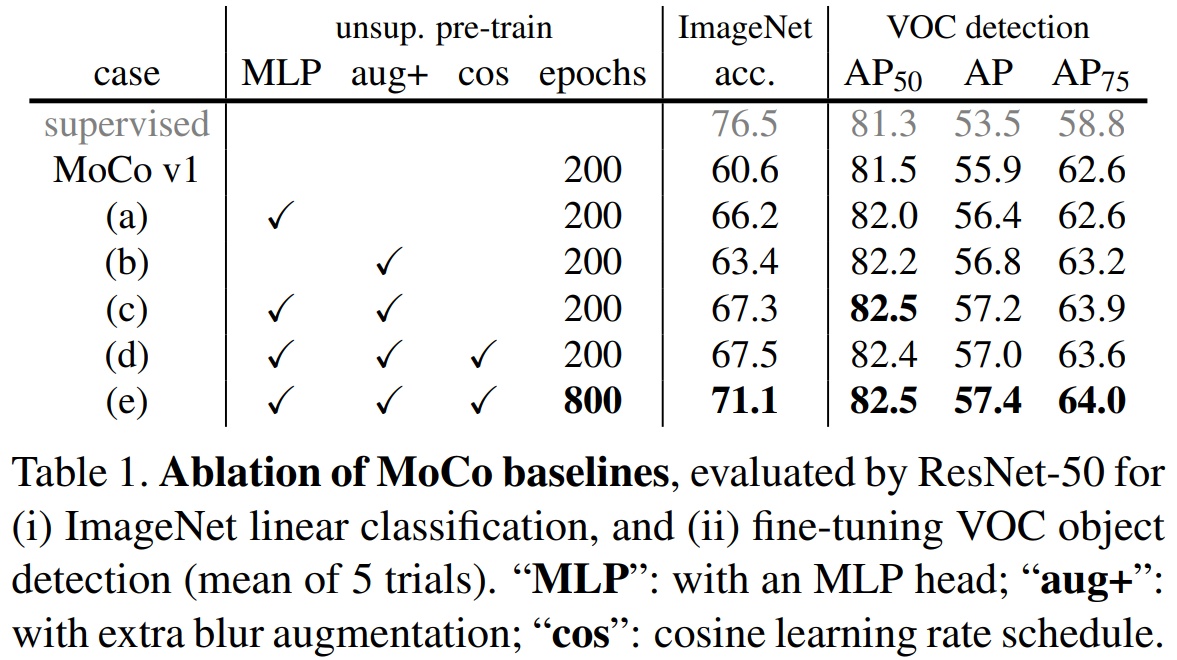
同等epoch 和SimCLR比较:同200epochs 高一个点;800epochs 比SimCLR 1000epochs高两个点。
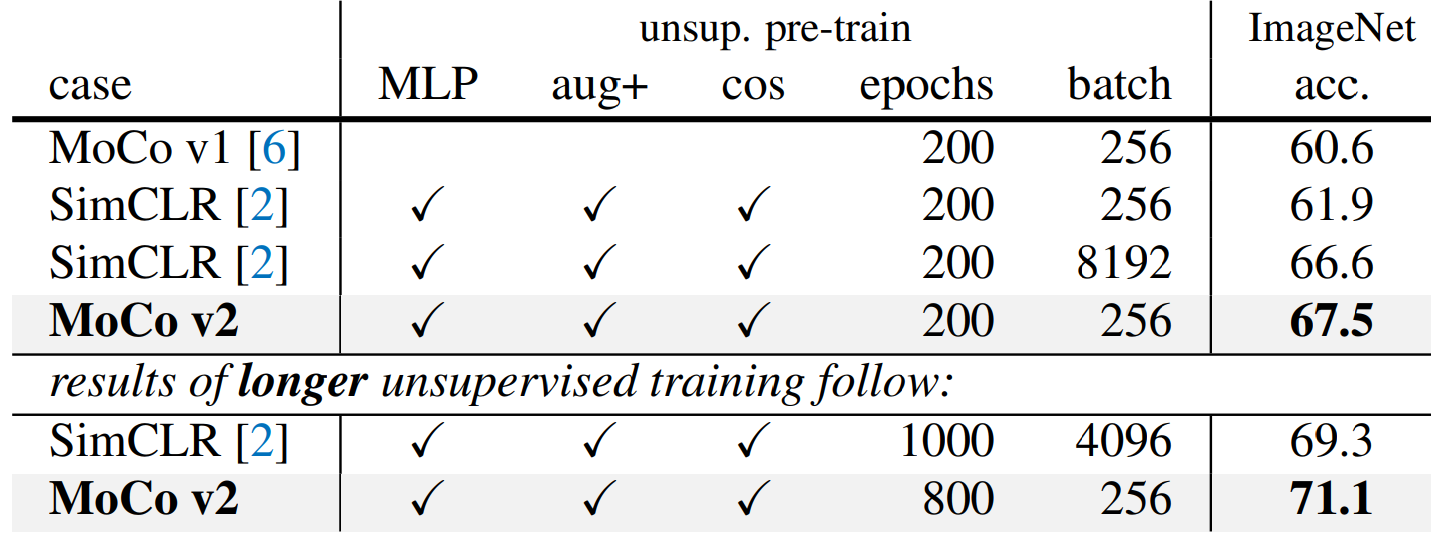
在内存使用和训练耗时也有优势。

4. SimCLRv2
Big Self-Supervised Models are Strong Semi-Supervised Learners
架构受到Noisy Student启发(ImageNet 数据集上实现了 88.4% 的 top-1 准确率,首次超越了人类水平的精度)
Self-training with Noisy Student improves ImageNet classification
使用已标注的数据训练一个教师模型,然后用这个教师模型为大量未标注的数据生成“伪标签”,再用这些生成的伪标签和原始标注数据一起,训练一个更大的学生模型。关键在于,在训练学生模型时,要注入各种“噪声”。
这个过程可以迭代进行:将训练好的学生模型作为新的教师模型,为下一轮生成伪标签,如此反复。这种方法之所以有效,是因为“噪声”的加入迫使学生模型不能简单地模仿教师模型的输出,而必须学习更鲁棒、更通用的特征,从而能够超越教师模型的性能。
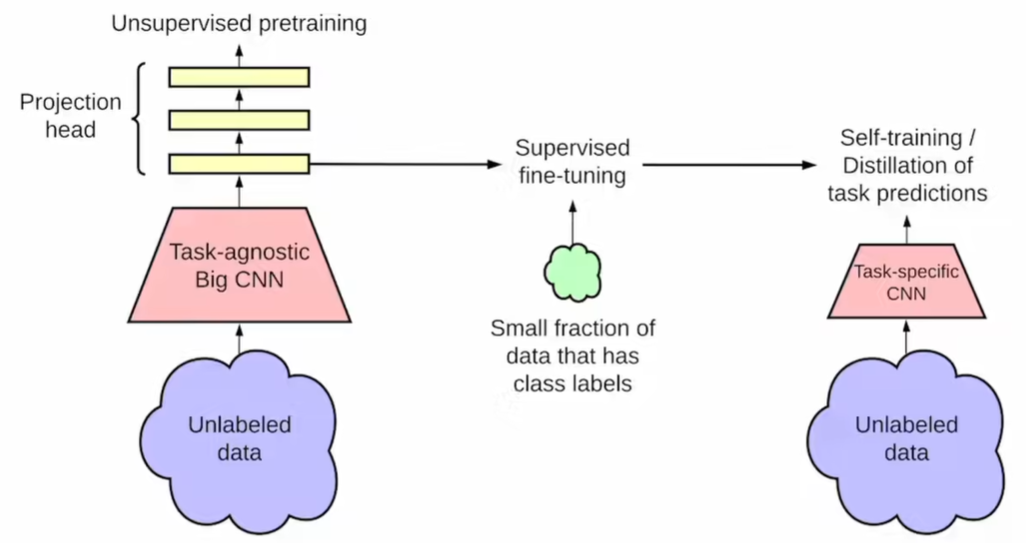
v1-v2 对比学习上升级的三个点:
(1)无监督学习 模型越大效果越好 ResNet-50 -> ResNet-152 更大的模型
(2)fc + relu + fc + relu 由一层变成两层的MLP
(3)借鉴MoCo的动量编码器 (且SimCLRv2 负样本数 minibatch也做到很大了 达到8192)
5. SWaV 对比+聚类
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
聚类也是一种无监督特征表示。相似的在聚类中心 不相似的远一些。
原做法 和大量负样本比(比如6w) 首先低效 其次只有到所有数据的一小部分 6/128。
考虑3000个聚类中心 把x的特征z 乘以矩阵C(前一维度为特征数 后一维度为聚类中心数)
得到的Q 相当于在不同聚类中心的比例;(相当于和聚类中心作比较)
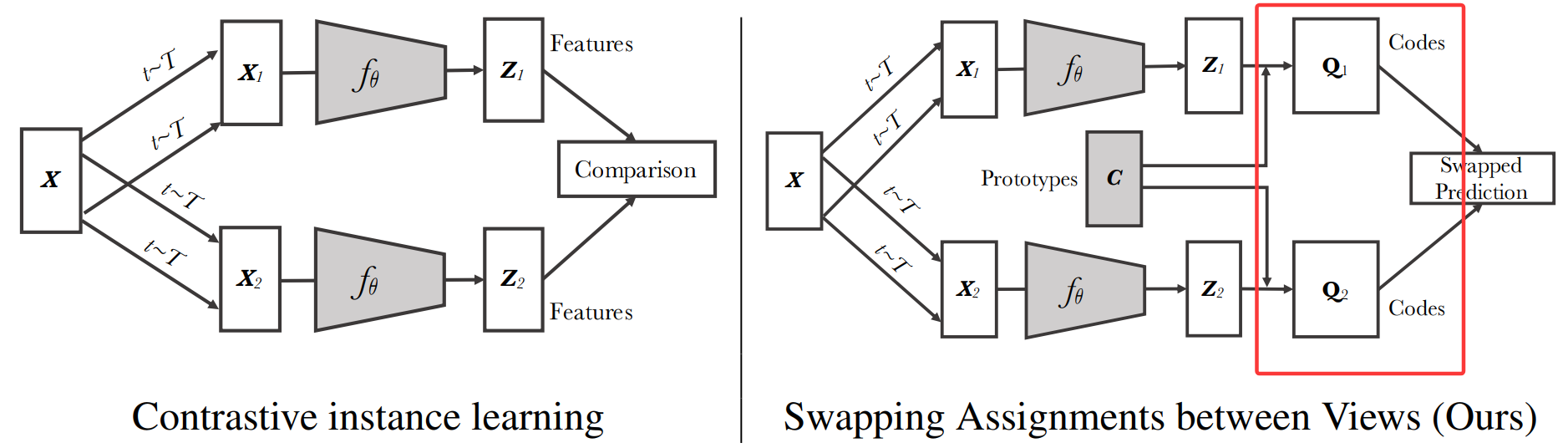
x做两次数据增强得到x1 x2 分别通过编码器得到 z1和z2也是相似的 所以可以进行“swapped” prediction 换位预测。分别用 C*z1,C*z2预测 Q2 Q1。
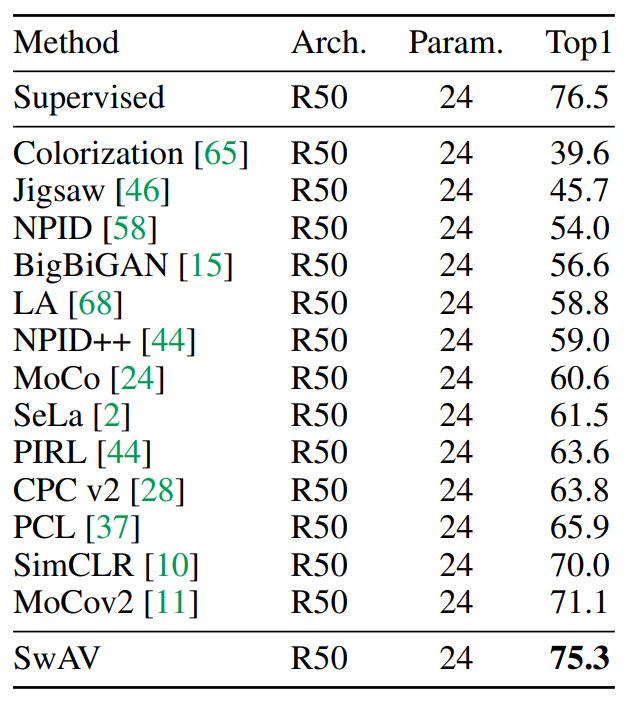
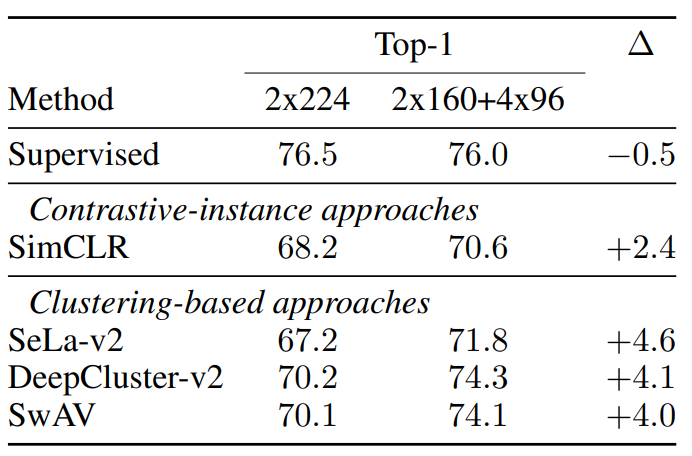
Trick:Multi-crop 把2*224 改成更多小块区域 2*160+4*96 分别捕捉全局和局部特征 提升四个点。(对多种对比学习模型 都有用)