数据库(四)MySQL读写分离原理和实现
文章目录
- 前言
- 一、MySQL 读写分离概述
- 1.1 工作原理
- 1.2 为什么要读写分离
- 1.3 实现方式
- 1.3.1 应用程序层实现
- 1.3.2 中间件层实现
- 二、什么是 MyCat
- 三、MyCat 安装与配置
- 3.1 下载与解压
- 3.2 创建用户并修改权限
- 3.3 目录说明
- 3.4 Java 环境要求
- 四、MyCat 启动与配置
- 4.1 配置环境变量
- 4.2 配置 Hosts
- 4.3 配置 MyCat
- 4.3.1 配置 server.xml
- 4.3.2 配置 schema.xml
- 4.4 启动 MyCat
- 五、配置 MySQL 主从复制
- 5.1 主库 (Master) 配置
- 5.2 从库 (Slave) 配置
- 六、测试读写分离
- 总结
前言
在现代互联网应用中,数据库往往是最核心同时也是最容易成为性能瓶颈的组件。面对海量数据和高并发访问,单台数据库服务器常常力不从心。MySQL 主从复制与读写分离技术,是解决这一问题的经典架构方案。它通过将数据库的写操作和读操作分散到不同的服务器上,极大地提升了数据库集群的吞吐能力和可用性。而 MyCat,作为一款流行的开源数据库中间件,能够以对应用透明的方式轻松实现这一架构,无需修改业务代码。本文将详细介绍如何使用 MyCat 来配置和管理 MySQL 主从读写分离环境。
一、MySQL 读写分离概述
1.1 工作原理
MySQL 读写分离的核心思想是将数据库操作按类型分发:
- 主库 (Master):专门负责处理写操作(
INSERT、UPDATE、DELETE)。 - 从库 (Slave):专门负责处理读操作(
SELECT)。 - 主从之间的数据一致性通过 MySQL 主从复制 (Replication) 机制来保证。
- 其内部数据同步流程为:主库上的写操作会被记录到二进制日志 (Binary Log) 中,从库通过读取和重放这些日志来保持与主库的数据同步。
1.2 为什么要读写分离
采用读写分离架构主要带来以下优势:
- 分担负载:突破单台服务器的性能瓶颈,将压力分散到多个节点。
- 缓解锁争用:写操作会施加排他锁(X锁),阻塞读操作。读写分离后,读操作在从库进行,避免了与主库写操作的锁竞争。
- 提升查询性能:从库可以选用不同的存储引擎(如 MyISAM),在特定场景下可能获得比 InnoDB 更好的查询性能。
- 提高可用性:增加了数据冗余,当主库出现故障时,可以从库可以快速切换,保证服务不中断。
1.3 实现方式
实现读写分离主要有两种方式:
1.3.1 应用程序层实现
- 优点:部署简单,对于访问压力中等的系统,性能表现良好。
- 缺点:将数据库路由逻辑与业务代码耦合,难以维护,且难以支持高级功能(如分库分表、故障自动转移),不适用于大型复杂系统。
1.3.2 中间件层实现
- 优点:
- 架构灵活:对应用程序透明,应用像连接单一数据库一样连接中间件。
- 功能强大:可以透明地实现分库分表、故障转移(Failover)、监控等高级功能。
- 常用中间件:
- Cobar:阿里巴巴开源的分布式数据库中间件,目前已停止更新。
- MyCat:基于 Cobar 二次开发,社区活跃,是国内非常流行的开源中间件。
- OneProxy:商业收费的中间件,以高并发下的稳定性著称。
- Vitess:YouTube 开发并使用,架构复杂,功能强大。
- 其他:Kingshard、Atlas、MaxScale、MySQL Router 等。
二、什么是 MyCat
MyCat 是一个开源的、面向企业应用开发的数据库中间件。它可以被看作是一个模拟 MySQL 协议的数据库代理服务器,前端应用程序可以像连接 MySQL 一样连接它,而后端它可以管理一个真正的数据库集群。
其主要特点包括:
- 支持 MySQL 协议,应用程序几乎无需改动。
- 支持事务和 ACID 属性。
- 可以作为 MySQL 集群或 Oracle 集群的廉价替代方案。
- 不仅支持关系型数据库,还融合了内存缓存、NoSQL 以及 HDFS 大数据技术。
- 核心功能是实现数据库的读写分离和分库分表。
三、MyCat 安装与配置
3.1 下载与解压
首先从官方渠道下载 MyCat 的发布版本。
# 下载 MyCat (请替换为最新版本的下载链接)
wget https://github.com/MyCATApache/Mycat-download/releases/download/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz# 解压到 /usr/local/ 目录
tar -xf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz -C /usr/local/
cd /usr/local/mycat
3.2 创建用户并修改权限
为安全起见,建议创建一个专门的系统用户来运行 MyCat。
useradd mycat
passwd mycat # 为 mycat 用户设置密码
chown -R mycat.mycat /usr/local/mycat # 将 mycat 目录的属主改为 mycat 用户
3.3 目录说明
了解 MyCat 的主要目录结构:
bin/:存放可执行文件和启动/停止的 Shell 脚本(如mycat start,mycat stop)。conf/:核心配置目录。server.xml:配置 MyCat 服务器参数、用户及权限。schema.xml:配置逻辑库、逻辑表、数据节点以及数据源(读写分离、分片规则)。rule.xml:配置分片规则。
lib/:存放 MyCat 运行所需的 Java JAR 包。logs/:存放日志文件,运行日志和 SQL 日志对排错非常重要。
3.4 Java 环境要求
MyCat 基于 Java 开发,需要预先安装 JDK(1.7 及以上版本)。
# 安装 JDK 示例
tar xf jdk-8u91-linux-x64.tar.gz -C /usr/java/# 配置环境变量
vim /etc/profile.d/java.sh
# 添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar# 使环境变量生效
source /etc/profile.d/java.sh
java -version # 验证安装
四、MyCat 启动与配置
4.1 配置环境变量
为了方便操作,可以配置 MyCat 的环境变量。
vim /etc/profile.d/mycat.sh
# 添加以下内容
export MYCAT_HOME=/usr/local/mycat
export PATH=$MYCAT_HOME/bin:$PATHsource /etc/profile.d/mycat.sh
4.2 配置 Hosts
如果使用主机名进行配置,需要在所有集群节点的 /etc/hosts 文件中配置 IP 与主机名的映射关系。
192.168.10.16 master
192.168.10.14 slave1
192.168.10.15 slave2
4.3 配置 MyCat
4.3.1 配置 server.xml
此文件用于定义连接到 MyCat 的用户及其权限。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/"><system>...</system> <!-- 系统配置属性,可保持默认 --><!-- 定义一个用户,用户名 mycat,密码 123456 --><user name="mycat"><property name="password">123456</property><property name="schemas">HelloDear</property> <!-- 该用户可访问的逻辑库名 --></user><!-- 定义一个只读用户 --><user name="user"><property name="password">user</property><property name="schemas">HelloDear</property><property name="readOnly">true</property> <!-- 只读属性 --></user>
</mycat:server>
4.3.2 配置 schema.xml
这是最核心的配置文件,定义了逻辑库、表、数据节点以及数据源(读写分离策略)。
首先备份原始文件:
mv /usr/local/mycat/conf/schema.xml /usr/local/mycat/conf/schema.xml.bak
然后创建新的 schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><!-- 定义逻辑库 schema --><schema name="ha" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema><!-- 定义数据节点 --><dataNode name="dn1" dataHost="dthost" database="ha"/><!-- 定义数据主机组 --><dataHost name="dthost" maxCon="500" minCon="10" balance="1"writeType="0" dbType="mysql" dbDriver="native"switchType="-1" slaveThreshold="100"><!-- 心跳检测语句 --><heartbeat>select user()</heartbeat><!-- 写节点(主库)配置 --><writeHost host="master" url="192.168.10.16:3306" user="mycat" password="123456"><!-- 读节点(从库)配置,内嵌在 writeHost 中 --><readHost host="slave1" url="192.168.10.14:3306" user="mycat" password="123456"/><readHost host="slave2" url="192.168.10.15:3306" user="mycat" password="123456"/></writeHost></dataHost>
</mycat:schema>
关键参数详解:
-
balance负载均衡策略:0:不开启读写分离,所有读请求都发往writeHost。1:所有readHost和备用的writeHost都参与读操作的负载均衡。这是最常用的模式。2:所有读操作随机在所有writeHost和readHost上分发。3:所有读操作随机分发到writeHost对应的readHost上执行。
-
writeType写节点策略:0:所有写操作发送到配置的第一个writeHost,第一个宕机后自动切换到第二个。推荐使用。
-
switchType切换策略:-1:不自动切换。1:自动切换。2:基于 MySQL 主从同步状态决定是否切换。
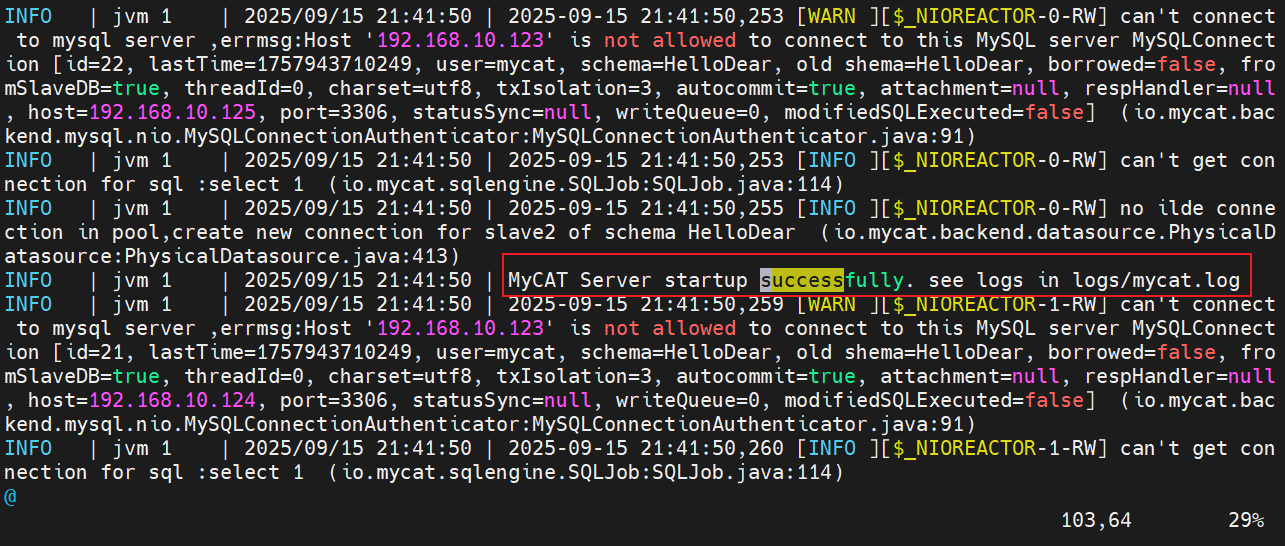
4.4 启动 MyCat
使用 mycat 脚本来启动服务。
cd /usr/local/mycat/bin
./mycat start # 启动
./mycat status # 查看状态
./mycat stop # 停止# 查看启动日志,这是排查问题的第一步
tail -f /usr/local/mycat/logs/wrapper.log
五、配置 MySQL 主从复制
MyCat 本身不负责数据同步,它依赖于后端 MySQL 自身的主从复制功能。
5.1 主库 (Master) 配置
- 修改配置文件
/etc/my.cnf:[mysqld] server-id=1 # 唯一服务器ID log-bin=master-bin # 开启二进制日志 binlog-do-db=ha # 指定要复制的数据库 binlog-ignore-db=mysql # 忽略系统库 - 重启 MySQL 并创建账户:
CREATE DATABASE ha; CREATE USER 'mycat'@'%' IDENTIFIED BY '123456'; GRANT ALL PRIVILEGES ON *.* TO 'mycat'@'%'; FLUSH PRIVILEGES;
5.2 从库 (Slave) 配置
- 修改配置文件
/etc/my.cnf:[mysqld] server-id=2 # 每个从库的 server-id 必须唯一 - 配置主从复制链路:
CHANGE MASTER TO MASTER_HOST='192.168.10.124', MASTER_USER='mycat', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin-master.000001', -- 需根据主库show master status的结果修改 MASTER_LOG_POS=603; -- 需根据主库show master status的结果修改START SLAVE; - 检查从库状态:
确保SHOW SLAVE STATUS\GSlave_IO_Running和Slave_SQL_Running两项均为Yes。
六、测试读写分离
配置完成后,可以通过 MyCat 连接数据库并进行测试。
#先安装数据库
yum install -y mariadb-server mariadb
systemctl start mariadb.service
#在客户端服务器上测试
mysql -u mycat -p123456 -h 192.168.10.123 -P8066
#通过mycat服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器
#在主服务器上:
use HelloDear;
create table test (id int(10),name varchar(10),address varchar(20));#在两台从服务器上:
stop slave; #关闭同步
use db_test;
#在slave1上:
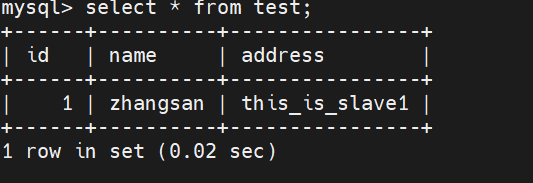
insert into test values('1','zhangsan','this_is_slave1');
#在slave2上:
insert into test values('2','lisi','this_is_slave2');
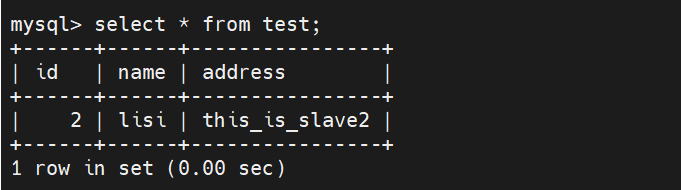
#在主服务器上:
insert into test values('3','wangwu','this_is_master');
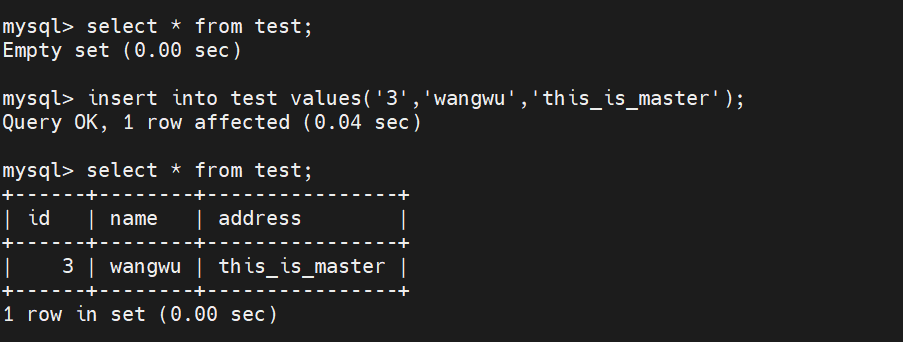
#在客户端服务器上:
use HelloDear;
select * from test; #客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据#在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
start slave;
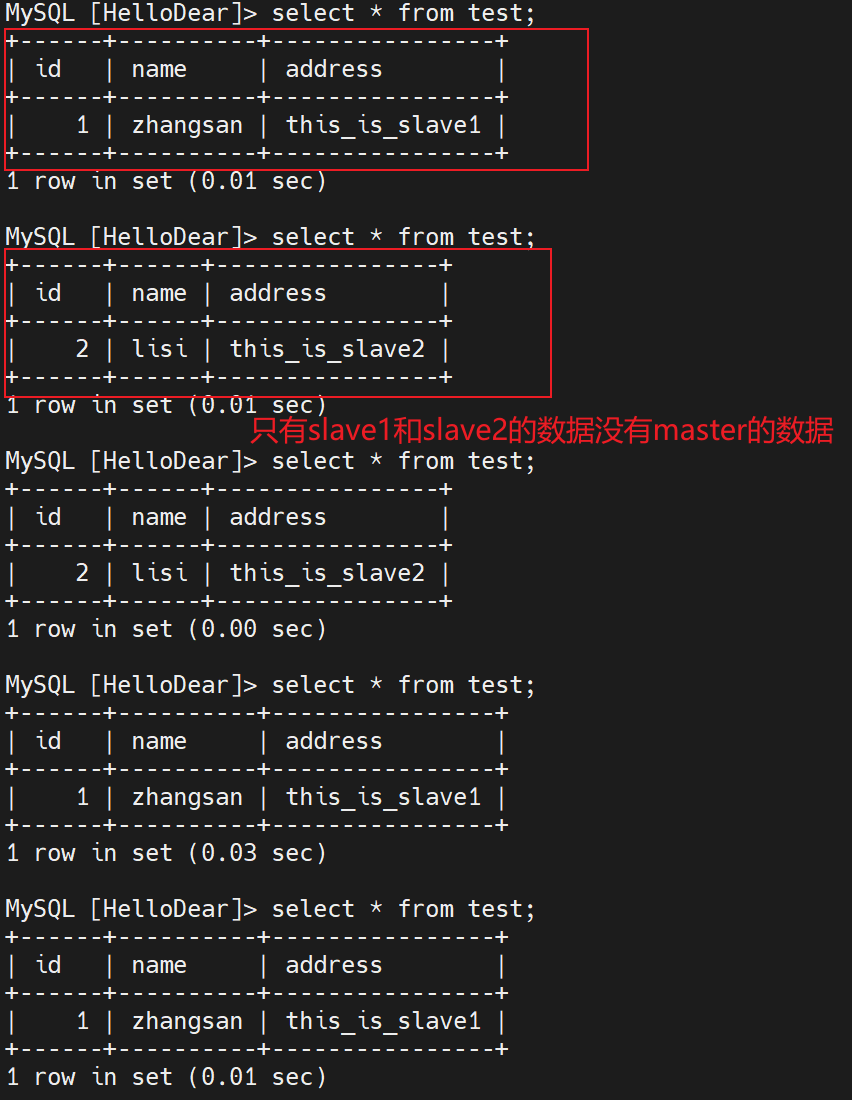
总结
通过本文的步骤,我们成功地使用 MyCat 搭建了一套 MySQL 主从读写分离架构。我们来回顾一下核心要点:
- 解耦与透明化:MyCat 作为中间件,完美地解耦了应用程序和底层数据库集群。应用程序无需关心数据是如何路由的,就像操作单机数据库一样简单。
- 核心配置:成功的关键在于正确配置
schema.xml文件,特别是dataHost中的balance(读负载策略)、writeType(写节点策略)参数,以及正确填写后端数据库的连接信息。 - 依赖基础:MyCat 的读写分离功能强烈依赖于 MySQL 自身的主从复制数据同步机制。必须首先确保主从复制配置正确且运行正常。
- 性能与高可用:此架构不仅提升了数据库的读性能,通过配置多个从库实现了负载均衡,还通过主从冗余提高了系统的整体可用性。
这种“MySQL主从 + MyCat读写分离”的架构,是应对中等规模数据库压力非常有效且成熟的方案,非常适合互联网初创公司和发展中的项目。